
Compensated Attention Feature Fusion and Hierarchical Multiplication Decoder Network for RGB-D Salient Object Detection


Abstract
1. Introduction
- We propose a hierarchical multiplication decoder to effectively suppress background distractors and enhance the salient object regions, based only on a simple multiplication operation in a hierarchical manner.
- To fully capture the depth cues when the object information is not salient in depth maps, we introduce an RGB Compensated Depth Attention module, which additionally introduces RGB to enhance the depth channel attention to highlight objects.
- Due to the advantages of the proposed CAF-HMNet, it pushes the performance of RGB-D SOD to a new level, achieving satisfactory performance on five public datasets.
2. Materials and Methods
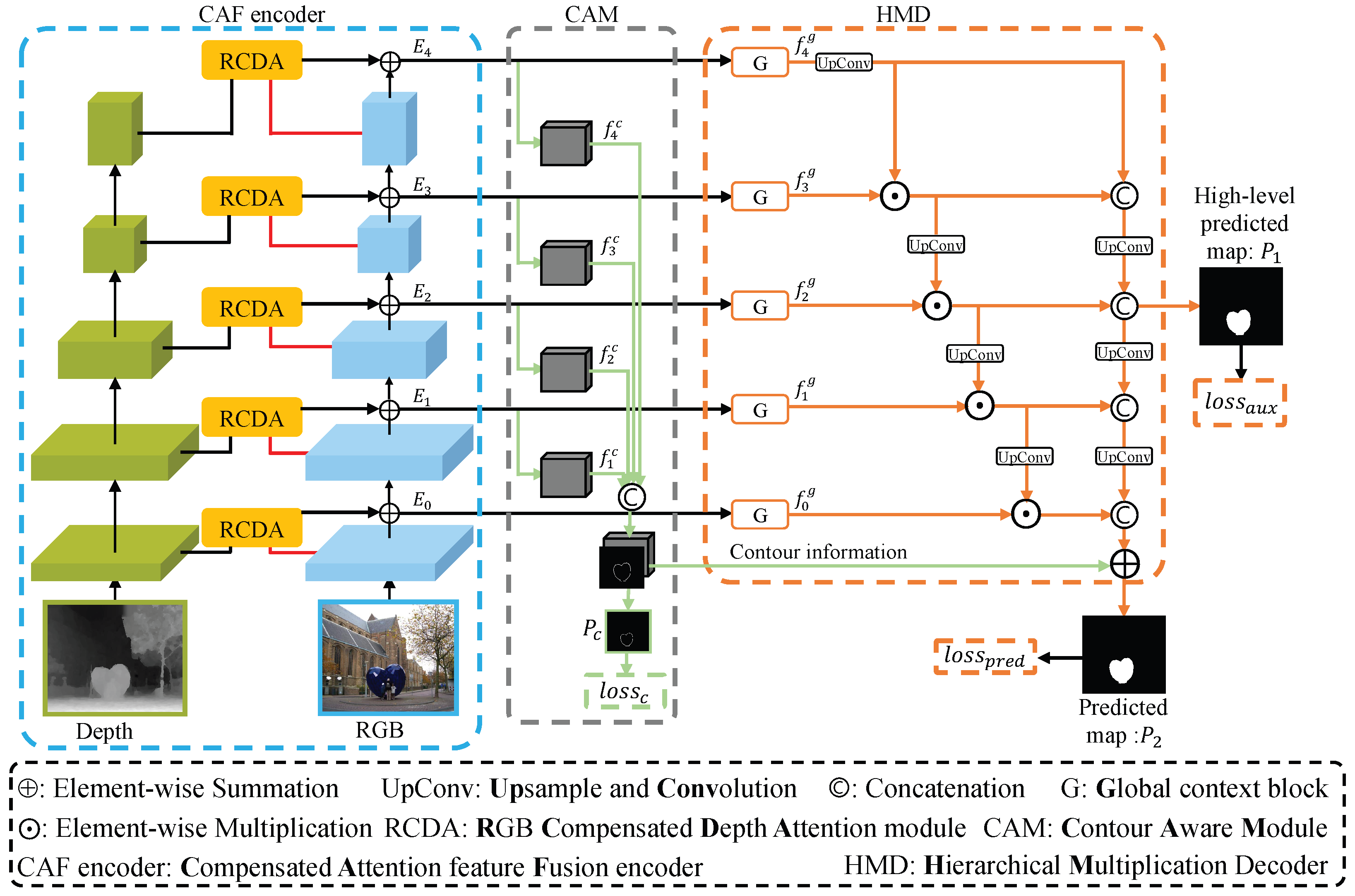
2.1. Overview
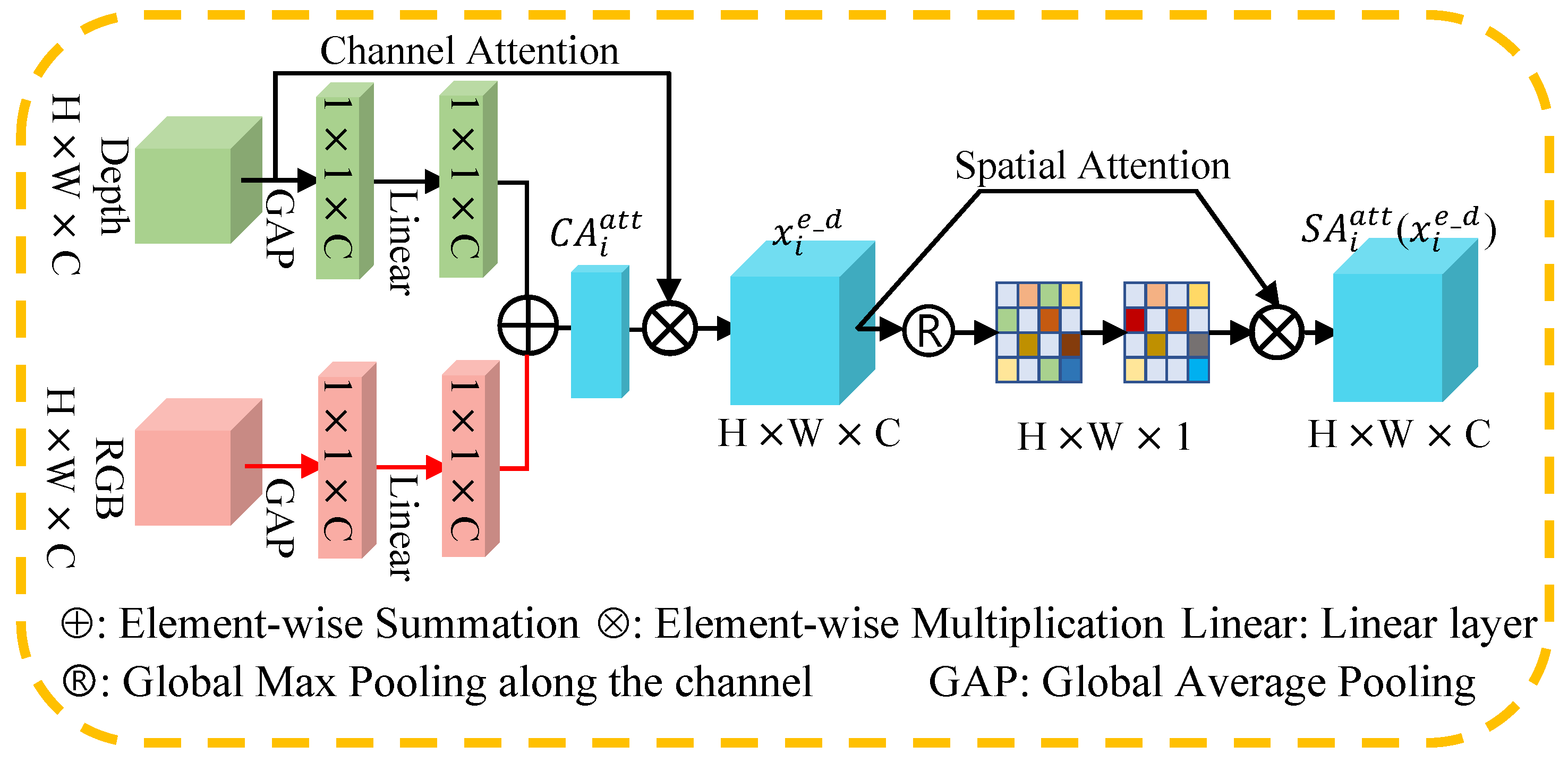
2.2. RGB Compensated Depth Attention Module
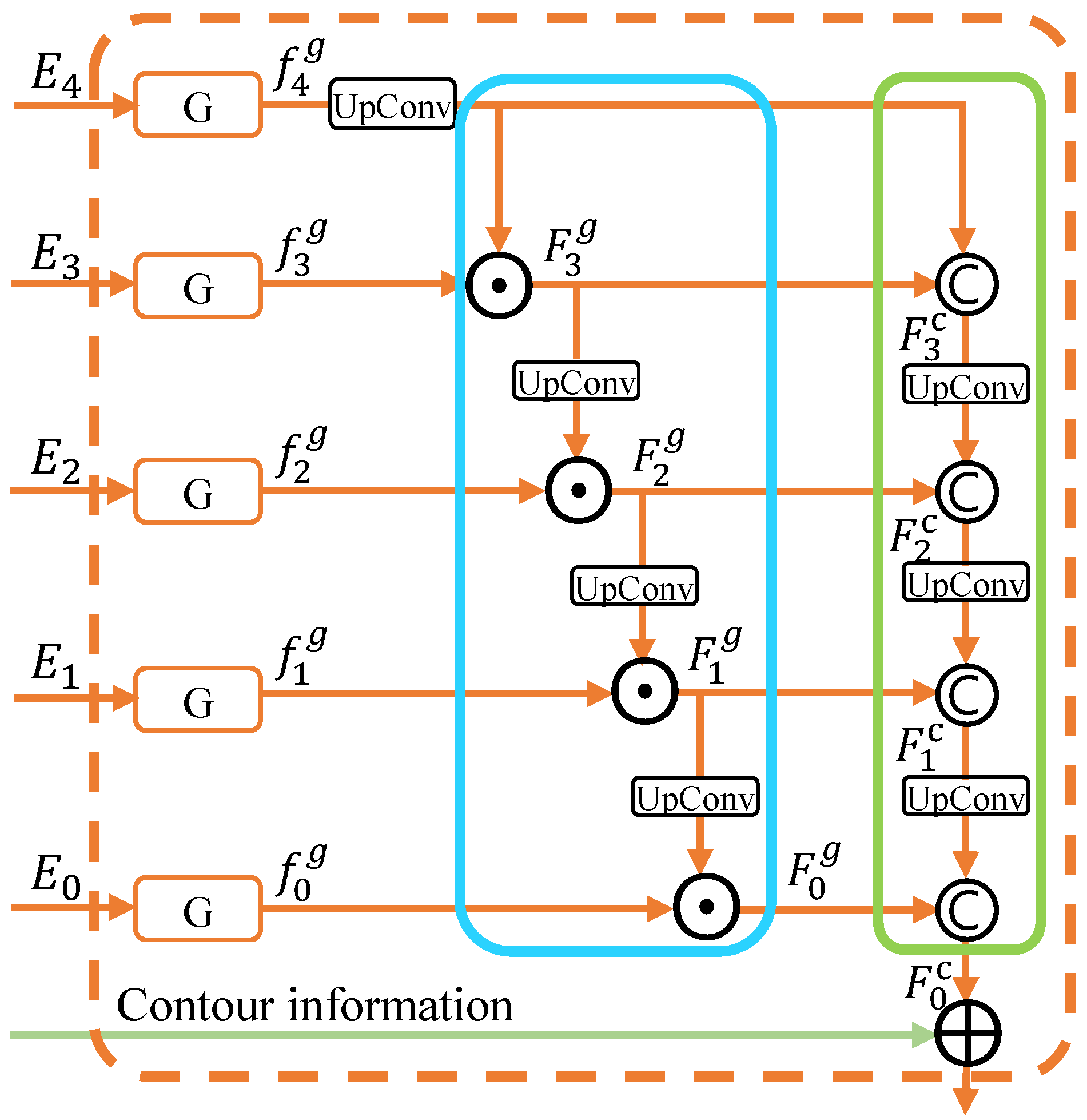
2.3. Hierarchical Multiplication Decoder
- Firstly, refine by with element-wise multiplication to obtain . Concatenate and to obtain .
- Secondly, refine by with element-wise multiplication to obtain . Concatenate and to obtain .
- Thirdly, refine by with element-wise multiplication to obtain . Concatenate and to obtain .
- Finally, refine by with element-wise multiplication to obtain . Concatenate and to obtain , as the final output of HMD.
2.4. Loss Function
3. Results
3.1. Datasets
3.2. Evaluation Metrics
3.3. Implementation Details
3.4. Comparison with State-of-the-Art Methods
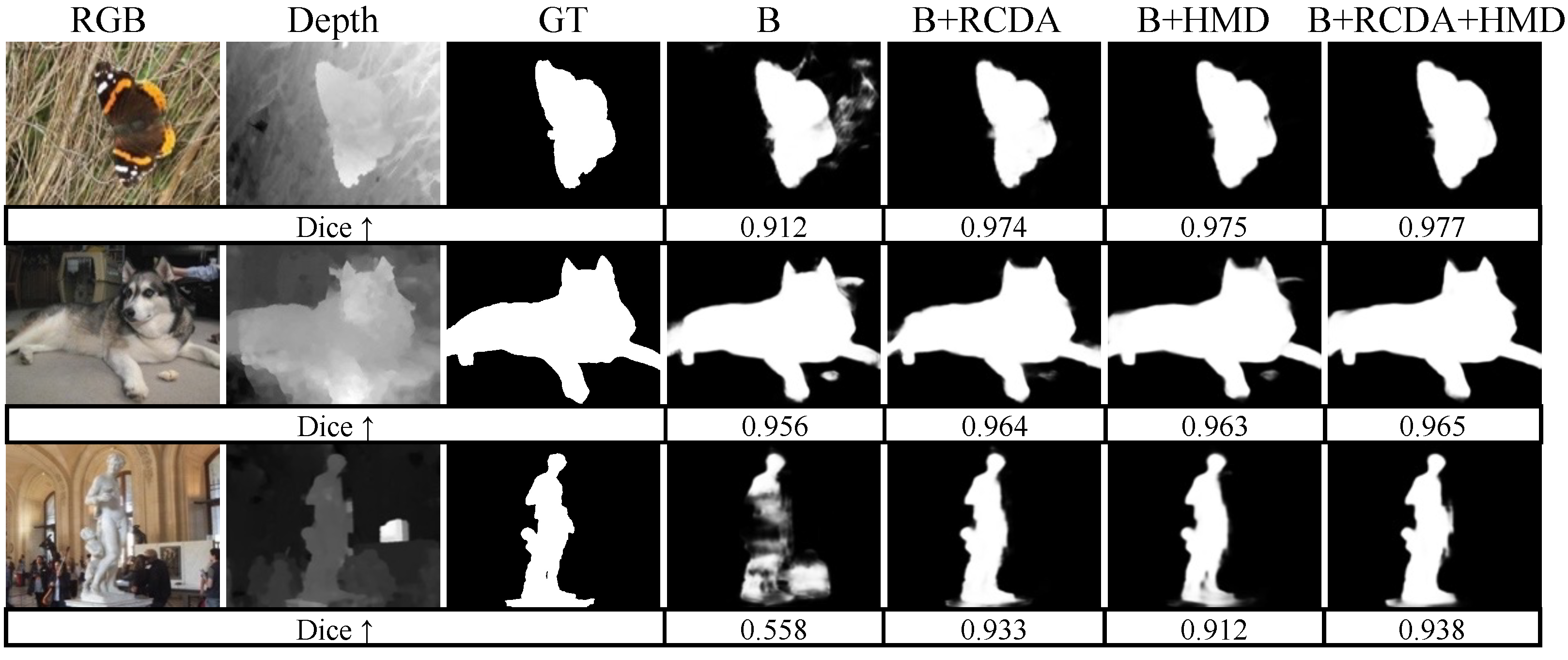
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Borji, A.; Cheng, M.M.; Hou, Q.; Jiang, H.; Li, J. Salient object detection: A survey. Comput. Vis. Media 2019, 5, 117–150. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Xu, D. Learning rotation-invariant and fisher discriminative convolutional neural networks for object detection. IEEE Trans. Image Process. 2018, 28, 265–278. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Shi, M.; Tao, D.; Xu, C. Database saliency for fast image retrieval. IEEE Trans. Multimed. 2015, 17, 359–369. [Google Scholar] [CrossRef]
- Jia, X.; Lu, H.; Yang, M.H. Visual tracking via coarse and fine structural local sparse appearance models. IEEE Trans. Image Process. 2016, 25, 4555–4564. [Google Scholar] [CrossRef]
