
Winter Wheat Mapping Method Based on Pseudo-Labels and U-Net Model for Training Sample Shortage
Abstract
1. Introduction
2. Materials and Methods
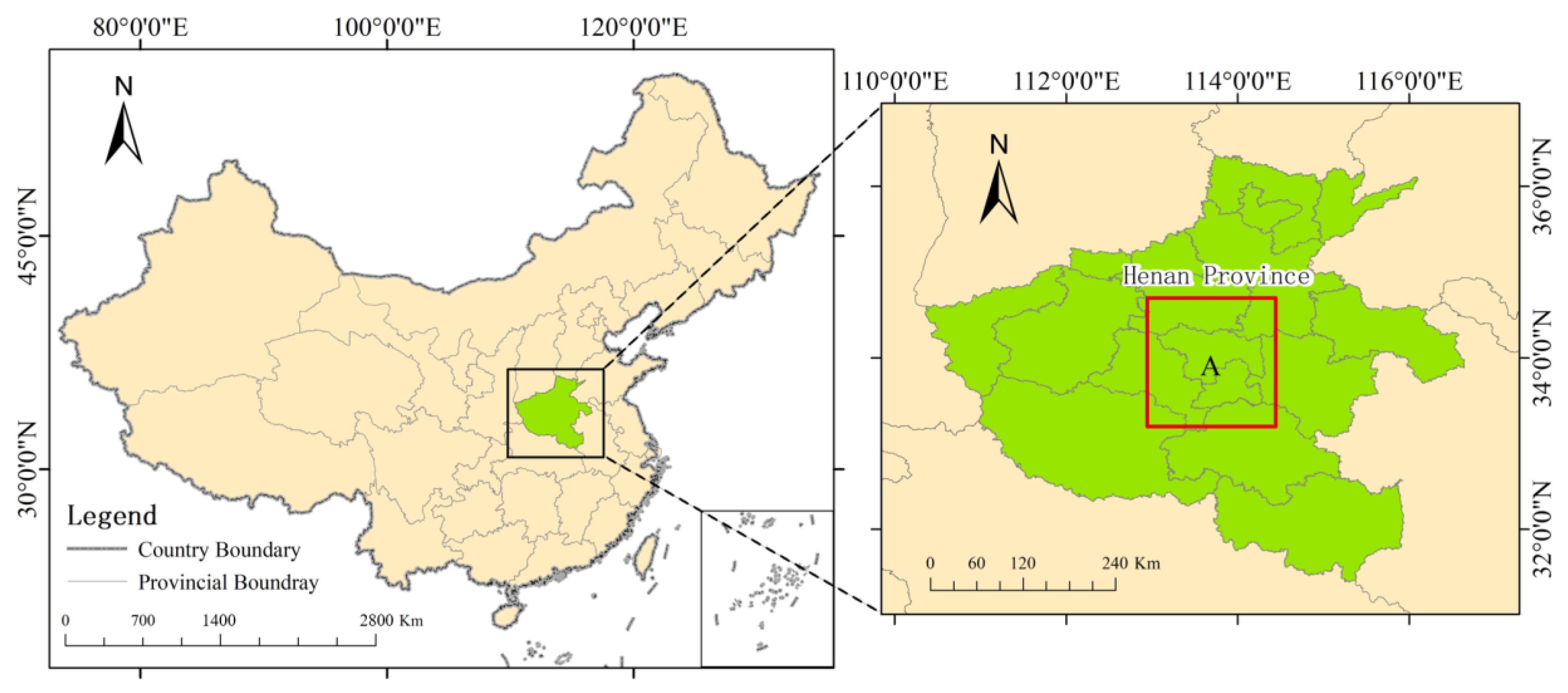
2.1. Study Area
2.2. Data Source
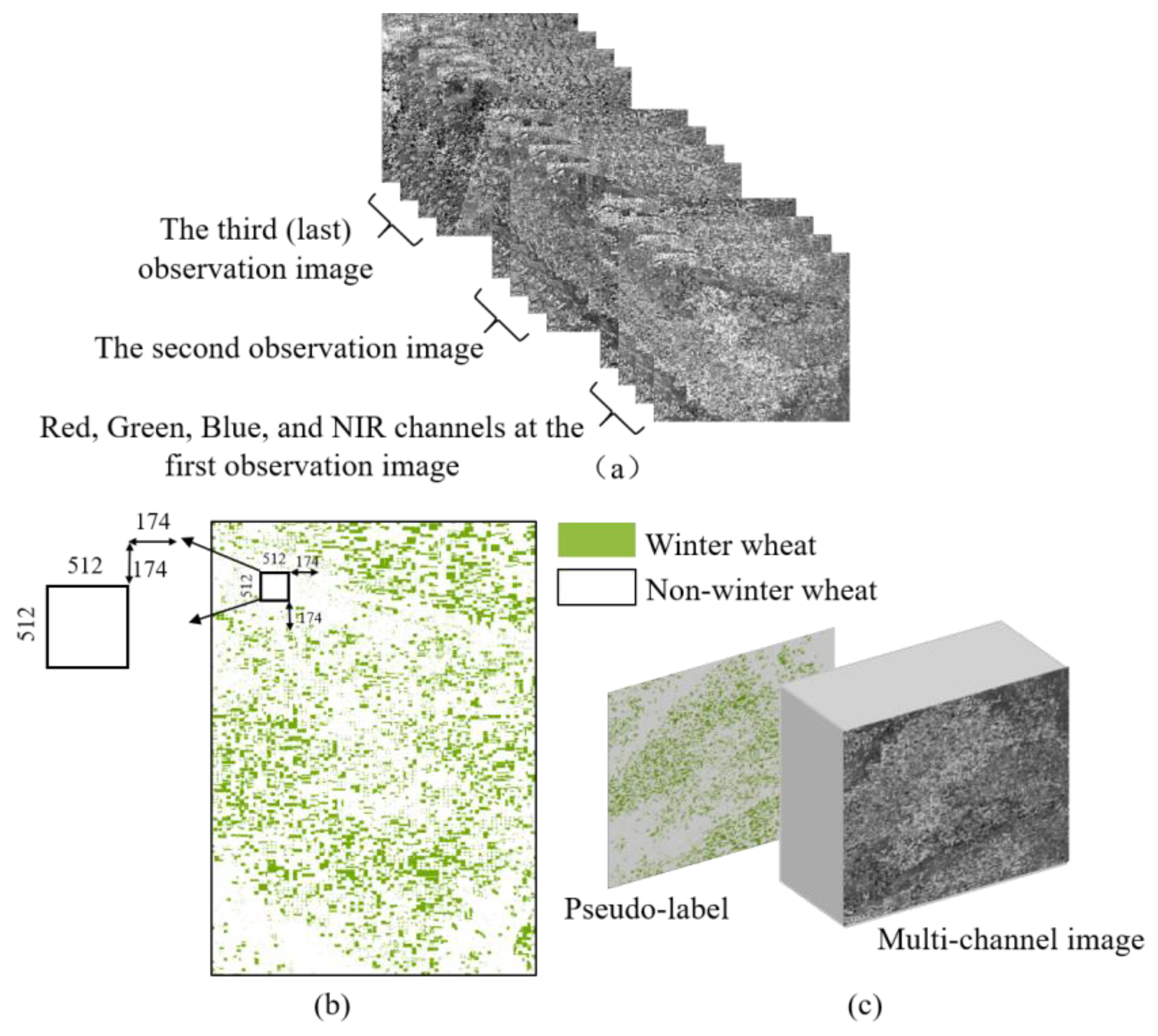
2.3. Dataset Production
3. Method
3.1. Technical Research Path
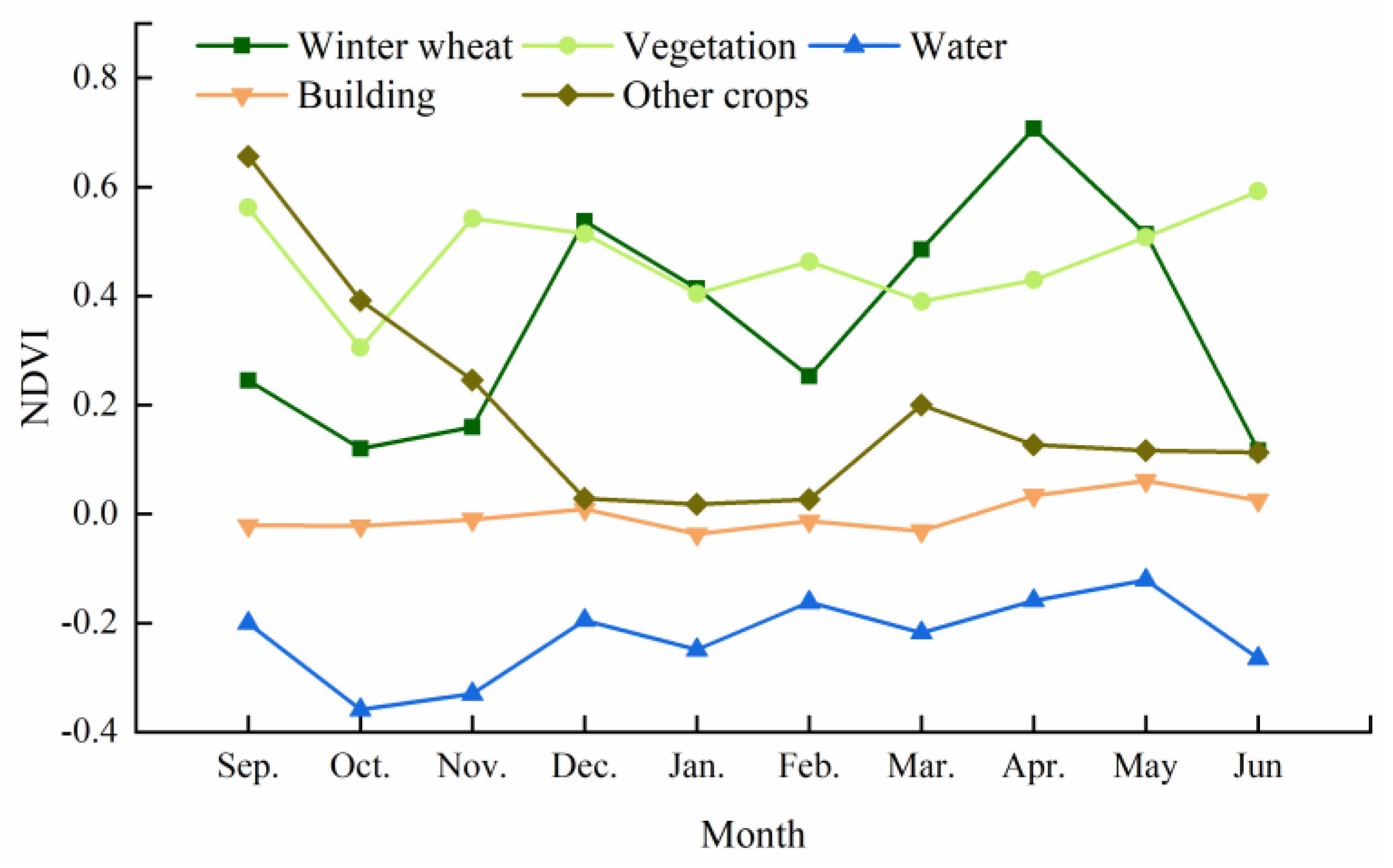
3.2. Winter Wheat Pseudo-Label Production Based on Random Forest
