
Infrared Dim and Small Target Detection Based on Superpixel Segmentation and Spatiotemporal Cluster 4D Fully-Connected Tensor Network Decomposition


Abstract
:1. Introduction
1.1. Single-Frame Detection Methods
1.2. Sequential Detection Methods
1.3. Related Work
1.4. Motivation
- First, superpixel segmentation is employed to remove the reliance of conventional algorithms on the dimensions of sliding windows. For the first time, the application of superpixel segmentation to infrared dim and small target detection utilizing spatiotemporal tensor models is presented in this study.
- Second, in order to make better use of the spatiotemporal correlation, the Cluster 4D-FCTN model is proposed. Based on the improved structure tensor theory, the image pixels are statistically clustered into three types: corner area, flat area, and edge area. The 3D patches with the same feature type are rearranged into the same group to form a four-dimensional tensor, and different weights are assigned to the image pixels with line prior and point prior to reduce the influence of strong background edges.
- A fully-connected tensor network (FCTN) is proposed to detect small infrared targets using spatial and temporal correlation, which can better approximate the tensor rank. The FCTN decomposition is able to fully characterize the correlation between any two modes of a tensor. Additionally, the alternating direction multiplier method (ADMM), a highly efficient approach, has been developed to precisely address the proposed optimization model.
2. Notations and Preliminaries
2.1. Notations
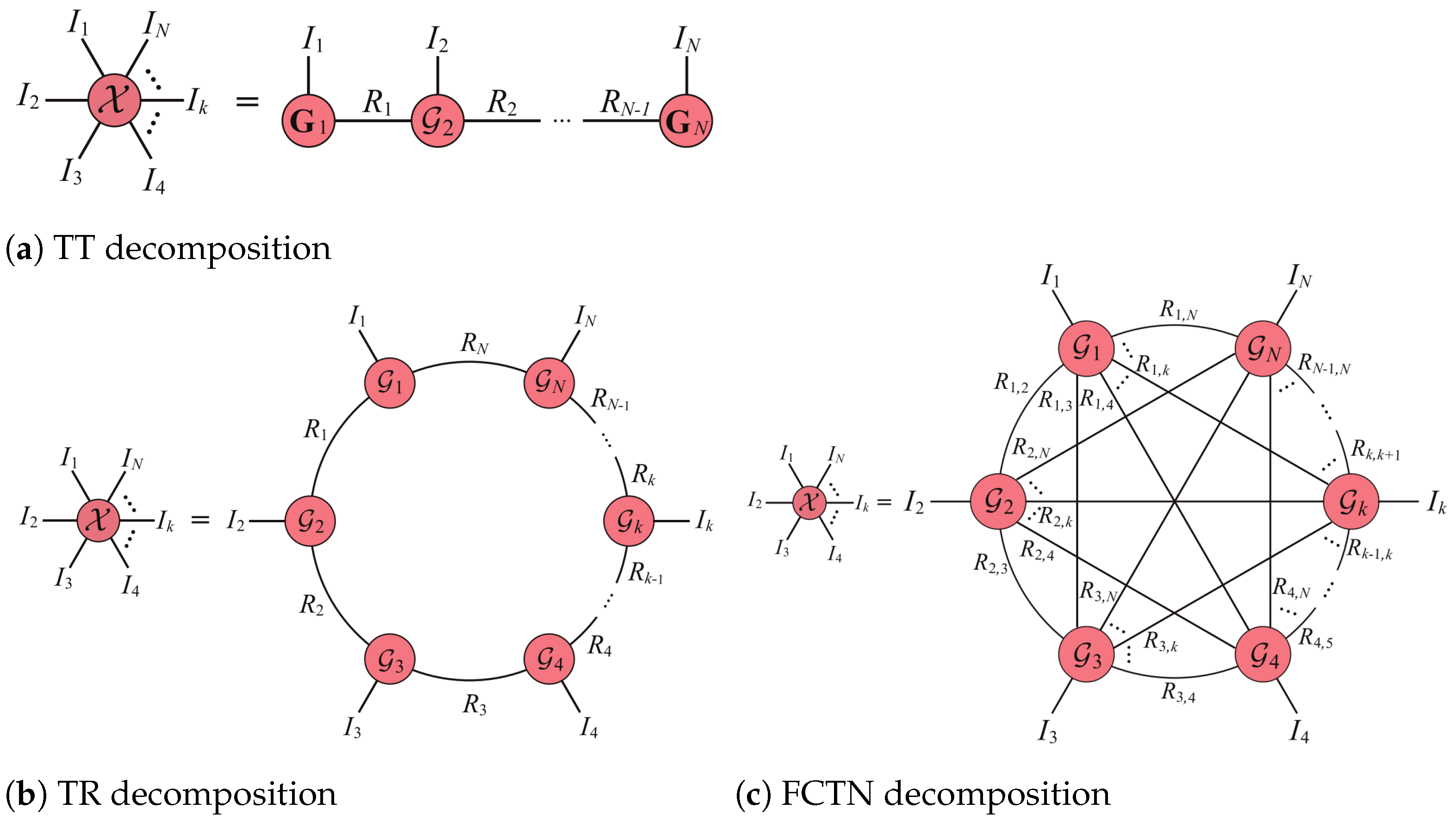
2.2. FCTN Decomposition
3. Methodology
3.1. Superpixel Segmentation
3.2. Description of Features Exploiting the Structure Tensor
3.3. The Cluster 4D-FCTN Model
3.3.1. Four-Dimensional Infrared Image Tensor Model
3.3.2. ISTD Based on C4D-FCTN
| Algorithm 1: The process of building the 4D infrared image tensor for clustering |
 |
3.4. Resolution of the Proposed Model
| Algorithm 2: Algorithm utilizing ADMM to solve the 4D-FCTN clustering problem. |
| Input: Original infrared tensor . parameter , , . |
| Output: Background tensor , target tensor , and noise tensor . |
| Initialization: , , , Multiplier of the Lagrangian function , , , parameters ,. |
| Update by Formula (27); |
