1. Introduction
Oil and gas (O&G) wells that are improperly abandoned or orphaned pose a significant environmental risk and potentially contribute to global methane emissions [
1]. Unplugged or damaged wells introduce the risk of contaminates to the soil and groundwater [
2,
3,
4,
5,
6] and greenhouse gasses to the atmosphere [
1,
7], meaning that each and every oil and gas well needs to be regularly assessed and maintained or properly plugged to isolate it from its surroundings.
There are currently over 120,000 documented orphaned wells [
8], and the Department of Energy estimates hundreds of thousands of undocumented orphaned wells (UOWs) in the U.S. [
9]. An orphaned O&G well is generally defined as an idle well for which the operator is unknown or insolvent. An undocumented well is defined as a well with an unknown location and missing information such as ownership and construction details [
8]. Thus, an undocumented orphaned O&G well (UOW) is idle and lost from the records. Without knowing where these wells are, it is impossible to characterize them (e.g., their age, depth, condition, and risk associations), quantify their methane emissions, and execute mitigation measures [
10]. Such an undertaking is daunting; however, developing automated techniques for identifying wells from high-resolution satellite imagery data is one of many approaches that hold promise for large-scale data analysis.
Machine learning (ML) is crucial in processing satellite data for various applications, including climate change mitigation [
11]. Here, we focus on two aspects: image classification [
12] and data fusion [
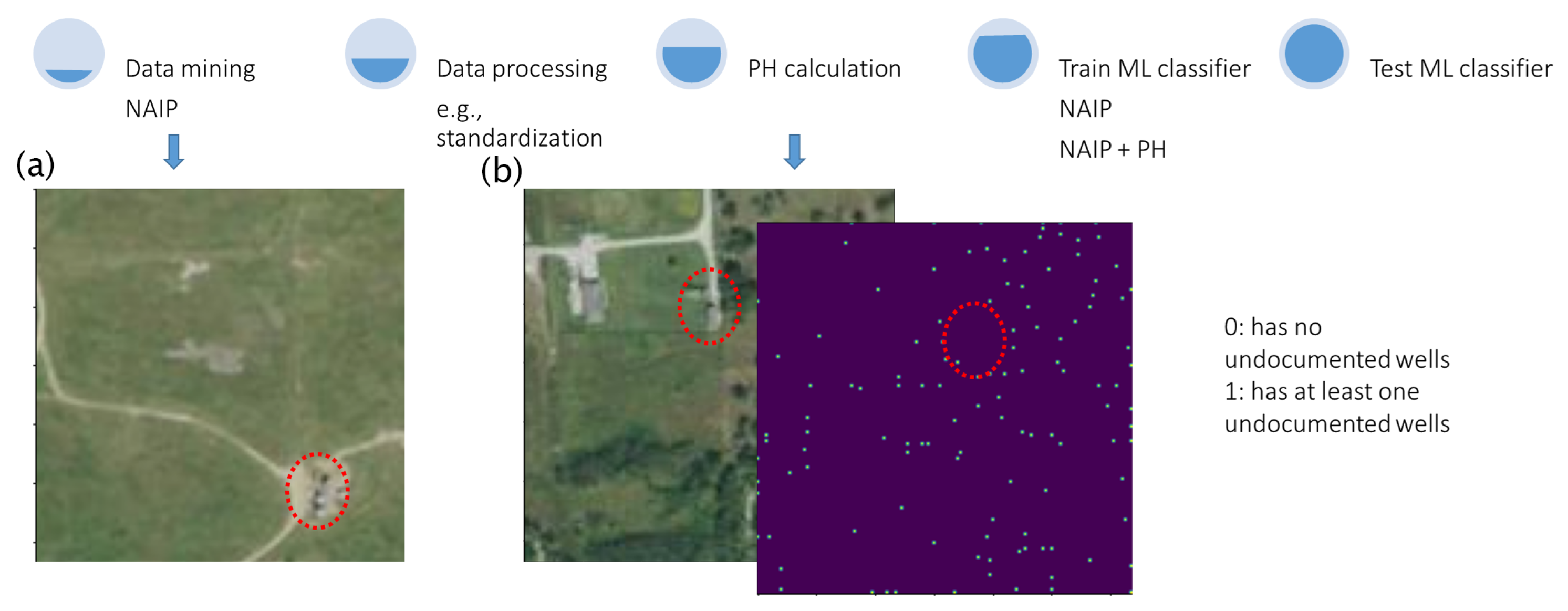
13]. ML algorithms can be trained to classify satellite images into different categories, such as images that contain UOWs or ones that do not (
Figure 1a). This enables the automated analysis of large volumes of satellite imagery, providing valuable information for identifying UOWs. Our ML problem here is a binary classification problem. Binary classification is an ML task that assigns input data points to one of two classes (0: no UOWs in the image; 1: at least one UOW in the image) or categories. The goal is to build a model to accurately predict the class label of new, unseen instances based on the patterns and relationships it learns from the training data.