- Chen, F.; Liu, H.; Zeng, Z.; Zhou, X.; Tan, X. BES-Net: Boundary enhancing semantic context network for high-resolution image semantic segmentation. Remote Sens. 2022, 14, 1638. [Google Scholar] [CrossRef]
- Zhang, Q.; Cong, R.; Li, C.; Cheng, M.M.; Fang, Y.; Cao, X.; Zhao, Y.; Kwong, S. Dense attention fluid network for salient object detection in optical remote sensing images. IEEE Trans. Image Process. 2020, 30, 1305–1317. [Google Scholar] [CrossRef]
- Zhao, K.; Han, Q.; Zhang, C.B.; Xu, J.; Cheng, M.M. Deep hough transform for semantic line detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4793–4806. [Google Scholar] [CrossRef]
- Zhu, C.; Li, G.; Wang, W.; Wang, R. An innovative salient object detection using center-dark channel prior. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1509–1515. [Google Scholar]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 569–582. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, J.X.; Liu, J.J.; Fan, D.P.; Cao, Y.; Yang, J.; Cheng, M.M. EGNet: Edge guidance network for salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Repulic of Korea, 27 October–2 November 2019; pp. 8779–8788. [Google Scholar]
- Liu, Z.; Zhu, Z.; Zheng, S.; Liu, Y.; Zhou, J.; Zhao, Y. Margin preserving self-paced contrastive learning towards domain adaptation for medical image segmentation. IEEE J. Biomed. Health Inform. 2022, 26, 638–647. [Google Scholar] [CrossRef]
- Bateson, M.; Kervadec, H.; Dolz, J.; Lombaert, H.; Ayed, I.B. Source-free domain adaptation for image segmentation. Med Image Anal. 2022, 82, 102617. [Google Scholar] [CrossRef]
- Stan, S.; Rostami, M. Domain Adaptation for the Segmentation of Confidential Medical Images. arXiv 2021, arXiv:2101.00522. [Google Scholar]
- Yao, K.; Su, Z.; Huang, K.; Yang, X.; Sun, J.; Hussain, A.; Coenen, F. A novel 3D unsupervised domain adaptation framework for cross-modality medical image segmentation. IEEE J. Biomed. Health Inform. 2022, 26, 4976–4986. [Google Scholar] [CrossRef]
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Multispectral fusion for object detection with cyclic fuse-and-refine blocks. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 276–280. [Google Scholar]