| Update by Formula (29); |
| Update and by Formulas (31) and (32); |
| Update Lagrangian multiplies by Formula (33); |
| Verify the condition of convergence: ; |
| Should the convergence criteria not be satisfied, increment t by 1 and proceed to Step 1. |
- (1)
- For a sequence of original images consisting of N frames, denoted as , we create three Cluster 4D infrared image tensors , , and by organizing a sequence of frames in the correct temporal sequence using Algorithm 1, as described in Step 1 of Figure 6.
- (2)
- For the three obtained 4D tensors, each is decomposed into target 4D tensors , background 4D tensors , and noise 4D tensors obtained through by Cluster 4D-FCTN decomposition using Algorithm 2, as described in Step 2 of Figure 6.
- (3)
- We reconstruct the target images from the 4D target tensor of the point feature , the 4D target tensor of the line feature , and the 4D target tensor of the flat feature using the reverse process outlined in Algorithm 1, as described in Step 3 of Figure 6.

3.5. Complexity Analysis
4. Experiment and Results
4.1. Data and Experiment Settings
4.2. Evaluation Metrics and Baselines
4.3. Parameter Settings
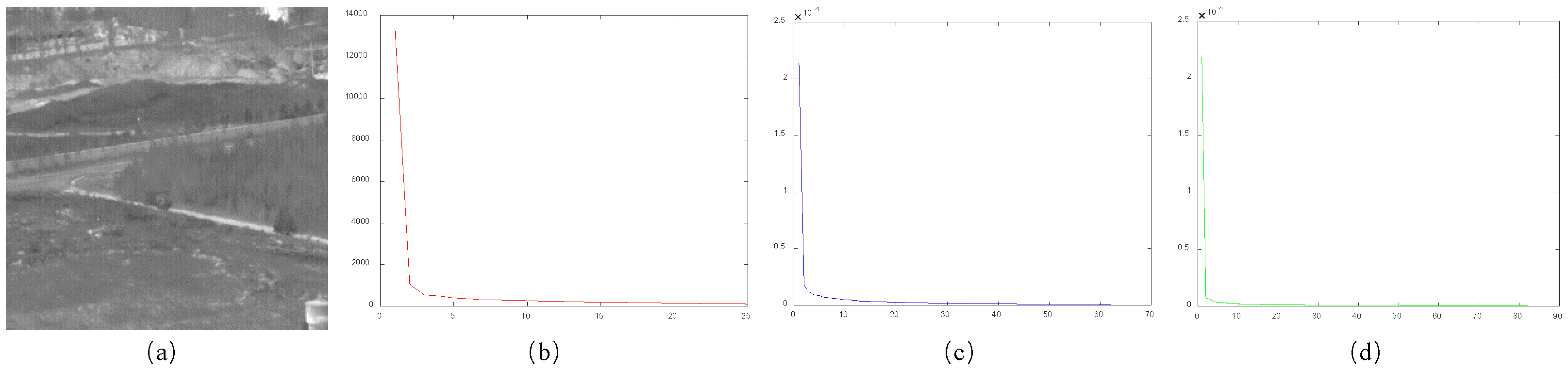
4.3.1. Patch Size
4.3.2. Temporal Size
4.4. Robustness of Scene Perception in Real-World and Synthetic Noisy Environments
4.4.1. Robustness in Diverse Environmental Conditions
4.4.2. Robustness against Noise
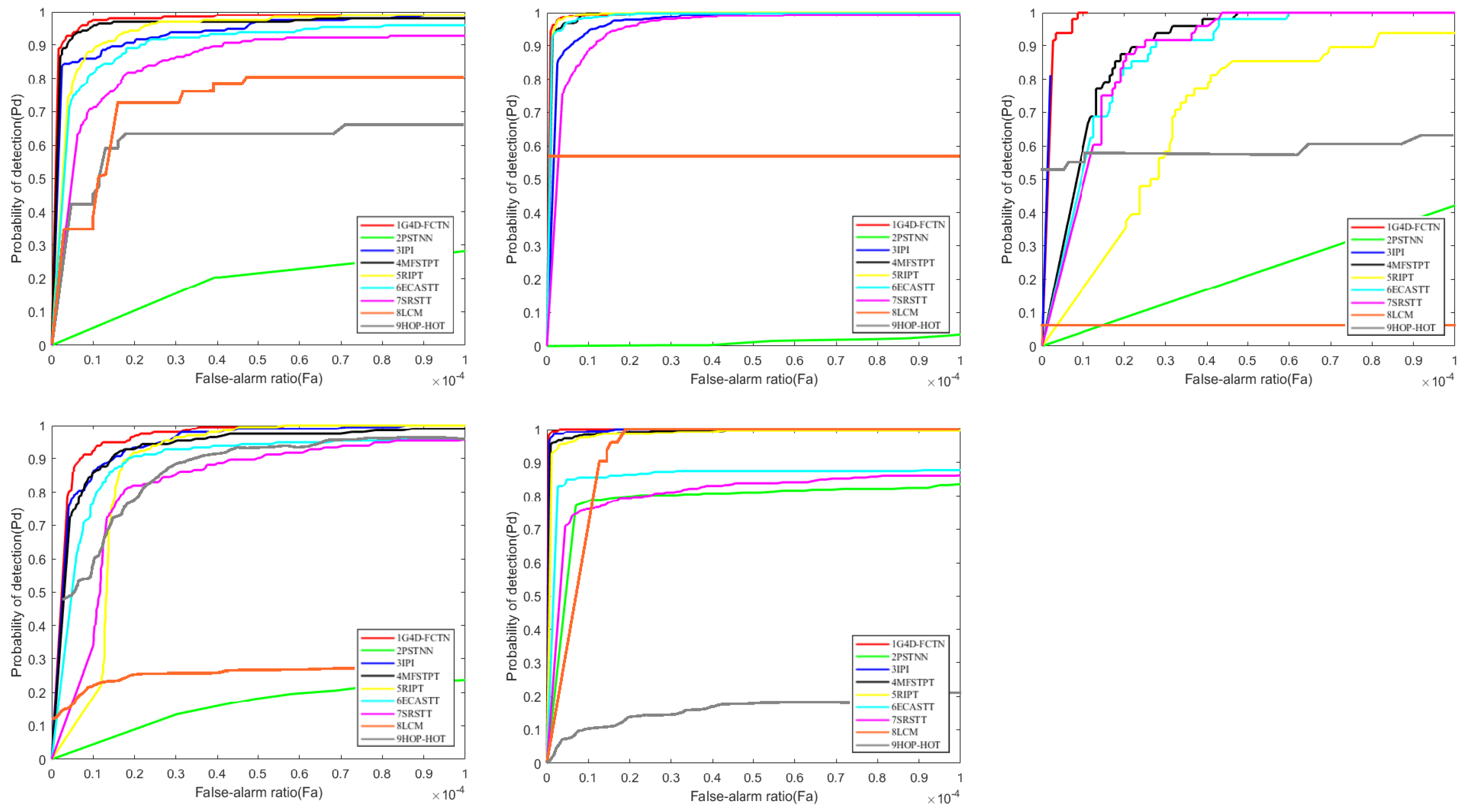
4.5. Comparison with Other Typical Methods
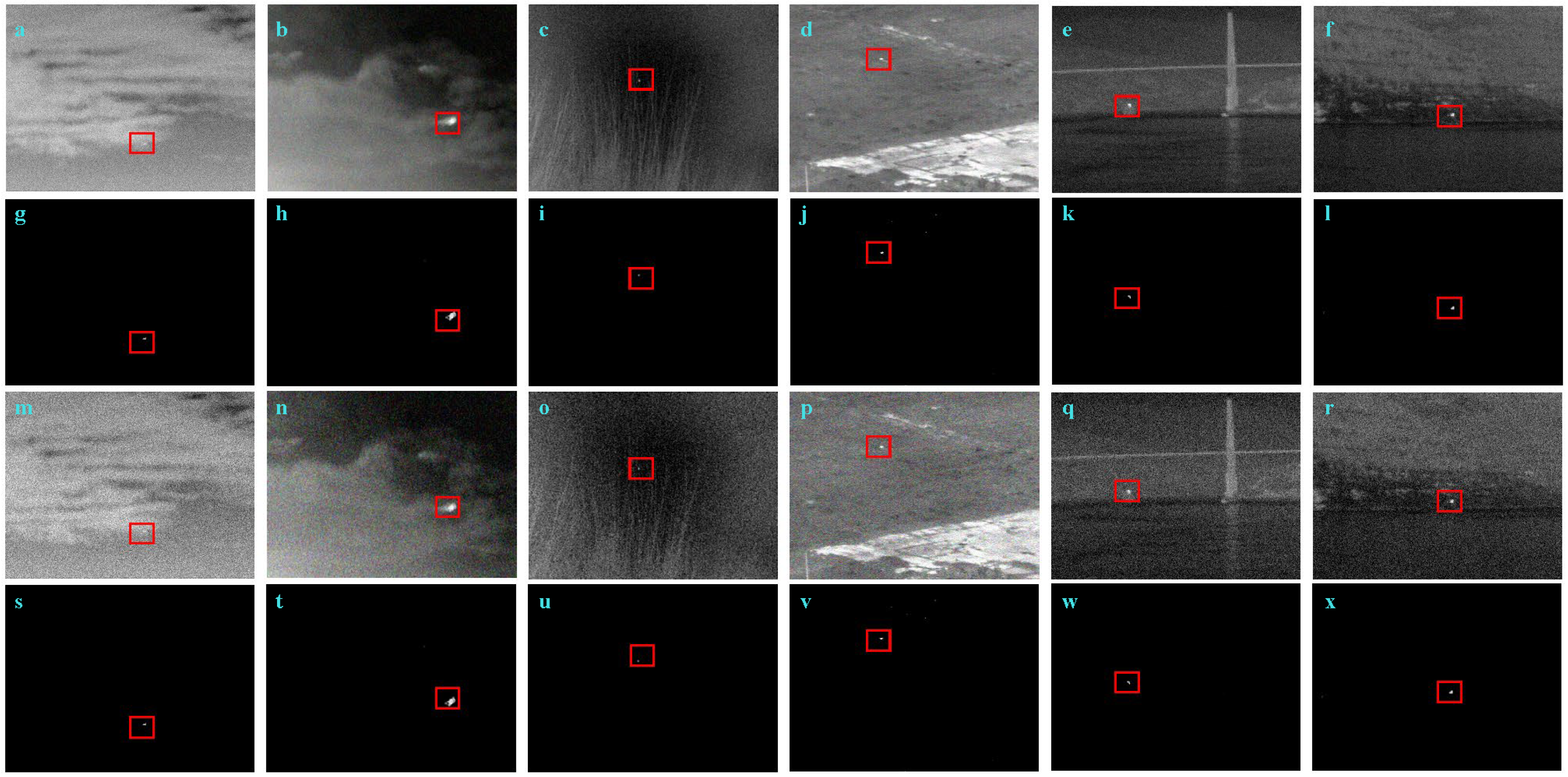
4.5.1. Visual Comparison
4.5.2. Qualitative Analysis
4.5.3. Comparison of Time Required for Computation
4.6. Ablation Study
5. Discussion
- The method based on low-rank sparse decomposition involves many parameters, such as the size of the sliding window, the moving step of the sliding window, the weight coefficient in the objective function, and more. These parameters have an important impact on the performance of the algorithm.
- At present, the construction of the tensor is relatively simple, generally using the sliding window to traverse the original infrared image or multi-frame sequence images to construct the tensor directly, which involves a large amount of redundant information that has nothing to do with the target.
- The background tensor rank approximation is not accurate.
