1. Introduction
Satellite-derived Land Use and Land Cover (LULC) products serve as vital data sources for an increasing number of applications, such as urban planning [
1], ecological evaluation [
2], climate change analysis [
3], agricultural management [
4], and policy making [
5]. In light of a rapidly developing world, higher resolution and regularly updated LULC maps are required [
6]. So far, annual LULC products have been produced even at a global scale, including the Moderate Resolution Imaging Spectroradiometer (MODIS) land cover-type product MCD12Q1 [
7,
8] (2001–2018, 500 m), European Space Agency Climate Change Initiative (ESA-CCI) Land Cover [
9,
10] (1992–2020, 300 m), and Copernicus Global Land Service Dynamic Land Cover Map (CGLS-LC100) (2015–2019, 100 m). However, these global products have coarse spatial resolutions. With the free availability of high-resolution satellite data, e.g., Landsat (30 m in visible and near-infrared bands) and Sentinel (10 m), land cover maps with more spatial detail can be generated. Recently, higher-resolution satellite-derived global urban land cover maps are available. Gong et al. [
11] generated and publicly released the first 30 m global land cover product in 2010, i.e., Finer Resolution Observation and Monitoring of Global Land Cover (FROM-GLC). More recently, 30 m FROM-GLC for the years 2010/2015/2017, 10 m FROM-GLC in 2017 [
12], and 10 m ESA WorldCover Product for 2020 and 2021 [
13] have been produced. In 2022, the first near real-time global product using Sentinel images, Dynamic World [
14], with the spatial resolution of 10 m, was proposed. Although the spatial resolution and temporal frequency of these products are significantly improved, 10 m products only provide LULC data preceding 2015 since the 10 m Sentinel-2 satellite was launched on 27 June 2015. For longer time-series high-resolution satellites images (1984–current), the 30 m Landsat offers suitable alternatives but fails to provide fine-grained LULC information. Therefore, generating high-resolution LULC maps using relatively lower-resolution remote sensing images is of great importance.
In general, there are two kinds of approaches to generate high-resolution maps from lower-resolution images: stage-wise and end-to-end approaches (
Table 1). Stage-wise approaches conduct semantic segmentation and super resolution (SR) independently [
15]. For example, Cui et al. [
16] proposed a novel stage-wise green tide extraction method for MODIS images. In this method, a super resolution model was trained with high spatial resolution Gaofen-1, and then semantic segmentation network for images with improved spatial resolution was introduced. Fu, et al. [
17] proposed a method to classify marsh vegetation using multi-resolution multi-spectral and hyperspectral images, where independent super resolution and semantic segmentation techniques were employed and combined. Zhu et al. [
18] proposed a CNN-based super-resolution method for multi-temporal classification. It was conducted in two stages: image super-resolution preprocessing and LULC classification. Huang, et al. [
19] employed Enhanced Super-Resolution Generative Adversarial Networks for super-resolution image construction, subsequently integrating semantic segmentation models for the classification of tree species. Since restored images with better super resolution quality do not always guarantee better semantic segmentation results and super-resolution and semantic segmentation can promote each other [
20], end-to-end approaches with interaction between these two tasks are introduced. Xu et al. [
15] proposed an end-to-end network to extract high-resolution building maps from low-resolution, and high-resolution images are not needed in the training phase. In [
21], the multi-task encoder-decoder network accepts low-resolution images as input and uses two different branches for super resolution and segmentation. Information interaction of these two subtasks is realized via shared decoder and overall weighted loss. Similar work in [
22] used a multi-loss approach for training a multi-task network. In addition, a feature affinity loss was added to combine the learning of both branches. Salgueiro et al. [
23] introduced a multi-task network designed to generate super-resolution images and semantic segmentation results utilizing freely available Sentinel-2 imagery. These studies jointly train super resolution and semantic segmentation using overall loss function, and information interaction between the two tasks relies on shared network structures. These kinds of networks attempt to solve the super resolution and semantic segmentation simultaneously, which can work well when high-resolution target images and low-resolution input images are just original images and their corresponding down-sampling results. The pivotal consideration is to attain an optimal balance in multi-task joint learning. However, in real-world situations, remote sensing images suffer from various image degradation factors such as blur and noise, due to imperfect illumination, atmospheric propagation, lens imaging, sensor quantification, temporal difference, etc. [
24]. Therefore, super resolution for real multi-resolution satellite images is more challenging. When coupled with the semantic segmentation task and treated equally, super resolution limits the final segmentation performance.