Data fusion is an essential step in analyzing satellite data, which frequently originates from diverse sources and sensors, each offering distinct types of information. Through ML algorithms, data fusion enables the merging and integration of data from multiple satellites, resulting in a more comprehensive and precise representation within analysis systems. In this context, we combine two distinct data streams: satellite images presented in RGB format and the persistent homology (PH) of those images (
Figure 1b). We hypothesize that, by incorporating additional input streams, we can enhance the ability of our ML models to learn meaningful patterns and consequently improve their accuracy in identifying UOWs.
PH, a tool from topological data analysis and computational topology, describes the connectivity structure of datasets [
14,
15,
16]. PH can be applied to different data types, such as point clouds, digital images, and level sets of real-valued functions, to observe the change in homology, or “holes” of different dimensions, over a filtration of nested simplicial or cubical complexes placed on the data [
17,
18]. Since its development, PH has been applied in a multitude of fields, such as the identification of cancer cells in medical imagery, e.g., [
19,
20], characterizing porous material, e.g., [
21,
22], collective behavior in biology, e.g., [
23], and comparing musical pieces [
24]. More recently, researchers have also realized the use of PH as an automatic detection tool for geospatial objects in the geosciences, e.g., [
25,
26], the social sciences, e.g., [
27,
28,
29], and transportation [
30]. We hypothesized that the PH analysis of satellite imagery can draw attention to surface features related to O&G wells.
2. Materials and Methods
2.1. Machine Learning (ML) Models
Binary classification aims to classify instances into two classes or categories. These classes are typically represented as “positive” and “negative”, “1” and “0”, or “yes” and “no [
31]”. The model is trained in binary classification using a labeled dataset in which each instance is associated with a class label [
32]. The input features or variables are used to make predictions or decisions about the class membership of new, unseen instances. Here, our inputs were the RGB imagery of three counties in Oklahoma from the National Agriculture Imagery Program [
