
Voxel- and Bird’s-Eye-View-Based Semantic Scene Completion for LiDAR Point Clouds


Abstract
1. Introduction
- •
- We propose an integrated network that merges a 3D SSCNet with a 2D SSCNet. For the former, a highly efficient MSB is devised to segment small, distant, and dense objects. Moreover, an LSB is developed to grasp the overall layout information of the outdoor scenes.
- •
- We propose the 2D SSCNet to process bird’s-eye-view (BEV) features of the scene, which deliver precise spatial layout information in the two-dimensional space, thereby enhancing the overall performance of 3D semantic scene completion.
- •
- We propose FFM for an improved interaction of the information from the 3D SSCNet and the 2D SSCNet, where the strengths of the other can enhance each set of features.
2. Related Work
2.1. Image-Based Methods
2.2. Point-Based Methods
2.3. Voxel-Based Methods
2.4. Multi-Modality-Based Methods
3. Methodology
3.1. Methodology Overview
3.2. 3D Semantic Scene Completion Network
3.2.1. Layout-Aware Semantic Block
3.2.2. Multi-Scale Convolutional Block
3.3. 2D Semantic Scene Completion Network
3.4. Feature Fusion Module
3.4.1. Feature Exchange Stage
3.4.2. Feature Fusion Stage
3.5. Overall objective
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
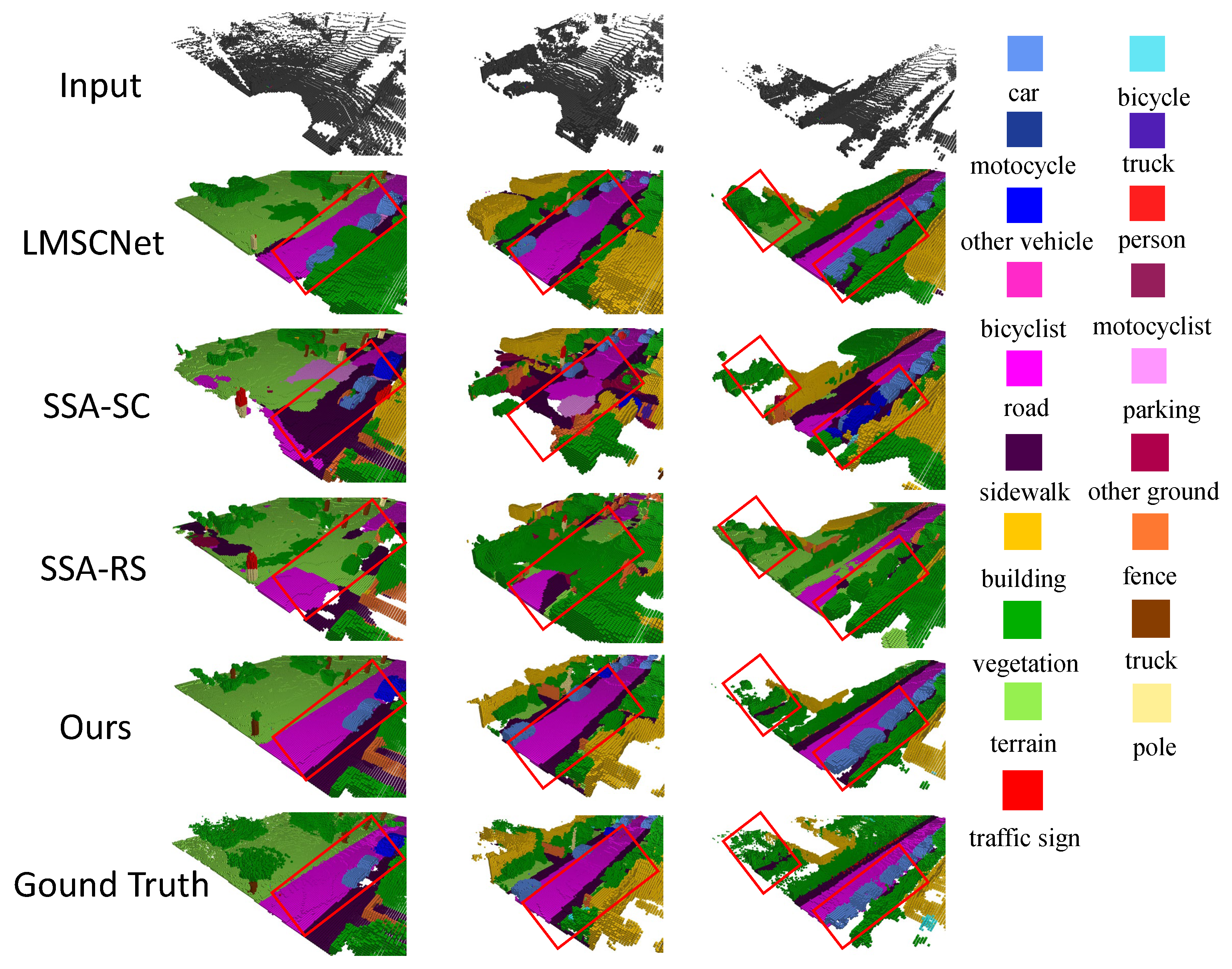
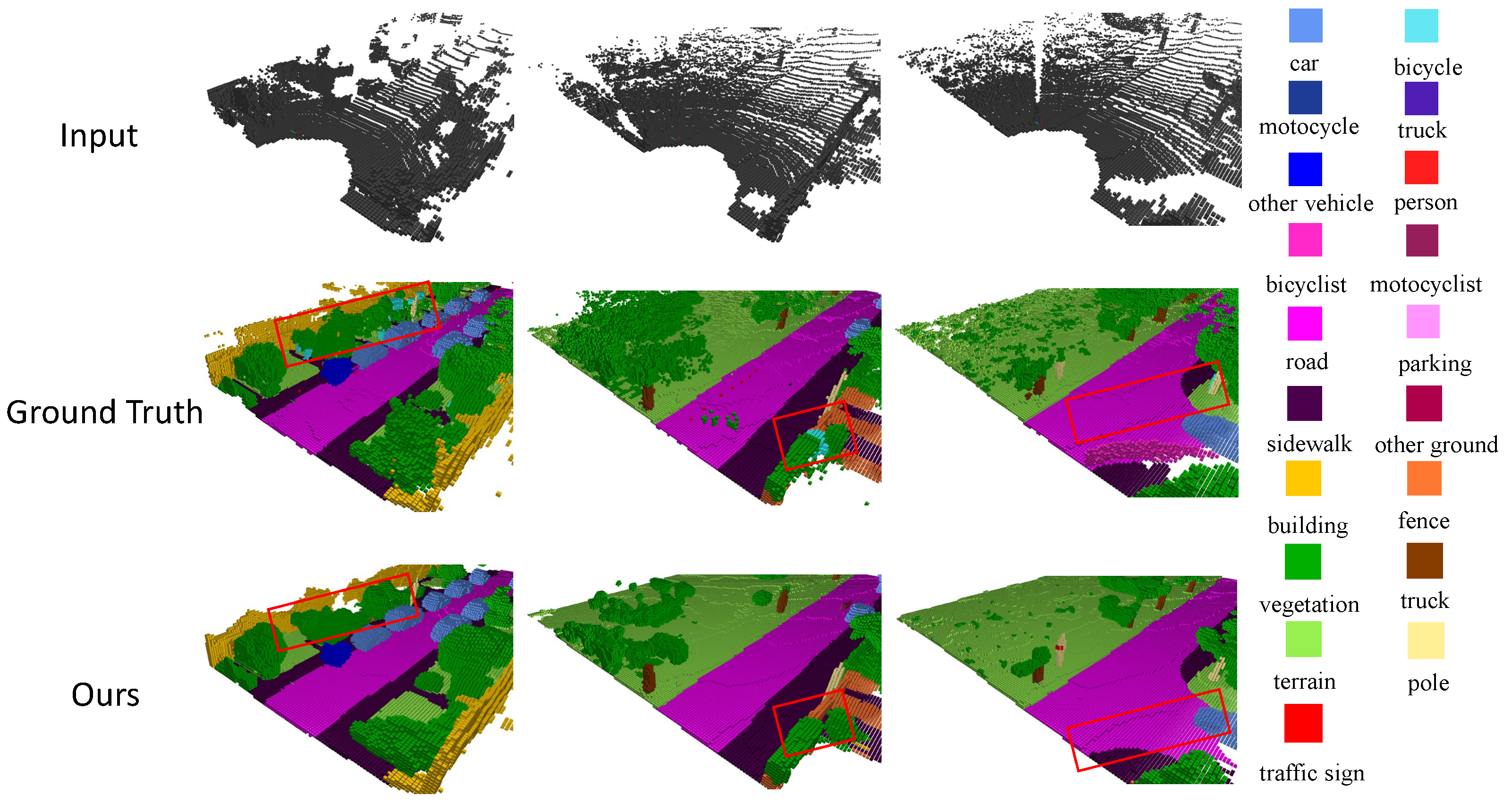
4.3. Results
4.4. Ablation Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Song, S.; Yu, F.; Zeng, A.; Chang, A.X.; Savva, M.; Funkhouser, T. Semantic scene completion from a single depth image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1746–1754. [Google Scholar]
- Roldao, L.; de Charette, R.; Verroust-Blondet, A. Lmscnet: Lightweight multiscale 3d semantic completion. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 111–119. [Google Scholar]
- Yan, X.; Gao, J.; Li, J.; Zhang, R.; Li, Z.; Huang, R.; Cui, S. Sparse single sweep lidar point cloud segmentation via learning contextual shape priors from scene completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 3101–3109. [Google Scholar]
- Cheng, R.; Agia, C.; Ren, Y.; Li, X.; Bingbing, L. S3cnet: A sparse semantic scene completion network for lidar point clouds. In Proceedings of the Conference on Robot Learning, PMLR, London, UK, 8–11 November 2021; pp. 2148–2161. [Google Scholar]
- Yang, X.; Zou, H.; Kong, X.; Huang, T.; Liu, Y.; Li, W.; Wen, F.; Zhang, H. Semantic segmentation-assisted scene completion for lidar point clouds. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3555–3562. [Google Scholar]
