1. Introduction
Global Navigation Satellite Systems (GNSS) have undergone rapid development and progress in past decades. With the successive establishment of global services such as GPS, BDS, GLONASS, Galileo and regional services such as QZSS, IRNSS, GNSS-based applications have also widely been implemented. Bike-sharing is a typical example among them. Due to its convenience for short-length travel and last-mile connectivity of public transportation, bike-sharing services have expanded to over 300 cities in mainland China and gained widespread popularity especially in super cities [
1]. However, the prosperous growth of bike-sharing has brought a series of problems. Over-deployment by operators, false-parking by users and poor scheduling by public management have caused mass disarray of public sharing-bikes, which has become a hot and troubling issue among citizens [
2].
A practical solution to this problem is to use electronic fence technology to regulate users’ parking behaviors, which means the bike-sharing service is made unable to deactivate unless they are parked in the range of virtual “parking zones”. Unfortunately, shared bikes often need to be parked in complex environments, which means GNSS signals could be easily blocked by street trees or affected by strong reflections from buildings on one or both sides [
3]. The deteriorated signal quality leads to a reduction in positioning precision, which limits the performance of electronic fence. To address this issue, adjusting the threshold of electronic fence according to the positioning precision is a feasible approach. However, the precision of positioning significantly varies in different obstruction conditions [
4], which makes it important to recognize the obstruction scenes before adjusting. On the other hand, improving the precision of GNSS positioning in complex urban environments is also considered as an effective approach and several studies have been proposed in recent years, including anti-multipath [
5,
6], array signal processing [
7,
8], high-sensitivity tracking algorithms [
9,
10] and so on [
11]. However, all these scene-adaptive methods require rapid and accurate recognition, or they may cause unexpected errors when scenes are mismatched.
In order to recognize the positioning scenes, researchers have proposed a series of methods, which can be mainly categorized into two technical approaches: multi-sensor fusion and GNSS signal-based methods. From the perspective of multi-sensor fusion, camera, LiDAR [
12,
13,
14], and signal sensors such as accelerometers and gyroscopes are put into use to detect the environmental features surrounding GNSS receivers in order to recognize contexts [
15,
16]. Although accurate context recognition could be accessible by multi-sensor fusion, the high computational power and device costs make it economically unappealing for bike-sharing operators. From the perspective of GNSS signal-based methods, different observation data and data-constructed features are selected to recognize GNSS positioning contexts. In the field of indoor and outdoor detection,
and the number of visible satellites are widely used as classification features [
17,
18,
19]. Recently, more and more research has focused on detailed contexts segmentation and the performances of machine learning in this field. Lai et al. [
20] use support vector machine (SVM) to divide the environment into open outdoors, occluded outdoors and indoors, which has reached a recognition accuracy of 90.3%. Dai et al. [
21] change the GNSS observation data into sky plots and compare the performances of CNN and Conv-LSTM in recognition of open-outdoor, semi-outdoor, shallow indoor and deep indoor. The results show that CNN can reach an accuracy of 98.82% while Conv-LSTM can reach 99.2%. Zhu et al. [
22] conducted an analysis of 196 variables related to visible satellite, satellite distribution, signal strength and multipath effect based on statistical methods to find the most important feature elements. They then used those selected features to recognize contexts and compare the performances of eight machine learning models. The results show that LSTM can reach an accuracy of 95.37% in vehicle-mounted dynamic environmental contexts (open area, urban canyon, boulevard, under viaduct and tunnel) awareness.
The above scene recognition methods show that excellent results can be achieved using GNSS observations to recognize scenes in the condition of lacking multi-sensors, which proves that GNSS-based methods are suitable for shared bikes’ application. However, there are still several unsolved issues:
- (a)
Many studies only consider large-scale scenes. With regard to urban static positioning tasks such as shared-bike parking, more detailed scenes should to be taken into consideration.