3.2.1. Dataset Establishment
3.2.2. Initial Winter Wheat Extraction Based on WCI
3.2.3. Generating Random Samples
3.2.4. Pseudo-Label Production
3.3. Establishment and Training of the U-Net Model
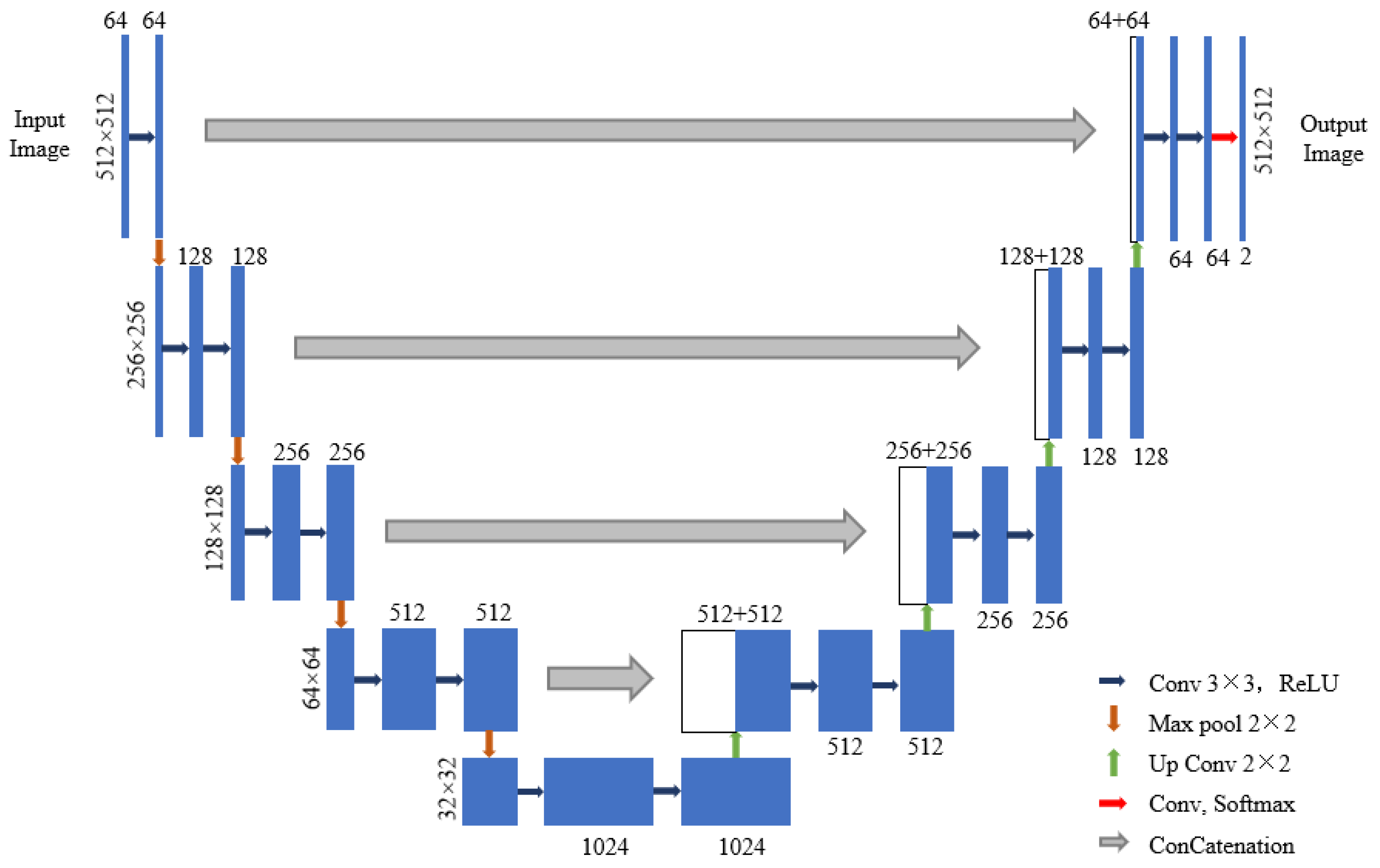
3.3.1. Establishment of the U-Net Model
3.3.2. Data Pre-Processing
3.3.3. Model Training
| Algorithm 1. Winter Wheat Extraction Model Implementation Steps |