33] and Oklahoma Corporation Commission’s O&G well database with positive and negative examples of orphan wells [
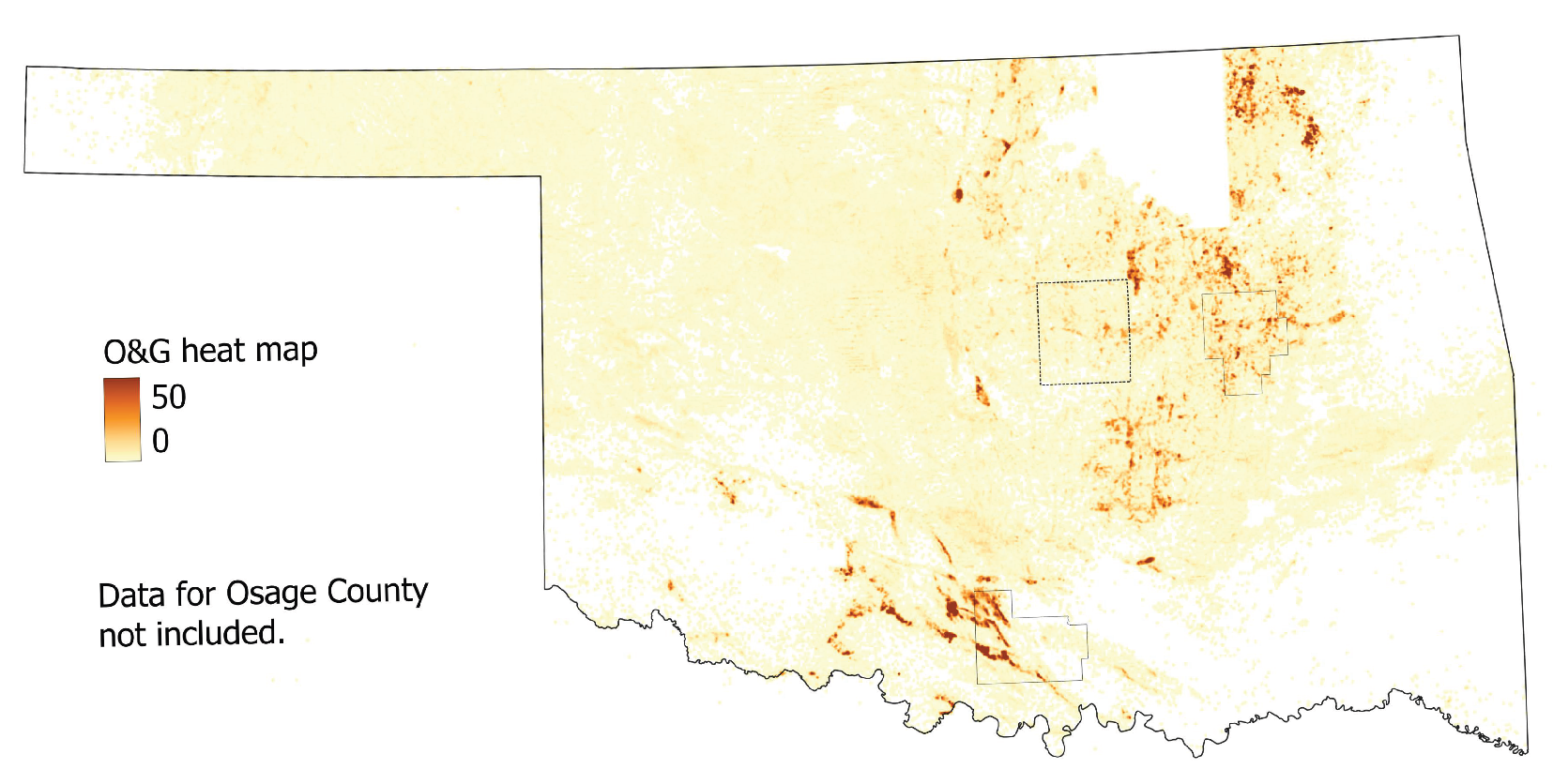
34], which served as our labeled data. This region was chosen for its high density of O&G wells (
Figure 2) and public database of documented orphan wells (DOWs). Our outputs were “1” if at least one UOW existed in the image and “0” if no UOWs existed.
Figure 3 highlights the different scenarios that the models faced.
We utilized five early deep convolutional neural network models—vanilla convolutional neural networks (CNN), ResNet-50, ResNet-101, RegNet-Y 400MF, and VGG-13 BN [
35,
36,
37,
38]—for this study. CNNs are effective for classification tasks, particularly in image recognition and capturing spatial patterns and hierarchical representations [
39]. Our vanilla CNN consists of two convolutional layers and three linear layers, each with ReLU activation. ResNet-50 and ResNet-101 are variants of the Residual Network (ResNet) architecture with 50 and 101 layers, respectively. They address the vanishing gradient problem, allowing for the training of very deep networks [
36]. RegNet-Y 400MF is a scalable and efficient model designed for various computer vision tasks [
37], and it balances the model’s size, computational efficiency, and performance. VGG-13 BN is a 13-layer variant of the VGG architecture with batch normalization, and it is known for its depth and strong performance in image classification tasks [
38,
40]. While computationally intensive, it is suitable for scenarios with adequate resources.
We selected these models because all except vanilla CNN have pre-trained versions available in PyTorch, facilitating the application of transfer learning. (We used vanilla CNN as the simplest version of the ML classifier.) We leveraged pre-trained weights to accelerate the training process and compare the performance of each model when trained from scratch versus when using transfer learning. Furthermore, these models represent diverse architectures widely studied and validated in the literature, providing a robust basis for the comparative analysis of the impacts of different architectural features on our tasks’ performance while ensuring reproducibility and ease of implementation.