- Xia, Z.; Liu, Y.; Li, X.; Zhu, X.; Ma, Y.; Li, Y.; Hou, Y.; Qiao, Y. SCPNet: Semantic Scene Completion on Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–19 June 2023; pp. 17642–17651. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 29 October–1 November 2019; pp. 9297–9307. [Google Scholar]
- Guo, Y.X.; Tong, X. View-volume network for semantic scene completion from a single depth image. arXiv 2018, arXiv:1806.05361. [Google Scholar]
- Wang, Y.; Tan, D.J.; Navab, N.; Tombari, F. Adversarial semantic scene completion from a single depth image. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 426–434. [Google Scholar]
- Wang, Y.; Tan, D.J.; Navab, N.; Tombari, F. Forknet: Multi-branch volumetric semantic completion from a single depth image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 29 October–1 November 2019; pp. 8608–8617. [Google Scholar]
- Zhang, P.; Liu, W.; Lei, Y.; Lu, H.; Yang, X. Cascaded context pyramid for full-resolution 3d semantic scene completion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 29 October–1 November 2019; pp. 7801–7810. [Google Scholar]
- Dai, A.; Diller, C.; Nießner, M. Sg-nn: Sparse generative neural networks for self-supervised scene completion of rgb-d scans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 849–858. [Google Scholar]
- Wu, S.C.; Tateno, K.; Navab, N.; Tombari, F. Scfusion: Real-time incremental scene reconstruction with semantic completion. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 801–810. [Google Scholar]
- Cao, A.Q.; de Charette, R. Monoscene: Monocular 3d semantic scene completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3991–4001. [Google Scholar]
- Li, Y.; Yu, Z.; Choy, C.; Xiao, C.; Alvarez, J.M.; Fidler, S.; Feng, C.; Anandkumar, A. Voxformer: Sparse voxel transformer for camera-based 3d semantic scene completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9087–9098. [Google Scholar]
- Li, B.; Sun, Y.; Jin, X.; Zeng, W.; Zhu, Z.; Wang, X.; Zhang, Y.; Okae, J.; Xiao, H.; Du, D. StereoScene: BEV-Assisted Stereo Matching Empowers 3D Semantic Scene Completion. arXiv 2023, arXiv:2303.13959. [Google Scholar]
- Jiang, H.; Cheng, T.; Gao, N.; Zhang, H.; Liu, W.; Wang, X. Symphonize 3D Semantic Scene Completion with Contextual Instance Queries. arXiv 2023, arXiv:2306.15670. [Google Scholar]
- Miao, R.; Liu, W.; Chen, M.; Gong, Z.; Xu, W.; Hu, C.; Zhou, S. Occdepth: A depth-aware method for 3d semantic scene completion. arXiv 2023, arXiv:2302.13540. [Google Scholar]