| 1 Input: Image data/Pseudo-label data; 2 Initialisation: Random initialisation of training parameters, parameter settings, learning rate 0.0001, training rounds 50 epochs; 3 Processing: 4 for j = 0 to N do (N is the number of iteration calculations) 5 calculate the loss L_loss 6 if (L_loss ≤ threshold) then 7 outputs 8 else extract features again based on the parameters updated by forward propagation to calculate L_loss; 9 Output: Trained model |
3.3.4. Model Prediction
3.4. Accuracy Evaluation Indicators
4. Results and Discussion
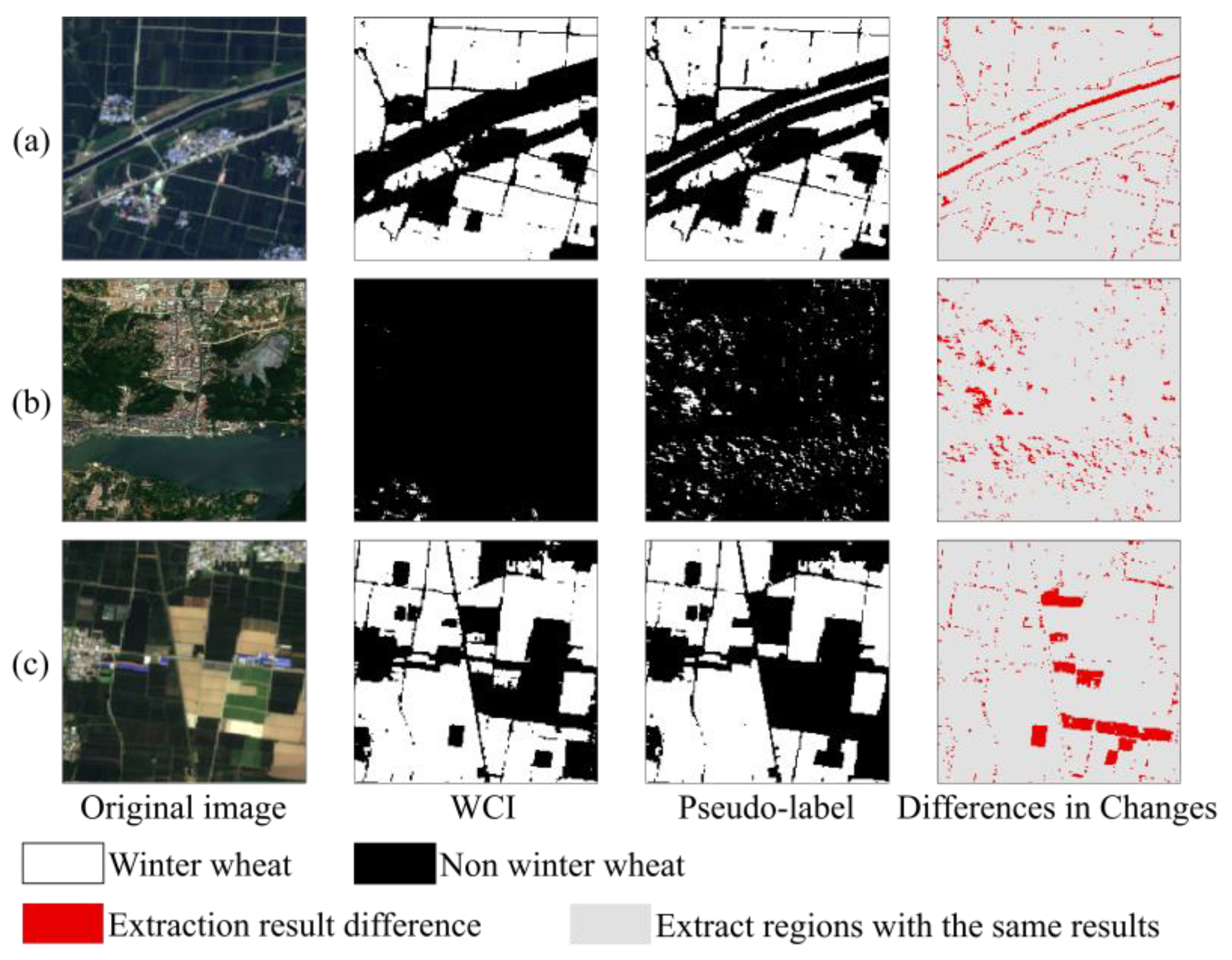
4.1. Pseudo-Label Production and Accuracy Verification Based on the Random Forest Model
4.2. Extraction Result Analysis
4.3. Accuracy Verification of Extraction Results
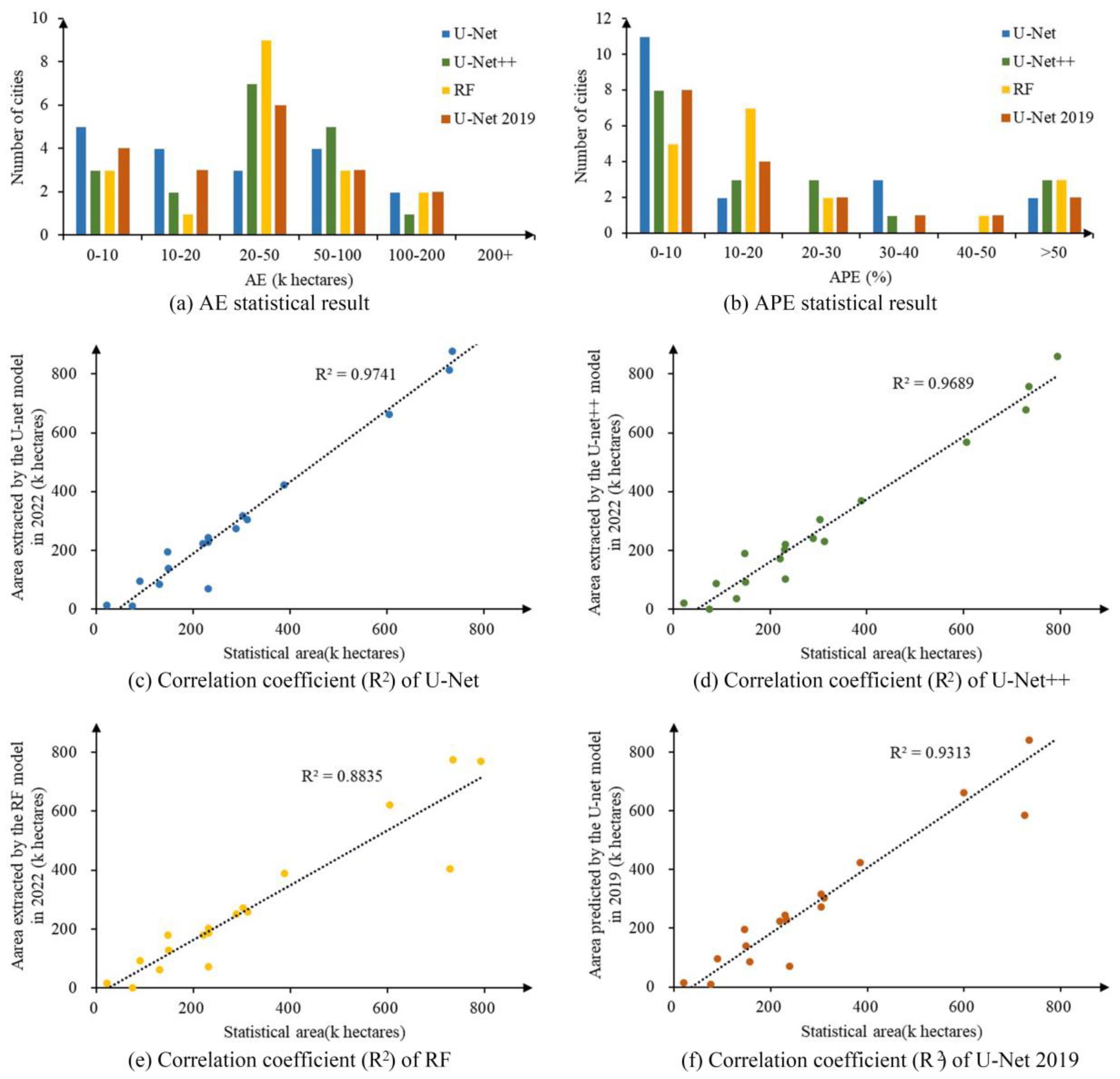
4.3.1. Accuracy Evaluation of Extraction Results Based on Statistical Data
4.3.2. Accuracy Verification Based on Manually-Selected Sample Points
4.4. Limitation & Expectation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- State of the Art and Perspective of Agricultural Land Use Remote Sensing Information Extraction-All Databases. Available online: https://webofscience.clarivate.cn/wos/alldb/full-record/CSCD:6732993 (accessed on 19 April 2024).
