
A Point Cloud Segmentation Method for Dim and Cluttered Underground Tunnel Scenes Based on the Segment Anything Model
 , ,
, ,  , ,
, , 
Abstract
:
1. Introduction
- Based on the zero-shot generalization capability of SAM, the study has formulated a framework for the semantic segmentation of 3D point clouds of complex underground tunnel scences. This framework demonstrates the automatic continuous segmentation ability of whole tunnel point clouds in complex scenes by utilizing point cloud slicing and label attribute transfer methods.
- Based on the prompt engineering capabilities of the SAM, our framework avoids additional training and does not depend on point cloud attributes like color and intensity. This framework optimizes the selection of front and back points required in the SAM prompt and controls the range of the segmented region by assigning different colors to pixels to improve the accuracy of tunnel point cloud segmentation.
- The study has conducted validation experiments involving 3D point cloud segmentation with complex settings, employing underground coal mine tunnels as an illustrative example. It is superior to traditional algorithms in both visualization and accuracy indicators. Consequently, the framework with good stability, flexibility, and scalability provides more ideas for point cloud segmentation in the development of foundation models.
2. Related Work
2.1. Semantic Segmentation of Point Clouds
2.2. Point Cloud Segmentation in Tunnel
3. Methods
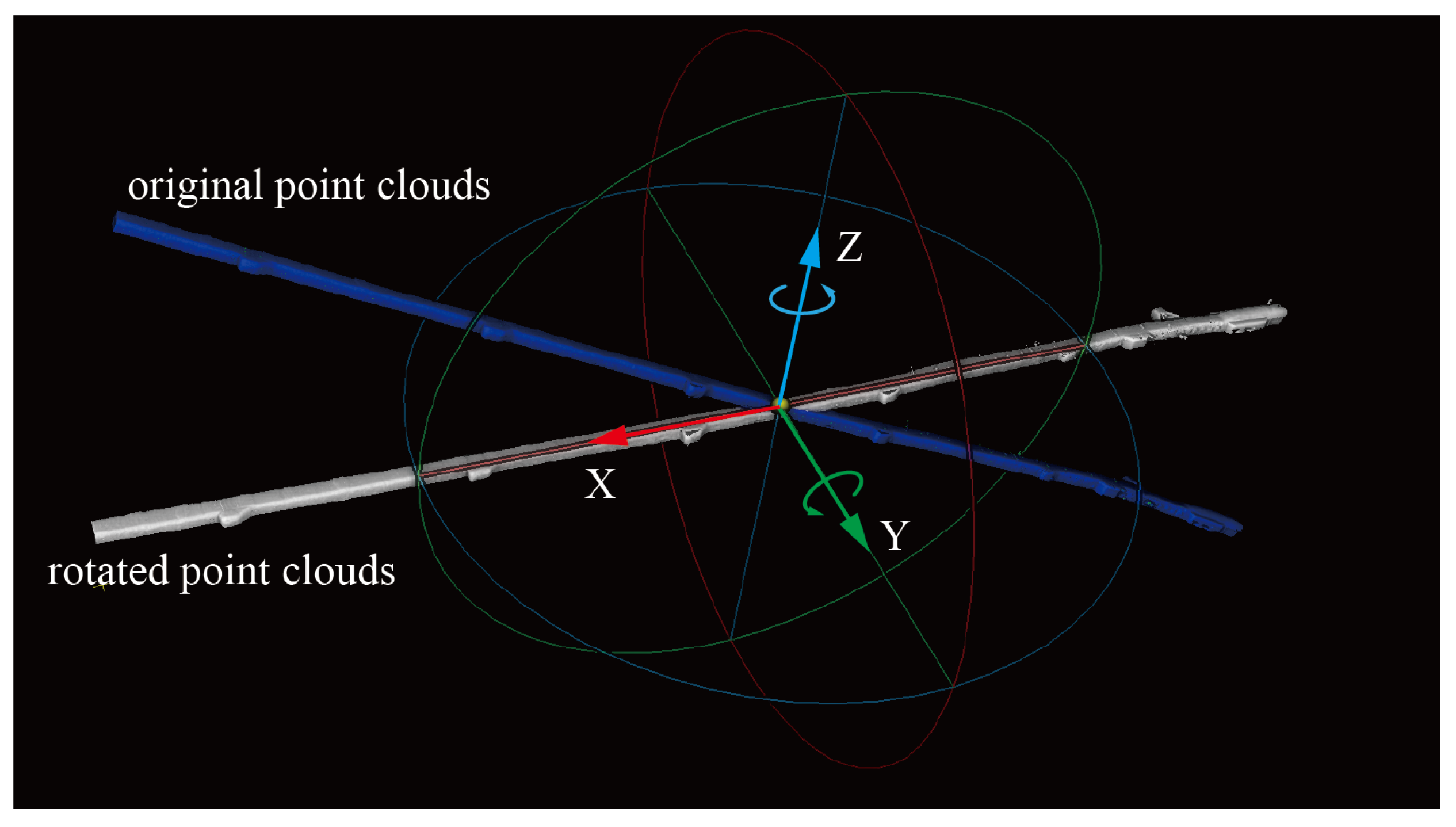
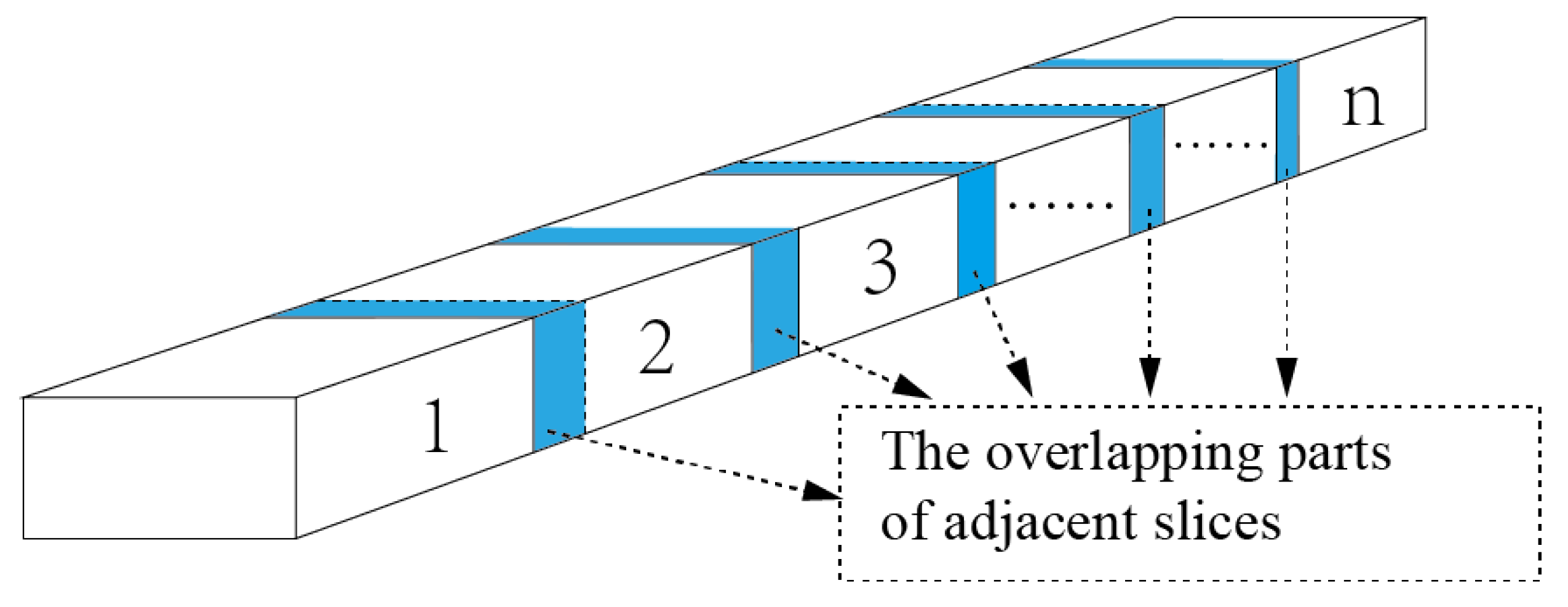
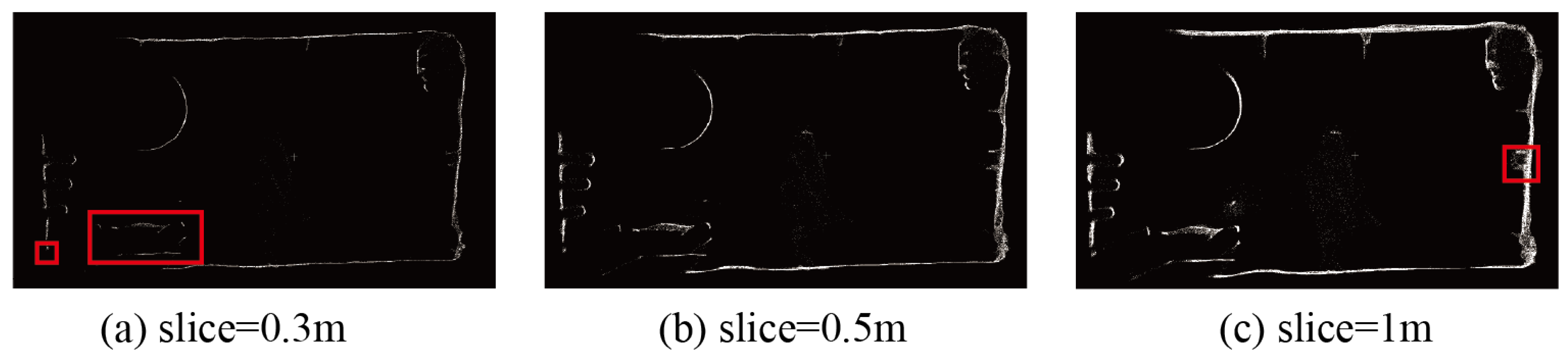
3.1. Point Cloud Rotation and Slicing
- Calculating the tunnel’s direction by using Principal Component Analysis (PCA) [50] to linearly reduce the dimension of the entire tunnel point cloud and calculate its first principal component as the tunnel’s direction, .
- Calculating the rotation matrix for the point cloud and applying a rotation transformation to all points. The rotation matrix is computed as shown in Equation (1); the point cloud is first rotated along the X-axis and then along the Y-axis, orienting it towards the X-axis direction.
