1. Introduction
Camera arrays capture both the intensity and direction of light rays [
1] and enable the synthesis of multiple perspectives to enhance the signal-to-noise ratio (SNR) between spatial dim targets and backgrounds [
2], thereby enhancing the detection capability for dim targets [
3]. This method addresses the limitations of traditional techniques in adapting to changes in illumination and complex backgrounds [
4], while also circumventing the data requirements and computational resource dependencies associated with deep-learning-based approaches [
5,
6].
The commercialization of light field (LF) imaging devices has accelerated the development of LF technology. Common LF imaging devices can be categorized into three distinct types based on their structural design: scanning LF cameras [
7,
8,
9], microlens-array-based LF cameras (also known as plenoptic cameras) [
10,
11,
12], and camera arrays [
13,
14,
15]. Scanning LF cameras require stability of the LF throughout the capture process, which limits their applicability to dynamic scenes [
8]. Plenoptic cameras have a limited overall resolution, and therefore must trade-off between spatial and angular resolution of captured LF images [
16]. Existing camera arrays are typically bulky and expensive [
17], and most still operate in the visible spectral range.
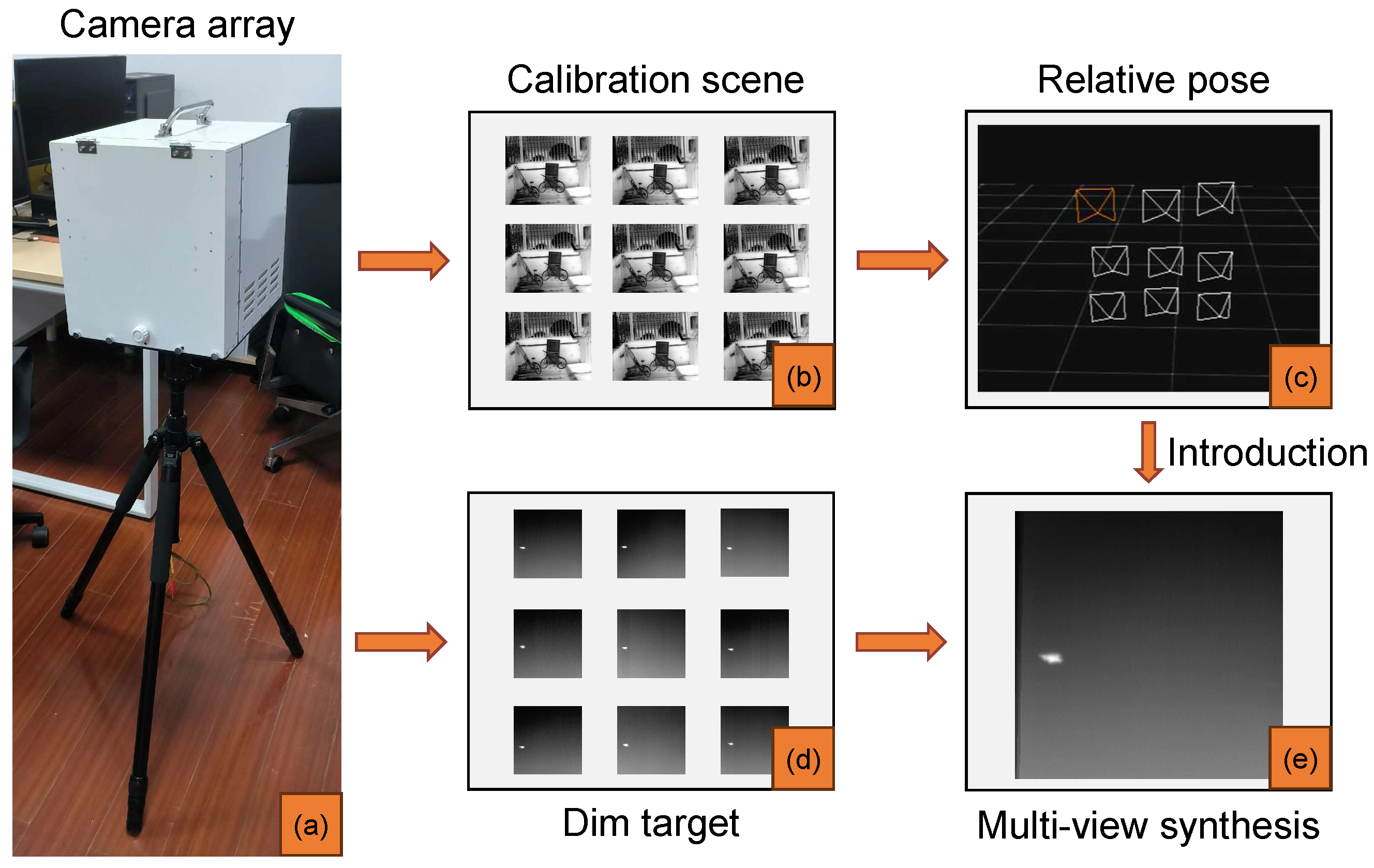
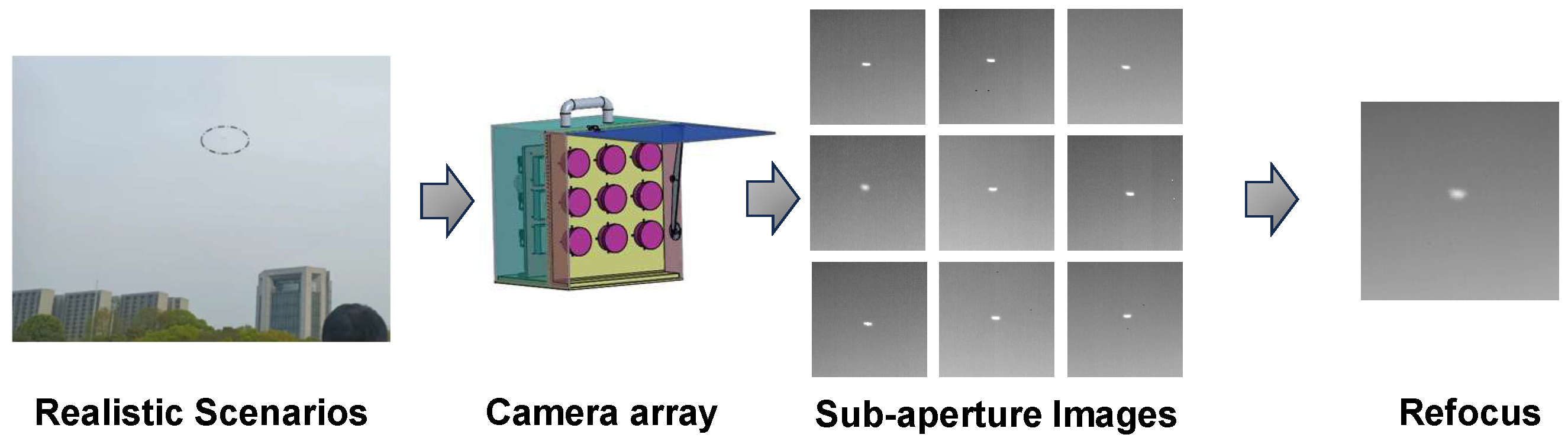
To address the structural limitations of conventional LF imaging devices for tasks such as dim target detection, this paper introduces a novel infrared camera array system (as shown in
