
Multimodal Semantic Collaborative Classification for Hyperspectral Images and LiDAR Data





Abstract
1. Introduction
- (1)
- Enhancing Land Cover Classification Accuracy with Instruction-driven Large Language Models: instruction-driven large language models guide the model to focus on and extract the critical features, thereby improving land cover classification accuracy.
- (2)
- Improving Multisource Data Feature Extraction with the ModaUnion Encoder: the ModaUnion encoder enhances multisource data feature extraction quality by implementing parameter sharing.
- (3)
- Addressing Multisource Heterogeneity with MoE-EN and Contrastive Learning: the MoE-EN structure and contrastive learning strategy enhance the expression of complementary information from each data source, effectively managing multisource heterogeneity.
2. Relate Work
2.1. Large Language Models
2.2. Multi-Modal Contrastive Representation Learning
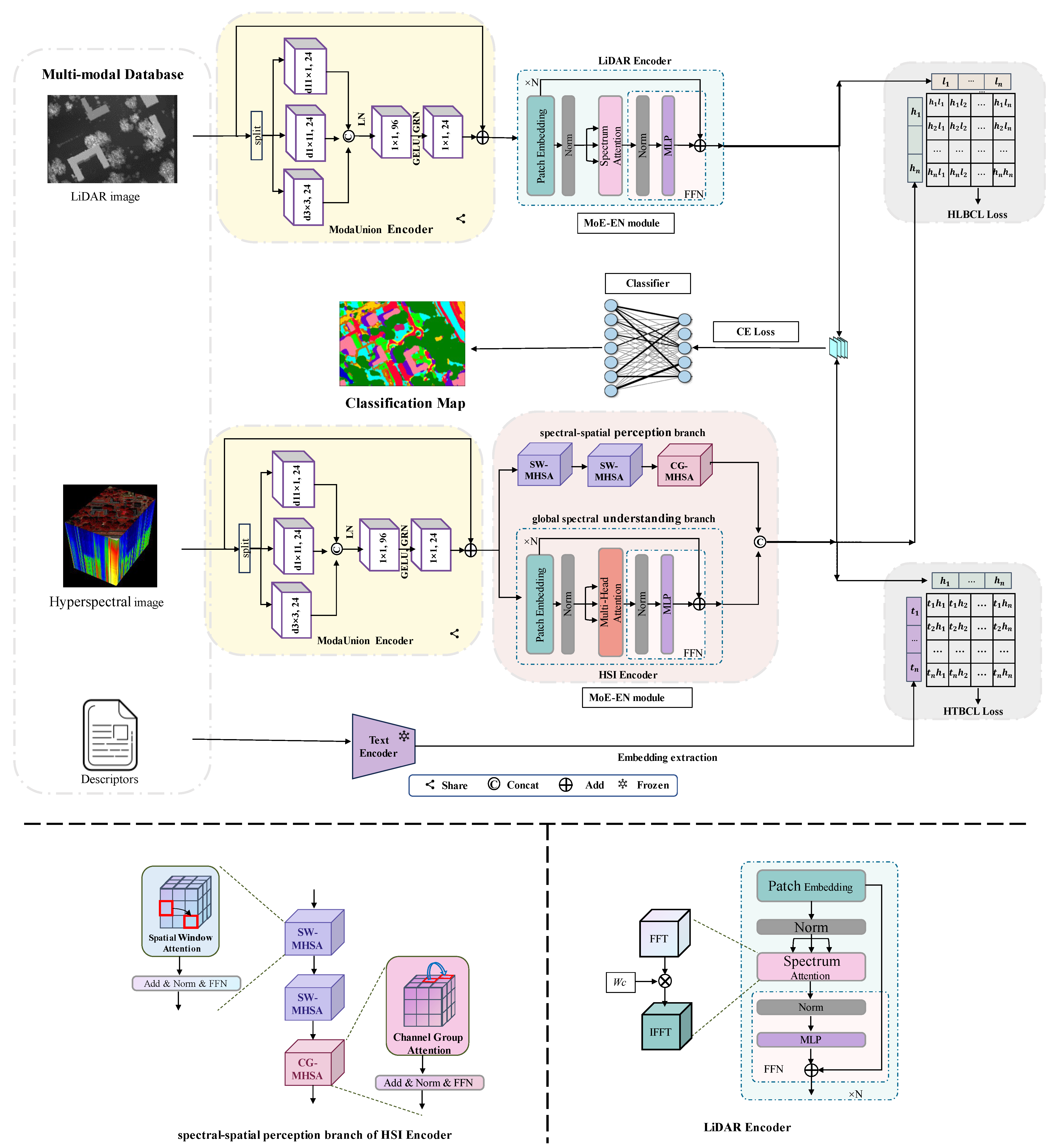
3. Method
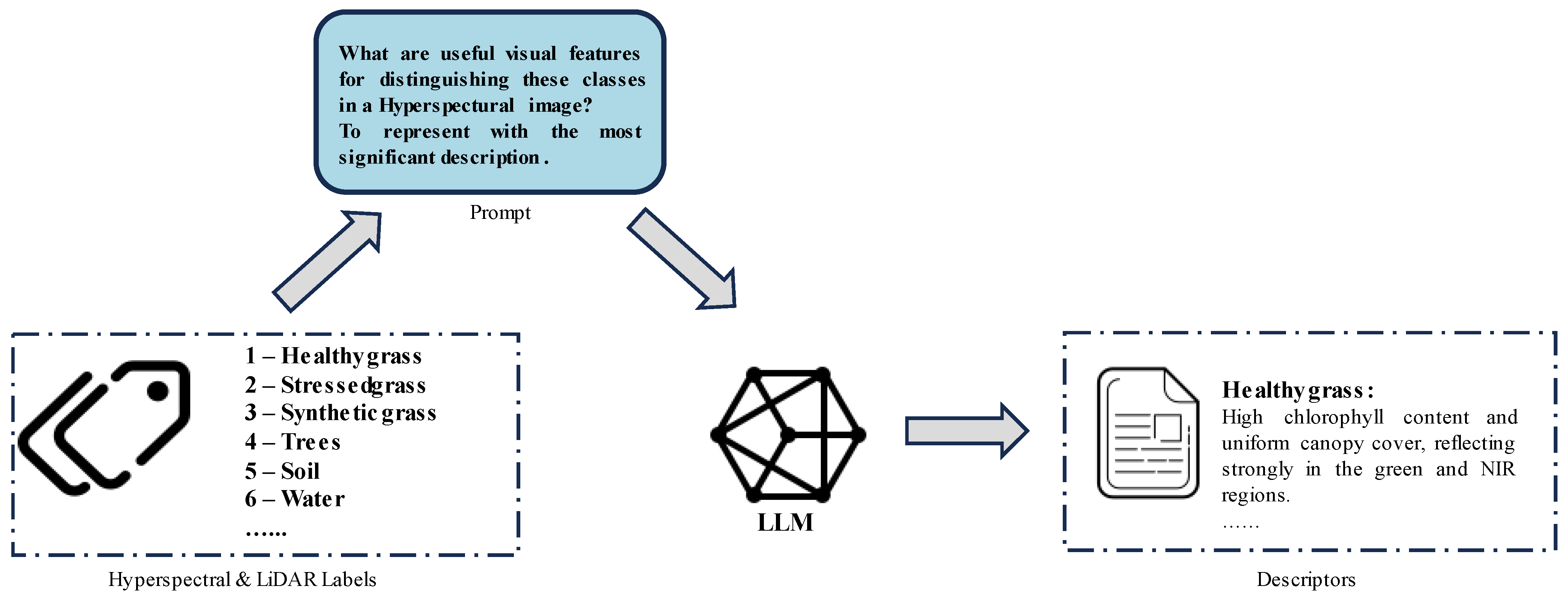
- (1)
- Automatic generation of category descriptions to create textual data corresponding to the categories.
- (2)
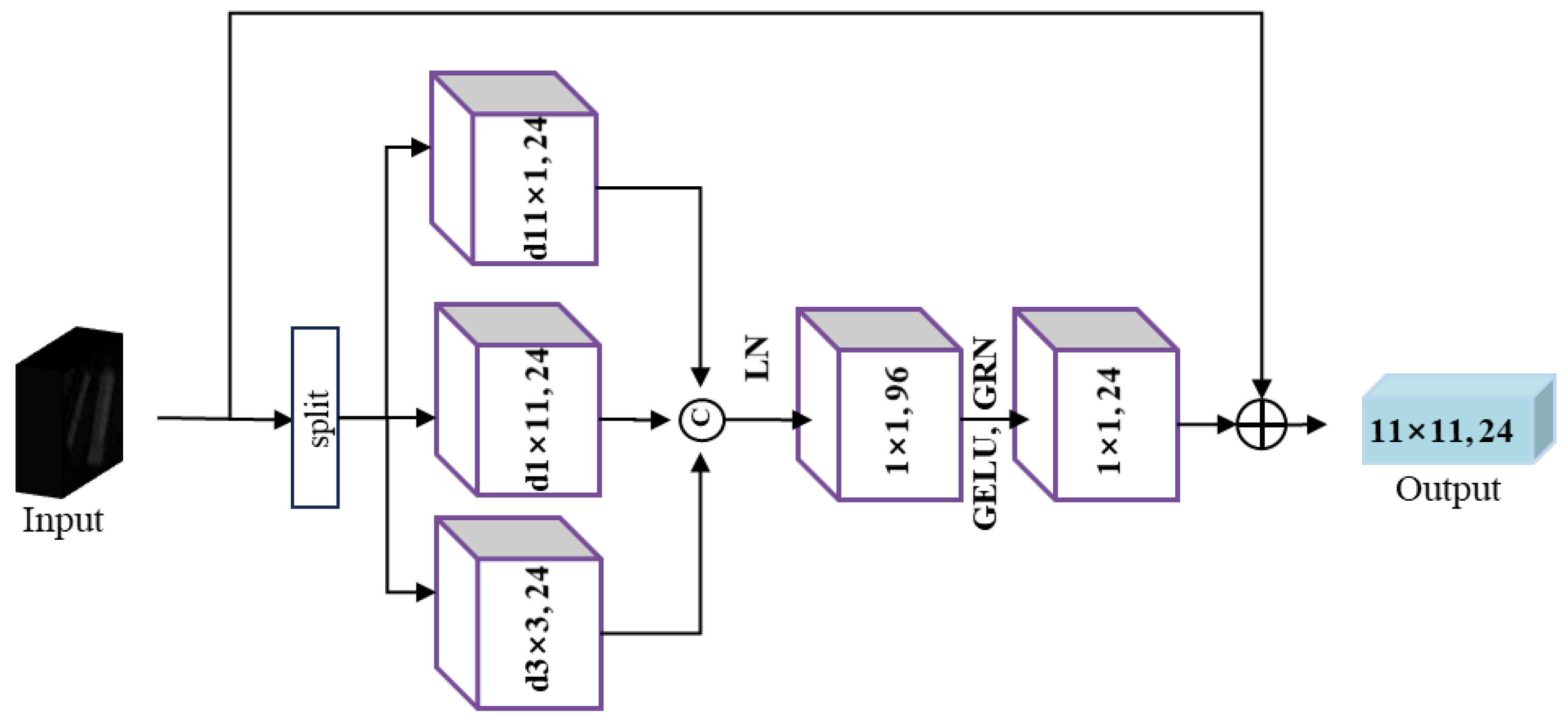
- ModaUnion Encoder is used for extracting shared features from HSI and LiDAR.
- (3)
- HSI and LiDAR Encoders are used for extracting visual embedding vectors. Text Encoder is used for extracting language embedding vectors.
- (4)
- HSI-LiDAR bidirectional contrastive loss (HLBCL), HSI-Text bidirectional contrastive loss (HTBCL), and cross-entropy (CE) loss are used for training the entire model.
3.1. Building Descriptors
3.2. Vision and Text Encoder
3.3. Loss Function
3.4. Final Classifier
| Algorithm 1 Training DSMSC2N model. |
| Input: HSI images: , LiDAR data: , Text data: , Training labels: |
| Output: land cover result: 1. Initialize: batch size = 64, epochs = 200, the initial learning rate set to 5 × 10−4 of AdamW; 2. Patches: Divide respectively; 3. for i = 1 to epochs do 4. \\ Extact Featre Embedding-ModaUnion Encoder 5. ; 6. ; 7. ; 8. ; 9. Optimize Feature Representation and Update the discriminators by optimizing Equation (8); 10. Obtain the land cover result: by computing Equations (17) and (18). 11. end for |
4. Results
4.1. Datasets
4.2. Implementation Details
4.3. Ablation Study
4.4. Comparison with Other Methods
4.5. Computational Complexity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Correction Statement
References
- Sishodia, R.P.; Ray, R.L.; Singh, S.K. Applications of remote sensing in precision agriculture: A review. Remote Sens. 2020, 12, 3136. [Google Scholar] [CrossRef]
- Tan, K.; Jia, X.; Plazae, A. Special Section Guest Editorial: Satellite Hyperspectral Remote Sensing: Algorithms and Applications. J. Appl. Remote Sens. 2021, 42601, 1. [Google Scholar]