- Cong, R.; Lei, J.; Fu, H.; Huang, Q.; Cao, X.; Ling, N. HSCS: Hierarchical sparsity based co-saliency detection for RGBD images. IEEE Trans. Multimed. 2018, 21, 1660–1671. [Google Scholar] [CrossRef]
- Fu, K.; Fan, D.P.; Ji, G.P.; Zhao, Q. JL-DCF: Joint learning and densely-cooperative fusion framework for RGB-D salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3052–3062. [Google Scholar]
- Liu, Z.; Shi, S.; Duan, Q.; Zhang, W.; Zhao, P. Salient object detection for RGB-D image by single stream recurrent convolution neural network. Neurocomputing 2019, 363, 46–57. [Google Scholar] [CrossRef]
- Fan, X.; Liu, Z.; Sun, G. Salient region detection for stereoscopic images. In Proceedings of the 2014 19th International Conference on Digital Signal Processing, Hong Kong, China, 20–23 August 2014; pp. 454–458. [Google Scholar]
- Wang, N.; Gong, X. Adaptive fusion for RGB-D salient object detection. IEEE Access 2019, 7, 55277–55284. [Google Scholar] [CrossRef]
- Chen, Z.; Cong, R.; Xu, Q.; Huang, Q. DPANet: Depth potentiality-aware gated attention network for RGB-D salient object detection. IEEE Trans. Image Process. 2020, 30, 7012–7024. [Google Scholar] [CrossRef]
- Li, C.; Cong, R.; Kwong, S.; Hou, J.; Fu, H.; Zhu, G.; Zhang, D.; Huang, Q. ASIF-Net: Attention steered interweave fusion network for RGB-D salient object detection. IEEE Trans. Cybern. 2020, 51, 88–100. [Google Scholar] [CrossRef]
- Ju, R.; Ge, L.; Geng, W.; Ren, T.; Wu, G. Depth saliency based on anisotropic center-surround difference. In Proceedings of the 2014 IEEE international conference on image processing (ICIP), Paris, France, 27–30 October 2014; pp. 1115–1119. [Google Scholar]
- Fan, D.P.; Lin, Z.; Zhang, Z.; Zhu, M.; Cheng, M.M. Rethinking RGB-D salient object detection: Models, data sets, and large-scale benchmarks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2075–2089. [Google Scholar] [CrossRef]
- Zhang, M.; Ren, W.; Piao, Y.; Rong, Z.; Lu, H. Select, supplement and focus for RGB-D saliency detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3472–3481. [Google Scholar]
- Chen, Q.; Fu, K.; Liu, Z.; Chen, G.; Du, H.; Qiu, B.; Shao, L. EF-Net: A novel enhancement and fusion network for RGB-D saliency detection. Pattern Recognit. 2021, 112, 107740. [Google Scholar] [CrossRef]
