1. Introduction
Multi-target tracking (MTT) is a process that uses the sensor observations with clutter, missed detection, and noise to acquire the state vectors of targets at different time steps [
1,
2,
3]. It finds numerous applications in maritime surveillance, air traffic monitoring, self-driving vehicles, and advanced driver-assistance systems [
4], thereby attracting the extensive attention of scholars [
5,
6,
7,
8,
9]. Many approaches such as random finite set (RFS) [
1,
2], multiple hypothesis tracking [
10], and joint probabilistic data association [
11] have been proposed to perform multi-target tracking.
The conventional RFS methods for MTT only concern multi-object filtering [
1,
2]. Their objective is to estimate the object states at different time steps. These methods do not attempt to generate object trajectories. The typical representatives of the conventional RFS methods are the multi-Bernoulli filter [
12] and probability hypothesis density filter [
13,
14]. These two filters have also been extended by several scholars to track maneuvering targets [
15] and extended targets [
16,
17,
18,
19].
To break through the restriction of RFS on providing target trajectories, Vo et al. proposed the labeled RFS [
20,
21]. Unlike the RFS approach that only provides the states of objects, the labeled RFS approach can provide both the states of objects and their trajectories. Moreover, the high signal to noise ratio that is required in the RFS approach is also obviated in the labeled RFS approach. The labeled RFS approach can give higher tracking accuracy at a larger computational cost than the RFS approach. This is because the former uses multiple hypotheses, and the number of hypotheses may increase exponentially as the recursion increases. To decrease the computational cost of the labeled RFS approach, Vo et al. proposed an efficient implementation of the generalized labeled multi-Bernoulli (GLMB) filter [
22]. Based on the labeled RFS, the tracking filters for spawning objects [
23], weak objects [
24], maneuvering objects [
25], and extended objects [
26] have also been proposed by several scholars.
The choice or establishment of birth models in the RFS filters and labeled RFS filters is a challenging problem. The conventional RFS filters [
12,
13,
14] and labeled RFS filters [
20,
21,
22] assume that targets appear from fixed locations such as airports, wharves, or doors. This assumption disenables these filters to track the objects appearing from unknown locations. Several adaptive filters based on the RFS and labeled RFS have been proposed to break through this limitation. Instead of using the prior locations, the adaptive filters in [
27,
28,
29,
30] use the observations at each time step to form the birth models. The drawback of these filters is that they assume that the covariance matrix of each birth object is fixed and known. To overcome this drawback, the adaptive filters in [
31,
32,
33] use the measurements from two consecutive time steps to establish the birth models, and the adaptive GLMB (AGLMB) filter in [
34] uses the measurements from three consecutive time steps to generate the birth tracks. The main weakness of the AGLMB filter is that some of the newborn tracks may be false tracks. To decrease the false-track probability, combining the logic-based track initiation technique into the marginal multi-target Bayesian (MTB) filter, Liu et al. proposed the adaptive MTB filter with assignment of measurements (AAMMTB filter) [
35]. Compared with the AGLMB filter [
34], the AAMMTB filter achieves high tracking accuracy at a low computational cost [
35]. The AGLMB filter and AAMMTB filter use the observations of three time steps to generate the birth tracks. Each birth track is regarded as a real track in these two adaptive filters. The difference between them is that the AGLMB filter uses the rule-based track initiation technique, while the AAMMTB filter uses the logic-based track initiation technique. The experimental results have shown that the AAMMTB filter has better performance than the AGLMB filter and other adaptive filters [
35].
To track multiple targets more efficiently in the presence of unknown number of targets, missed detection, clutter, and noise, an adaptive multi-hypothesis marginal Bayes (AMHMB) filter is proposed in this article. Instead of delivering multiple hypotheses in the filtering recursion, the AMHMB filter propagates the probability density function (PDF) of each potential object and its existence probability. It uses the multiple hypotheses to solve the data association problem to form the PDFs of potential objects and their existence probabilities and employs the measurements from two time steps to generate the potential birth objects. Compared with the birth approach in [
29,
30], the birth approach in this article can form the covariance matrix of the potential birth target adaptively, thereby obviating the need for a prior covariance matrix. Unlike the AGLMB filter and AAMMTB filter that use the measurements from three time steps to generate the birth tracks, the AMHMB filter uses the measurements from two time steps to establish the potential birth targets. The simulation results exhibit that the AMHMB filter is robust, and it can obtain higher tracking accuracy than other filters.
The contributions of this article are as follows:
A novel approach for generating the potential birth targets is developed. In this approach, the initial state and error covariance of the potential birth target is formed adaptively, and its existence probability is given in terms of the unused probabilities of the two observations for generating this potential birth target;
A mathematical model for multiple hypotheses is established to solve the data association problem in the MTT. The multiple hypotheses are used for forming the PDFs of potential objects and their existence probabilities;
Based on the mathematical model for multiple hypotheses and the novel birth approach, an AMHMB filter is proposed.
The rest of the paper is as follows: The object dynamic model, the sensor observation model and the generating method for potential birth targets are provided in
Section 2, and then, the mathematical model for multiple hypotheses is given in
Section 3. In
Section 4, the AMHMB filter is presented. Simulation results are given in
Section 5 to compare the AMHMB filter with other filters. Conclusions are summarized in
Section 6.
2. Generation of Potential Birth Targets
In this article, the object dynamic and sensor observation models are as follows:
where
and
denote the state of an object and its observation;
and
are the state transition matrix and nonlinear measurement function;
is process noise; and
is observation noise. These two noises are the zero-mean Gaussian noises. The covariance of the former is
, and the covariance of the latter is
.
In the surveillance region, a radar at position
observes the moving targets. Let
denote the state of a target; the observation of this target is given below:
where
and
are the angle observation and angle noise, respectively;
and
are the range observation and range noise, respectively.
By converting observation
to the Cartesian coordinates, converted observation
can be given by the following:
According to [
34], the corresponding converted error covariance is as follows:
where
is the standard deviation of
,
is the standard deviation of
, and
is as follows:
In the RFS and labeled RFS filters, the establishment of the birth models is a core problem. The standard RFS and labeled RFS filters use the fixed birth positions with a small spatial uncertainty to generate birth intensity and density. This birth method is beneficial at a high clutter density because it can decrease the incidence of false tracks [
29]. However, it requires a good prior knowledge about the surveillance region, and it fails to initialize the track of an object if this object leaves the surroundings of the fixed positions. Adaptive birth intensity and adaptive birth density have been proposed to overcome the drawback of the fixed birth position approach [
27,
28,
29,
30,
31,
32,
33,
34,
35].
In [
29], an adaptive birth distribution for the labeled multi-Bernoulli (LMB) filter was proposed, which uses the observations from a time step to form the birth LMB distribution. Compared with the fixed birth locations, this approach increases the incidence of false tracks [
29]. Instead, we established the potential birth targets according to the observations from two time steps. A potential birth object (or birth track) is established if two observations from different time steps satisfy the speed requirement. Let
and
denote the set of converted measurements and the set of converted error covariance matrices at time step
, and let
denote the set of observations at time step
, where
and
are the observation numbers. Assume that the used probabilities of measurements
and
are given by
and
, respectively. By using (4) and (5) to deal with each observation in set
, the converted observation set
and converted covariance set
are obtained. Then, the potential birth objects are established in terms of converted observation sets
and
. Next, we pick observations
and
from sets
and
and test whether they satisfy the following:
where
is the scan period, and
and
are two given speeds. Parameters
and
can be chosen according to the kind of objects tracked because a radar is commonly used to track a kind of object. If
and
satisfy (7), a potential birth target is detected. According to [
35], the initial mean vector of this birth object is as follows:
where
According to [
35], the error covariance of this birth object is given below:
where
is the converted covariance of
, and
is the converted covariance of
.
Assume that potential birth object
is established in terms of converted observations
and
. This object may be given by the following:
where
and
denote the target state and Gaussian distribution, respectively; and
,
, and
denote the track label, existence probability, and weight. They are given as follows:
where
is the maximum existence probability of a potential birth object. In terms of (12), the existence probability of potential birth object
is less than
if
or
.
