


ABNet: An Aggregated Backbone Network Architecture for Fine Landcover Classification
Abstract
1. Introduction
2. Related Work
2.1. Backbones for Remote Sensing Image Semantic Segmentation Work
2.2. Research on Fine Landcover Classification with Semantic Segmentation Network
3. Methods
3.1. Aggregated Backbone Network
3.2. Basic Backbone Networks
3.2.1. Residual Network (ResNet)
3.2.2. High-Resolution Network (HRNet)
3.2.3. Variety of View Network (VoVNet)
3.3. Backbone Ensemble
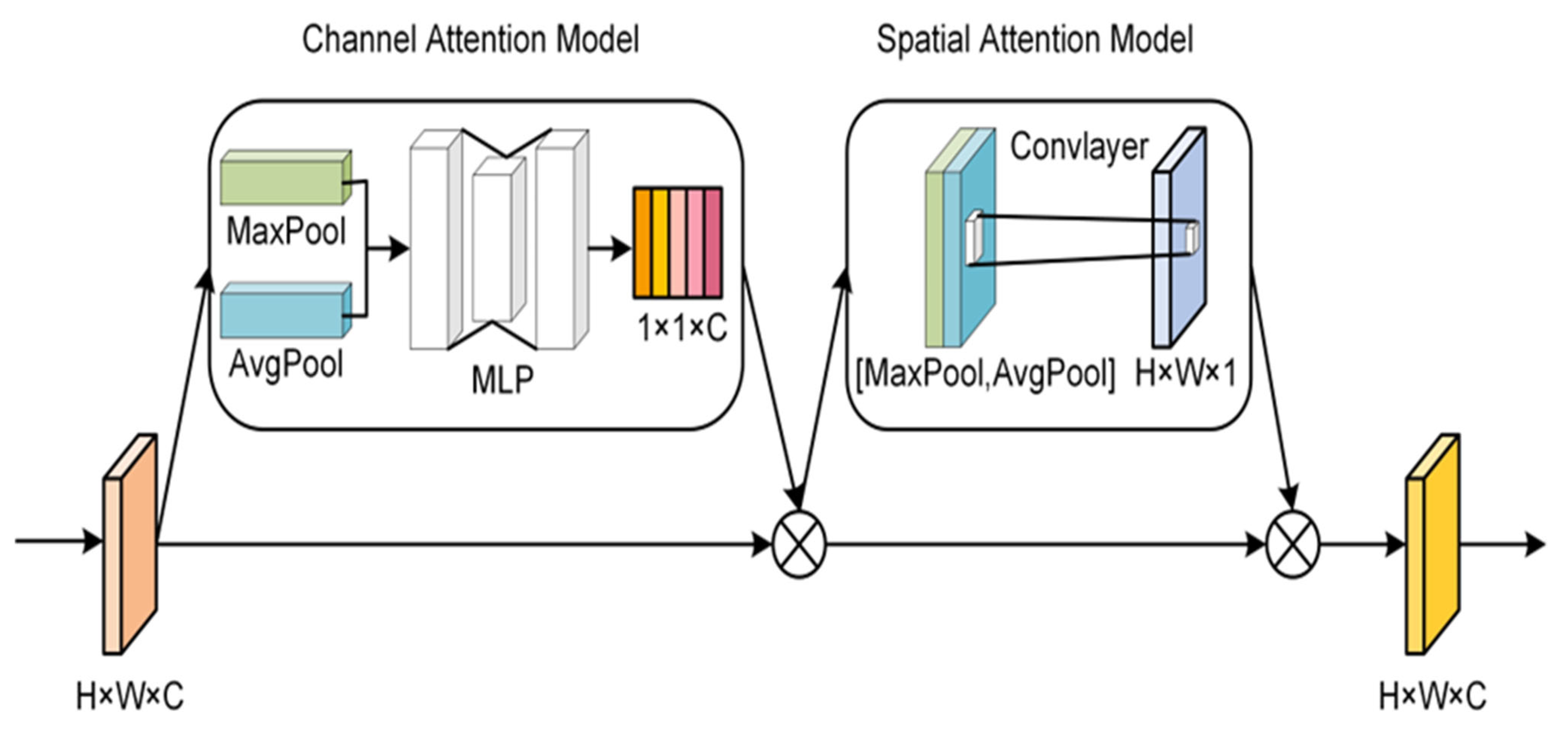
3.4. Convolutional Block Attention Module (CBAM)
4. Experiments and Results
4.1. Datasets
4.1.1. LoveDA Dataset
4.1.2. Gaofen Image Dataset (GID)
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Ablation Studies
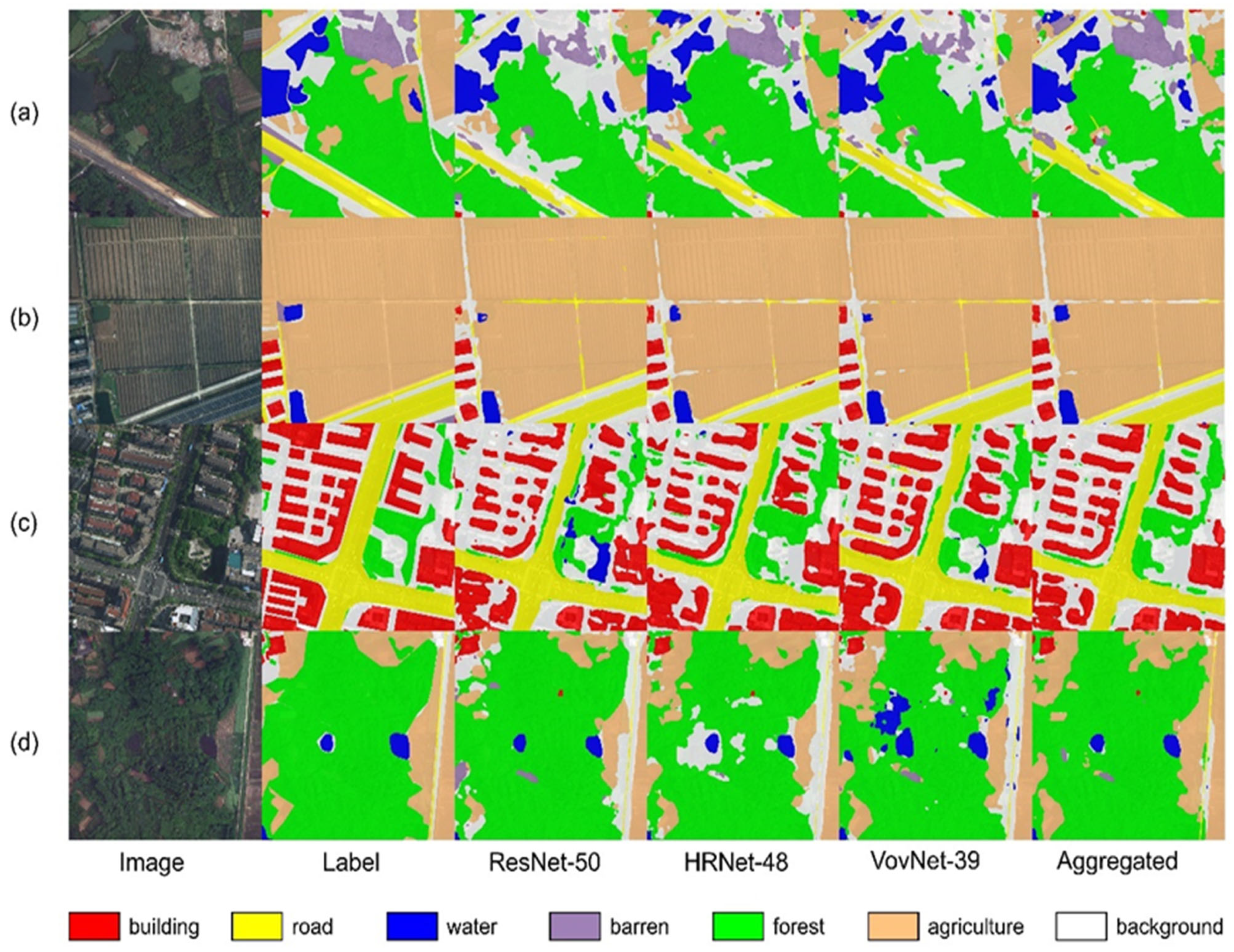
4.4.1. LoveDA Dataset
4.4.2. GID15 Dataset
4.5. Comparing with the State-of-the-Art
4.5.1. LoveDA Dataset
4.5.2. GID15 Dataset
5. Discussion
5.1. Advantages and Limitations
5.1.1. Advantages
5.1.2. Limitations
5.2. Potential Improvements
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Y.Z.; Sun, Y.H.; Cao, X.Y.; Wang, Y.H.; Zhang, W.K.; Cheng, X.L. A review of regional and Global scale Land Use/Land Cover (LULC) mapping products generated from satellite remote sensing. ISPRS J. Photogramm. Remote Sens. 2023, 206, 311–334. [Google Scholar] [CrossRef]
- Su, Y.; Qian, K.; Lin, L.; Wang, K.; Guan, T.; Gan, M.Y. Identifying the driving forces of non-grain production expansion in rural China and its implications for policies on cultivated land protection. Land Use Policy 2020, 92, 104435. [Google Scholar] [CrossRef]
- Boguszewski, A.; Batorski, D.; Ziemba-Jankowska, N.; Dziedzic, T.; Zambrzycka, A. LandCover.ai: Dataset for Automatic Mapping of Buildings, Woodlands, Water and Roads from Aerial Imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 1102–1110. [Google Scholar]
- Tong, X.Y.; Xia, G.S.; Zhu, X.X. Enabling country-scale land cover mapping with meter-resolution satellite imagery. ISPRS J. Photogramm. Remote Sens. 2023, 196, 178–196. [Google Scholar] [CrossRef] [PubMed]