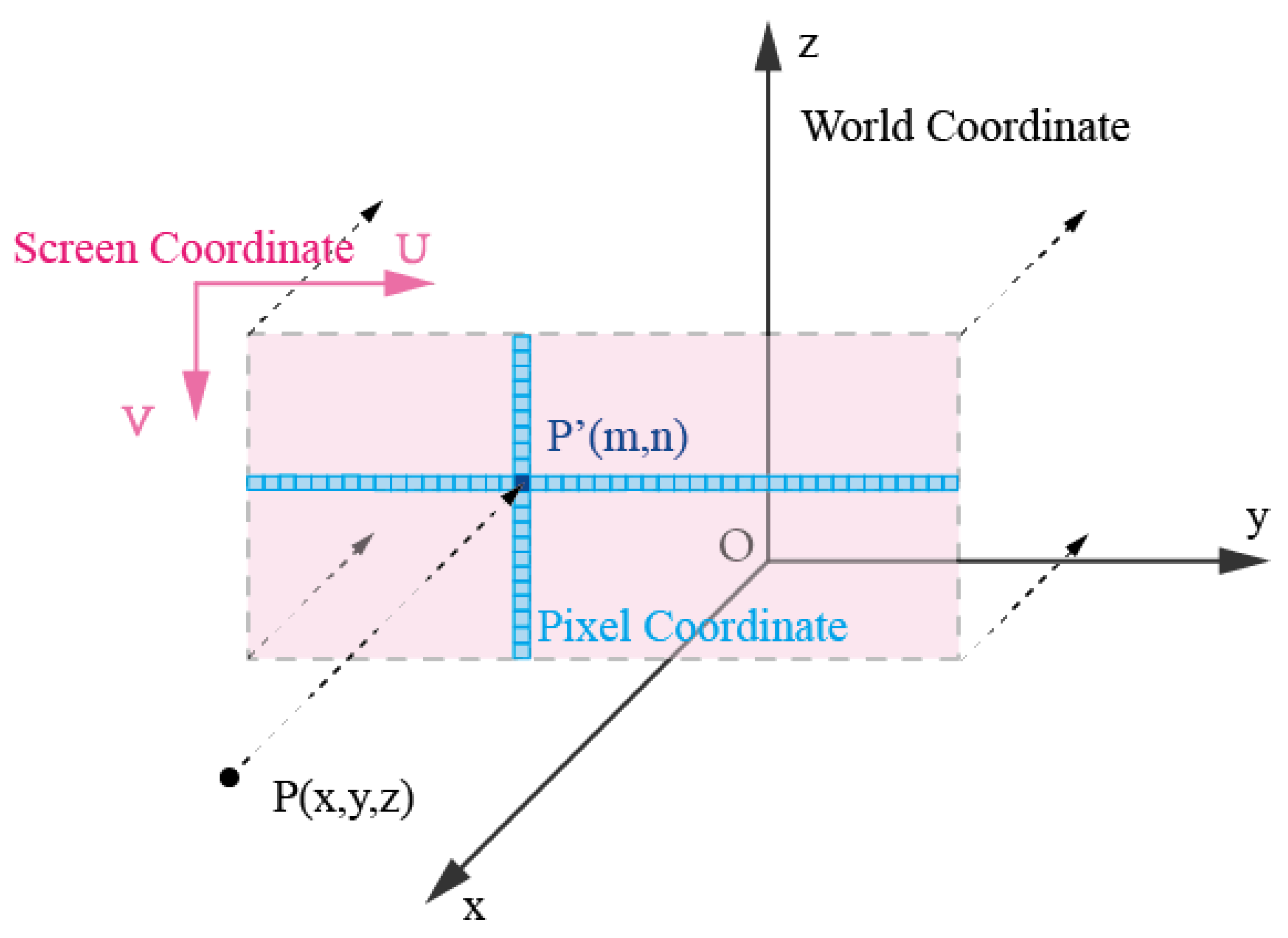
3.2. Mapping 3D Point Clouds into 2D Images
3.2.1. Parallel Projection
- Select Projection Plane: After the tunnel slice processing in the previous section, for each slice, choose the slice with the maximum X-coordinate as the target plane for projection, with the tunnel’s direction as the projection direction.
- Determine the Plane Coordinate System: Calculate the minimum bounding box for each 3D point cloud slice, find the maximum and minimum values in the Y and Z directions, namely, . Take as the origin of the plane and transform the 3D coordinates of the point cloud in the slice into 2D coordinates on the plane, where points are marked as .
- Generate Projection Images: Use and as the width and height of the image on the projection plane, respectively. Based on the desired image resolution , divide the plane into grids and then convert each point in the slice into pixel coordinates on the image. The points in pixel coordinates are marked as
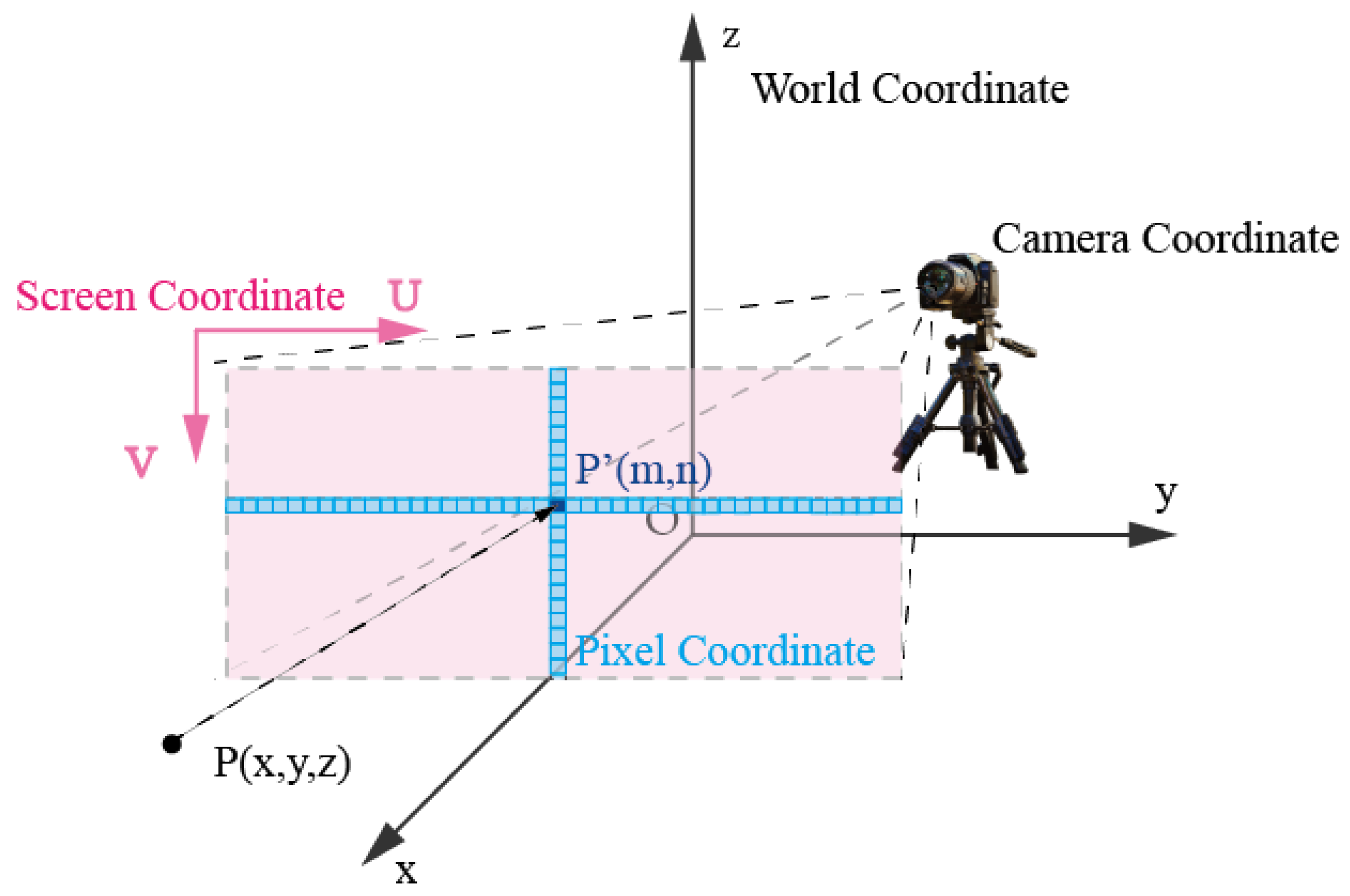
3.2.2. Perspective Projection
- Selecting the Viewpoint:In perspective projection, it is necessary to determine the observer’s viewpoint, which is the observer’s eyes. This article uniformly sets the observation distance d and calculates the minimum bounding box and coordinate center for each slice. The viewpoint for each slice is placed at a distance d from the coordinate center towards the negative x-axis, which is marked as .