- When utilizing time-domain information, existing algorithms based on low-rank sparse decomposition mainly fuse the time domain information into the image matrix or tensor data, and use multi-frame images instead of the original single-frame images to construct new data. However, the sequence information between the frames is not fully mined.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhou, F.; Wu, Y.; Dai, Y.; Wang, P.; Ni, K. Graph-regularized laplace approximation for detecting small infrared target against complex backgrounds. IEEE Access 2019, 7, 85354–85371. [Google Scholar] [CrossRef]
- Ren, X.; Wang, J.; Ma, T.; Zhu, X.; Bai, K.; Wang, J. Review on infrared dim and small target detection technology. J. Zhengzhou Univ. (Nat. Sci. Ed.) 2020, 52, 1–21. [Google Scholar]
- Bai, X.; Bi, Y. Derivative entropy-based contrast measure for infrared small-target detection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2452–2466. [Google Scholar] [CrossRef]
- Li, J.; Zhang, P.; Wang, X.; Huang, S. Infrared small-target detection algorithms: A survey. J. Image Graph. 2020, 25, 1739–1753. [Google Scholar]
- Jinhui, H.; Yantao, W.; Zhenming, P.; Qian, Z.; Yaohong, C.; Yao, Q.; Nan, L. Infrared dim and small target detection: A review. Infrared Laser Eng. 2022, 51, 20210393-1. [Google Scholar]
- Liu, C.; Wang, H. Research on infrared dim and small target detection algorithm based on low-rank tensor recovery. J. Syst. Eng. Electron. 2023, 34, 861–872. [Google Scholar]
- Yang, W.P.; Shen, Z.K. Small target detection and preprocessing technology in infrared image sequences. Infrared Laser Eng. 1998, 27, 23–28. [Google Scholar]
- Deshpande, S.D.; Er, M.H.; Venkateswarlu, R.; Chan, P. Max-mean and max-median filters for detection of small targets. In Signal and Data Processing of Small Targets 1999 Denver, CO, United States; SPIE: Bellingham, DC, USA, 1999; Volume 3809, pp. 74–83. [Google Scholar]
- Yu, N.; Wu, C.Y.; Tang, X.Y.; Li, F.M. Adaptive background perception algorithm for infrared target detection. Acta Electonica Sin. 2005, 33, 200. [Google Scholar]
- Liu, Y.; Tang, X.; Li, Z. A new top hat local contrast based algorithm for infrared small target detection. Infrared Technol. 2015, 37, 544–552. [Google Scholar]
- Bi, Y.; Chen, J.; Sun, H.; Bai, X. Fast detection of distant, infrared targets in a single image using multiorder directional derivatives. IEEE Trans. Aerosp. Electron. Syst. 2019, 56, 2422–2436. [Google Scholar] [CrossRef]
- Lu, R.; Yang, X.; Li, W.; Fan, J.; Li, D.; Jing, X. Robust infrared small target detection via multidirectional derivative-based weighted contrast measure. IEEE Geosci. Remote. Sens. Lett. 2020, 19, 7000105. [Google Scholar] [CrossRef]
- Dong, L.; Wang, B.; Zhao, M.; Xu, W. Robust infrared maritime target detection based on visual attention and spatiotemporal filtering. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3037–3050. [Google Scholar] [CrossRef]
- Han, J.; Liu, C.; Liu, Y.; Luo, Z.; Zhang, X.; Niu, Q. Infrared small target detection utilizing the enhanced closest-mean background estimation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 645–662. [Google Scholar] [CrossRef]
- Yang, L.; Yang, J.; Yang, K. Adaptive detection for infrared small target under sea-sky complex background. Electron. Lett. 2004, 40, 1. [Google Scholar] [CrossRef]
- Qi, S.; Ma, J.; Li, H.; Zhang, S.; Tian, J. Infrared small target enhancement via phase spectrum of quaternion Fourier transform. Infrared Phys. Technol. 2014, 62, 50–58. [Google Scholar] [CrossRef]
- Sheng, Z.; Jian, L.; Jinwen, T. Research of SVM-based infrared small object segmentation and clustering method. Signal Process. 2005, 21, 515–519. [Google Scholar]
- Dong, X.; Huang, X.; Zheng, Y.; Bai, S.; Xu, W. A novel infrared small moving target detection method based on tracking interest points under complicated background. Infrared Phys. Technol. 2014, 65, 36–42. [Google Scholar] [CrossRef]
