
Multi-Level Attention Interactive Network for Cloud and Snow Detection Segmentation




Abstract
:1. Introduction
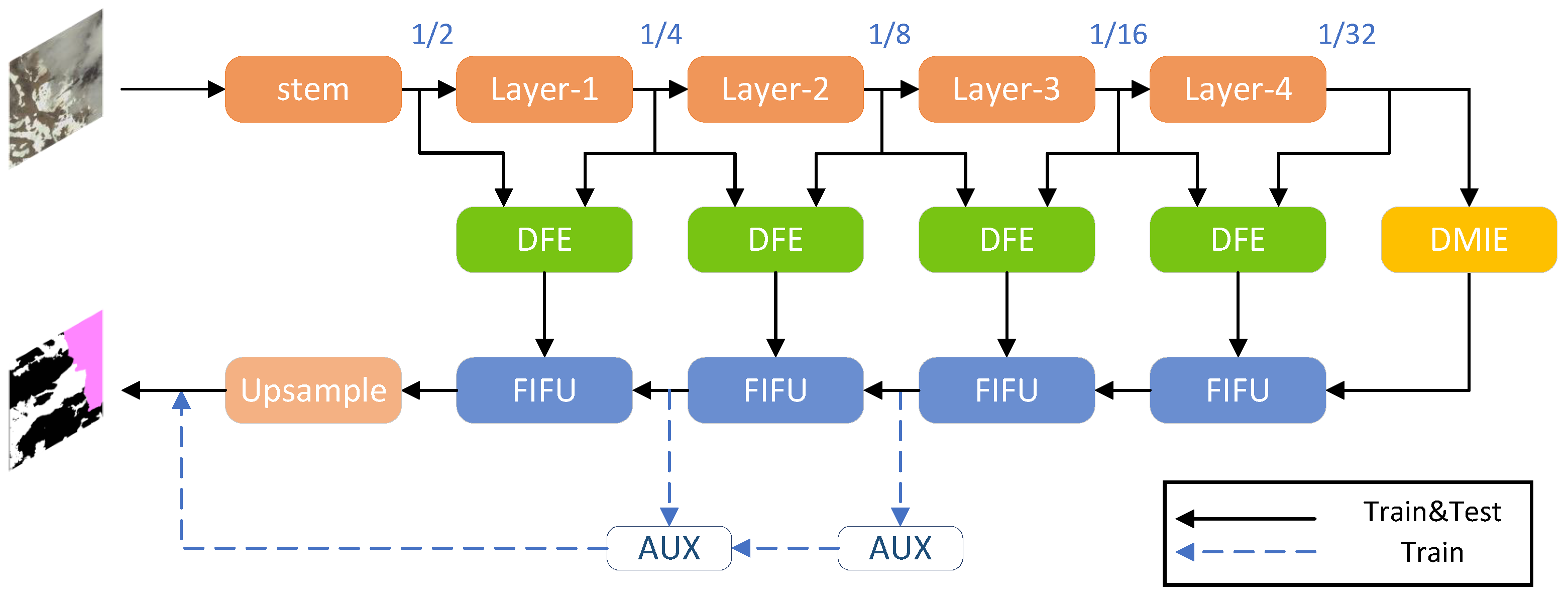
- A new cloud and snow detection network, a Multi-level Attention Interactive Network (MAINet), is proposed to strengthen the attention to the details of cloud and snow, which only uses visible channel remote sensing images to achieve higher detection accuracy and faster detection speed.