- (b)
Research studies about machine learning in GNSS scenes recognition still remain in the stage of directly using existing neural networks or constructing feature inputs that meet the requirements of these networks. Those space-transfer strategies may lead to the degradation of original data features. Being able to make full use of observation data in scene recognition remains a challenging problem.
- (c)
Multi-systems and complex deep learning networks are used to improve the accuracy of recognition. However, the multi-system observations and computation consumption may not be available in low-cost receivers and microprocessors equipped on public devices such as shared bikes. Moreover, there are relatively few studies on transfer learning in GNSS scenes recognition. It is crucial to develop methods that can be quickly transferred into different time periods.
Therefore, summarizing the shortcomings of existing works and considering the characteristics of urban static positioning (shared bike parking) application scenes, we propose a deep-learning-based scene recognition method. Our contributions can be summarized as follows:
- (a)
A more detailed set of scenes that is suitable for urban static positioning is proposed, including open area, shade of tree, high urban canyon, low urban canyon and unilateral urban canyon. A dataset of 15,000 epochs (3000 s for each scene) is collected for research.
- (b)
A spatio-temporal correlated method for constructing raw data features is used to analyze the importance of different observation data in recognition based on machine learning. A multi-channel Long Short-Term Memory (MC-LSTM) network for GNSS scene recognition is proposed. The result shows that our method can achieve an accuracy of 99.14% under the condition of using low-cost GNSS receivers to observe single satellite navigation system.
- (c)
In order to manage the degradation in performances between different time periods, we conduct the transfer learning test of our method’s model. The result shows that our pre-trained model can be fine-tuned with a small number of epochs to adapt to different time periods at the same location, which is cost-acceptable for bike-sharing operators.
The remainder of this article is organized as follows:
Section 2 introduces the methodology of our proposed model.
Section 3 presents the experiments and an analysis of the results.
Section 5 provides our conclusions and directions for future works.
2. Methodology
In this section, we first present the feature analysis and construction. Then we propose a deep-learning-based scene recognition model. The overview of our model is shown in
Figure 1. The observation data are firstly constructed into different feature vectors. Then those feature vectors are fed into a multi-channel long short-term memory network (MC-LSTM) to identify five scenes (open area, high urban canyon, unilateral urban canyon, shade of tree, low urban canyon).
2.1. Feature Analysis and Constructions
In this subsection, we first present the observation data and their hidden information. Then we introduce the elevation and azimuth, which shows the geometric relationship between navigation satellites and receivers. Finally, we propose the feature vector definition for our model’s input.
2.1.1. GNSS Observations
Global Navigation Satellite Systems (GNSS) typically consist of three segments: the space (space navigation constellation and satellites), the ground control (master control station, monitoring stations and uploading stations), and the user terminals. Users can receive carrier signals transmitted by the space satellites by various of terminals (receivers). The carrier signals are modulated with ranging codes and navigation messages which can be processed by receivers into different observation data, including the Pseudo range [
23], Carrier Phase [
24], Doppler frequency [
25] and
[
26].
Pseudo range: The pseudo range observation is an absolute measurement of the distance from the satellite to the receiver, obtained by measuring the signal propagation time delay, and is expressed in meters. The pseudo range includes atmospheric delays and clock biases, and its accuracy is typically at the meter level.
Carrier Phase: Carrier phase observations measure the phase difference between the satellite carrier signal and the reference carrier signal produced by the receiver’s oscillator, making it a relative observation. It is expressed in cycles and includes atmospheric delays, clock biases and ambiguity of whole cycles.
Doppler frequency: The frequency of the GNSS carrier signal received by the receiver differs from the actual frequency transmitted by the satellite. This difference is known as the Doppler shift, and its magnitude is related to the rate of change in distance between the receiver and the satellite. Specifically, the Doppler observation equation for GNSS is as follows:
where
is the Doppler frequency and it is expressed in Hz.
is the wavelength of the carrier wave.
is the rate of change of the distance between the receiver (subscript
r denotes the receiver) and the satellite (superscript denotes the satellite).
and
is the clock drift of the receiver and the satellite.
and
is the time derivatives of ionospheric and tropospheric delays.
