

A New Open-Source Software to Help Design Models for Automatic 3D Point Cloud Classification in Coastal Studies
 , , ,
, , ,
Abstract

1. Introduction
1.1. Motivation
1.2. Goal of the Paper
2. Materials and Methods
2.1. Classification with Machine Learning
2.1.1. Supervised Machine Learning
2.1.2. cLASpy_T Software
2.1.3. Machine Learning Algorithms Used
Random Forest Classifier
Gradient Boosting Classifier
Multi-Layer Perceptron Classifier
2.2. Model Design, Tuning, and Predictions
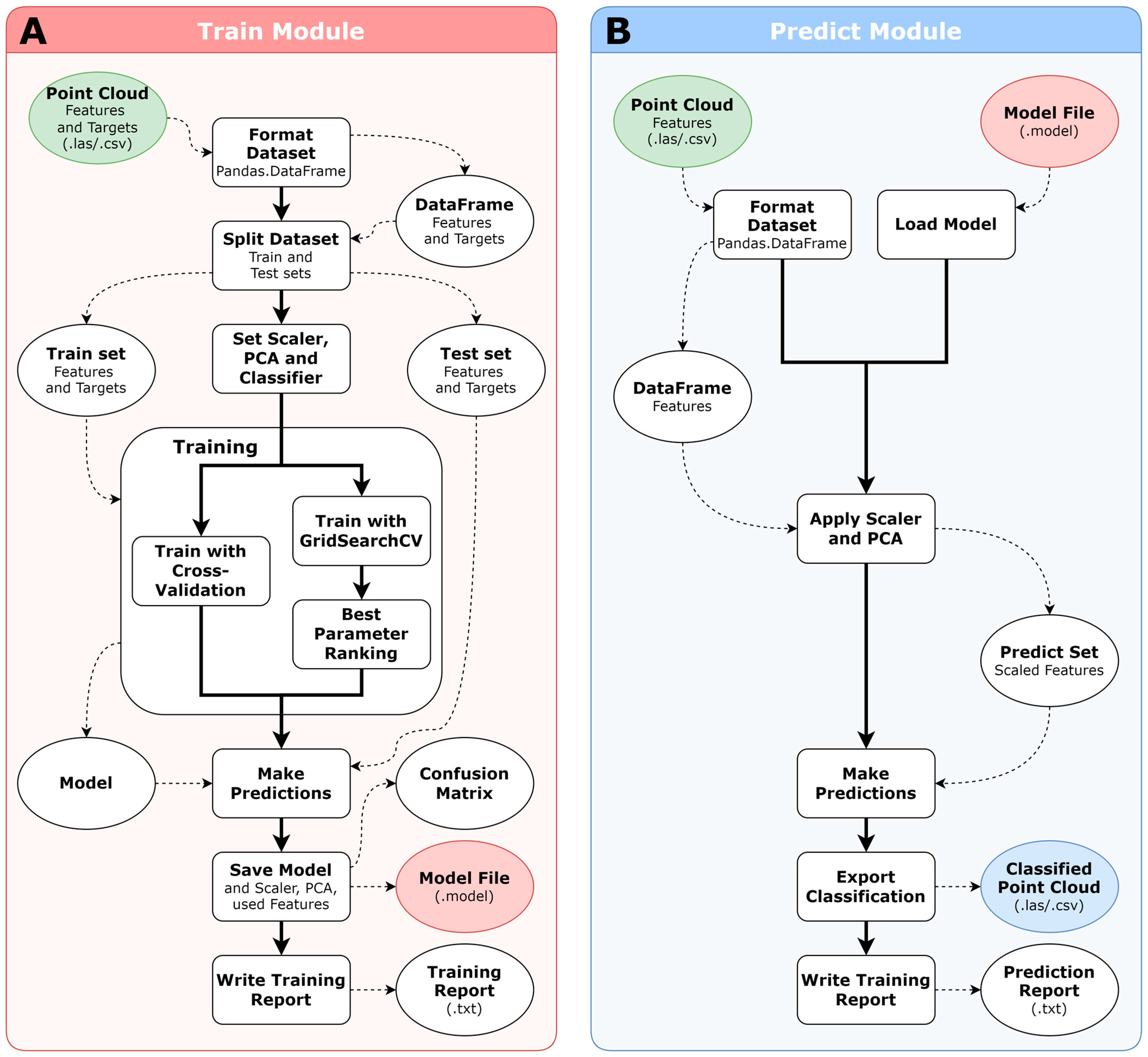
2.2.1. Training Workflow
Convert 3D Point Cloud as Pandas DataFrame
Split into Train and Test Sets
Set the Scaler, PCA and Classifier in a Pipeline
Train Model
Write Training Report
2.2.2. Prediction Workflow
Load Prediction Set and Model File
Find Features, Apply Scaler, PCA
Make Predictions and Export Classification
- A ‘Prediction’ field for the classification performed by the model;
- A ‘BestProba’ field for maximum likelihood;
- A ‘ProbaClass_X’ field for each class for the likelihood per class.