- Sertel, E.; Ekim, B.; Osgouei, P.E.; Kabadayi, M.E. Land Use and Land Cover Mapping Using Deep Learning Based Segmentation Approaches and VHR Worldview-3 Images. Remote Sens. 2022, 14, 4558. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.L.; Ye, Y.X.; Yin, G.F.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic Segmentation of Small Objects and Modeling of Uncertainty in Urban Remote Sensing Images Using Deep Convolutional Neural Networks. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 680–688. [Google Scholar]
- Ye, Z.R.; Fu, Y.Y.; Gan, M.Y.; Deng, J.S.; Comber, A.; Wang, K. Building Extraction from Very High Resolution Aerial Imagery Using Joint Attention Deep Neural Network. Remote Sens. 2019, 11, 2970. [Google Scholar] [CrossRef]
- Fu, Y.Y.; Liu, K.K.; Shen, Z.Q.; Deng, J.S.; Gan, M.Y.; Liu, X.G.; Lu, D.M.; Wang, K. Mapping Impervious Surfaces in Town-Rural Transition Belts Using China’s GF-2 Imagery and Object-Based Deep CNNs. Remote Sens. 2019, 11, 280. [Google Scholar] [CrossRef]
- Zhang, D.J.; Pan, Y.Z.; Zhang, J.S.; Hu, T.G.; Zhao, J.H.; Li, N.; Chen, Q. A generalized approach based on convolutional neural networks for large area cropland mapping at very high resolution. Remote Sens. Environ. 2020, 247, 111912. [Google Scholar] [CrossRef]
- Kumar, D.G.; Chaudhari, S. Comparison of Deep Learning Backbone Frameworks for Remote Sensing Image Classification. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 7763–7766. [Google Scholar]
- Wieland, M.; Martinis, S.; Kiefl, R.; Gstaiger, V. Semantic segmentation of water bodies in very high-resolution satellite and aerial images. Remote Sens. Environ. 2023, 287, 113452. [Google Scholar] [CrossRef]
- Liu, Y.D.; Wang, Y.T.; Wang, S.W.; Liang, T.T.; Zhao, Q.J.; Tang, Z.; Ling, H.B. CBNet: A Novel Composite Backbone Network Architecture for Object Detection. In Proceedings of the 34th AAAI Conference on Artificial Intelligence/32nd Innovative Applications of Artificial Intelligence Conference/10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11653–11660. [Google Scholar]
- Liang, T.T.; Chu, X.J.; Liu, Y.D.; Wang, Y.T.; Tang, Z.; Chu, W.; Chen, J.D.; Ling, H.B. CBNet: A Composite Backbone Network Architecture for Object Detection. IEEE Trans. Image Process. 2022, 31, 6893–6906. [Google Scholar] [CrossRef]
