1. Introduction
With the rapid global increase in positioning and navigation demands, high-precision, real-time positioning services are becoming increasingly critical in sectors such as intelligent transportation, urban planning, and autonomous driving. A pivotal element in the construction and updating of high-precision maps involves the accurate collection and updating of POIs such as traffic light intersections, gas stations, parking lots, and tunnels within the road network. Urbanization intensifies the complexity of traffic, making the efficient modernization of urban road networks one of the current focal topics in transportation research [
1,
2]. Traditional methods of manual data collection and annotation, hindered by their lack of timeliness and precision, struggle to meet the demands for swift updates of modern maps. The need to identify urban road network POIs accurately and swiftly has become increasingly urgent. Recent years have seen a significant expansion in the application of remote sensing technology and vehicle-mounted global navigation satellite systems (GNSSs), facilitating the large-scale collection and processing of vehicle trajectory data and remote sensing information, which introduces innovative approaches for updating road data.
In the realm of remote sensing applications for urban geographic information extraction, researchers have deployed various strategies to manage the complex characteristics of roads and buildings. Initially, Xiao et al. utilized an edge detection-based approach, which, by recognizing image edge information, facilitated the extraction of road contours, thus laying the foundation for basic road feature extraction [
3]. Advancing this field, Singh et al. developed a two-stage framework that leverages the distinctive features of impervious surfaces to enhance the precision and efficiency of road extraction from high-resolution satellite imagery [
4]. Concurrently, Hou et al. explored the use of shadows in images to deduce building heights, a method that underscores the importance of spatial coordinates in the process of inferring building dimensions. This approach offers a novel perspective for urban planning and building monitoring [
5]. Furthermore, Kaur et al. enhanced the classification capabilities of satellite images by improving the Marr–Hildreth method and integrating it with fuzzy clustering, demonstrating its superiority in areas such as rock cover planning, shadow detection, and building identification [
6]. With the growing demand for greater accuracy and more complex scene analysis, Cai et al. proposed a multi-attention residual integration network that improves hyperspectral image recognition by reducing redundant features and enhancing feature fusion, thus addressing the high complexity in remotely sensed images [
7]. Qi et al. improved the method for recognizing remote sensing images by implementing an optimization strategy and machine learning algorithms specifically for extracting landslide features, significantly enhancing the capability for monitoring natural disasters [
8]. To mine both global and local feature information simultaneously and improve the detail processing capabilities of image recognition, Cui et al. introduced a dual-channel deep learning network for remote sensing image recognition [
9]. Supported by modern computing technologies, He et al. presented a cloud-edge collaborative feature extraction framework for satellite multi-access edge computing. This framework, by training a feature extractor on a terrestrial cloud server, optimizes the process of extracting useful features from satellite data, showcasing the efficacy and potential of cloud and edge computing in processing remote sensing data [
10].
To improve the understanding and management of urban traffic flows, scholars have employed various advanced methods and algorithms to process and analyze GPS-based floating car data. In terms of updating and enhancing the accuracy of digital road maps: Li et al. utilized data from the National Commercial Vehicle Monitoring Platform to propose an incremental road network extraction method, suited for low sampling frequencies and extensive GPS data coverage [
11]. Zheng et al. developed a novel incremental clustering algorithm specifically designed to extract the road network topology from floating car data [
12]. Additionally, Zhang et al. employed mathematical morphology and gravity models to incrementally extract urban road networks from spatio-temporal trajectory data, thereby increasing the precision and complexity of data processing methods [
13]. In terms of traffic flow monitoring and analysis, Chen et al. analyzed traffic conditions on urban highways using floating car data, identifying traffic congestion patterns [
14]. Concurrently, Guo et al. enhanced traffic flow analysis accuracy by applying a weighted least squares method to mine road networks from floating vehicle data [
15]. In terms of the identification of urban functions, Sun et al. analyzed vehicle trajectory data to explore the importance of human mobility and ultimately determine the functional types of key locations [
16]. Hu et al. introduced a graph convolutional neural network framework to model the relationship between traffic interactions and urban functions at the road segment level, aiming to categorize social functions along streets [
17]. In terms of travel behavior analysis, Huang et al. focused on the personal travel patterns of private vehicle drivers using a large-scale dataset and clustering with the DBSCAN method [
18]. Furthermore, Xiao et al. introduced an improved edit distance with real penalty (IERP) to measure the spatio-temporal distance between trajectories, assisting in the analysis and extraction of regular travel behaviors from private car trajectory data [
19].