Write Prediction Report
2.3. Results of Supervised Classification
2.3.1. Confusion Matrix
Global Accuracy
Precision
Recall
F1-Score
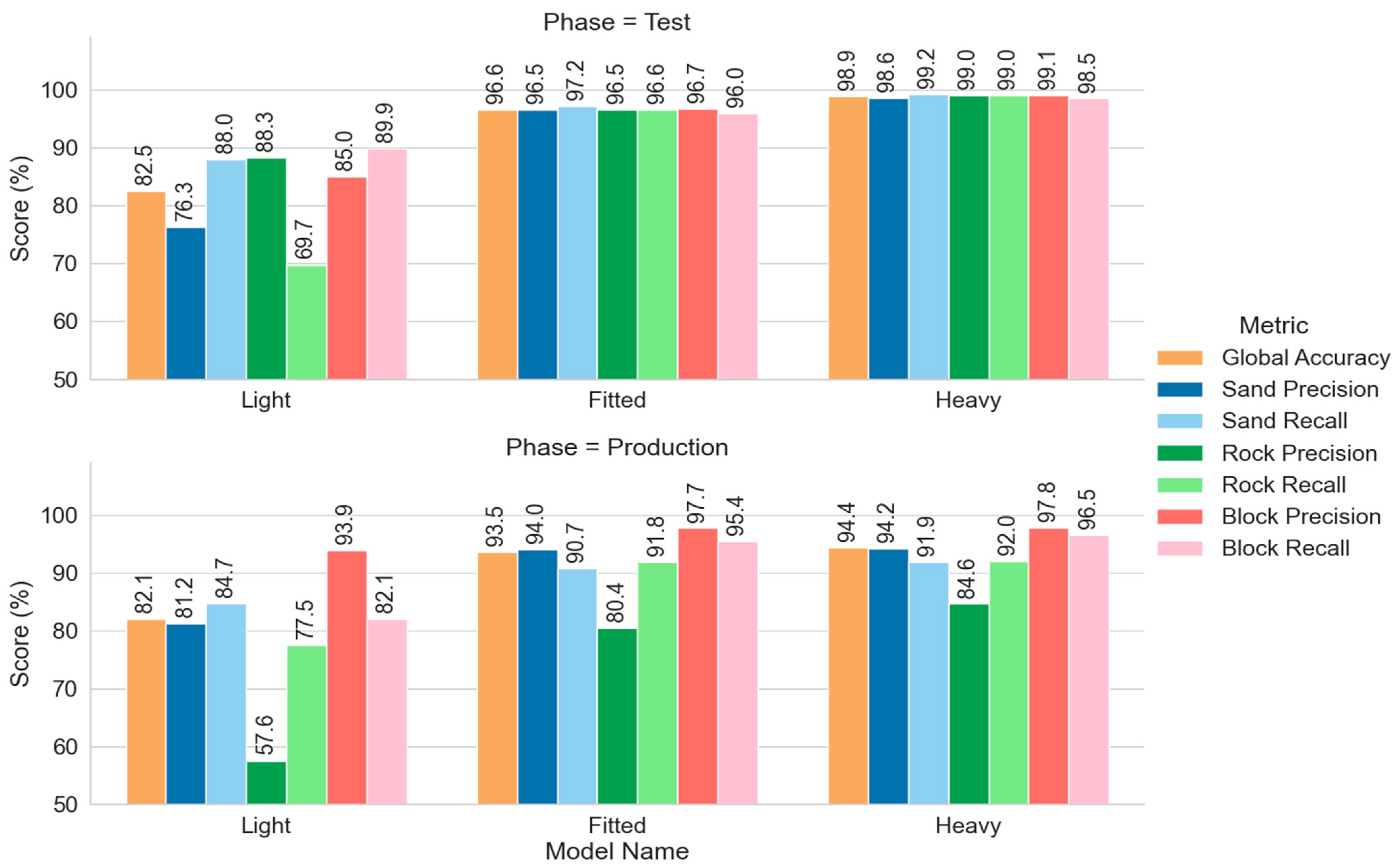
2.3.2. Generalization, Underfitting, and Overfitting
2.4. Training Set Design
2.4.1. Classification Purpose
2.4.2. Data Acquisition
Study Site
Acquisition
2.4.3. Primary Features
2.4.4. Data Discovery
2.4.5. Secondary Features
2.4.6. Class Definition
2.5. Datasets
3. Results
3.1. Algorithm Parameters and Features Selection
3.1.1. Impact of the Algorithm Parameters
3.1.2. Impact of the Features Selection
3.2. Training, Prediction, and Model Generalization
3.2.1. Simple Training and Predictions
3.2.2. Model Generalization
3.3. Cross-Date Training
3.4. Hierarchical Classification
3.5. A Classification Example with Point Cloud from ALS
4. Discussion
4.1. A Model Design Example
4.2. Classification for Point Clouds from Other Sensors
4.3. Manual vs. ML Classification
4.4. Using cLASpy_T or Not for ML Model Design
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xie, Y.; Tian, J.; Zhu, X.X. Linking Points With Labels in 3D: A Review of Point Cloud Semantic Segmentation. IEEE Geosci. Remote Sens. Mag. 2020, 8, 38–59. [Google Scholar] [CrossRef]
- Sturdivant, E.; Lentz, E.; Thieler, E.R.; Farris, A.; Weber, K.; Remsen, D.; Miner, S.; Henderson, R. UAS-SfM for Coastal Research: Geomorphic Feature Extraction and Land Cover Classification from High-Resolution Elevation and Optical Imagery. Remote Sens. 2017, 9, 1020. [Google Scholar] [CrossRef]
- Le Mauff, B.; Juigner, M.; Ba, A.; Robin, M.; Launeau, P.; Fattal, P. Coastal Monitoring Solutions of the Geomorphological Response of Beach-Dune Systems Using Multi-Temporal LiDAR Datasets (Vendé e Coast, France). Geomorphology 2018, 304, 121–140. [Google Scholar] [CrossRef]
- Pellerin Le Bas, X.; Levoy, F.; Robin, N.; Anthony, E.J. The Formation and Morphodynamics of Complex Multi-hooked Spits and the Contribution of Swash Bars. Earth Surf. Process. Landf. 2021, 47, esp.5236. [Google Scholar] [CrossRef]
- Bakula, K.; Salach, A.; Zelaya Wziatek, D.; Ostrowski, W.; Gorski, K.; Kurczynski, Z. Evaluation of the Accuracy of Lidar Data Acquired Using a UAS for Levee Monitoring: Preliminary Results. Int. J. Remote Sens. 2017, 38, 2921–2937. [Google Scholar] [CrossRef]
- Froideval, L.; Conessa, C.; Pellerin Le Bas, X.; Benoit, L.; Mouazé, D. Efficient Dike Monitoring Using Terrestrial SfM Photogrammetry. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2022, 2, 359–366. [Google Scholar] [CrossRef]