Repeating the above process to acquire a set of potential birth objects in terms of Algorithm 1, this set is as follows:
where
is the object number.
| Algorithm 1: Generation of potential birth targets |
.
.
.
.
according to (8) and (10).
according to (12).
end
end
end
.
. |
Although both the proposed birth approach and the birth approach in [
29] use the unused probability of observation to form the existence probability of the birth target, they are different. In the birth approach of [
29], even if the unused probability of the observation for generating a birth target is less than 1, the maximum existence probability may also be used as the existence probability of this birth target. This is unreasonable and is avoided in the proposed birth approach.
3. Mathematical Model for Multiple Hypotheses
The multiple hypotheses are used to solve the data association problem in the MTT, each of which may identify which target generates which observation, which target is missed, and which target has disappeared. If a target generates an observation, its updated PDF is used as its PDF; if a target is missed, its predicted PDF is used as its PDF; and if a target has disappeared, its information is discarded.
To establish the mathematical model for multiple hypotheses, three cases for each target need to be considered. The first case is that a target is existing, and it is detected; the second is that the target is existing, but it is missed; and the third is that the target has disappeared. The likelihood ratio or probability of the three cases can be defined as follows:
where
,
, and
are the likelihood ratio in case 1, probability in case 2, and probability in case 3, respectively;
is the detecting probability;
is the average clutter density;
is the predicted existence probability of target
; and
is the likelihood that object
generates observation
. The clutter number is assumed to follow a Poisson distribution as
, and the clutter is uniform in the monitoring area, where
denotes the average clutter number, and
is the clutter number. Let
denote the monitoring area;
can be given by
.
Hypothesis
is used to identify which object is detected, which object is missed, and which object has disappeared. If a target is detected, hypothesis
is also used to confirm which observation belongs to this target. The generalized joint-likelihood ratio for hypothesis
is given by the following:
where
is the target number;
denotes the index of the observation belonging to target
,
, and
, where
is the observation number;
,
, and
are the binary variables. Their values are either 0 or 1, and
.
reveals that object
is detected, and it generates observation
;
implies that object
is existing, but it is missed; and
demonstrates that object
has disappeared.
The K-best hypotheses are obtained by maximizing
as follows:
The maximization in (18) can be transformed into the minimization of
:
The minimization of (19) is a 2-dimensional (2D) assignment problem:
subject to
where
,
, and
are the binary variables, and their values are either 0 or 1; and
,
, and
are the three costs. They are given as follows:
The cost matrix used for this 2D assignment is given below:
where
In terms of cost matrix
, the K-best hypotheses may be acquired by using the Murty algorithm [
36]. The index matrix of the K-best hypotheses and their cost vector
may be given by the following:
where
is the column index of
;
is the cost of hypothesis
, where
and
.
indicates that object
is detected, and
belongs to it;
reveals that object
is missed; and
implies that object
has disappeared. The weights of different hypotheses are given by the following:
Index matrix
in (28) and the weights
of different hypotheses are employed to form a set of updated potential objects. This is given in
Section 4.
4. Adaptive MHMB Filter
The adaptive MHMB filter is proposed to propagate the existence probability, track label, and PDF of the potential target. Suppose that, at time step
, the potential targets are as follows:
where
,
,
, and
denote the number of potential targets, existence probability, track label, and PDF of target
at time step
, respectively;
is the initial state vector of target
, and it is given in terms of (8);
is an indicator to declare whether target
is a birth target or an existing target.
or
indicates that target
is a birth target, whereas
implies that target
is an existing target. The PDF of target
is given by the following:
where
is the number of sub-distributions of target
;
is the weight of sub-distribution
of object
; and
and
are its mean vector and covariance matrix, respectively. Weight
satisfies the following:
Assume that, at time step , the used probabilities of measurements are , and the converted observations and converted covariance matrices are and , respectively. The recursion of the AMHMB filter consists of the following steps:
4.1. Prediction
According to (30) and (31), the predicted potential targets are as follows:
where
,
,
, and
are given by the following:
where
Algorithm 2 gives the pseudo-code for prediction.
| Algorithm 2: Prediction |
.
.
.
end
end
. |
4.2. Update
Using observation
to update potential target
, the updated PDF of potential object
is given by the following:
where
denotes the observation number, and
and
are given by the following:
where
is given by (3), and
and
are given by the following:
where
The likelihood that potential object
generates observation
is as follows:
Algorithm 3 gives the pseudo-code for update.
| Algorithm 3: Update |
.
according to (37), (39) and (40), respectively.
end
according to (43).
end
end
. |
4.3. Forming the Potential Targets According to K-Best Hypotheses
Cost matrix
can be established according to (24). Employing the optimizing Murty algorithm [
36] to obtain the K-best hypotheses, the index matrix and weights of hypotheses may be given by (28) and (29), respectively. In terms of index matrix
and weights
of different hypotheses, a set of potential targets can be formed according to Algorithm 4.
| Algorithm 4: Forming the potential targets according to the K-best hypotheses |
.
.
.
.
Establish cost matrix according to (24).
Employ the Murty algorithm to obtain matrix .
according to (29).
.
.
.
end
.
end
end
end
end
.
.
end
. |
The set of potential targets is given below:
where
4.4. Extracting the Real Targets
The real targets are extracted in terms of Algorithm 5. A potential target is confirmed as a real target if its existence probability is larger than parameter
. By using Algorithm 5, a set of real targets is acquired. This set consists of mean vectors of real targets and their track labels and is given by
, where
and
are the mean vector and track label of real object
, and
is the estimated object number. This set is regarded as the output of the filter at time step
. At the same time, Algorithm 5 also generates set
, where
is the initial state vector of object
,
is its track label, and
is the object number. This set consists of the initial mean vectors and track labels of those potential birth targets confirmed to be real targets. It is used to supply the output of the filter at time step
.
| Algorithm 5: Extracting the real targets |
.
.
.
.
.
end
end
end
.
. |
4.5. Combination
Using Algorithm 1 to generate the potential birth objects, they can be given as follows:
where
,
, and
is as follows:
Combining the set in (46) into the set in (44) according to Algorithm 6, the set of potential objects after combination is as follows:
where
and
is given below:
| Algorithm 6: Combination |
.
.
.
.
end
.
. |
4.6. Pruning and Merging
The objective of pruning and merging is to reduce the computational load. Algorithm 7 is used to finish the task of pruning and merging. In terms of Algorithm 7, a potential target is discarded if its existence probability is smaller than . At the same time, a sub-item of potential target is also removed if its weight is less than . Multiple sub-items of each potential target should be merged into a sub-item if they are close together, i.e., merging these sub-items between which the distance is less than into a sub-item. Parameters , , and in Algorithm 7 are three given thresholds.
According to Algorithm 7, the set of residual potential objects is as follows:
where
is the object number,
,
,
,
, and
is as follows:
where
,
,
, and
. The potential targets in (50), the used probabilities
of different measurements in Algorithm 4, and the converted observations
and converted error covariance matrices
in Algorithm 1 are propagated to the next time step.
| Algorithm 7: Pruning and merging |
.
.
.
.
.
repeat
).
.
.
.
.