Figure 1). The infrared camera array we designed offers excellent mobility, highly synchronized image acquisition accuracy, impressive baseline depth resolution, and the ability to detect dim targets in the long-wave infrared spectrum (LWIR). The camera array fulfills the requirement to capture moving dim targets under a wide range of conditions, which eliminates the limitations of traditional LF imaging equipment.
The calibration of camera arrays is critical for LF imaging and spatial dim target perception. Extensive research has been conducted across various domains, including 3D target localization [
18], full optical camera calibration [
19], spatial position and pose measurement [
20], target position measurement [
21], and robot visual measurement [
22]. The calibration of camera arrays involves considerations of pose [
23,
24] and disparity [
25,
26] for each camera viewpoint. Numerous calibration methods have been developed to meet the diverse requirements of different applications. While current methods, such as metric calibration [
27] and structure-from-motion (SfM)-based method [
28], have made considerable progress, they still treat the camera array as a combination of pinhole cameras, and the geometrical constraints that exist between sub-cameras have not been investigated, which leads to unsatisfactory calibration accuracy. In addition, the infrared camera arrays we designed faced unique challenges. Since the camera array is used to detect dim targets at long distances, its sub-cameras capture clear images at infinity by adjusting their focal lengths. Therefore, during the calibration process, the calibration scene should also be chosen far enough away so that the camera array can capture a calibrated scene with sharp texture details. However, choosing a calibration scene that is too far away can lead to parallax deficiency problems, so the rays reconstructed from a single array frame are very dense and easily corrupted by noise.