- Zhao, J.; Tang, Z.; Yang, J.; Liu, E. Infrared small target detection using sparse representation. J. Syst. Eng. Electron. 2011, 22, 897–904. [Google Scholar] [CrossRef]
- Liu, D.; Li, Z.; Liu, B.; Chen, W.; Liu, T.; Cao, L. Infrared small target detection in heavy sky scene clutter based on sparse representation. Infrared Phys. Technol. 2017, 85, 13–31. [Google Scholar] [CrossRef]
- Xu, K.; Hu, W.; Zhou, W.; Zheng, H. Target detection based on the artificial neural network technology. In Proceedings of the 2006 9th International Conference on Control, Automation, Robotics and Vision, Orlando, FL, USA, 15–19 May 2006; pp. 1–5. [Google Scholar]
- Ma, Q.; Zhu, B.; Cheng, Z.; Zhang, Y. Detection and recognition method of fast low-altitude unmanned aerial vehicle based on dual channel. Acta Opt. Sin. 2019, 39, 105–115. [Google Scholar]
- Hou, Q.; Wang, Z.; Tan, F.; Zhao, Y.; Zheng, H.; Zhang, W. RISTDnet: Robust infrared small target detection network. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional local contrast networks for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Zhang, X.; Ren, K.; Wan, M.; Gu, G. Infrared small target tracking based on sample constrained particle filtering and sparse representation. Infrared Phys. Technol. 2017, 87, 72–82. [Google Scholar]
- Fan, X.; Li, J.; Chen, H.; Min, L.; Li, F. Dim and small target detection based on improved hessian matrix and F-Norm collaborative filtering. Remote Sens. 2022, 14, 4490. [Google Scholar] [CrossRef]
- Liu, D.; Li, Z.; Wang, X.; Zhang, J. Moving target detection by nonlinear adaptive filtering on temporal profiles in infrared image sequences. Infrared Phys. Technol. 2015, 73, 41–48. [Google Scholar] [CrossRef]
- Fan, X.; Li, J.; Min, L.; Feng, L.; Yu, L.; Xu, Z. Dim and Small Target Detection Based on Energy Sensing of Local Multi-Directional Gradient Information. Remote Sens. 2023, 15, 3267. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared patch-image model for small target detection in a single image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef] [PubMed]
- Dai, Y.; Wu, Y. Reweighted infrared patch-tensor model with both nonlocal and local priors for single-frame small target detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3752–3767. [Google Scholar] [CrossRef]
- Wang, X.; Peng, Z.; Kong, D.; Zhang, P.; He, Y. Infrared dim target detection based on total variation regularization and principal component pursuit. Image Vis. Comput. 2017, 63, 1–9. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, Z. Infrared small target detection based on partial sum of the tensor nuclear norm. Remote Sens. 2019, 11, 382. [Google Scholar] [CrossRef]
- Cao, Z.; Kong, X.; Zhu, Q.; Cao, S.; Peng, Z. Infrared dim target detection via mode-k1k2 extension tensor tubal rank under complex ocean environment. ISPRS J. Photogramm. Remote Sens. 2021, 181, 167–190. [Google Scholar] [CrossRef]
- Kong, X.; Yang, C.; Cao, S.; Li, C.; Peng, Z. Infrared small target detection via nonconvex tensor fibered rank approximation. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–21. [Google Scholar] [CrossRef]
- Zhang, P.; Zhang, L.; Wang, X.; Shen, F.; Pu, T.; Fei, C. Edge and corner awareness-based spatial–temporal tensor model for infrared small-target detection. IEEE Trans. Geosci. Remote Sens. 2020, 59, 10708–10724. [Google Scholar] [CrossRef]
- Hu, Y.; Ma, Y.; Pan, Z.; Liu, Y. Infrared dim and small target detection from complex scenes via multi-frame spatial–temporal patch-tensor model. Remote Sens. 2022, 14, 2234. [Google Scholar] [CrossRef]
- Li, J.; Zhang, P.; Zhang, L.; Zhang, Z. Sparse Regularization-Based Spatial–Temporal Twist Tensor Model for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Wu, F.; Yu, H.; Liu, A.; Luo, J.; Peng, Z. Infrared Small Target Detection Using Spatio-Temporal 4D Tensor Train and Ring Unfolding. IEEE Trans. Geosci. Remote Sens. 2023. [Google Scholar]