- Pang, Y.; Zhang, L.; Zhao, X.; Lu, H. Hierarchical dynamic filtering network for rgb-d salient object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 235–252. [Google Scholar]
- Chen, C.; Wei, J.; Peng, C.; Qin, H. Depth-quality-aware salient object detection. IEEE Trans. Image Process. 2021, 30, 2350–2363. [Google Scholar] [CrossRef]
- Zhang, W.; Jiang, Y.; Fu, K.; Zhao, Q. BTS-Net: Bi-directional transfer-and-selection network for RGB-D salient object detection. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Li, G.; Liu, Z.; Chen, M.; Bai, Z.; Lin, W.; Ling, H. Hierarchical alternate interaction network for RGB-D salient object detection. IEEE Trans. Image Process. 2021, 30, 3528–3542. [Google Scholar] [CrossRef] [PubMed]
- Zhai, Y.; Fan, D.P.; Yang, J.; Borji, A.; Shao, L.; Han, J.; Wang, L. Bifurcated backbone strategy for RGB-D salient object detection. IEEE Trans. Image Process. 2021, 30, 8727–8742. [Google Scholar] [CrossRef] [PubMed]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H. Deeply supervised salient object detection with short connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3203–3212. [Google Scholar]
- Chen, H.; Li, Y. Progressively complementarity-aware fusion network for RGB-D salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3051–3060. [Google Scholar]
- Chen, H.; Li, Y. Three-stream attention-aware network for RGB-D salient object detection. IEEE Trans. Image Process. 2019, 28, 2825–2835. [Google Scholar] [CrossRef] [PubMed]
- Piao, Y.; Ji, W.; Li, J.; Zhang, M.; Lu, H. Depth-induced multi-scale recurrent attention network for saliency detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Repulic of Korea, 27 October–2 November 2019; pp. 7254–7263. [Google Scholar]
- Liu, Z.; Wang, Y.; Tu, Z.; Xiao, Y.; Tang, B. TriTransNet: RGB-D salient object detection with a triplet transformer embedding network. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 4481–4490. [Google Scholar]
- Li, G.; Liu, Z.; Ling, H. ICNet: Information conversion network for RGB-D based salient object detection. IEEE Trans. Image Process. 2020, 29, 4873–4884. [Google Scholar] [CrossRef] [PubMed]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Cong, R.; Lin, Q.; Zhang, C.; Li, C.; Cao, X.; Huang, Q.; Zhao, Y. CIR-Net: Cross-modality interaction and refinement for RGB-D salient object detection. IEEE Trans. Image Process. 2022, 31, 6800–6815. [Google Scholar] [CrossRef]