The existing research on urban traffic data extraction predominantly relies on a single data source, which often results in issues such as inadequate accuracy. In response to these challenges, numerous scholars have advocated for the integration of diverse data sources in recent years. In terms of basic road and area feature extraction, Yali Li et al. crafted a multivariate integration method that effectively extracts road intersections by combining vehicle trajectory data with remote sensing images, significantly improving the extraction accuracy [
20]. Similarly, Fang et al. capitalized on the unique advantages of GNSS trajectory points and high-resolution remote sensing images to develop a road area detection method in remote sensing imagery, which focuses on the continuity of trajectory data and the similarity of image features [
21]. Furthermore, Qian et al. implemented an integrated model that uses satellite imagery and taxi GPS trajectories to perform a four-step process for urban functional area (UFA) recognition [
22]. In terms of enhancing the creation and updating of digital maps for traffic information systems, Qin et al. established a composite updating framework that merges trajectory data with UAV remote sensing images, based on a hidden Markov model (HMM) map-matching approach to discern new road sections [
23]. Additionally, Wang et al. introduced the DelvMap framework, utilizing courier trajectories and satellite imagery to fill in missing road data on maps, thus addressing gaps in digital road mapping [
24]. Deep learning and automated methods have been increasingly applied in traffic feature extraction. Yang et al. proposed an automated road extraction solution named DuARE, which aims to extract basic road features from aerial imagery and trajectory data in a fully automated manner [
25]. Wu et al. developed a deep convolutional neural network called DeepDualMapper, which seamlessly integrates aerial imagery and trajectory data for digital map extraction [
26]. Furthermore, Li et al. introduced an approach integrating GPS trajectories and RS images using a U-Net variant to construct road maps consisting of intersections and road segments [
27].
In recent years, a considerable number of researchers have focused on employing various deep learning network architectures for road network extraction, achieving significant advancements in the accuracy and efficiency of road object detection. The integration of dynamic convolution techniques and density-aware mechanisms has notably enhanced the recognition performance of various road objects in complex and congested traffic environments. In terms of the development of foundational deep learning models and frameworks, Badrinarayanan introduced a practical and novel deep fully convolutional neural network architecture, SegNet. This architecture efficiently achieves semantic pixel-level segmentation by utilizing pooling indices for nonlinear upsampling during the maximum pooling steps [
28]. Zhou and colleagues developed a semantic segmentation neural network, D-LinkNet, which utilizes an encoder–decoder structure, dilated convolutions, and a pretrained encoder specifically for road extraction tasks [
29]. In the application of multi-task and multi-scale learning frameworks, Shao et al. devised a dual-task end-to-end convolutional neural network, the multi-task road related extraction network (MRENet), which serves for both pavement extraction and road centerline extraction [
30]. Lu and colleagues proposed a novel multi-scale, multi-task automated deep learning framework (MSMT-RE) for road extraction, which effectively carries out road detection and centerline extraction tasks concurrently [
31]. In terms of solutions for specific problems and advanced network architectures, Zhou et al. offered the boundary and topology aware road extraction network (BT-RoadNet), which enhances road network extraction capabilities, addressing disruptions caused by shadows and occlusions, and is capable of extracting roads of varying scales and materials, including those with incomplete spectral and geometric properties [
32]. Xiong et al. proposed an improved semantic segmentation model, DP-LinkNet, which uses the D-LinkNet architecture as a backbone and incorporates hybrid dilation convolution (HDC) and spatial pyramid pooling (SPP) modules [
33].
In the application and optimization of multimodal data fusion techniques, Gao et al. used floating vehicle trajectories for trajectory correction, subsequently extracting road features from both the channel and spatial domains of target images using a convolutional network model based on a dual-attention mechanism [
34]. Li et al. developed a decoder fusion model based on dilated Res-U-Net (DF-DRUNet) that efficiently merges GPS trajectories with remote sensing images to extract road networks [
35]. Shimabukuro and colleagues introduced an early fusion network that uses RGB and surface model images to provide complementary geometric data for improved pavement extraction [
36]. Roy et al. proposed a new multimodal fusion transformer network (MFT), featuring multi-head cross-patch attention (mCrossPA) for classifying HSI land cover [
37]. Ma et al. presented the FTransUNet, a multi-level multimodal fusion scheme that integrates CNN and Vit into a unified fusion framework, providing a robust and effective multimodal fusion backbone for semantic segmentation [
38]. In summary, despite numerous studies on utilizing multi-source spatiotemporal data for identifying POIs in road networks, current approaches still encounter specific challenges:
- (1)
Remote sensing methods have primarily depended on the physical characteristics (e.g., geometric shape, texture, color) of POIs for identification. However, in complex terrains such as mountains, vegetation, or buildings, occlusion often leads to the failure of these physical features to accurately reflect the POIs of frequent human activity in typical road sections.