- Gonçalves, D.; Gonçalves, G.; Pérez-Alvavez, J.A.; Andriolo, U. On the 3D Reconstruction of Coastal Structures by Unmanned Aerial Systems with Onboard Global Navigation Satellite System and Real-Time Kinematics and Terrestrial Laser Scanning. Remote Sens. 2022, 14, 1485. [Google Scholar] [CrossRef]
- Westoby, M.J.; Brasington, J.; Glasser, N.F.; Hambrey, M.J.; Reynolds, J.M. ‘Structure-from-Motion’ Photogrammetry: A Low-Cost, Effective Tool for Geoscience Applications. Geomorphology 2012, 179, 300–314. [Google Scholar] [CrossRef]
- Medjkane, M.; Maquaire, O.; Costa, S.; Roulland, T.; Letortu, P.; Fauchard, C.; Antoine, R.; Davidson, R. High-Resolution Monitoring of Complex Coastal Morphology Changes: Cross-Efficiency of SfM and TLS-Based Survey (Vaches-Noires Cliffs, Normandy, France). Landslides 2018, 15, 1097–1108. [Google Scholar] [CrossRef]
- Froideval, L.; Pedoja, K.; Garestier, F.; Moulon, P.; Conessa, C.; Pellerin Le Bas, X.; Traoré, K.; Benoit, L. A Low-cost Open-source Workflow to Generate Georeferenced 3D SfM Photogrammetric Models of Rocky Outcrops. Photogram Rec. 2019, 34, phor.12297. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Y.; Wang, J. Map-Based Localization Method for Autonomous Vehicles Using 3D-LIDAR. IFAC-Pap. OnLine 2017, 50, 276–281. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Jazayeri, I.; Rajabifard, A.; Kalantari, M. A Geometric and Semantic Evaluation of 3D Data Sourcing Methods for Land and Property Information. Land Use Policy 2014, 36, 219–230. [Google Scholar] [CrossRef]
- Li, J.; Liu, J.; Huang, Q. PointDMM: A Deep-Learning-Based Semantic Segmentation Method for Point Clouds in Complex Forest Environments. Forests 2023, 14, 2276. [Google Scholar] [CrossRef]
- Mukhandi, H.; Ferreira, J.F.; Peixoto, P. SyS3DS: Systematic Sampling of Large-Scale LiDAR Point Clouds for Semantic Segmentation in Forestry Robotics. Sensors 2024, 24, 823. [Google Scholar] [CrossRef] [PubMed]
- Pellerin Le Bas, X. cLASpy_T v0.3. Available online: https://github.com/TrickyPells/cLASpy_T (accessed on 4 August 2024).
- Rabbani, T.; Heuvel, F.A.; Vosselman, G. Segmentation of Point Clouds Using Smoothness Constraint. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2006, 36, 248–253. [Google Scholar]
- Bhanu, B.; Lee, S.; Ho, C.-C.; Henderson, T.C. Range Data Processing: Representation of Surfaces by Edges. In Proceedings of the Eighth International Conference on Pattern Recognition, Paris, France, 27–31 October 1986; p. 15. [Google Scholar]