- Zhou, T.; Pan, J.; Zhang, P.; Wei, S.; Han, T. Mapping Winter Wheat with Multi-Temporal SAR and Optical Images in an Urban Agricultural Region. Sensors 2017, 17, 1210. [Google Scholar] [CrossRef] [PubMed]
- Tiwar, V.; Matin, M.A.; Qamer, F.M.; Ellenburg, W.L.; Bajracharya, B.; Vadrevu, K.; Rushi, B.R.; Yusafi, W. Wheat Area Mapping in Afghanistan Based on Optical and SAR Time-Series Images in Google Earth Engine Cloud Environment. Front. Environ. Sci. 2020, 8, 77. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global Land Cover Mapping at 30m Resolution: A POK-Based Operational Approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Lefebvre, A.; Sannier, C.; Corpetti, T. Monitoring Urban Areas with Sentinel-2A Data: Application to the Update of the Copernicus High Resolution Layer Imperviousness Degree. Remote Sens. 2016, 8, 606. [Google Scholar] [CrossRef]
- Rujoiu-Mare, M.-R.; Olariu, B.; Mihai, B.-A.; Nistor, C.; Săvulescu, I. Land Cover Classification in Romanian Carpathians and Subcarpathians Using Multi-Date Sentinel-2 Remote Sensing Imagery. Eur. J. Remote Sens. 2017, 50, 496–508. [Google Scholar] [CrossRef]
- Aryal, J.; Sitaula, C.; Aryal, S. NDVI Threshold-Based Urban Green Space Mapping from Sentinel-2A at the Local Governmental Area (LGA) Level of Victoria, Australia. Land 2022, 11, 351. [Google Scholar] [CrossRef]
- Ali, U.; Esau, T.J.; Farooque, A.A.; Zaman, Q.U.; Abbas, F.; Bilodeau, M.F. Limiting the Collection of Ground Truth Data for Land Use and Land Cover Maps with Machine Learning Algorithms. ISPRS Int. J. Geo-Inf. 2022, 11, 333. [Google Scholar] [CrossRef]
- Wei, P.; Chai, D.; Lin, T.; Tang, C.; Du, M.; Huang, J. Large-Scale Rice Mapping under Different Years Based on Time-Series Sentinel-1 Images Using Deep Semantic Segmentation Model. ISPRS J. Photogramm. Remote Sens. 2021, 174, 198–214. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE: New York, NY, USA, 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Parente, L.; Taquary, E.; Silva, A.P.; Souza, C.; Ferreira, L. Next Generation Mapping: Combining Deep Learning, Cloud Computing, and Big Remote Sensing Data. Remote Sens. 2019, 11, 2881. [Google Scholar] [CrossRef]
- Gargiulo, M.; Dell’Aglio, D.A.G.; Iodice, A.; Riccio, D.; Ruello, G. Integration of Sentinel-1 and Sentinel-2 Data for Land Cover Mapping Using W-Net. Sensors 2020, 20, 2969. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Pan, Y.; Zhang, J.; Hu, T.; Zhao, J.; Li, N.; Chen, Q. A Generalized Approach Based on Convolutional Neural Networks for Large Area Cropland Mapping at Very High Resolution. Remote Sens. Environ. 2020, 247, 111912. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Yang, W. Efficient Semantic Segmentation Method Based on Convolutional Neural Networks, in Chinese. Doctoral Dissertation, University of Chinese Academy of Sciences, Institute of Optics and Electronics, Chinese Academy of Sciences, Beijing, China, 2019. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Lin, H.; Shi, Z.; Zou, Z. Maritime Semantic Labeling of Optical Remote Sensing Images with Multi-Scale Fully Convolutional Network. Remote Sens. 2017, 9, 480. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, PT III, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing Ag: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2021, Nashville, TN, USA, 20–25 June 2021; IEEE Computer Soc: Los Alamitos, CA, USA, 2021; pp. 6877–6886. [Google Scholar]
- Wei, P.; Chai, D.; Huang, R.; Peng, D.; Lin, T.; Sha, J.; Sun, W.; Huang, J. Rice Mapping Based on Sentinel-1 Images Using the Coupling of Prior Knowledge and Deep Semantic Segmentation Network: A Case Study in Northeast China from 2019 to 2021. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102948. [Google Scholar] [CrossRef]
