

Spatial Information Enhancement with Multi-Scale Feature Aggregation for Long-Range Object and Small Reflective Area Object Detection from Point Cloud

Abstract
1. Introduction
- A Foreground Voxel Proposal (FVP) module was designed to enhance point cloud density by proposing voxels at the foreground of sparse objects, thereby circumventing the bias that arises from an imbalanced point density. It improved the network’s detection capabilities of distant objects.
- We present a Multi-scale Feature Integration Network (MsFIN) based on the cascading attention framework, which progressively incorporates contextual information at larger scales, supplementing the objects with surrounding voxel features. It improved the network’s detection capabilities of small-reflective-area objects.
- We combine the FVP module with MsFIN and propose the Multi-scale Foreground Voxel Proposal (Ms-FVP) network, which balances the detection of long-range objects with that of small-reflective-area objects. We compare a variety of other models and demonstrate the effectiveness of our algorithm.
2. Related Work
2.1. 3D Object Detection on Point Clouds
2.2. Non-Uniform Density Point Cloud in 3D Detection
2.3. Small-Reflective-Area Object Detection in Point Cloud
2.4. Transformer-Based Network on Point Clouds
3. Method
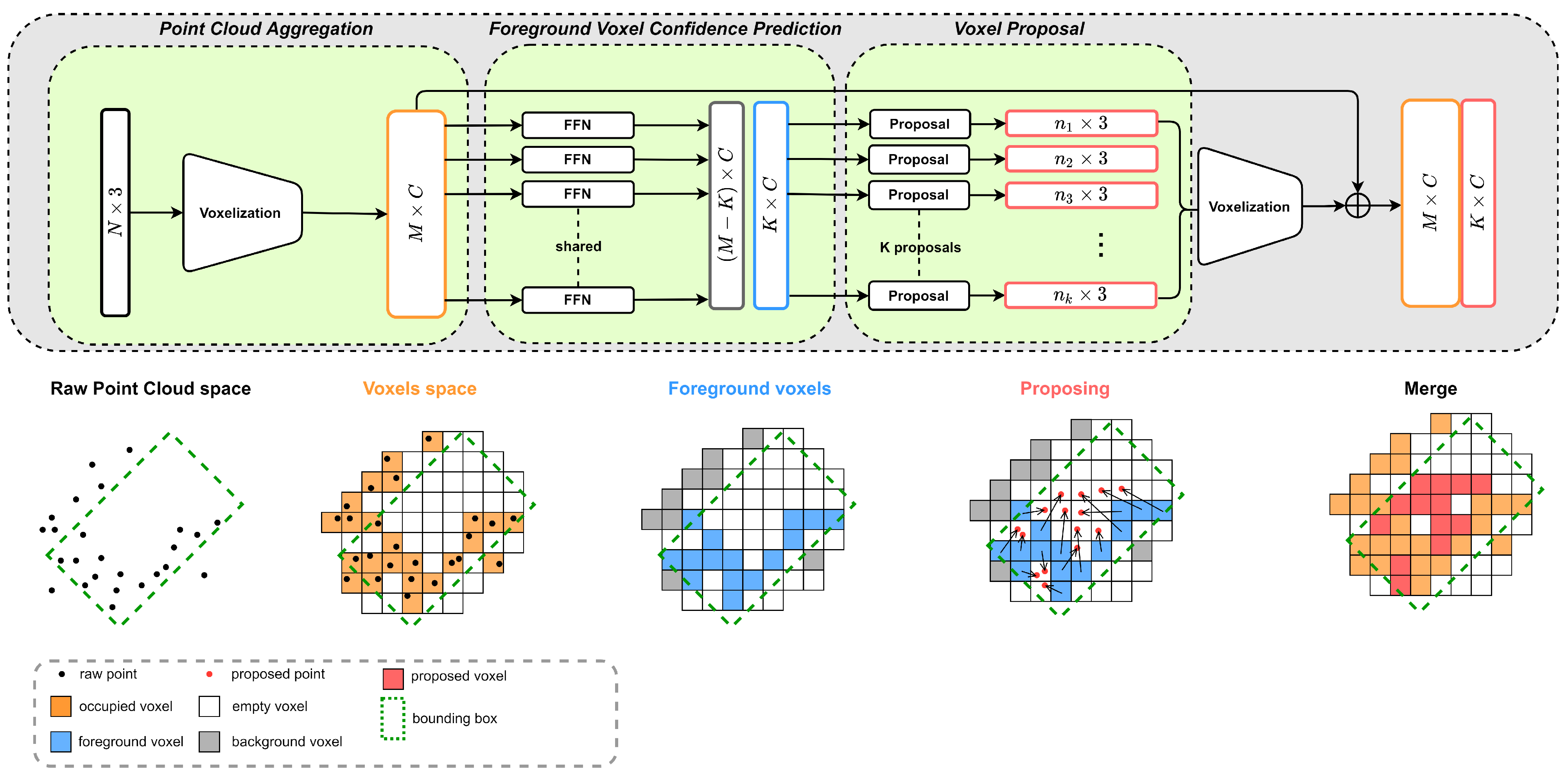
3.1. Foreground Voxel Proposal Module
3.1.1. Point Cloud Aggregation
3.1.2. Foreground Voxel Confidence Prediction
3.1.3. Voxel Proposal
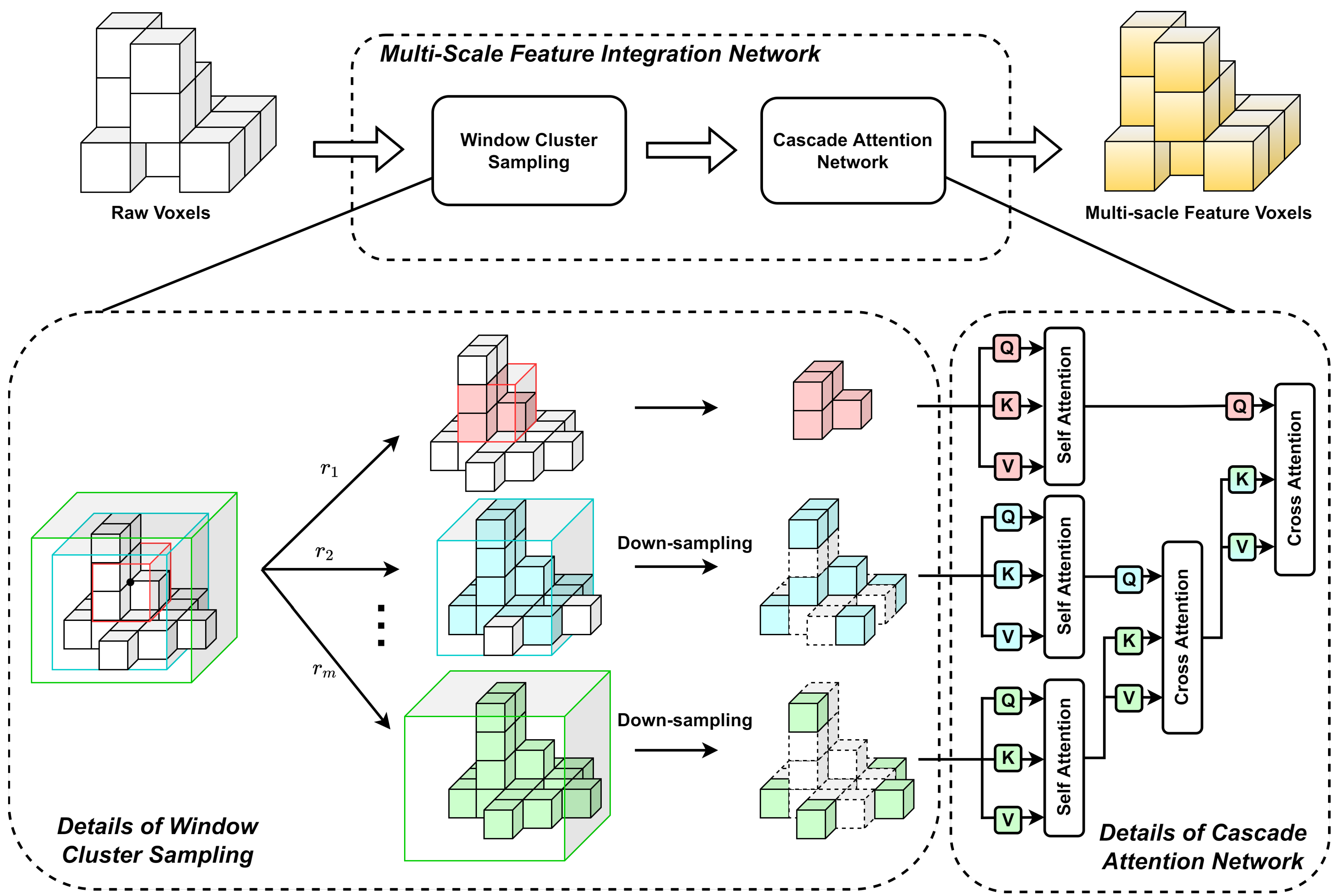
3.2. Multi-Scale Feature Integration Network
3.2.1. Window Cluster Sampling
3.2.2. Cascade Attention Network
3.2.3. Position Encoding
3.2.4. Sparse Accelerator
3.3. Region Proposal Network
4. Experiments
4.1. Implementation Details
4.2. Result on KITTI
4.2.1. Dataset Setups
4.2.2. Main Results
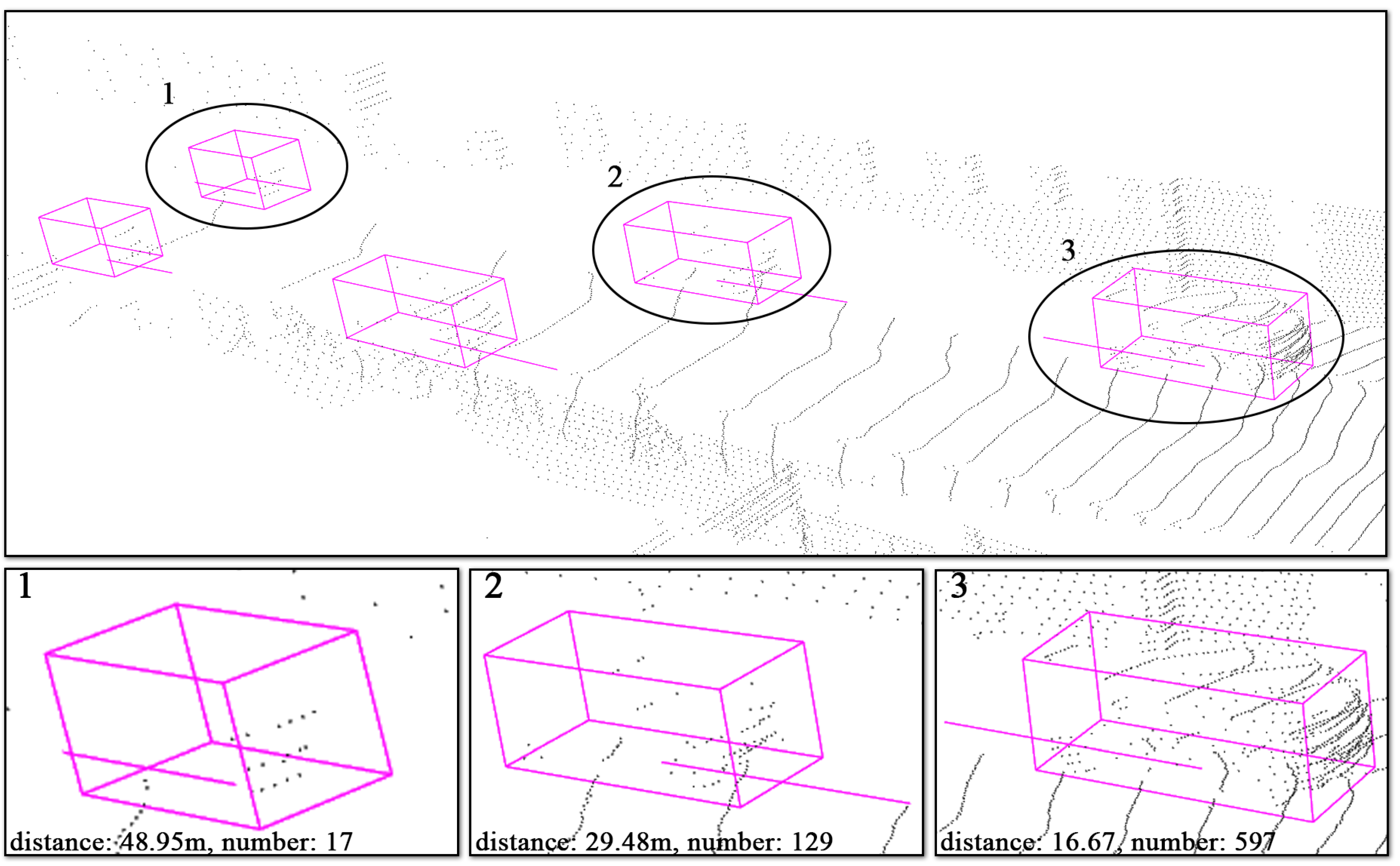