- Ahmad, M.; Shabbir, S.; Roy, S.K.; Hong, D.; Wu, X.; Yao, J.; Khan, A.M.; Mazzara, M.; Distefano, S.; Chanussot, J. Hyperspectral image classification—Traditional to deep models: A survey for future prospects. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 15, 968–999. [Google Scholar]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar]
- Liu, Q.; Xiao, L.; Yang, J.; Chan, J.C.-W. Content-guided convolutional neural network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6124–6137. [Google Scholar]
- Zakaria, Z.B.; Islam, M.R. Hybrid 3DNet: Hyperspectral Image Classification with Spectral-spatial Dimension Reduction using 3D CNN. Int. J. Comput. Appl. 2022, 975, 8887. [Google Scholar]
- Ma, A.; Filippi, A.M.; Wang, Z.; Yin, Z.; Huo, D.; Li, X.; Güneralp, B. Fast sequential feature extraction for recurrent neural network-based hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5920–5937. [Google Scholar]
- Yang, X.; Cao, W.; Lu, Y.; Zhou, Y. Hyperspectral image transformer classification networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5528715. [Google Scholar]
- He, L.; Li, J.; Liu, C.; Li, S. Recent advances on spectral–spatial hyperspectral image classification: An overview and new guidelines. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1579–1597. [Google Scholar]
- Zhang, Y.; Lan, C.; Zhang, H.; Ma, G.; Li, H. Multimodal remote sensing image matching via learning features and attention mechanism. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5603620. [Google Scholar]
- Ma, X.; Zhang, X.; Pun, M.-O.; Liu, M. A multilevel multimodal fusion transformer for remote sensing semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5403215. [Google Scholar]
- Wang, Q.; Chen, W.; Huang, Z.; Tang, H.; Yang, L. MultiSenseSeg: A cost-effective unified multimodal semantic segmentation model for remote sensing. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4703724. [Google Scholar]
- Li, J.; Hong, D.; Gao, L.; Yao, J.; Zheng, K.; Zhang, B.; Chanussot, J. Deep learning in multimodal remote sensing data fusion: A comprehensive review. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102926. [Google Scholar]
- Gómez-Chova, L.; Tuia, D.; Moser, G.; Camps-Valls, G. Multimodal classification of remote sensing images: A review and future directions. Proc. IEEE 2015, 103, 1560–1584. [Google Scholar]
- Ma, M.; Ma, W.; Jiao, L.; Liu, X.; Li, L.; Feng, Z.; Yang, S. A multimodal hyper-fusion transformer for remote sensing image classification. Inf. Fusion 2023, 96, 66–79. [Google Scholar]
- Ghamisi, P.; Rasti, B.; Yokoya, N.; Wang, Q.; Hofle, B.; Bruzzone, L.; Bovolo, F.; Chi, M.; Anders, K.; Gloaguen, R. Multisource and multitemporal data fusion in remote sensing: A comprehensive review of the state of the art. IEEE Geosci. Remote Sens. Mag. 2019, 7, 6–39. [Google Scholar]