Super resolution aided semantic segmentation is another research direction where semantic segmentation and super resolution are considered as main and auxiliary tasks, respectively. As stated in [
25], main tasks are designed to produce final required output for an application, and auxiliary tasks serve for learning and supporting the main tasks. Following this research trajectory, in [
26], the main task is land cover classification and the super resolution task aims to increase the resolution of remote sensing images. In [
27], a target-guided feature super resolution network is proposed for vehicle detection, where features of small objects are enhanced for better detection results. However, a few existing methods have attempted to consider super resolution just as an auxiliary task by introducing a guidance module for main tasks under the constraint of super resolution. However, these methods still train the whole network in an end-to-end manner using a multi-task loss function. In addition, the employed datasets are just high-resolution remote sensing images and down-sampled low-resolution ones.
In summary, there are two main challenges in generating high-resolution LULC maps using relatively lower-resolution remote sensing images. Firstly, it is a predicament to guarantee the consistency of image degradation factors for real multi-resolution satellite images. Therefore, synthetic lower-resolution images generated by simple degradation models (e.g., bicubic down-sampling) can lead to domain gap, making models that do not generalize well to real-world data. At present, this domain gap between real lower-resolution and synthetic ones is very common and has not been solved. Second, higher super resolution accuracy does not guarantee better higher classification performance, especially for real multi-resolution satellite images. The general end-to-end training with multi-task loss function cannot deal with this problem. Therefore, how to treat the different tasks is very crucial. Based on these aforementioned problems, the deeply fused super resolution guided semantic segmentation network using real lower-resolution images is proposed. The main contributions of this article are reflected in the following aspects.
- (1)
We introduce an open-source, large-scale, diverse dataset for super resolution and semantic segmentation tasks, situated within real-world scenarios. This dataset serves as a pivotal resource, directing the capturing of intricate land cover details from lower-resolution remote sensing images. In this dataset, the testing and training data are from different cities, which enables performance evaluation in terms of generalization capability and transferability.
- (2)
We present a novel network architecture named the Deeply Fused Super Resolution Guided Semantic Segmentation Network (DFSRSSN), which combines super resolution and semantic segmentation tasks. By enhancing feature reuse of the super-resolution module, preserving detailed information, and fusing cross-resolution features, the finer-grained land cover information using lower-resolution remote sensing images was achieved. By integrating the super-resolution module into the semantic segmentation network, our model achieves generation of 10 m land cover maps using 30 m Landsat images, effectively enhancing spatial resolution. For training the entire network, we leverage pre-trained super resolution parameters to initialize the weights of the semantic segmentation module. This strategy expedites model convergence and improves prediction accuracy.
An overview of the created dataset for the super resolution guided semantic segmentation method is provided in
Section 2. The proposed method is presented in
Section 3, followed by the experiments and analysis of the experimental results in
Section 4. Finally,
Section 5 concludes this article.
2. Dataset and Methodology
In this paper, we created a dataset for a super resolution guided semantic segmentation network. Based on this dataset, we propose a novel deeply fused super resolution guided semantic segmentation network, denoted as DFSRSSN, for the purpose of generating 10 m land cover product from Landsat imagery, as shown in
Figure 1. The DFSRSSN comprises two fundamental components: (1) a super resolution module, i.e., Super Resolution Residual Network (SRResNet), and (2) a semantic segmentation module, i.e., Cross-Resolution Feature Fusion Network (CRFFNet). The performance of SR inherently affects the semantic segmentation module since SR features are fused in the semantic segmentation module. First, we train the super resolution module to achieve the maximum possible SR performance with the given architecture and data. Subsequently, pre-trained SR parameters, obtained through SRResNet, are leveraged as the initial weights during the training of the semantic segmentation module. This facilitates faster model convergence and higher prediction accuracy. This two-step training process enables the semantic segmentation module to learn to effectively leverage the predicted super resolution related information to enhance the classification of land cover types.
