1. Introduction
In modern technology, radar plays an important role in environment interpretation. The increased demands of industries on sensors’ abilities promote the development of the radar system. Modern radar has evolved toward high resolution, namely high-resolution radar (HRR) [
1]. Abundant information about target details is available in HRR, which enables target imaging and recognition based on the radar system. However, the high resolution of radar brings not only benefits but also challenges for traditional radar task, such as target detection [
2].
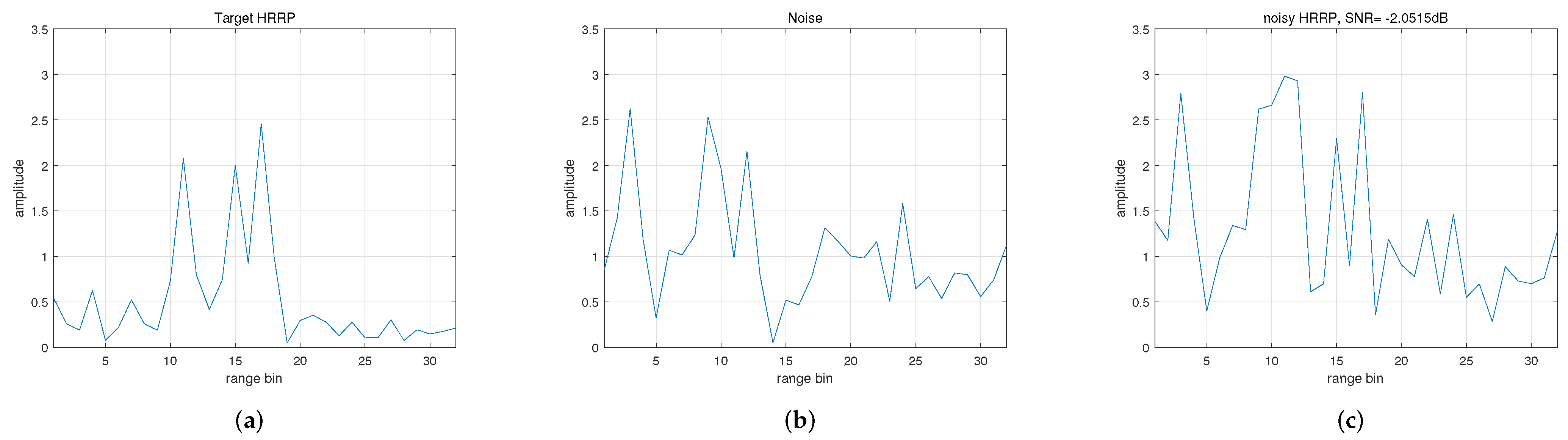
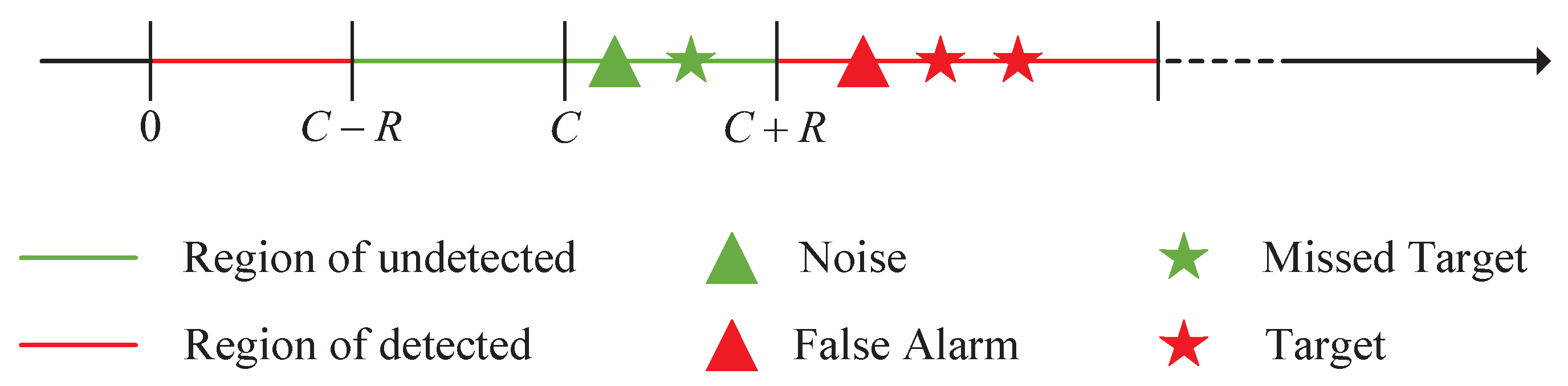
In HRR, a single target does not appear as a point target in traditional low-resolution radar (LRR) but rather as a spread target consisting of multiple scattering centers. A radar with high resolution on the range dimension results in a one-dimension high-resolution range profile (HRRP) in the receiving window. The target in there is represented by several scatterers within a range window, i.e., the range-spread target (RST). The HRRP enables the observation of structural characteristics of an RST. However, the energy of an RST is spread into scatterers in different range bins, and the signal-to-noise ratio (SNR) of a single scatterer is lower than that of the whole target. Therefore, the target detection in HRR is much more difficult than in LRR.
Over the past few decades, the detection of an RST in HRR is a major concern of researchers, and significant progress has been made. To mitigate the performance degradation caused by target energy dispersion, a reasonable way is to improve the integration efficiency, namely improving the output SNR by integrating target dispersed energy as well as suppressing noise.
In [
3], two types of detectors are considered for RST detection, i.e., an energy integration (EI) detector and M out of N (M/N) detector. The EI detector integrates the energy of all range bins in an HRRP indiscriminately. Therefore, not only the dispersed target energy is integrated but also the energy of noise. This could lead to performance degradation when most of the integrated range bins are noise-occupied: namely, the target scatterers are sparsely distributed in the HRRP. For the M/N detector, it is implemented in a way of double-threshold detection. The first threshold figures out range bins, which are target-occupied and the binary integrated result is compared with the second threshold to determine whether a target is present. The M/N detector is designed for sparse target, but the performance lacks robustness. The two detectors are basics of adaptive RST detection exploiting target scattering characteristic.
An enhanced EI detector is proposed in [
4], which uses an optimized window to lessen the collapsing loss but requires an additional search process. Several double-threshold detectors are proposed for improvement of the M/N detector [
5,
6,
7]. The GLRT-DT in [
5] optimizes the selection of the first threshold by information criterion and energy integration is used to replace the binary integration to avoid the performance loss. However, there could be a misjudgement between range bins of target and noise, resulting in performance degradation.
In [
8], the designed SDD-GLRT detector exploits an a priori assumption of the target scattering characteristic to achieve better detection performance. However, the detection performance will be degraded using mismatched priori knowledge. The ASCE-GLRT detector in [
9] treats the estimation of the target scattering characteristic as a problem of sparse optimization to avoid the priori requirement, but the calculated dynamic regularization parameter is influenced by noise and will affect the performance.
The detectors in [
10,
11,
12] perform cross-correlation between consecutive HRRPs to exploit the similarity in HRRPs. The MCOM detector in [
10] proposes a nonlinear shrinkage (NLS) function for the noise reduction of HRRP to mitigate the impact of noise on cross-correlation. But the effect of NLS function for noise reduction can result in a loss of target energy and lead to performance degradation, especially for dense targets. The detector in [
13] combines a time-frequency feature with sparse representation to realize target detection, which involves complicated computation. An order statistics-based detector is proposed in [
14]. The range bins are sorted by energy and integrated to perform target detection. However, the calculation of the detection threshold requires iterative computation.
The above-mentioned detectors make every effort to improve the detection performance. The key idea is to distinguish the noise and target scatterers. However, in the case of a low SNR, it could be challenging, and the detection performance is usually limited.
In recent years, deep learning with its superiority is explored by researchers and applied to various radar tasks [
15,
16,
17], including radar target detection [
18].