.
end
. |
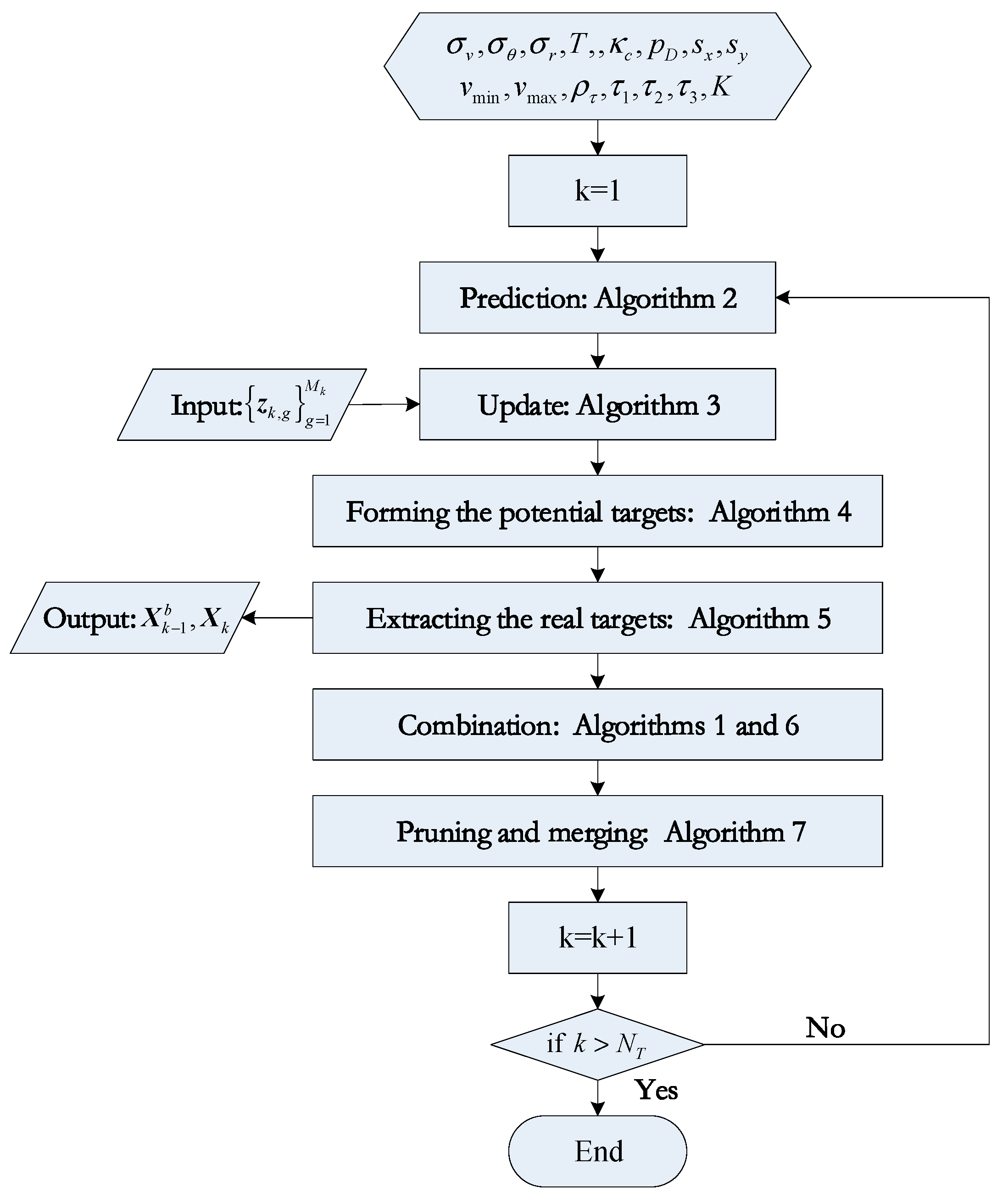
The flowchart of the AMHMB filter is given in
Figure 1, where
denotes the maximum recursion number.
To form the PDFs and existence probabilities of different targets in the recursion, the K-best hypotheses are needed in the proposed AMHMB filter. This filter uses the measurements from time steps and to form the potential birth objects. The state vectors and covariance matrices for potential birth targets are given adaptively.
5. Simulation Results
In this section, in order to test the tracking performance of the AMHMB filter, the AGLMB filter in [
34], the AAMMTB filter in [
35], and the adaptive GLMB filter in [
30] were selected as the comparison filters. The adaptive GLMB filter in [
30] is called the AGLMB1 filter in this article. The original adaptive GLMB filter in [
30] uses a robust CPHD filter to estimate the clutter rate (or clutter density) and detection probability. Since the estimations of the clutter rate and detection probability are not involved in this article, prior clutter rate and detection probability are used in the AGLMB1 filter. The fixed prior covariance matrix for the AGLMB1 filter is given as follows:
According to [
30], the existence probability of the potential birth object in this adaptive filter is given by the following:
where
is the maximum existence probability of a potential birth object,
is the used probability of observation
, and
is the expected number of birth targets at time step
. In the experiment,
is set to
, and parameter
in the AMHMB filter and AGLMB1 filter is set to
.
The metrics used for evaluating the performance of filters are the OSPA
(2) distance [
37], cardinality error, and performing time. The OSPA
(2) distance is a metric for evaluating the dissimilarity between two sets of tracks. Let
and
denote two sets of tracks. If
, the OSPA
(2) distance between these two sets is as follows:
where
and
denote the order,