- Hayler, A.; Wimbauer, F.; Muhle, D.; Rupprecht, C.; Cremers, D. S4C: Self-Supervised Semantic Scene Completion with Neural Fields. arXiv 2023, arXiv:2310.07522. [Google Scholar]
- Mei, J.; Yang, Y.; Wang, M.; Zhu, J.; Zhao, X.; Ra, J.; Li, L.; Liu, Y. Camera-based 3D Semantic Scene Completion with Sparse Guidance Network. arXiv 2023, arXiv:2312.05752. [Google Scholar]
- Rist, C.B.; Schmidt, D.; Enzweiler, M.; Gavrila, D.M. Scssnet: Learning spatially-conditioned scene segmentation on lidar point clouds. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1086–1093. [Google Scholar]
- Wang, P.S.; Liu, Y.; Tong, X. Deep octree-based CNNs with output-guided skip connections for 3D shape and scene completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 266–267. [Google Scholar]
- Nie, Y.; Hou, J.; Han, X.; Nießner, M. Rfd-net: Point scene understanding by semantic instance reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4608–4618. [Google Scholar]
- Zhang, S.; Li, S.; Hao, A.; Qin, H. Point cloud semantic scene completion from rgb-d images. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 3385–3393. [Google Scholar]
- Rist, C.B.; Emmerichs, D.; Enzweiler, M.; Gavrila, D.M. Semantic scene completion using local deep implicit functions on lidar data. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7205–7218. [Google Scholar] [CrossRef] [PubMed]
- Xiong, Y.; Ma, W.C.; Wang, J.; Urtasun, R. Learning Compact Representations for LiDAR Completion and Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1074–1083. [Google Scholar]
- Xu, J.; Li, X.; Tang, Y.; Yu, Q.; Hao, Y.; Hu, L.; Chen, M. Casfusionnet: A cascaded network for point cloud semantic scene completion by dense feature fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 3018–3026. [Google Scholar]
- Li, H.; Dong, J.; Wen, B.; Gao, M.; Huang, T.; Liu, Y.H.; Cremers, D. DDIT: Semantic Scene Completion via Deformable Deep Implicit Templates. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 21894–21904. [Google Scholar]
- Zhang, J.; Zhao, H.; Yao, A.; Chen, Y.; Zhang, L.; Liao, H. Efficient semantic scene completion network with spatial group convolution. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 733–749. [Google Scholar]
- Dai, A.; Ritchie, D.; Bokeloh, M.; Reed, S.; Sturm, J.; Nießner, M. Scancomplete: Large-scale scene completion and semantic segmentation for 3d scans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4578–4587. [Google Scholar]