4.2.3. Visualization
4.3. Ablation Studies
4.3.1. Effect of Key Components
4.3.2. Impact of Foreground Voxel Confidence Prediction Settings
4.3.3. Impact of Window Cluster Sampling Settings
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2647–2664. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–28 June 2018; pp. 4490–4499. [Google Scholar]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel r-cnn: Towards high performance voxel-based 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1201–1209. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 14–19 June 2020; pp. 10529–10538. [Google Scholar]
- Li, Z.; Yao, Y.; Quan, Z.; Xie, J.; Yang, W. Spatial information enhancement network for 3D object detection from point cloud. Pattern Recognit. 2022, 128, 108684. [Google Scholar] [CrossRef]
- Mao, J.; Niu, M.; Bai, H.; Liang, X.; Xu, H.; Xu, C. Pyramid r-cnn: Towards better performance and adaptability for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 19–25 June 2021; pp. 2723–2732. [Google Scholar]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel transformer for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3164–3173. [Google Scholar]
- Zheng, W.; Tang, W.; Jiang, L.; Fu, C.W. SE-SSD: Self-ensembling single-stage object detector from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 14494–14503. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Fan, L.; Pang, Z.; Zhang, T.; Wang, Y.X.; Zhao, H.; Wang, F.; Wang, N.; Zhang, Z. Embracing single stride 3d object detector with sparse transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 8458–8468. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Qi, C.R.; Litany, O.; He, K.; Guibas, L.J. Deep hough voting for 3d object detection in point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9277–9286. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Std: Sparse-to-dense 3d object detector for point cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1951–1960. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3dssd: Point-based 3d single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 14–19 June 2020; pp. 11040–11048. [Google Scholar]
- Shi, G.; Li, R.; Ma, C. Pillarnet: Real-time and high-performance pillar-based 3d object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 24–28 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 35–52. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 12697–12705. [Google Scholar]
- Corral-Soto, E.R.; Bingbing, L. Understanding strengths and weaknesses of complementary sensor modalities in early fusion for object detection. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1785–1792. [Google Scholar]
- Hu, J.S.; Kuai, T.; Waslander, S.L. Point density-aware voxels for lidar 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 8469–8478. [Google Scholar]
- Arief, H.A.; Arief, M.; Bhat, M.; Indahl, U.G.; Tveite, H.; Zhao, D. Density-Adaptive Sampling for Heterogeneous Point Cloud Object Segmentation in Autonomous Vehicle Applications. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 26–33. [Google Scholar]
- Yuan, W.; Khot, T.; Held, D.; Mertz, C.; Hebert, M. Pcn: Point completion network. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Piscataway, NJ, USA, 5–8 September 2018; pp. 728–737. [Google Scholar]
- Qi, C.R.; Chen, X.; Litany, O.; Guibas, L.J. Imvotenet: Boosting 3d object detection in point clouds with image votes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 4404–4413. [Google Scholar]
- Xu, Q.; Zhou, Y.; Wang, W.; Qi, C.R.; Anguelov, D. Spg: Unsupervised domain adaptation for 3d object detection via semantic point generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 19–25 June 2021; pp. 15446–15456. [Google Scholar]