- Detail Feature Extraction (DFE) is supplied to extract the sameness and difference between the information in the down-sampling stage, reduce the information loss, strengthen the detail information, and realize the refinement of the edge;
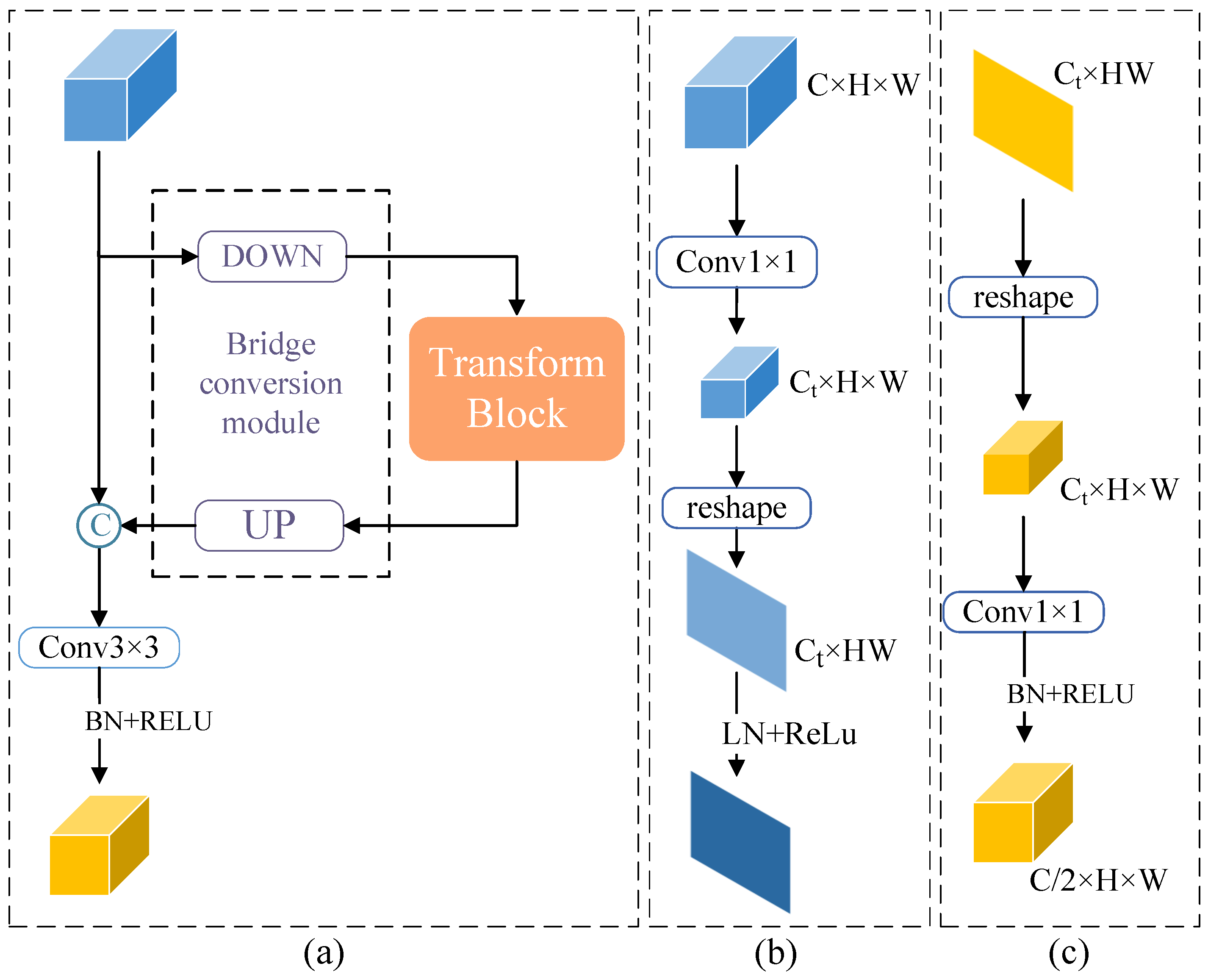
- Deep Multi-head Information Enhancement (DMIE) is created in the last step of down-sampling. The CNN and Transformer structures were combined by bridging units to accomplish the purpose of retaining local and global features, which can more deeply mine the relationship between deep features and enhance the network’s capacity for representation;