denotes the set
, and
is a set of weights. If
, then
. For the OSPA
(2) distance, the reader may acquire more detail from [
37]. In the experiment, the parameters for the OSPA
(2) distance are set to
,
, and
, where
is the size of
.
Cardinality error denotes the difference of object numbers. Its definition is the following:
where
denotes the number of Monte Carlo runs,
is the number of time steps, and
and
denote the estimated object number and true object number, respectively.
The performing time is the average time required for a Monte Carlo run. Its definition is as follows:
where
is the time required for Monte Carlo run
.
The simulation hardware environment is Lenovo ThinkPad T470, and software environment is Windows 10 and MATLAB R2021b. In the simulation, two scenarios are considered.
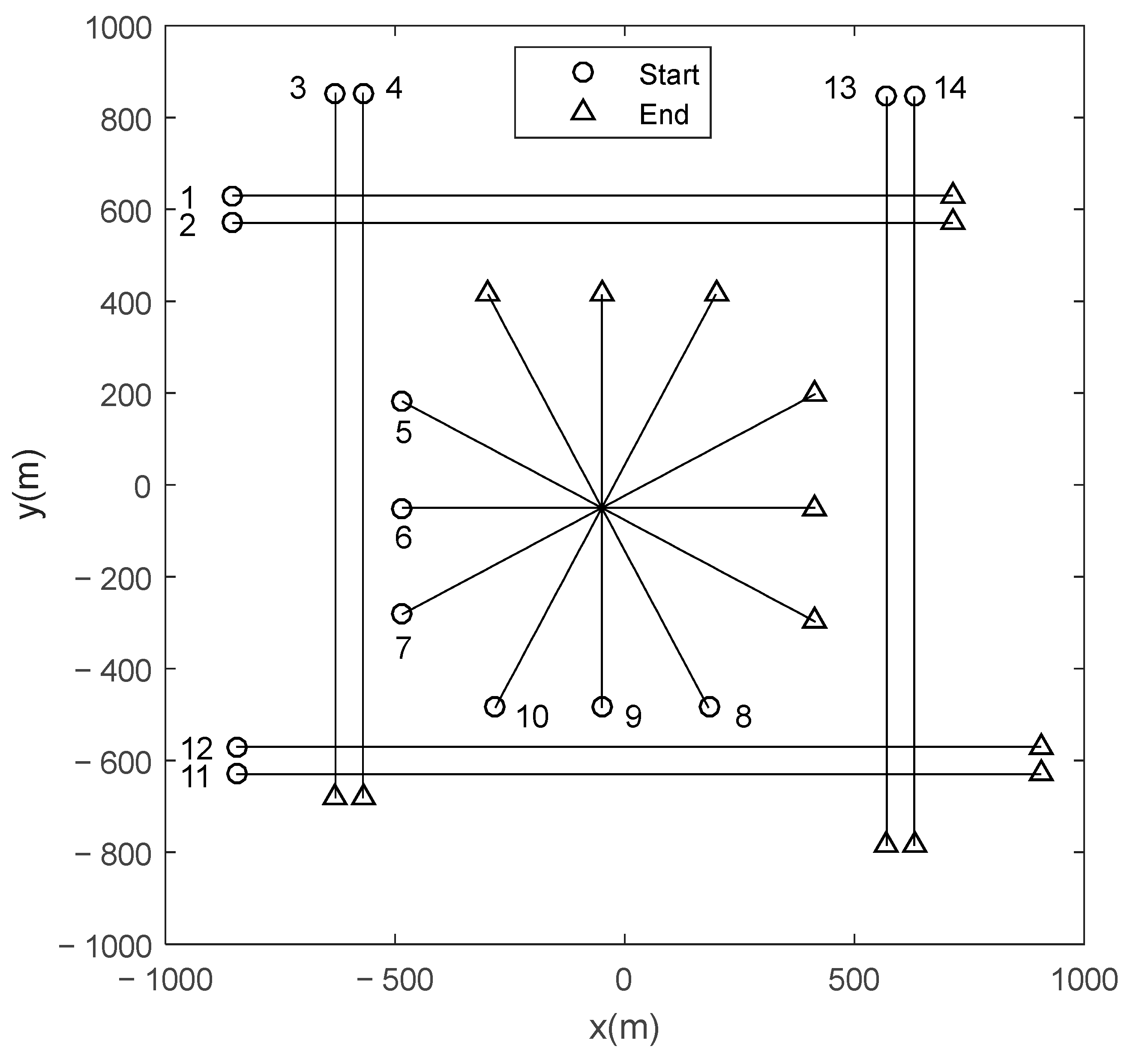
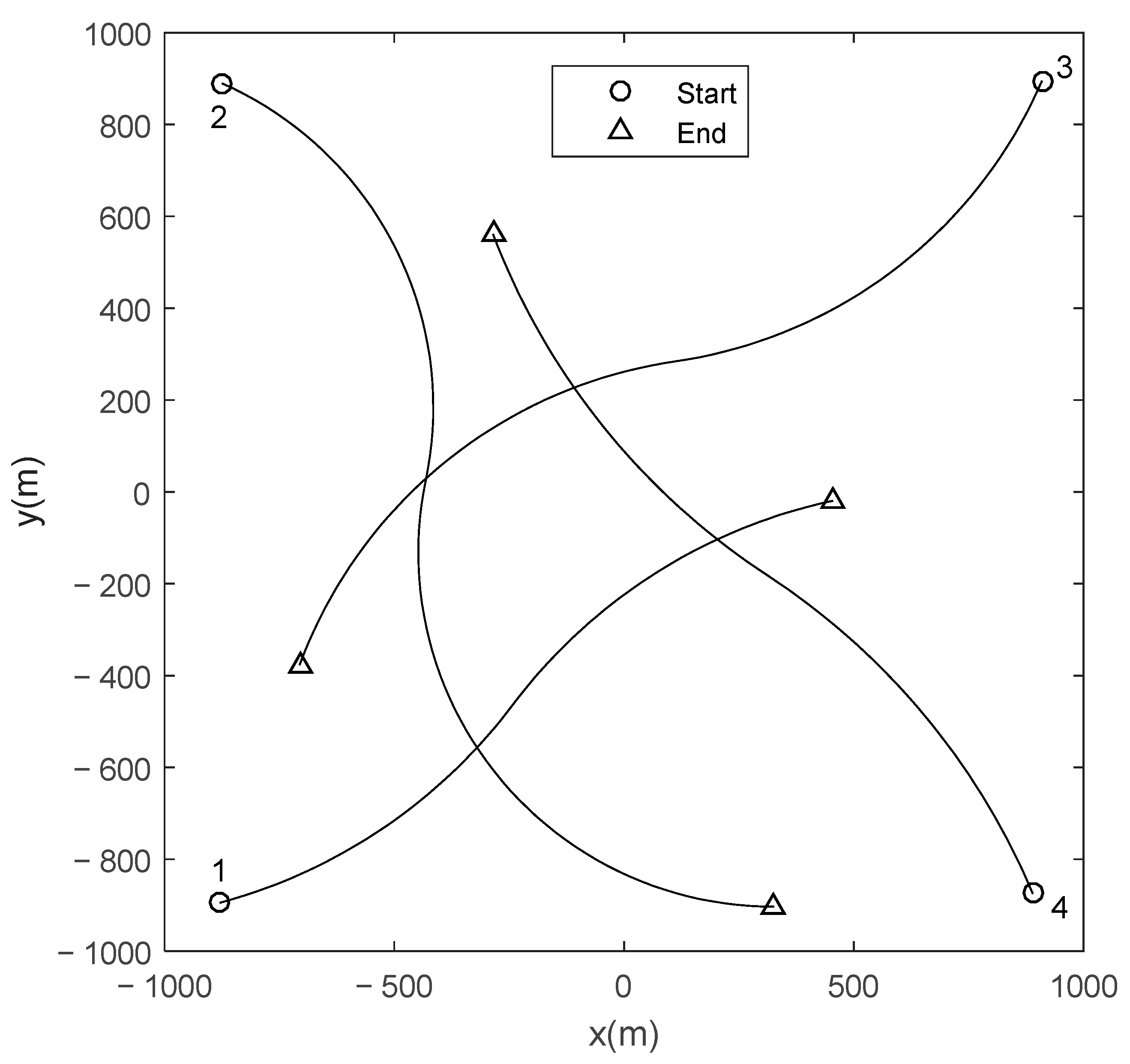
Scenario 1: There are fourteen moving targets in this scenario. Their true tracks are illustrated in
Figure 2, and their appearing time, disappearing time, and state vector are given in
Table 1. The state vector of target
at time step
is
, where
and
are the position components, and their unit is m;
and
are the velocity components, and their unit is ms
−1.
The fourteen targets move according to (1), and
and
in (1) and (35) are given by the following:
where scan period
, and standard deviation of process noise
. Random process noise may result in the perturbations of the moving tracks of targets. It can simulate the realistic scenario of target motion.
A radar located at [0, 0]
T observes the fourteen targets moving in the surveillance region. The target-originated observations are generated according to (2), where
in (2) and (37) is given by the following:
Detection probability
, average clutter number
(i.e., average clutter density is
), and standard deviations of observation noises
and
are used to generate simulated measurements.