- Dong, P.; Chen, Q. LiDAR Remote Sensing and Applications; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Fusion of hyperspectral and LIDAR remote sensing data for classification of complex forest areas. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1416–1427. [Google Scholar]
- Ghamisi, P.; Benediktsson, J.A.; Phinn, S. Land-cover classification using both hyperspectral and LiDAR data. Int. J. Image Data Fusion 2015, 6, 189–215. [Google Scholar]
- Dong, W.; Yang, T.; Qu, J.; Zhang, T.; Xiao, S.; Li, Y. Joint contextual representation model-informed interpretable network with dictionary aligning for hyperspectral and LiDAR classification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 6804–6818. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16133–16142. [Google Scholar]
- Yu, W.; Zhou, P.; Yan, S.; Wang, X. Inceptionnext: When inception meets convnext. arXiv 2023, arXiv:2303.16900. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Ding, M.; Xiao, B.; Codella, N.; Luo, P.; Wang, J.; Yuan, L. Davit: Dual attention vision transformers. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 74–92. [Google Scholar]
- Patro, B.N.; Namboodiri, V.P.; Agneeswaran, V.S. SpectFormer: Frequency and Attention is what you need in a Vision Transformer. arXiv 2023, arXiv:2304.06446. [Google Scholar]
- Zhang, M.; Li, W.; Tao, R.; Li, H.; Du, Q. Information fusion for classification of hyperspectral and LiDAR data using IP-CNN. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5506812. [Google Scholar]
- Zhao, G.; Ye, Q.; Sun, L.; Wu, Z.; Pan, C.; Jeon, B. Joint classification of hyperspectral and LiDAR data using a hierarchical CNN and transformer. IEEE Trans. Geosci. Remote Sens. 2022, 61, 5500716. [Google Scholar]
- Xue, Z.; Tan, X.; Yu, X.; Liu, B.; Yu, A.; Zhang, P. Deep hierarchical vision transformer for hyperspectral and LiDAR data classification. IEEE Trans. Image Process. 2022, 31, 3095–3110. [Google Scholar]
- Xu, X.; Li, W.; Ran, Q.; Du, Q.; Gao, L.; Zhang, B. Multisource remote sensing data classification based on convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 56, 937–949. [Google Scholar]
- Hong, D.; Gao, L.; Hang, R.; Zhang, B.; Chanussot, J. Deep encoder–decoder networks for classification of hyperspectral and LiDAR data. IEEE Geosci. Remote Sens. Lett. 2020, 19, 5500205. [Google Scholar]
- Li, J.; Liu, Y.; Song, R.; Liu, W.; Li, Y.; Du, Q. HyperMLP: Superpixel Prior and Feature Aggregated Perceptron Networks for Hyperspectral and Lidar Hybrid Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5505614. [Google Scholar]