- Sun, Y.; Yang, J.; Long, Y.; An, W. Infrared small target detection via spatial–temporal total variation regularization and weighted tensor nuclear norm. IEEE Access 2019, 7, 56667–56682. [Google Scholar] [CrossRef]
- Liu, H.K.; Zhang, L.; Huang, H. Small target detection in infrared videos based on spatio-temporal tensor model. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8689–8700. [Google Scholar] [CrossRef]
- Liu, Y.Y.; Zhao, X.L.; Song, G.J.; Zheng, Y.B.; Huang, T.Z. Fully-connected tensor network decomposition for robust tensor completion problem. arXiv 2021, arXiv:2110.08754. [Google Scholar] [CrossRef]
- Vaswani, N.; Bouwmans, T.; Javed, S.; Narayanamurthy, P. Robust subspace learning: Robust PCA, robust subspace tracking, and robust subspace recovery. IEEE Signal Process. Mag. 2018, 35, 32–55. [Google Scholar] [CrossRef]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor robust principal component analysis with a new tensor nuclear norm. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 925–938. [Google Scholar] [CrossRef] [PubMed]
- Grasedyck, L.; Hackbusch, W. An introduction to hierarchical (H-) rank and TT-rank of tensors with examples. Comput. Methods Appl. Math. 2011, 11, 291–304. [Google Scholar] [CrossRef]
- Wang, W.; Aggarwal, V.; Aeron, S. Efficient low rank tensor ring completion. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5697–5705. [Google Scholar]
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J. Tensor completion for estimating missing values in visual data. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 208–220. [Google Scholar] [CrossRef]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor robust principal component analysis: Exact recovery of corrupted low-rank tensors via convex optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5249–5257. [Google Scholar]
- Oseledets, I.V. Tensor-train decomposition. SIAM J. Sci. Comput. 2011, 33, 2295–2317. [Google Scholar] [CrossRef]
- Yu, J.; Li, C.; Zhao, Q.; Zhao, G. Tensor-ring nuclear norm minimization and application for visual: Data completion. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3142–3146. [Google Scholar]
- Huang, H.; Liu, Y.; Long, Z.; Zhu, C. Robust low-rank tensor ring completion. IEEE Trans. Comput. Imaging 2020, 6, 1117–1126. [Google Scholar] [CrossRef]
- Zheng, Y.B.; Huang, T.Z.; Zhao, X.L.; Zhao, Q.; Jiang, T.X. Fully-connected tensor network decomposition and its application to higher-order tensor completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 11071–11078. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Di Zenzo, S. A note on the gradient of a multi-image. Comput. Vision Graph. Image Process. 1986, 33, 116–125. [Google Scholar] [CrossRef]
- Förstner, W.; Gülch, E. A fast operator for detection and precise location of distinct points, corners and centres of circular features. In Proceedings of the ISPRS Intercommission Conference on Fast Processing of Photogrammetric Data, Interlaken, Switzerland, 2–4 June 1987; Volume 6, pp. 281–305. [Google Scholar]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Hui, B.; Song, Z.; Fan, H.; Zhong, P.; Hu, W.; Zhang, X.; Lin, J.; Su, H.; Jin, W.; Zhang, Y.; et al. A dataset for infrared image dim-small aircraft target detection and tracking under ground/air background. Sci. Data Bank 2019, 5, 12. [Google Scholar]
- Wang, G.; Tao, B.; Kong, X.; Peng, Z. Infrared small target detection using nonoverlapping patch spatial–temporal tensor factorization with capped nuclear norm regularization. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5001417. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Seq. | Image Size | Frames | Average SCR | Target Description | Background Description |
