
Remote Sensing Image Compression Based on the Multiple Prior Information


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- To capture the local redundancy as well as global redundancy, a new entropy model based on transformer-based prior and CNN-based prior is designed. The transformer-based prior is the main focus for capturing the global redundancy and the CNN-based prior is the main focus on the local redundancy. When fused, these two pieces of information priors can achieve a better compression performance than a single prior.
- Based on the transformer and the CNN-based transformer, a new compression algorithm for HRRSIs is designed. To reduce the gap between the training and testing, the proposed algorithm adopts a three-stage refined processing. The refined stage can help refine the entropy network as well as the decoder network, which can help us obtain a more accurate entropy model and better reconstructed images.
- The experiment is conducted on an HRRSI dataset, and the results show that the proposed algorithm obtains a better compression than JPEG and JPEG2000 and other leaned image compression algorithms.
2. Formulation of Lossy Image Compression
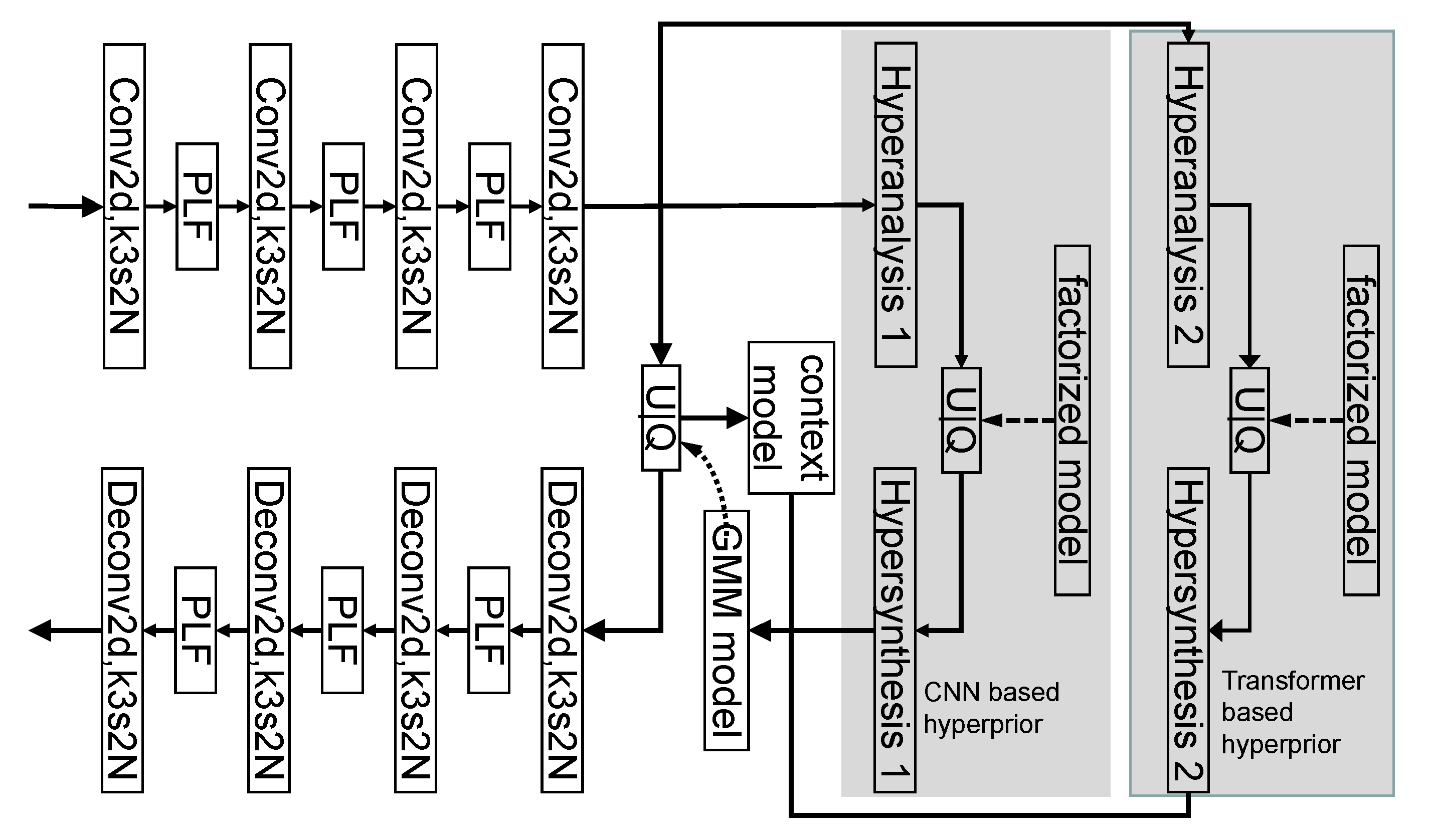
3. Proposed Algorithm
3.1. Motivation
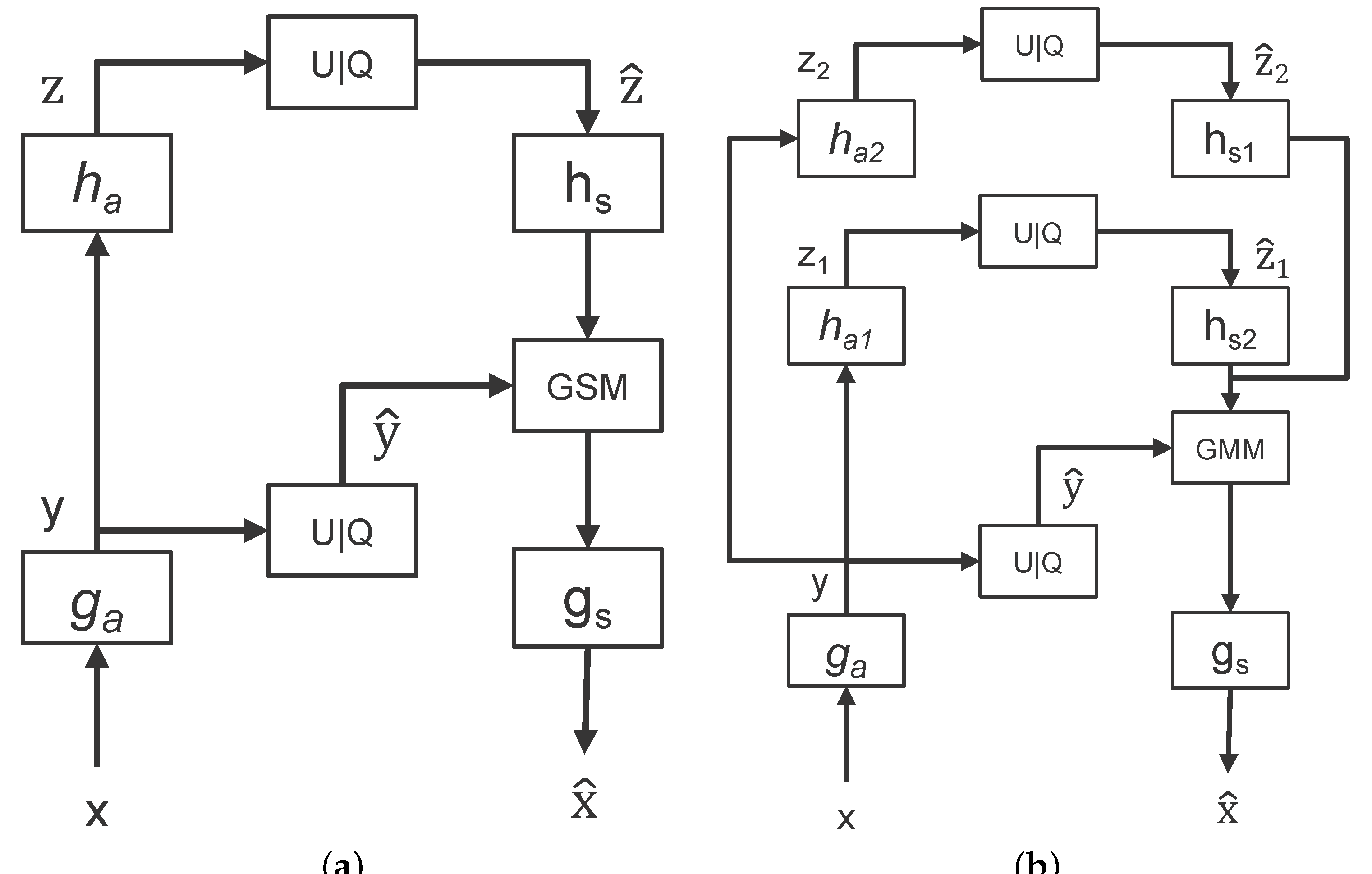
- Ref. [46] only adopts a CNN network to explore the hyperprior information, but the proposed compression scheme adopts two branches to explore local and global context information. The two branches include a transformer-based and a CNN-based network.