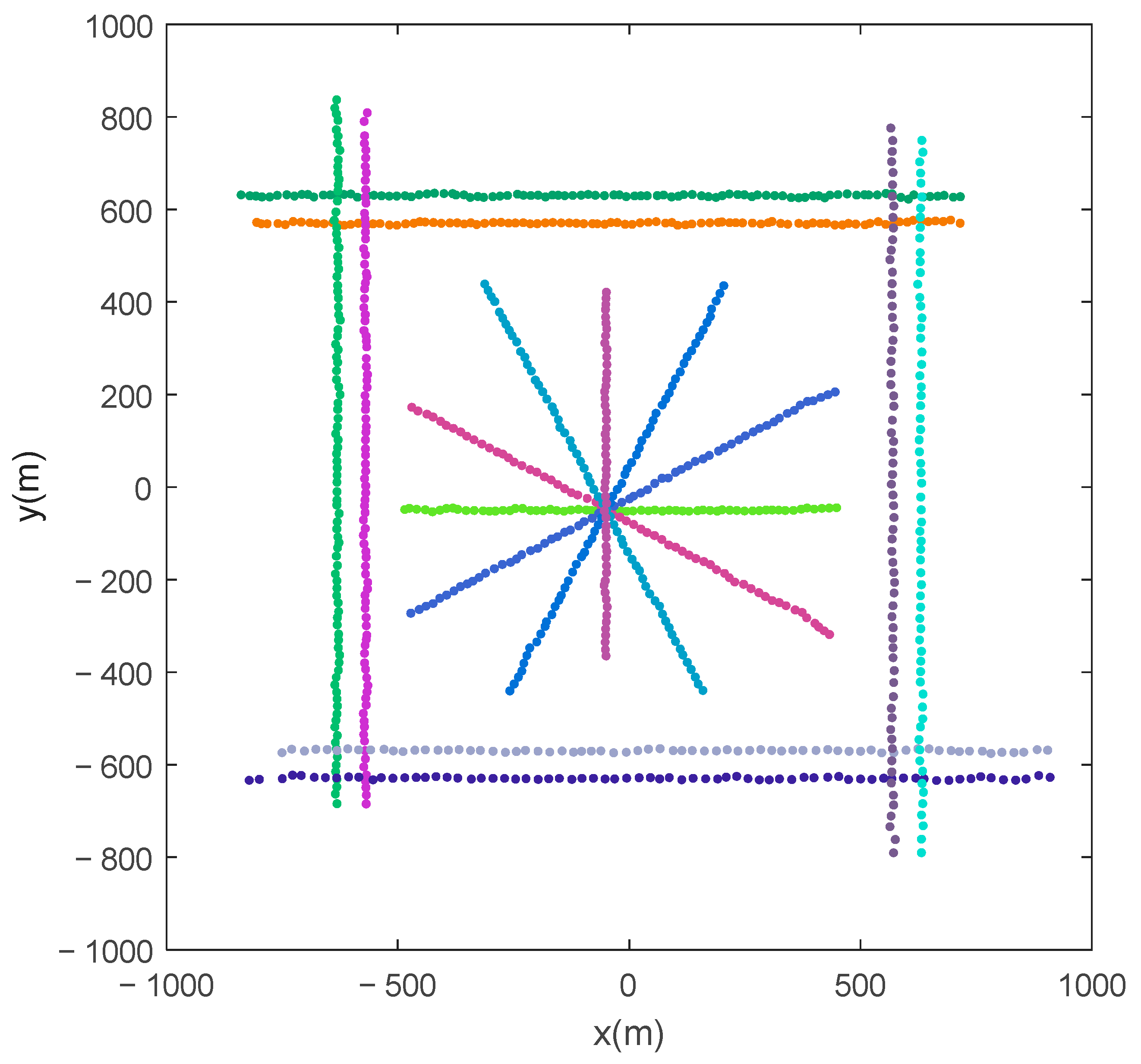
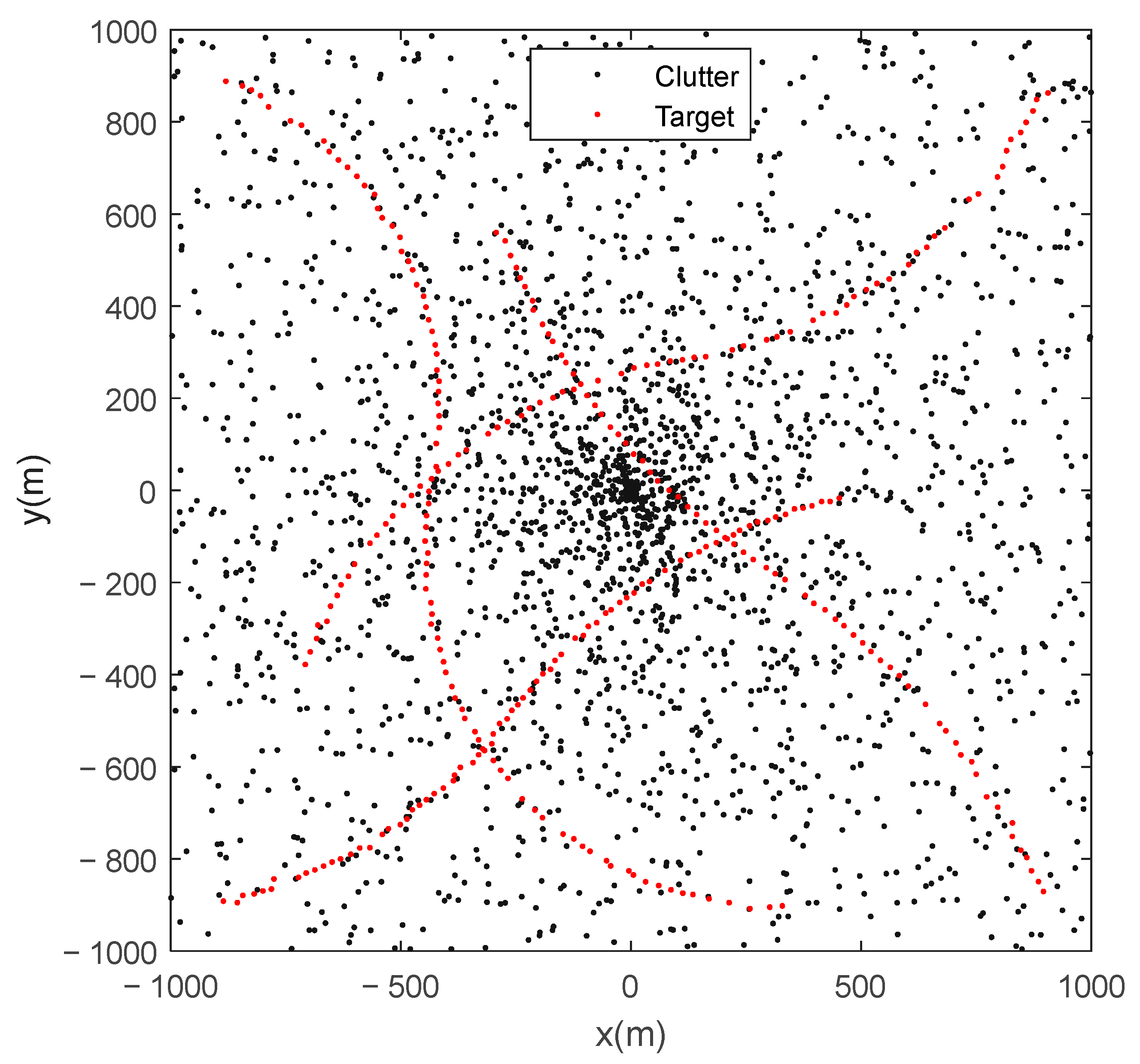
Figure 3 illustrates the simulated observations of a Monte Carlo run, where black dots denote clutter, and red dots denote the target-originated observations. Due to process noise and observation noise, the target-originated observations deviate from the true positions of targets. Some of the target-originated observations are missing by reason of missed detection.
In the experiment, parameters
and
in (7) are set to
and
; the number of hypotheses in the AMHMB filter is set to
, and its other parameters are
,
, and
; and the other parameters of the AAMMTB filter, AGLMB filter, and AGLMB1 filter are identical to those in Ref. [
35], Ref. [
34], and Ref. [
22], respectively.
Figure 4 and
Figure 5 can be acquired by using the AMHMB filter to handle the simulated measurements in
Figure 3. A comparison of
Figure 4 with
Figure 2 shows that the AMHMB filter can track the fourteen objects, and the estimated target positions approximate the true target positions. A comparison of
Figure 4 with
Figure 3 shows that clutter is removed by the AMHMB filter, and this filter can provide the state estimation of a target if this target is undetected.