- Elharrouss, O.; Akbari, Y.; Almaadeed, N.; Al-Maadeed, S. Backbones-Review: Feature Extraction Networks for Deep Learning and Deep Reinforcement Learning Approaches. arXiv 2022, arXiv:2206.08016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Lee, Y.W.; Hwang, J.W.; Lee, S.; Bae, Y.; Park, J. An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 752–760. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J.D. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5686–5696. [Google Scholar]
- Tan, M.X.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2Net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef] [PubMed]
- Ye, M.; Ruiwen, N.; Chang, Z.; He, G.; Tianli, H.; Shijun, L.; Yu, S.; Tong, Z.; Ying, G. A Lightweight Model of VGG-16 for Remote Sensing Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6916–6922. [Google Scholar] [CrossRef]
- Tao, C.X.; Meng, Y.Z.; Li, J.J.; Yang, B.B.; Hu, F.M.; Li, Y.X.; Cui, C.L.; Zhang, W. MSNet: Multispectral semantic segmentation network for remote sensing images. GIScience Remote Sens. 2022, 59, 1177–1198. [Google Scholar] [CrossRef]
- Liu, K.; Yu, S.T.; Liu, S.D. An Improved InceptionV3 Network for Obscured Ship Classification in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4738–4747. [Google Scholar] [CrossRef]
- Xu, Y.Y.; Xie, Z.; Feng, Y.X.; Chen, Z.L. Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Zhao, L.R.; Niu, R.Q.; Li, B.Q.; Chen, T.; Wang, Y.Y. Application of Improved Instance Segmentation Algorithm Based on VoVNet-v2 in Open-Pit Mines Remote Sensing Pre-Survey. Remote Sens. 2022, 14, 2626. [Google Scholar] [CrossRef]
- Guo, S.C.; Yang, Q.; Xiang, S.M.; Wang, P.F.; Wang, X.Z. Dynamic High-Resolution Network for Semantic Segmentation in Remote-Sensing Images. Remote Sens. 2023, 15, 2293. [Google Scholar] [CrossRef]
- Hu, S.; Liu, J.; Kang, Z.W. DeepLabV3+/Efficientnet Hybrid Network-Based Scene Area Judgment for the Mars Unmanned Vehicle System. Sensors 2021, 21, 8136. [Google Scholar] [CrossRef]