2.1. Dataset
The proposed dataset contains a total of 10,375 image patches (3.84 km × 3.84 km). This dataset includes 10 m Sentinel-2 images, 30 m Landsat-8 images, and 10 m European Space Agency (ESA) Land Cover Product. It should be noted that the ESA Land Cover products are mapped globally at a 10 m resolution for the years 2020 and 2021, utilizing Sentinel-1 and Sentinel-2 images. In addition, 8 categories of land cover (i.e., tree cover, shrubland, grassland, cropland, built-up, bare/sparse vegetation, permanent water bodies, and herbaceous wetland) are considered. In the experiments, Landsat-8 images with blue, green, red, and near-infrared bands (Band 2, Band 3, Band 4, and Band 5, respectively) were used as input, and Sentinel-2 images with the same four bands (B2, B3, B4, and B8, respectively) and 10 m ESA Land Cover Product of the year 2020 (ESA 2020) were used as output for super resolution and semantic segmentation tasks, respectively. The ESA 2020 achieved a global overall accuracy of 74.4%, as reported in [
28].
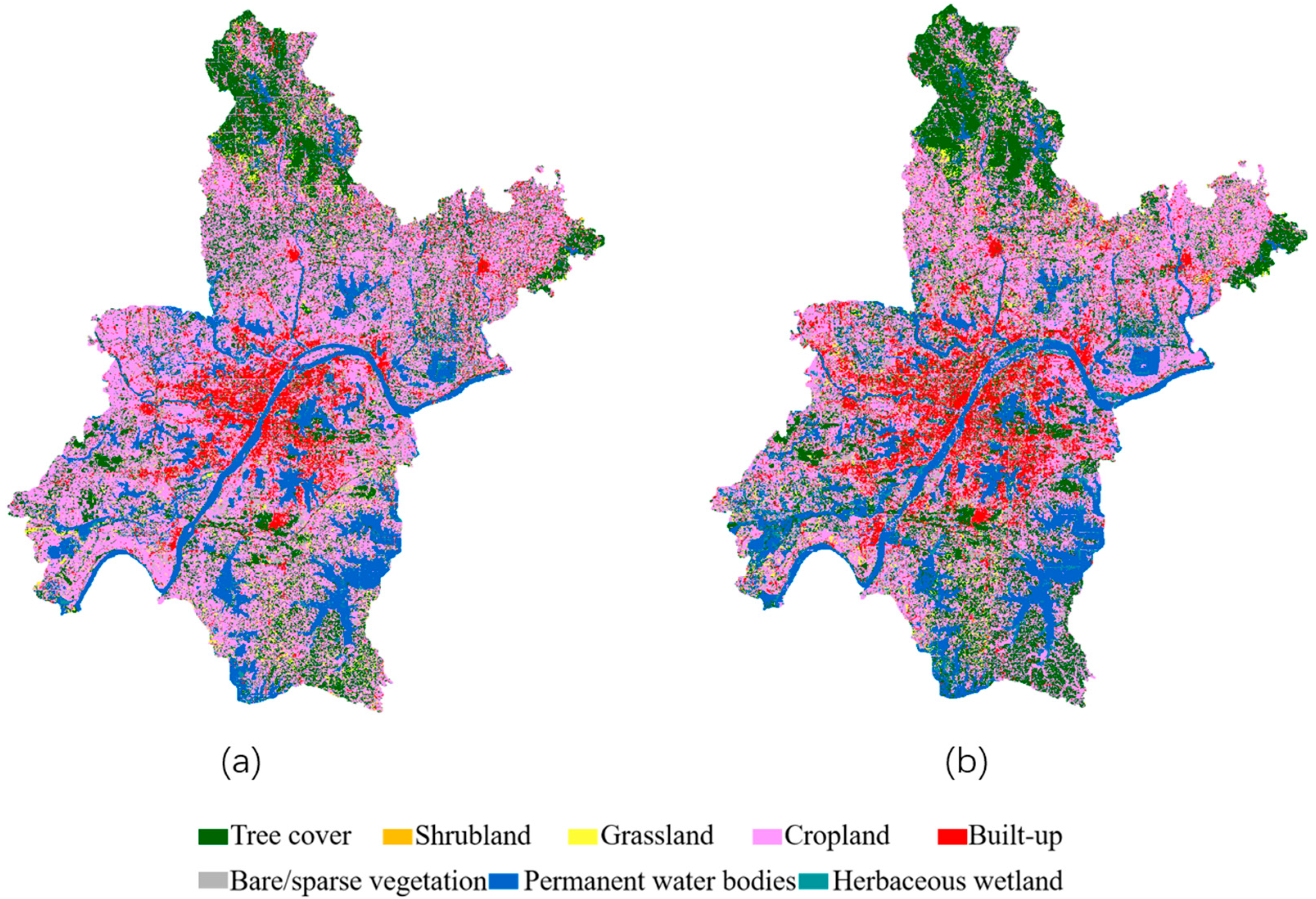
For model training and validation, a total of 20 Chinese cities were selected (
Table 2), including 2 first-tier cities, 1 second-tier city, 8 third-tier cities, 6 fourth-tier cities, and 3 fifth-tier cities. The 8707 image patches (3.84 km × 3.84 km) of these Chinese cities were split into 80% for training and 20% for testing (dataset I). In addition, a total of 4 cities, i.e., Wuhan, China (II); Kassel, Germany (III); Aschaffenburg, Germany (IV); and Joliet, US (V), were selected as additional testing datasets. The percentages for different land cover types in ESA Land Cover Product for the five different testing sets are provided in
Table 3. Dataset I has the same or similar data distribution as the training data since the data are from the same cities (i.e., 20 Chinese cities). The other four testing datasets (II–V) and training data are from different cities. Therefore, dataset I serves to evaluate model fitting performance on the training dataset, and datasets II–V can be used to properly evaluate the generalization capability and transferability of the model [
29].