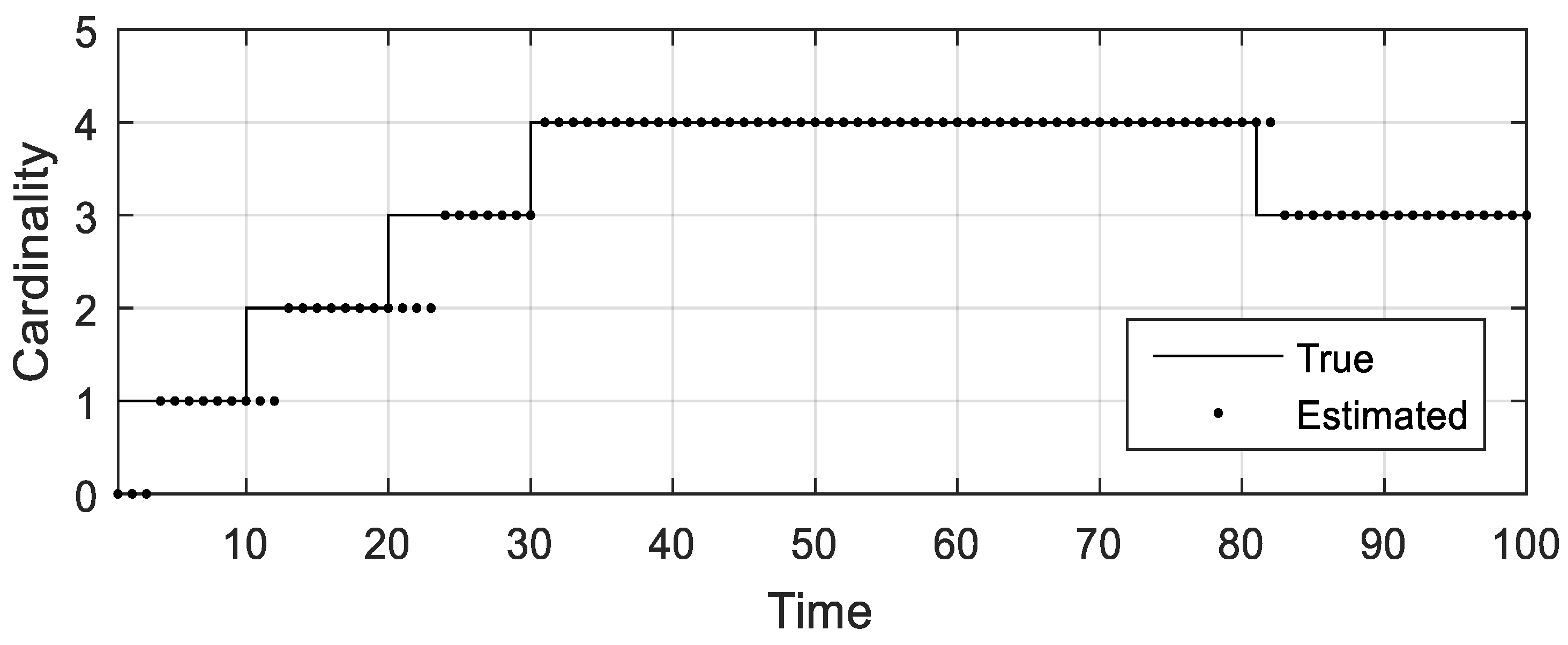
Figure 5 indicates that the estimated object number approximates the true object number and also reveals that the AMHMB filter has a delayed response to target appearance and disappearance. The estimated number of targets is less than the number of true targets during target appearing stage and is larger than the number of true targets during target disappearing stage.
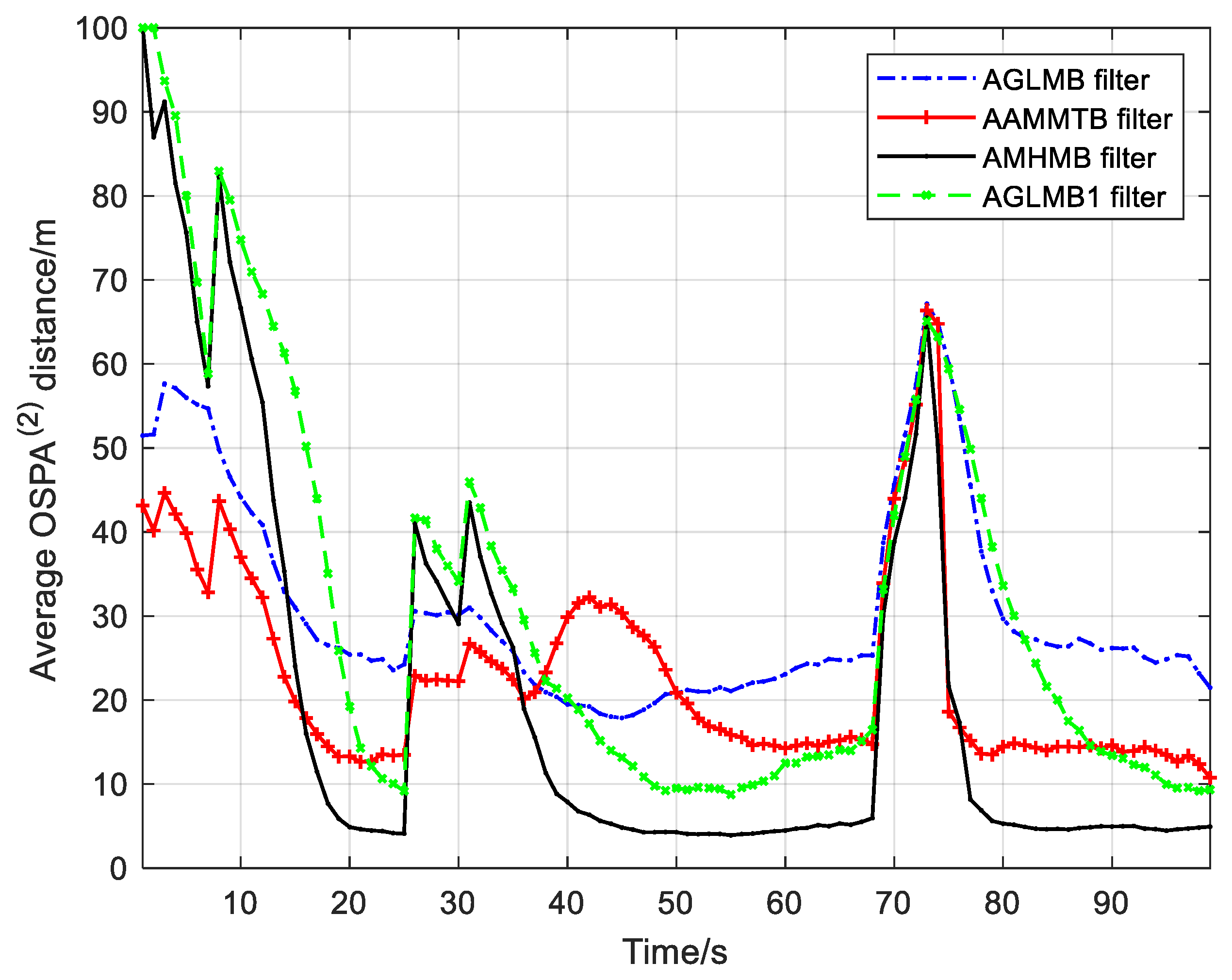
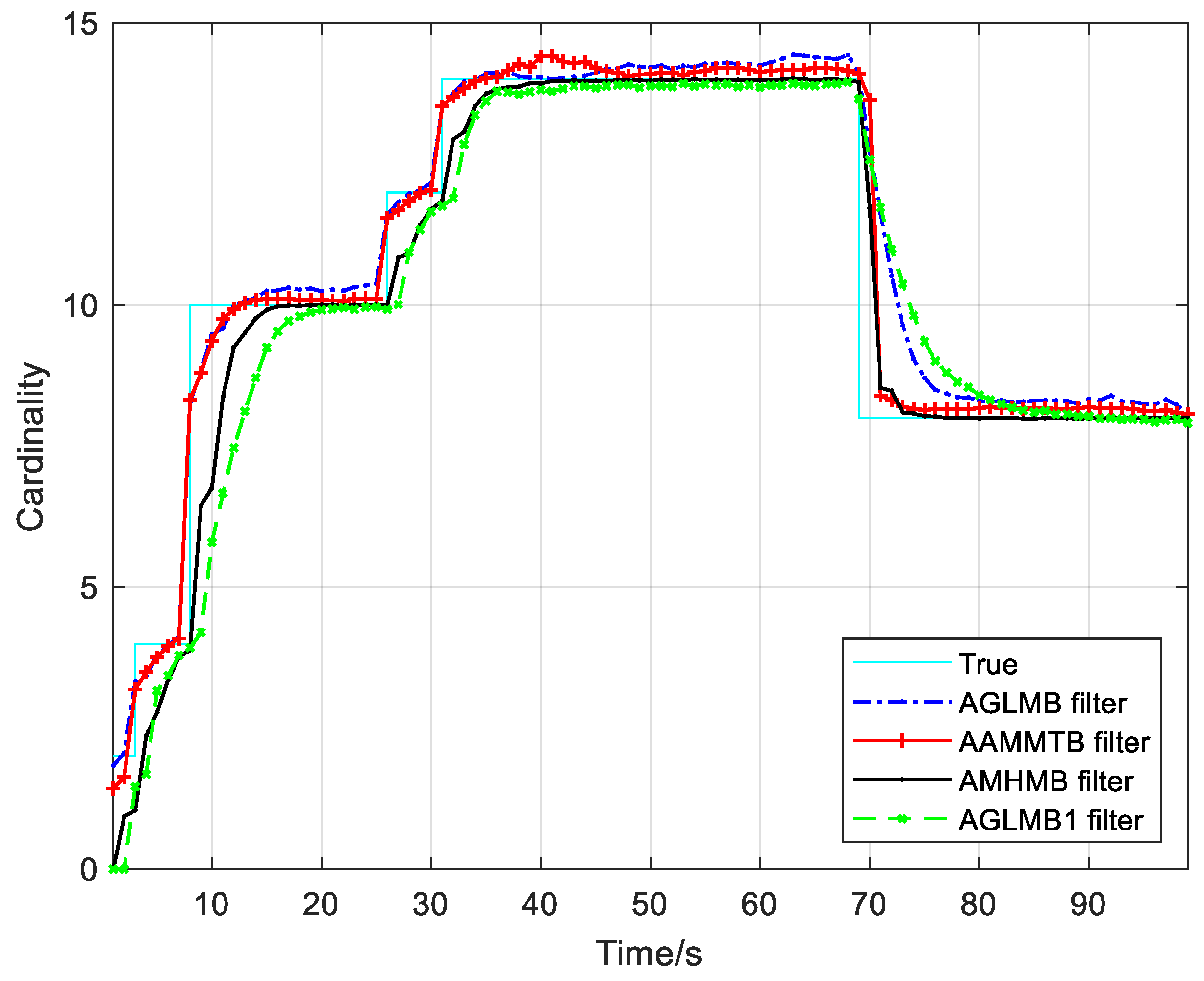
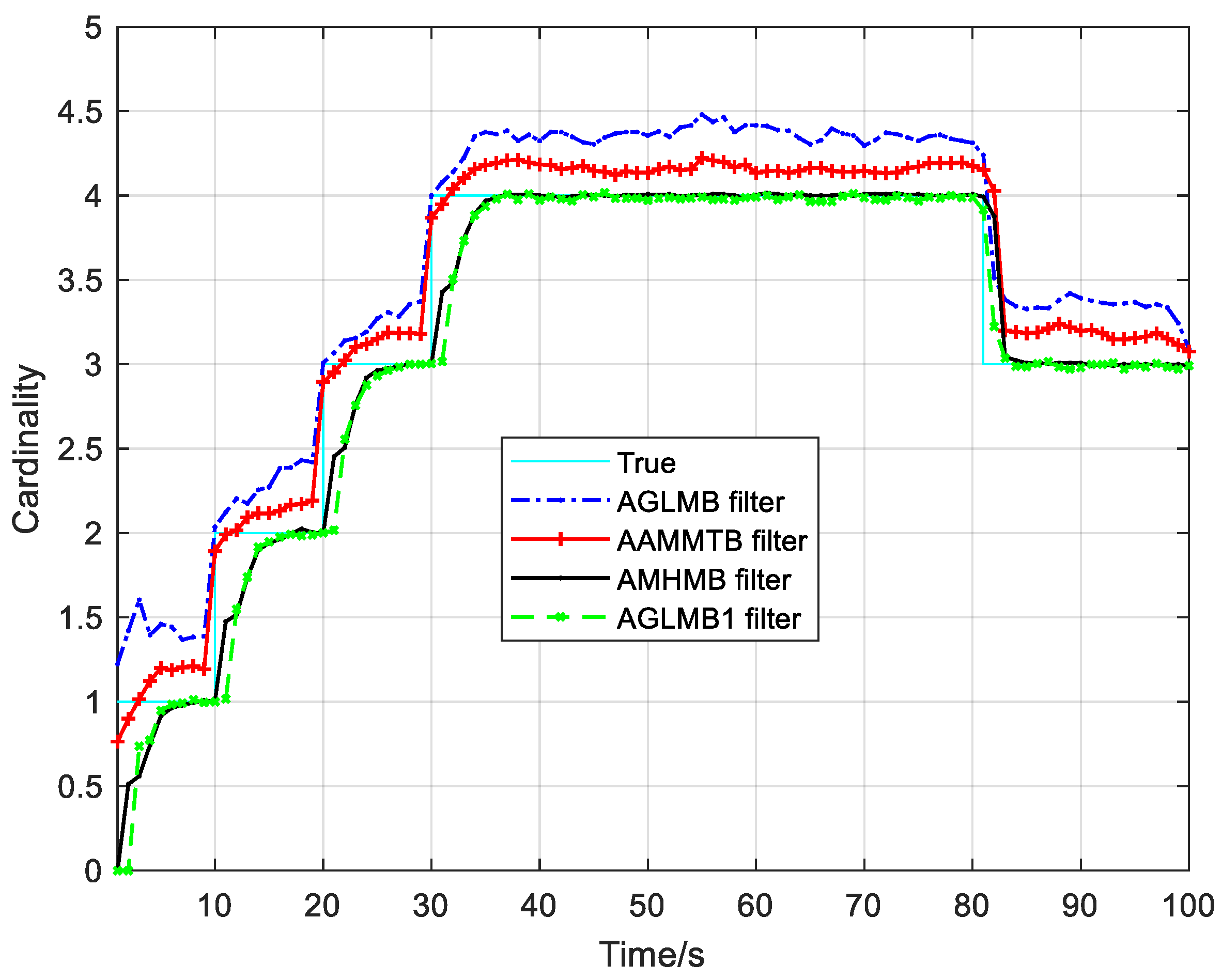
The results from the testing of the AMHMB filter and comparison filters over 250 Monte Carlo runs are given in
Figure 6 and
Figure 7 as well as
Table 2. The OSPA
(2) distance in
Figure 6 and
Table 2 shows that the AMHMB filter performs best among these four filters, followed by the AAMMTB filter. The cardinality error in
Figure 7 and
Table 2 reveals that the AAMMTB filter has a slightly smaller cardinality error than the AMHMB filter. In terms of
Figure 6 and
Figure 7, the AMHMB filter shows a lower performance than the AAMMTB filter during the target appearing stage. This is because the AAMMTB filter has a more rapid response to target appearance than the AMHMB filter. The AMHMB filter requires more time steps to detect a new target. The performing time in
Table 2 indicates that the computational load of the AAMMTB filter is the least. This is because the AAMMTB filter requires only an optimal assignment in each recursion, whereas the other three filters need multiple hypotheses in the recursion. According to
Table 2, the computational cost of the AMHMB filter is moderate: larger than that of the AAMMTB filter and smaller than that of other two filters.
To test the robustness, different detecting probabilities, different noisy standard deviations, and different clutter densities are used to generate the simulated observations. The tracking results over 50 Monte Carlo runs for each case are given in
Table 3,
Table 4 and
Table 5, which indicate that the AMHMB filter is the best in most cases. As shown in
Table 3 and
Table 5, its OSPA
(2) distance is slightly larger than that of AAMMTB filter at
and
as well as
,
, and
. Two reasons may be the cause of this phenomenon. The first is that the AAMMTB filter has a more rapid response to target appearance than the AMHMB filter. The second is that the accuracy of the data association of the AAMMTB filter is improved significantly under conditions of low clutter density and high detection probability. The experimental results indicate that the AMHMB filter is robust. Unlike the AAMMTB filter that requires a low clutter density and a high detection probability, the AMHMB filter obviates this requirement. It performs better at high clutter densities and low detection probabilities than other adaptive filters.