Deep learning-based background data processing is studied to benefit radar target detection [
19,
20,
21,
22]. The proposed network in [
19] is based on the convolutional neural network (CNN) and realizes a classification of background noise and clutter. However, it can only be used to serve the selection of detection methods, and further work is required. Traditional constant false alarm rate (CFAR) algorithms are improved based on deep learning [
20,
21,
22]. In [
21], the noise estimation process is optimized in the presence of masking effects. The proposed model in [
22] enhances the background estimation in the presence of interfering targets using a peak sequence classification network, and targets are detected based on a CFAR regulation processor. These methods focus on the optimization of background noise processing which is beneficial to the target detection, but the detection performance is still limited by the used CFAR methods.
Two detection networks are proposed in [
23,
24]. They are based on the raw radar data and eliminate the need for the preprocessing of a radar signal. In [
23], a model for the multitask target detection network is proposed. The input is across three dimensions, corresponding to sampling in the range, pulse and channel. Target detection and motion parameters estimation such as range, velocity, and angle are realized based on the designed network. However, the extra estimation tasks will affect the detection performance, and the false alarm rate of the designed network is not considered. The proposed network in [
24] is based on an artificial neural network (ANN) and takes the time-domain frequency modulated continuous wave (FMCW) signal as input. Traditional fast Fourier transform and CFAR procedures are replaced by the network, but the performance of the network requires a high SNR level to outperform a traditional CFAR detector.
The two-dimensional (2D) spectrum of radar data is commonly used for deep learning-based detectors. In [
25], a deep learning-based detector is proposed to help object detection in traffic scenes. The proposed detector combines the YOLOv8 (You Only Look Once) [
26] architecture with the ConvLSTM (Convolution and Long Short-Term Memory) structure and attention module to treat the time series of a range-Doppler spectrum. The additional information from the time series improves the performance of the proposed detector but also leads to the increase in computation complexity. In [
27], a CNN detector is proposed based on the LENET [
28], which performs target detection based on the range-Doppler spectrum. Binary labels are used to represent the hypotheses, and target detection is treated as a classification problem. However, the false alarm rate of the proposed detector is changed with SNR, which is undesirable for radar detection.
An HRRP recognition network is proposed in [
29]. The time-related feature is extracted based on the combination of the CNN-based autoencoder and the LSTM structure. The classification of target HRRP and noise is based on the support vector data description (SVDD) [
30] in which a hyper-sphere is established as the classification judgement condition. However, the LSTM structure is with limited performance gain. In [
31], marine target detection is considered via CNN. The proposed detector takes the processed time-Doppler spectrum and amplitude information as dual-channel input. Features of input are extracted and fused for further classification. The control of the false alarm rate is discussed and realized using a variable threshold softmax classifier and false alarm controllable support vector machines (SVMs). However, the detection performance is affected by the control of the false alarm rate.