C/N0: The carrier-to-noise density ratio (or in more straightforward terms) refers to the ratio of the signal power to the noise power per unit bandwidth in the received GNSS signal. It is expressed in dB and reflects the quality of the RF signal received by the receiver.
Then we consider the characteristics of above observations in urban static positioning scene. Under the conditions of no signal occlusion, the distance between the receiver and the satellite changes in a predictable manner due to the receiver being stationary and the satellite moving in a fixed orbit. In different obstruction scenes, the nature of the obstructions and the characteristics of multipath reflections cause varying rates of change in the distance between the receiver and the satellite. Therefore, we believe that the temporal characteristics of the observations can serve as a basis for scene recognition.
All these observation data can be read directly from Receiver Independent Exchange Format (RINEX format) files or the receivers’ output data stream without additional calculations. This is favorable for our application scene which only supports edge computing power. In order to unify the data scale, we normalize the raw observations as follows:
where
and
are the maximum and minimum values of a specific type of observation data within a time step, and
d is the original observation data. The normalization only requires simple arithmetic operations, but can ensure network convergence [
27,
28].
2.1.2. Satellite Elevation and Azimuth
The satellite elevation angle refers to the angle between the vector from the user’s location to the satellite’s position and its projection onto the Earth ellipsoid tangent plane passing through the user’s location. The satellite azimuth angle refers to the angle between this projection and the true North coordinate axis on the tangent plane, with counterclockwise direction considered positive. The satellite elevation angle and azimuth angle are both related to the position of the user’s receiver [
29]. They reflect certain aspects of satellite signals, ranging accuracy, and multipath effects. As shown in
Figure 2, visible satellites often exhibit different geometric distributions under various obstruction scenes. The calculation methods for satellite elevation angle and azimuth angle are as follows [
30]:
where
,
,
represent the satellite position in the local topocentric coordinate system (ENU).
,
,
and
,
,
represent the satellite position (calculated from the satellite ephemeris) and station position in the Earth-Centered Earth-Fixed coordinate system (ECEF), respectively.
H is the transformation matrix between ENU system and the ECEF system.
and
are the geodetic latitude and longitude of the receiver. Therefore, the elevation (
.) and azimuth (
.) angle is calculated as follows:
From the physical definitions of the satellite elevation angle and azimuth angle, it can be observed that both the elevation and azimuth angles have upper and lower bounds. The elevation angle ranges from 0 to 90 degrees, and the azimuth angle ranges from
degrees to 180 degrees. Similarly to the normalization method used for raw observations, we normalize the satellite elevation and azimuth angles as follows:
where the elevation and azimuth angles are both expressed in degree.
2.1.3. Feature Vector Definition
The feature vector is used as the input of recognition model. In this subsection, we are going to introduce our feature vector definition, which considers both original observation data and geometric relationships between satellites and receivers. We use fixed-length sequential vectors to represent the constellation of a specific satellite navigation system. For example, a 32-dimensional vector is used to store the normalized pseudo range observations of GPS because the pseudo-random noise (PRN) code of satellites is in range of 1 to 32 (G01∼G32).
Additionally, we regard the satellite elevation and azimuth angles as a combined feature, which represents the geometric distribution of satellites that the receiver can use. Instead of changing visible satellites into sky plots like
Figure 2, we use a
-dimensional vector to store the normalized angles(where
N is the max PRN of the navigation satellite system). Actually, the different dimensions of observation data is the basic of establishment of our multi-channel model, which will be introduced in
Section 3 in detail. Our feature definition can be summarized as
Table 1. It is worth noting that these vectors of different dimensions can be used both individually and in combination as the input of the multi-channel model.
