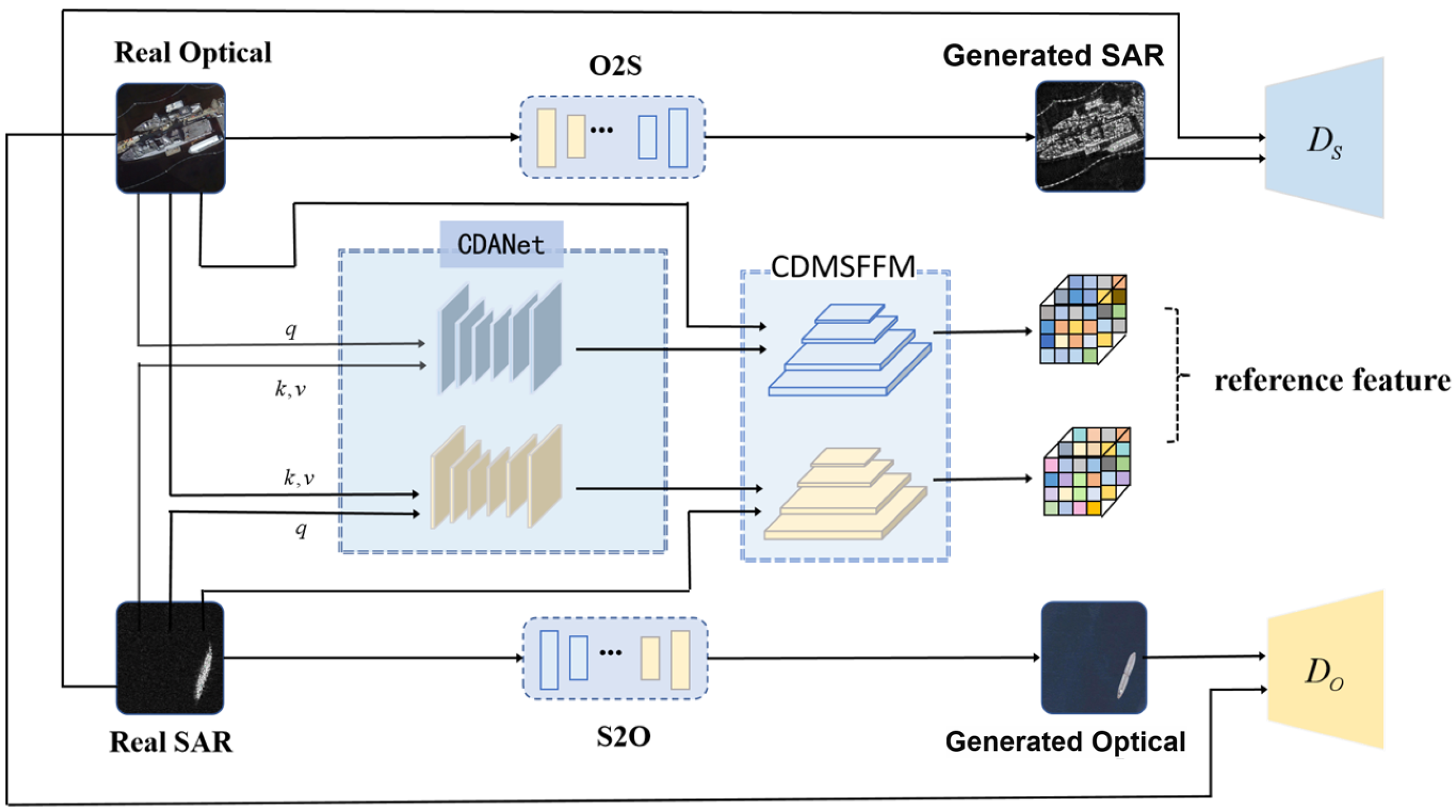
2.1. Overall Framework of CDA-GAN
The proposed CDA-GAN for optical–SAR image translation is shown in
Figure 2, where O2S (S2O) and
(
) represent the generator and discriminator of the SAR (optical) domain in GAN, respectively.