In dataset I, the land cover class distribution is extremely unbalanced, ranging from 0.15% for shrubland to 45.42% for cropland. Furthermore, the class distribution varied among the other four datasets, exhibiting diverse compositions across different land cover types. Specifically, the majority class type for datasets III and IV is tree cover (46.56% and 54.04%, respectively), and the majority class type for datasets II and V is cropland (41.62% and 69.81%, respectively). Shrubland and herbaceous wetland are extremely rare minority classes with extremely low percentages. Therefore, generating 10 m LULC products using 30 m Landsat images not only faces challenges related to spatial resolution gap and absence of true labels but also involves addressing the issue of an extremely imbalanced long-tailed distribution of land cover classes.
2.2. Super Resolution Module
The super resolution module, built upon the SRResNet architecture, is deployed with the primary objective of improving the spatial resolution of low-resolution images (denoted as Im_LR). The spatial resolution is improved by learning a mapping between low-resolution images (Im_LR) and high-resolution images (Im_HR) while preserving spectral information. The SRResNet, employed as the underlying framework, is characterized by a succession of residual blocks, local and global residual connections, and a pixel shuffle block [
30]. The selection of SRResNet for this task is predicated on several rationale-driven considerations. First, the utilization of local and global residual learning can alleviate gradient vanishing problems in deep models, making it feasible to enhance the network performance in learning middle-frequency and high-frequency features and super-resolving images [
31]. Secondly, the integration of the pixel shuffle block within SRResNet plays a pivotal role in suppressing the deleterious effects of redundant features on super resolution results. In comparison to the conventional transpose convolution methods, the pixel shuffle block proves to be superior in its ability to yield super resolution results [
32]. It is noteworthy that the implementation of SRResNet in this study predominantly comprises 48 residual blocks and a shuffle block.
Peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) are two fundamental quantitative metrics for assessing the degree of similarity between super resolution images and their corresponding high-resolution counterparts. PSNR serves as a measure of image reconstruction quality with regard to noise. This is accomplished by comparing the grayscale values of corresponding pixels. On the other hand, SSIM delves into a more comprehensive evaluation by taking into account three key facets of image structure, namely brightness, contrast, and structure pattern [
33].
To ensure the preservation of pixel grayscale values and fine spatial details of the image, both PSNR and SSIM are integrated into the loss function. It is imperative to note that larger PSNR and SSIM values correspond to a superior quality of super resolution images. Accordingly, the training objective of the SRResNet revolves around the minimization of the ensuing loss function, denoted as follows:
2.3. Semantic Segmentation Module
For the task of semantic segmentation, we have opted for the ResUnet architecture as our foundational framework. This architectural choice is particularly well-suited for facilitating precise pixel-to-pixel semantic segmentation. ResUnet achieves this by establishing connectivity between coarse multi-level features extracted from the initial convolutional layers within the encoder and the corresponding layers within the decoder through the utilization of skip connections, thus synergizing the strengths inherent in both the Unet and residual learning [
34].
In this study, we have employed a ResUnet variant characterized by a nine-level architecture, indicating the depth of blocks in the network. This modified ResUnet architecture takes low-resolution images (Im_LR), super resolution images (Im_SR), and super resolution features (Fea_SR) as input, with the objective of producing a land cover (LC) map at a higher resolution. Consequently, adaptations to the classical ResUnet framework were imperative to address the challenge of cross-resolution feature fusion, resulting in the formulation of the CRFFNet.