- (2)
Although trajectory data-based methods use spatial location and dynamic connection features for POI identification, the identification accuracy of these methods is not ideal in some areas due to the uneven spatial distribution of trajectory data and signal noise problems in occluded or semi-occluded areas.
- (3)
Although the multi-source data fusion method combines the geometric characteristics of remote sensing data with the dynamic traffic characteristics of trajectory data, the existing models are complex and there have been relatively few studies on road POI identification.
- (4)
Segmentation methods such as U-Net rely heavily on extensive, high-quality annotated data; however, in specific scenarios, suitable annotated data are often scarce. The manual acquisition of such data is not only cumbersome but also time consuming, significantly constraining the training and refined development of models.
To address these issues, this paper introduces DualNet-PoiD, a hybrid neural network approach for effectively identifying POIs in road networks within intricate urban terrains. This method aims to detect and classify common POIs such as petrol stations, traffic light intersections, parking lots, tunnels, and straight roads. The primary contributions of this paper are as follows:
- (1)
We create a publicly available dataset comprising remote sensing data and vehicle trajectory datasets for POIs in areas with complex topography. Previous research has lacked publicly available datasets providing continuous stopping time and location information necessary for identifying typical road network POIs in complex terrain areas. This dataset now serves as a valuable resource for future scholars conducting research in this field.
- (2)
This paper introduces an innovative hybrid neural network designed to integrate remote sensing data with vehicle trajectory data for the identification of POIs in road networks. The principal advantage of this approach is its capability to simultaneously process the static geometric features derived from remote sensing data and the dynamic traffic features provided by trajectory data. By leveraging this data fusion, the model effectively addresses the recognition limitations encountered in scenarios with occlusions, significantly enhancing the precision and coverage of POI identification without depending on traditional data annotation processes.
- (3)