- Wang, X.; Zhu, J.; Feng, Y.; Wang, L. MS2CANet: Multi-scale Spatial-Spectral Cross-modal Attention Network for Hyperspectral image and LiDAR Classification. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5501505. [Google Scholar]
- Song, T.; Zeng, Z.; Gao, C.; Chen, H.; Li, J. Joint Classification of Hyperspectral and LiDAR Data Using Height Information Guided Hierarchical Fusion-and-Separation Network. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5505315. [Google Scholar]
- Chen, F.-L.; Zhang, D.-Z.; Han, M.-L.; Chen, X.-Y.; Shi, J.; Xu, S.; Xu, B. Vlp: A survey on vision-language pre-training. Mach. Intell. Res. 2023, 20, 38–56. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the International Conference on Machine Learning, Baltimore, MA, USA, 17–23 July 2022; pp. 12888–12900. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 19730–19742. [Google Scholar]
- Dai, W.; Li, J.; Li, D.; Tiong, A.M.H.; Zhao, J.; Wang, W.; Li, B.; Fung, P.N.; Hoi, S. Instructblip: Towards general-purpose vision-language models with instruction tuning. In Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2024; p. 2142. [Google Scholar]
- Liu, F.; Chen, D.; Guan, Z.; Zhou, X.; Zhu, J.; Ye, Q.; Fu, L.; Zhou, J. Remoteclip: A vision language foundation model for remote sensing. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5622216. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.-T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.-H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Online, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Floridi, L.; Chiriatti, M. GPT-3: Its nature, scope, limits, and consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Roumeliotis, K.I.; Tselikas, N.D. Chatgpt and open-ai models: A preliminary review. Future Internet 2023, 15, 192. [Google Scholar] [CrossRef]
- Yue, X.; Qu, X.; Zhang, G.; Fu, Y.; Huang, W.; Sun, H.; Su, Y.; Chen, W. Mammoth: Building math generalist models through hybrid instruction tuning. arXiv 2023, arXiv:2309.05653. [Google Scholar]
- Zhou, H.; Gu, B.; Zou, X.; Li, Y.; Chen, S.S.; Zhou, P.; Liu, J.; Hua, Y.; Mao, C.; Wu, X. A survey of large language models in medicine: Progress, application, and challenge. arXiv 2023, arXiv:2311.05112. [Google Scholar]
- Bolton, E.; Venigalla, A.; Yasunaga, M.; Hall, D.; Xiong, B.; Lee, T.; Daneshjou, R.; Frankle, J.; Liang, P.; Carbin, M. Biomedlm: A 2.7 b parameter language model trained on biomedical text. arXiv 2024, arXiv:2403.18421. [Google Scholar]
- Li, J.; Liu, W.; Ding, Z.; Fan, W.; Li, Y.; Li, Q. Large Language Models are in-Context Molecule Learners. arXiv 2024, arXiv:2403.04197. [Google Scholar]