Furthermore, having pre-trained models allows us to compare the performance of each model when trained from scratch versus when using transfer learning. This comparison provides valuable insights into the benefits and limitations of transfer learning in our specific application context. By analyzing these two versions, we can better understand how pre-trained weights influence model convergence, generalization capabilities, and overall performance, informing future model selection and training strategies.
During the training phase, we utilized the ADAM optimizer— [
41] with a learning rate of 0.0001 and a weight decay of
. The remaining parameters of the optimizer were left at their default values. Each model was trained for 50 epochs, employing a batch size of 128. We utilized the early stopping technique to mitigate overfitting during training, and we used generalized cross-validation criteria [
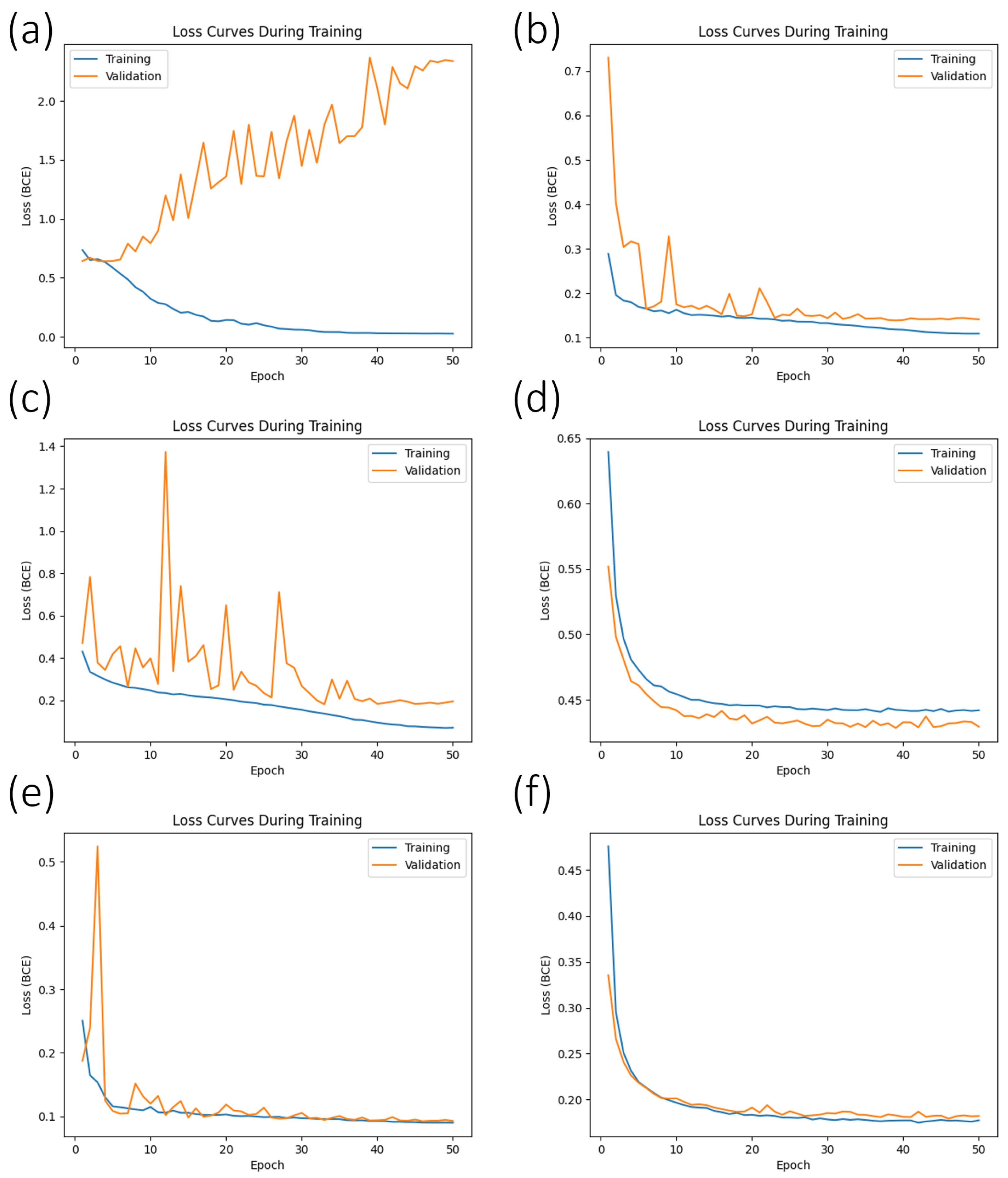
42]. Rather than abruptly ending the training process, we adopted a strategy to save the set of trained weights and biases only when the current validation loss was lower than the lowest observed in all previous training cycles. This approach enabled us to identify the optimal model that minimized the validation loss and enhanced the model’s generalization performance. For instance, if the validation loss reached its lowest point at the 43rd epoch, see
Figure 4a, we utilized the weights and biases obtained for the inference phase on the test set. On the other hand, if the lowest validation loss was at the 8th epoch, we utilized the weights and biases obtained at that epoch for the test set.