The experiments demonstrate the effectiveness of multimodal data and DualNet-PoiD in identifying POIs across various topographic environments. A comprehensive series of experiments were conducted, including comparisons between DualNet-PoiD and single DAD-LinkNet, single GRU, and single LSTM models. These experiments covered various complex terrain conditions, such as the presence of tall buildings, trees, and tunnels. The accuracy of the experiments was illustrated using precision, recall, F1-score, and IoU indicators. The results fully demonstrate the superior performance of DualNet-PoiD in handling diverse complex terrains and multiple POI types.
2. Research Methodology
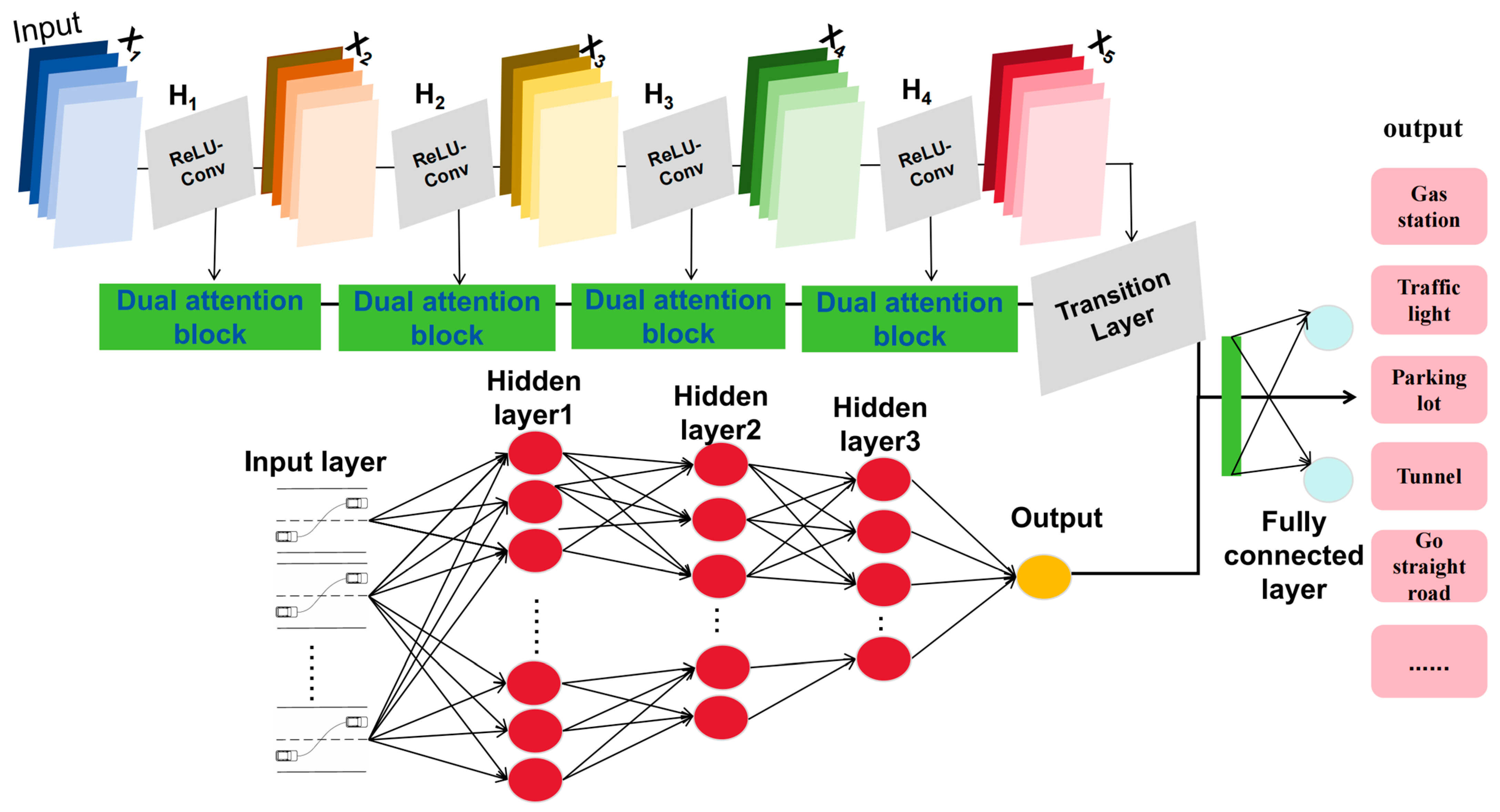
This study introduces an innovative neural network structure designed to automatically identify and extract POIs related to roads in urban areas with rugged terrain. We achieve effective POI identification in complex urban areas by combining static geometric features of roads with dynamic traffic features, utilizing DAD-LinkNet and GRU. This fusion process can be accomplished through either simple splicing or weighted averaging methods.
Initially, we generate remote sensing data and vehicle trajectory data that meet the specified criteria.
Figure 1 illustrates the sequence of preprocessing steps these data undergo before entering the architecture, which consists of three primary components.
Part I: Representation Learning from Remote Sensing Data. This phase involves the acquisition of remote sensing imagery for POIs such as gas stations, traffic light intersections, parking lots, tunnels, and straight roads. The images undergo preprocessing operations including scaling, cropping, and normalization to prepare them for further analysis. The preprocessed images are then fed into a DAD-LinkNet equipped with a dual-attention mechanism, designed to extract the geometric features of the roads.
Part II: Representation Learning from Trajectory Data. Trajectory data, encompassing timestamps, vehicle IDs, longitude, and latitude information, are processed to simulate the paths vehicles take through specific POIs, with constraints set on time and space. These data are input into GRU to capture the underlying traffic dynamics associated with the roads.
Part III: Multimodal Data Fusion and POIs Identification. In this stage, features from trajectory and image data are merged using methods such as simple concatenation or weighted averaging. After the feature fusion, a hybrid neural network is constructed to identify critical traffic POIs. Weighted hyperparameters are used as the loss function to optimize the network parameters, enhancing the model’s performance in recognizing and classifying POIs.
