
Enhanced Window-Based Self-Attention with Global and Multi-Scale Representations for Remote Sensing Image Super-Resolution



Abstract
:1. Introduction
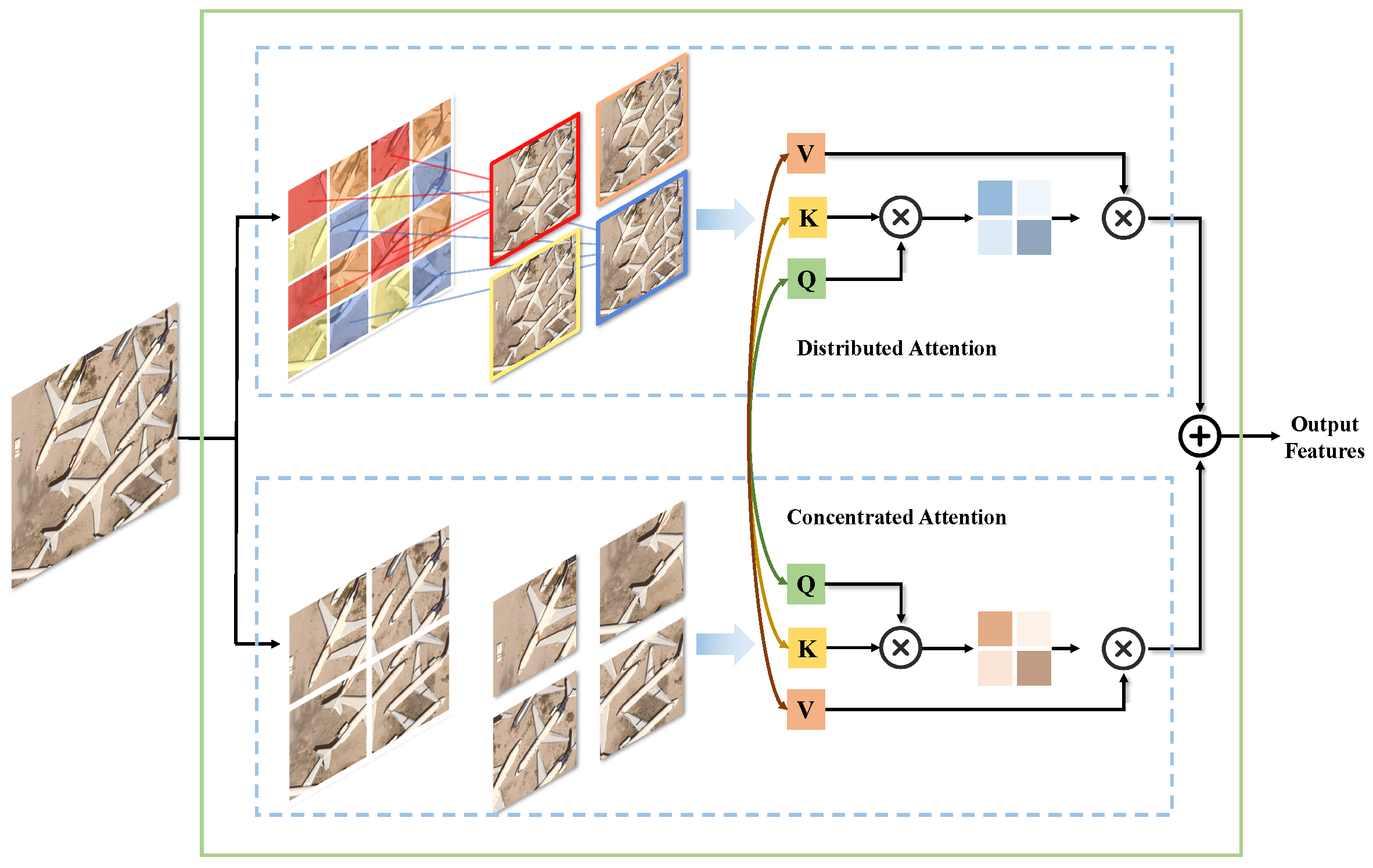
- We present a novel Dual Window-based Self-Attention (DWSA) module, comprising distributed global attention and concentrated local attention, for remote sensing image super-resolution. This innovative approach enables the utilization of a global receptive field while maintaining linear complexity.