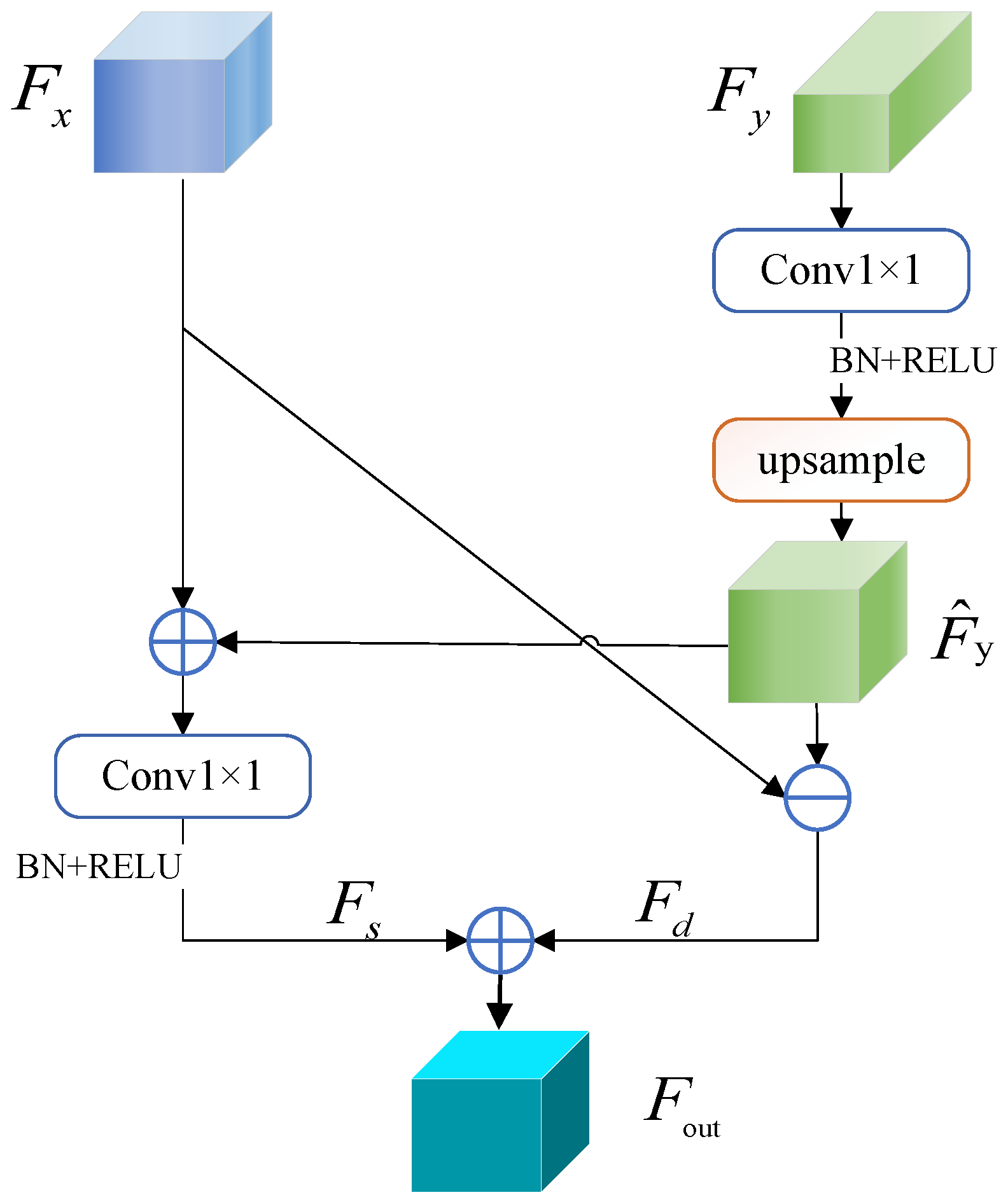
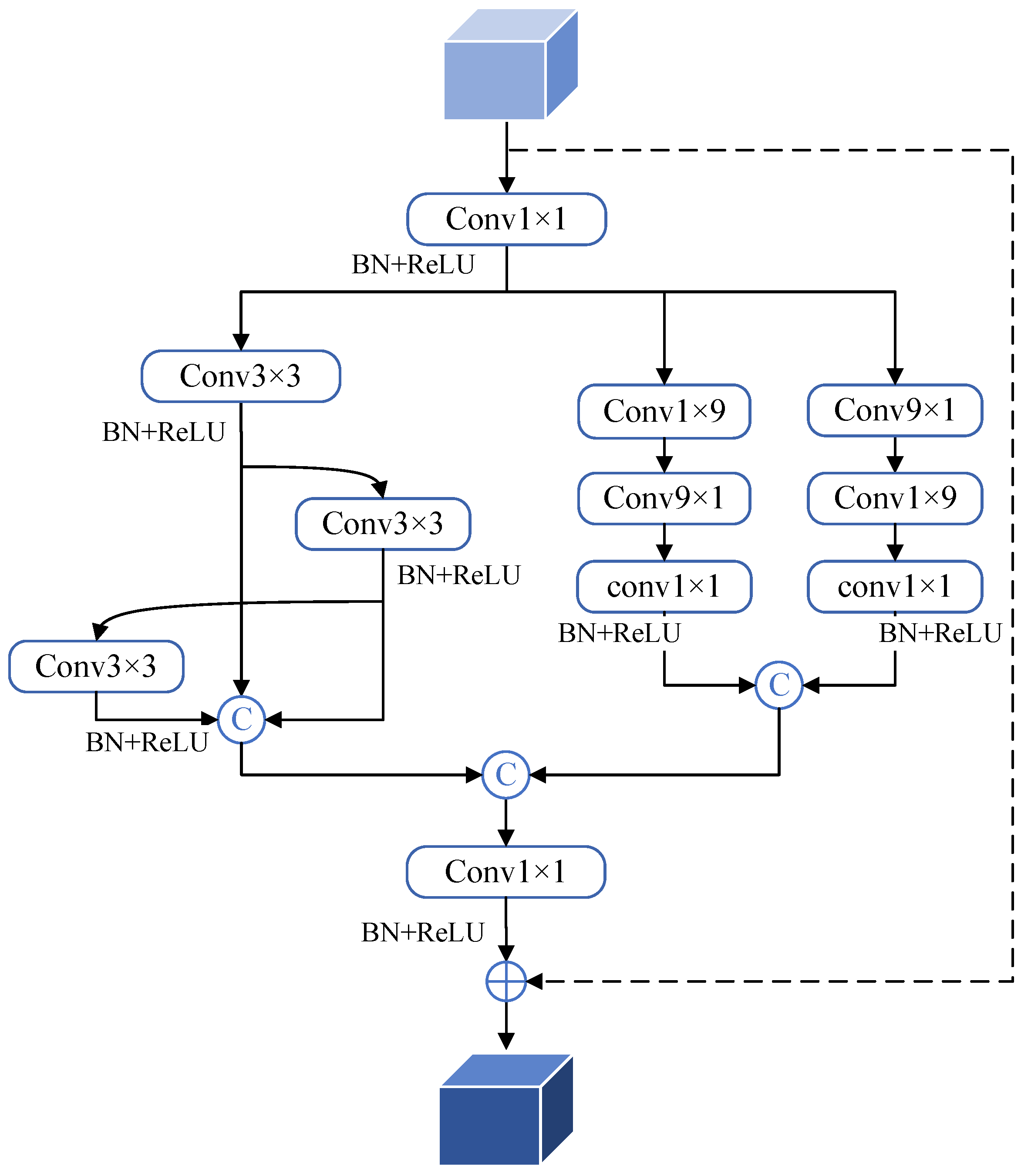
- Feature Interaction and Fusion Up-sampling modules (FIFU) is also proposed in the up-sampling process to restore remote sensing images more effectively and improve prediction accuracy, which consists of three small blocks. The MSBC block extracts multi-scale information and captures edge feature. The SCA block uses a spatial and channel feature attention mechanism to enhance the spatial relationship information and important channel information. The SFIF block aggregates the two types of