- Wu, Y.H.; Liu, Y.; Xu, J.; Bian, J.W.; Gu, Y.C.; Cheng, M.M. MobileSal: Extremely efficient RGB-D salient object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 10261–10269. [Google Scholar] [CrossRef]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3907–3916. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE/CVF Conference on computer VISION and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Wang, T.; Zhang, L.; Wang, S.; Lu, H.; Yang, G.; Ruan, X.; Borji, A. Detect globally, refine locally: A novel approach to saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3127–3135. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Zhao, Z.; Xia, C.; Xie, C.; Li, J. Complementary trilateral decoder for fast and accurate salient object detection. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 4967–4975. [Google Scholar]
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Peng, H.; Li, B.; Xiong, W.; Hu, W.; Ji, R. RGBD salient object detection: A benchmark and algorithms. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 92–109. [Google Scholar]
- Niu, Y.; Geng, Y.; Li, X.; Liu, F. Leveraging stereopsis for saliency analysis. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 454–461. [Google Scholar]
- Cheng, Y.; Fu, H.; Wei, X.; Xiao, J.; Cao, X. Depth enhanced saliency detection method. In Proceedings of the International Conference on Internet Multimedia Computing and Service, Xiamen, China, 10–12 July 2014; pp. 23–27. [Google Scholar]
- Ji, W.; Yan, G.; Li, J.; Piao, Y.; Yao, S.; Zhang, M.; Cheng, L.; Lu, H. Dmra: Depth-induced multi-scale recurrent attention network for rgb-d saliency detection. IEEE Trans. Image Process. 2022, 31, 2321–2336. [Google Scholar] [CrossRef]
- Zhao, J.X.; Cao, Y.; Fan, D.P.; Cheng, M.M.; Li, X.Y.; Zhang, L. Contrast prior and fluid pyramid integration for RGBD salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3927–3936. [Google Scholar]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment Measure for Binary Foreground Map Evaluation. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the ICLR (Poster), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Wang, X.; Li, S.; Chen, C.; Fang, Y.; Hao, A.; Qin, H. Data-level recombination and lightweight fusion scheme for RGB-D salient object detection. IEEE Trans. Image Process. 2020, 30, 458–471. [Google Scholar] [CrossRef]