- Selecting Projection Lines: Projection lines refer to the lines that pass through the point cloud points from the viewpoint and intersect the projection plane vertically. By varying the endpoint positions of the projection lines, a greater number of perspective projection effect diagrams can be obtained. In the paper, the central projection line is used as an illustrative example. The center projection line starts from the center point of the slice with the smallest x-coordinate .
- Selecting the Projection Plane: Once the projection lines and viewpoint are determined, a projection plane is generated at a distance f from the viewpoint, perpendicular to the direction of the projection lines.
- Calculating Projection Points: Displaying the 3D point cloud in the projection plane. Firstly, the 3D point cloud in the original spatial coordinate system is transformed to have the viewpoint as the new coordinate system’s origin, with one axis as the direction of the projection lines. The homogeneous coordinates of the original point cloud are marked as , and the homogeneous coordinates of the point cloud under the new coordinates are represented as , where is calculated in Equation (4), ,Secondly, the 3D coordinates in the new coordinate system are transformed into the 2D coordinate system of the projection plane to calculate the perspective projection coordinates of each point in 3D space on the projection plane. The points in the projection plane are marked as .
- Generating the Point Cloud Perspective Projection Image: Calculate the minimum bounding box of the projection points on the projection plane, based on the desired image resolution. The method is similar to the one mentioned in Section 3.2.1.
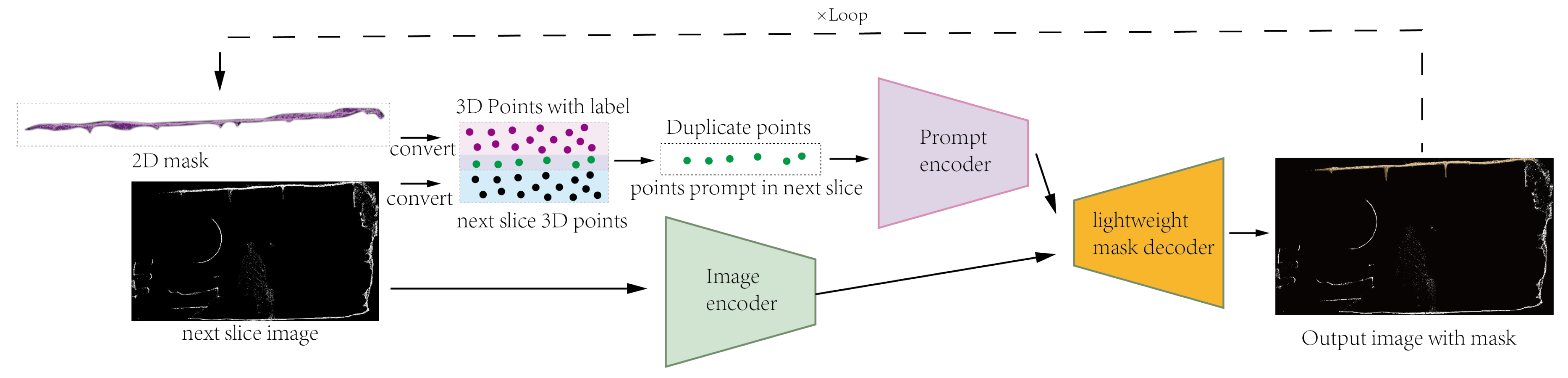
3.3. Using SAM to Generate a Single 3D Mask
3.4. Automatically Generate 3D Masks for Whole Tunnel
4. Experiment
4.1. Data and Experimental Environment
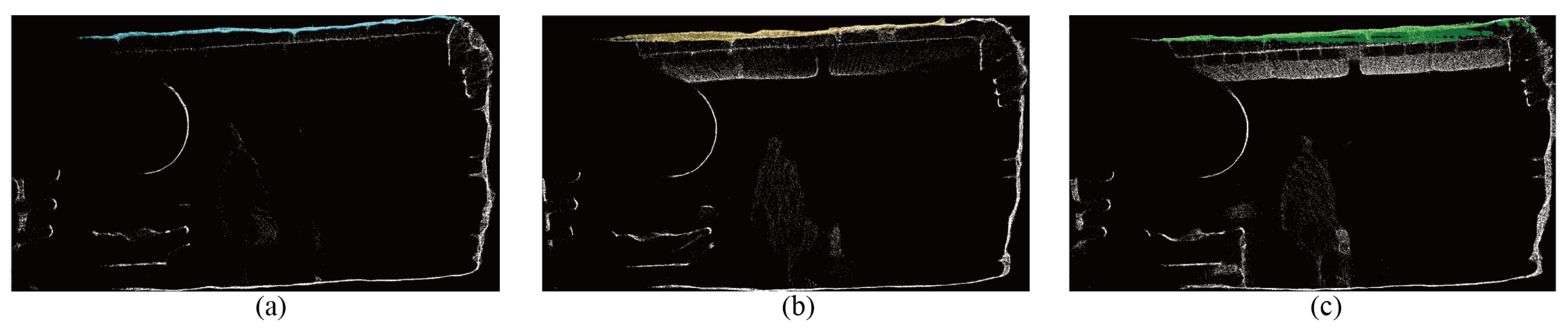
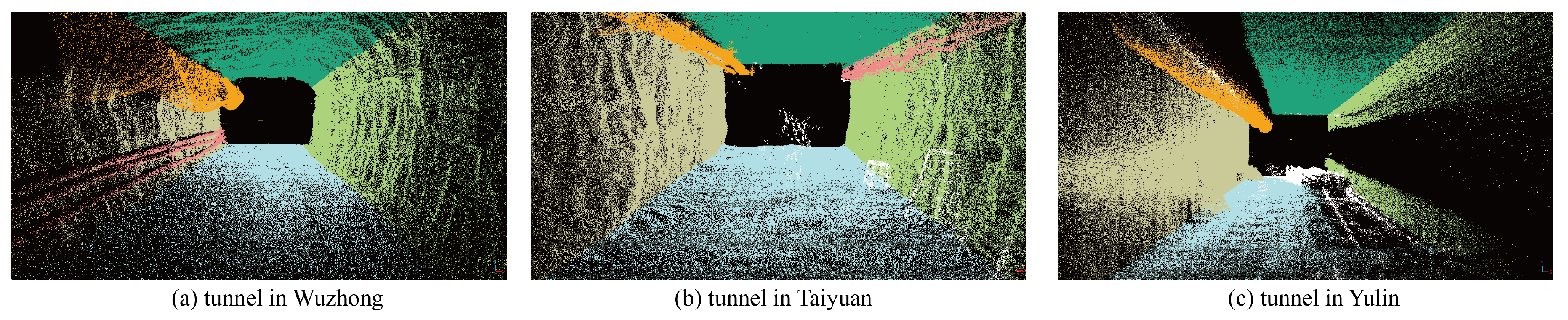
4.2. Result of Semantic Segmentation
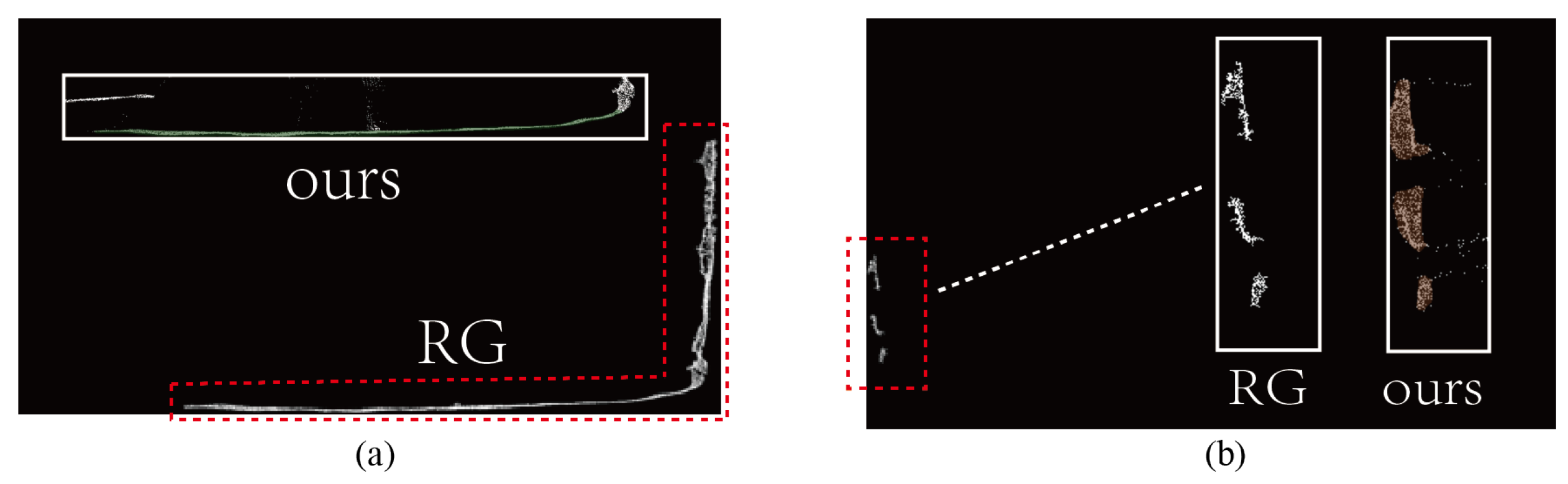
4.3. Comparative Experiment
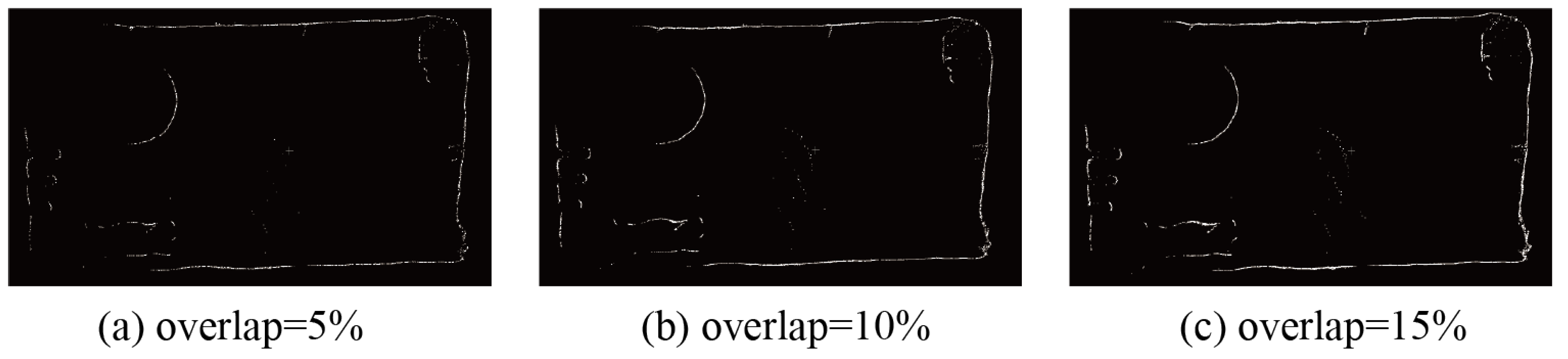
4.4. Scalability Experiment
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| Symbols | Description |
| Tunnel’s direction | |
| Rotation matrix along the Z-axis | |
| Rotation matrix along the Y-axis | |
| The position of a point in the world coordinate system | |
| The position of a point in the plane coordinate system | |
| The position of a point in the planar pixel coordinate system | |
| The position of the viewpoint in the world coordinate system | |
| The position of the point cloud center in the world coordinate system | |
| Vector from viewpoint to point cloud center | |
| Original point cloud homogeneous coordinate set | |
| Rotated point cloud homogeneous coordinate set | |
| Rotation translation matrix | |
| f | Distance between projection plane and viewpoint |
| Pixel size of the image | |
| Unit vector of projected image facing right | |
| Unit vector of projected image facing upwards | |
