1. Introduction
Feature point matching, as a fundamental and crucial process in computer vision tasks, aims to perform consistency or similarity analysis on contents or structures with the same or similar attributes in two images and achieve recognition and alignment at the pixel level [
1]. The aligned features of the image can be taken as an input for high-level vision tasks, such as vision simultaneous localization and mapping (VSLAM) [
2,
3], structure from motion (SFM) [
4,
5] and 3D reconstruction [
6]. Generally, the images to be matched are usually taken from the same or similar scenes or targets, or other types of images with the same shape or semantic information. Point features typically represent pixel points or interest points in the image that have significant characteristics, making them simple and stable. Moreover, other features can be converted into point features for matching. Therefore, feature matching based on point features is a fundamental problem.
Typical feature matching methods consist of four parts: feature detection, feature description, descriptor matching, and mismatch removal. Feature detection is extracting key points. With key points extracted from the image, the next step is to calculate descriptors to establish the initial relation between key points in the image pair. Feature description can be categorized into two types: histogram of gradient (HoG) descriptors and binary descriptors. For the former type, Lowe et al. [
7] first proposed the well-known Scale-Invariant Feature Transform (SIFT) algorithm. Others, such as Speed Up Robust Feature (SURF) [
8] and Principal Components Analysis SIFT (PCA-SIFT) [
9], are improved algorithms of the SIFT. Binary descriptor uses Hamming distance to measure the similarity of key points, such as binary robust independent elementary features (BRIEF) [
10], binary robust invariant scalable keypoints (BRISK) [
11], and fast retina keypoint (FREAK) [
12].
Descriptor matching is a matching strategy for generating putative correspondences by using the similarity between descriptors. Brute-force (BF) matcher [
13] utilizes the distance, e.g., Euclidean distance and Hamming distance, between descriptors to generate matched key points. Lowe et al. [
7] proposed a ratio test (RT), which compares the distance between the first- and the second-nearest neighbors for identifying distinctive correspondences. Muja et al. [
14] proposed a fast library for approximate nearest neighbors (FLANN) matcher, which finds correspondences in building and searching for the approximate nearest neighbor search tree.
In recent years, more and more scholars use deep learning to solve the problems of image matching. Verdie et al. [
15] proposed a learning-based key point detection algorithm, a Temporally Invariant Learned Detector (TILDE), which exhibits good robustness in scenes with severe changes of illumination. Yi et al. [
16] proposed Learned Invariant Feature Transform (LIFT), which is the first end-to-end trainable deep-learning-based feature extraction network. DeTone et al. [
17] proposed the SuperPoint algorithm, which has shown excellent performance in efficiency and accuracy. Sarlin et al. [
18] proposed the SuperGlue algorithm, which builds on the SuperPoint algorithm and extends it to handle challenging matching scenarios, such as occlusions, large changes in viewpoint or lighting conditions, and repetitive structures. Feature matching methods based on deep learning exhibit strong learning capabilities and end-to-end advantages. However, they also face challenges in terms of data requirements, training complexity, and interpretability. Typical methods [
19,
20] have high computational efficiency and are suitable for real-time processing in resource-constrained environments. Additionally, they often do not require large amounts of data for training and can achieve good performance on small-scale datasets. However, typical methods usually rely on manually designed feature extractors, and their performance is greatly influenced by the design of these features.
The feature matching methods based on the feature descriptors mentioned above only extract the local information of the key points, and are also affected by image distortion and noise. Only exploring the similarity between descriptors is not sufficient, and additional constraints are needed to further filter out correct matches, i.e., mismatch removal. One of the most popular methods is the Random Sampling Consensus (RANSAC) [
21] algorithm, which is a resampling-based iterative method. It estimates the transformation model between the matching point sets by repeated random sampling and finds the maximum inlier set that fits its predefined model as the correct matching point pair. A series of optimizations and improvements for resampling methods have been conducted, such as Maximum Likelihood Estimation Sample Consensus (MLESAC) [
22], Locally Optimized RANSAC (LO-RANSAC) [
23], Progressive Sampling Consensus (PROSAC) [
24], Graph-Cut RANSAC (GC-RANSAC) [
25], Marginalizing Sample Consensus (MAGSAC) [
26], MAGSAC++ [
27], and Triangular Topology Probability Sampling Consensus (TSAC) [
28]. Raguram et al. [
29] proposed Universal Sample Consensus (USAC), differing from RANSAC, which uses a unified framework that allows for the estimation of multiple models simultaneously, as well as the use of different scoring metrics to evaluate the quality of the models. Nevertheless, the performance of resampling methods relies on the number of correct matches, and these methods are not suitable for situations where dynamic objects exist.