Overall, radar target detection based on deep learning is promising. Therefore, in this work, the detection of an RST is considered in the scenarios of a single HRRP and double HRRPs, and deep learning-based detectors are designed to improve the detection performance.
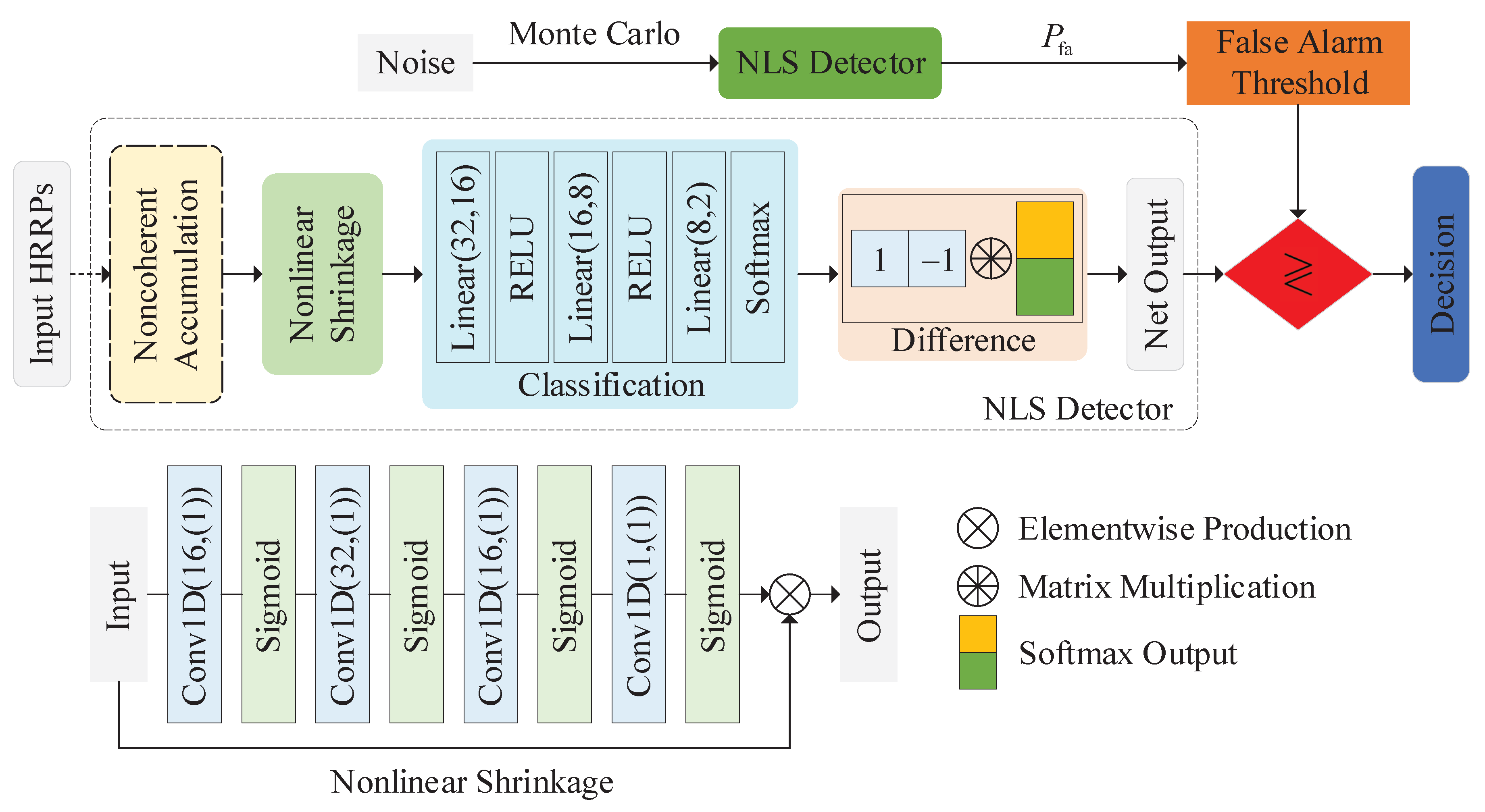
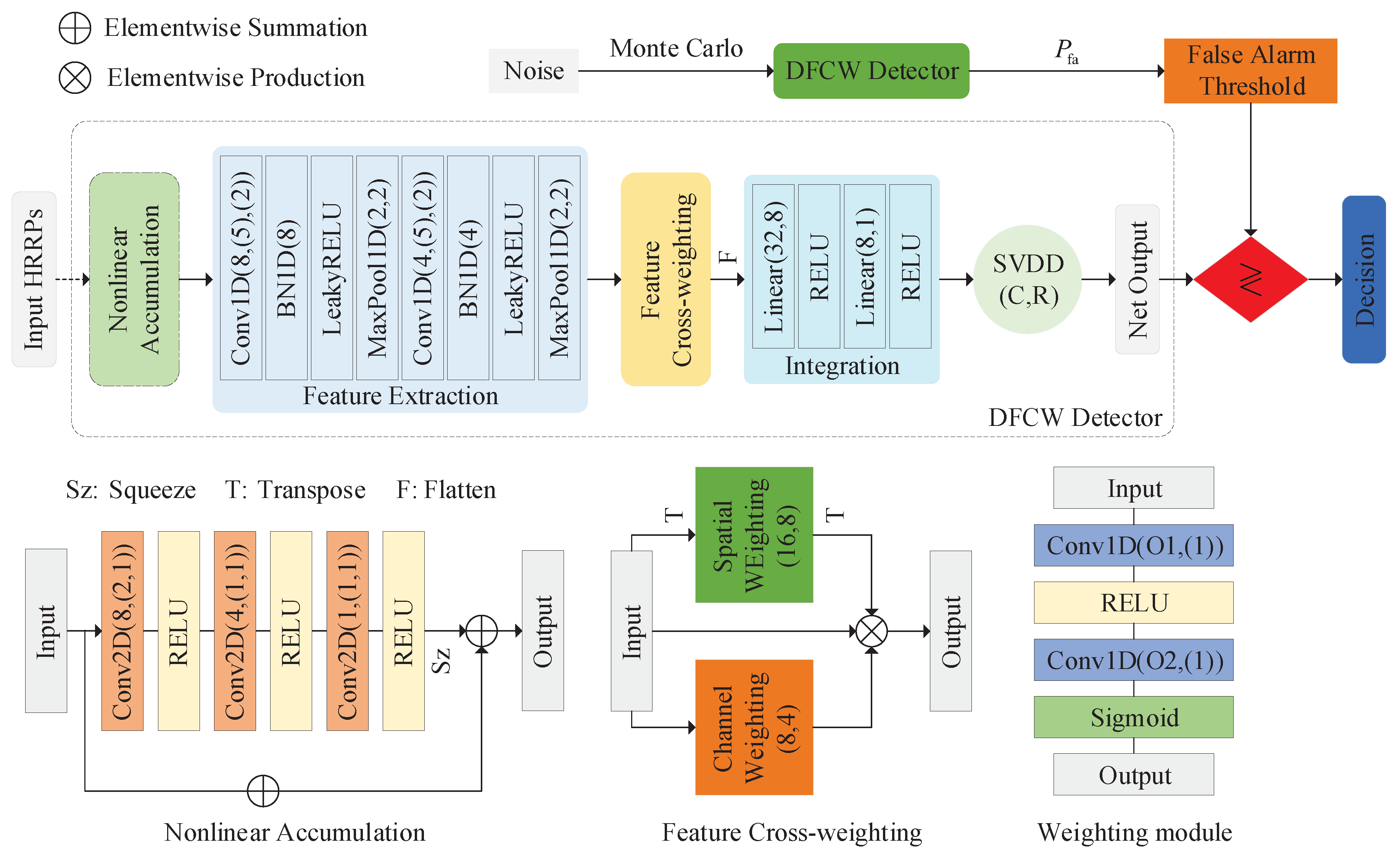
Two network detectors for RST detection are proposed in this paper based on different design philosophies. The first detector is a nonlinear shrinkage based detector (NLS detector). Denoising is a common method used to improve the performance of radar [
32] and sonar systems [
33,
34,
35]. Therefore, the proposed NLS detector takes the HRRP as a low-level feature vector, and an NLS module is designed for noise reduction, referring to the traditional mapping function in the MCOM detector [
10]. The RST detection is regarded as a binary classification problem, and a classifier with two output neurons is introduced to obtain the classification result. Finally, the classification output is combined with a difference module to realize the control of the false alarm rate. The second detector is a deep feature cross-weighting based detector (DFCW detector). The DFCW detector, referring to the CNN-LSTM detector [
29], introduces the CNN-based feature extraction module to obtain the high-level feature map of the HRRP, and target detection is treated as anomaly detection based on the SVDD. A feature cross-weighting module, considering channel and spatial information jointly, performs element-wise feature weighting in the feature map to select important features. The weighted feature map is then integrated into a statistical feature and used in SVDD to perform anomaly detection. For a double-HRRP detection scenario, a nonlinear accumulation module is designed to replace the traditional noncoherent accumulation operation and to improve the detection performance. For performance evaluation, the simulated dataset and measured dataset based on real target echoes are generated. The two datasets take into account the range-spread characteristic of the target to analyze its influence on detection performance. Finally, the effectiveness of the proposed network detectors is verified and compared with traditional and deep learning-based detectors. The contributions of this work are summarized as follows:
An NLS module is designed assisted by the domain knowledge of a traditional detector. The NLS module learns a data adaptive mapping function to perform noise suppression for the input HRRP. Based on the NLS module, a network detector for RST detection is proposed, which takes the denoised HRRP as a low-level feature vector and realizes target detection via binary classification.
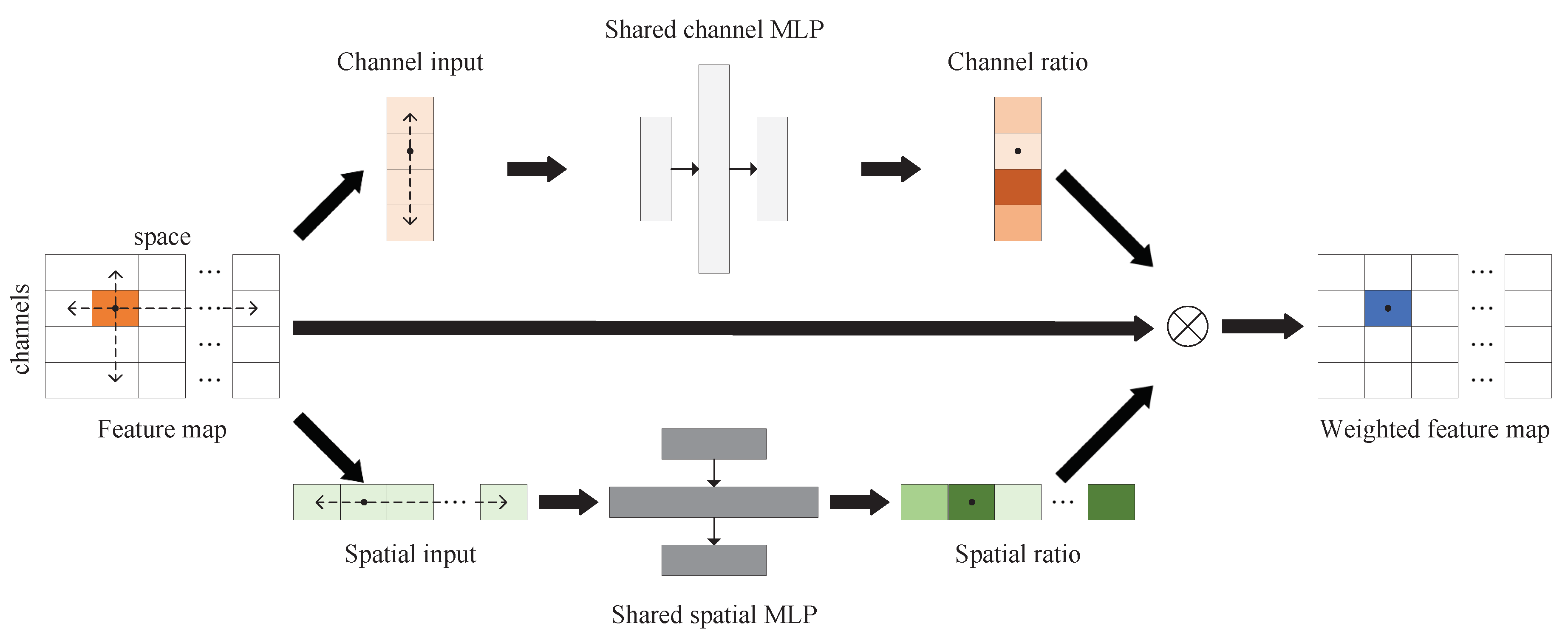
A network detector for RST detection based on high-level feature extraction of HRRP is proposed. In the proposed detector, a feature cross-weighting module based on joint channel-spatial information is designed for element-wise feature weighting. A nonlinear accumulation module for the preprocessing of double-HRRP input is developed, which replaces the traditional noncoherent accumulation in a double-HRRP detection scenario and enhances the detection performance.
The range-spread characteristic of an RST is considered for performance evaluation. Signal sparseness in [
36] is introduced for quantification, and simulated and measured datasets with different sparseness are generated. The effectiveness of the proposed detectors is verified and compared to traditional and deep learning-based detectors.
3. Experiments and Results
In this section, four experiments are conducted to analyze the effectiveness of the two proposed network detectors. The organization of the four experiments is shown in
Table 3.