2.1. Geometric Feature Extraction Based on Remote Sensing Data
Remote sensing data representation learning is a critical means for analyzing conditions of the Earth’s surface and atmosphere. This paper employs a convolutional neural network based on an improved ResNet18 architecture, named DAD-LinkNet. This network structure, through the Dual-Attention Module (DAM), effectively enhances the capability to extract key features from remote sensing images. Such improvements allow the network to more accurately identify surface characteristics, change detection, and other environmental monitoring elements when processing a large volume of remote sensing image data.
DAD-LinkNet combines the deep feature extraction capabilities of ResNet18 with the significant advantages of attention mechanisms. ResNet18 addresses the issue of vanishing gradients in deep networks by introducing residual connections, which are formulated as follows in its residual blocks:
Within this formulate, represents a combination operation of a convolution layer, batch normalization layer, and activation function, where denotes the input and the output.
Building on this, DAD-LinkNet further enhances its feature extraction capability by incorporating the DAM. The DAM consists of two main components: the Channel Attention Mechanism [
39] (
CA) and the Spatial Attention Mechanism [
40] (
SA). The Channel Attention Mechanism utilizes both max pooling and average pooling to capture global information, which is then processed by fully connected layers. The specific computation formula is as follows:
The spatial attention mechanism extracts spatial information through a convolution operation, calculated as follows:
The Spatial Attention Mechanism extracts spatial information via convolution operations, with the computation formula expressed as follows: is the Sigmoid activation function, and symbolizes the convolution operation, with and indicating maximum pooling and average pooling, respectively. The DAM ensures that the model focuses on the most informative regions within remote sensing images.
By integrating these two attention mechanisms, DAD-LinkNet enhances its focus on the most informative areas within remote sensing images during the feature extraction process, thereby improving the overall performance of the model. The specific network layers are described as follows:
- (1)
Input Layer: Receives remote sensing images that have been normalized and resized to prepare for subsequent feature extraction.
- (2)
Initial Convolutional and Pooling Layers: The first layer is a 7 × 7 convolutional layer with a stride of 2, followed by batch normalization and a ReLU activation function, performing preliminary feature extraction. This is followed by a 3 × 3 maximum pooling layer with a stride of 2, which reduces the spatial dimensions of the feature map, enhancing the model’s capacity for abstraction.
- (3)
Residual Blocks: Contains four sets of residual blocks, each comprising two 3 × 3 convolutional layers, with each convolutional operation followed by batch normalization and ReLU activation. These blocks use residual connections to help the network learn deeper features without losing important information.
- (4)
DAM: Positioned after the intermediate residual blocks. This module consists of two parts: CA and SA. CA is achieved through global average pooling and maximum pooling, followed by processing the pooled results with two 1 × 1 convolutional layers and merging them through a Sigmoid function, enhancing the model’s focus on specific channels. SA utilizes the outputs from the channel attention, bolstering spatial features through a 7 × 7 convolutional layer and a Sigmoid function, thus strengthening the model’s recognition capabilities in key image areas.
- (5)
Output Layer: A global average pooling layer converts the feature map into a one-dimensional feature vector, followed by a fully connected layer that outputs the final feature representation, used for subsequent feature fusion tasks.
2.2. Extracting Traffic Semantics Based on Trajectory Data
Trajectory data representation learning is crucial for understanding the movement patterns of objects in space and time. This paper utilizes a model based on GRU [
41], named the RNN Model, which captures the temporal dependencies and dynamic characteristics of trajectories to extract valuable information for traffic flow analysis, urban planning, and mobility patterns.
The design of the RNN Model leverages the advantages of GRU to effectively handle long-term dependencies in time series data. The model structure is as follows:
- (1)
Input Data Preprocessing: Trajectory data are processed with temporal and spatial constraints to simulate the paths of vehicles passing through specific POIs.
- (2)
GRU Layer: The input data are fed into the GRU layer, which captures the temporal dependencies. The computation formula for the GRU layer is as follows:
is the update gate. is the reset gate. is the updated hidden state. is the candidate hidden state. is the input at time t. is the previous hidden state at time t − 1. denotes the sigmoid activation function, which limits values between 0 and 1, crucial for gates in GRU as it regulates the amount of information that should be passed through. represents the hyperbolic tangent function, which helps in regulating the information flow within the network by providing outputs between −1 and 1, suitable for maintaining the scale of the hidden state. , , and are the respective weight matrices for the update gate, reset gate, and the candidate hidden state. indicates element-wise multiplication, which is essential in applying the reset gate to the previous hidden state before combining it with the current input for candidate activation.