- Zou, H.; Yang, X.; Huang, T.; Zhang, C.; Liu, Y.; Li, W.; Wen, F.; Zhang, H. Up-to-Down Network: Fusing Multi-Scale Context for 3D Semantic Scene Completion. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 16–23. [Google Scholar]
- Li, P.; Shi, Y.; Liu, T.; Zhao, H.; Zhou, G.; Zhang, Y.Q. Semi-supervised implicit scene completion from sparse LiDAR. arXiv 2021, arXiv:2111.14798. [Google Scholar]
- Liu, S.; Hu, Y.; Zeng, Y.; Tang, Q.; Jin, B.; Han, Y.; Li, X. See and think: Disentangling semantic scene completion. Adv. Neural Inf. Process. Syst. 2018, 31, 261–272. [Google Scholar]
- Guedes, A.B.S.; de Campos, T.E.; Hilton, A. Semantic scene completion combining colour and depth: Preliminary experiments. arXiv 2018, arXiv:1802.04735. [Google Scholar]
- Li, J.; Liu, Y.; Yuan, X.; Zhao, C.; Siegwart, R.; Reid, I.; Cadena, C. Depth based semantic scene completion with position importance aware loss. IEEE Robot. Autom. Lett. 2019, 5, 219–226. [Google Scholar] [CrossRef]
- Garbade, M.; Chen, Y.T.; Sawatzky, J.; Gall, J. Two stream 3d semantic scene completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Li, J.; Liu, Y.; Gong, D.; Shi, Q.; Yuan, X.; Zhao, C.; Reid, I. Rgbd based dimensional decomposition residual network for 3d semantic scene completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7693–7702. [Google Scholar]
- Chen, X.; Lin, K.Y.; Qian, C.; Zeng, G.; Li, H. 3d sketch-aware semantic scene completion via semi-supervised structure prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4193–4202. [Google Scholar]
- Li, S.; Zou, C.; Li, Y.; Zhao, X.; Gao, Y. Attention-based multi-modal fusion network for semantic scene completion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11402–11409. [Google Scholar]
- Liu, Y.; Li, J.; Yan, Q.; Yuan, X.; Zhao, C.; Reid, I.; Cadena, C. 3D gated recurrent fusion for semantic scene completion. arXiv 2020, arXiv:2002.07269. [Google Scholar]
- Li, J.; Wang, P.; Han, K.; Liu, Y. Anisotropic convolutional neural networks for RGB-D based semantic scene completion. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8125–8138. [Google Scholar] [CrossRef] [PubMed]
- Cai, Y.; Chen, X.; Zhang, C.; Lin, K.Y.; Wang, X.; Li, H. Semantic scene completion via integrating instances and scene in-the-loop. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 324–333. [Google Scholar]
- Li, J.; Ding, L.; Huang, R. Imenet: Joint 3d semantic scene completion and 2d semantic segmentation through iterative mutual enhancement. arXiv 2021, arXiv:2106.15413. [Google Scholar]
- Dourado, A.; Guth, F.; de Campos, T. Data augmented 3d semantic scene completion with 2d segmentation priors. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 3781–3790. [Google Scholar]