2.2. Data Imbalance
The dataset exhibited a data imbalance issue [
43]. Due to the large number of O&G wells in our study area, there were significantly more samples representing orphan wells than those without. This can have various impacts on models [
44] such as biased model performance, due to which the majority class is favored, the ability to learn patterns is reduced, data overfitting occurs in the training set, and feature representation is biased.
Two primary ways to deal with this data imbalance are (1) undersampling and (2) oversampling [
45]. Undersampling involves reducing the number of samples from the majority class to create a more balanced dataset. By removing instances from the majority class, we can match the number of samples with the minority class, thereby reducing the class imbalance [
46]. There are multiple ways to perform undersampling, such as random undersampling, cluster-based undersampling, Tomek-links undersampling, or edited nearest neighbors [
47]. Our study, however, limited our scope only to random undersampling. Random undersampling involves randomly selecting a subset of samples from the majority class until the desired balance is achieved. This approach can lead to the loss of potentially valuable information present in the majority class.
Conversely, oversampling involves increasing the number of samples in the minority class to balance the dataset. By replicating or generating synthetic instances, the minority class representation is enhanced, allowing the model to learn its characteristics more effectively. We focused on Rotation–GaussianBlur–Solarization (RGS), the Synthetic Minority Over-Sampling Technique (SMOTE), borderline SMOTE, and Adaptive Synthetic (ADASYN) [
48,
49,
50,
51]. RGS applies a random rotation, Gaussian blur, and solarization to create variations in the minority-class samples. SMOTE generates synthetic samples by interpolating between neighboring instances, expanding the representation of the minority class [
49]. As the name implies, borderline SMOTE targets borderline instances near the decision boundary, generating synthetic samples to improve classification accuracy in these challenging areas [
50]. ADASYN focuses on difficult-to-learn instances by assigning higher weights during the generation process, adaptively balancing the class distribution [
51]. The choice between SMOTE, borderline SMOTE, and ADASYN depends on the dataset’s characteristics and the problem being addressed. We used implementations provided in Scikit-learn [
52] with a random seed of 42 for reproducibility. Additionally, we acknowledge the potential of generative AI, such as generative adversarial networks (GANs), for data augmentation, and we will investigate this approach in future studies.
Apart from undersampling or undersampling techniques, we pre-processed our input stream (satellite data and PH) using classical standardization or z-score normalization [
53]. Standardization transforms the data with a mean of 0 and a standard deviation (std) of 1. The formula for standardization is standardized
, where
x is the original value, the mean is the mean of the dataset, and std is the standard deviation of the dataset. By subtracting the mean and dividing it by the std, the data are centered around 0 and scaled based on the spread of the data.
2.3. Data Fusion with Persistent Homology (PH)
In addition to imagery data represented in RGB format (3 channels), we also explored the integration of PH as an additional input, introducing an extra channel (RGB + PH). PH extracts features from a topological space X based on a function defined within that space. In the context of remote sensing data, we can view the data as a two-dimensional, rough surface where the morphology is described using pixel values (referred to as height, denoted as , where x and y represent the column and row positions, respectively).