- Vo, A.-V.; Truong-Hong, L.; Laefer, D.F.; Bertolotto, M. Octree-Based Region Growing for Point Cloud Segmentation. ISPRS J. Photogramm. Remote Sens. 2015, 104, 88–100. [Google Scholar] [CrossRef]
- Xu, L.; Oja, E.; Kultanen, P. A New Curve Detection Method: Randomized Hough Transform (RHT). Pattern Recognit. Lett. 1990, 11, 331–338. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Filin, S. Surface Clustering from Airborne Laser Scanning Data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2002, 34, 119–124. [Google Scholar]
- Xu, Y.; Yao, W.; Tuttas, S.; Hoegner, L.; Stilla, U. Unsupervised Segmentation of Point Clouds From Buildings Using Hierarchical Clustering Based on Gestalt Principles. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4270–4286. [Google Scholar] [CrossRef]
- Weinmann, M.; Schmidt, A.; Mallet, C.; Hinz, S.; Rottensteiner, F.; Jutzi, B. Contextual Classification of Point Cloud Data by Exploiting Individual 3d Neigbourhoods. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2015, II-3/W4, 271–278. [Google Scholar] [CrossRef]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-View Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 922–928. [Google Scholar]
- Zhang, J.; Lin, X.; Ning, X. SVM-Based Classification of Segmented Airborne LiDAR Point Clouds in Urban Areas. Remote Sens. 2013, 5, 3749–3775. [Google Scholar] [CrossRef]
- Vosselman, G.; Coenen, M.; Rottensteiner, F. Contextual Segment-Based Classification of Airborne Laser Scanner Data. ISPRS J. Photogramm. Remote Sens. 2017, 128, 354–371. [Google Scholar] [CrossRef]
- Müller, A.C.; Guido, S. Introduction to Machine Learning with Python: A Guide for Data Scientists, 1st ed.; O’Reilly: Beijing, China; Boston, MA, USA; Farnham, UK; Sebastopol, CA, USA; Tokyo, Japan, 2016; ISBN 978-1-4493-6941-5. [Google Scholar]
- Qian, G.; Hamdi, A.; Zhang, X.; Ghanem, B. Pix4Point: Image Pretrained Standard Transformers for 3D Point Cloud Understanding. arXiv 2022, arXiv:2208.12259. [Google Scholar]
- Teruggi, S.; Grilli, E.; Russo, M.; Fassi, F.; Remondino, F. A Hierarchical Machine Learning Approach for Multi-Level and Multi-Resolution 3D Point Cloud Classification. Remote Sens. 2020, 12, 2598. [Google Scholar] [CrossRef]
- Axelsson, P. Processing of Laser Scanner Data—Algorithms and Applications. ISPRS J. Photogramm. Remote Sens. 1999, 54, 138–147. [Google Scholar] [CrossRef]