- Tsai, D.; Berrio, J.S.; Shan, M.; Nebot, E.; Worrall, S. Viewer-centred surface completion for unsupervised domain adaptation in 3D object detection. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), IEEE, London, UK, 29 May–2 June 2023; pp. 9346–9353. [Google Scholar]
- Chen, X.; Chen, B.; Mitra, N.J. Unpaired point cloud completion on real scans using adversarial training. arXiv 2019, arXiv:1904.00069. [Google Scholar]
- Zhang, J.; Chen, X.; Cai, Z.; Pan, L.; Zhao, H.; Yi, S.; Yeo, C.K.; Dai, B.; Loy, C.C. Unsupervised 3d shape completion through gan inversion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 1768–1777. [Google Scholar]
- Li, J.; Luo, C.; Yang, X. PillarNeXt: Rethinking network designs for 3D object detection in LiDAR point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 18–22 June 2023; pp. 17567–17576. [Google Scholar]
- Dong, S.; Ding, L.; Wang, H.; Xu, T.; Xu, X.; Wang, J.; Bian, Z.; Wang, Y.; Li, J. Mssvt: Mixed-scale sparse voxel transformer for 3d object detection on point clouds. Adv. Neural Inf. Process. Syst. 2022, 35, 11615–11628. [Google Scholar]
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.J.; Martin, R.R.; Hu, S.M. Pct: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 19–25 June 2021; pp. 16259–16268. [Google Scholar]
- He, C.; Li, R.; Li, S.; Zhang, L. Voxel set transformer: A set-to-set approach to 3d object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 8417–8427. [Google Scholar]
- Zhang, C.; Wan, H.; Liu, S.; Shen, X.; Wu, Z. Pvt: Point-voxel transformer for 3d deep learning. arXiv 2021, arXiv:2108.06076. [Google Scholar]
- Park, C.; Jeong, Y.; Cho, M.; Park, J. Fast point transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 16949–16958. [Google Scholar]