2.2. A Multi-Channel Model for Scene Recognition
In this subsection, we first introduce the Long Short-Term Memory (LSTM) model, which is served as the fundamental building block for the construction of our model. After comparing the performances of different channels (different feature vectors), we propose our multi-channel model to integrate information from different channels. Finally, we consider the transferability of the model and introduce the transfer learning strategy we use in the temporal dimension.
2.2.1. LSTM and Single-Channel Network
Long short-term memory (LSTM) networks are primarily used for learning and predicting temporal features in data sequences. Actually, in the field of GNSS positioning scene recognition, LSTM has been proven to be the most effective network model among numerous machine learning models [
21,
22,
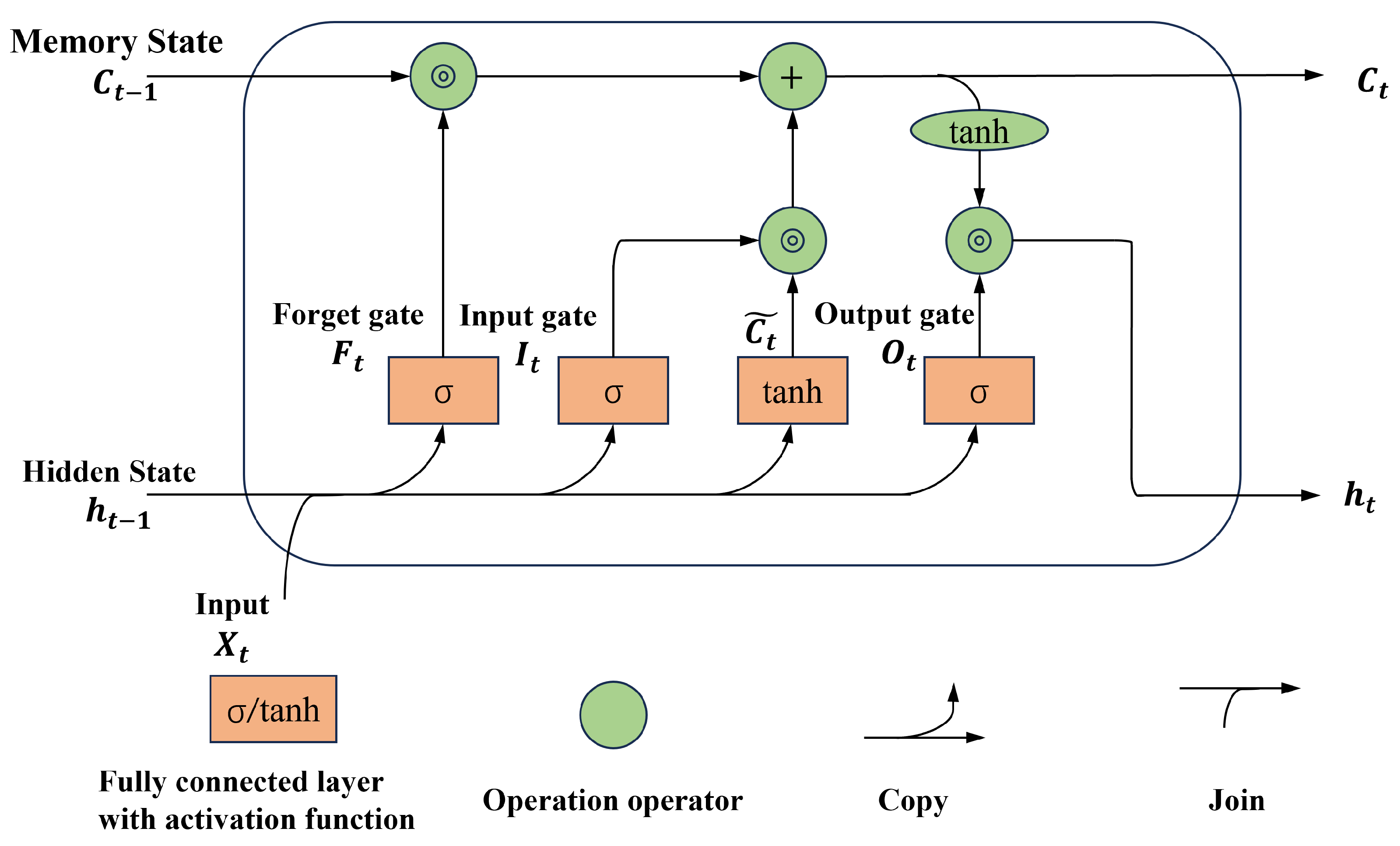
31]. LSTM is composed of numerous LSTM cells
Figure 3, which are used to determine whether information is useful. There are three gates in one cell, including a input gate, a forget gate and an output gate. Additionally, a candidate memory cell is set in the LSTM cell in order to process the chosen memory. A hidden state
and the memory passed to the next cell
are output by each cell. The key expression of the LSTM cell is as follows [
32,
33,
34]:
where ⊙ represents the dot product and
represents the sigmoid activation function.