The first three experiments are ablation experiments, which are used to verify the contribution of the designed modules to the detection performance of the proposed network detectors. The final experiment is the performance comparison with reference detectors to verify the effectiveness of the proposed detectors.
3.1. Dataset Description
The received HRRPs are used in this work for the detection of an RST, and only the magnitude of HRRPs is considered. Two datasets are generated for tje evaluation of the performance of RST detectors. The first dataset is a simulated dataset and the second dataset is a measured dataset based on real radar data. As illustrated in (
3), target detection is considered in scenarios using a single HRRP and double HRRPs. Therefore, each of the datasets are further divided into the single-HRRP dataset and double-HRRP dataset.
For the generation of datasets, the influence of the target spread characteristic on detector performance is considered, as described in [
36], of which the target spread characteristic is modeled as the sparseness of HRRP. Therefore, the defined quantitative measurement of sparseness in [
36] is introduced to characterize the datasets and is expressed as
where the sparseness of an HRRP is in the range of 0 to 1. An HRRP with a sparseness of 0 indicates all range bins in the window are of equal magnitude. It is usually the worst case. There are not strong scatterers in the RST, and detection performance is poor. An HRRP with a sparseness of 1 indicates that only a single range bin is of non-zero magnitude. Target energy is concentrated, and the RST becomes a point target. With the HRRP is a fixed size, the detection of an RST is easier with the increase in HRRP sparseness.
The signal energy-to-noise ratio (ENR) in [
37] is introduced to describe the signal intensity for radar target detection, which is given as
where the numerator is the energy of the signal, and the denominator is the power of the noise. The ENR is a preferred definition for analyzing radar target detection performance, and the relationship between ENR and SNR is
.
3.1.1. Simulated Dataset
In the simulated dataset, the RST is represented by a window of continuous range bins with length . The magnitude of a single range bin follows one of the three uniform distributions, which are , and , corresponding to the strong, moderate and weak scatterers, respectively. The phase of range bins follows . The magnitude and phase of range bins are set independently.
The simulated dataset is with a sparseness range of 0.1 to 0.5 and it is divided into two parts.
The first part is used for training the network. The sparseness is continuously distributed. There are 24,000 different target HRRPs, and they are energy-normalized. Based on these noiseless HRRPs, noise is added to form noisy HRRPs. In this work, the added noise in a single range bin is assumed to be complex Gaussian noise with unit power, i.e., , and noise in different range bins is independent and identically distributed. A total of 288,000 noisy HRRPs are generated, and the formed ENRs range from to . The same number of HRRPs consisting only of noise is generated for class balance. Therefore, a total of 576,000 input HRRPs are available for network training.
The second part is used for the performance evaluation of detectors. The sparseness is sampled with an interval of 0.05 in , and there are nine samples of sparseness in total. For each sampled sparseness, 10 different noiseless HRRPs are generated. Therefore, a total of 90 target HRRPs are generated. The detection performance of a detector is obtained using the Monte Carlo simulation method. The number of Monte Carlo simulations is 2000. In other words, for each of the 90 target HRRPs, 2000 noisy samples are generated for a single ENR. The sampled ENR is from to with an interval of . Thus, a total of 3,420,000 noisy HRRPs of targets are obtained. In addition, 5000 HRRPs consisting only of noise are generated to calculate the required false alarm threshold. Therefore, the number of input HRRPs for evaluation is 3,425,000.
The generated dataset above is for the single-HRRP detection case. In the double-HRRP detection case, for each input sample of the target, an identical pair of noiseless HRRPs are generated, and they are added with independent noise. For each input sample of noise, a pair of HRRPs consisting only of independent noise is generated.
Examples of the simulated dataset are shown in
Figure 6.
3.1.2. Measured Dataset
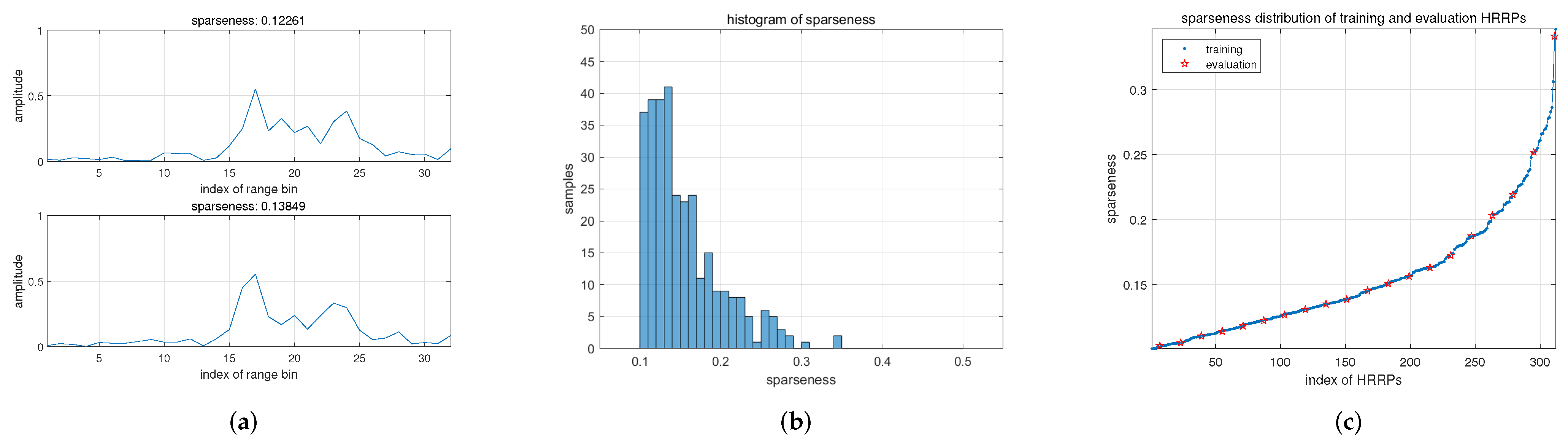
Experimental data are used in this work. The monitored target is a satellite, the and data are collected by the real radar. The experimental data are with high SNR and are regarded as noiseless data. The target is located in a windowed HRRP of length , and a total of 312 HRRPs are available.
The sparseness of the obtained HRRPs ranges from 0.1 to 0.35. They are divided into two parts, 292 HRRPs for constructing the training set and 20 HRRPs for constructing the evaluation set.
Data enhancement is used while generating the training set. Flip operations on the left and right side, cyclic shift and noise addition are used for each of the 292 HRRPs. The flip operation doubles the number of HRRPs, and each of these HRRPs performs cyclic shift four times independently. Therefore, 2336 noiseless HRRPs are generated. The ENR of the training set ranges from to , and for a single ENR, each noiseless HRRP performs noise addition eight times independently. Thus, a total number of = 224,256 noisy target HRRPs are generated. For class balance while training, the same number of HRRPs consisting only of noise is generated.
To construct the evaluation set, each of the 20 HRRPs generates 2000 noisy HRRPs for a single ENR. The formed ENR ranges from to . A total of 760,000 noisy target HRRPs are generated, and 5000 HRRPs of noise are also generated.
For the measured dataset in the double-HRRP case, it is constructed in the same way as the simulated dataset.
Examples of the measured dataset are shown in
Figure 7.
Two examples of experimental HRRPs are shown in
Figure 7a. In
Figure 7b, the obtained HRRPs from the satellite are of low sparseness. The sparseness is non-uniformly distributed, and most are around the range of 0.1 to 0.2. In
Figure 7c, the 292 HRRPs are sorted in order of sparseness. The 20 HRRPs for evaluation are evenly sampled from the sorted HRRPs, and the rest are for training.
3.2. Experimental Platform and Training Details
The mentioned network models in this work are implemented using PyTorch. Training and evaluation are complemented on the Intel(R) Core(TM) i7-10700F CPU with 32 GB RAM and GeForce GTX 1660 SUPER with 6 GB graphics memory. The batch size is set as 128, and the training epoch is 50 for all models. For the two proposed detectors, they are optimized with an Adam optimizer with the initialized learning rate of 0.001, and the learning rate is decayed by a factor of 0.1 at epochs 35 and 45. The hyper-parameters of the DFCW detector are set as
and
. For the referenced CNN-LSTM detector, the settings are kept as those originally provided in [
29].