- We introduce the Multi-scale Depth-wise Convolution Attention (MDCA) module, which is particularly crucial in addressing the limitation posed by the fixed window size of the transformer, achieved through a multi-branch convolution strategy to enhance model performance.
- We have developed a new Tracing-Back Structure (TBS) to comprehensively enhance the feature representation capabilities of the proposed MDCA and DWSA modules. Accordingly, we introduce the Multi-Scale and Global Representation Enhancement-based Transformer (MSGFormer). The evaluation of various public remote sensing datasets demonstrates that MSGFormer attains state-of-the-art performance.
2. Related Works
2.1. CNN-Based SR
2.2. Transformer-Based SR
2.3. Hybrid CNN–Transformer Structure
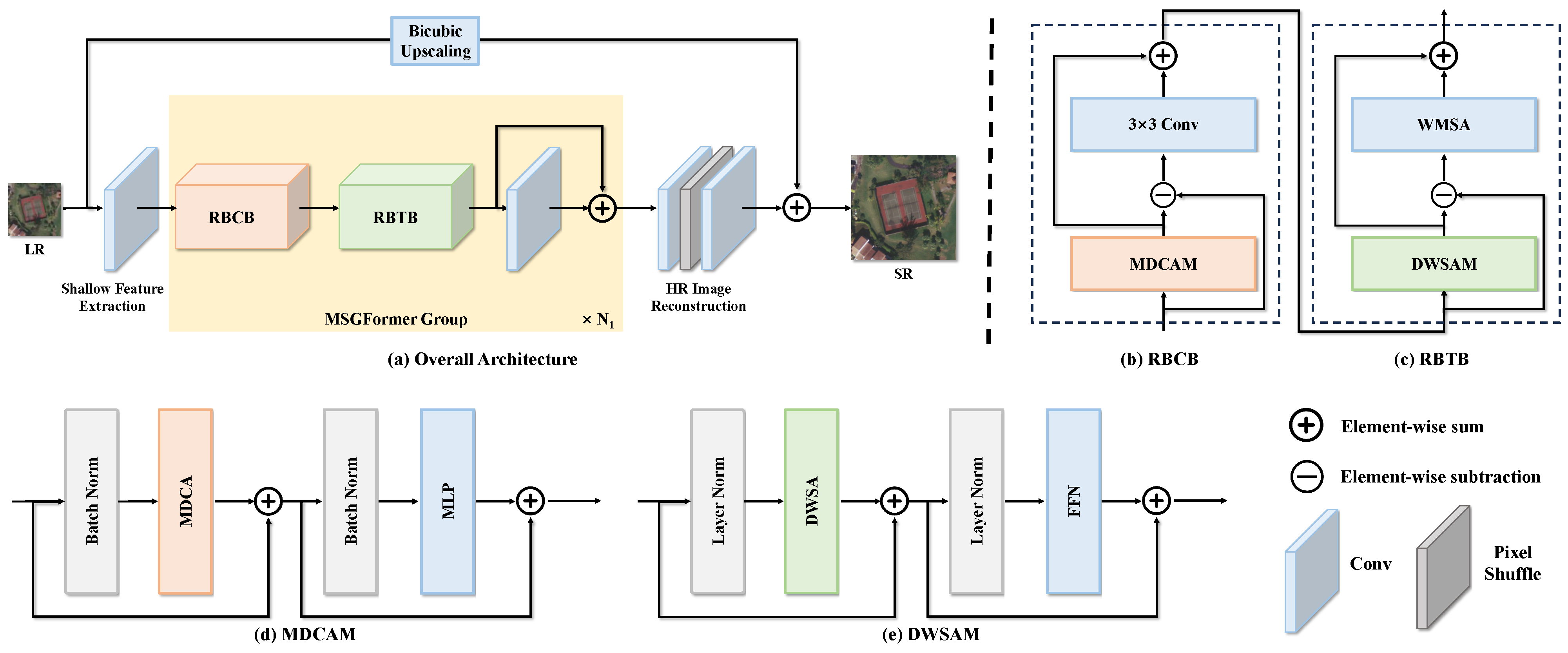
3. Methods
3.1. Overview of MSGFormer
3.2. Dual Window-Based Self-Attention
3.2.1. Concentrated Attention
3.2.2. Distributed Attention
3.3. Multi-Scale Depth-Wise Convolution Attention
3.4. Tracing-Back Structure
4. Results
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Metrics
4.1.3. Implementation Details
4.1.4. Hyperparameter Details
4.2. Quantitative and Qualitative Comparisons
4.2.1. Quantitative Results
4.2.2. Qualitative Results
4.3. Ablation Studies
4.3.1. Effect of DWSA
4.3.2. Effect of MDCA
4.3.3. Effect of TBS
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hong, D.; Zhang, B.; Li, X.; Li, Y.; Li, C.; Yao, J.; Yokoya, N.; Li, H.; Ghamisi, P.; Jia, X.; et al. SpectralGPT: Spectral remote sensing foundation model. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5227–5244. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Zhang, B.; Lu, J.; Yan, H. Towards Integrity and Detail with Ensemble Learning for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5606813. [Google Scholar] [CrossRef]
- Sambandham, V.T.; Kirchheim, K.; Ortmeier, F.; Mukhopadhaya, S. Deep learning-based harmonization and super-resolution of Landsat-8 and Sentinel-2 images. ISPRS J. Photogramm. Remote Sens. 2024, 212, 274–288. [Google Scholar] [CrossRef]
- Wang, Y.; Yuan, W.; Xie, F.; Lin, B. ESatSR: Enhancing Super-Resolution for Satellite Remote Sensing Images with State Space Model and Spatial Context. Remote Sens. 2024, 16, 1956. [Google Scholar] [CrossRef]
- Wu, J.; Xia, L.; Chan, T.O.; Awange, J.; Yuan, P.; Zhong, B.; Li, Q. A novel fusion framework embedded with zero-shot super-resolution and multivariate autoregression for precipitable water vapor across the continental Europe. Remote Sens. Environ. 2023, 297, 113783. [Google Scholar] [CrossRef]