|---|---|---|---|---|---|
| 1 | 256 × 256 | 300 | 0.83 | Single, tiny, low nonlocal contrast | Artifical structures, clutter |
| 2 | 256 × 256 | 200 | 6.08 | Small, slow-moving airplane | Village, reflective road, forest |
| 3 | 256 × 256 | 100 | 0.71 | Small, slow-moving airplane | village, reflective road, forest |
| 4 | 256 × 256 | 300 | 14.52 | Single, slow-moving airplane | Forest, bright rock, noise |
| 5 | 256 × 256 | 200 | 7.55 | Small, dim, regular shape | River, noise, heavy clutter |
| Method | Parameters |
|---|---|
| IPI | Patch size: : 50 × 50, sliding size: 10, , |
| RIPT | Patch size: : 30 × 30, sliding size: 10, , |
| PSTNN | Patch size: : 40 × 40, sliding size: 40, , |
| ECASTT | , t = 3, , , , |
| MFSTPT | Patch size: : 60 × 60, sliding size: 60, |
| SRSTT | L = 30, , , , , |
| Ours | Patch size: , temporal size: , |
| Method | Seq1 | Seq2 | Seq3 | Seq4 | Seq5 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| SCRG | BSF | SCRG | BSF | SCRG | BSF | SCRG | BSF | SCRG | BSF | |
| IPI | 7.63 | 2.38 | 8.63 | 7.63 | 5.30 | 2.87 | 10.62 | 5.62 | 25.64 | 7.17 |
| ECASTT | 60.16 | 15.81 | 15.29 | 23.47 | 11.91 | 26.49 | 11.34 | 9.75 | 84.64 | 14.45 |
| MFSTPT | 24.60 | 19.96 | 102.79 | 295.14 | 13.51 | 207.24 | 1.02 | 0.69 | 34.68 | 12.45 |
| PSTNN | 26.17 | 23.30 | 0.95 | 59.55 | 82.49 | 10.75 | 274.37 | 11.26 | 6.45 | 25.45 |
| RIPT | 6.71 | 1.32 | 10.41 | 2.18 | 4.61 | 4.21 | 9.42 | 1.92 | 15.14 | 9.65 |
| SRSTT | 56.96 | 262.48 | 346.98 | 245.78 | 206.97 | 94.52 | 49.09 | 98.97 | 64.52 | 246.54 |
| Ours | 70.17 | 221.32 | 408.55 | 1330.8 | 860.65 | 301.44 | 767.19 | 374.39 | 56.96 | 285.62 |
| Method | Seq1 | Seq2 | Seq3 | Seq4 | Seq5 | |||||
| CG | LSNRG | CG | LSNRG | CG | LSNRG | CG | LSNRG | CG | LSNRG | |
| IPI | 1.27 | 2.75 | 19.54 | 1.43 | 1.10 | 1.22 | 1.90 | 2.73 | 1.23 | 17.08 |
| ECASTT | 0 | 32.67 | 1.35 | 1.30 | 1.21 | 1.12 | 0 | 2.87 | 1.62 | 4.44 |
| MFSTPT | 1.57 | 1.03 | 1.07 | 4.60 | 1.09 | 2.31 | 1.57 | 0 | 1.05 | 28.38 |
| PSTNN | 0.11 | 2.87 | 0.18 | 0.07 | 0.03 | 0.05 | 0.11 | 0 | 0.84 | 0.86 |
| RIPT | 2.31 | 2.87 | 1.40 | 2.04 | 1.25 | 1.43 | 2.30 | 0 | 1.31 | 4.27 |
| SRSTT | 2.83 | 47.08 | 1.28 | 20.01 | 2.81 | 2.89 | 2.87 | 0 | 1.56 | 8.36 |
| Ours | 3.75 | 68.45 | 2.25 | 35.64 | 1.14 | 0.98 | 2.32 | 47.08 | 1.60 | 4.62 |
| Method | Seq1 | Seq2 | Seq3 | Seq4 | Seq5 |
|---|---|---|---|---|---|
| IPI | 10.53 | 11.706 | 12.272 | 17.341 | 23.929 |
| ECASTT | 9.205 | 14.823 | 15.006 | 16.087 | 13.821 |
| MFSTPT | 0.956 | 1.103 | 1.035 | 1.324 | 0.998 |
| PSTNN | 0.113 | 0.125 | 0.213 | 0.341 | 0.245 |
| RIPT | 2.800 | 2.341 | 2.515 | 2.641 | 3.069 |
| SRSTT | 18.625 | 17.633 | 19.562 | 20.065 | 17.326 |
| Ours | 0.351 | 0.247 | 0.650 | 0.324 | 0.231 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, W.; Ma, T.; Li, M.; Zuo, H. Infrared Dim and Small Target Detection Based on Superpixel Segmentation and Spatiotemporal Cluster 4D Fully-Connected Tensor Network Decomposition. Remote Sens. 2024, 16, 34. https://doi.org/10.3390/rs16010034
Wei W, Ma T, Li M, Zuo H. Infrared Dim and Small Target Detection Based on Superpixel Segmentation and Spatiotemporal Cluster 4D Fully-Connected Tensor Network Decomposition. Remote Sensing. 2024; 16(1):34. https://doi.org/10.3390/rs16010034
Chicago/Turabian StyleWei, Wenyan, Tao Ma, Meihui Li, and Haorui Zuo. 2024. "Infrared Dim and Small Target Detection Based on Superpixel Segmentation and Spatiotemporal Cluster 4D Fully-Connected Tensor Network Decomposition" Remote Sensing 16, no. 1: 34. https://doi.org/10.3390/rs16010034
APA StyleWei, W., Ma, T., Li, M., & Zuo, H. (2024). Infrared Dim and Small Target Detection Based on Superpixel Segmentation and Spatiotemporal Cluster 4D Fully-Connected Tensor Network Decomposition. Remote Sensing, 16(1), 34. https://doi.org/10.3390/rs16010034