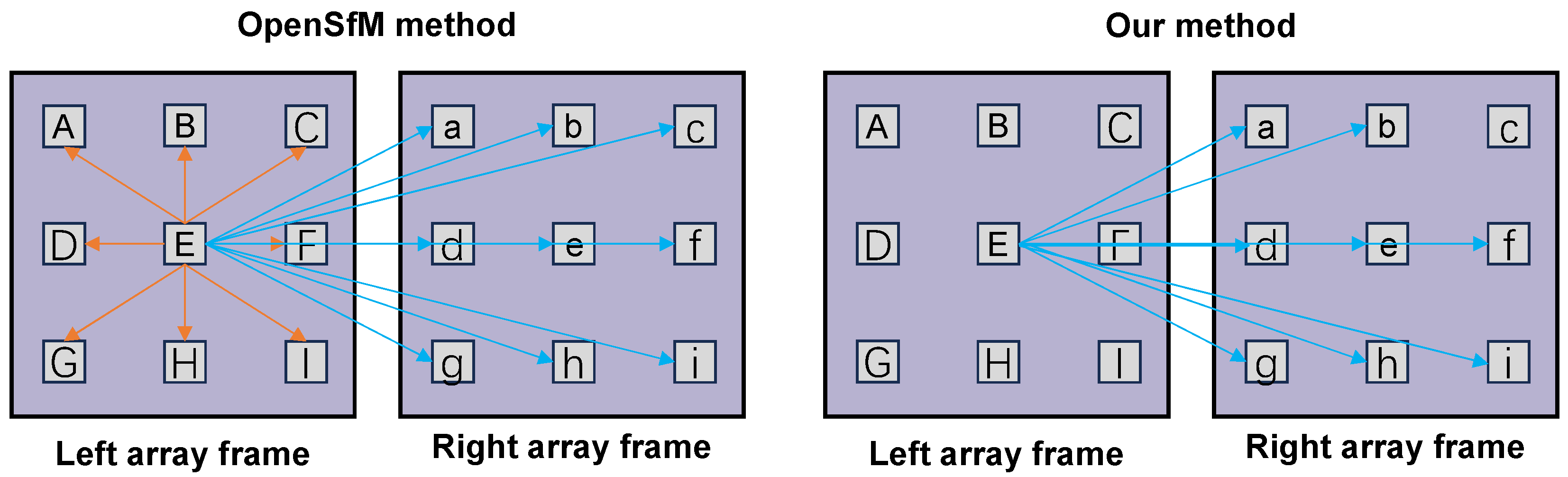
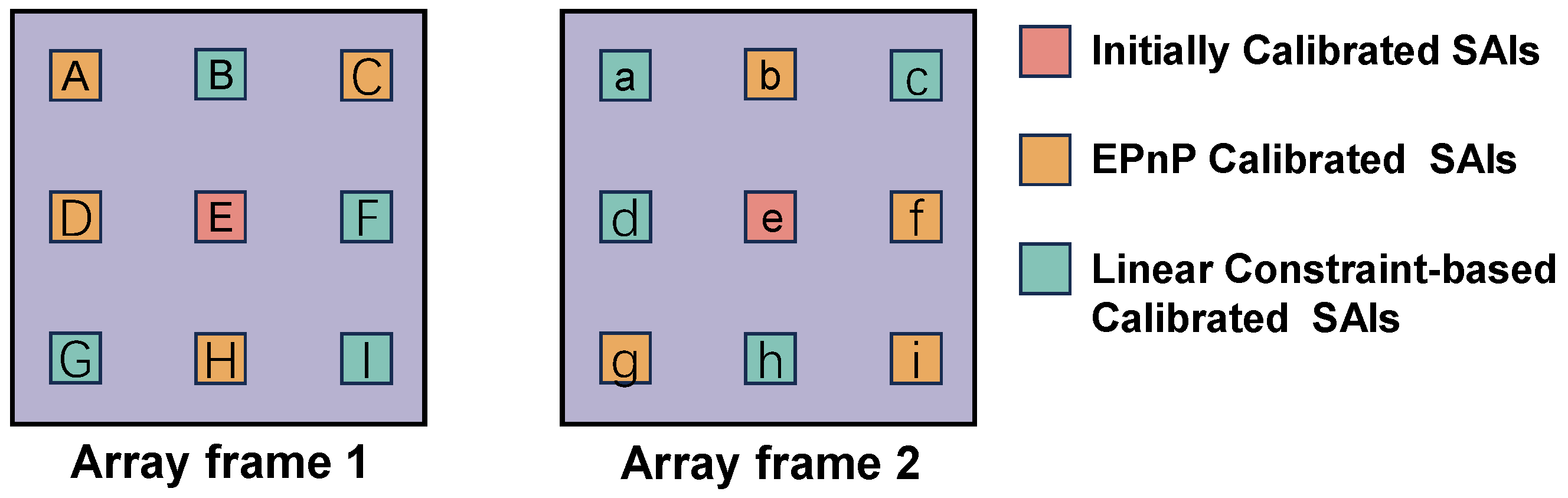
To address this problem, we propose a comprehensive calibration model. The model enhances the discrepancy by capturing the scene twice at different spatial locations, thus extending the spatial resolution of the LF. In addition, the model derives a set of linear constraints regarding the ray space correspondence between dual-array frames. This maintains the minimum degrees of freedom of the model by adding orderly sub-aperture images (SAIs) and effectively reduces the cumulative reprojection error due to the addition of LF images.