,
,
are the outputs of the input gate, forget gate and output gate.
,
;
,
;
,
are the weight matrices of input, forget, output gates.
,
are the weight matrices of the candidate memory cell.
,
,
,
are the biases. The hidden state
is caculated as follows:
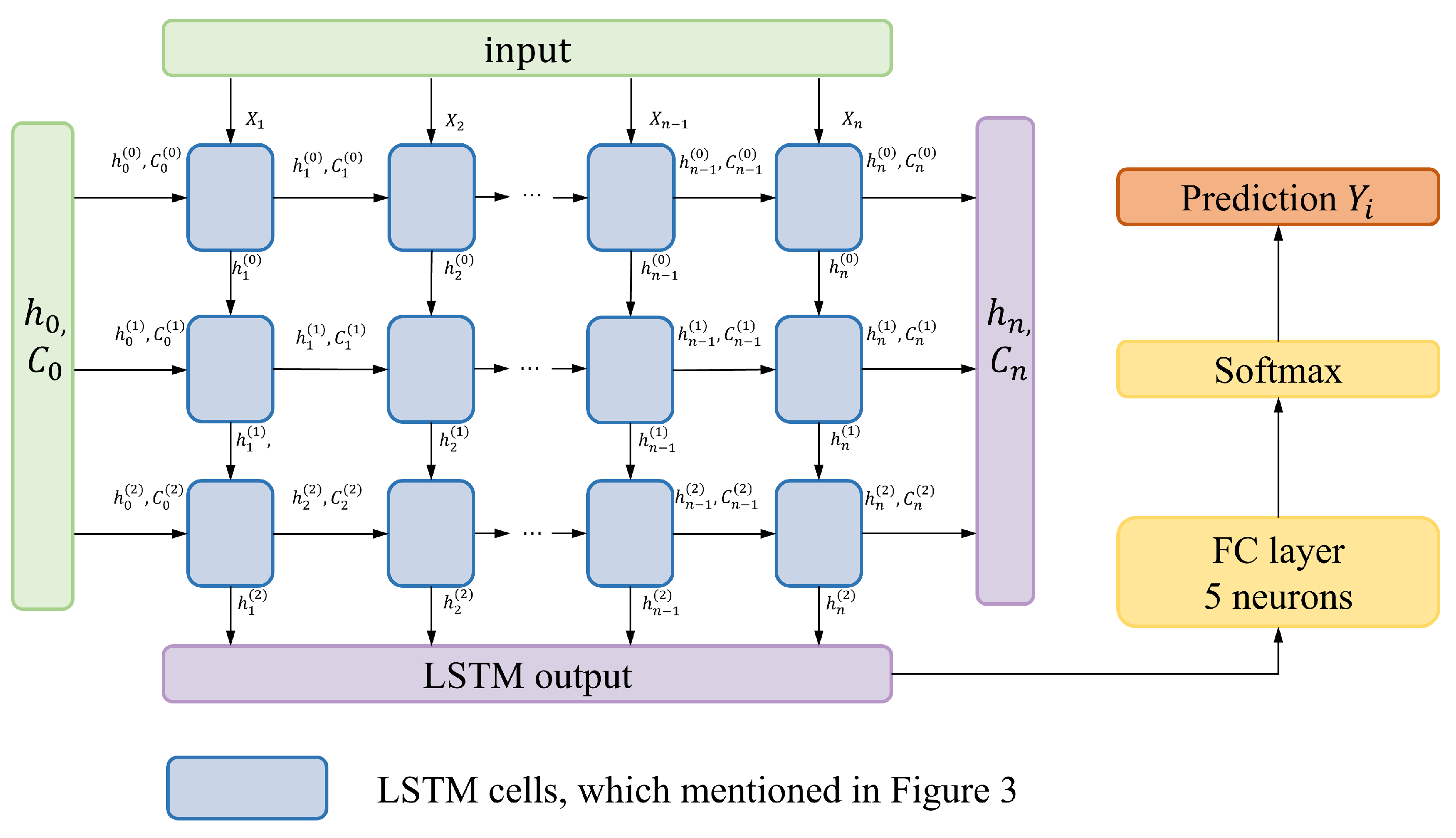
To change our feature vector to the input of LSTM, the original feature vector sequences should be transmitted into time segments with a sliding window. It means we combine data vectors within a certain time step into a sequence in chronological order and make it the input of single channel. Take pseudo range feature for example, if a
N-dimensional vector represents the normalized pseudo range of the time
, the input of single LSTM channel is in dimension of
, where
is the time step of sequence. The overview of our single channel LSTM is shown in
Figure 4.
To ensure the real-time performance of the algorithm and consider the practical application requirements, we add only 3 LSTM layers in a single channel which is used to process a single type of feature vector. Meanwhile, the time step is set in 10 s. The sliding window is set in 1 s so that 2990 sequences of each scene can be collected. Similar to the majority of machine learning classification tasks, we use the cross-entropy loss function and optimize the parameters of the network with Adam. The network is trained on training and validation datasets for approximately 500 epochs. The batch size is set to 32 and the learning rate is set to .
2.2.2. Scene Categories and Single Channel LSTM Performances
Usually, GNSS positioning scenes are divided into two main parts: outdoor and indoor [
17,
18,
19]. Within urban environments, urban canyons and boulevard are also considered in scene recognition [
22,
35]. Given the specificity of our application scene (static positioning for shared bikes’ parking), we have subdivided urban canyons into high urban canyon, low urban canyon and unilateral urban canyon. So we divide the positioning scenes into five categories:
open area,
shade of tree,
high urban canyon,
low urban canyon and
unilateral urban canyon. Due to the bike parking rule, we no longer consider the indoor scenes, which are easily identifiable based on the presence of satellite signals.
Figure 5 shows the real-world locations and the street view where we collected data, and
Figure 2 shows the distribution of satellites in various scenes.
In our proposed algorithm, we encode the scene categories as one-hot vectors as
Table 2. So the index of the max number of output vector represents the highest possibility of the scene. For example, if the model outputs a vector of [0.1, 0.1,
0.5, 0.2, 0.1], the prediction result of scene recognition is the unilateral urban canyon. Under the training setting mentioned in subsection, we have trained and validated the single channel model and the performances are shown in
Figure 6.