In the network training process, the training set in each of the generated datasets is further divided into two parts with a ratio of 8:2 for training and validation, respectively.
3.3. Evaluation Indicators
For radar detection, the detection performance is evaluated with the probability of detecting a target under the limitation of a fixed false alarm rate.
The false alarm rate is given as
where
is the input signal,
is the detection statistic, and
is the selected detection threshold.
is the probability density function (PDF) of
in the case of
. Usually, the false alarm rate
is set to a required value, i.e.,
, and the detection threshold is calculated based on the required
.
The detection probability is given as
where
is the PDF of
in the case of
. The
is related to both the
and the signal intensity, namely ENR.
However, because of the nonlinearity of the network, theoretical expressions of the detection statistics, i.e., and , are not available. Therefore, in this work, Monte Carlo simulations are conducted based on the generated datasets to obtain the numerical solutions of and . Taking the performance analysis of the NLS detector on the simulated dataset as an example, the calculations of and are as follows:
Based on the evaluation set, 5000 samples for are obtained and sorted in descending order, i.e., .
The false alarm rate is set to the desired value, i.e., = .
The detection threshold is set to a value close to but less than , so that the number of false alarms is 5, corresponding to = .
For one of the 90 target HRRPs, at each ENR, 2000 samples for are obtained, i.e., . The detection probability is calculated as .
In this way, a performance curve of the detection probability via ENR with the desired false alarm rate is obtained.
Therefore, the first used indicator for evaluation is the detection performance curve. In this work, the desired false alarm rate is set as = . The evaluation sets in the simulated dataset and measured dataset contain 90 and 20 independent target HRRPs, respectively. Thus, for each of the datasets, an averaged performance curve is obtained and used as the indicator.
One more indicator used in this work is the global detection probability. It is an overall metric and is used to quantify the detection probability on the entire evaluation set, which is formulated as
where the
is the number of correct detections of the target in the evaluation set, and
is the total number of target samples in the evaluation set. Taking the simulated dataset as an example,
and
are the number of detection statistic samples greater than
.
3.4. Experimental Results
For performance comparison, based on the evaluation indicators, the experimental results are organized according to the used dataset and the number of used HRRPs, i.e., single HRRP detection on the simulated dataset, double HRRP detection on the simulated dataset, single HRRP detection on the measured dataset and double HRRP detection on the measured dataset.
3.4.1. Experimental Results of the NLS Module
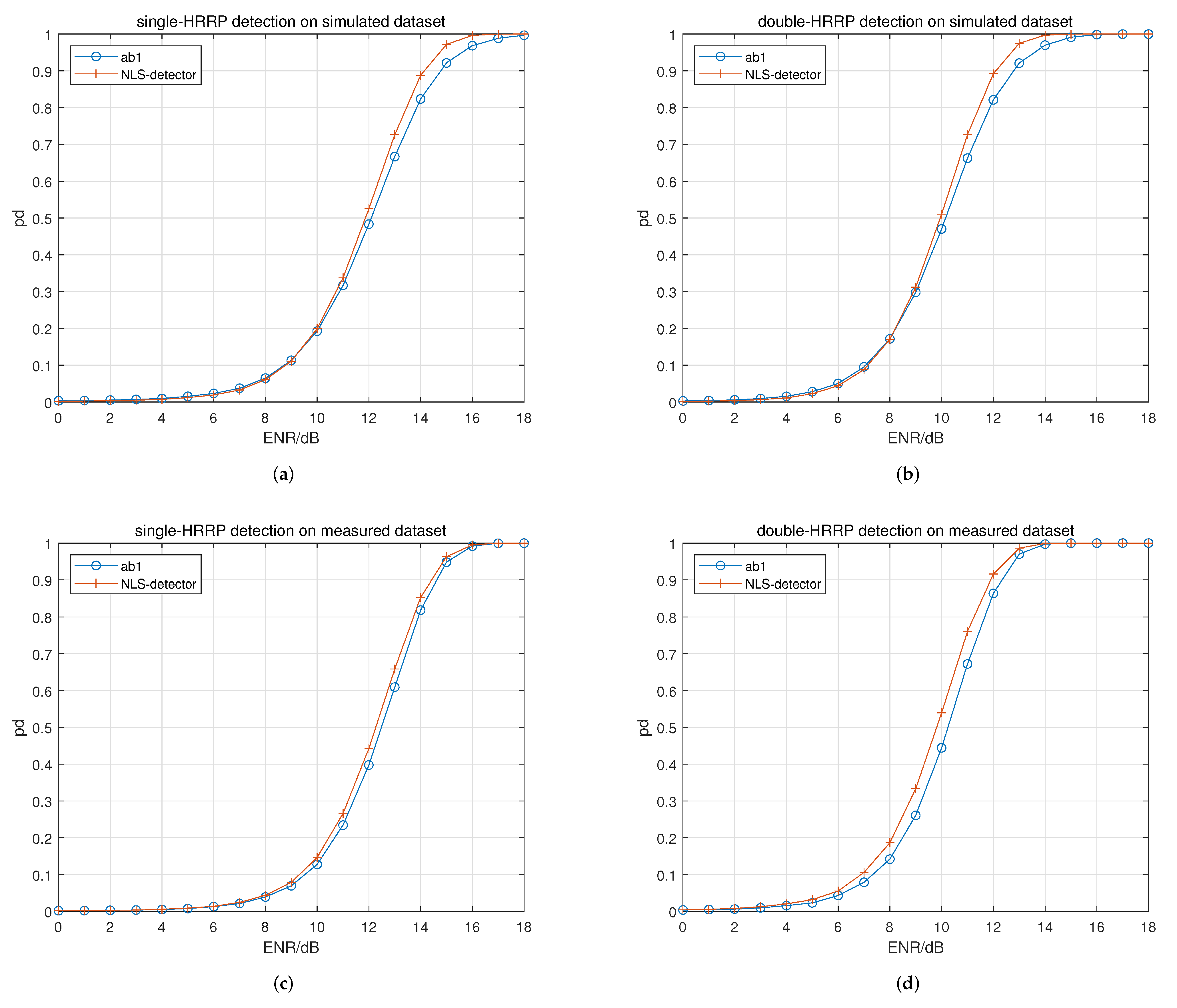
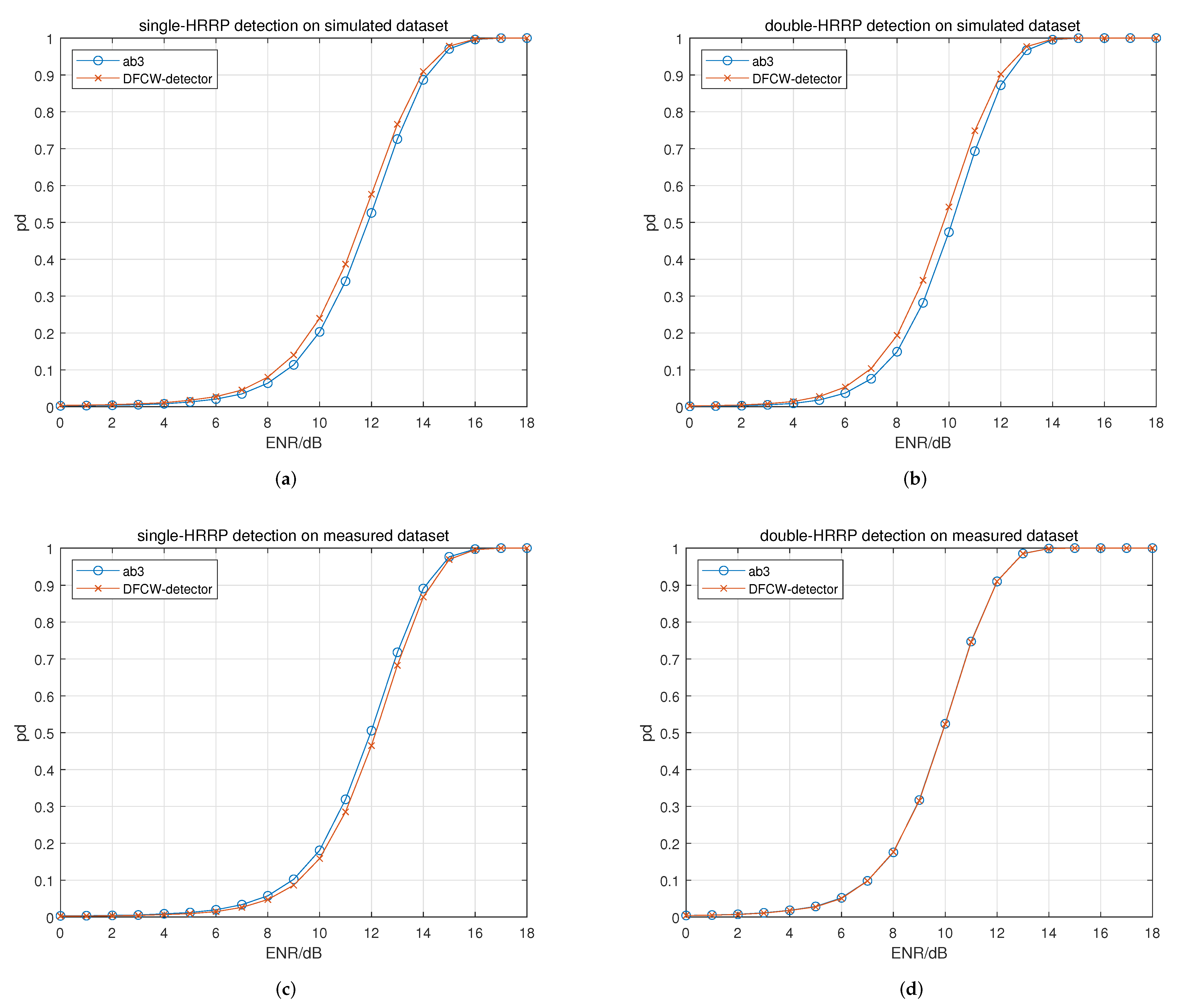
In experiment 1, the effects of the NLS module on the performance of the proposed NLS detector in different detection scenarios are studied. A model removing the NLS module is used as the baseline model for comparison. The results are given in
Figure 8 and
Table 4.