- Wang, J.; Lu, Y.; Wang, S.; Wang, B.; Wang, X.; Long, T. Two-stage Spatial-Frequency Joint Learning for Large-Factor Remote Sensing Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5606813. [Google Scholar] [CrossRef]
- Zheng, Q.; Tian, X.; Yu, Z.; Ding, Y.; Elhanashi, A.; Saponara, S.; Kpalma, K. MobileRaT: A Lightweight Radio Transformer Method for Automatic Modulation Classification in Drone Communication Systems. Drones 2023, 7, 596. [Google Scholar] [CrossRef]
- Zhao, Y.; Yin, Y.; Gui, G. Lightweight deep learning based intelligent edge surveillance techniques. IEEE Trans. Cogn. Commun. 2020, 6, 1146–1154. [Google Scholar] [CrossRef]
- Zheng, Q.; Tian, X.; Yang, M.; Wu, Y.; Su, H. PAC-Bayesian framework based drop-path method for 2D discriminative convolutional network pruning. Multidimens. Syst. Signal Process. 2020, 31, 793–827. [Google Scholar] [CrossRef]
- Maeda, S. Image super-resolution with deep dictionary. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 464–480. [Google Scholar]
- Ran, R.; Deng, L.J.; Jiang, T.X.; Hu, J.F.; Chanussot, J.; Vivone, G. GuidedNet: A general CNN fusion framework via high-resolution guidance for hyperspectral image super-resolution. IEEE Trans. Cybern. 2023, 53, 4148–4161. [Google Scholar] [CrossRef]
- Wang, J.; Wang, B.; Wang, X.; Zhao, Y.; Long, T. Hybrid attention based u-shaped network for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5612515. [Google Scholar] [CrossRef]
- Hu, W.; Ju, L.; Du, Y.; Li, Y. A Super-Resolution Reconstruction Model for Remote Sensing Image Based on Generative Adversarial Networks. Remote Sens. 2024, 16, 1460. [Google Scholar] [CrossRef]
- Yao, S.; Cheng, Y.; Yang, F.; Mozerov, M.G. A continuous digital elevation representation model for DEM super-resolution. ISPRS J. Photogramm. Remote Sens. 2024, 208, 1–13. [Google Scholar] [CrossRef]
- Mardieva, S.; Ahmad, S.; Umirzakova, S.; Rasool, M.A.; Whangbo, T.K. Lightweight image super-resolution for IoT devices using deep residual feature distillation network. Knowl.-Based Syst. 2024, 285, 111343. [Google Scholar] [CrossRef]
- Gu, J.; Dong, C. Interpreting super-resolution networks with local attribution maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 9199–9208. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Dong, C. Activating more pixels in image super-resolution transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 22367–22377. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Ding, M.; Xiao, B.; Codella, N.; Luo, P.; Wang, J.; Yuan, L. Davit: Dual attention vision transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 74–92. [Google Scholar]