- Axelsson, P. DEM Generation from Laser Scanner Data Using Adaptive Tin Models. Int. Arch. Photogramm. Remote Sens. 2000, 33 (Part B3), 85–92. [Google Scholar]
- Arttu Soininen Terrasolid TerraScan. Available online: https://terrasolid.com (accessed on 4 August 2024).
- Sithole, G.; Vosselman, G. Experimental Comparison of Filter Algorithms for Bare-Earth Extraction from Airborne Laser Scanning Point Clouds. ISPRS J. Photogramm. Remote Sens. 2004, 59, 85–101. [Google Scholar] [CrossRef]
- Brodu, N.; Lague, D. 3D Terrestrial Lidar Data Classification of Complex Natural Scenes Using a Multi-Scale Dimensionality Criterion: Applications in Geomorphology. ISPRS J. Photogramm. Remote Sens. 2012, 68, 121–134. [Google Scholar] [CrossRef]
- Gaydon, C. Myria3D: Deep Learning for the Semantic Segmentation of Aerial Lidar Point Clouds; IGN (French Mapping Agency): Paris, France, 2022. [Google Scholar]
- Falcon, W. The PyTorch Lightning Team PyTorch Lightning 2019. Available online: https://github.com/Lightning-AI/pytorch-lightning (accessed on 4 August 2024).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API Design for Machine Learning Software: Experiences from the Scikit-Learn Project. In Proceedings of the ECML PKDD Workshop: Languages for Data Mining and Machine Learning, Prague, The Czech Republic, 23-27 September 2013; pp. 108–122. [Google Scholar]
- Froideval, L.; Conessa, C.; Laurent, B. 3D Model Time Series of a Coastal Dike in Ouistreham, France 2024, 3258744154 Bytes. Available online: https://doi.org/10.6084/m9.figshare.25908823.v1 (accessed on 4 August 2024).
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3D.Net: A New Large-Scale Point Cloud Classification Benchmark. arXiv 2017, arXiv:1704.03847. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Khalid, S.; Xiao, W.; Trigoni, N.; Markham, A. Towards Semantic Segmentation of Urban-Scale 3D Point Clouds: A Dataset, Benchmarks and Challenges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Gaydon, C.; Daab, M.; Roche, F. FRACTAL: An Ultra-Large-Scale Aerial Lidar Dataset for 3D Semantic Segmentation of Diverse Landscapes. arXiv 2024, arXiv:2405.04634. [Google Scholar]
- Gaydon, C.; Roche, F. PureForest: A Large-Scale Aerial Lidar and Aerial Imagery Dataset for Tree Species Classification in Monospecific Forests. arXiv 2024, arXiv:2404.12064. [Google Scholar]
- Artelnics OpenNN. Available online: https://github.com/Artelnics/OpenNN (accessed on 4 August 2024).