| Unit vector from viewpoint to point cloud center |
References
- Cacciari, P.P.; Futai, M.M. Mapping and Characterization of Rock Discontinuities in a Tunnel Using 3D Terrestrial Laser Scanning. Bull. Eng. Geol. Environ. 2016, 75, 223–237. [Google Scholar] [CrossRef]
- Cacciari, P.P.; Futai, M.M. Modeling a Shallow Rock Tunnel Using Terrestrial Laser Scanning and Discrete Fracture Networks. Rock Mech. Rock Eng. 2017, 50, 1217–1242. [Google Scholar] [CrossRef]
- Jiang, W.; Zhou, Y.; Ding, L.; Zhou, C.; Ning, X. UAV-based 3D Reconstruction for Hoist Site Mapping and Layout Planning in Petrochemical Construction. Autom. Constr. 2020, 113, 103137. [Google Scholar] [CrossRef]
- Ding, L.; Jiang, W.; Zhou, Y.; Zhou, C.; Liu, S. BIM-based Task-Level Planning for Robotic Brick Assembly through Image-Based 3D Modeling. Adv. Eng. Inf. 2020, 43, 100993. [Google Scholar] [CrossRef]
- Ramón, A.F.; Celestino, O.; Silverio, G.C.; Javier, R.P. Measurement Planning for Circular Cross-Section Tunnels Using Terrestrial Laser Scanning. Autom. Constr. 2013, 31, 1–9. [Google Scholar] [CrossRef]
- Cao, Z.; Chen, D.; Shi, Y.; Zhang, Z.; Jin, F.; Yun, T.; Xu, S.; Kang, Z.; Zhang, L. A Flexible Architecture for Extracting Metro Tunnel Cross Sections from Terrestrial Laser Scanning Point Clouds. Remote Sens. 2019, 11, 297. [Google Scholar] [CrossRef]
- Han, J.Y.; Guo, J.; Jiang, Y.S. Monitoring Tunnel Deformations by Means of Multi-Epoch Dispersed 3D LiDAR Point Clouds: An Improved Approach. Tunn. Undergr. Space Technol. 2013, 38, 385–389. [Google Scholar] [CrossRef]
- Walton, G.; Delaloye, D.; Diederichs, M.S. Development of an Elliptical Fitting Algorithm to Improve Change Detection Capabilities with Applications for Deformation Monitoring in Circular Tunnels and Shafts. Tunn. Undergr. Space Technol. 2014, 43, 336–349. [Google Scholar] [CrossRef]
- Cheng, Y.J.; Qiu, W.G.; Duan, D.Y. Automatic Creation of As-Is Building Information Model from Single-Track Railway Tunnel Point Clouds. Autom. Constr. 2019, 106, 102911. [Google Scholar] [CrossRef]
- Yi, C.; Lu, D.; Xie, Q.; Liu, S.; Li, H.; Wei, M.; Wang, J. Hierarchical Tunnel Modeling from 3D Raw LiDAR Point Cloud. Comput.-Aided Des. 2019, 114, 143–154. [Google Scholar] [CrossRef]
- Alexander, K.; Eric, M.; Nikhila, R.; Hanzi, M.; Chloe, R.; Laura, G.; Tete, X.; Spencer, W.; Alexander, C.B.; Lo, W.-Y.; et al. Segment Anything. arXiv 2020, arXiv:2304.02643. [Google Scholar] [CrossRef]
- Xie, Y.; Tian, J.; Zhu, X.X. Linking Points With Labels in 3D: A Review of Point Cloud Semantic Segmentation. IEEE Geosci. Remote Sens. Mag. 2020, 8, 38–59. [Google Scholar] [CrossRef]
- Anh, N.; Bac, L. 3D Point Cloud Segmentation: A Survey. In Proceedings of the 2013 6th IEEE Conference on Robotics, Automation and Mechatronics (RAM), Manila, Philippines, 12–15 November 2013; pp. 225–230. [Google Scholar]
- Angel Domingo, S.; Michel, D. Fast Range Image Segmentation by an Edge Detection Strategy. In Proceedings of the Third International Conference on 3-D Digital Imaging and Modeling, Quebec City, QC, Canada, 28 May–1 June 2001; pp. 292–299. [Google Scholar]