In this paper, our goal is to provide a high-precision self-calibration method for infrared camera arrays to achieve dim target perception, as shown in
Figure 1. The main contributions of this paper can be briefly described as follows:
- (1)
We design an innovative infrared camera array system to provide a novel solution for open world dim target detection.
- (2)
We propose a comprehensive calibration model for the infrared camera array. This model establishes linear constraints on the ray space correspondence within the camera array at two different spatial positions.
- (3)
We develop a real-world LF dataset for comprehensive performance evaluation. In addition, guided by the obtained camera poses, we achieve dim target SNR enhancement based on multi-view synthesis.
The remaining sections of the paper are structured as follows.
Section 2 provides an overview of previous related work. In
Section 3, we introduce our own designed and developed infrared camera array, which demonstrates its advantages in visual perception and target detection.
Section 4 proposes a self-calibration method for the infrared camera array.
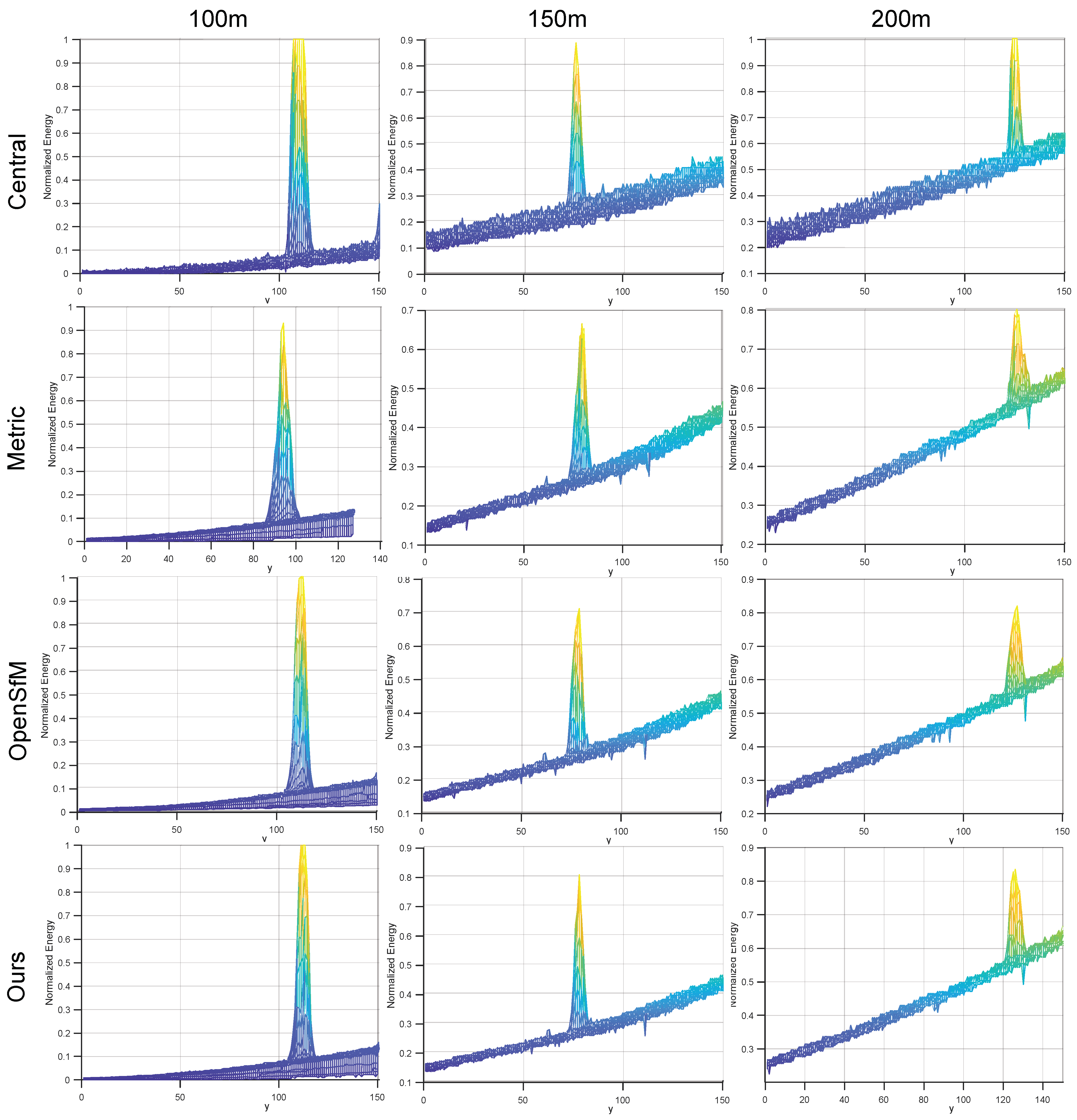
Section 5 presents experimental results on real-world data, which demonstrate the accuracy and robustness of the proposed self-calibration method compared to state-of-the-art methods.
Section 6 discusses the application prospects and existing problems of the designed infrared camera array and its self-calibration model in practical tasks, which provides direction for our next research efforts. Finally,