- In the entropy model construction, Ref. [46] uses the GSM, while the proposed algorithm uses the Gaussian mixture model (GMM) instead.
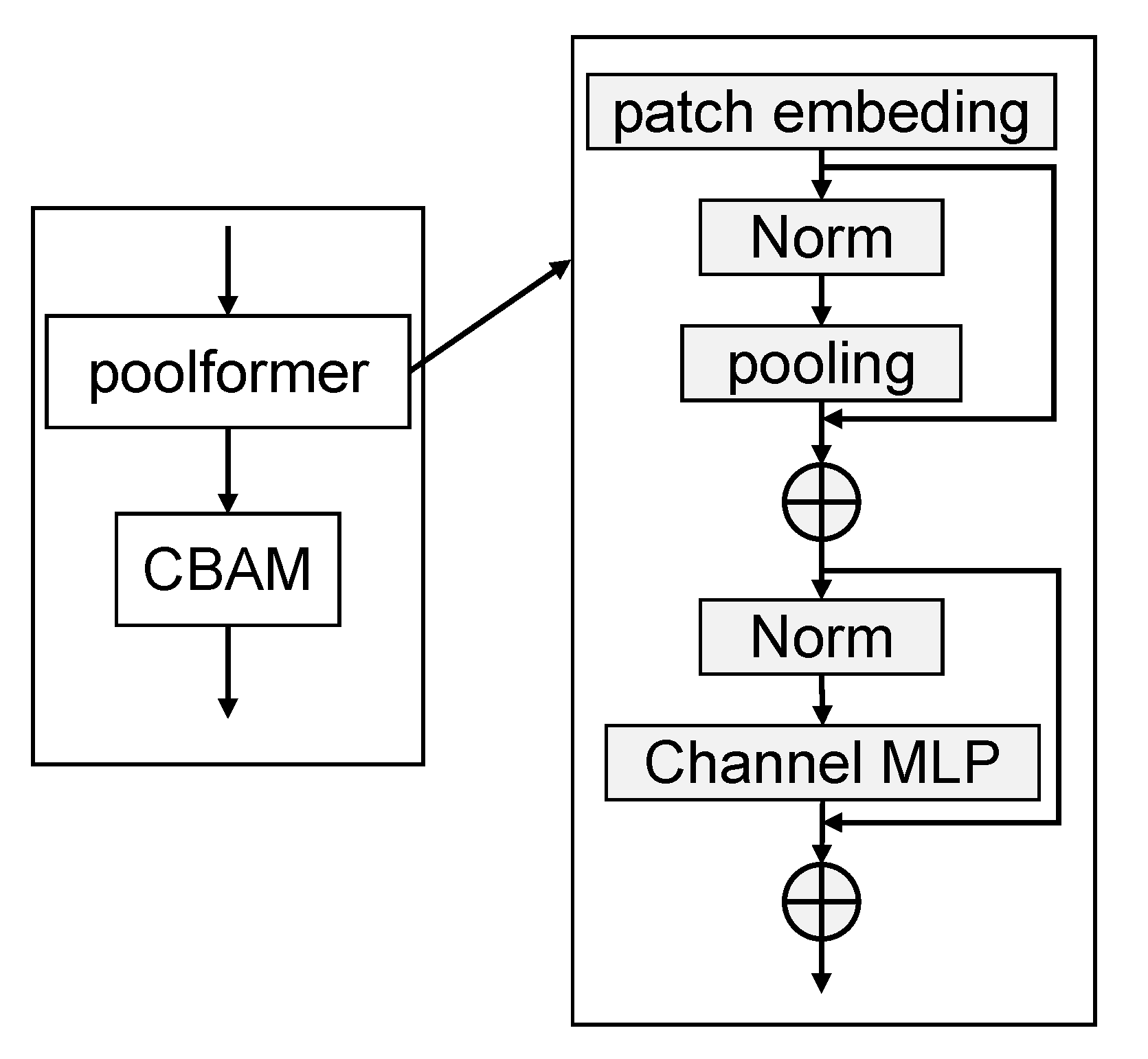
- Additionally, the GDN layers are replaced by a layer of a transformer-based layer, poolformer, in the proposed algorithm.