information and guides them to make the semantic features of the cloud and snow more complete and boost the effectiveness of feature extraction.
2. Methodology
2.1. Network Architecture
2.2. Deep Multi-Headed Information Enhancement
2.3. Detail Feature Extraction
2.4. Feature Interaction and Fusion Up-Sampling
2.4.1. Multi-Scale and Strip Boundary Convolution
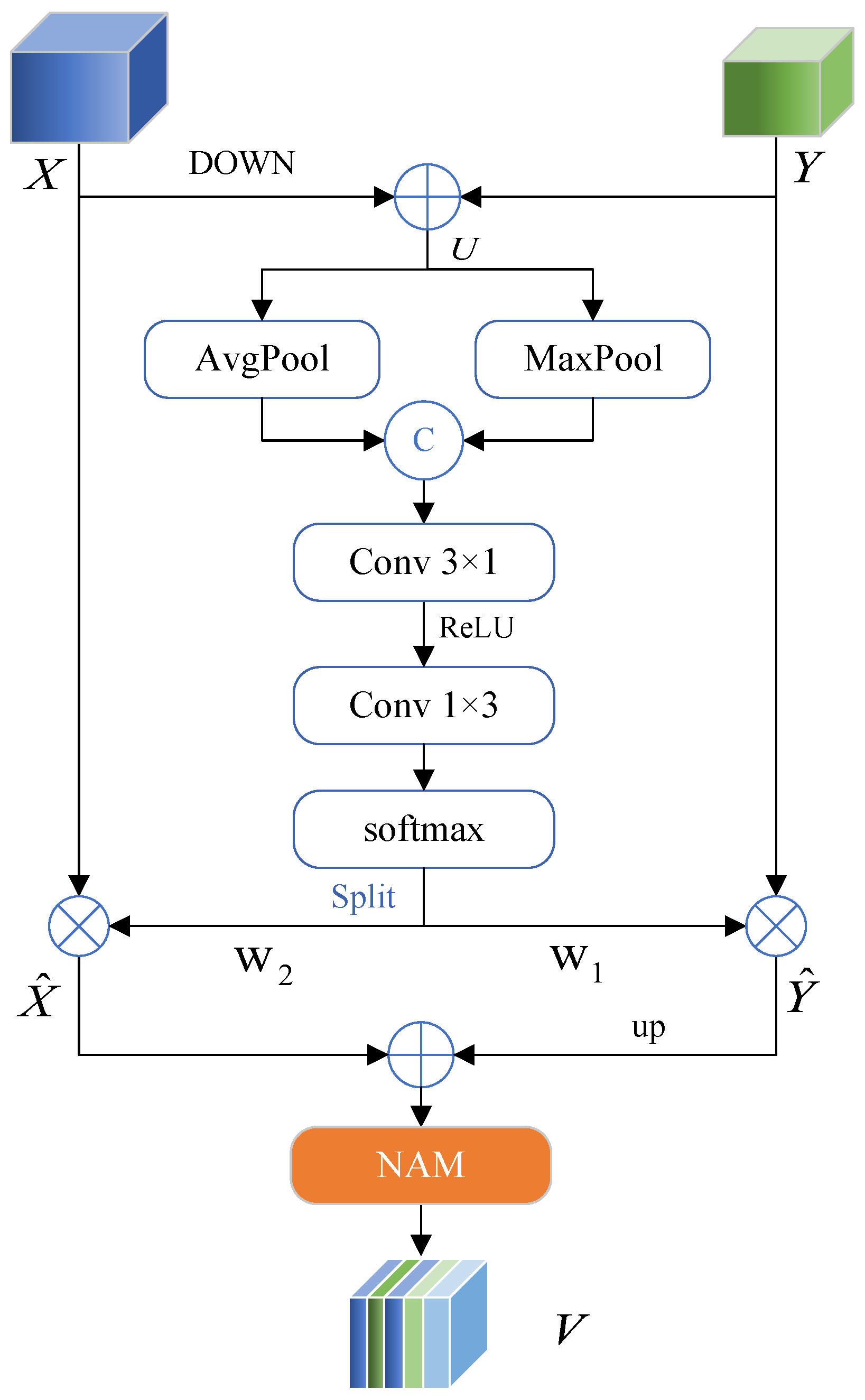
2.4.2. Spatial Channel Attention
2.4.3. Spatial Feature Interactive Fusion
3. Experiment
3.1. Dataset Introduction
3.1.1. CSWV Dataset
3.1.2. HRC_WHU Dataset
3.2. Experimental Setup
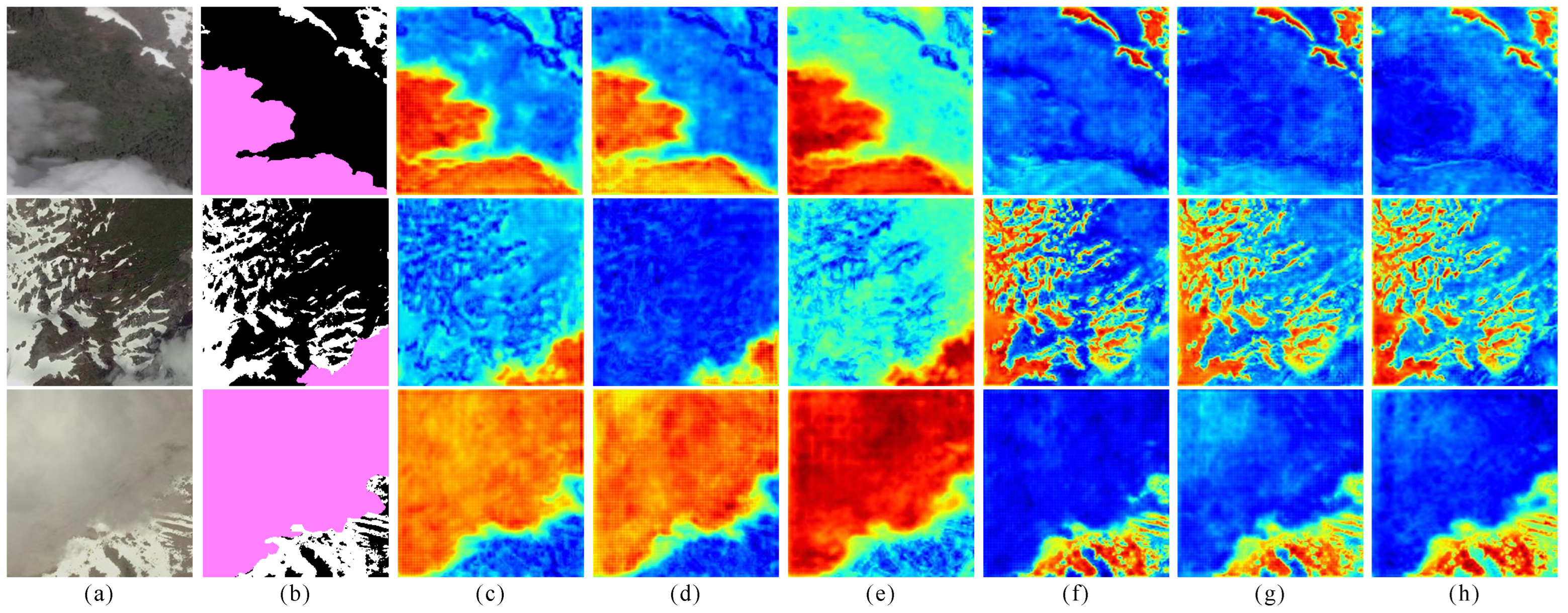
3.3. Ablation Experiment
- Ablation for SCA: The spatial channel self-attention mechanism module combines two attention mechanisms of the space and channel to determine spatial connections between pixels and direct the network to adaptively focus on important channel information in the entire image. This lessens the amount of redundant, irrelevant information and significantly increases the categorization information prediction accuracy. The data in Table 2 demonstrate that SCA can improve the PA and MIoU indexes by 0.44% and 1.01%, respectively, which exactly validated our analysis.