- Chen, Q.; Wu, Q.; Wang, J.; Hu, Q.; Hu, T.; Ding, E.; Cheng, J.; Wang, J. Mixformer: Mixing features across windows and dimensions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5249–5259. [Google Scholar]
- Lei, S.; Shi, Z.; Mo, W. Transformer-based multistage enhancement for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5615611. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Chen, Z.; Zhang, Y.; Gu, J.; Zhang, Y.; Kong, L.; Yuan, X. Cross Aggregation Transformer for Image Restoration. In Proceedings of the Advances in neural information processing systems, New Orleans, CA, USA, 28 November–9 December 2022; pp. 25478–25490. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Lu, Z.; Li, J.; Liu, H.; Huang, C.; Zhang, L.; Zeng, T. Transformer for Single Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 457–466. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 1833–1844. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Wang, H.; Chen, X.; Ni, B.; Liu, Y.; Liu, J. Omni Aggregation Networks for Lightweight Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 22378–22387. [Google Scholar]
- Choi, H.; Lee, J.; Yang, J. N-gram in swin transformers for efficient lightweight image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 2071–2081. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 391–407. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Lei, S.; Shi, Z.; Zou, Z. Super-resolution for remote sensing images via local–global combined network. IEEE Trans. Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Haut, J.M.; Paoletti, M.E.; Fernández-Beltran, R.; Plaza, J.; Plaza, A.; Li, J. Remote sensing single-image superresolution based on a deep compendium model. IEEE Trans. Geosci. Remote Sens. Lett. 2019, 16, 1432–1436. [Google Scholar] [CrossRef]
- Dong, X.; Wang, L.; Sun, X.; Jia, X.; Gao, L.; Zhang, B. Remote sensing image super-resolution using second-order multi-scale networks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3473–3485. [Google Scholar] [CrossRef]
- Zhang, D.; Shao, J.; Li, X.; Shen, H.T. Remote sensing image super-resolution via mixed high-order attention network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5183–5196. [Google Scholar] [CrossRef]
- Wang, Z.; Li, L.; Xue, Y.; Jiang, C.; Wang, J.; Sun, K.; Ma, H. FeNet: Feature enhancement network for lightweight remote-sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5622112. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Washington, DC, USA, 11–15 November 2017; Volume 30.