In
Figure 8a,b where the simulated dataset is used, the NLS detector, compared with the baseline model, shows a significant improvement on the detection performance under high ENRs. In
Figure 8c,d where the measured dataset is used, the performance curve of the proposed NLS detector moves to the left at different degrees compared to that of the baseline model.
For the quantitative results in
Table 4, it can be seen that the
values in four scenarios are all improved. The improvements in
from left to right are 1.35%, 1.30%, 1.15%, and 2.26%, respectively.
3.4.2. Experimental Results of the Nonlinear Accumulation Module
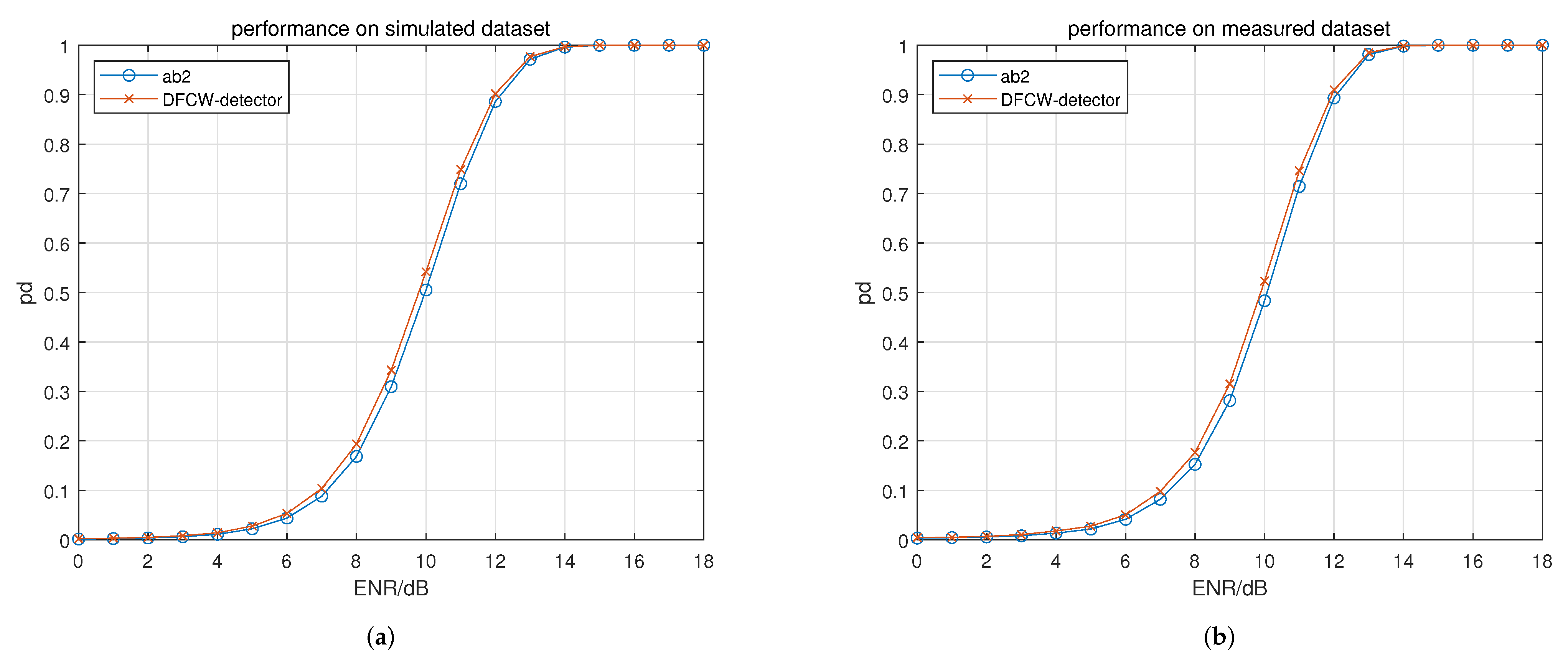
In experiment 2, for the proposed DFCW detector, the contribution of the nonlinear accumulation module on detection performance is evaluated. The nonlinear accumulation module in the DFCW detector is replaced by a traditional noncoherent accumulation and used as comparison. The experiment is conducted on the double HRRP dataset. The results are shown in
Figure 9 and
Table 5.
In
Figure 9, it can be seen that the nonlinear accumulation module makes the detection performance better on both the simulated and measured datasets.
Based on the obtained
in
Table 5, it can be seen that the
values are increased by 0.98% and 1.0%, respectively.
3.4.3. Experimental Results of the Feature Cross-Weighting Module
In experiment 3, the effect of the feature cross-weighting module on the detection performance is evaluated. The DFCW detector removing the feature cross-weighting module is used as comparison. The results are given in
Figure 10 and
Table 6.
Figure 10a,b represent the single-HRRP and double-HRRP detection performance on the simulated dataset. It can be seen that the performance is improved by using the feature cross-weighting module.
Figure 10c,d show the results of the measured dataset. However, with the feature cross-weighting module, the performance is decreased in the single HRRP detection scenario and is basically unchanged in the double-HRRP detection scenarios.
From
Table 6, the differences in
from left to right are 1.48%, 1.78%, −1.11% and −0.04%, respectively. In other words, the effect of the feature cross-weighting module on detection performance changes with the used dataset.