First, the features from the optical and SAR domains are fused in the form of attention to obtain the main feature distribution of one domain and the content display of the other domain, which are named reference images after CDMSFFM. Second, the L1 norm is used to calculate the difference between reference image of the corresponding domain and image generated by the generator to obtain the reference loss. Third, discriminators are used to judge whether the image is a real image, performing confrontational learning with the generator. In the training process, cross-domain attention is combined with cycle consistency loss to generate deeper features of the corresponding domain, and the reference loss is added to the loss function to train the whole network. The differences of features (such as scattering mechanism, etc.) between SAR and optical images are learned automatically by CDA-GAN. The details of the proposed CDA-GAN, including CDANet, CDMSFFM, and the loss function, are presented in what follows.
2.2. Cross-Domain Attention Net (CDANet)
First, features are extracted from images in the optical domain and SAR domain through the CNNs to obtain features of different sizes, called main feature layers, which are the following:
, measuring 32 × 32;
, measuring 64 × 64;
, measuring 128 × 128; and
, measuring 256 × 256. Among all main feature layers,
is used as one of the inputs to obtain a cross-domain attention feature map. Then, a cross-domain attention feature map goes through a cross-domain pyramid structure for feature fusion to obtain a reference image.
and
, with height
H, width
W, and channels
C, represent the intermediate feature space in the optical and SAR domain, respectively. As shown in
Figure 3, the first map
is set to query
. By using 1 × 1 convolutions,
is set to the key
and value
. Afterwards, the initial correspondence
is learned following the traditional attention mechanism:
where
,
, and
are position indices;
and
are the average values of
and
, respectively.
is the matching score between
and
.
An initial correspondence map of previous methods is used typically to rearrange an exemplar to control local patterns in image synthesis. involves unreliable matching scores due to the difficulty of cross-domain correspondence learning. Therefore, the restructured image will have incredible artifacts during training process. In order to overcome this disadvantage, masks were designed to fine-tune the matching scores, leading to more realistic feature map fusion.
is designed by multiplying K and V through two different 1 × 1 convolutions. The results of cross-domain attention features are divided into two parts, reliable features and extra features. Then,
is used to warp the value features to get reliable features.
In order to make full use of information from the optical domain,
is used to warp
to get extra features, further obtaining supplementary information from
Q. First,
Q is normalized to obtain
, and normalization operation is performed on the second dimension.
and
come from
. Then, we can formulate the modulation as follows:
Thus,
and derived supplementary features preserve semantic information from images in optical domain. In this way, cross-domain attention can connect the two domains and fully explore the available information in the two domains. The reliable features and extra features complement each other, so that the style of the cross-attention feature map moves towards the target domain, while preserving the semantic features of source domain as much as possible:
Finally, reliable features and extra features are designed through a convolutional layer to obtain a cross-domain attention feature map.
2.3. Cross-Domain Multi-Scale Feature Fusion Module (CDMSFFM)
CNNs cannot extract the features of target fully at global level due to the limited size of the input image and convolution kernel. In order to strengthen the connection between local and global levels when extracting the features of target, pixel-level multi-scale feature fusion is designed to fuse feature maps at different levels in this paper. The object of fusion is fusing the reference feature map obtained by CDANet and the main features extracted by CNN. Taking optical-to-SAR mapping as an example, the main feature map of the optical domain and the main feature map of the SAR domain are input into CDANet to obtain the reference feature map. Then, with the other main special pattern diagrams of the optical domain ,, and , the feature fusion can be performed.