As illustrated in
Figure 1, the CRFFNet contains three primary components, namely, an encoder with multiple inputs, up-sampling blocks, and the multi-level feature fusion within the decoder. More specifically, the Siamese encoder is structured with four down-sampling blocks, which share weights and serve the purpose of feature extraction. The input to the encoder is an image pair, i.e.,
Im_LR and
Im_SR. Subsequently, the down-sampled convolutional features are fused and fed into the Siamese decoder. However, it is essential to recognize that differences exist in the spatial dimensions of features derived from
Im_LR and
Im_SR at corresponding encoder levels. To address this incongruity, the up-sampling block (
UP) is introduced for features derived from
Im_LR, which is composed of two convolutions followed by bilinear interpolation up-sampling. In this manner, the cross-resolution feature fusion is described as follows:
where
and
denote the features derived from
Im_LR and
Im_SR, respectively, through the encoder. The variables
c,
h, and
w represent the number of channels, height, and width of the features, while
sf denotes the up-sampling factor. In this paper,
sf is set as 3 since the spatial resolution of
Im_LR is 3 times that in
Im_SR. The term
de represents deconvolution operations with a scale of 2 to up-sample the fused features at the previous level. In this way, the fused features at the
ith level (
) of the decoder are concatenated (
cat) by
FSR,
UP features for
FLR with the scaling factor of
sf, and deconvolution operations of features from the (
i − 1)th level (
).
Furthermore, to utilize the valuable features learned during the super resolution task and multi-scale features in the semantic segmentation task, the pixel shuffle outputs from the final residual blocks in the SRResNet and UP of different-level features in the decoder are concatenated with the output from the last up-sampling block in ResUnet. Ultimately, three convolution layers are employed to generate the final land cover map.
2.4. Implementation Details