To perform PH on a rough surface, such as single-channel remote sensing data, we set a sequence of decreasing heights uniformly spaced between the images’ maximum and minimum pixel values. Conceptually, we can think of this process using the analogy from [
54]: PH on a rough surface is akin to observing a landscape with islands of varying sizes as the sea level changes. No islands are visible when the sea level is high enough (
h > maximum pixel value). This state corresponds to
. As the sea level drops, islands (0-dimensional homological or
features) start to emerge, representing different levels of
and gradually increasing in size (
). Islands can merge as the sea level reaches a saddle location, similar to two islands merging. The formation of isolated pools occurs when further sea level drops are 1-dimensional homological or
features with their boundaries defined by the connected land surrounding them. The levels of pools correspond to the sea level, and eventually, they dry up. The birth and death of islands and pools define the topological structure of the land surface, and PH identifies and quantifies these features. By computing the difference between birth and death, often referred to as the lifetime, we can measure the persistence of these features. In the case of our data—natural-color imagery with a resolution of 1 m—RBG images were converted from RGB to grayscale using the Luminosity method (
) to provide a single-channel surface for analysis. The lifespans of 0-dimensional homology reflect grayscale peaks; thus, PH analysis allowed us to detect and characterize surface features that produced a color contrast to their surroundings.
We utilized the Ripser PH package in Python [
55,
56] to compute PH and visualize persistence diagrams. Ripser PH employs the lower-star filtration method, which enables PH sublevel-set filtration on an image. This technique is particularly suitable for continuous data, treating the image as a continuous entity, rather than a collection of discrete Euclidean points, e.g., [
57,
58]. The lower-star filtration divides the image into segments, ranging from a minimum to a maximum limit, similar to a rising sea level. We inverted each image by scaling it by −1 to accommodate this filtration process. This adjustment allowed us to identify local maxima in the image as births and saddle points as deaths in
. It is important to note that, although PH can provide information on higher-order homology (such as
), the Python implementation of the lower star filtration method only returns
results. We chose this because it allowed us to efficiently map the features’ locations regarding pixel indices. As explained in the following section, this limitation influenced the selection of the most suitable dataset for our purposes.
With the wide range of publicly available remote sensing information, each has pros and cons. In regions with ample vegetation, the presence of a well may be identifiable as clearings or a distinctive lack of vegetation. Magnetic surveys (0–50 m above ground level) are highly suitable for detecting the anomalous magnetic field intensity from well casing. We opted to perform PH on the imagery we were training and testing for binary classification to specifically test whether the images contained PH information that improved the model’s performance, see
Figure 5 for an example of PH.
2.4. Evaluation Metrics
To assess the performance of our approach, we utilized appropriate evaluation metrics. Commonly used metrics for binary classification tasks include overall accuracy (herein referred to as accuracy), recall, and the F1 score. Accuracy measures the overall correctness of the predictions, while recall calculates the proportion of correctly predicted UOWs out of all actual wells. The F1 score is the harmonic mean of precision and recall, providing a balanced measure. We used the implementation provided in Scikit-learn [
52].
We employed accuracy, recall, and the F1 score as evaluation metrics to assess the performance of our models [
59]. These widely used metrics in ML and statistics offer valuable insights into various aspects of model performance, enabling us to evaluate their effectiveness. By considering accuracy, recall, and the F1 score, we comprehensively understand how well our models perform in classification tasks. The description and formulation of these metrics are listed below [
59,
60].
This study focused on key performance metrics such as Accuracy, Recall, and the F1 score, see
Table 1. While Precision is an important metric in evaluating a model’s performance, we opted not to present it separately due to space constraints. It is important to note that Precision can be inferred from the provided metrics. Specifically, Precision can be derived using the F1 score and Recall, as it is integral to calculating the F1 score. The full list of performance metrics is in
Appendix A.
3. Results
Trainable parameters are the weights and biases within the neural network that are updated during the training process. We defined all layers as models that do not employ transfer learning, meaning that these models were built from scratch without pre-trained models and only replaced the last layer with a fresh linear layer. When employing the transfer learning approach, where a pre-trained model is utilized, and only the last layer is replaced, the number of trainable parameters significantly decreases. This is because the pre-trained model has already learned useful features from a large dataset, and only the final layer needs to be fine-tuned to adapt to the specific task at hand.