3.4.4. Experimental Results of Performance Comparison
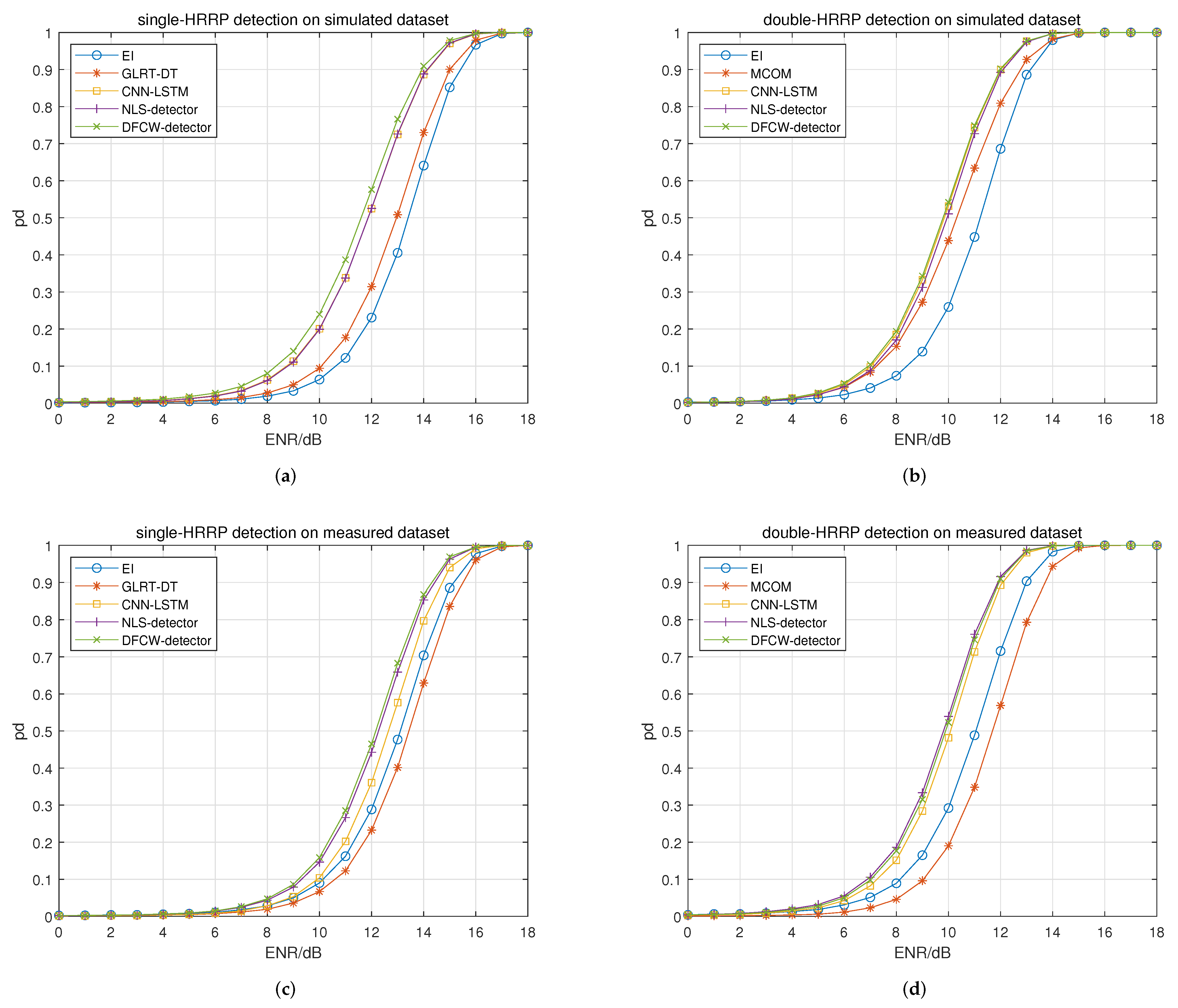
In experiment 4, the effectiveness of the proposed detection networks is verified by performance comparison with traditional and deep learning-based detectors. For the traditional detector, the EI detector [
3], GLRT-DT detector [
5] and MCOM detector [
10] are used. For the deep learning-based detector, the CNN-LSTM detector [
29] is used. Experimental results are shown in
Figure 11 and
Table 7.
Figure 11a shows the single-HRRP detection performance on the simulated dataset. It can be seen that the deep learning-based detectors are much better than traditional detectors. For the deep learning-based detector, the DFCW detector performs better than the other two detectors. The performance of the CNN-LSTM detector and the NLS detector is basically the same. For all detectors, the detection performance in descending order is DFCW detector, CNN-LSTM detector, NLS detector, GLRT-DT detector and EI detector.
Figure 11b shows the double-HRRP detection performance on the simulated dataset. It can be seen that although the deep learning-based detectors are better than traditional detectors, the performance gap between traditional detectors and deep learning-based detectors is narrowed. The MCOM detector approaches deep learning-based detectors at low ENRs but suffers performance degradation compared with that of deep learning-based detectors at high ENRs. For the deep learning-based detectors, the three detectors are close to each other. For all detectors, the detection performance in descending order is DFCW detector, CNN-LSTM detector, NLS detector, MCOM detector and EI detector.
Figure 11c shows the single-HRRP detection performance on the measured dataset. It can be seen that the performance gap is further narrowed. For deep learning-based detectors, the DFCW detector and the NLS detector are comparable, and both are better than the CNN-LSTM detector. For all detectors, the detection performance in descending order is DFCW detector, NLS detector, CNN-LSTM detector, EI detector and GLRT-DT detector.
Figure 11d shows the double-HRRP detection performance on the measured dataset. It can be seen that the performance gap between traditional detectors and deep learning-based detectors becomes wider. For deep learning-based detectors, the two proposed detectors are better than the CNN-LSTM detector, but the performance improvement is decreased compared with the single-HRRP detection scenario. For all detectors, the detection performance in descending order is NLS detector, DFCW detector, CNN-LSTM detector, EI detector and MCOM detector, respectively.
4. Discussion
4.1. Analysis of NLS Module
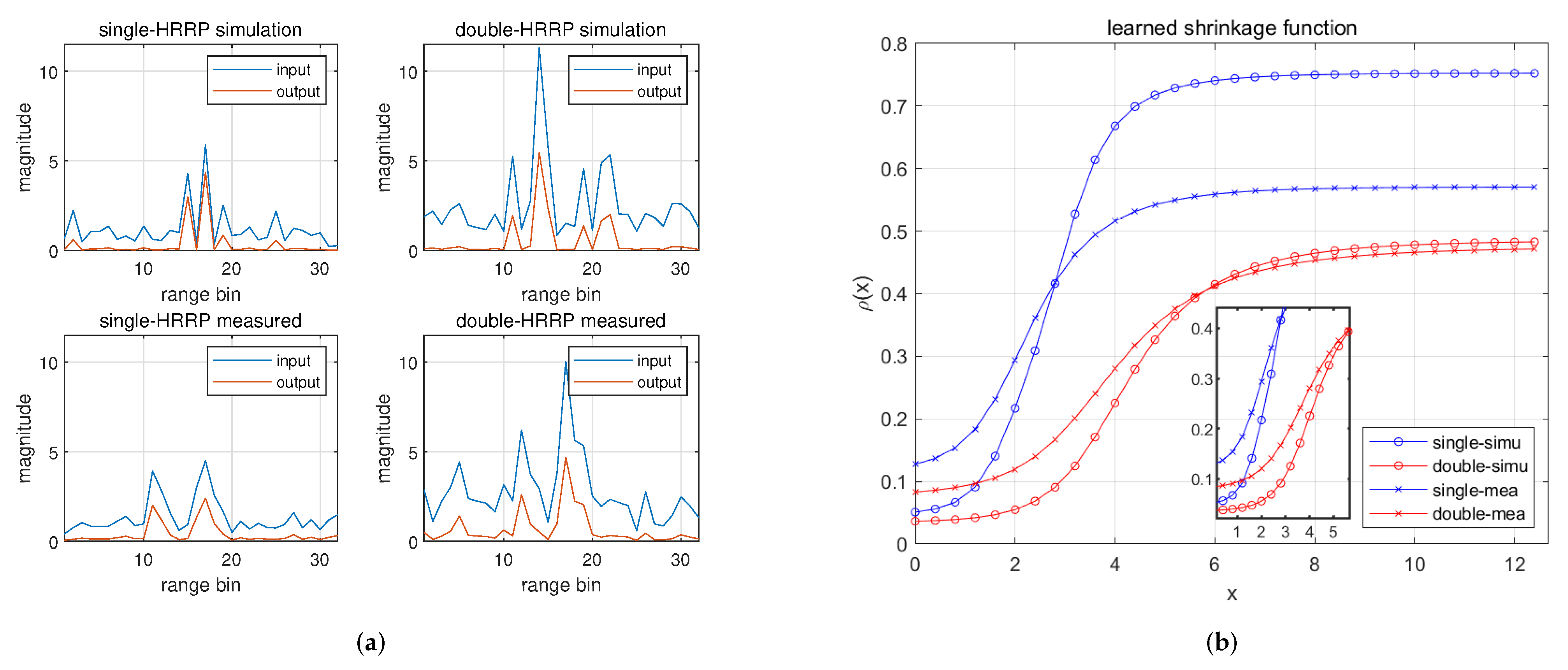
Based on the results of experiment 1, it can be seen that the NLS module behaves differently on different datasets. For detailed analysis, the outputs and the learned nonlinear shrinkage functions of the NLS module in four detection scenarios are shown in
Figure 12.