The feature map
output by cross-domain attention module combines the semantic information of the optical domain and the style information of the SAR domain. After upsampling
twice, splicing it with
in the second dimension, and then changing the channel dimension through channel convolution, it is obtained. Each stitching operation is on the main feature layer extracted from the optical domain. The principle of each stitching selection is that the size of the feature map increases from small to large until the size of the stitched image is 256 × 256. Finally, the channel number reduces to 3 through channel convolution again and then the final reference image is obtained. The structure of the proposed feature fusion method is shown in
Figure 4. The features at each layer of different sizes can be fused by the pixel-level multi-scale feature fusion module.
2.4. Loss Function
The network structure of the algorithm proposed in this paper is mainly divided into four parts, namely generators, discriminators, CDANet, and CDMSFFM. According to the reverse mapping relationship from optical to SAR and from SAR to optical, each part has two networks with exactly the same structure and completely opposite mapping relationship. Based on the principle of the proposed CDA-GAN, an additional loss (named reference loss in this paper) was added on the basis of losses of the previous GAN-based methods. In short, in the proposed CDA-GAN, we have identity loss, adversarial loss, cycle consistency loss, and the proposed reference loss. The specific formulations of these losses are elaborated as follows.
Identity loss: In order to ensure that generators are able to generate domain-specific images, it is essential to constrain them with real images of the specific domain. It is defined as
where
and
are the generators that generate fake optical and SAR images, respectively.
and
are the real optical and SAR images, respectively.
Adversarial loss: The confrontation of GAN is mainly reflected in the discriminators of the optical and SAR domain. The discriminator is used to discriminate the image of real optical (SAR) domain and the image generated by
(
). For the mapping G:O → S, adversarial loss is formulated as
Similarly, the inverse mapping G:S → O adversarial loss is as follows:
Finally, the overall loss in both optical and SAR domain is
Cycle consistency loss: Only the constraints of identity loss and adversarial loss hardly guarantee the exact mapping from the input domain to the target domain, because a network of sufficient capacity can contain arbitrary random permutations, which cannot guarantee the desired output. To solve this problem, a cycle consistency loss proposed in CycleGAN is used to measure the difference between the input image
I and the image
[
14]. The cycle consistency loss is set as
where,
means that the image in the optical domain is first mapped to the SAR domain by the generator
, and then mapped to the optical domain by the generator
. The contrary mapping is
.
Reference loss (the additional proposed loss in CDA-GAN): By introducing an additional feature map loss term, the generator is encouraged to acquire domain-specific features while participating well in cross-domain unpaired image fusion to assist images in two-way image translation. Specifically, for the optical domain, as CDA-GAN participating samples
and
, the loss between the reference image obtained by CDA-GAN and the SAR image generated by the generator is calculated as follows:
where
is the CDA-GAN that generates the mapping reference SAR image, where Q is from optical domain, and K and V are from SAR domain. Similarly, the loss between the inverse mapping reference image and the generated image in optical domain is calculated as
where
is the generator that generates fake optical images.
is the CDA-GAN that generates the mapping reference optical image, where Q is from SAR domain, and K and V are from optical domain.
is the L1 norm. In image-to-image translation tasks, the L1 norm is widely used to measure the absolute distance of two targets, so as to minimize the loss in optimization. For example, L1 is used to calculate the feature map loss per unit channel in [
38]. Moreover, compared to the L2 norm, the L1 norm retains edge information to a greater extent, so L1 norm is chosen to calculate feature map loss between reference images and generated images.