Many researchers attempted to add additional constraints to eliminate incorrect matches. Ma et al. [
30] proposed a vector field consensus (VFC) algorithm, which uses Tikhonov regularization within the framework of Reproducing Kernel Hilbert Space (RKHS) to iteratively optimize the vector field that formed by the displacement vectors between the matching points, as well as using the optimal vector field to remove mismatches. Bian et al. [
31] proposed a grid-based motion statistics (GMS) algorithm, which encapsulates motion smoothness in a local region. Though the motion consistency assumption is a good hypothesis for eliminating wrong matches, its assumption can be invalidated at image edges, where adjacent pixels may belong to separate objects with independent motion patterns. Similar algorithms to GMS include locality-preserving matching (LPM) [
32] and motion-consistency-driven matching (MCDM) [
33].
Unlike an RGB (Red Green Blue) image, which only provides texture information, an RGBD (Red Green Blue Depth) image combines depth information into an image and offers additional information to reveal the inherent structure and form of the scene. Karpushin et al. [
34] focused on extracting key points in RGBD images and proposed a detector, which employed means of depth value of the surface within the scene to obtain viewpoint-covariant key points. The TRISK (Tridimensional Rotational Invariant Surface Keypoints) [
35] algorithm is a local feature extraction method in an RGBD image; experimental results indicate that this method fits a low-cost computational platform. Cong et al. [
36] proposed a co-saliency detection method for RGBD images, which introduces depth information and multi-constraint feature matching to extract common salient regions among a set of images. Bao et al. [
37,
38] suggested converting depth information into a 3-D point cloud and extracting feature points from a pair of matched point cloud planes, which has been validated to perform well in terms of accuracy.
For removing more incorrect matches from dynamic objects and obtaining more reliable true matches, we proposed a robust mismatch removal method in this paper, which is named LCS-SSM. Inspired by GMS, LCS-SSM utilizes motion consistency assumption and structural similarity within a local region to filter wrong matches. Moreover, we use a resampling method to complement the shortcoming of the motion consistency assumption that it cannot recognize isolated true matches. The main contributions of this paper are as follows: (1) Unlike a typical mismatch removal algorithm that only relies on the smoothness constraint of texture features, we combine the smoothness constraint and structural similarity of RGB images to discern potentially correct matches preliminarily, which enhances the robustness of image matching. (2) To resolve the problem that motion consistency assumption invalidates in edges, we integrate depth images to distinguish key points located in fast-moving objects. We use Hu moments and the direction of a gradient to measure the structural similarity between a local region of a corresponding depth image pair, which enables us to distinguish that matched key points are located in a static object and dynamic object. (3) We introduce a resampling-based method to preserve isolated true matched points that do not satisfy the motion consistency assumption that we use the number of matches within the neighborhood of the matched key points to discern true and false matches.
In the rest of this paper, our organization is as follows: In
Section 2, we introduce the proposed mismatch removal method in detail. We conduct a series of experiments to demonstrate the performance of the proposed algorithm in
Section 3. In
Section 4, we analyze the result of the experiments and, finally, give a conclusion in
Section 5.
2. Proposed Method (LCS-SSM)
In this section, the proposed mismatch removal method LCS-SSM is presented in detail.