Section 7 concludes the paper.
3. Design and Construction of Infrared Camera Array System
3.1. System Composition and Principle
As shown in
Figure 2, the 3 × 3 infrared camera array system measures 270 × 251.3 × 50 mm externally. It is made up of nine non-cooled LWIR cameras, four five-port gigabit switches, three GPUs, and a power supply module.
Each LWIR camera consists of a lens with adjustable back focus and a detector. They are mounted as a unit on a bracket. A set of three cameras share a five-port gigabit switch and GPU, which are combined in one unit and powered by a power module.
The power supply module receives 12 V of external power and converts it to the voltage required by each component to ensure proper operation. Eight LWIR cameras operate simultaneously, triggered by the exposure signal from one camera. All nine LWIR cameras capture images of the external scene at a consistent exposure time and frame rate.
The image processing module processes three streams of image data, compresses and streams the data, and sends it to the host computer through the switch. When a store command is received, it transfers the raw camera data to the storage module. The storage module then writes these data to a storage card. The continuous image storage time is greater than 30 min at 50 Hz. The data can be exported and deleted through the PC management system.
The 3 × 3 infrared camera array system’s main specifications are listed in
Table 1.
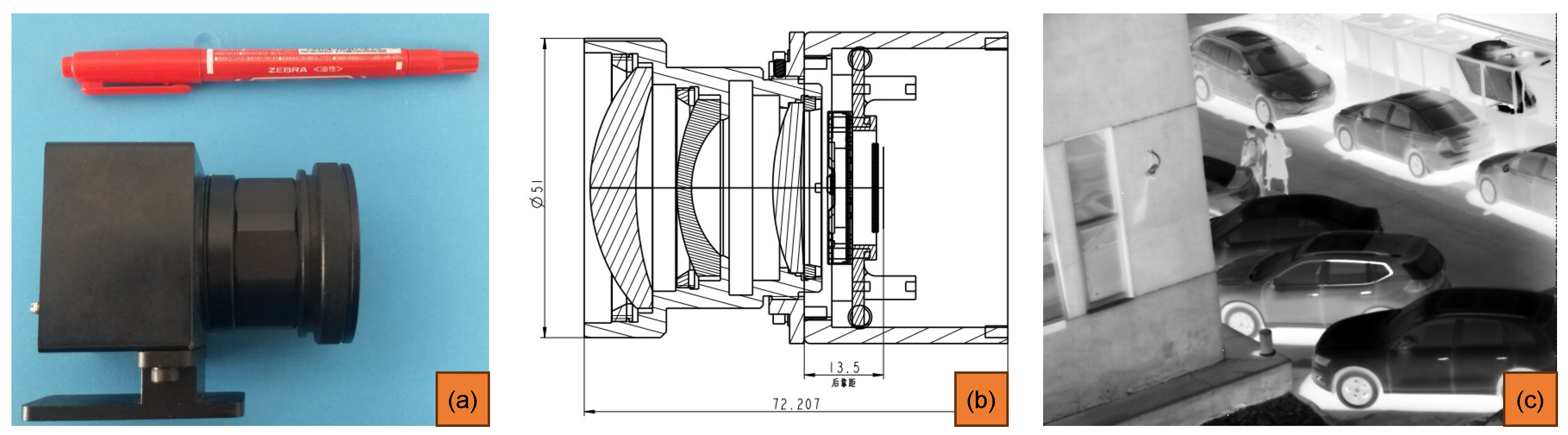
3.2. Non-Cooled LWIR Camera Design Proposal
The camera features a non-cooled LWIR sensor and a lens.