- Felix, M.; Erich, M.; Benjamin, K.; Klaus, I.I.; Matthias, D.; Britta, A. LIDAR-based Geometric Reconstruction of Boreal Type Forest Stands at Single Tree Level for Forest and Wildland Fire Management. Remote Sens. Environ. 2004, 92, 353–362. [Google Scholar] [CrossRef]
- Aparajithan, S.; Jie, S. Segmentation and Reconstruction of Polyhedral Building Roofs from Aerial Lidar Point Clouds. IEEE Trans. Geosci. Remote Sens. 2009, 48, 1554–1567. [Google Scholar] [CrossRef]
- Aparajithan, S.; Jie, S. Clustering Based Planar Roof Extraction from Lidar Data. In Proceedings of the American Society for Photogrammetry and Remote Sensing Annual Conference, Reno, Nevada, 1–5 May 2006; pp. 1–6. [Google Scholar]
- Zhu, X.X.; Shahzad, M. Facade Reconstruction Using Multiview Spaceborne TomoSAR Point Clouds. IEEE Trans. Geosci. Remote Sens. 2013, 52, 3541–3552. [Google Scholar] [CrossRef]
- Muhammad, S.; Zhu, X.X.; Richard, B. Façade Structure Reconstruction Using Spaceborne TomoSAR Point Clouds. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 467–470. [Google Scholar]
- Josep Miquel, B.; José Luis, L. Unsupervised Robust Planar Segmentation of Terrestrial Laser Scanner Point Clouds Based on Fuzzy Clustering Methods. ISPRS J. Photogramm. Remote Sens. 2008, 63, 84–98. [Google Scholar] [CrossRef]
- Hojjatoleslami, S.A.; Kittler, J. Region growing: A new approach. IEEE Trans. Image Process. 1998, 7, 1079–1084. [Google Scholar] [CrossRef]
- Roland, G.; Uwe, S. Segmentation of Laser Altimeter Data for Building Reconstruction: Different Procedures and Comparison. Int. Arch. Photogramm. Remote Sens. 2000, 33, 326–334. [Google Scholar]
- Daniel, T.; Norbert, P. Segmentation Based Robust Interpolation-a New Approach to Laser Data Filtering. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2005, 36, 79–84. [Google Scholar]
- Ning, X.; Zhang, X.; Wang, Y.; Jaeger, M. Segmentation of Architecture Shape Information from 3D Point Cloud. In Proceedings of the 8th International Conference on Virtual Reality Continuum and Its Applications in Industry, Yokohama, Japan, 14–15 December 2009; pp. 127–132. [Google Scholar]
- Dong, Z.; Yang, B.; Hu, P.; Scherer, S. An Efficient Global Energy Optimization Approach for Robust 3D Plane Segmentation of Point Clouds. ISPRS J. Photogramm. Remote Sens. 2018, 137, 112–133. [Google Scholar] [CrossRef]
- Hang, S.; Subhransu, M.; Evangelos, K.; Erik, L.M. Multi-View Convolutional Neural Networks for 3d Shape Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Kerkyra, Greece, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Daniel, M.; Sebastian, S. Voxnet: A 3d Convolutional Neural Network for Real-Time Object Recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Charles Ruizhongtai, Q.; Li, Y.; Hao, S.; Leonidas, J.G. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/d8bf84be3800d12f74d8b05e9b89836f-Paper.pdf (accessed on 20 December 2023).
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, X.; He, T.; Zhao, H.; Liu, X. SAM3D: Segment Anything in 3D Scenes. arXiv 2023, arXiv:2306.03908. [Google Scholar]