- Du, M.; Huang, J.; Wei, P.; Yang, L.; Chai, D.; Peng, D.; Sha, J.; Sun, W.; Huang, R. Dynamic Mapping of Paddy Rice Using Multi-Temporal Landsat Data Based on a Deep Semantic Segmentation Model. Agronomy 2022, 12, 1583. [Google Scholar] [CrossRef]
- Wei, S.; Zhang, H.; Wang, C.; Wang, Y.; Xu, L. Multi-Temporal SAR Data Large-Scale Crop Mapping Based on U-Net Model. Remote Sens. 2019, 11, 68. [Google Scholar] [CrossRef]
- Pan, Z.; Xu, J.; Guo, Y.; Hu, Y.; Wang, G. Deep Learning Segmentation and Classification for Urban Village Using a Worldview Satellite Image Based on U-Net. Remote Sens. 2020, 12, 1574. [Google Scholar] [CrossRef]
- Pang, J.; Zhang, R.; Yu, B.; Liao, M.; Lv, J.; Xie, L.; Li, S.; Zhan, J. Pixel-Level Rice Planting Information Monitoring in Fujin City Based on Time-Series SAR Imagery. Int. J. Appl. Earth Obs. Geoinf. 2021, 104, 102551. [Google Scholar] [CrossRef]
- Paris, C.; Bruzzone, L. A Novel Approach to the Unsupervised Extraction of Reliable Training Samples From Thematic Products. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1930–1948. [Google Scholar] [CrossRef]
- Supriatna; Rokhmatuloh; Wibowo, A.; Shidiq, I.P.A. Spatial Analysis of Rice Phenology Using Sentinel-1 and Sentinel-2 in Karawang Regency. IOP Conf. Ser. Earth Environ. Sci. 2020, 500, 012033. [Google Scholar] [CrossRef]
- Saadat, M.; Seydi, S.T.; Hasanlou, M.; Homayouni, S. A Convolutional Neural Network Method for Rice Mapping Using Time-Series of Sentinel-1 and Sentinel-2 Imagery. Agriculture 2022, 12, 2083. [Google Scholar] [CrossRef]
- Lee, D. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on Challenges in Representation Learning, ICML, Atlanta, GA, USA, 16–21 June 2013; Volume 3, p. 896. [Google Scholar]
- Zhu, A.-X.; Zhao, F.-H.; Pan, H.-B.; Liu, J.-Z. Mapping Rice Paddy Distribution Using Remote Sensing by Coupling Deep Learning with Phenological Characteristics. Remote Sens. 2021, 13, 1360. [Google Scholar] [CrossRef]
- Wei, P.; Huang, R.; Lin, T.; Huang, J. Rice Mapping in Training Sample Shortage Regions Using a Deep Semantic Segmentation Model Trained on Pseudo-Labels. Remote Sens. 2022, 14, 328. [Google Scholar] [CrossRef]
- Mullissa, A.; Vollrath, A.; Odongo-Braun, C.; Slagter, B.; Balling, J.; Gou, Y.; Gorelick, N.; Reiche, J. Sentinel-1 SAR Backscatter Analysis Ready Data Preparation in Google Earth Engine. Remote Sens. 2021, 13, 1954. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First Experience with Sentinel-2 Data for Crop and Tree Species Classifications in Central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- Lobert, F.; Löw, J.; Schwieder, M.; Gocht, A.; Schlund, M.; Hostert, P.; Erasmi, S. A Deep Learning Approach for Deriving Winter Wheat Phenology from Optical and SAR Time Series at Field Level. Remote Sens. Environ. 2023, 298, 113800. [Google Scholar] [CrossRef]
- Xu, F.; Li, Z.; Zhang, S.; Huang, N.; Quan, Z.; Zhang, W.; Liu, X.; Jiang, X.; Pan, J.; Prishchepov, A.V. Mapping Winter Wheat with Combinations of Temporally Aggregated Sentinel-2 and Landsat-8 Data in Shandong Province, China. Remote Sens. 2020, 12, 2065. [Google Scholar] [CrossRef]
- Pan, L.; Xia, H.; Zhao, X.; Guo, Y.; Qin, Y. Mapping Winter Crops Using a Phenology Algorithm, Time-Series Sentinel-2 and Landsat-7/8 Images, and Google Earth Engine. Remote Sens. 2021, 13, 2510. [Google Scholar] [CrossRef]
- Rapid Mapping of Winter Wheat in Henan Province-All Databases. Available online: https://webofscience.clarivate.cn/wos/alldb/full-record/CSCD:6012581 (accessed on 19 April 2024).