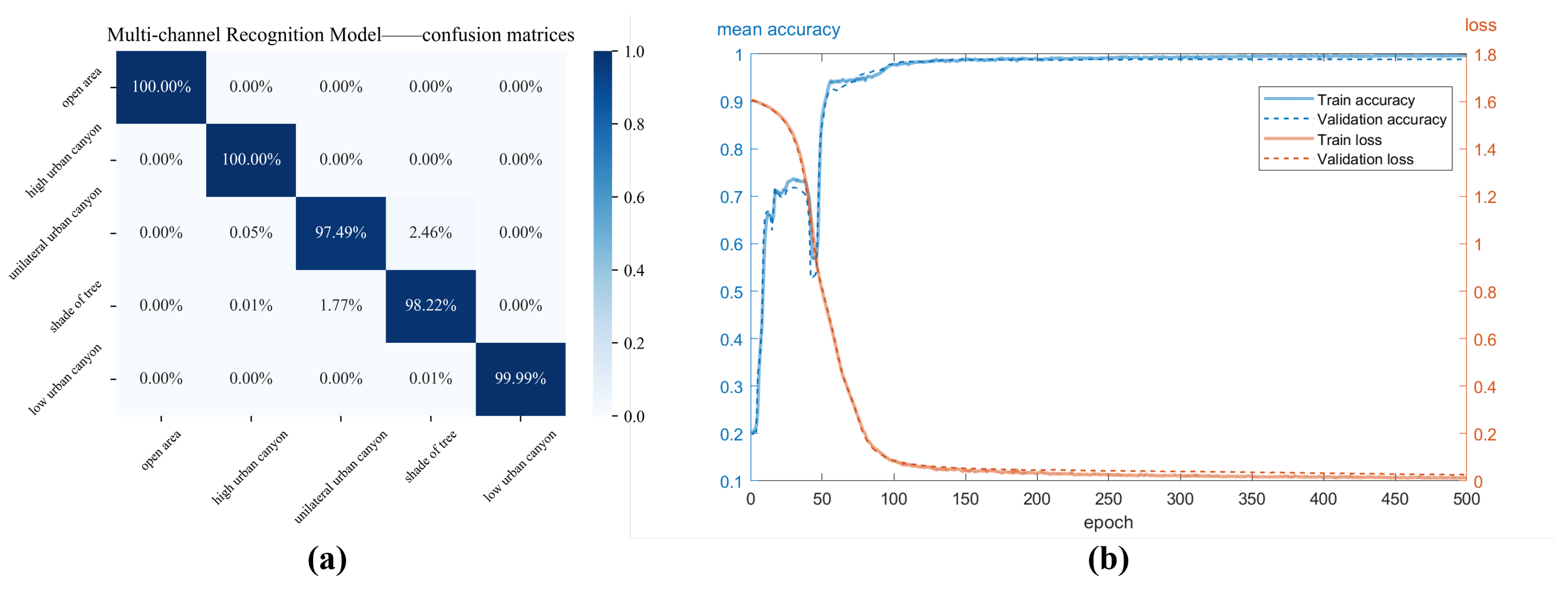
From the confusion matrices shown in
Figure 6, we can find that different feature data have varying sensitivities to the recognition of different scenes. The feature of az/el and
performs the best in all categories while other feature data performs in specific category (pseudo range in shade of tree, phase + LLI in high urban canyon). Meanwhile, the convergence speeds of the individual single-channel models also show significant differences, as shown in
Figure 7. The az/el has the fast convergence speed while the phase has the slowest. Moreover, the performance of phase + LLI is better than single phase no matter the accuracy or the convergence speed, which prompts us to combine the carrier phase and LLI into one feature consideration in the subsequent research.