- Sonnenburg, S.; Raetsch, G.; Henschel, S.; Widmer, C.; Behr, J.; Zien, A.; de Bona, F.; Binder, A.; Gehl, C.; Franc, V. The Shogun Machine Learning Toolbox. J. Mach. Learn. Res. 2010, 11, 1799–1802. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. arXiv 2015, arXiv:1603.04467. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Allen, D.M. The Relationship Between Variable Selection and Data Agumentation and a Method for Prediction. Technometrics 1974, 16, 125–127. [Google Scholar] [CrossRef]
- Stone, M. Cross-Validatory Choice and Assessment of Statistical Predictions. J. R. Stat. Soc. Ser. B Stat. Methodol. 1974, 36, 111–133. [Google Scholar] [CrossRef]
- Breiman, L. Arcing Classifiers. Ann. Stat. 1998, 26, 801–824. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic Gradient Boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2009; ISBN 978-0-387-84857-0. [Google Scholar]
- Hinton, G.E. Connectionist Learning Procedures. Artif. Intell. 1989, 40, 185–234. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the Difficulty of Training Deep Feedforward Neural Networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Chia Laguna Resort, Sardinia, Italy, 13 May 2010; Teh, Y.W., Titterington, M., Eds.; Volume 9, pp. 249–256. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2002; ISBN 978-0-387-95442-4. [Google Scholar]
- QGIS Development Team. QGIS 3.34 Geographic Information System; QGIS Development Team: Zurich, Switzerland, 2024. [Google Scholar]
- Moulon, P.; Monasse, P.; Perrot, R.; Marlet, R. OpenMVG: Open Multiple View Geometry. In Reproducible Research in Pattern Recognition: First International Workshop, Proceedings of the Reproducible Research in Pattern Recognition, Cancún, Mexico, 4 December 2016; Kerautret, B., Colom, M., Monasse, P., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 60–74. [Google Scholar]
- Cernea, D. OpenMVS v2.3.0: Multi-View Stereo Reconstruction Library. Available online: https://github.com/cdcseacave/openMVS (accessed on 4 August 2024).
- Bisnath, S.; Uijt de Haag, M.; Diggle, D.W.; Hegarty, C.; Milbert, D.; Walter, T. Differential GNSS and Precise Point Positioning. In Understanding GPS/GNSS: Principles and Applications; GNSS Technology and Applications Series; Artech House: Boston, MA, USA; London, UK, 2017; pp. 709–788. ISBN 978-1-63081-058-0. [Google Scholar]
- Girardeau-Montaut, D. CloudCompare (Version 2.13.1) [GPL Software]; 2024. Available online: https://www.danielgm.net/cc/ (accessed on 4 August 2024).
- Cignoni, P.; Callieri, M.; Corsini, M.; Dellepiane, M.; Ganovelli, F.; Ranzuglia, G. MeshLab: An Open-Source Mesh Processing Tool. In Proceedings of the European Interdisciplinary Cybersecurity Conference, Edinburgh, UK, 25–28 May 2008. [Google Scholar]
- Lloyd, S. Least Squares Quantization in PCM. IEEE Trans. Inform. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 1 January 1967; Volume 1, pp. 281–297. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the KDD, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Hackel, T.; Wegner, J.D.; Schindler, K. Contour Detection in Unstructured 3D Point Clouds. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1610–1618. [Google Scholar]
- Froideval, L.; Monfort, O.; Benoit, L.; Bonte, Y. Mesure Topographique par LiDAR Aéroporté et Modèle Numérique Terrain de l’estuaire de l’Orne du 03/06/2015. Available online: https://sextant.ifremer.fr/record/93c7ba76-9a65-4144-8802-acb86343cc47 (accessed on 4 August 2024).
- Froideval, L.; Pellerin Le Bas, X.; Conessa, C.; Laurent, B. ALS Orne Estuary ML Labeled Data 2024, 6597898321 Bytes. Available online: https://doi.org/10.6084/m9.figshare.26346709.v1 (accessed on 4 August 2024).