- Li, K.; Wang, Y.; Zhang, J.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. Uniformer: Unifying convolution and self-attention for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12581–12600. [Google Scholar] [CrossRef] [PubMed]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Hassani, A.; Walton, S.; Li, J.; Li, S.; Shi, H. Neighborhood attention transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 6185–6194. [Google Scholar]
- Zhou, L.; Gong, C.; Liu, Z.; Fu, K. SAL: Selection and attention losses for weakly supervised semantic segmentation. IEEE Trans. Multimed. 2020, 23, 1035–1048. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, J.; Willette, J.; Hwang, S.J. Mpvit: Multi-path vision transformer for dense prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 7287–7296. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 200. [Google Scholar] [CrossRef]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5791–5800. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12175–12185. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16519–16529. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Maaz, M.; Shaker, A.; Cholakkal, H.; Khan, S.; Zamir, S.W.; Anwer, R.M.; Shahbaz Khan, F. Edgenext: Efficiently amalgamated cnn-transformer architecture for mobile vision applications. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 3–20. [Google Scholar]
- Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Dong, X.; Yuan, L.; Liu, Z. Mobile-former: Bridging mobilenet and transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5270–5279. [Google Scholar]
- Li, Y.; Yuan, G.; Wen, Y.; Hu, J.; Evangelidis, G.; Tulyakov, S.; Wang, Y.; Ren, J. Efficientformer: Vision transformers at mobilenet speed. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, CA, USA, 28 November–9 December 2022; pp. 12934–12949. [Google Scholar]
- Fang, J.; Lin, H.; Chen, X.; Zeng, K. A hybrid network of cnn and transformer for lightweight image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1103–1112. [Google Scholar]
- Gao, G.; Xu, Z.; Li, J.; Yang, J.; Zeng, T.; Qi, G.J. Ctcnet: A cnn-transformer cooperation network for face image super-resolution. IEEE Trans. Image Process. 2023, 32, 1978–1991. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, Y.; Gu, J.; Kong, L.; Yang, X.; Yu, F. Dual Aggregation Transformer for Image Super-Resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 12312–12321. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Liu, J.; Chen, C.; Tang, J.; Wu, G. From coarse to fine: Hierarchical pixel integration for lightweight image super-resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 1666–1674. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Liu, Z.N.; Cheng, M.M.; Hu, S.M. Visual attention network. Comput. Vis. Media 2023, 9, 733–752. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Park, N.; Kim, S. How do vision transformers work? arXiv 2022, arXiv:2202.06709. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z. Hybrid-scale self-similarity exploitation for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5401410. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Civco, D.L.; Silander, J.A. A wavelet transform method to merge Landsat TM and SPOT panchromatic data. Int. J. Remote Sens. 1998, 19, 743–757. [Google Scholar] [CrossRef]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the Third Annual JPL Airborne Geoscience Workshop, Pasadena, CA, USA, 1–5 June 1992; Volume 1. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Scale | UCMerced | RSSCN7 | AID | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | SCC | SAM | PSNR | SSIM | SCC | SAM | PSNR | SSIM | SCC | SAM | |||||
| VDSR [35] | ×2 | 33.87 | 0.9280 | 0.6196 | 0.0519 | 30.04 | 0.8027 | 0.2967 | 0.1018 | 35.11 | 0.9340 | 0.6181 | 0.0544 | |||
| DCM [38] | ×2 | 33.65 | 0.9274 | 0.6291 | 0.0507 | 30.03 | 0.8024 | 0.2979 | 0.1019 | 35.35 | 0.9366 | 0.6407 | 0.0531 | |||
| MHAN [40] | ×2 | 33.92 | 0.9283 | 0.6242 | 0.0518 | 30.06 | 0.8036 | 0.2996 | 0.1016 | 35.56 | 0.9390 | 0.6641 | 0.0520 | |||
| HSENet [68] | ×2 | 34.22 | 0.9327 | 0.6341 | 0.0500 | 30.15 | 0.8070 | 0.3056 | 0.1006 | 35.50 | 0.9383 | 0.6626 | 0.0524 | |||
| TransENet [23] | ×2 | 34.05 | 0.9294 | 0.6275 | 0.0511 | 30.08 | 0.8040 | 0.2984 | 0.1013 | 35.40 | 0.9372 | 0.6538 | 0.0530 | |||
| SRDD [10] | ×2 | 34.12 | 0.9303 | 0.6331 | 0.0507 | 30.05 | 0.8051 | 0.2993 | 0.1014 | 35.33 | 0.9367 | 0.6373 | 0.0531 | |||
| FENet [41] | ×2 | 33.95 | 0.9284 | 0.6243 | 0.0518 | 30.05 | 0.8033 | 0.2991 | 0.1016 | 35.33 | 0.9364 | 0.6390 | 0.0533 | |||
| OmniSR [30] | ×2 | 34.16 | 0.9303 | 0.6326 | 0.0506 | 30.11 | 0.8052 | 0.3023 | 0.1010 | 35.50 | 0.9383 | 0.6523 | 0.0522 | |||
| MSGFormer (Ours) | ×2 | 34.77 | 0.9361 | 0.6560 | 0.0471 | 30.30 | 0.8112 | 0.3189 | 0.0993 | 35.78 | 0.9411 | 0.6764 | 0.0508 | |||
| VDSR [35] | ×3 | 29.75 | 0.8346 | 0.3941 | 0.0829 | 27.94 | 0.7010 | 0.1495 | 0.1303 | 31.17 | 0.8511 | 0.3800 | 0.0836 | |||
| DCM [38] | ×3 | 29.86 | 0.8393 | 0.4025 | 0.0820 | 27.96 | 0.7027 | 0.1524 | 0.1301 | 31.31 | 0.8561 | 0.3946 | 0.0822 | |||
| MHAN [40] | ×3 | 29.94 | 0.8391 | 0.4304 | 0.0816 | 28.00 | 0.7045 | 0.1551 | 0.1296 | 31.55 | 0.8603 | 0.4098 | 0.0801 | |||
| HSENet [68] | ×3 | 30.04 | 0.8433 | 0.4131 | 0.0806 | 28.02 | 0.7067 | 0.1572 | 0.1292 | 31.49 | 0.8588 | 0.4053 | 0.0806 | |||
| TransENet [23] | ×3 | 29.90 | 0.8397 | 0.3988 | 0.0816 | 28.02 | 0.7054 | 0.1532 | 0.1292 | 31.50 | 0.8588 | 0.4067 | 0.0806 | |||
| SRDD [10] | ×3 | 29.92 | 0.8411 | 0.4084 | 0.0815 | 27.96 | 0.7052 | 0.1552 | 0.1300 | 31.38 | 0.8564 | 0.3984 | 0.0817 | |||
| FENet [41] | ×3 | 29.80 | 0.8379 | 0.3941 | 0.0826 | 27.97 | 0.7031 | 0.1524 | 0.1300 | 31.33 | 0.8550 | 0.3955 | 0.0823 | |||