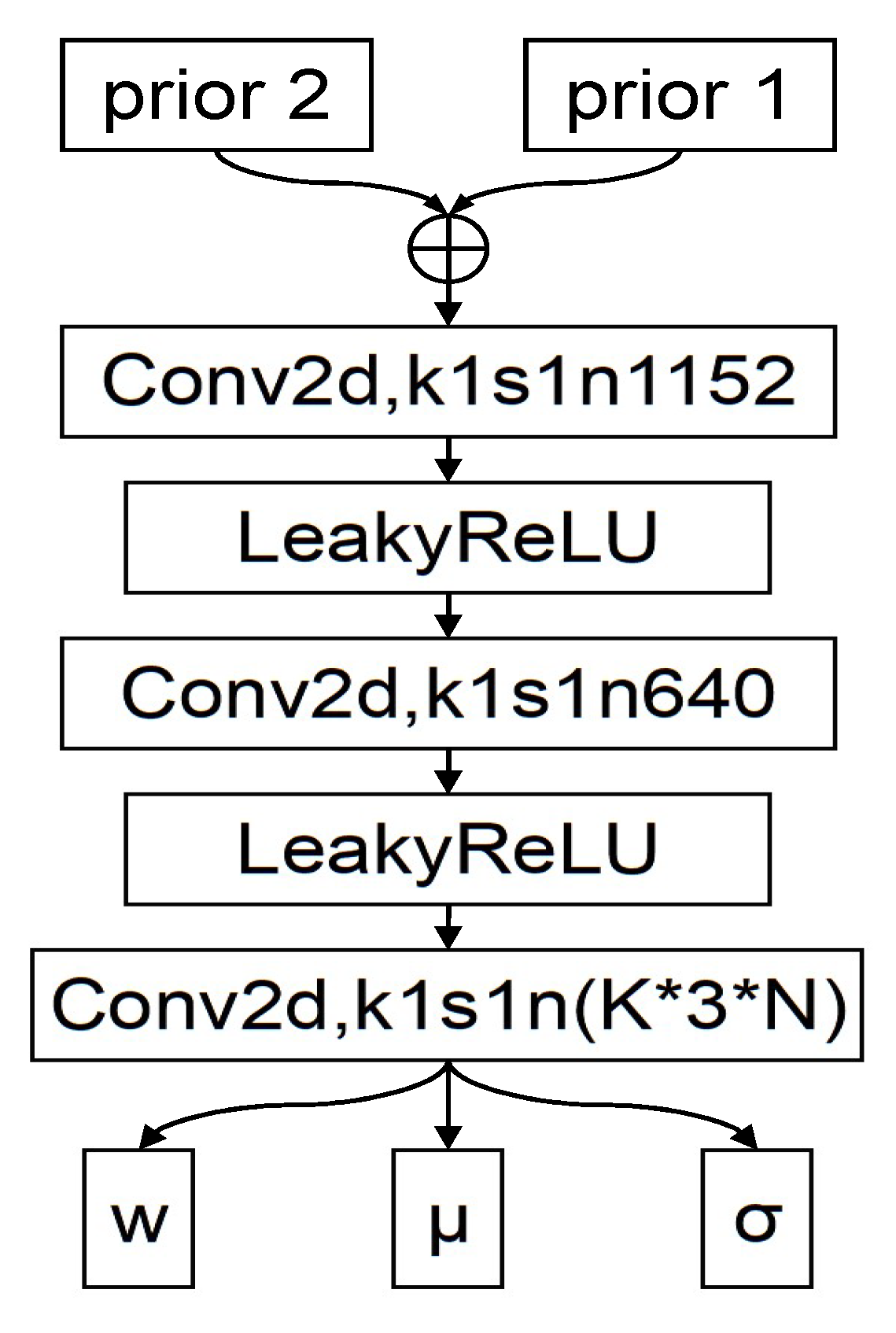
3.2. Entropy Model
3.3. Training Strategy