Our model is implemented on the PyTorch framework, leveraging the computational power of a single NVIDIA RTX 4090 GPU. For optimization, we employed the Adam optimizer with a learning rate of 5 × 10−4 to minimize the loss function. The size of each input batch is 128 × 128 pixels with four spectral bands, and the batch size is set to 8. A total of 50 epochs is set for SRResNet and DFSRSSN to facilitate model convergence.
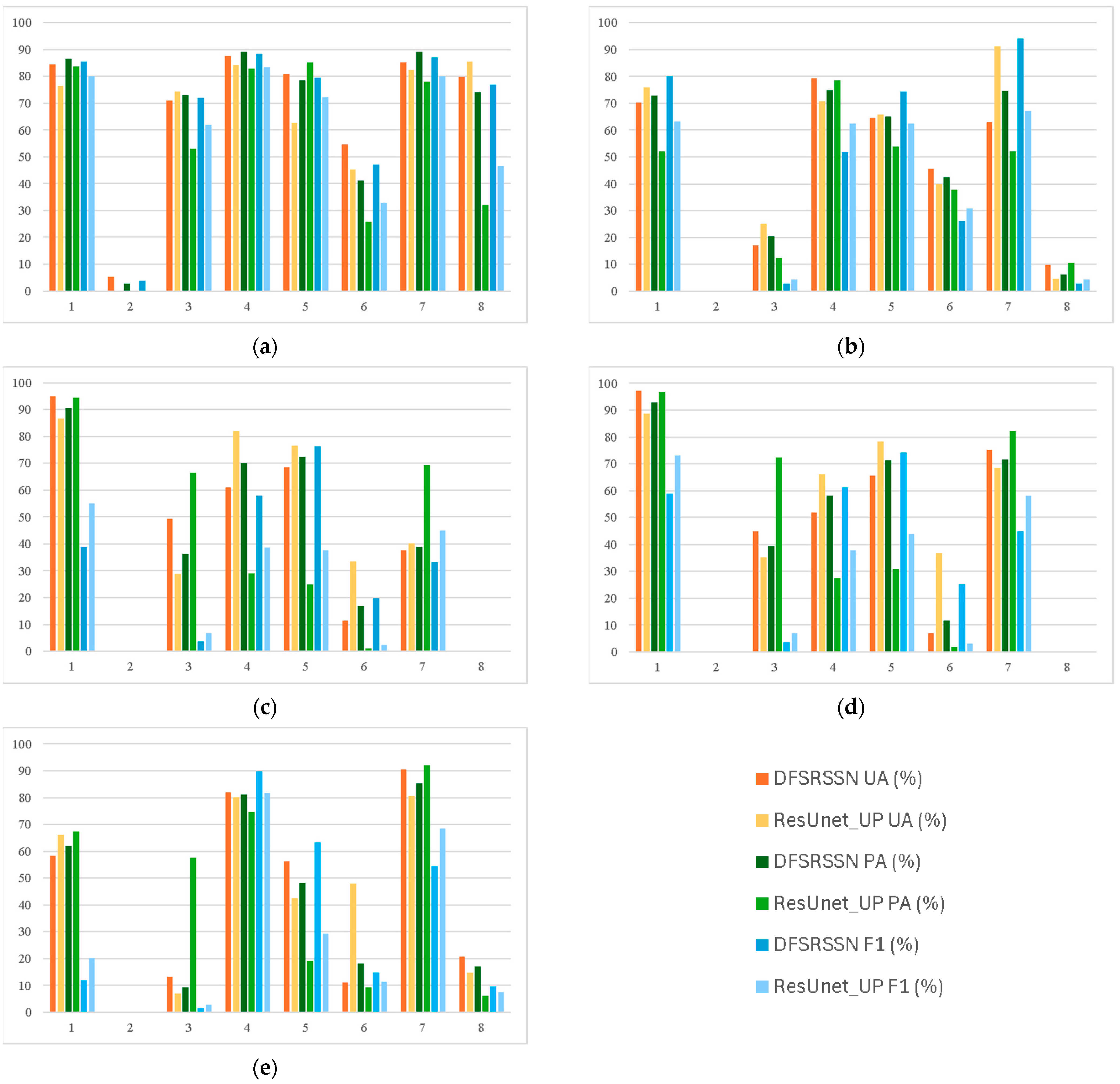
As for the evaluation of the proposed segmentation network, overall accuracy (
OA) [
35] and kappa coefficient (
KC) [
36] were used to evaluate the overall performance. We used user’s accuracy (
UA) [
37], producer’s accuracy (
PA) [
37], and
F1 score [
38] to evaluate the ability to classify different land cover types. These metrics are defined as follows:
where
xii is the number of correctly classified pixels for the
ith land cover type;
xi+ and
x+i is the number of pixels for the
ith land cover type in the classification result and reference data, respectively;
n and
N are the total number of land cover types and samples, respectively.
OA is calculated as the ratio between the number of correctly classified pixels and the total number of pixels.
KC is also used to measure the agreement between the classified result and the reference data but excluding chance agreement [
35].
KC is more appropriate with imbalanced class distributions than
OA.
UA quantifies the proportion of
ith land cover type in the classification result consistent with the reference data, while
PA quantifies the probability of
ith land cover type on the ground correctly classified by the classification result, thereby indicating commission errors and omission errors [
39].
F1 score, the harmonic mean of
UA and
PA, is a tradeoff metric to quantify class-wise commission errors and omission errors [
40].
5. Conclusions
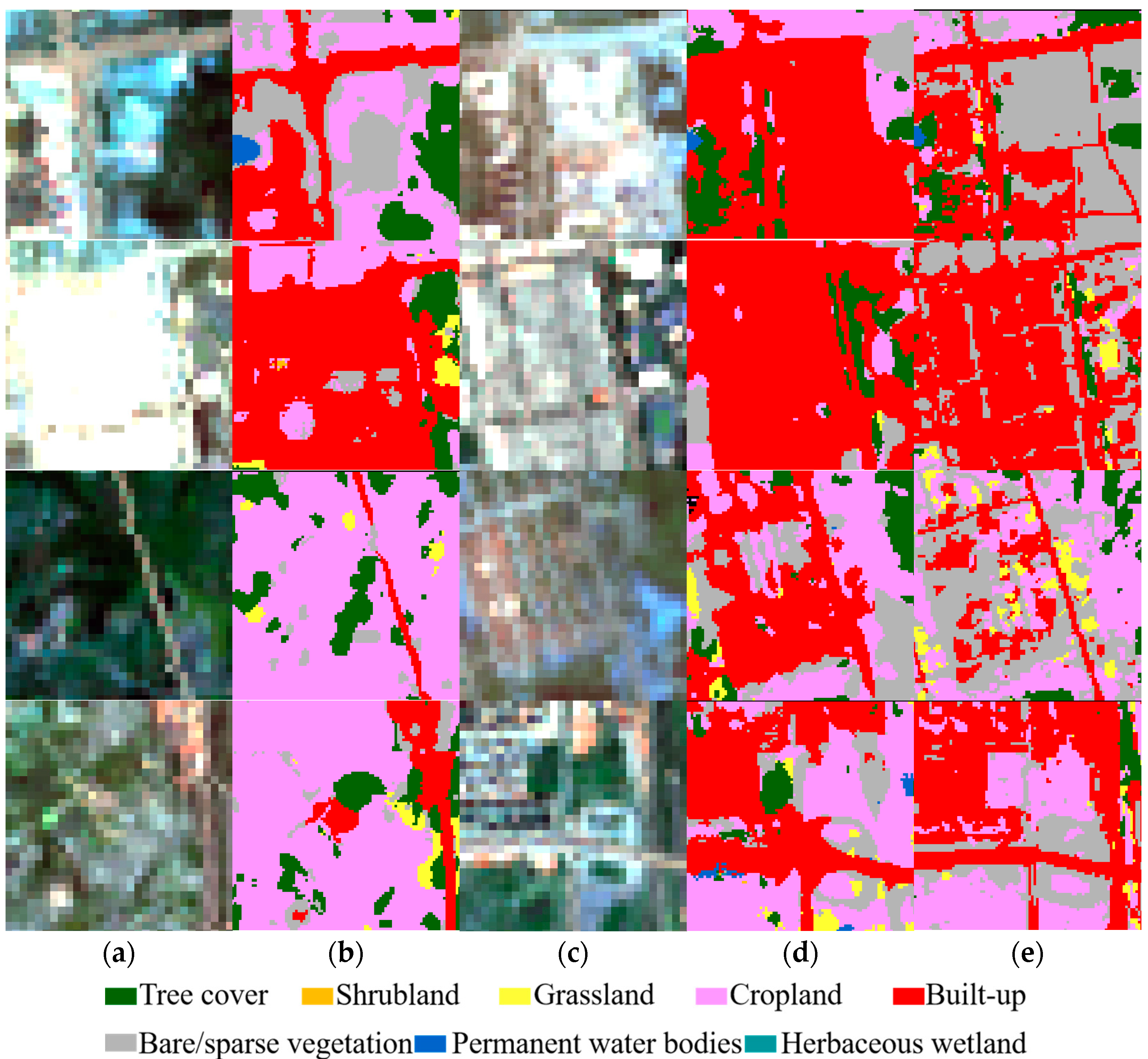
In this study, we proposed a deeply fused super resolution guided semantic seg-mentation network for generating high-resolution land cover maps using relatively lower-resolution remote sensing images. We introduced a large-scale and diverse dataset consisting of 10 m Sentinel-2 images, 30 m Landsat-8 images, and 10 m European