Table 2 shows that the VGG-13 BN model possesses the highest number of trainable parameters, making it the most computationally expensive model. This implies that the VGG-13 BN architecture has a larger number of layers and more complex network connections, resulting in more parameters to be trained. On the other end of the spectrum, the RegNet-Y 400MF model has the least trainable parameters, making it the least computationally expensive model. This indicates that the RegNet-Y 400MF architecture has a simpler network structure with fewer layers and connections, resulting in fewer parameters that must be trained.
When we incorporated PH as an additional input feature, the number of trainable parameters slightly increased for both the transfer and non-transfer learning approaches. This was not surprising, as the PH feature requires additional weights and biases to be learned within the network, contributing to a marginal rise in the overall number of trainable parameters.
Data Augmentation
As stated before, data imbalance mitigation techniques are required with this particular dataset. Our original dataset consists of 48,400 samples, with 46,778 samples labeled 0 (no DOWs) and 1622 samples labeled 1 (with DOWs). We focused on having a significantly smaller number of samples with DOWs (labeled as 1 in 1622 samples) than those without (labeled as 0 in 46,778 samples). We randomly subsampled the label-0 samples from 46,778 to 3244 samples using a uniform distribution as prior. After the different oversampling techniques were applied, the ratio of samples with DOWs and those without DOWs ranged from 0.49 to 0.54 (
Table 3).
To partition the total samples, we allocated 70% to training, 20% to validation, and 10% to testing. We tested the generalization capability of our model by evaluating it with out-of-distribution data. Specifically, we trained our model using satellite and well data from Okmulgee County, and we tested its performance using satellite and well data from Okmulgee (
Table 4), Carter (
Table 5), and Lincoln (
Table 6) counties. We followed early stopping and generalized cross-validation criteria to prevent overfitting during training [
42]. Rather than strictly stopping the training cycle, we only saved the set of trained weights and biases when the current validation loss was lower than the lowest from all previous training cycles. This approach helped us find the optimal model that minimized the validation loss and improved the generalization performance of our model. All the model performance results presented here are the mean and standard deviation (std) of five runs. Examples of training and validation losses using RegNet-Y 400 MF (
Figure 6) were organized by data augmentation technique.
4. Discussion
4.1. Data Augmentation Tool Comparison
The employed models with no data augmentation approaches yielded near-zero F1 scores, regardless of whether the data were in distribution (Okmulgee) or out of distribution (Carter and Lincoln), which suggests that undersampling might not be the optimal solution for this classification task. While all the models benefited from data augmentation, we highlight the approaches that produced the most favorable results with out-of-distribution data, noting that Carter had far fewer samples with DOWs (78) than Lincoln (558).
RGS augmentation significantly improved the Lincoln models (F1 scores = 0.62–0.69) and, to a lesser degree, improved the Carter models (F1 scores = 0.02–0.24), suggesting a higher degree of similarity between Okmulgee and Lincoln counties (full metrics in
Table A2). SMOTE augmentation improved the Carter models nearly 2× more than RGS augmentation in Carter (full metrics in
Table A3). We interpret this to mean that SMOTE synthesizes new samples from the minority class through interpolation between neighboring samples and enhancing the generalizability of the models. However, the overall out-of-distribution performance was poor (F1 score = 0.25–0.4) indicating that SMOTE augmentation may also remove the similarities between Okmulgee and Lincoln that contributed to significantly improved RGS performance. Borderline SMOTE (full metrics in
Table A4) did not improve model performance beyond what SMOTE already accomplished. ADASYN performed slightly better in Carter and slightly worse in Lincoln (full metrics in
Table A5). SMOTE and ADASYN yielded better results than borderline SMOTE. All three data augmentation tools improved the models compared to those with no augmentation; however, RGS performed much better in Lincoln, likely due to similarities between the Okmulgee and Lincoln samples.
We considered a joint implementation of RGS and SMOTE to improve the SMOTE, borderline SMOTE, and ADASYN performance (full metrics in
Table A9. This had no benefit in the Carter models, and in fact, the performance was worse than with SMOTE alone. The Lincoln models yielded similar F1 scores to RGS alone. These scores indicate that the influence of RGS augmentation on model performance outweighs that of SMOTE techniques.
4.2. Data Augmentation with Pre-Trained Layers
Training only the newly added layer allowed us to adapt the model to our target task while minimizing the risk of overfitting or losing valuable knowledge in the pre-trained layers. The pre-trained models used in this study were obtained from the PyTorch model zoo (
https://pytorch.org/vision/stable/models.html accessed on 22 September 2022), and they came with pre-trained weights learned from large-scale image datasets like ImageNet.