- Tipping, M.E.; Bishop, C.M. Mixtures of Probabilistic Principal Component Analyzers. Neural Comput. 1999, 11, 443–482. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Class | Recall | ||||
|---|---|---|---|---|---|
| Sand | Rock | Block | |||
| Expected class | Sand | 3000 | 150 | 100 | 92.3% |
| Rock | 110 | 1500 | 25 | 91.7% | |
| Block | 45 | 160 | 5000 | 96.1% | |
| Precision | 95.1% | 82.9% | 97.6% | 94.2% | |
| Date | Camera | Focal (mm) | Aperture | Number of Photos | Number of Points (Mpts) | Referencing (cm) | |
|---|---|---|---|---|---|---|---|
| Absolute | Relative | ||||||
| April | Canon EOS 80D | 18 | F/11 to F/9 | 557 | 391 | 1.8 | - |
| May | 18 | F/22 | 561 | 372 | - | 0.7 | |
| June | 18 | F/18 to F/16 | 646 | 471 | - | 0.9 | |
| November | Sony A6000 | 16 | F/8 to F/5.6 | 722 | 431 | - | 0.8 |
| Name | Scikit-Learn Algorithm | Parameter 1 | Parameter 2 | Parameter 3 |
|---|---|---|---|---|
| RF | RandomForest Classifier | n_estimators 20 | max_depth 12 | min_samples_split 200 |
| GB | GradientBoosting Classifier | n_estimators 50 | max_depth 5 | min_samples_split 200 |
| MLP | MLP Classifer | hidden_layer_sizes [10, 5] | activation Tanh | max_iter 1000 |
| RF Predicted | RF Recall | GB Predicted | GB Recall | MLP Predicted | MLP Recall | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sand | Rock | Block | Sand | Rock | Block | Sand | Rock | Block | |||||
| Expected | Sand | 2,650,977 | 166,696 | 103,761 | 90.7% | 2,635,103 | 191,368 | 94,963 | 90.2% | 2,685,161 | 159,066 | 77,207 | 91.9% |
| Rock | 112,400 | 1,484,641 | 19,662 | 91.8% | 90,112 | 1,509,196 | 17,395 | 93.4% | 97,592 | 1,468,478 | 50,633 | 90.8% | |
| Block | 56,643 | 194,923 | 5,210,297 | 95.4% | 52,846 | 155,879 | 5,253,138 | 96.2% | 91,505 | 237,244 | 5,133,114 | 94.0% | |
| Precision | 94.0% | 80.4% | 97.7% | 93.5% | 94.9% | 81.3% | 97.9% | 94.0% | 93.4% | 78.7% | 97.6% | 92.9% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pellerin Le Bas, X.; Froideval, L.; Mouko, A.; Conessa, C.; Benoit, L.; Perez, L. A New Open-Source Software to Help Design Models for Automatic 3D Point Cloud Classification in Coastal Studies. Remote Sens. 2024, 16, 2891. https://doi.org/10.3390/rs16162891
Pellerin Le Bas X, Froideval L, Mouko A, Conessa C, Benoit L, Perez L. A New Open-Source Software to Help Design Models for Automatic 3D Point Cloud Classification in Coastal Studies. Remote Sensing. 2024; 16(16):2891. https://doi.org/10.3390/rs16162891
Chicago/Turabian StylePellerin Le Bas, Xavier, Laurent Froideval, Adan Mouko, Christophe Conessa, Laurent Benoit, and Laurent Perez. 2024. "A New Open-Source Software to Help Design Models for Automatic 3D Point Cloud Classification in Coastal Studies" Remote Sensing 16, no. 16: 2891. https://doi.org/10.3390/rs16162891
APA StylePellerin Le Bas, X., Froideval, L., Mouko, A., Conessa, C., Benoit, L., & Perez, L. (2024). A New Open-Source Software to Help Design Models for Automatic 3D Point Cloud Classification in Coastal Studies. Remote Sensing, 16(16), 2891. https://doi.org/10.3390/rs16162891