- Ji, W.; Li, J.; Zhang, M.; Piao, Y.; Lu, H. Accurate RGB-D salient object detection via collaborative learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 52–69. [Google Scholar]
- Chen, H.; Deng, Y.; Li, Y.; Hung, T.Y.; Lin, G. RGBD salient object detection via disentangled cross-modal fusion. IEEE Trans. Image Process. 2020, 29, 8407–8416. [Google Scholar] [CrossRef]
- Piao, Y.; Rong, Z.; Zhang, M.; Ren, W.; Lu, H. A2dele: Adaptive and attentive depth distiller for efficient RGB-D salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9060–9069. [Google Scholar]
- Zhao, X.; Zhang, L.; Pang, Y.; Lu, H.; Zhang, L. A single stream network for robust and real-time RGB-D salient object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 646–662. [Google Scholar]
- Jin, W.D.; Xu, J.; Han, Q.; Zhang, Y.; Cheng, M.M. CDNet: Complementary depth network for RGB-D salient object detection. IEEE Trans. Image Process. 2021, 30, 3376–3390. [Google Scholar] [CrossRef]
- Sun, P.; Zhang, W.; Wang, H.; Li, S.; Li, X. Deep RGB-D saliency detection with depth-sensitive attention and automatic multi-modal fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1407–1417. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
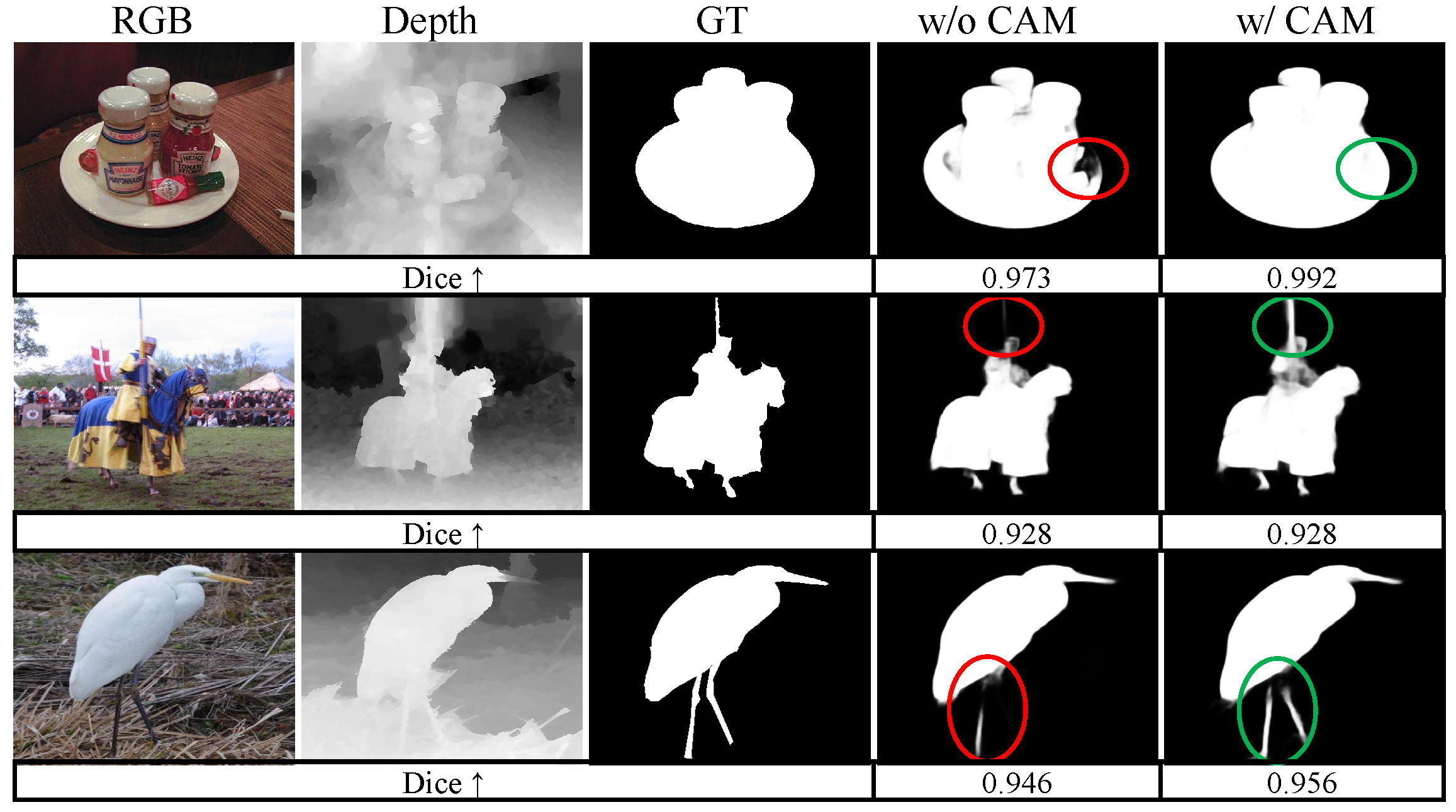{kind=link}
{kind=link}
| Datasets | Metric | TANet TIP19 [35] | DMRA ICCV19 [36] | SSF CVPR20 [26] | DRLF TIP20 [65] | CoNet ECCV20 [66] | DCMF TIP20 [67] | A2dele CVPR20 [68] | D3Net TNNLS20 [25] | ICNet TIP20 [38] | DANet ECCV20 [69] | BBSNet ECCV20 [32] | CDNet TIP21 [70] | DSA2F CVPR21 [71] | Ours |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NJU2K | 0.878 | 0.886 | 0.899 | 0.886 | 0.894 | 0.889 | 0.869 | 0.900 | 0.894 | 0.899 | 0.917 | 0.885 | 0.904 | 0.922 | |
| 0.874 | 0.886 | 0.886 | 0.883 | 0.872 | 0.859 | 0.874 | 0.900 | 0.868 | 0.871 | 0.899 | 0.866 | 0.898 | 0.923 | ||
| 0.925 | 0.927 | 0.913 | 0.926 | 0.912 | 0.897 | 0.897 | 0.950 | 0.905 | 0.908 | 0.917 | 0.911 | 0.922 | 0.953 | ||
| 0.060 | 0.051 | 0.043 | 0.055 | 0.047 | 0.052 | 0.051 | 0.041 | 0.052 | 0.045 | 0.037 | 0.048 | 0.039 | 0.034 | ||