- Wang, X.; Lin, D.; Wan, L. Ffnet: Frequency fusion network for semantic scene completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 22 February–1 March 2022; Volume 36, pp. 2550–2557. [Google Scholar]
- Tang, J.; Chen, X.; Wang, J.; Zeng, G. Not all voxels are equal: Semantic scene completion from the point-voxel perspective. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 22 February–1 March 2022; Volume 36, pp. 2352–2360. [Google Scholar]
- Fu, R.; Wu, H.; Hao, M.; Miao, Y. Semantic scene completion through multi-level feature fusion. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 8399–8406. [Google Scholar]
- Wang, F.; Zhang, D.; Zhang, H.; Tang, J.; Sun, Q. Semantic Scene Completion with Cleaner Self. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 867–877. [Google Scholar]
- Dong, H.; Ma, E.; Wang, L.; Wang, M.; Xie, W.; Guo, Q.; Li, P.; Liang, L.; Yang, K.; Lin, D. Cvsformer: Cross-view synthesis transformer for semantic scene completion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 8874–8883. [Google Scholar]
- Cao, H.; Behnke, S. SLCF-Net: Sequential LiDAR-Camera Fusion for Semantic Scene Completion using a 3D Recurrent U-Net. arXiv 2024, arXiv:2403.08885. [Google Scholar]
- Hou, Y.; Zhu, X.; Ma, Y.; Loy, C.C.; Li, Y. Point-to-voxel knowledge distillation for lidar semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 8479–8488. [Google Scholar]
- Tang, L.; Zhan, Y.; Chen, Z.; Yu, B.; Tao, D. Contrastive boundary learning for point cloud segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8489–8499. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Li, J.; Hassani, A.; Walton, S.; Shi, H. Convmlp: Hierarchical convolutional mlps for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6307–6316. [Google Scholar]
- Mei, J.; Yang, Y.; Wang, M.; Huang, T.; Yang, X.; Liu, Y. SSC-RS: Elevate LiDAR Semantic Scene Completion with Representation Separation and BEV Fusion. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 1–8. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | mIoU | Completion | Precision | Recall | Parameters (M) | Car | Bicycle | Motorcycle | Truck | Other Vehicle | Person | Bicyclist | Motorcyclist | Road | Parking | Sidewalks | Other Ground | Building | Fence | Vegetation | Trunk | Terrain | Pole | Traffic Sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LMSCNet-SS [2] | 16.8 | 54.2 | - | - | 0.4 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | |
| UDNet [31] | 20.7 | 58.9 | 78.5 | 70.9 | - | 42.1 | 1.8 | 2.3 | 25.7 | 11.2 | 2.5 | 1.2 | 0.0 | 67.0 | 20.3 | 37.2 | 2.2 | 36.0 | 11.9 | 40.1 | 18.3 | 45.8 | 23.0 | 3.8 |
| Local-DIFs [25] | 26.1 | 57.8 | - | - | - | 51.3 | 4.3 | 3.3 | 32.3 | 10.6 | 15.7 | 24.7 | 0.0 | 71.2 | 31.8 | 43.8 | 3.3 | 38.6 | 13.6 | 40.1 | 19.6 | 50.6 | 25.7 | 14.0 |
| SSA-SC [5] | 24.5 | 58.2 | 78.5 | 69.3 | 41.0 | 47.0 | 9.2 | 7.4 | 39.7 | 19.1 | 6.3 | 3.2 | 0.0 | 72.8 | 21.0 | 44.3 | 4.1 | 41.5 | 15.2 | 41.9 | 22.0 | 49.5 | 17.9 | 4.4 |
| JS3C-Net [3] | 24.0 | 57.0 | 71.5 | 73.5 | 3.1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | |
| SSC-RS [56] | 24.8 | 58.6 | 78.5 | 69.8 | 23.0 | 46.8 | 1.5 | 6.9 | 41.5 | 19.8 | 6.2 | 1.5 | 0.0 | 73.8 | 26.6 | 45.3 | 2.1 | 41.0 | 15.8 | 42.6 | 22.2 | 50.6 | 17.9 | 4.6 |
| S3CNet [4] | 33.1 | 57.1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| SCPNet [6] w/o downsampling | 37.2 | 49.9 | - | - | - | 50.5 | 28.5 | 31.7 | 58.4 | 41.4 | 19.4 | 19.9 | 0.2 | 70.5 | 60.9 | 52.0 | 20.2 | 34.1 | 33.0 | 35.3 | 33.7 | 51.9 | 38.3 | 27.5 |
| SCPNet [6] w downsampling | 33.1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| Ours | 35.7 | 51.4 | 83.5 | 57.2 | 40.0 | 46.8 | 20.7 | 26.7 | 49.6 | 41.1 | 8.3 | 4.4 | 0.0 | 73.7 | 58.8 | 54.0 | 27.6 | 36.4 | 38.2 | 40.3 | 35.7 | 56.6 | 37.7 | 21.4 |
| Method | mIoU | Completion | Car | Bicycle | Motorcycle | Truck | Other Vehicle | Person | Bicyclist | Motorcyclist | Road | Parking | Sidewalks | Other Ground | Building | Fence | Vegetation | Trunk | Terrain | Pole | Traffic Sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| w/o LSB | 28.9 | 44.9 | 41.8 | 8.9 | 3.2 | 38.8 | 19.8 | 7.8 | 3.1 | 7.3 | 70.6 | 56.8 | 49.3 | 30.6 | 32.4 | 37.9 | 33.8 | 28.5 | 53.3 | 17.4 | 5.8 |
| w/o MSB | 26.7 | 39.1 | 39.0 | 6.9 | 13.7 | 42.3 | 22.0 | 5.2 | 0.0 | 0.0 | 66.4 | 48.7 | 46.2 | 18.5 | 26.5 | 37.1 | 27.6 | 34.7 | 44.2 | 23.2 | 4.6 |
| w/o 2D SSCNet | 31.9 | 46.4 | 44.8 | 14.3 | 29.8 | 45.9 | 18.8 | 9.3 | 2.5 | 2.7 | 72.5 | 57.2 | 52.2 | 32.6 | 32.2 | 37.3 | 34.8 | 35.0 | 54.0 | 22.9 | 7.5 |
| w/o FFM | 33.9 | 49.0 | 45.2 | 30.1 | 33.3 | 50.6 | 38.5 | 9.4 | 1.6 | 0.0 | 71.4 | 56.3 | 50.6 | 27.6 | 34.2 | 35.6 | 36.7 | 36.3 | 55.6 | 25.2 | 5.2 |
| Full Model | 35.7 | 51.4 | 46.8 | 20.7 | 26.7 | 49.6 | 41.1 | 8.3 | 4.4 | 0.0 | 73.7 | 58.8 | 54.0 | 27.6 | 36.4 | 38.2 | 40.3 | 35.7 | 56.6 | 37.7 | 21.4 |