- Sheng, H.; Cai, S.; Liu, Y.; Deng, B.; Huang, J.; Hua, X.S.; Zhao, M.J. Improving 3d object detection with channel-wise transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 19–25 June 2021; pp. 2743–2752. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 2446–2454. [Google Scholar]
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3d tracking and forecasting with rich maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 8748–8757. [Google Scholar]
- Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. Reluplex made more practical: Leaky ReLU. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Piscataway, NJ, USA, 7–10 July 2020; pp. 1–7. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Shi, S.; Wang, Z.; Wang, X.; Li, H. Part-a2 net: 3d part-aware and aggregation neural network for object detection from point cloud. arXiv 2019, arXiv:1907.03670. [Google Scholar]
- Yin, T.; Zhou, X.; Krähenbühl, P. Multimodal virtual point 3d detection. Adv. Neural Inf. Process. Syst. 2021, 34, 16494–16507. [Google Scholar]
- Shi, S.; Jiang, L.; Deng, J.; Wang, Z.; Guo, C.; Shi, J.; Wang, X.; Li, H. PV-RCNN++: Point-voxel feature set abstraction with local vector representation for 3D object detection. Int. J. Comput. Vis. 2023, 131, 531–551. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 19–25 June 2021; pp. 10012–10022. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 3D Detection | BEV Detection | ||||||
|---|---|---|---|---|---|---|---|---|
| 0–20 m | 20–40 m | >40 m | Mean | 0–20 m | 20–40 m | >40 m | Mean | |
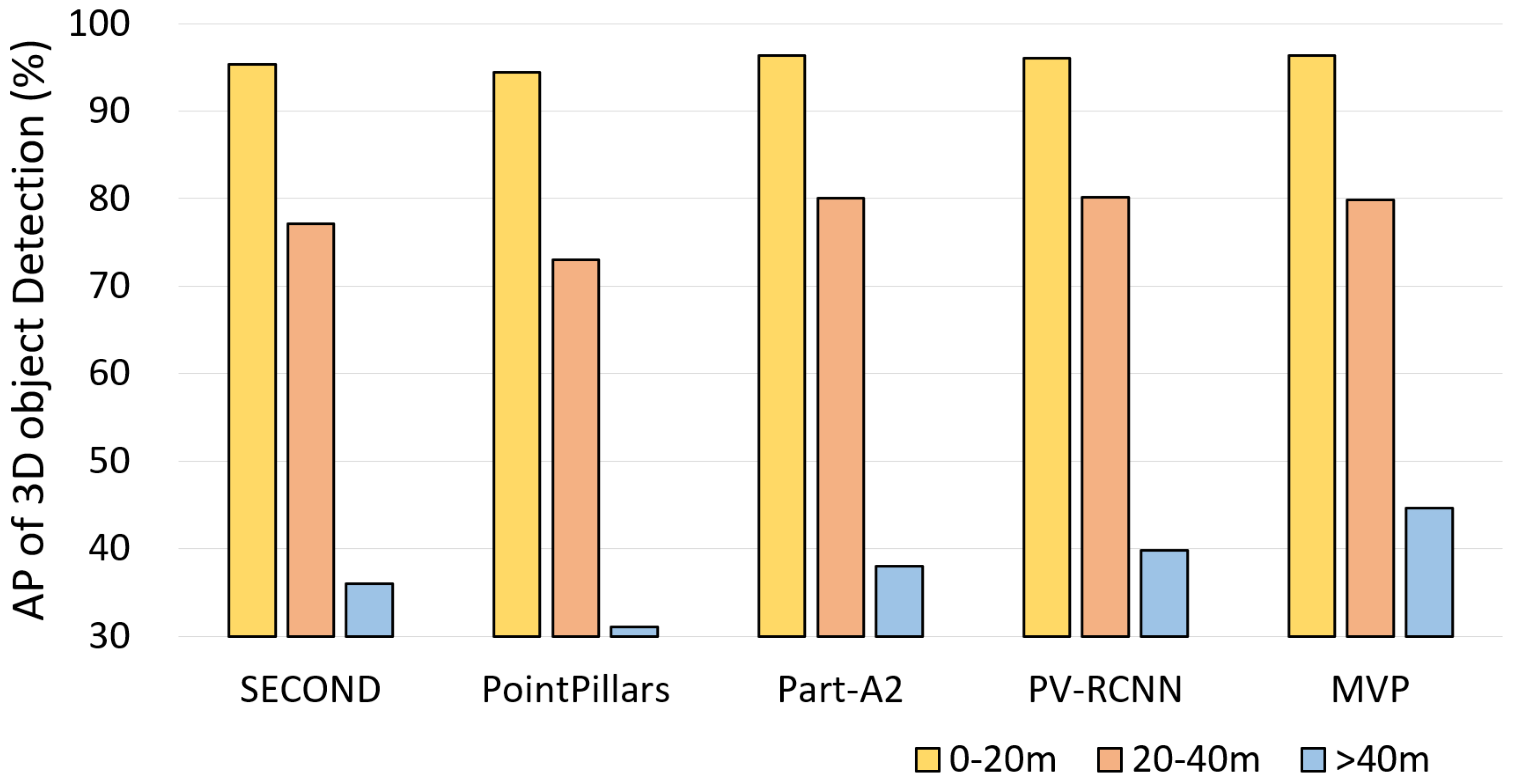
| SECOND [8] | 95.32 | 77.08 | 35.97 | 69.46 | 96.14 | 88.89 | 54.31 | 79.78 |
| PointPillars [21] | 94.15 | 76.41 | 31.24 | 67.26 | 95.63 | 87.66 | 50.66 | 77.98 |
| Part-A2 [45] | 96.30 | 80.03 | 38.01 | 71.45 | 96.69 | 88.59 | 54.65 | 79.97 |
| PV-RCNN [9] | 96.02 | 80.10 | 39.80 | 71.97 | 96.36 | 88.85 | 55.47 | 80.23 |