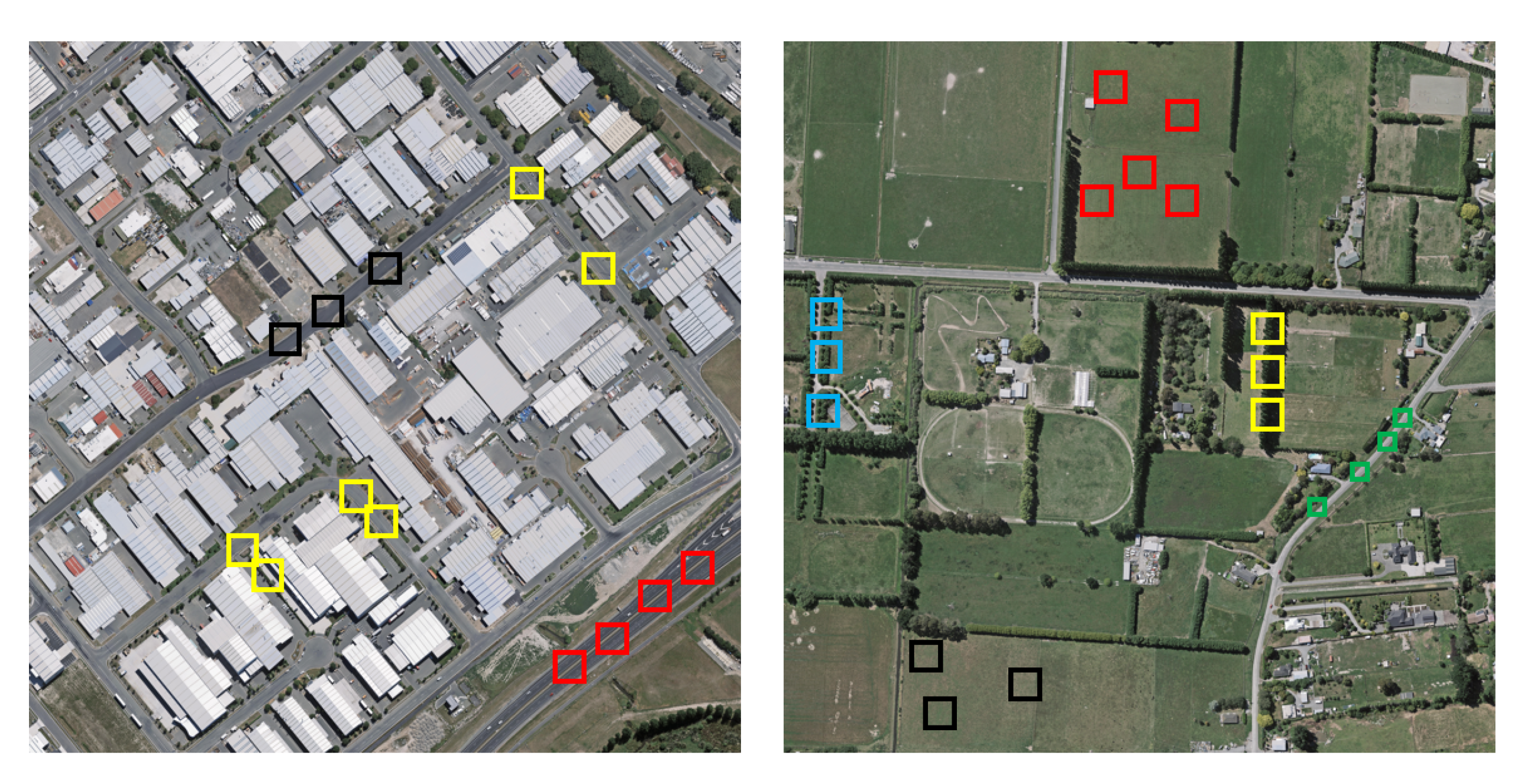
4. Experiments and Results
4.1. Dataset and Training Setting