- Wang, Z.; Yu, X.; Rao, Y.; Zhou, J.; Lu, J. P2P: Tuning Pre-trained Image Models for Point Cloud Analysis with Point-to-Pixel Prompting. Adv. Neural Inf. Process. Syst. 2022, 35, 14388–14402. [Google Scholar]
- Zhang, Z.; Ji, A.; Wang, K.; Zhang, L. UnrollingNet: An attention-based deep learning approach for the segmentation of large-scale point clouds of tunnels. Autom. Constr. 2022, 142, 104456. [Google Scholar] [CrossRef]
- Ji, A.; Chew, A.W.Z.; Xue, X.; Zhang, L. An encoder-decoder deep learning method for multi-class object segmentation from 3D tunnel point clouds. Autom. Constr. 2022, 137, 104187. [Google Scholar] [CrossRef]
- Soilán, M.; Nóvoa, A.; Sánchez-Rodríguez, A.; Riveiro, B.; Arias, P. Semantic Segmentation Of Point Clouds With Pointnet And Kpconv Architectures Applied To Railway Tunnels. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2020, 2, 281–288. [Google Scholar] [CrossRef]
- Ai, Z.; Bao, Y.; Guo, F.; Kong, H.; Bao, Y.; Lu, J. Central Axis Elevation Extraction Method of Metro Shield Tennel Based on 3D Laser Scanning Technology. China Metrol. 2023, 26, 68–71+77. [Google Scholar] [CrossRef]
- Wang, X.; Jing, D.; Xu, F. Deformation Analysis of Shield Tunnel Based on 3D Laser Scanning Technology. Beijing Surv. Mapp. 2021, 35, 962–966. [Google Scholar] [CrossRef]
- Li, M.; Kang, J.; Liu, H.; Li, Z.; Liu, X.; Zhu, Q.; Xiao, B. Study on parametric 3D modeling technology of mine roadway based on BIM and GIS. Coal Sci. Technol. 2022, 50, 25–35. [Google Scholar] [CrossRef]
- Si, L.; Wang, Z.; Liu, P.; Tan, C.; Chen, H.; Wei, D. A Novel Coal–Rock Recognition Method for Coal Mining Working Face Based on Laser Point Cloud Data. IEEE Trans. Instrum. Meas. 2021, 70, 1–18. [Google Scholar] [CrossRef]
- Lu, X.; Zhu, N.; Lu, F. An Elliptic Cylindrical Model for Tunnel Filtering. Geomat. Inf. Sci. Wuhan Univ. 2016, 41, 1476–1482. [Google Scholar] [CrossRef]
- Liu, S.; Sun, H.; Zhang, Z.; Li, Y.; Zhong, R.; Li, J.; Chen, S. A Multiscale Deep Feature for the Instance Segmentation of Water Leakages in Tunnel Using MLS Point Cloud Intensity Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Du, L.; Zhong, R.; Sun, H.; Pang, Y.; Mo, Y. Dislocation Detection of Shield Tunnel Based on Dense Cross-Sectional Point Clouds. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22227–22243. [Google Scholar] [CrossRef]
- Farahani, B.V.; Barros, F.; Sousa, P.J.; Tavares, P.J.; Moreira, P.M. A railway tunnel structural monitoring methodology proposal for predictive maintenance. Struct. Control Health Monit. 2020, 27, e2587. [Google Scholar] [CrossRef]
- Yi, C.; Lu, D.; Xie, Q.; Xu, J.; Wang, J. Tunnel Deformation Inspection via Global Spatial Axis Extraction from 3D Raw Point Cloud. Sensors 2020, 20, 6815. [Google Scholar] [CrossRef]
- Zhang, Z.; Ji, A.; Zhang, L.; Xu, Y.; Zhou, Q. Deep learning for large-scale point cloud segmentation in tunnels considering causal inference. Autom. Constr. 2023, 152, 104915. [Google Scholar] [CrossRef]