| Methods | mIoU | Completion | Car | Bicycle | Motorcycle | Truck | Other Vehicle | Person | Bicyclist | Motorcyclist | Road | Parking | Sidewalks | Other Ground | Building | Fence | Vegetation | Trunk | Terrain | Pole | Traffic Sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Our Method w/o MSB | 26.7 | 39.1 | 39.0 | 6.9 | 13.7 | 42.3 | 22.0 | 5.2 | 0.0 | 0.0 | 66.4 | 48.7 | 46.2 | 18.5 | 26.5 | 37.1 | 27.6 | 34.7 | 44.2 | 23.2 | 4.6 |
| Our Method w MSB | 35.7 | 51.4 | 46.8 | 20.7 | 26.7 | 49.6 | 41.1 | 8.3 | 4.4 | 0 | 73.7 | 58.8 | 54.0 | 27.6 | 36.4 | 38.2 | 40.3 | 35.7 | 56.6 | 37.7 | 21.4 |
| Methods | mIoU | Completion | Car | Bicycle | Motorcycle | Truck | Other Vehicle | Person | Bicyclist | Motorcyclist | Road | Parking | Sidewalks | Other Ground | Building | Fence | Vegetation | Trunk | Terrain | Pole | Traffic Sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Our Method w/o 2D SSCNet | 31.9 | 46.4 | 44.8 | 14.3 | 29.8 | 45.9 | 18.8 | 9.3 | 2.5 | 2.7 | 72.5 | 57.2 | 52.2 | 32.6 | 32.2 | 37.3 | 34.8 | 35.0 | 54.0 | 22.9 | 7.5 |
| Our Method w 2D SSCNet | 35.7 | 51.4 | 46.8 | 20.7 | 26.7 | 49.6 | 41.1 | 8.3 | 4.4 | 0 | 73.7 | 58.8 | 54.0 | 27.6 | 36.4 | 38.2 | 40.3 | 35.7 | 56.6 | 37.7 | 21.4 |
| Methods | mIoU | Completion | Car | Bicycle | Motorcycle | Truck | Other Vehicle | Person | Bicyclist | Motorcyclist | Road | Parking | Sidewalks | Other Ground | Building | Fence | Vegetation | Trunk | Terrain | Pole | Traffic Sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Our Method w/o FFM | 33.9 | 49.0 | 45.2 | 30.1 | 33.3 | 50.6 | 38.5 | 9.4 | 1.6 | 0.0 | 71.4 | 56.3 | 50.6 | 27.6 | 34.2 | 35.6 | 36.7 | 36.3 | 55.6 | 25.2 | 5.2 |
| Our Method w FFM | 35.7 | 51.4 | 46.8 | 20.7 | 26.7 | 49.6 | 41.1 | 8.3 | 4.4 | 0 | 73.7 | 58.8 | 54.0 | 27.6 | 36.4 | 38.2 | 40.3 | 35.7 | 56.6 | 37.7 | 21.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, L.; Akhtar, N.; Vice, J.; Mian, A. Voxel- and Bird’s-Eye-View-Based Semantic Scene Completion for LiDAR Point Clouds. Remote Sens. 2024, 16, 2266. https://doi.org/10.3390/rs16132266
Liang L, Akhtar N, Vice J, Mian A. Voxel- and Bird’s-Eye-View-Based Semantic Scene Completion for LiDAR Point Clouds. Remote Sensing. 2024; 16(13):2266. https://doi.org/10.3390/rs16132266
Chicago/Turabian StyleLiang, Li, Naveed Akhtar, Jordan Vice, and Ajmal Mian. 2024. "Voxel- and Bird’s-Eye-View-Based Semantic Scene Completion for LiDAR Point Clouds" Remote Sensing 16, no. 13: 2266. https://doi.org/10.3390/rs16132266
APA StyleLiang, L., Akhtar, N., Vice, J., & Mian, A. (2024). Voxel- and Bird’s-Eye-View-Based Semantic Scene Completion for LiDAR Point Clouds. Remote Sensing, 16(13), 2266. https://doi.org/10.3390/rs16132266