The performance of the RGS, SMOTE, and ADASYN data augmentation techniques using a pre-trained model (full metrics in
Table A6,
Table A7, and
Table A8, respectively) were compared against those same techniques without the use of a pre-trained model. RGS with a pre-trained model is only marginally different from RGS without a pre-trained model. One possible explanation for this minimal difference in RGS performance is that the RGS augmentation technique (which involves rotation, Gaussian blur, and solarization) does not closely resemble the data types to which the pre-trained models were exposed during their training. Pre-trained models are typically trained on large-scale datasets like ImageNet, consisting of natural images with diverse lighting, poses, and object appearance variations. Therefore, the features learned via pre-trained models might not align perfectly with the specific augmentations introduced in RGS.
The performance of SMOTE and ADASYN with a pre-trained model, on the other hand, showed significant improvement in out-of-distribution testing with the Carter models (F1 scores = 0.79–0.90), performing better than the Lincoln models (0.59–0.71). The higher scores obtained in out-of-distribution testing imply that the synthetic data generated via SMOTE augmentation captured important patterns and characteristics present in the training data, aligning more closely with the representations learned via the pre-trained models. As a result, the models became more adept at handling previously unseen data, demonstrating their improved ability to generalize beyond the training distribution.
4.3. Data Augmentation and Data Fusion
Recall that PH data were derived from satellite images and incorporated as a fourth channel. Grayscale images proved the most useful in performing PH to detect our features of interest. In grayscale images, the cleared area surrounding a well has a fairly constant pixel value, and the well structure is a ”bright spot” in the middle. Note that this brightness is a function of the pixel color; different RGB combinations can translate to the same grayscale value. A well is more easily recognized as an
feature in lower-star filtration results (
Figure 5, bottom). The filtration produced what this application considers false positives and true negatives even when we implemented a height cut-off. Nevertheless, the results add a layer of information for ML to consider. This was incorporated in the models with data augmentation and no pre-trained model, as well as data augmentation with a pre-trained model. Since borderline SMOTE showed inferior performance, and ADASYN exhibited such similar behavior to SMOTE, they are not discussed further.
There was a small enhancement when adding PH to RGS-augmented data (full metric in
Table A10) compared to RGS and no PH information. For the Lincoln models, the difference was not notable. For the Carter models, the performance was worse. As noted before, the far better performance in the Lincoln models suggests more similarities between the Okmulgee and Lincoln samples. The PH analysis of Lincoln imagery likely revealed similar patterns as those found in Okmulgee that were absent in Carter, thus making the addition of PH in the Carter models not beneficial. Utilizing a pre-trained model (full metric in
Table A12) resulted in a decline in performance.
The inclusion of PH in SMOTE-augmented data resulted in a decline in performance. Although utilizing a pre-trained model (full metrics in
Table A13) resulted in better performance than without a pre-trained model (full metrics in
Table A11), both results were very poor. We interpret this to indicate that the fourth (PH) channel has the potential to decrease the model’s generalization capabilities, which is an important consideration for overall performance across different testing scenarios.
Our analysis suggests that the RegNetY model delivers the most accurate results across different testing scenarios. For in-distribution testing, where the model was trained and tested with Okmulgee data, using RGS data augmentation with PH augmentation achieved an F1 score of 0.98, with 9493 true positives (TPs) and only 293 false negatives (FNs). In out-of-distribution testing, when the model was trained on Okmulgee data and tested on Carter data, using SMOTE data augmentation without PH augmentation resulted in an F1 score of 0.90, with 46 true positives and 10 false negatives. For testing with Lincoln data, using RGS data augmentation with PH augmentation produced an F1 score of 0.73, with 129 true positives and 97 false negatives. This demonstrates the model’s high performance and the effectiveness of different augmentation techniques under varying conditions.
It is worth noting that, for future studies, one can explore different strategies for freezing and retraining specific parts of the models. This includes freezing some intermediate layers while retraining others, providing more flexibility in leveraging pre-trained models. Such investigations could uncover additional insights into the transferability of features across different layers and their impact on a model’s performance.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}