| MVP [46] | 96.35 | 79.83 | 44.62 | 73.60 | 96.96 | 89.22 | 58.83 | 81.67 |
| SIENet [10] | 96.23 | 82.78 | 44.59 | 74.53 | 96.67 | 89.70 | 60.37 | 82.25 |
| Ms-FVP (Ours) | 95.93 | 83.65 | 46.51 | 75.36 | 96.22 | 90.43 | 62.52 | 83.05 |
| Method | Param | Validation | Test | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D Car (IoU = 0.7) | 3D Ped. (IoU = 0.5) | 3D Cyc. (IoU = 0.5) | 3D Car (IoU = 0.7) | ||||||||||
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | ||
| VoxelNet [6] | 6.4 M | 81.97 | 65.46 | 62.85 | 57.86 | 53.42 | 48.87 | 67.17 | 47.65 | 45.11 | 77.47 | 65.11 | 57.73 |
| SECOND [8] | 5.3 M | 86.46 | 77.28 | 74.65 | 61.63 | 56.27 | 52.60 | 80.10 | 62.69 | 59.71 | 84.65 | 75.96 | 68.71 |
| PointPillars [5] | 4.8 M | 88.61 | 78.62 | 77.22 | 56.55 | 52.98 | 47.73 | 80.59 | 67.16 | 53.11 | 82.58 | 74.31 | 68.99 |
| 3DSSD [19] | 2.8 M | 88.55 | 78.45 | 77.30 | 58.18 | 54.32 | 49.56 | 86.25 | 70.49 | 65.32 | 88.36 | 79.57 | 74.55 |
| VoTr-SS [36] | 4.8 M | 87.86 | 78.27 | 76.93 | - | - | - | - | - | - | 88.36 | 79.57 | 74.55 |
| VoxelSet [35] | 3.1 M | 88.45 | 78.48 | 77.07 | 60.62 | 54.74 | 50.39 | 84.07 | 68.11 | 65.14 | 88.53 | 82.06 | 77.46 |
| PointRCNN [4] | 4.1 M | 89.03 | 78.78 | 77.86 | 62.50 | 55.18 | 50.15 | 87.49 | 72.55 | 66.01 | 86.96 | 75.64 | 70.70 |
| PV-RCNN [9] | 13.1 M | 89.35 | 83.69 | 78.70 | 63.12 | 54.84 | 51.78 | 86.06 | 69.48 | 64.50 | 90.25 | 81.43 | 76.82 |
| VoTr-TS [36] | 12.6 M | 89.04 | 84.04 | 78.68 | - | - | - | - | - | - | 89.90 | 82.09 | 79.14 |
| PV-RCNN++ [47] | 14.1 M | - | - | - | - | - | - | - | - | - | 90.14 | 81.88 | 77.15 |
| MsSVT [32] | - | 89.08 | 78.75 | 77.35 | 63.59 | 57.33 | 53.12 | 88.57 | 71.70 | 66.29 | 90.04 | 82.10 | 78.25 |
| VoxelRCNN [7] | 7.6 M | 89.41 | 84.52 | 78.93 | - | - | - | - | - | - | 90.90 | 81.62 | 77.06 |