- Shi, B.; Zhao, P.; Wang, Z.; Zhang, Y.; Wang, Y.; Li, J.; Dai, W.; Zou, J.; Xiong, H.; Tian, Q. UMG-CLIP: A Unified Multi-Granularity Vision Generalist for Open-World Understanding. arXiv 2024, arXiv:2401.06397. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Luo, H.; Ji, L.; Zhong, M.; Chen, Y.; Lei, W.; Duan, N.; Li, T. Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning. Neurocomputing 2022, 508, 293–304. [Google Scholar]
- Rao, Y.; Zhao, W.; Chen, G.; Tang, Y.; Zhu, Z.; Huang, G.; Zhou, J.; Lu, J. Denseclip: Language-guided dense prediction with context-aware prompting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18082–18091. [Google Scholar]
- Narasimhan, M.; Rohrbach, A.; Darrell, T. Clip-it! language-guided video summarization. Adv. Neural Inf. Process. Syst. 2021, 34, 13988–14000. [Google Scholar]
- Zhang, R.; Guo, Z.; Zhang, W.; Li, K.; Miao, X.; Cui, B.; Qiao, Y.; Gao, P.; Li, H. Pointclip: Point cloud understanding by clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8552–8562. [Google Scholar]
- Elizalde, B.; Deshmukh, S.; Al Ismail, M.; Wang, H. Clap learning audio concepts from natural language supervision. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Xue, L.; Yu, N.; Zhang, S.; Panagopoulou, A.; Li, J.; Martín-Martín, R.; Wu, J.; Xiong, C.; Xu, R.; Niebles, J.C. Ulip-2: Towards scalable multimodal pre-training for 3d understanding. arXiv 2023, arXiv:2305.08275. [Google Scholar]
- Arora, S.; Khandeparkar, H.; Khodak, M.; Plevrakis, O.; Saunshi, N. A theoretical analysis of contrastive unsupervised representation learning. arXiv 2019, arXiv:1902.09229. [Google Scholar]
- Wang, T.; Isola, P. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Online, 13–18 July 2020; pp. 9929–9939. [Google Scholar]
- HaoChen, J.Z.; Wei, C.; Gaidon, A.; Ma, T. Provable guarantees for self-supervised deep learning with spectral contrastive loss. Adv. Neural Inf. Process. Syst. 2021, 34, 5000–5011. [Google Scholar]
- Huang, W.; Yi, M.; Zhao, X.; Jiang, Z. Towards the generalization of contrastive self-supervised learning. arXiv 2021, arXiv:2111.00743. [Google Scholar]
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More diverse means better: Multimodal deep learning meets remote-sensing imagery classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4340–4354. [Google Scholar]
- Wang, X.; Feng, Y.; Song, R.; Mu, Z.; Song, C. Multi-attentive hierarchical dense fusion net for fusion classification of hyperspectral and LiDAR data. Inf. Fusion 2022, 82, 1–18. [Google Scholar]
- Mohla, S.; Pande, S.; Banerjee, B.; Chaudhuri, S. Fusatnet: Dual attention based spectrospatial multimodal fusion network for hyperspectral and lidar classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 92–93. [Google Scholar]