- Ablation for SFIF: The module introduces shallow information across layers in the deep network to strengthen the spatial information with less computation and parameters and effectively integrates the information of different branches, which can recover remote sensing images more effectively. According to the experiments’ data, our model improved the PA and MIoU indexes by 0.19% and 0.34%.
- Ablation for MSBC: This module extracts the information of multi-scale receptive fields for the shallow information introduced across layers through convolutional kernels of different sizes and adopts strip convolutional kernels to more effectively collect edge features while enhancing the global semantics. Table 2 shows that the MSBC module increased the PA and MIoU by 0.09% and 0.19%, respectively.
- Ablation for DFE: Since some important details may be lost in the sampling operation, DFE extracts the sameness and difference information from two adjacent different scales’ features, then aggregates both pieces of information to obtain a richer feature map. The obtained feature map will be used as the shallow branch of SFIF, which can more successfully serve as a reference for remote sensing image restoration. As the details are reproduced, it can be seen from Table 2 that DFE had beneficial effects; DFE can improve the PA of the model from 95.10% to 95.28% and the MIoU from 89.71% to 90.09%.
- Ablation for DMIE: This module takes into account the respective structural advantages of the CNN and Transformer, realizes the combination of the two in the deep layer through the bridge unit, so as to retain local and global feature extraction, and can dig for the features more deeply. Although this module adds many parameters and calculations, it further strengthens the segmentation effect and increases the network’s capacity for representation. The results showed that DMIE improved the PA from 95.28% to 95.51% and the MIoU from 90.09% to 90.50%, which proved the effectiveness of DMIE.
3.4. Comparison Test of CSWV Dataset
3.5. Generalization Experiment
4. Discussion
4.1. Advantages of the Proposed Method
4.2. Limitations and Future Research Directions
5. Summary
- Some contributions adopted in MAINet’s structure:
- −
- MAINet utilizes an encoder–decoder network with ResNet50 as the backbone, which mines semantic data at various levels.
- −
- The DMIE module combines the CNN and Transformer features to deeply mine rich feature information.
- −
- The DFE module compensates for the detailed semantic information that was lost during the encoder’s down-sampling process.
- −
- In the FIFU module, SFIF performs two-channel fusion. For information communication, CSAM enhances the deep spatial channel information, and MSBC enhances the peripheral information and feature information of the segmentation boundaries.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cohen, W.B.; Fiorella, M.; Gray, J.; Helmer, E.; Anderson, K. An efficient and accurate method for mapping forest clearcuts in the Pacific Northwest using Landsat imagery. Photogramm. Eng. Remote Sens. 1998, 64, 293–299. [Google Scholar]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Automated cloud, cloud shadow, and snow detection in multitemporal Landsat data: An algorithm designed specifically for monitoring land cover change. Remote Sens. Environ. 2014, 152, 217–234. [Google Scholar] [CrossRef]
- Chen, K.; Dai, X.; Xia, M.; Weng, L.; Hu, K.; Lin, H. MSFANet: Multi-Scale Strip Feature Attention Network for Cloud and Cloud Shadow Segmentation. Remote Sensing 2023, 15, 4853. [Google Scholar] [CrossRef]
- Campos, N.; Quesada-Román, A.; Granados-Bolaños, S. Mapping Mountain Landforms and Its Dynamics: Study Cases in Tropical Environments. Appl. Sci. 2022, 12, 10843. [Google Scholar] [CrossRef]
- Quesada-Román, A.; Umaña-Ortíz, J.; Zumbado-Solano, M.; Islam, A.; Abioui, M.; Zangmo Tefogoum, G.; Kariminejad, N.; Mutaqin, B.W.; Pupim, F. Geomorphological regional mapping for environmental planning in developing countries. Environ. Dev. 2023, 48, 100935. [Google Scholar] [CrossRef]
- Klein, A.G.; Hall, D.K.; Riggs, G.A. Improving snow cover mapping in forests through the use of a canopy reflectance model. Hydrol. Process. 1998, 12, 1723–1744. [Google Scholar] [CrossRef]