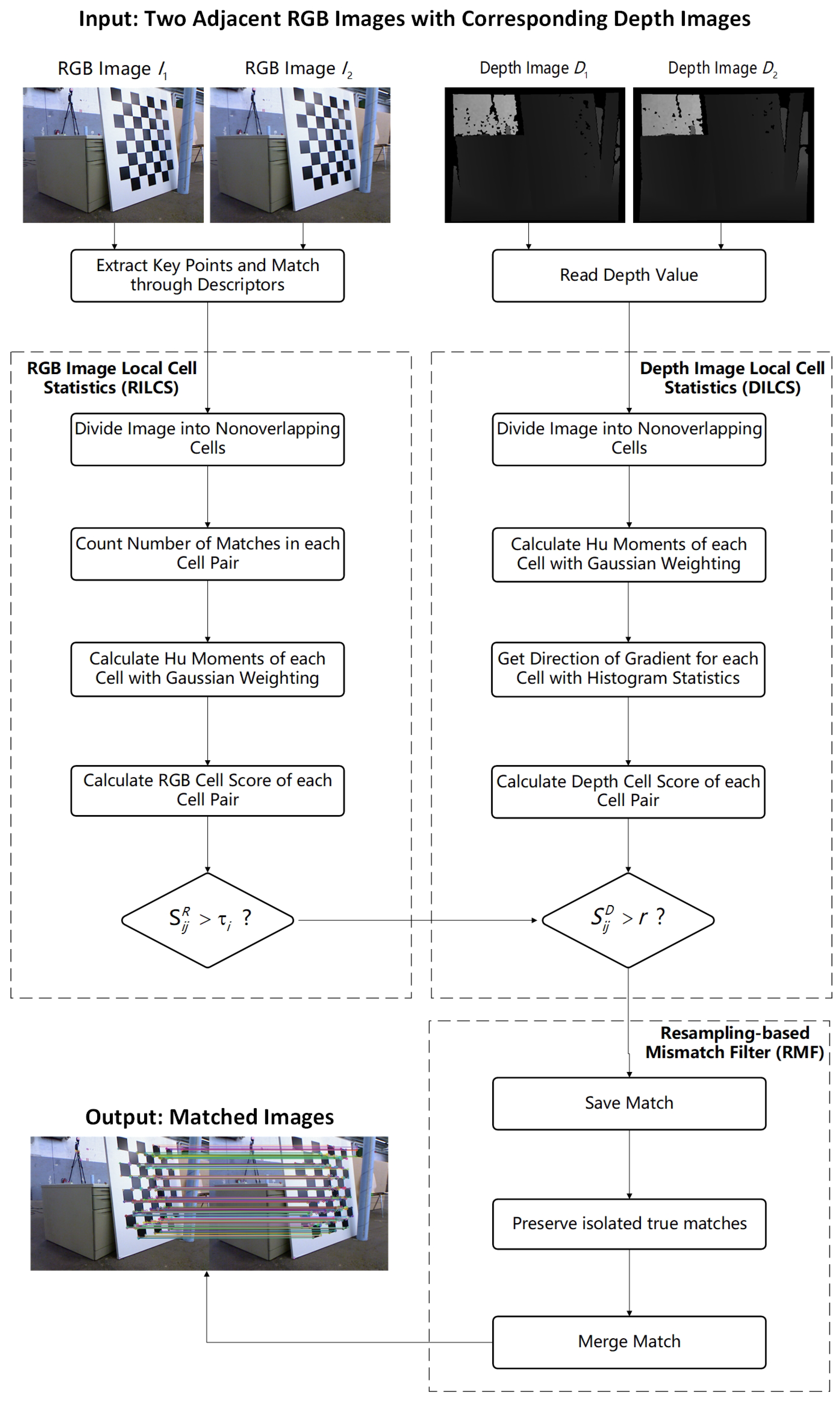
Figure 1 demonstrates a flowchart of the proposed LCS-SSM. First, we propose an RGB image local cell statistics algorithm (RILCS) to discern potentially correct matches within a local cell region. For the input RGB images
and
, the first step of the proposed RILCS is to extract key points. The original matched image is generated by calculating descriptors and matched key points by brute force. Then we divide
and
into nonoverlapping cells, which is for counting the number of matches
and calculating Hu moments within a local cell region conveniently. For each cell, we calculate the RGB cell score
that determines the cell pair of matches into the input of the proposed DILCS algorithm.
The depth image local cell statistics algorithm (DILCS) is presented to verify the reliability of the cell region. Simultaneously, for the adjacent depth images and corresponding to the RGB images and , the proposed DILCS algorithm performs a similar operation to the RILCS algorithm. We divide and into the same nonoverlapping cells with and , and calculate the Hu moments of each cell. Then we use the Sobel operator to detect edges for obtaining the direction of the gradient of the cell region. Then we calculate the depth cell score, which is used to ultimately determine whether a pair of matched points is correct.
Lastly, we propose a resampling-based mismatch filter algorithm (RMF) to preserve isolated true matches, which is to ensure that isolated true matches that cannot satisfy the requirement of the RILCS algorithm can be preserved. Assume that is a set of true matches and is a set of false matches that are output by the RILCS and DILCS algorithms. is used as an input of the RANSAC algorithm to obtain a highly reliable homography matrix that can be used to fit and filter out the isolated true matches.
2.1. Structural Similarity Measurement
Structural similarity is a significant metric for enhancing the robustness of image matching, and many algorithms are proposed to characterize image structural similarity. In this paper, we introduce Hu moments [
39] to measure the structural similarity between images.