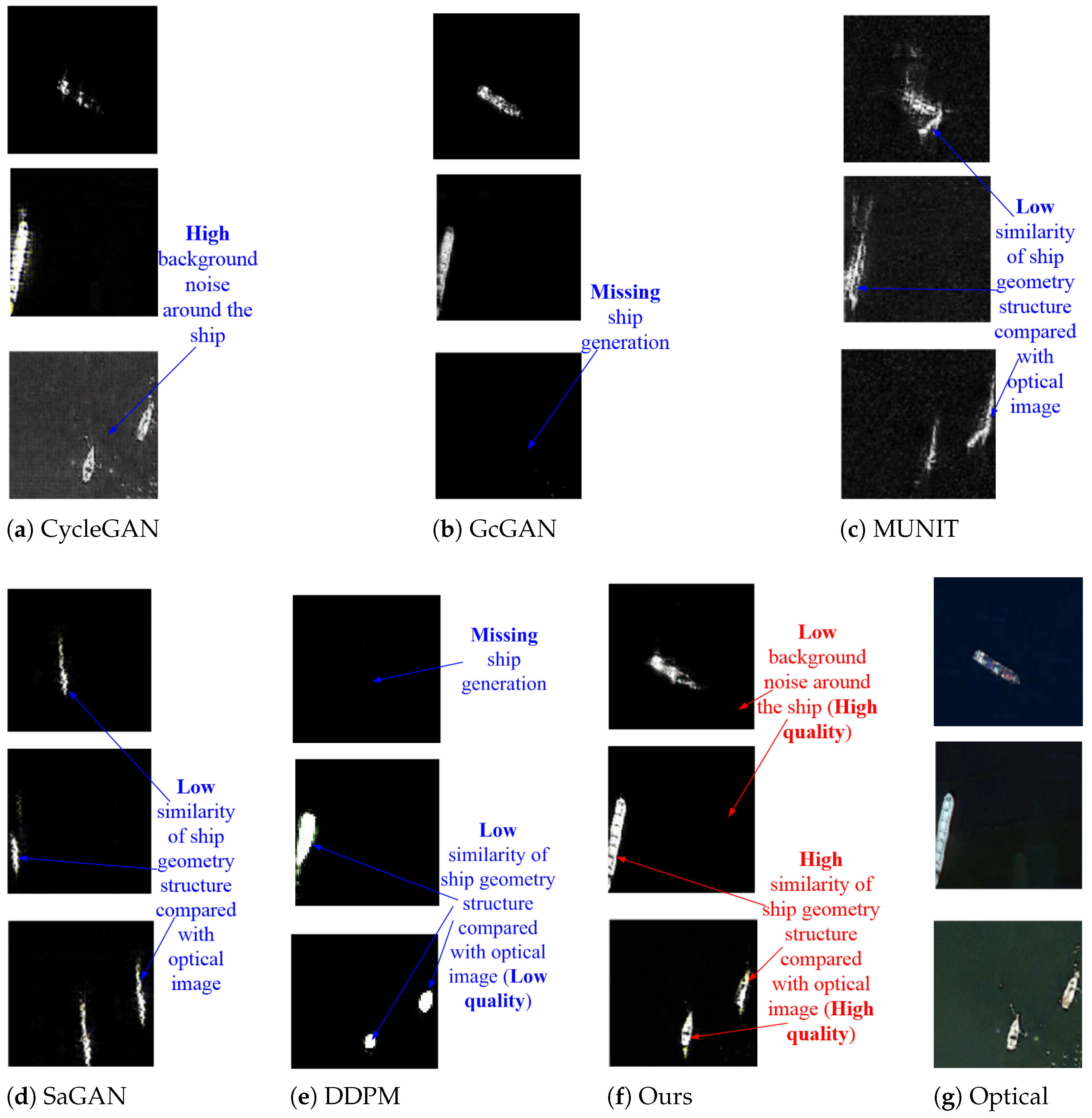
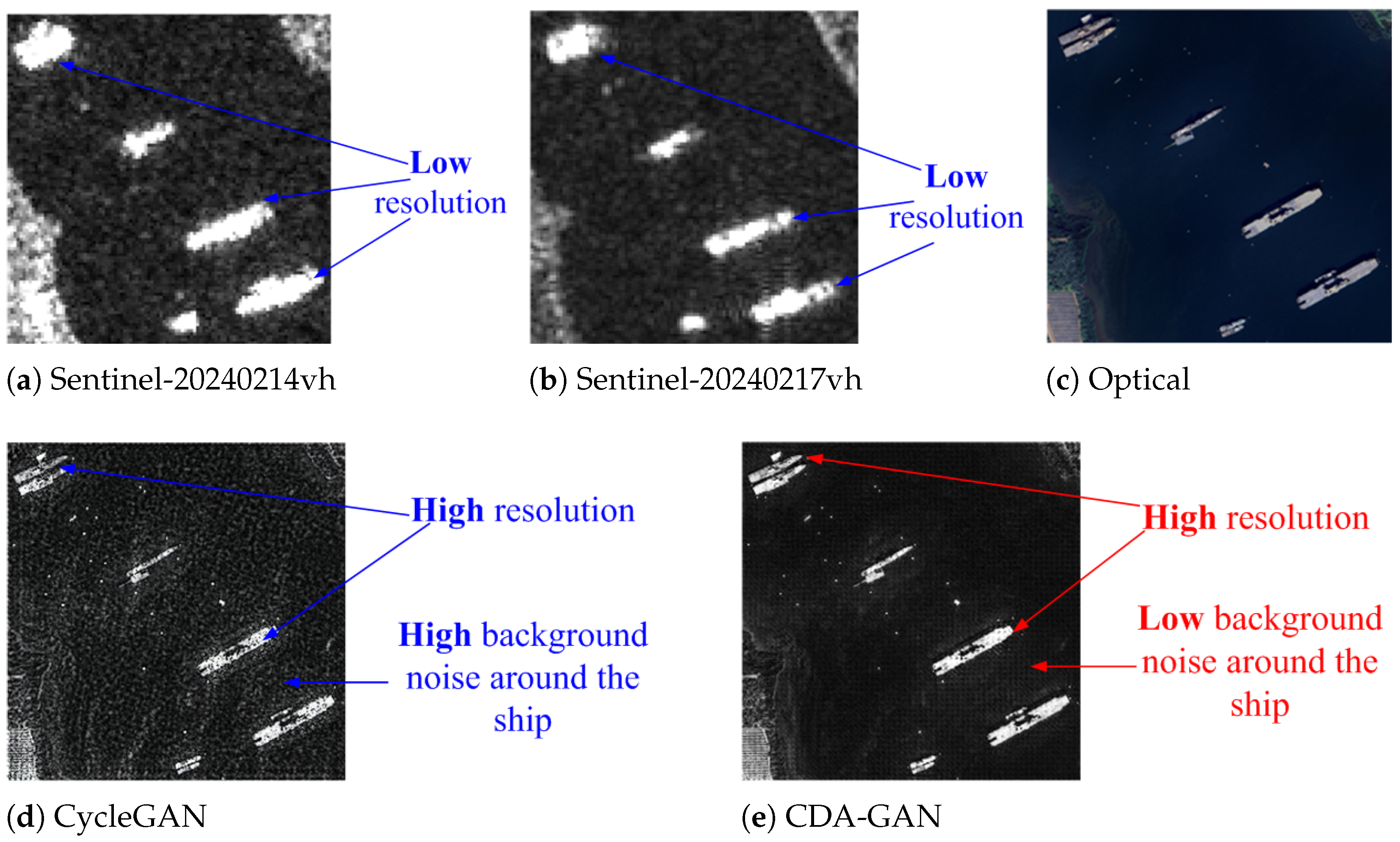
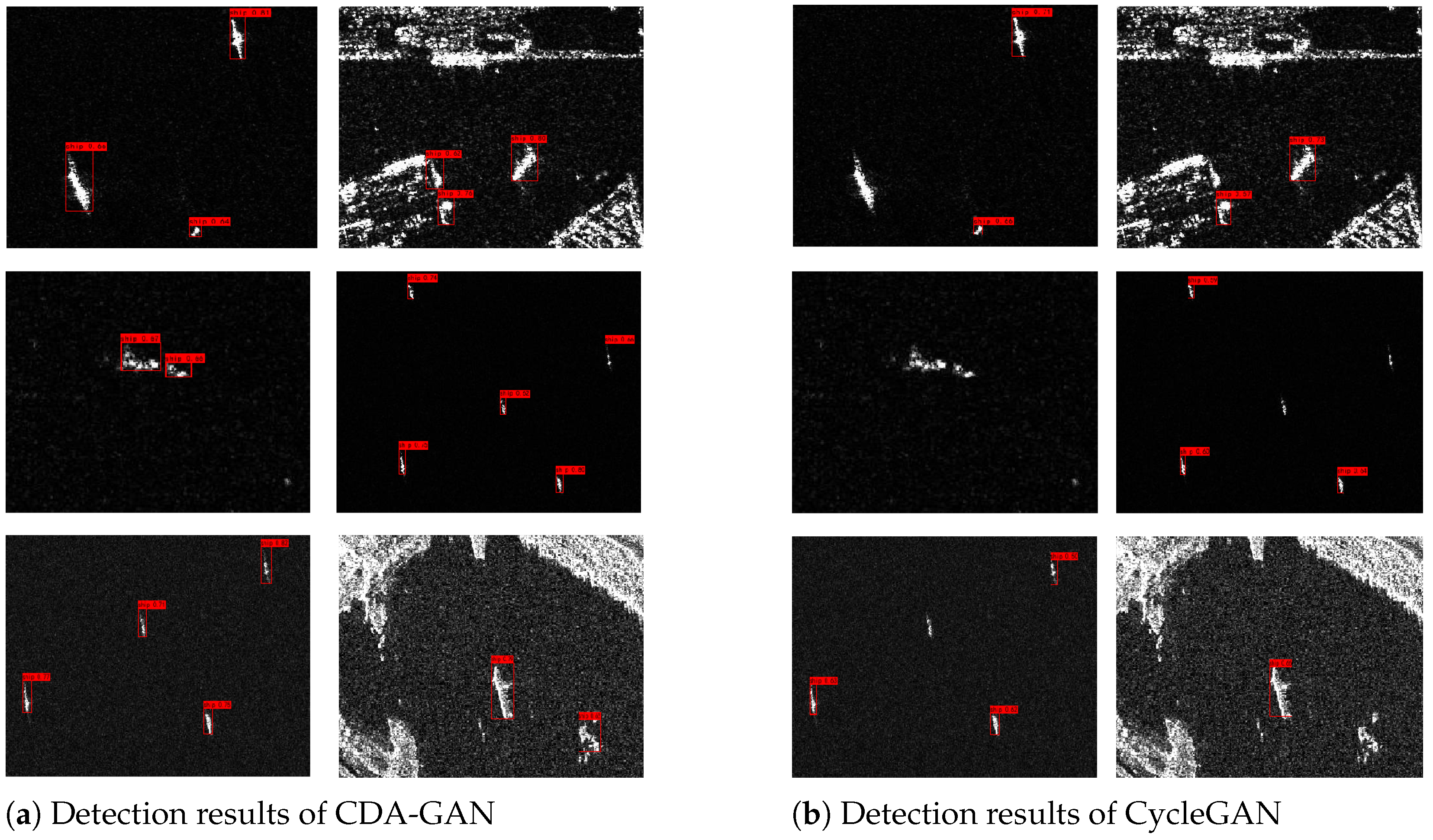
In the experimental results shown in
Section 3, the reference loss can make use of transformer as the framework to combine information of different domains in a hierarchical form, forcing the image to generate the style of the target domain in the mapping direction. Simultaneously, the semantic information of the source domain is retained to the greatest extent.
Consequently, the overall loss of CDA-GAN will be
where
,
, and
are the weighted coefficients between different losses. Our optimization goal is to solve the following min–max problem:











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}