- Lu, T.; Ding, K.; Fu, W.; Li, S.; Guo, A. Coupled adversarial learning for fusion classification of hyperspectral and LiDAR data. Inf. Fusion 2023, 93, 118–131. [Google Scholar]
- Yang, Y.; Zhu, D.; Qu, T.; Wang, Q.; Ren, F.; Cheng, C. Single-stream CNN with learnable architecture for multisource remote sensing data. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5409218. [Google Scholar]
- Dao, T.; Fu, D.; Ermon, S.; Rudra, A.; Ré, C. Flashattention: Fast and memory-efficient exact attention with io-awareness. Adv. Neural Inf. Process. Syst. 2022, 35, 16344–16359. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Class Name | Train Num | Test Num | Color |
|---|---|---|---|---|
| C1 | Healthy Grass | 198 | 1053 | |
| C2 | Stressed Grass | 190 | 1064 | |
| C3 | Synthetic Grass | 192 | 505 | |
| C4 | Trees | 188 | 1056 | |
| C5 | Soil | 186 | 1056 | |
| C6 | Water | 182 | 143 | |
| C7 | Residential | 196 | 1072 | |
| C8 | Commercial | 191 | 1053 | |
| C9 | Road | 193 | 1059 | |
| C10 | Highway | 191 | 1036 | |
| C11 | Railway | 181 | 1054 | |
| C12 | Parking Lot1 | 192 | 1041 | |
| C13 | Parking Lot2 | 184 | 285 | |
| C14 | Tennis Court | 181 | 247 | |
| C15 | Running Track | 187 | 473 | |
| - | Total | 2832 | 12,197 |
| Class | Class Name | Train Number | Test Number | Color |
|---|---|---|---|---|
| C1 | Apples | 129 | 3905 | |
| C2 | Buildings | 15 | 2778 | |
| C3 | Ground | 105 | 374 | |
| C4 | Woods | 154 | 8969 | |
| C5 | Vineyard | 184 | 10,317 | |
| C6 | Roads | 122 | 3252 | |
| - | Total | 819 | 29,395 |
| Class | Class Name | Train Number | Test Number | Color |
|---|---|---|---|---|
| C1 | Trees | 100 | 23,146 | |
| C2 | Mostly grass | 100 | 4170 | |
| C3 | Mixed ground surface | 100 | 6782 | |
| C4 | Dirt and sand | 100 | 1726 | |
| C5 | Road | 100 | 6587 | |
| C6 | Water | 100 | 366 | |
| C7 | Buildings shadow | 100 | 2133 | |
| C8 | Buildings | 100 | 6140 | |
| C9 | Sidewalk | 100 | 1285 | |
| C10 | Yellow curb | 100 | 83 | |
| C11 | Cloth panels | 100 | 169 | |
| - | Total | 1100 | 52,587 |
| Data Source | Evaluation Index | ||||
|---|---|---|---|---|---|
| HSI | LiDAR | Text | OA (%) | AA (%) | K × 100 |
| ✓ | ✗ | ✗ | 95.99 | 94.55 | 94.64 |
| ✗ | ✓ | ✗ | 88.84 | 85.67 | 85.21 |
| ✓ | ✓ | ✗ | 98.75 | 98.13 | 98.33 |
| ✓ | ✓ | ✓ | 98.78 | 98.14 | 98.37 |
| Network Structure | Evaluation Index | ||
|---|---|---|---|
| OA (%) | AA (%) | K × 100 | |
| Transformer (EF) | 96.96 | 94.43 | 95.28 |
| MoE-EN(LF) | 97.01 | 94.46 | 96.01 |
| ModaUnion + MoE-EN (MF) | 98.78 | 98.14 | 98.37 |
| Network Structure | Evaluation Index | ||
|---|---|---|---|
| OA (%) | AA (%) | K × 100 | |
| MHSA | 97.41 | 95.98 | 96.54 |
| SW-MHSA | 97.96 | 96.79 | 97.27 |
| CG-MHSA | 98.33 | 97.42 | 97.78 |
| SW-MHSA + CG-MHSA | 98.78 | 98.14 | 98.37 |