Hu moments of an image, as a type of image feature, exhibit desirable properties of translation, rotation, and scale invariance, which are composed of multiple normalized central moments. To obtain the Hu moments of an image, it is necessary to calculate the raw moments and central moments first. Assuming that there are M × N pixels, raw moments m and central moments
can be calculated using the following formula:
where
is a gray level of the pixel located at the horizontal coordinate
x and the vertical coordinate
y. Additionally,
,
represents centroid coordinates of the image. We can further calculate the normalized central moments
and Hu moments
v as follows:
2.2. RGB Image Local Cell Statistics
In scenarios involving severe occlusion, deformation, or variations in illumination, local feature descriptors may lose their effective matching capability. Similarly, in images containing abundant repetitive textures, the uniqueness of descriptors might diminish, resulting in increased uncertainty in matching. Therefore, given putative matches to differentiate true and false correspondences by descriptors solely is unreliable. Meanwhile, the efficiency of the image-matching strategy based on descriptors is exhaustively needed for a real-time environment. To solve this problem, the motion consistency assumption is introduced to distinguish true and false matches, which is a simple, intuitive, and robust constraint. This basic property of motion consistency constraint assumes that objects move smoothly between image pairs, which means that pixels that are close to each other in the spatial coordinates of the image will move together. Therefore, we can assume that the likelihood that adjacent pixels belong to a single rigid object or structure results in correlated motion patterns among them. According to this, true correspondences are expected to exhibit analogous motion patterns, thereby displaying greater similarity to neighboring points within a certain region than false correspondences.
To quantify the influence caused by the analogous motion pattern of pixels, we use the number of matches within the neighborhood of the matched key points to discern true and false matches. For the input of RGB images
and
, we set
as one of the matches across
and
, which connects key points
and
. Then we can define the neighborhood of
as follows:
where
d is the Euclidean distance of two points, and
h is a threshold.
To discern true and false matches, we model the probability of
being correct or incorrect as follows:
where
B refers to the binomial distribution, and
is the number of matches within
.
t and
separately represent probabilities that
M is true and false matches.
Therefore, the standardized mean difference between true and false matches can be defined as follows:
where
and
are expectation, and
and
are variations that
M is true and false, respectively. It shows that we increase the number of matches
and improve the quality of the match
t; the increased separability between true and false matches leads to more reliable correct matches.
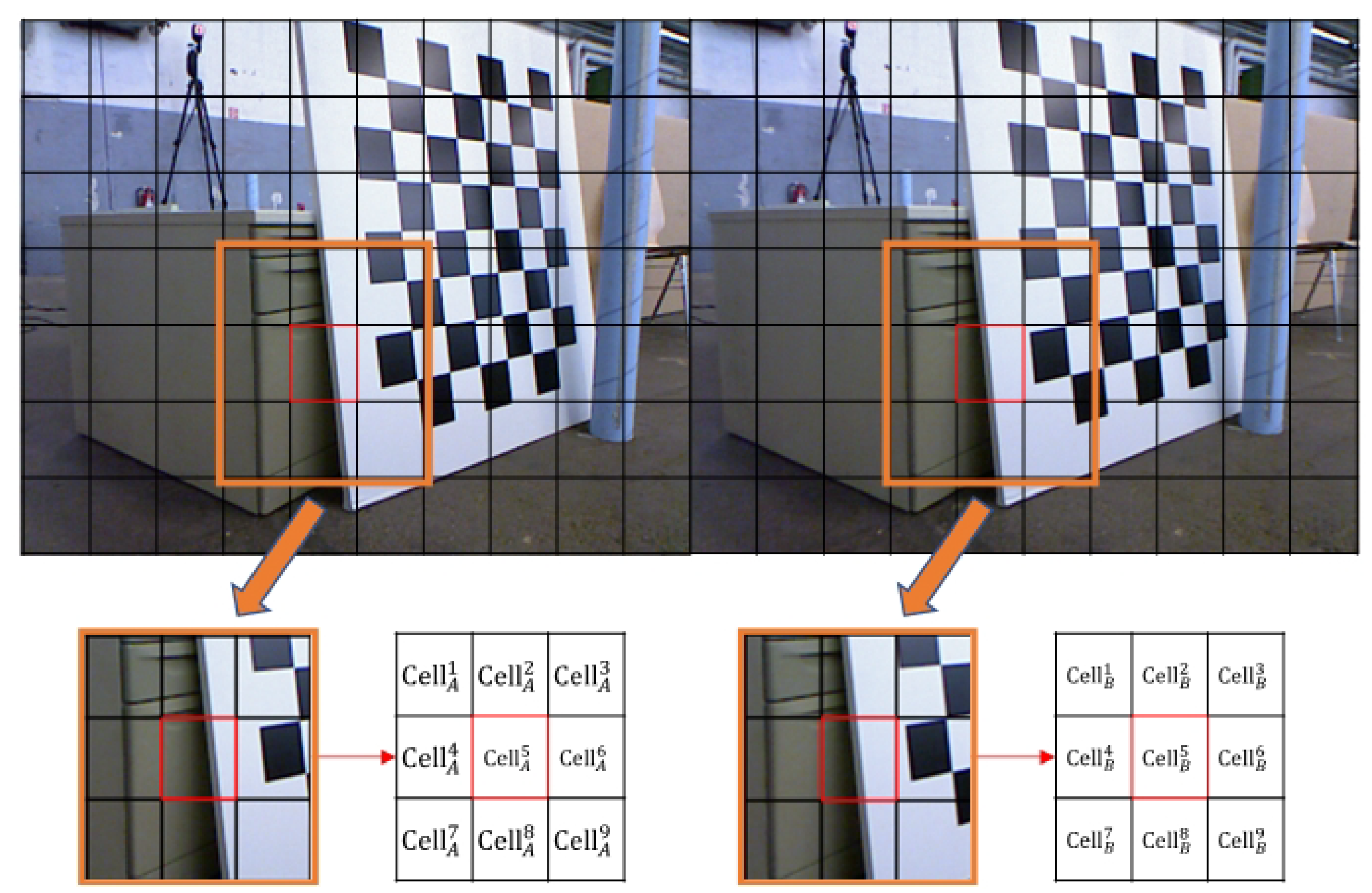
To quantify the size of the neighborhood of matched key points and enhance computational efficiency, we introduce a grid-based processing approach for images. Original image pairs are divided into nonoverlapped cells. Assuming that the resolution ratio of an image is
:
, for uniformly generating same-size cells, we determine the size of cells with the following formula:
where
is the resolution of each cell, and
is an experimental coefficient to determine the specific size of a cell.
Given specific cells in the image, such as that shown in
Figure 2, with a motion consistency assumption and Equations (
5), (
7) and (
8), we define the RGB cell score
, which indicates that all correspondences have scores to differentiate true and false matches for an RGB image. Therefore,
actually refers to the score of
, which indicates the correctness of matches across
and
to a certain extent, as follows:
where
c is a constant to prevent the denominator from being zero,
is the number of matches between
and
, and
represents the n-th order Hu moment of a cell.
Let
be the threshold of
to determine the cell pair of
into the input of depth image local cell statistics.
When , we consider that is potentially correct and sets the cell pair as an input of a depth image local cell statistics algorithm, which can verify the reliability of the cell region.
2.3. Depth Image Local Cell Statistics
As mentioned above, the motion consistency assumption provides a good hypothesis to limit the occurrence of a mismatch. Meanwhile, we noticed that the assumption can be invalidated at image edges, where adjacent pixels may pertain to distinct objects with independent motion patterns. To mitigate such circumstances, we use structural similarity in a depth image as a crucial constraint to differentiate between true and false correspondences.
The RGB image merely captures the chromaticity of the visual world, without providing any additional information of its inherent structure or form. Thus, it is challenging to distinguish objects with independent motion patterns in image pairs based on RGB channels. Depth images can effectively compensate for this shortcoming, which can capture the spatial information regarding the objects within a scene.
In
Figure 3, there exist wrong matches caused by high-speed motion objects, which are difficult to differentiate with RGB channel images solely. Meanwhile, obvious differences between wrong matches are exposed in the same region of the corresponding depth image. There exist substantial disparities in the depth values of regions containing rapidly moving objects between two consecutive frames of depth images.
Similarly, we introduce a grid-based processing approach for depth images, which can quantify the impact of analogous motion patterns of pixels of local regions. We divide the depth image into nonoverlapping cells and utilize the structural similarity of a local region of a depth image to identify true correspondences. Let
be one of the cells in the former depth image
and
be one of the cells in the latter depth image
. We calculate the Hu moments of each cell with Gaussian weighting; thus, we can obtain a vector of Hu moments, as follows:
where
represents the n-th order a Hu moment of a cell.
We perform edge detection using the Sobel operator to obtain the gradient of
and
. In
Figure 4, we demonstrate several edge detection algorithms for depth images. In our work, we do not place a significant emphasis on the accuracy of image edge extraction, as we need to consider the overall structure of a local region of an mage and do not require high specificity for fine textures. Therefore, using the Sobel operator for image edge detection ensures a certain degree of accuracy while maintaining high efficiency.