- Park, J.; Kim, B.-K.; Lee, J.S.; Yoo, M.; Lee, I.-W.; Ryu, Y.-M. Automated semantic segmentation of 3D point clouds of railway tunnel using deep learning. In Expanding Underground-Knowledge and Passion to Make a Positive Impact on the World; CRC Press: Boca Raton, FL, USA, 2023; pp. 2844–2852. [Google Scholar]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3D Semantic Parsing of Large-Scale Indoor Spaces. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016. [Google Scholar]
- Angela, D.; Angel, X.C.; Manolis, S.; Maciej, H.; Thomas, F.; Matthias, N. ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xing, Z.; Zhao, S.; Guo, W.; Guo, X.; Wang, S.; Ma, J.; He, H. Coal Wall and Roof Segmentation in the Coal Mine Working Face Based on Dynamic Graph Convolution Neural Networks. ACS Omega 2021, 6, 31699–31715. [Google Scholar] [CrossRef]
- Herve, A.; Lynne J, W. Principal Component Analysis. Nat. Rev. Methods Prim. 2022, 2, 100. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Data |
|---|---|
| Handheld size | L204 mm × W130 mm × H385 mm |
| Handheld weight | 1.74 kg |
| Scanning field of view | 280° × 360° |
| LiDAR accuracy | ±3 cm |
| Point frequency | 320,000 pts/s |
| mIoU | Left Wall | Right Wall | Roof | Floor | Wires | Belts Transport | Air Tube | |
|---|---|---|---|---|---|---|---|---|
| RG [21] | IOU | 0.6145 | 0.4513 | 0.9198 | 0.3881 | 0.9408 | 0.5590 | 0.9878 |
| Precision | 0.7362 | 0.5084 | 0.9312 | 0.5068 | 0.9574 | 0.7053 | 0.9912 | |
| PN [29] | IOU | 0.8756 | 0.8940 | 0.9467 | 0.3728 | 0.0923 | 0.5136 | 0.8883 |
| Precision | 0.9031 | 0.9215 | 0.9534 | 0.5041 | 0.1487 | 0.6675 | 0.9152 | |
| Ours | IOU | 0.8774 | 0.7520 | 0.8217 | 0.9852 | 0.9554 | 0.7262 | 0.9958 |
| Precision | 0.8923 | 0.7741 | 0.8389 | 0.9961 | 0.9721 | 0.7513 | 0.9971 |
| Indicator | Right Wall | Roof | |
|---|---|---|---|
| pointnet++ | IOU | 0.8940 | 0.9467 |
| Precision | 0.9215 | 0.9534 | |
| ours-view 1 | IOU | 0.9124 | 0.9552 |
| Precision | 0.9238 | 0.9718 | |
| ours-view 2 | IOU | 0.9086 | 0.9485 |
| Precision | 0.9234 | 0.9633 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, J.; Chen, N.; Li, M.; Mao, S.; Zhang, H.; Fan, Y.; Liu, H. A Point Cloud Segmentation Method for Dim and Cluttered Underground Tunnel Scenes Based on the Segment Anything Model. Remote Sens. 2024, 16, 97. https://doi.org/10.3390/rs16010097
Kang J, Chen N, Li M, Mao S, Zhang H, Fan Y, Liu H. A Point Cloud Segmentation Method for Dim and Cluttered Underground Tunnel Scenes Based on the Segment Anything Model. Remote Sensing. 2024; 16(1):97. https://doi.org/10.3390/rs16010097
Chicago/Turabian StyleKang, Jitong, Ning Chen, Mei Li, Shanjun Mao, Haoyuan Zhang, Yingbo Fan, and Hui Liu. 2024. "A Point Cloud Segmentation Method for Dim and Cluttered Underground Tunnel Scenes Based on the Segment Anything Model" Remote Sensing 16, no. 1: 97. https://doi.org/10.3390/rs16010097
APA StyleKang, J., Chen, N., Li, M., Mao, S., Zhang, H., Fan, Y., & Liu, H. (2024). A Point Cloud Segmentation Method for Dim and Cluttered Underground Tunnel Scenes Based on the Segment Anything Model. Remote Sensing, 16(1), 97. https://doi.org/10.3390/rs16010097