| NLPR | 0.886 | 0.899 | 0.914 | 0.903 | 0.907 | 0.900 | 0.896 | 0.912 | 0.923 | 0.920 | 0.924 | 0.902 | 0.918 | 0.937 | |
| 0.863 | 0.879 | 0.875 | 0.880 | 0.848 | 0.839 | 0.878 | 0.897 | 0.870 | 0.875 | 0.880 | 0.848 | 0.892 | 0.929 | ||
| 0.941 | 0.947 | 0.949 | 0.939 | 0.936 | 0.933 | 0.945 | 0.953 | 0.944 | 0.951 | 0.954 | 0.935 | 0.950 | 0.969 | ||
| 0.041 | 0.031 | 0.026 | 0.032 | 0.031 | 0.035 | 0.028 | 0.030 | 0.028 | 0.027 | 0.025 | 0.032 | 0.024 | 0.020 | ||
| STERE | 0.871 | 0.835 | 0.887 | 0.888 | 0.908 | 0.883 | 0.878 | 0.899 | 0.903 | 0.901 | 0.901 | 0.896 | 0.897 | 0.909 | |
| 0.861 | 0.847 | 0.867 | 0.878 | 0.885 | 0.841 | 0.874 | 0.891 | 0.865 | 0.868 | 0.876 | 0.873 | 0.893 | 0.906 | ||
| 0.923 | 0.911 | 0.921 | 0.929 | 0.923 | 0.904 | 0.915 | 0.938 | 0.915 | 0.921 | 0.920 | 0.922 | 0.927 | 0.946 | ||
| 0.060 | 0.066 | 0.046 | 0.050 | 0.041 | 0.054 | 0.044 | 0.046 | 0.045 | 0.043 | 0.043 | 0.042 | 0.039 | 0.039 | ||
| DES | 0.858 | 0.900 | 0.905 | 0.895 | 0.910 | 0.877 | 0.885 | 0.898 | 0.920 | 0.924 | 0.918 | 0.875 | 0.916 | 0.924 | |
| 0.827 | 0.888 | 0.876 | 0.869 | 0.861 | 0.820 | 0.865 | 0.885 | 0.889 | 0.899 | 0.871 | 0.839 | 0.901 | 0.920 | ||
| 0.910 | 0.943 | 0.948 | 0.940 | 0.945 | 0.923 | 0.922 | 0.946 | 0.959 | 0.968 | 0.951 | 0.921 | 0.955 | 0.961 | ||
| 0.046 | 0.030 | 0.025 | 0.030 | 0.027 | 0.040 | 0.028 | 0.031 | 0.027 | 0.023 | 0.025 | 0.034 | 0.023 | 0.022 | ||
| SIP | 0.835 | 0.806 | 0.868 | 0.850 | 0.858 | 0.859 | 0.826 | 0.860 | 0.854 | 0.875 | 0.879 | 0.823 | 0.862 | 0.883 | |
| 0.830 | 0.821 | 0.851 | 0.813 | 0.842 | 0.819 | 0.825 | 0.861 | 0.836 | 0.855 | 0.883 | 0.805 | 0.865 | 0.892 | ||
| 0.895 | 0.875 | 0.911 | 0.891 | 0.909 | 0.898 | 0.892 | 0.909 | 0.899 | 0.914 | 0.922 | 0.880 | 0.908 | 0.926 | ||
| 0.075 | 0.085 | 0.056 | 0.071 | 0.063 | 0.068 | 0.070 | 0.063 | 0.069 | 0.054 | 0.055 | 0.076 | 0.057 | 0.050 |
| Models | NJU2K | NLPR | STERE | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No. 1 | 0.922 | 0.923 | 0.953 | 0.034 | 0.937 | 0.929 | 0.969 | 0.020 | 0.909 | 0.906 | 0.946 | 0.039 |
| No. 2 | 0.922 | 0.924 | 0.954 | 0.033 | 0.930 | 0.917 | 0.962 | 0.023 | 0.908 | 0.903 | 0.943 | 0.040 |
| No. 3 | 0.922 | 0.921 | 0.952 | 0.034 | 0.930 | 0.918 | 0.965 | 0.022 | 0.905 | 0.900 | 0.940 | 0.041 |