| MoE-EN | ACC (%) | Evaluation Index | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Spatial–Channel Sub-Branch | Spectral Context Sub-Branch | Spectrum Former | Apples | Buildings | Ground | Woods | Vineyard | Roads | OA (%) | AA (%) | K × 100 |
| ✓ | ✗ | ✗ | 97.17 | 98.03 | 99.37 | 99.92 | 99.99 | 87.55 | 98.10 | 97.01 | 97.46 |
| ✗ | ✓ | ✗ | 88.37 | 99.08 | 77.99 | 95.72 | 95.03 | 69.04 | 91.72 | 87.53 | 89.01 |
| ✓ | ✓ | ✗ | 98.35 | 99.59 | 98.74 | 99.99 | 99.97 | 90.47 | 98.35 | 97.42 | 97.81 |
| ✓ | ✗ | ✓ | 96.78 | 98.76 | 95.81 | 99.58 | 99.93 | 92.27 | 98.42 | 97.19 | 97.90 |
| ✗ | ✓ | ✓ | 86.59 | 95.59 | 77.99 | 97.27 | 91.40 | 75.20 | 91.00 | 87.34 | 88.04 |
| ✓ | ✓ | ✓ | 97.76 | 99.48 | 98.95 | 99.62 | 99.97 | 93.01 | 98.78 | 98.13 | 98.37 |
| Class | Two- Branch | EndNet | MDL- Middle | MAHiDFNet | FusAtNet | CALC | SepG-ResNet50 | DSMSC2N |
|---|---|---|---|---|---|---|---|---|
| Healthy grass | 82.90 | 81.58 | 83.10 | 82.91 | 80.72 | 86.51 | 72.36 | 90.12 |
| Stressed grass | 84.31 | 83.65 | 85.06 | 84.68 | 97.46 | 84.59 | 77.35 | 84.59 |
| Synthetic grass | 96.44 | 100.00 | 99.60 | 100.00 | 90.69 | 90.50 | 34.85 | 98.81 |
| Trees | 96.59 | 93.09 | 91.57 | 93.37 | 99.72 | 91.86 | 86.84 | 90.91 |
| Soil | 99.62 | 99.91 | 98.86 | 99.43 | 97.92 | 100.00 | 91.38 | 100.00 |
| Water | 82.52 | 95.10 | 100.00 | 99.30 | 93.71 | 99.30 | 95.10 | 95.80 |
| Residential | 85.54 | 82.65 | 97.64 | 83.58 | 91.98 | 88.71 | 81.62 | 91.12 |
| Commercial | 76.64 | 81.29 | 88.13 | 81.96 | 85.19 | 83.19 | 61.73 | 95.38 |
| Road | 87.35 | 88.29 | 85.93 | 83.76 | 85.93 | 91.60 | 86.31 | 95.04 |
| Highway | 60.71 | 89.00 | 74.42 | 66.41 | 69.50 | 65.44 | 46.26 | 67.66 |
| Railway | 90.61 | 83.78 | 84.54 | 74.57 | 85.48 | 95.92 | 69.35 | 97.22 |
| Parking Lot1 | 90.78 | 90.39 | 95.39 | 88.38 | 89.15 | 90.78 | 86.94 | 93.66 |
| Parking Lot2 | 86.67 | 82.46 | 87.37 | 88.42 | 77.19 | 91.93 | 78.25 | 92.63 |
| Tennis court | 92.31 | 100.00 | 95.14 | 100.00 | 84.21 | 94.74 | 87.04 | 100.00 |
| Running track | 99.79 | 98.10 | 100.00 | 100.00 | 87.53 | 100.00 | 18.82 | 97.46 |
| OA (%) | 86.68 | 88.52 | 89.55 | 85.87 | 88.14 | 88.84 | 72.67 | 91.49 |
| AA (%) | 87.52 | 89.95 | 91.05 | 88.55 | 87.76 | 90.34 | 71.63 | 92.69 |
| K × 100 | 85.56 | 87.59 | 87.59 | 84.76 | 87.12 | 87.92 | 70.40 | 90.76 |
| Class | Two- Branch | EndNet | MDL- Middle | MAHiDFNet | FusAtNet | CALC | SepG-ResNet50 | DSMSC2N |
|---|---|---|---|---|---|---|---|---|
| Apples | 98.61 | 93.95 | 99.93 | 100.00 | 99.45 | 94.55 | 93.28 | 99.33 |
| Buildings | 98.93 | 96.54 | 98.14 | 99.80 | 89.87 | 99.55 | 99.38 | 97.42 |
| Ground | 75.16 | 96.24 | 97.08 | 96.03 | 91.23 | 92.69 | 74.35 | 96.66 |
| Woods | 98.72 | 99.36 | 99.93 | 100.00 | 93.86 | 100.00 | 99.88 | 99.29 |