Space Agency (ESA) Land Cover Product, encompassing 8 land cover categories. Our method integrates a super resolution module (SRResNet) and a semantic segmentation module (CRFFNet) to effectively leverage super resolution guided information for finer-resolution segmentation results. Through extensive experiments and analyses, we demonstrated the efficacy of our proposed method. DFSRSSN outperformed the baseline ResUnet with pixel shuffle blocks in terms of overall accuracy and kappa coefficient, achieving significant improvements in land cover classification accuracy. Furthermore, our method exhibited better spatial transferability across different testing datasets, showcasing its robustness in handling diverse landscape patterns and imaging conditions. Moreover, the multi-temporal results demonstrated the spatiotemporal transferability of our proposed method, enabling the generation of 10 m land cover maps for past scenarios preceding the availability of 10 m Sentinel data. This capability opens up avenues for studying long-term LULC changes at a finer spatial resolution. In addition, the comparison of the state-of-the-art full semantic segmentation models indicate that spatial details are fully exploited and presented in semantic segmentation results using super-resolution guided information. In conclusion, our study contributes to the advancement of high-resolution land cover mapping using remote sensing data, offering a valuable tool for urban planning, ecological evaluation, climate change analysis, agricultural management, and policy making. The integration of super resolution guided information into semantic segmentation networks represents a promising approach for enhancing the spatial resolution and accuracy of land cover mapping, thereby facilitating informed decision-making and sustainable development initiatives. Nevertheless, it is imperative to acknowledge certain limitations of our methodology. Label errors in the ESA Land Cover Product may cause overfitting to mislabeled data. Therefore, pseudo label refinement can be considered in a further study.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}