Figure 3 shows the hardware design of this camera, and its main specifications are listed in
Table 2.
The optical system is a passive non-thermalized optical structure. It consists of three lenses made of sulfur glass and zinc selenide (ZnSe). The total length of the optical system is 50 mm, the total weight is about 63.2 g, and the back focal length is greater than 14 mm. The detector’s pixel size is 12 × 12 , with a Nyquist spatial frequency of about 1/(2 × 12 ) ≈ 40 lp/mm. The modulation transfer function (MTF) value at 40 lp/mm is over 0.4, and the energy concentration exceeds 0.3.
Due to the fact that a temperature change will cause refractive index changes, optical materials and lens barrel materials undergo thermal expansion. This causes the optical system to defocus, which affects the image quality of the system. Therefore, the system uses aluminium alloy as the lens barrel material (the coefficient of thermal expansion is about 23.6 × /K). At the same time, we consider the mechanical structure and the effect of the optical components on the image quality when subjected to temperature changes. Through the reasonable combination of different materials, the system can meet the image quality requirements from low temperatures (−20 °C) to high temperatures (50 °C).
The optical system consists of five lenses. The surface of each lens is coated with a transmittance enhancement film. The transmittance of a single piece can reach 97%, and the total transmittance of the optical system is = 0.973. The rear flange is connected to the detector, and the flange is connected to the lens by threads so that the rear leaning distance can be fine-tuned and locked by three set screws around the circumference.
3.3. Function and Specification of the System
The infrared camera array and image acquisition system is primarily used for high-frame-rate imaging of specific application scenarios. The system can control camera imaging parameters, synchronize image data acquisition, provide real-time display previews, and store and retrieve data. Image acquisition between sub-cameras requires high time synchronization accuracy and a consistent output frame rate. The control and image data readout interfaces for the camera array are designed with versatility in mind and have the ability to store and replay raw data. Its main technical indicators are shown in
Table 1.
6. Discussion
The infrared camera array we designed aims to provide a solution for enhancing the detection capability of dim targets at long distances. With this solution, the detection distance of the target is directly related to the baseline length between the sub-cameras. In this study, the baseline between adjacent sub-cameras of the infrared camera array is 10 cm, which can preliminarily satisfy multi-view synthesis for dim targets within a range of 300 m. Therefore, this camera array is merely an experimental verification device. In practical tasks, to meet the detection of targets at different distances, the baseline between sub-cameras can be expanded or reduced as needed. To further reduce the impact of noise on the target, an appropriate increase in the number of sub-cameras can also be considered.
The self-calibration model we have designed is intended to provide high-precision camera poses for the infrared camera array without the constraints of calibration objects and scenes. The method draws on the advanced techniques of light-field camera calibration. It explores the structural priors of the camera array before and after multiple captures and organizes the disordered images for pose calibration. Although the calibration effect has been improved compared to methods based on structure from motion (SfM), the selection of calibration scenes still presents a challenging issue. This includes the distance of scene objects from the images, the area occupied by scene objects in the images, and other problems. Therefore, further experimental validation is required to address these issues.
In the future, we plan to conduct more extensive experiments to validate the performance of our infrared camera array and self-calibration model under different conditions and environments. We also aim to optimize the calibration process and reduce the computational complexity of the algorithm. Moreover, we will explore the integration of our method with other advanced technologies, such as deep learning and computer vision, to further enhance the detection capability of dim targets.
We believe that these future work directions will not only address the limitations of our current research but also contribute to the development of new applications and technologies in the field of infrared imaging and detection.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}