| Vineyard | 97.43 | 80.72 | 98.54 | 95.30 | 92.92 | 99.53 | 95.91 | 99.70 |
| Roads | 96.83 | 90.14 | 89.51 | 86.74 | 90.71 | 93.82 | 68.05 | 96.60 |
| OA (%) | 96.53 | 90.86 | 98.14 | 96.89 | 93.53 | 98.30 | 93.82 | 98.93 |
| AA (%) | 92.30 | 92.81 | 97.19 | 96.31 | 93.01 | 96.69 | 88.47 | 98.16 |
| K × 100 | 95.38 | 88.01 | 97.52 | 95.87 | 91.51 | 97.74 | 91.79 | 98.57 |
| Class | Two- Branch | EndNet | MDL- Middle | MAHiDFNet | FusAtNet | CALC | SepG- ResNet50 | DSMSC2N |
|---|---|---|---|---|---|---|---|---|
| Trees | 90.29 | 83.55 | 87.31 | 89.87 | 80.36 | 91.97 | 86.78 | 94.23 |
| Mostly grass | 75.68 | 79.38 | 76.38 | 63.19 | 73.57 | 81.77 | 78.47 | 85.81 |
| Mixed ground surface | 69.71 | 76.28 | 68.33 | 75.85 | 68.24 | 77.56 | 71.20 | 81.97 |
| Dirt and sand | 93.97 | 87.08 | 78.74 | 96.18 | 70.74 | 95.19 | 89.98 | 86.65 |
| Road | 91.79 | 89.59 | 83.76 | 88.52 | 80.95 | 89.19 | 76.38 | 89.72 |
| Water | 99.73 | 95.90 | 88.52 | 85.25 | 81.15 | 100.00 | 99.73 | 99.65 |
| Buildings shadow | 91.84 | 88.28 | 92.12 | 9..72 | 89.40 | 95.17 | 91.70 | 94.18 |
| Buildings | 94.79 | 92.07 | 89.69 | 95.44 | 87.92 | 96.91 | 87.31 | 90.87 |
| Sidewalk | 72.30 | 76.96 | 77.04 | 75.80 | 77.98 | 69.81 | 69.88 | 79.75 |
| Yellow curb | 96.39 | 95.18 | 86.75 | 91.57 | 78.31 | 95.18 | 90.36 | 92.00 |
| Cloth panels | 97.63 | 97.63 | 99.41 | 99.41 | 99.41 | 100.00 | 99.41 | 98.82 |
| OA (%) | 87.03 | 84.33 | 83.54 | 86.45 | 79.24 | 89.31 | 82.90 | 91.19 |
| AA (%) | 88.56 | 87.45 | 84.37 | 86.80 | 80.73 | 90.25 | 85.56 | 90.87 |
| K × 100 | 83.10 | 79.85 | 78.84 | 82.37 | 73.81 | 86.05 | 77.94 | 88.33 |
| Methods | #Param. (M) | FLOPs (M) |
|---|---|---|
| Two-Branch | 5.6 | 120.81 |
| EndNet | 0.09 | 0.09 |
| MDL-Middle | 0.1 | 5.28 |
| MAHiDFNet | 77.0 | 155.00 |
| FusAtNet | 36.9 | 3460.31 |
| CALC | 0.3 | 28.79 |
| SepG-ResNet50 | 14.7 | 48.28 |
| DSMSC2N | 0.7 | 104.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, A.; Dai, S.; Wu, H.; Iwahori, Y. Multimodal Semantic Collaborative Classification for Hyperspectral Images and LiDAR Data. Remote Sens. 2024, 16, 3082. https://doi.org/10.3390/rs16163082
Wang A, Dai S, Wu H, Iwahori Y. Multimodal Semantic Collaborative Classification for Hyperspectral Images and LiDAR Data. Remote Sensing. 2024; 16(16):3082. https://doi.org/10.3390/rs16163082
Chicago/Turabian StyleWang, Aili, Shiyu Dai, Haibin Wu, and Yuji Iwahori. 2024. "Multimodal Semantic Collaborative Classification for Hyperspectral Images and LiDAR Data" Remote Sensing 16, no. 16: 3082. https://doi.org/10.3390/rs16163082
APA StyleWang, A., Dai, S., Wu, H., & Iwahori, Y. (2024). Multimodal Semantic Collaborative Classification for Hyperspectral Images and LiDAR Data. Remote Sensing, 16(16), 3082. https://doi.org/10.3390/rs16163082