- Das, A.; Chandran, S. Transfer Learning with Res2Net for Remote Sensing Scene Classification. In Proceedings of the 11th International Conference on Cloud Computing, Data Science and Engineering (Confluence), Uttar Pradesh, India, 28–29 January 2021; pp. 796–801. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.E.; Zhu, Y.K.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Zhao, H.S.; Shi, J.P.; Qi, X.J.; Wang, X.G.; Jia, J.Y. Pyramid Scene Parsing Network. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.J.; Li, Y.; Bao, Y.J.; Fang, Z.W.; Lu, H.Q. Dual Attention Network for Scene Segmentation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3141–3149. [Google Scholar]
- Xiao, T.T.; Liu, Y.C.; Zhou, B.L.; Jiang, Y.N.; Sun, J. Unified Perceptual Parsing for Scene Understanding. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 432–448. [Google Scholar]
- Huang, Z.L.; Wang, X.G.; Wei, Y.C.; Huang, L.C.; Shi, H.; Liu, W.Y.; Huang, T.S. CCNet: Criss-Cross Attention for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6896–6908. [Google Scholar] [CrossRef]
- Liang, C.B.; Xiao, B.H.; Cheng, B.; Dong, Y.Y. XANet: An Efficient Remote Sensing Image Segmentation Model Using Element-Wise Attention Enhancement and Multi-Scale Attention Fusion. Remote Sens. 2023, 15, 236. [Google Scholar] [CrossRef]
- Wang, D.; Yang, R.H.; Liu, H.H.; He, H.Q.; Tan, J.X.; Li, S.D.; Qiao, Y.C.; Tang, K.Q.; Wang, X. HFENet: Hierarchical Feature Extraction Network for Accurate Landcover Classification. Remote Sens. 2022, 14, 4244. [Google Scholar] [CrossRef]
- Chen, C.; Zhao, H.L.; Cui, W.; He, X. Dual Crisscross Attention Module for Road Extraction from Remote Sensing Images. Sensors 2021, 21, 6873. [Google Scholar] [CrossRef] [PubMed]
- Ye, Z.R.; Si, B.; Lin, Y.; Zheng, Q.M.; Zhou, R.; Huang, L.; Wang, K. Mapping and Discriminating Rural Settlements Using Gaofen-2 Images and a Fully Convolutional Network. Sensors 2020, 20, 6062. [Google Scholar] [CrossRef]
- Kotaridis, I.; Lazaridou, M. Cnns in land cover mapping with remote sensing imagery: A review and meta-analysis. Int. J. Remote Sens. 2023, 44, 5896–5935. [Google Scholar] [CrossRef]
- Bigdeli, B.; Pahlavani, P.; Amirkolaee, H.A. An ensemble deep learning method as data fusion system for remote sensing multisensor classification. Appl. Soft Comput. 2021, 110, 107563. [Google Scholar] [CrossRef]
- Fan, R.Y.; Feng, R.Y.; Wang, L.Z.; Yan, J.N.; Zhang, X.H. Semi-MCNN: A Semisupervised Multi-CNN Ensemble Learning Method for Urban Land Cover Classification Using Submeter HRRS Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4973–4987. [Google Scholar] [CrossRef]