| OmniSR [30] | ×3 | 29.99 | 0.8403 | 0.4073 | 0.0810 | 28.04 | 0.7061 | 0.1584 | 0.1290 | 31.53 | 0.8596 | 0.4081 | 0.0803 | |||
| MSGFormer (Ours) | ×3 | 30.49 | 0.8506 | 0.4370 | 0.0770 | 28.20 | 0.7142 | 0.1696 | 0.1267 | 31.75 | 0.8646 | 0.4208 | 0.0783 | |||
| VDSR [35] | ×4 | 27.54 | 0.7522 | 0.2589 | 0.1055 | 26.75 | 0.6336 | 0.0825 | 0.1495 | 28.99 | 0.7753 | 0.2427 | 0.1055 | |||
| DCM [38] | ×4 | 27.60 | 0.7556 | 0.2610 | 0.1051 | 26.79 | 0.6363 | 0.0867 | 0.1490 | 29.20 | 0.7826 | 0.2679 | 0.1032 | |||
| MHAN [40] | ×4 | 27.63 | 0.7581 | 0.2649 | 0.1043 | 26.79 | 0.6360 | 0.0850 | 0.1491 | 29.39 | 0.7892 | 0.2825 | 0.1008 | |||
| HSENet [68] | ×4 | 27.75 | 0.7611 | 0.2692 | 0.1034 | 26.82 | 0.6378 | 0.0867 | 0.1485 | 29.32 | 0.7867 | 0.2765 | 0.1017 | |||
| TransENet [23] | ×4 | 27.78 | 0.7635 | 0.2701 | 0.1029 | 26.81 | 0.6373 | 0.0845 | 0.1485 | 29.44 | 0.7912 | 0.2884 | 0.1002 | |||
| SRDD [10] | ×4 | 27.67 | 0.7609 | 0.2718 | 0.1047 | 26.74 | 0.6364 | 0.0842 | 0.1495 | 29.21 | 0.7835 | 0.2695 | 0.1030 | |||
| FENet [41] | ×4 | 27.59 | 0.7538 | 0.2568 | 0.1053 | 26.80 | 0.6367 | 0.0871 | 0.1487 | 29.16 | 0.7812 | 0.2651 | 0.1037 | |||
| OmniSR [30] | ×4 | 27.80 | 0.7637 | 0.2779 | 0.1027 | 26.85 | 0.6388 | 0.0898 | 0.1480 | 29.19 | 0.7829 | 0.2636 | 0.1033 | |||
| MSGFormer (Ours) | ×4 | 28.16 | 0.7763 | 0.3029 | 0.0988 | 26.96 | 0.6447 | 0.0957 | 0.1467 | 29.59 | 0.7960 | 0.3024 | 0.0987 | |||
| Class Name | MHAN | HSENet | TransENet | SRDD | MSGFormer (Ours) |
|---|---|---|---|---|---|
| airport | 29.20 | 29.12 | 29.26 | 29.05 | 29.39 |
| bare land | 36.36 | 36.34 | 36.38 | 36.34 | 36.50 |
| baseball field | 31.57 | 31.49 | 31.63 | 31.62 | 31.95 |
| beach | 32.62 | 32.60 | 32.66 | 32.62 | 32.80 |
| bridge | 31.65 | 31.55 | 31.70 | 31.54 | 31.93 |
| center | 28.03 | 27.91 | 28.09 | 27.84 | 28.27 |
| church | 24.50 | 24.43 | 24.53 | 24.36 | 24.65 |
| commercial | 27.96 | 27.90 | 28.00 | 27.86 | 28.12 |
| dense residential | 25.08 | 25.02 | 25.17 | 24.92 | 25.26 |
| desert | 39.50 | 39.47 | 39.55 | 39.40 | 39.60 |
| farmland | 34.65 | 34.59 | 34.67 | 34.58 | 34.84 |
| forest | 28.52 | 28.54 | 28.59 | 28.49 | 28.62 |
| industrial | 27.18 | 27.09 | 27.24 | 26.99 | 27.38 |
| meadow | 33.00 | 32.97 | 33.00 | 33.05 | 33.16 |
| medium residential | 28.48 | 28.41 | 28.50 | 28.29 | 28.60 |
| mountain | 29.24 | 29.22 | 29.30 | 29.23 | 29.34 |
| park | 27.97 | 27.93 | 28.04 | 27.96 | 28.20 |
| parking | 26.35 | 26.16 | 26.49 | 25.86 | 26.72 |
| playground | 30.34 | 30.19 | 30.38 | 30.21 | 30.75 |
| pond | 30.53 | 30.48 | 30.58 | 30.69 | 30.89 |
| port | 26.90 | 26.80 | 26.95 | 26.66 | 27.05 |
| railway station | 28.59 | 28.52 | 28.64 | 28.42 | 28.80 |
| resort | 28.07 | 28.00 | 28.13 | 27.86 | 28.17 |
| river | 31.00 | 30.97 | 31.04 | 30.99 | 31.13 |
| school | 27.18 | 27.10 | 27.25 | 27.04 | 27.40 |
| sparse residential | 26.62 | 26.60 | 26.63 | 26.55 | 26.69 |