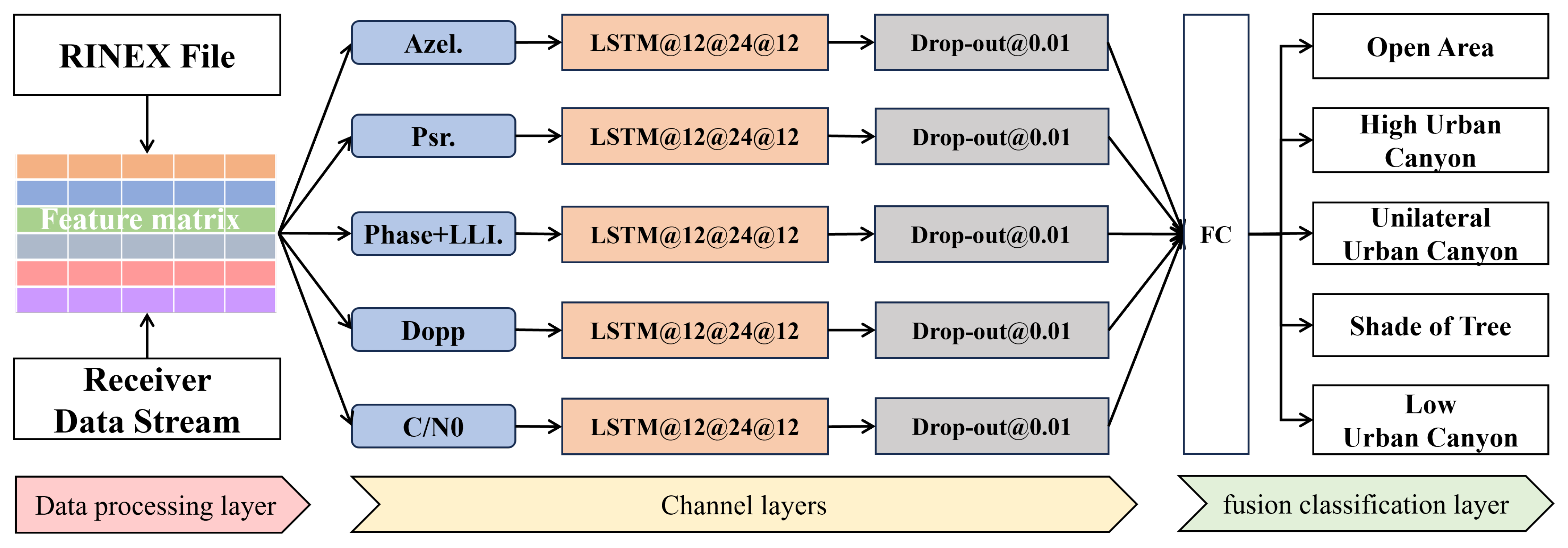
2.2.3. MC-LSTM Design
In the last subsection, we analysed the performances of different feature vectors. To improve recognition accuracy and convergence speed of our model across all scenes, we integrate information from different feature vectors through a multi-channel parallel design. The overview of our model is shown in
Figure 8. The model consists of channel layers and a fusion classification layer. Different feature vectors are input into corresponding LSTM channels. After LSTM processes and outputs hidden states, these are passed through fully connected layers to merge and classify scene recognition results. It is important to note that the dropout layers are used to introduce non-linearity to the model, which helps prevent overfitting and enhances the model’s ability to generalize [
36,
37].
In addition, our proposed multi-channel model allows for flexible combinations of channels based on scenes and requirements. If the receiver cannot output a certain type of observation, the corresponding data vector channel can be excluded.
2.2.4. Transfer Learning Settings
A trained model can achieve a high accuracy in training and validation dataset but usually does not perform well in another dataset. Therefore, classification models need to be retrained when changes in the feature space or the feature distribution occur [
38]. In our application scene for recognizing shared bicycle parking locations, the absolute position used is generally fixed, but the time when users park is random. It makes the cost exceptionally high for collecting data from all time periods for training. Therefore, the quicker we can execute the transfer learning between time periods, the stronger our model’s generalization is. This means the operator of shared bikes can quickly deploy the pre-trained model with simple fine-tuning to different time periods, significantly reducing the time required for model training. To test the temporal transfer performance of our model, we collected data from different time periods and performed full-layer transfer. The distribution of the data over time is shown in
Table 3.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}