- Quesada-Román, A.; Peralta-Reyes, M. Geomorphological Mapping Global Trends and Applications. Geographies 2023, 3, 610–621. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0: Improved cloud and cloud shadow detection in Landsats 4–8 and Sentinel-2 imagery. Remote Sens. Environ. 2019, 231, 111205. [Google Scholar] [CrossRef]
- Gladkova, I.; Shahriar, F.; Grossberg, M.; Frey, R.A.; Menzel, W.P. Impact of the aqua MODIS Band 6 restoration on cloud/snow discrimination. J. Atmos. Ocean. Technol. 2013, 30, 2712–2719. [Google Scholar] [CrossRef]
- Haiyan, D.; Lingling, M.; Ziyang, L.; Lingli, T. Automatic identification of cloud and snow based on fractal dimension. Remote Sens. Technol. Appl. 2013, 28, 52–57. [Google Scholar]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Wang, J.; Li, W. Comparison of methods of snow cover mapping by analysing the solar spectrum of satellite remote sensing data in China. Int. J. Remote Sens. 2003, 24, 4129–4136. [Google Scholar] [CrossRef]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Hollstein, A.; Segl, K.; Guanter, L.; Brell, M.; Enesco, M. Ready-to-use methods for the detection of clouds, cirrus, snow, shadow, water and clear sky pixels in Sentinel-2 MSI images. Remote Sens. 2016, 8, 666. [Google Scholar] [CrossRef]
- Hughes, M.J.; Hayes, D.J. Automated detection of cloud and cloud shadow in single-date Landsat imagery using neural networks and spatial post-processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef]
- Sun, L.; Cao, X. Feature extraction based on combined textural features from panchromatic cloud and snow region. Electron. Design Eng. 2014, 22, 174–176. [Google Scholar]
- Ghasemian, N.; Akhoondzadeh, M. Introducing two Random Forest based methods for cloud detection in remote sensing images. Adv. Space Res. 2018, 62, 288–303. [Google Scholar] [CrossRef]
- Kang, X.; Gao, G.; Hao, Q.; Li, S. A coarse-to-fine method for cloud detection in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 110–114. [Google Scholar] [CrossRef]
- Chai, D.; Newsam, S.; Zhang, H.K.; Qiu, Y.; Huang, J. Cloud and cloud shadow detection in Landsat imagery based on deep convolutional neural networks. Remote Sens. Environ. 2019, 225, 307–316. [Google Scholar] [CrossRef]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Dai, X.; Chen, K.; Xia, M.; Weng, L.; Lin, H. LPMSNet: Location Pooling Multi-Scale Network for Cloud and Cloud Shadow Segmentation. Remote Sens. 2023, 15, 4005. [Google Scholar] [CrossRef]
- Ji, H.; Xia, M.; Zhang, D.; Lin, H. Multi-Supervised Feature Fusion Attention Network for Clouds and Shadows Detection. ISPRS Int. J. Geo-Inf. 2023, 12, 247. [Google Scholar] [CrossRef]
- Dai, X.; Xia, M.; Weng, L.; Hu, K.; Lin, H.; Qian, M. Multi-Scale Location Attention Network for Building and Water Segmentation of Remote Sensing Image. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5609519. [Google Scholar] [CrossRef]
- Lu, C.; Xia, M.; Qian, M.; Chen, B. Dual-Branch Network for Cloud and Cloud Shadow Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5410012. [Google Scholar] [CrossRef]
- Weng, L.; Pang, K.; Xia, M.; Lin, H.; Qian, M.; Zhu, C. Sgformer: A Local and Global Features Coupling Network for Semantic Segmentation of Land Cover. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 6812–6824. [Google Scholar] [CrossRef]
- Zhan, Y.; Wang, J.; Shi, J.; Cheng, G.; Yao, L.; Sun, W. Distinguishing cloud and snow in satellite images via deep convolutional network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1785–1789. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Xie, F.; Shi, M.; Shi, Z.; Yin, J.; Zhao, D. Multilevel cloud detection in remote sensing images based on deep learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3631–3640. [Google Scholar] [CrossRef]