To obtain the main direction of the gradient of a cell that has numerous pixels, we divide the value range of a depth value into
equal bins. For each cell, we count the number of pixels
in each bin of the value range. Let
be the main direction of the gradient of a cell, which can be calculated by the following:
To enhance the robustness of the gradient direction in matching, the corresponding direction will be considered the auxiliary direction of the gradient
for the corresponding cell if the secondary peak value exceeds 60% of the main direction peak value. Therefore, we can obtain a vector of a gradient direction as follows:
With a vector of Hu moments and a gradient direction of a cell, we define the depth cell score
between
and
as follows:
where
c is a constant to prevent the denominator from being zero. Several indices of depth image are considered comprehensively, making
good indicators for differentiating evident motions from a background within a certain region.
Assuming that
is considered as a suspected true match, we calculate the depth cell score
of cells that is located in
. Let
r be the threshold of
to determine whether the matched key point is true and false matches, as follows:
where
r represents an empirical threshold used to ultimately determine whether a pair of matched points in this set is correct. Actually, a depth cell score is a combination of cosine similarities where the value range is
; therefore, we set
experimentally.
2.4. Resampling-Based Mismatch Filter
Resampling-based feature matching methods are a class of classical algorithms for mismatch removal that aim to estimate the predefined transformation model between the matched point sets, i.e., the homography matrix between two images, by repeatedly sampling from the initial matches. In this way, these methods seek to find the maximum inlier set that satisfies the estimated model as the true matches. However, these methods are limited by the reliance on the accuracy of sampling, for instance, when a large number of false matches exist in the initial matching. In such cases, not only will the estimated homography matrix have a significant error due to the presence of a large number of outliers, but also the number of sampling iterations will significantly increase, resulting in a considerable increase in the time complexity of the algorithm.
Meanwhile, RILCS algorithm perform well in the region that exists numerous matches to satisfy motion consistency assumption. However, relying solely on local cell statistics cannot identify the true matches that are isolated matches in a partial region. For there are no other matches in the neighbor to support correctness of the isolated true matches.
For preserving isolated true matches, we propose a resampling-based mismatch filter algorithm. Assume that is a set of true matches and is a set of false matches that are output by the RILCS and DILCS algorithms. For , which is a set with a considerable number of true matches, using it as an input to the RANSAC algorithm can compensate for the dependence of resampling-based algorithms on the correctness of the initial matches. Therefore, a highly reliable homography matrix can be obtained, which can be used to fit and filter out the isolated true matches.
The details of the LCS-SSM algorithm will be explained in Algorithm 1.
| Algorithm 1 LCS-SSM Algorithm |
Require: Two adjacent RGB images , and corresponding depth images , .
Ensure: A set of true matches between and .
1: Detect key points and calculate corresponding descriptors for and .
2: Divide , , , and into nonoverlapping cells, respectively.
3: Locate matched key points in and .
4: for each matched key point do
5: Statistic number of matches within neighbor of and .
6: Calculate RGB cell score and corresponding threshold .
7: if then
8: Save and .
9: Calculate depth cell score .
10: if then
11:
12: else
13:
14: end if
15: end if
16: end for
17: Using as input of RANSAC algorithm to calculate homography matrix H.
18: Using H to fit , preserve true matches from .
19: |
4. Discussion
Traditional feature matching methods are unreliable because they solely rely on feature detectors and descriptors to distinguish true and false correspondences. To solve this problem, we introduce a simple, intuitive, and robust constraint and motion consistency assumption, which assumes that pixels that are close to each other in the spatial coordinates of the image will move together. However, this assumption does not invariably hold true, which can be invalidated at image edges, where adjacent pixels may pertain to distinct objects with independent motion patterns. We select four sequences from the TUM RGB-D dataset, which all have quickly moving dynamic objects within most of the scenes that can invalidate the motion consistency assumption. The performance of methods like GMS, which is solely based on the motion consistency assumption, is demonstrated in
Figure 3. To inhibit the impact of the above scenarios, we introduce another crucial element, the structural similarity of an image, which is a significant metric that can reflect the similarity in structure between two images, to further eliminate more wrong matches that satisfy the motion consistency assumption. In addition, we utilize a resampling method to preserve isolated true matches that dissatisfy the RILCS. By integrating the aforementioned theories and methods, we propose the LCS-SSM algorithm.