- (3)
Fully FC: The output from the GRU layer is passed through a fully connected layer to generate the final feature representation.
- (4)
Output Layer: The final output features are used for subsequent fusion tasks, supporting complex decision-making processes.
2.3. Multimodal Data Feature Fusion and POI Recognition
Multimodal data feature fusion is crucial for enhancing the accuracy and efficiency of location-based services. We implement the HybridModel, a framework that integrates the outputs of DAD-LinkNet and RNN Model through a fully connected layer, enabling simultaneous processing of image and time series data within a unified framework, thereby enabling more precise POI recognition. Multimodal data feature fusion is essential to improve the accuracy and efficiency of location-related services. We do this by implementing the HybridModel, a model that combines the outputs of DAD-LinkNet and RNN Model with a fully connected layer for final classification, allowing for a more accurate identification of POIs by processing both image data and time-series data within a unified framework.
The model fusion process is structured as follows:
- (1)
Image and Trajectory Data Preprocessing: Image and trajectory data are preprocessed separately.
- (2)
Feature Extraction: Image data are input into DAD-LinkNet to extract geometric features, while trajectory data are fed into RNN Model to extract temporal features.
- (3)
Feature Fusion: The output features from DAD-LinkNet and RNN Model are fused either by concatenation or weighted averaging.
The formula for this process is as follows:
where
denotes the feature vector obtained from the features extracted from the CNN model after global average pooling (
GAP) and
DAM processing through a
FC.
denotes the feature vector obtained by passing the features extracted from the RNN Model (here,
GRU) through a fully connected layer.
and
represent image data and time series data, respectively.
denotes feature concatenation.
Moreover, a weighted loss function was used to balance the acquisition of diverse tasks:
where
and
are weight parameters,
and
are the cross-entropy loss and mean square error loss, respectively. This structure enables the model to handle not only single-modal data but also to efficiently integrate information from multiple sources, providing robust support for complex classification tasks. This integration method significantly enhances the model’s adaptability and usefulness in real-world scenarios, particularly when processing various data types concurrently.
Figure 2 displays the comprehensive configuration of the hybrid model.
4. Conclusions and Outlook
This study introduces a hybrid neural network approach for efficiently recognizing POIs in the road networks of urban areas with complex terrain, with experiments conducted in the central urban district of Chongqing, leveraging complex topography and multi-source data. By integrating the geometric features from remote sensing imagery and the dynamic traffic characteristics from vehicle trajectory data, the effectiveness of the hybrid model in POI recognition is validated. The experimental results demonstrate that the hybrid model exhibits superior performance under both obstructed and unobstructed terrain conditions, underscoring its adaptability and robustness in complex terrain settings. Additionally, comparisons between single models and multimodal models under various terrain and obstruction scenarios further confirm the high efficiency of the proposed DualNet-PoiD model in integrating multi-source information. These findings not only showcase significant performance improvements in the model under optimal parameter settings but also highlight its potential in practical applications for recognizing typical network POIs such as gas stations and parking lots. Although visual analysis is not extensively utilized, the current methodology provides a solid empirical foundation for the validation of the model.
The foremost advantage of the model lies in its ability to significantly enhance the accuracy and coverage of POI recognition, particularly in urban environments where physical obstructions are prevalent. By autonomously analyzing remote sensing data and vehicle trajectory data, the DualNet-PoiD model reduces the costs associated with model training and application without the need for manual data labeling. Furthermore, the model demonstrates exceptional adaptability, capable of adjusting to and responding to diverse urban terrains and complex environmental conditions, thereby maintaining high recognition precision.
Despite the multiple strengths exhibited by DualNet-PoiD, it does face some limitations. Firstly, the model’s reliance on substantial computational resources may hinder its deployment in scenarios with limited resources. Secondly, due to the complexity of the model’s structure, which involves advanced deep learning functionalities, tuning and maintenance pose significant challenges.
Future research could be directed towards enhancing the accuracy and application scope of the hybrid model introduced in this article for POI recognition using remote sensing imagery and vehicle trajectory data within road networks. Considering the challenges posed by mountainous terrains and other unique geographical features on POI recognition, forthcoming efforts could concentrate on refining the model and its processing capabilities. The integration of advanced methods such as the U-Net [
43] model or mamba [
44] may facilitate better handling of these environmental variables. Additionally, the exploration of further visual analysis techniques could significantly improve the model’s interpretability and user trust.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}