- Cao, Y.; Huo, C.L.; Xu, N.; Zhang, X.; Xiang, S.M.; Pan, C.H. HENet: Head-Level Ensemble Network for Very High Resolution Remote Sensing Images Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506005. [Google Scholar] [CrossRef]
- Ekim, B.; Sertel, E. Deep neural network ensembles for remote sensing land cover and land use classification. Int. J. Digit. Earth 2021, 14, 1868–1881. [Google Scholar] [CrossRef]
- Mao, M.; Zhang, B.; Doermann, D.; Guo, J.; Han, S.; Feng, Y.; Wang, X.; Ding, E. Probabilistic Ranking-Aware Ensembles for Enhanced Object Detections. arXiv 2021, arXiv:2105.03139. [Google Scholar]
- Chen, M.H.; Fu, J.L.; Ling, H.B. One-Shot Neural Ensemble Architecture Search by Diversity-Guided Search Space Shrinking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 16525–16534. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Tong, X.Y.; Xia, G.S.; Lu, Q.K.; Shen, H.F.; Li, S.Y.; You, S.C.; Zhang, L.P. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- Xia, L.; Zhao, F.; Chen, J.; Yu, L.; Lu, M.; Yu, Q.Y.; Liang, S.F.; Fan, L.L.; Sun, X.; Wu, S.R.; et al. A full resolution deep learning network for paddy rice mapping using Landsat data. ISPRS J. Photogramm. Remote Sens. 2022, 194, 91–107. [Google Scholar] [CrossRef]
- Qiang, J.; Liu, W.J.; Li, X.X.; Guan, P.; Du, Y.L.; Liu, B.; Xiao, G.L. Detection of citrus pests in double backbone network based on single shot multibox detector. Comput. Electron. Agric. 2023, 212, 108158. [Google Scholar] [CrossRef]
- Neupane, B.; Horanont, T.; Aryal, J. Deep Learning-Based Semantic Segmentation of Urban Features in Satellite Images: A Review and Meta-Analysis. Remote Sens. 2021, 13, 808. [Google Scholar] [CrossRef]
- Cui, Z.Y.; Li, Q.; Cao, Z.J.; Liu, N.Y. Dense Attention Pyramid Networks for Multi-Scale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Zhang, Y.H.; Lu, H.Y.; Ma, G.Y.; Zhao, H.J.; Xie, D.L.; Geng, S.T.; Tian, W.; Sian, K. MU-Net: Embedding MixFormer into Unet to Extract Water Bodies from Remote Sensing Images. Remote Sens. 2023, 15, 3559. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | First Publication | Features | Application in Remote Sensing |
|---|---|---|---|