In
Figure 12a, the inputs and outputs of the NLS module are shown. The two subplots at the top are based on the simulated dataset, and the two at the bottom are based on the measured dataset. The two subplots on the left are based on a single HRRP, and the two on the right are based on double HRRPs. Overall, it can be seen that the smaller the magnitude of a single range bin, the stronger the extent of suppression. In
Figure 12b, the learned nonlinear shrinkage functions are shown. It can be seen that the nonlinear shrinkage functions are different with each other and are adaptive to the specific dataset. In the double-HRRP scenarios, the two HRRPs are noncoherently accumulated, and the magnitude is much larger than that of single-HRRP scenarios, as shown in
Figure 12a. In
Figure 12b, the learned nonlinear shrinkage curves for the double-HRRP case are shifted to the right on the x-axis, corresponding to larger input. The difference in the sparseness of datasets also affects the learned nonlinear shrinkage functions. The measured dataset has a much lower sparseness than the simulated dataset, and the unsaturated intervals of curves of the measured dataset are to the left of that of the simulated dataset, as shown in the zoom plot.
4.2. Analysis of Nonlinear Accumulation Module
In experiment 2, the nonlinear accumulation shows a positive contribution on detection performance. To further analyze the effect of the nonlinear accumulation module, the outputs of this module are given in
Figure 13.
Figure 13a,b show the outputs of the nonlinear accumulation module trained on the simulated and measured dataset, respectively. The top subplot corresponds to a noisy target HRRP with an ENR of 18 dB, and the bottom subplot corresponds to a noise input. It can be seen that the residual output has a small value on the range bin where the output magnitude of the noncoherent accumulation is large. Once the noncoherent accumulation output is larger than a certain value, the residual output reaches zero. Therefore, in the region where the noncoherent accumulation output is smaller than a certain value, the output is compensated by the residual output, making the magnitude fluctuation flattened, as shown in the nonlinear accumulation output. On the contrary, the regions where the noncoherent accumulation output is large are kept unchanged, and these regions tend to be range bins of strong scatterers. This characteristic of the nonlinear accumulation output could be a reason for the improvement of detection performance.
4.3. Analysis of Feature Cross-Weighting Module
The feature cross-weighting module is based on the extracted high-level feature map of the HRRP, and the reasonability of the weighting coefficients will influence the detection performance. From the results, the feature cross-weighting module performs well in the double-HRRP detection scenario of the simulated dataset but poorly in the single-HRRP detection scenario of the measured dataset. Therefore, in this subsection, the effectiveness of the module is analyzed, considering the difference in the detection scenarios.
The sparseness of the simulated dataset ranges from 0.1 to 0.5, which is higher than that of the measured dataset (0.1 to 0.35). For an RST, the higher the sparseness of the target HRRP, the fewer the number of scatterers and the stronger the amplitude of the scatterers. Thus, in this case, it is easier to distinguish target from noise. Using double HRRPs for detection provides more target information. Therefore, it is reasonable to assume that the higher the sparseness of dataset and the more HRRP used, the easier it is for the module to obtain suitable weighting coefficients for the feature map. The performance gain of the feature cross-weighting module in descending order is 1.78% > 1.48% > −0.04% > −1.11%, corresponding to the four scenarios from the simulated dataset to the measured dataset and from double-HRRP detection to single-HRRP detection as expected.
Specifically, for double-HRRP detection on the measured dataset, the low sparseness poses challenges in calculating reasonable weighting coefficients, yet leveraging double HRRPs can compensate for this limitation. Thus, it may explain the result in
Figure 10d, where the influence of the two factors appears to be evenly balanced. The same is also applicable for the other three scenarios in
Figure 10.
4.4. Analysis of Detection Performance
Overall, the detection performance is related to the detection scenarios. For the two datasets in this work, the transition from the measured dataset to the simulated dataset results in the increase in sparseness and enhances the detectors’ performance. Therefore, the performance curves shift to the right from
Figure 11a to
Figure 11c and from
Figure 11b to
Figure 11d. Increasing the number of used HRRPs results in performance improvement, too. Thus, the performance curves shift to the left from
Figure 11a to
Figure 11b and from
Figure 11c to
Figure 11d.
Although the trend remains consistent, variations in detection performance still exist among different types of detectors. Based on the experimental results, the performance comparison of different detectors is given as follows.
For traditional detectors, the EI detector is the only one that is not affected by the sparseness of HRRPs. Therefore, the EI detector in the measured dataset obtains better performance compared with the other traditional detectors. However, in the simulated dataset, the GLRT-DT and the MCOM detectors benefit from the increased sparseness and are superior to the EI detector. The MCOM detector requires at least two HRRPs to perform target detection and is better than the GLRT-DT detector in the sparse and double-HRRP detection scenario.
For deep learning-based detectors, they consistently outperform traditional detectors in the four detection scenarios. This advantage stems from the network’s capability to learn more efficient representations for distinguishing between targets and noise.
However, discrepancies persist among the three deep learning-based detectors. The NLS detector regards the HRRP as a feature vector and implements traditional signal processing through a network module, ensuring the physical meaning of the module outputs is retained. The CNN-LSTM detector and the DFCW detector are based on the feature map of the HRRP. The LSTM structure is introduced to explore the relationship between spatial features. However, in the initial HRRP, scatterers of an RST exhibit relative independence, resulting in a weak spatial correlation. Therefore, the LSTM module does not ensure performance improvement. The feature cross-weighting module in the DFCW detector, considering the independence of spatial features, treats each element in the feature map independently but identically and calculates a weighting coefficient to represent the importance of each feature element.
A detailed performance comparison of deep learning-based detectors is shown in
Table 8, which is given as the difference in
.
The results presented in the table represent the performance enhancements achieved by the two proposed network detectors with the performance of the CNN-LSTM detector serving as a benchmark. It can be seen that the detection performance of the NLS detector is slightly worse than the referenced CNN-LSTM detector in the simulated dataset, but it is much better in the measured dataset. For the DFCW detector, it outperforms the CNN-LSTM detector in all detection scenarios. Furthermore, the table results can also be analyzed from the following two perspectives:
1. Considering the influence of the sparseness of datasets, the sorted results are expressed as 2.21% > −0.03% and 1.47% > −0.56% for the first line and 2.82% > 1.54% and 1.0% > 0.27% for the second line. In other words, the CNN-LSTM detector suffers much more serious performance degradation when the sparseness of used dataset decreases compared to the NLS detector and the DFCW detector.
2. Considering the influence of the number of used HRRPs, the sorted results are given as −0.03% > −0.56% and 2.21% > 1.47% for the first line and 1.54% > 0.27% and 2.82% > 1.0% for the second line. In other words, the CNN-LSTM detector exhibits a greater performance improvement as the number of used HRRPs increases compared to the NLS detector and the DFCW detector.
Therefore, compared with the CNN-LSTM detector, the two proposed detectors demonstrate enhanced adaptability in challenging scenarios, such as a dataset with low sparseness or detection using a single HRRP. In comparing the two proposed detectors, the DFCW detector performs best in the two detection scenarios on the simulated dataset and the single-HRRP detection scenario on the measured dataset, but the NLS detector achieves the best performance in the double-HRRP detection scenario on the measured dataset.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}