| No. 4 | 0.924 | 0.925 | 0.954 | 0.033 | 0.932 | 0.923 | 0.967 | 0.022 | 0.904 | 0.897 | 0.938 | 0.042 |
| AP | 0.923 | 0.923 | 0.953 | 0.034 | 0.932 | 0.922 | 0.966 | 0.022 | 0.907 | 0.904 | 0.942 | 0.041 |
| SD | 0.00087 | 0.00148 | 0.00083 | 0.00050 | 0.00286 | 0.00476 | 0.00259 | 0.00109 | 0.00206 | 0.00415 | 0.00303 | 0.00112 |
| Models | NJU2K | NLPR | STERE | SIP | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B | 0.911 | 0.908 | 0.943 | 0.038 | 0.924 | 0.910 | 0.955 | 0.026 | 0.891 | 0.885 | 0.933 | 0.048 | 0.867 | 0.870 | 0.907 | 0.062 |
| B + RCDA | 0.919 | 0.917 | 0.948 | 0.036 | 0.929 | 0.918 | 0.961 | 0.024 | 0.907 | 0.902 | 0.944 | 0.041 | 0.881 | 0.887 | 0.920 | 0.054 |
| B + HMD | 0.920 | 0.919 | 0.950 | 0.036 | 0.930 | 0.921 | 0.966 | 0.023 | 0.895 | 0.886 | 0.933 | 0.047 | 0.878 | 0.884 | 0.919 | 0.055 |
| B + RCDA + HMD | 0.920 | 0.922 | 0.950 | 0.035 | 0.931 | 0.921 | 0.962 | 0.024 | 0.907 | 0.901 | 0.942 | 0.041 | 0.884 | 0.889 | 0.924 | 0.052 |
| Models | NJU2K | NLPR | STERE | FLOPs (G) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RCDA | 0.922 | 0.923 | 0.953 | 0.034 | 0.937 | 0.929 | 0.969 | 0.020 | 0.909 | 0.906 | 0.946 | 0.039 | 43.14 |
| RCDA + MaxPooling | 0.922 | 0.924 | 0.953 | 0.034 | 0.930 | 0.917 | 0.960 | 0.024 | 0.906 | 0.902 | 0.943 | 0.040 | 43.15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, Z.; Liu, H.; Chen, F.; Tan, X. Compensated Attention Feature Fusion and Hierarchical Multiplication Decoder Network for RGB-D Salient Object Detection. Remote Sens. 2023, 15, 2393. https://doi.org/10.3390/rs15092393
Zeng Z, Liu H, Chen F, Tan X. Compensated Attention Feature Fusion and Hierarchical Multiplication Decoder Network for RGB-D Salient Object Detection. Remote Sensing. 2023; 15(9):2393. https://doi.org/10.3390/rs15092393
Chicago/Turabian StyleZeng, Zhihong, Haijun Liu, Fenglei Chen, and Xiaoheng Tan. 2023. "Compensated Attention Feature Fusion and Hierarchical Multiplication Decoder Network for RGB-D Salient Object Detection" Remote Sensing 15, no. 9: 2393. https://doi.org/10.3390/rs15092393
APA StyleZeng, Z., Liu, H., Chen, F., & Tan, X. (2023). Compensated Attention Feature Fusion and Hierarchical Multiplication Decoder Network for RGB-D Salient Object Detection. Remote Sensing, 15(9), 2393. https://doi.org/10.3390/rs15092393