- Yang, G.; Li, X.; Liu, P.; Yao, X.; Zhu, Y.; Cao, W.; Cheng, T. Automated In-Season Mapping of Winter Wheat in China with Training Data Generation and Model Transfer. ISPRS J. Photogramm. Remote Sens. 2023, 202, 422–438. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Chai, D.; Newsam, S.; Zhang, H.K.; Qiu, Y.; Huang, J. Cloud and Cloud Shadow Detection in Landsat Imagery Based on Deep Convolutional Neural Networks. Remote Sens. Environ. 2019, 225, 307–316. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Series | Image Information | Study Area A (2022) | Henan Province (2022) | Study Area A (2019) | Henan Province (2019) |
|---|---|---|---|---|---|
| 1 | Date | 11 October 2022–21 October 2022 | 11 October 2022–21 October 2022 | 1 October 2018–21 October 2018 | 1 October 2018–21 October 2018 |
| Number | 15 | 81 | 22 | 134 | |
| 2 | Date | 26 April 2022–16 May 2022 | 26 April 2022–16 May 2022 | 16 April 2019–16 May 2019 | 16 April 2019–16 May 2019 |
| Number | 13 | 86 | 17 | 86 | |
| 3 | Date | 1 June 2023–21 June 2023 | 1 June 2023–21 June 2023 | 1 June 2019–21 June 2019 | 1 June 2019–21 June 2019 |
| Number | 24 | 105 | 17 | 91 |
| Type of Sample Points | Study Area A (2022) | Henan Province (2022) | Henan Province (2019) |
|---|---|---|---|
| Winter Wheat | 600 | 443 | 400 |
| Non-Winter Wheat | 900 | 857 | 800 |
| Total number | 1500 | 1300 | 1200 |
| Estimate Value = 1 | Estimate Value = 0 | |
|---|---|---|
| True value = 1 | TP | FN |
| True value = 0 | FP | TN |
| Training Times | First | Second | Third | Fourth |
|---|---|---|---|---|
| Overlap Rate | 96.10% | 98.53% | 98.86% | 99.25% |
| Indicators | OA | Kappa Coefficient | F1-Score | UA | PA | |||
|---|---|---|---|---|---|---|---|---|
| Winter Wheat | Non-Winter Wheat | Winter Wheat | Non-Winter Wheat | Winter Wheat | Non-Winter Wheat | |||
| Value | 97.53% | 0.95 | 0.97 | 0.98 | 95.77% | 98.76% | 98.17% | 97.11% |
| Model | OA | Kappa Coefficient | F1-Score | UA | PA | |||
|---|---|---|---|---|---|---|---|---|
| Winter Wheat | Non-Winter Wheat | Winter Wheat | Non-Winter Wheat | Winter Wheat | Non-Winter Wheat | |||
| U-Net | 93.08% | 0.85 | 0.91 | 0.95 | 84.41% | 98.73% | 97.74% | 90.67% |
| U-Net++ | 92.64% | 0.84 | 0.89 | 0.94 | 87.23% | 95.67% | 91.85% | 93.05% |
| RF | 86.08% | 0.70 | 0.81 | 0.89 | 76.95% | 91.52% | 84.42% | 86.93% |
| U-Net 2019 | 89.15% | 0.77 | 0.85 | 0.91 | 81.76% | 93.76% | 89.08% | 89.19% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; You, S.; Liu, A.; Xie, L.; Huang, C.; Han, X.; Li, P.; Wu, Y.; Deng, J. Winter Wheat Mapping Method Based on Pseudo-Labels and U-Net Model for Training Sample Shortage. Remote Sens. 2024, 16, 2553. https://doi.org/10.3390/rs16142553
Zhang J, You S, Liu A, Xie L, Huang C, Han X, Li P, Wu Y, Deng J. Winter Wheat Mapping Method Based on Pseudo-Labels and U-Net Model for Training Sample Shortage. Remote Sensing. 2024; 16(14):2553. https://doi.org/10.3390/rs16142553
Chicago/Turabian StyleZhang, Jianhua, Shucheng You, Aixia Liu, Lijian Xie, Chenhao Huang, Xu Han, Penghan Li, Yixuan Wu, and Jinsong Deng. 2024. "Winter Wheat Mapping Method Based on Pseudo-Labels and U-Net Model for Training Sample Shortage" Remote Sensing 16, no. 14: 2553. https://doi.org/10.3390/rs16142553
APA StyleZhang, J., You, S., Liu, A., Xie, L., Huang, C., Han, X., Li, P., Wu, Y., & Deng, J. (2024). Winter Wheat Mapping Method Based on Pseudo-Labels and U-Net Model for Training Sample Shortage. Remote Sensing, 16(14), 2553. https://doi.org/10.3390/rs16142553