| VGG-16 [16] | 2014 | Deep convolutional network | Topography and geomorphology classification [24] |
| ResNet-50 [17] | 2016 | Residual connection | Multispectral image classification [25] |
| Inceptionv3 [18] | 2016 | Multi-scale convolutional kernel | Sheltered Vessels classification [26] |
| DenseNet [19] | 2017 | Dense connection of all layers | Road extraction [27] |
| VoVNet [20] | 2019 | Dense connection of the final layer | Open-pit mine extraction [28] |
| HRNet [21] | 2019 | Parallel connection of multi-resolution layers | Landcover classification [29] |
| EfficientNet [22] | 2019 | Neural structure search | Mars scene recognition [30] |
| Res2Net [23] | 2021 | Hierarchical residual connection | Remote sensing scene recognition [31] |
| Stage | HRNet-48 | ResNet-50 | VoVNet-39 |
|---|---|---|---|
| Stem | 3 × 3 conv, 64, stride = 2 3 × 3 conv, 64, stride = 2 | 7 × 7 conv, 64, stride = 2 3 × 3 max pool, stride = 2 | 3 × 3 conv, 64, stride = 2 |
| Stage1 | ×4 | ×3 | 3 × 3 conv, 64, stride = 1 3 × 3 conv, 128, stride = 1 |
| Stage2 | ×4 | ×4 | ×1 |
| Stage3 | ×4 | ×6 | ×1 |
| Stage4 | ×4 | ×3 | ×2 |
| Stage5 | ×2 |
| Backbone | Background | Building | Road | Water | Barren | Forest | Agricultural |
|---|---|---|---|---|---|---|---|
| ResNet-50 | 52.19 | 56.03 | 51.51 | 62.85 | 22.4 | 39.83 | 50.56 |
| HRNet-48 | 52.87 | 59.63 | 53.01 | 60.85 | 29.23 | 38.58 | 47.66 |
| VoVNet-39 | 48.98 | 62.51 | 53.51 | 61.32 | 18.06 | 37.48 | 45.65 |
| ABNet | 53.85 | 63.69 | 54.06 | 69.99 | 33.86 | 40.23 | 51.33 |
| Class | ResNet-50 | HRNet-48 | VoVNet-39 | ABNet |
|---|---|---|---|---|
| Background | 70.01 | 69.61 | 70.47 | 73.02 |
| Industrial land | 59.51 | 60.03 | 61.93 | 63.43 |
| Urban residential | 64.34 | 63.58 | 66.57 | 67.38 |
| Rural residential | 56.03 | 54.18 | 58.09 | 57.81 |
| Traffic land | 59.93 | 63.86 | 63.9 | 64.05 |
| Paddy field | 63.07 | 65.8 | 64.52 | 68.22 |
| Irrigated land | 71.37 | 71.29 | 71.24 | 73.27 |
| Dry cropland | 59.01 | 56.68 | 58.76 | 61.06 |
| Garden plot | 31.38 | 39.54 | 24.02 | 44.22 |
| Arbor woodland | 78.35 | 78.64 | 75.52 | 79.39 |
| Shrub land | 13.67 | 23.15 | 21.67 | 29.3 |
| Natural grassland | 61.94 | 62.54 | 64.06 | 67.01 |
| Artificial grassland | 24.37 | 24.53 | 32.62 | 30.03 |