| Ms-FVP (Ours) | 9.8 M | 89.21 | 85.56 | 79.24 | 62.81 | 57.51 | 54.59 | 87.64 | 74.25 | 68.75 | 89.86 | 83.47 | 79.46 |
| VP | CAN | WCS | PE | Car | Ped. | Cyc. |
|---|---|---|---|---|---|---|
| - | - | - | - | 78.46 | 55.23 | 69.73 |
| ✓ | - | - | - | 80.98 | 56.01 | 70.01 |
| ✓ | ✓ | - | - | 83.53 | 56.31 | 70.86 |
| ✓ | ✓ | ✓ | - | 85.10 | 57.35 | 73.34 |
| ✓ | ✓ | ✓ | ✓ | 85.56 | 57.51 | 74.25 |
| Confidence Settings | Positive Propose Rate | mAP (%) |
|---|---|---|
| 12.1% | 76.25 | |
| 47.5% | 79.25 | |
| 71.2% | 83.91 | |
| 79.2% | 80.21 | |
| 85.2% | 79.62 |
| Window Size | Car | Ped. | Cyc. |
|---|---|---|---|
| 80.80 | 55.37 | 72.05 | |
| 84.36 | 57.73 | 75.91 | |
| 84.67 | 58.09 | 76.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Tao, H.; Deng, Q.; Xiao, S.; Zhou, J. Spatial Information Enhancement with Multi-Scale Feature Aggregation for Long-Range Object and Small Reflective Area Object Detection from Point Cloud. Remote Sens. 2024, 16, 2631. https://doi.org/10.3390/rs16142631
Li H, Tao H, Deng Q, Xiao S, Zhou J. Spatial Information Enhancement with Multi-Scale Feature Aggregation for Long-Range Object and Small Reflective Area Object Detection from Point Cloud. Remote Sensing. 2024; 16(14):2631. https://doi.org/10.3390/rs16142631
Chicago/Turabian StyleLi, Hanwen, Huamin Tao, Qiuqun Deng, Shanzhu Xiao, and Jianxiong Zhou. 2024. "Spatial Information Enhancement with Multi-Scale Feature Aggregation for Long-Range Object and Small Reflective Area Object Detection from Point Cloud" Remote Sensing 16, no. 14: 2631. https://doi.org/10.3390/rs16142631
APA StyleLi, H., Tao, H., Deng, Q., Xiao, S., & Zhou, J. (2024). Spatial Information Enhancement with Multi-Scale Feature Aggregation for Long-Range Object and Small Reflective Area Object Detection from Point Cloud. Remote Sensing, 16(14), 2631. https://doi.org/10.3390/rs16142631