| square | 29.38 | 29.30 | 29.46 | 29.23 | 29.63 |
| stadium | 27.40 | 27.28 | 27.48 | 27.16 | 27.62 |
| storage tanks | 26.20 | 26.12 | 26.22 | 26.03 | 26.31 |
| viaduct | 28.19 | 28.09 | 28.24 | 28.06 | 28.42 |
| avg | 29.39 | 29.32 | 29.44 | 29.28 | 29.59 |
| Method | Params | FLOPs | PSNR |
|---|---|---|---|
| VDSR [35] | 671 K | 241.87 G | 28.99 dB |
| DCM [38] | 2175 K | 71.40 G | 29.20 dB |
| MHAN [40] | 11,351 K | 278.09 G | 29.39 dB |
| HSENet [68] | 5430 K | 105.49 G | 29.32 dB |
| TransENet [23] | 37,460 K | 108.52 G | 29.44 dB |
| SRDD [10] | 9337 K | 32.73 G | 29.21 dB |
| FENet [41] | 351 K | 7.54 G | 29.16 dB |
| OmniSR [30] | 793 K | 17.77 G | 29.19 dB |
| MSGFormer (Ours) | 2144 K | 61.91 G | 29.59 dB |
| MDCA | DWSA | TBS | Params | FLOPs | PSNR | SSIM |
|---|---|---|---|---|---|---|
| ✓ | ✓ | 1.34 M | 9.04 G | 28.104 dB | 0.7737 | |
| ✓ | ✓ | 2.08 M | 11.33 G | 28.092 dB | 0.7743 | |
| ✓ | ✓ | 1.38 M | 8.32 G | 28.128 dB | 0.7751 | |
| ✓ | ✓ | ✓ | 2.14 M | 12.33 G | 28.155 dB | 0.7763 |
| Window Size | FLOPs | PSNR | SSIM | SCC | SAM |
|---|---|---|---|---|---|
| 4 | 12.22 G | 28.034 dB | 0.7737 | 0.2968 | 0.1001 |
| 8 | 12.25 G | 28.079 dB | 0.7743 | 0.2990 | 0.0996 |
| 16 | 12.33 G | 28.155 dB | 0.7763 | 0.3029 | 0.0988 |
| 5 × 5 | 7 × 7 | 11 × 11 | Params | FLOPs | PSNR | SSIM |
|---|---|---|---|---|---|---|
| ✓ | ✓ | 2.13 M | 12.26 G | 28.150 dB | 0.7762 | |
| ✓ | ✓ | 2.11 M | 12.20 G | 28.131 dB | 0.7754 | |
| ✓ | ✓ | 2.07 M | 12.01 G | 28.140 dB | 0.7760 | |
| ✓ | ✓ | ✓ | 2.14 M | 12.33 G | 28.155 dB | 0.7763 |
| TBS-MDCA | TBS-DWSA | PSNR | SSIM | SCC | SAM |
|---|---|---|---|---|---|
| ✓ | 28.082 dB | 0.7738 | 0.2978 | 0.0995 | |
| ✓ | 28.062 dB | 0.7728 | 0.2975 | 0.0995 | |
| ✓ | ✓ | 28.155 dB | 0.7763 | 0.3029 | 0.0988 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Y.; Wang, S.; Wang, B.; Zhang, X.; Wang, X.; Zhao, Y. Enhanced Window-Based Self-Attention with Global and Multi-Scale Representations for Remote Sensing Image Super-Resolution. Remote Sens. 2024, 16, 2837. https://doi.org/10.3390/rs16152837
Lu Y, Wang S, Wang B, Zhang X, Wang X, Zhao Y. Enhanced Window-Based Self-Attention with Global and Multi-Scale Representations for Remote Sensing Image Super-Resolution. Remote Sensing. 2024; 16(15):2837. https://doi.org/10.3390/rs16152837
Chicago/Turabian StyleLu, Yuting, Shunzhou Wang, Binglu Wang, Xin Zhang, Xiaoxu Wang, and Yongqiang Zhao. 2024. "Enhanced Window-Based Self-Attention with Global and Multi-Scale Representations for Remote Sensing Image Super-Resolution" Remote Sensing 16, no. 15: 2837. https://doi.org/10.3390/rs16152837
APA StyleLu, Y., Wang, S., Wang, B., Zhang, X., Wang, X., & Zhao, Y. (2024). Enhanced Window-Based Self-Attention with Global and Multi-Scale Representations for Remote Sensing Image Super-Resolution. Remote Sensing, 16(15), 2837. https://doi.org/10.3390/rs16152837