| River | 79.85 | 78.81 | 80.48 | 82.7 |
| Lake | 70.99 | 67.99 | 69.79 | 71.69 |
| Pond | 62.29 | 64.01 | 63.99 | 66.86 |
| mIoU | 57.88 | 59.02 | 59.23 | 62.47 |
| Model | Backbone | OA | mIoU | mAcc |
|---|---|---|---|---|
| UNet | ResNet-50 | 63.50 | 45.10 | 61.76 |
| FPN | ResNet-50 | 67.88 | 49.76 | 62.99 |
| PSPNet | ResNet-50 | 68.82 | 50.53 | 62.08 |
| DANet | ResNet-50 | 68.19 | 48.73 | 60.13 |
| CBNet | CB-ResNet50 | 68.26 | 50.28 | 62.39 |
| UPerNet | ResNet-50 | 68.72 | 50.36 | 62.03 |
| CCNet | ResNet-50 | 68.87 | 50.92 | 63.72 |
| ABNet | Aggregated Backbone | 72.75 | 52.43 | 67.82 |
| Model | Backbone | OA | mIoU | mAcc |
|---|---|---|---|---|
| UNet | ResNet-50 | 81.33 | 54.89 | 65.39 |
| FPN | ResNet-50 | 81.74 | 59.66 | 67.77 |
| PSPNet | ResNet-50 | 82.05 | 60.78 | 68.48 |
| DANet | ResNet-50 | 82.19 | 60.84 | 68.83 |
| CCNet | ResNet-50 | 82.29 | 60.46 | 69.09 |
| UPerNet | ResNet-50 | 82.27 | 61.09 | 69.54 |
| CBNet | CB-ResNet50 | 82.83 | 61.27 | 68.92 |
| ABNet | Aggregated Backbone | 83.27 | 62.47 | 72.74 |
| Method | Parameters (M) | FLOPs (T) |
|---|---|---|
| Deeplabv3plus_Res-50 | 41.22 | 0.71 |
| Deeplabv3plus_HRNet-48 | 68.59 | 1.01 |
| Deeplabv3plus_VoVNet-39 | 34.27 | 0.88 |
| DANet | 47.93 | 0.96 |
| PSPNet | 46.61 | 0.72 |
| CCNet | 47.46 | 0.84 |
| UPerNet | 64.04 | 0.95 |
| CBNet | 69.71 | 1.08 |
| ABNet | 170.26 | 1.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Si, B.; Wang, Z.; Yu, Z.; Wang, K. ABNet: An Aggregated Backbone Network Architecture for Fine Landcover Classification. Remote Sens. 2024, 16, 1725. https://doi.org/10.3390/rs16101725
Si B, Wang Z, Yu Z, Wang K. ABNet: An Aggregated Backbone Network Architecture for Fine Landcover Classification. Remote Sensing. 2024; 16(10):1725. https://doi.org/10.3390/rs16101725
Chicago/Turabian StyleSi, Bo, Zhennan Wang, Zhoulu Yu, and Ke Wang. 2024. "ABNet: An Aggregated Backbone Network Architecture for Fine Landcover Classification" Remote Sensing 16, no. 10: 1725. https://doi.org/10.3390/rs16101725
APA StyleSi, B., Wang, Z., Yu, Z., & Wang, K. (2024). ABNet: An Aggregated Backbone Network Architecture for Fine Landcover Classification. Remote Sensing, 16(10), 1725. https://doi.org/10.3390/rs16101725