Scenario 2: To test the performance of the AMHMB filter on tracking the maneuvering target, four turn-maneuvering targets are considered in scenario 2. The initial states of targets 1, 2, 3, and 4 are [−900, 20, −900, 5]
T, [−900, 25, 900, −10]
T, [920, −10, 920, −25]
T, and [900, −10, −900, 25]
T, respectively. They appear at t = 1 s, t = 10 s, t = 20 s, and t = 30 s and disappear at t = 80 s, t = 101 s, t = 101 s, and t = 101 s, respectively. Their initial turn rates are
rads
−1,
rads
−1,
rads
−1, and
rads
−1, respectively. These four targets change their turn rates from
to
at t = 40 s, t = 50 s, t = 60 s, and t = 65 s, respectively, where
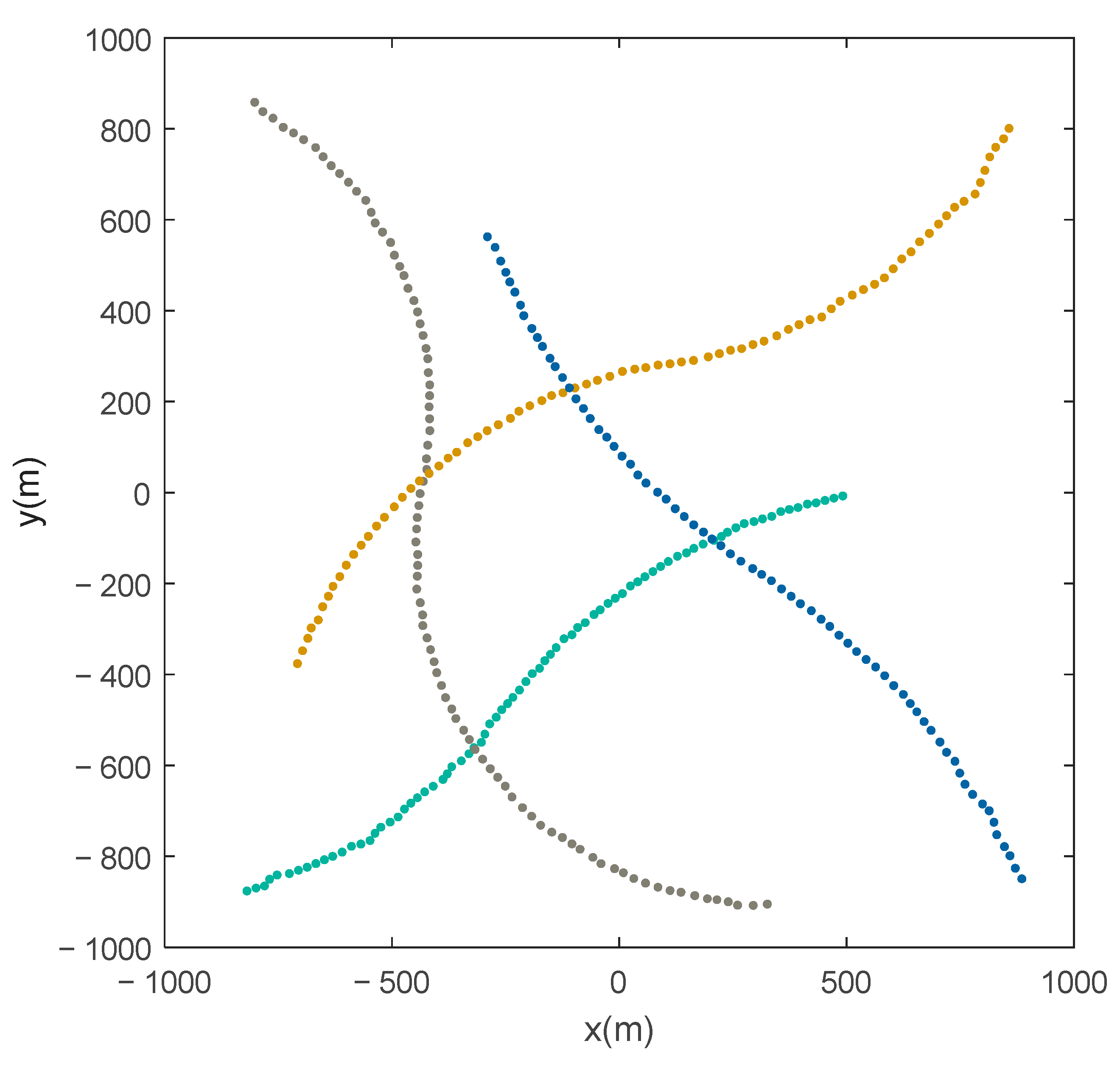
. The true trajectories of the four maneuvering targets are given in
Figure 8. Using process noise
, detection probability
, average clutter number
(i.e., average clutter density is
), and standard deviations of observation noises
and
to generate simulated measurements, the simulated observations of a Monte Carlo run are given in
Figure 9, where black dots denote clutter, and red dots denote the target-originated observations. Due to process noise and observation noise, the target-originated observations deviate from true positions of targets. Some of target-originated observations are missing by reason of missed detection.
Figure 10 and
Figure 11 can be acquired by using the AMHMB filter to handle the simulated measurements in
Figure 9. A comparison of
Figure 10 with
Figure 8 shows that the AMHMB filter can track the four maneuvering targets in the presence of missed detection, clutter, and noise.
Figure 11 indicates that it may provide an accurate estimation of object number.
Figure 11 also reveals that two to four time steps are required for the AMHMB filter to start tracking a new target.
The tracking result (over 250 Monte Carlo runs) in
Figure 12 and
Figure 13 as well as
Table 6 indicates that the OSPA
(2) distance and cardinality error of the AMHMB filter are the least among these four filters, and its computational load is moderate: larger than that of the AAMMTB filter and smaller than that of other two filters. Compared with the OSPA
(2) distance of the AAMMTB filter, the OSPA
(2) distance of the AMHMB filter is reduced by 16% in terms of
Table 6.
Different detecting probabilities, different noisy standard deviations, and different clutter densities were used to test the robustness. The tracking results over 50 Monte Carlo runs for each case are given in
Table 7,
Table 8 and
Table 9. Conclusions identical to scenario 1 can be drawn according to
Table 7,
Table 8 and
Table 9. The AMHMB filter is the best in most cases. The AAMMTB filter performs better than the AMHMB filter under conditions of low clutter density and high detection probability. The AMHMB filter performs better at high clutter densities and low detection probabilities than other adaptive filters.
Effect of
: Different values of
are used in the AMHMB filter to test the effect of the number of hypotheses on its performance.
Table 10 shows the OSPA
(2) distances and performing times over 50 Monte Carlo runs in scenario 1 and scenario 2. According to
Table 10, a large value of
leads to the increase of the computational load, and the OSPA
(2) distance is the smallest at
. The suggested value of
is
in terms of
Table 10.
Effect of
: Different values of
were used in the AMHMB filter to test the effect of the maximum existence probability on its performance.
Table 11 shows the OSPA
(2) distances and performing times over 50 Monte Carlo runs in scenario 1 and scenario 2. According to
Table 11, the computational load decreases as the value of
reduces, and the OSPA
(2) distance is the smallest at
in scenario 1 and is the smallest at
in scenario 2. The suggested value range of
is
in terms of
Table 11.
Superiority of the birth approach: Replacing the birth approach in the AMHMB filter with the birth approach in the adaptive GLMB filter of [
30], an AMHMB1 filter can be established. The main difference between the AMHMB filter and the AMHMB1 filter is that they use the different birth approaches.
Table 12 shows the OSPA
(2) distances, cardinality errors, and performing times over 50 Monte Carlo runs in scenario 1 and scenario 2, which reveals that the OSPA
(2) distances, cardinality errors, and performing times of the AMHMB filter are less than those of the AMHMB1 filter. This result also indicates the use of the birth approach proposed in this article improves the tracking accuracy and decreases the computational load. The reason may be that the proposed birth approach reduces the number of potential birth targets.
Computational complexity: The AMHMB filter has a computational complexity, where , , and are the object number, observation number, and hypothesis number, respectively. Reducing the object number and reducing the hypothesis number can decrease the computational cost of the AMHMB filter.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}