- Zhang, G.; Gao, X.; Yang, Y.; Wang, M.; Ran, S. Controllably Deep Supervision and Multi-Scale Feature Fusion Network for Cloud and Snow Detection Based on Medium-and High-Resolution Imagery Dataset. Remote Sens. 2021, 13, 4805. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 1–26 July 2016; pp. 770–778. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image Transformer. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local features coupling global representations for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 367–376. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual Transformers: Token-based image representation and processing for computer vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable Transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Chen, B.; Xia, M.; Qian, M.; Huang, J. MANet: A multi-level aggregation network for semantic segmentation of high-resolution remote sensing images. Int. J. Remote Sens. 2022, 43, 5874–5894. [Google Scholar] [CrossRef]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based Attention Module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Dosovitskiy, A.; Springenberg, J.T.; Brox, T. Unsupervised feature learning by augmenting single images. arXiv 2013, arXiv:1312.5242. [Google Scholar]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep learning based cloud detection for medium and high resolution remote sensing images of different sensors. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AUX | PA (%) | MIoU (%) | Parameter (M) | Flops (G) |
|---|---|---|---|---|---|
| ResNet50 | ✓ | 95.51 | 90.50 | 13.81 | 60.66 |
| ResNet50 | ✗ | 94.76 | 88.91 | 13.35 | 60.43 |
| Method | PA (%) | MIoU (%) | Parameter (M) | Flops (G) |
|---|---|---|---|---|
| ResNet50 | 94.37 | 88.18 | 38.86 | 10.82 |
| ResNet50+SCA | 94.81 | 89.18 | 42.01 | 11.36 |
| ResNet50+SCA+SFIF | 95.01 | 89.52 | 42.01 | 11.37 |
| ResNet50+SCA+SFIF+MSBC | 95.10 | 89.71 | 43.08 | 12.34 |
| ResNet50+SCA+SFIF+MSBC+DFE | 95.28 | 90.09 | 44.13 | 12.75 |
| ResNet50+SCA+SFIF+MSBC+DFE+DMIE | 95.51 | 90.50 | 60.66 | 13.81 |
| Method | PA (%) | F1 (%) | MPA (%) | MIoU (%) |
|---|---|---|---|---|
| CvT | 89.71 | 88.11 | 88.36 | 78.84 |
| DeepLabV3Plus | 91.16 | 89.77 | 90.26 | 81.63 |
| HRNet | 91.49 | 90.38 | 90.51 | 82.46 |
| SegNet | 91.64 | 90.65 | 91.35 | 82.85 |
| OCRNet | 92.02 | 90.49 | 91.30 | 83.52 |
| CGNet | 91.98 | 91.08 | 91.47 | 83.67 |
| DABNet | 91.97 | 91.15 | 91.40 | 83.68 |
| FCN8s | 91.89 | 91.14 | 91.68 | 83.74 |
| ACFNet | 92.34 | 91.42 | 91.73 | 84.21 |
| PSPNet | 92.51 | 91.70 | 91.98 | 84.71 |
| PAN | 92.66 | 91.91 | 92.37 | 85.05 |
| DFN | 93.23 | 92.53 | 92.10 | 86.22 |
| CSDNet | 93.78 | 93.10 | 93.71 | 87.08 |
| UNet | 93.94 | 93.45 | 94.31 | 87.60 |
| MAINet | 94.53 | 94.01 | 94.35 | 88.71 |
| PAN † | 93.83 | 93.27 | 93.77 | 87.39 |
| FCN8s † | 94.11 | 93.56 | 93.00 | 87.83 |
| PSPNet † | 94.44 | 93.95 | 93.88 | 88.60 |
| MAINet † | 95.51 | 94.99 | 95.21 | 90.50 |
| Method | PA (%) | F1 (%) | MPA (%) | MIoU (%) |
|---|---|---|---|---|
| CvT | 93.41 | 92.18 | 93.26 | 87.36 |
| CGNet | 93.98 | 93.03 | 94.19 | 88.45 |
| FCN8s | 94.21 | 93.11 | 94.04 | 88.80 |
| HRNet | 94.30 | 93.20 | 94.11 | 88.95 |
| UNet | 94.34 | 93.36 | 94.39 | 89.07 |
| PAN | 94.39 | 93.35 | 94.30 | 89.14 |
| CSDNet | 94.39 | 93.45 | 94.51 | 89.17 |
| DABNet | 94.53 | 93.58 | 94.55 | 89.42 |
| SegNet | 94.58 | 93.59 | 94.51 | 89.50 |
| PSPNet | 94.59 | 93.65 | 94.62 | 89.53 |
| DFN | 94.64 | 93.73 | 94.74 | 89.63 |
| DeepLabV3Plus | 94.84 | 93.97 | 94.94 | 89.99 |
| ACFNet | 94.88 | 94.02 | 95.00 | 90.07 |
| OCRNet | 95.13 | 94.20 | 94.97 | 90.49 |
| MAINet | 95.34 | 94.54 | 95.42 | 90.91 |
| FCN8s † | 94.73 | 93.80 | 94.74 | 89.77 |
| PSPNet † | 94.90 | 93.97 | 94.86 | 90.08 |
| PAN † | 95.22 | 94.40 | 95.30 | 90.69 |
| MAINet † | 95.60 | 94.82 | 95.64 | 91.39 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, L.; Xia, M.; Lin, H.; Hu, K. Multi-Level Attention Interactive Network for Cloud and Snow Detection Segmentation. Remote Sens. 2024, 16, 112. https://doi.org/10.3390/rs16010112
Ding L, Xia M, Lin H, Hu K. Multi-Level Attention Interactive Network for Cloud and Snow Detection Segmentation. Remote Sensing. 2024; 16(1):112. https://doi.org/10.3390/rs16010112
Chicago/Turabian StyleDing, Li, Min Xia, Haifeng Lin, and Kai Hu. 2024. "Multi-Level Attention Interactive Network for Cloud and Snow Detection Segmentation" Remote Sensing 16, no. 1: 112. https://doi.org/10.3390/rs16010112
APA StyleDing, L., Xia, M., Lin, H., & Hu, K. (2024). Multi-Level Attention Interactive Network for Cloud and Snow Detection Segmentation. Remote Sensing, 16(1), 112. https://doi.org/10.3390/rs16010112