However, it has to be mentioned that LCS-SSM requires a sufficient number of matched key points to obtain as many as possible true matches. The accuracy of LCS-SSM is decreased by insufficient matched key points. Especially when facing a scene with low texture and structure and using the key point extraction algorithm that cannot provide adequate true matched key points in the challenging scenario, LCS-SSM may be invalidated. Therefore, how to improve the performance of the mismatch removal method in cases with low texture and having fewer key points is the next work of our team.
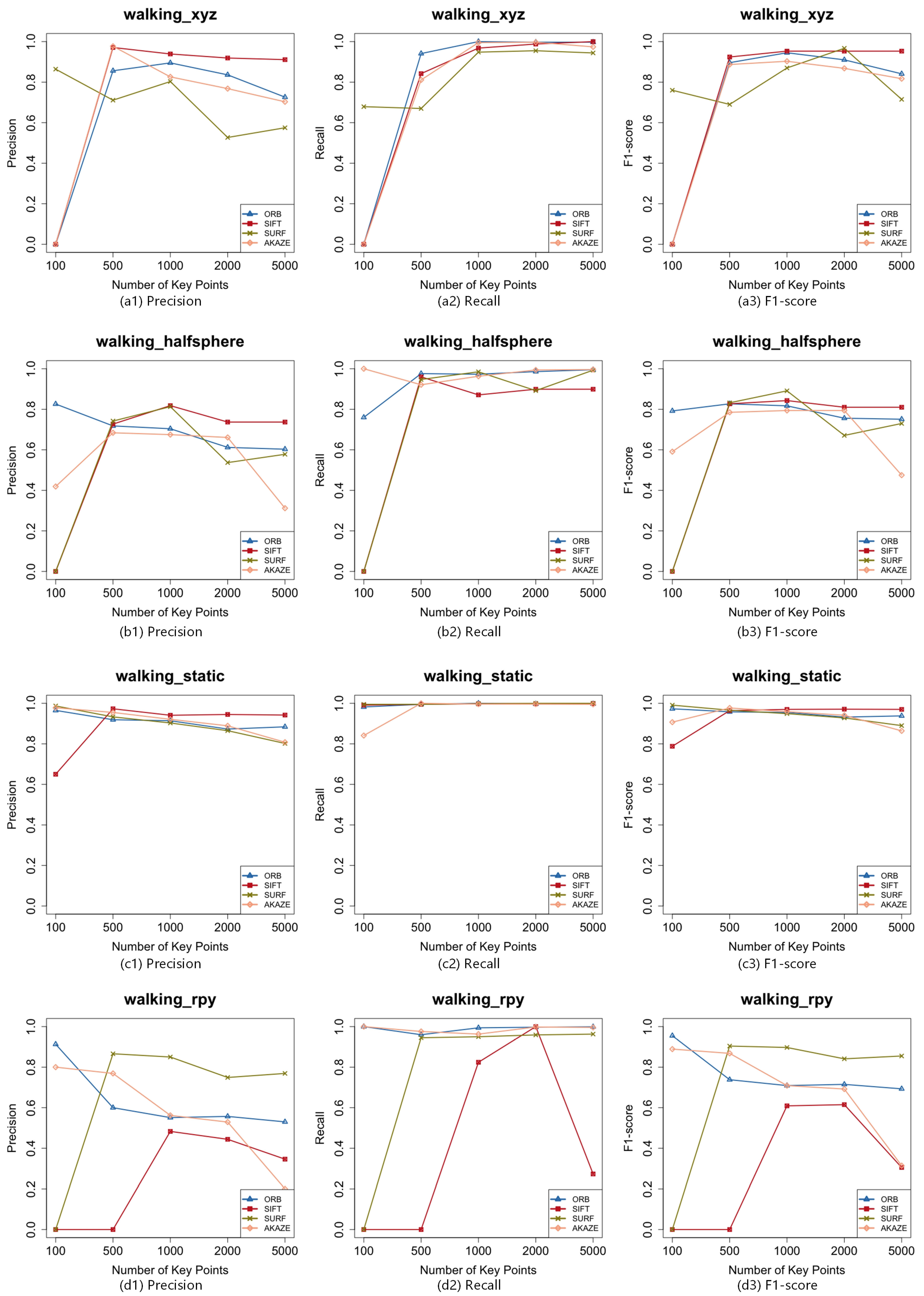
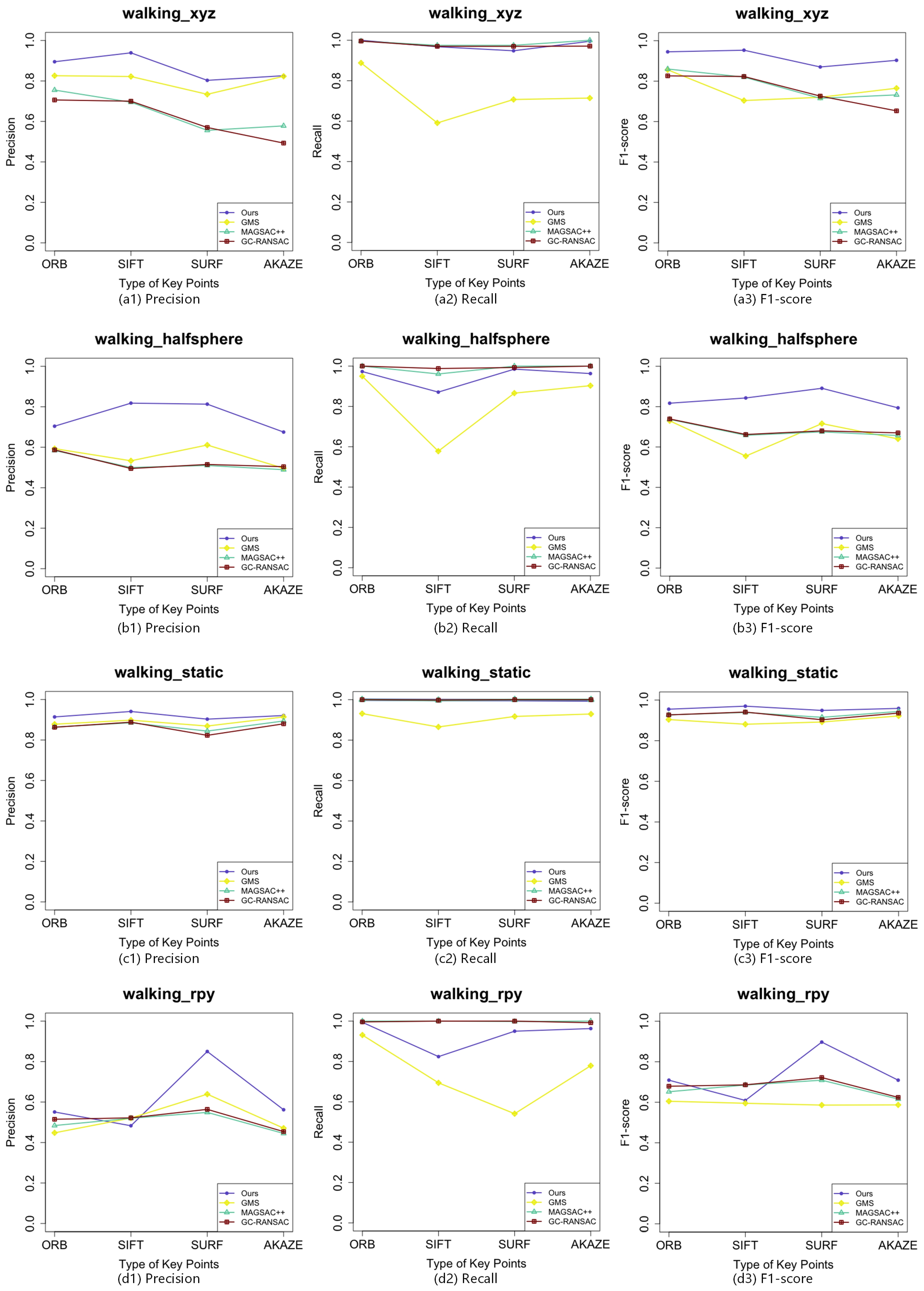
According to our experimental results, LCS-SSM performs well in using various types of key points and sequences with different difficulties, which is the most outstanding algorithm compared with the state-of-the-art methods in the area of mismatch removal. More specifically, the precision performance of LCS-SSM using SURF on the four sequences has improved by 19.38% on average, which is the highest compared with the values of 9.1% of ORB, 13.91% of SIFT, and 12.6% of AKAZE. However, it can be seen from
Figure 7 that the recall performance of LCS-SSM is slightly lower than those of others. The F1-score performance of LCS-SSM has improved by 7% using ORB, 9.83% by using SIFT, 15.55% by using SURF, and 11.23% by using AKAZE. In terms of the runtime of LCS-SSM, although the execution times are related to the number of key points, it maintains high efficiency even when processing 5000 key points. It costs about 50 milliseconds to process a pair of RGBD images in a single CPU thread.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}