4.2. Evaluation Metrics
4.3. Comparison Algorithms
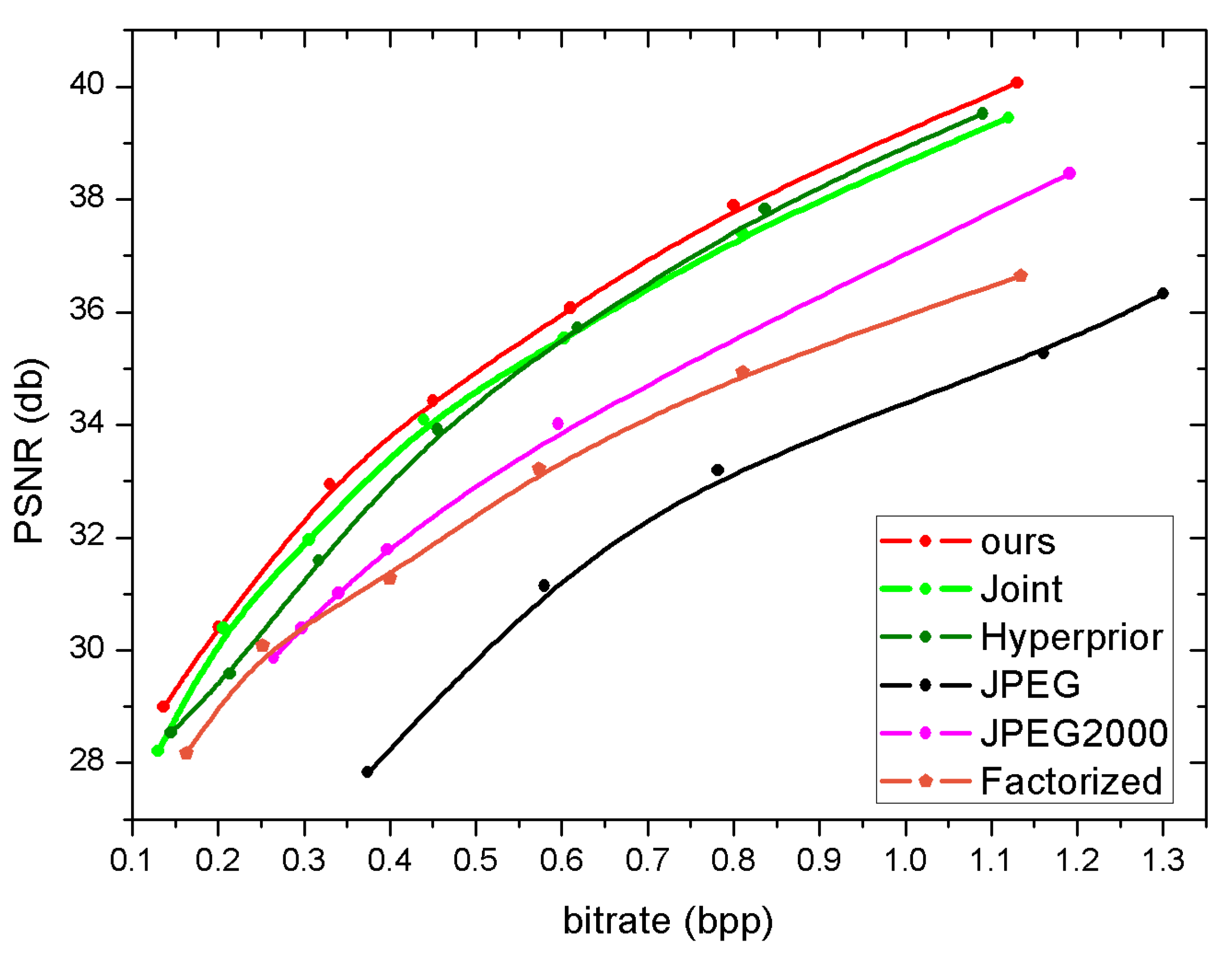
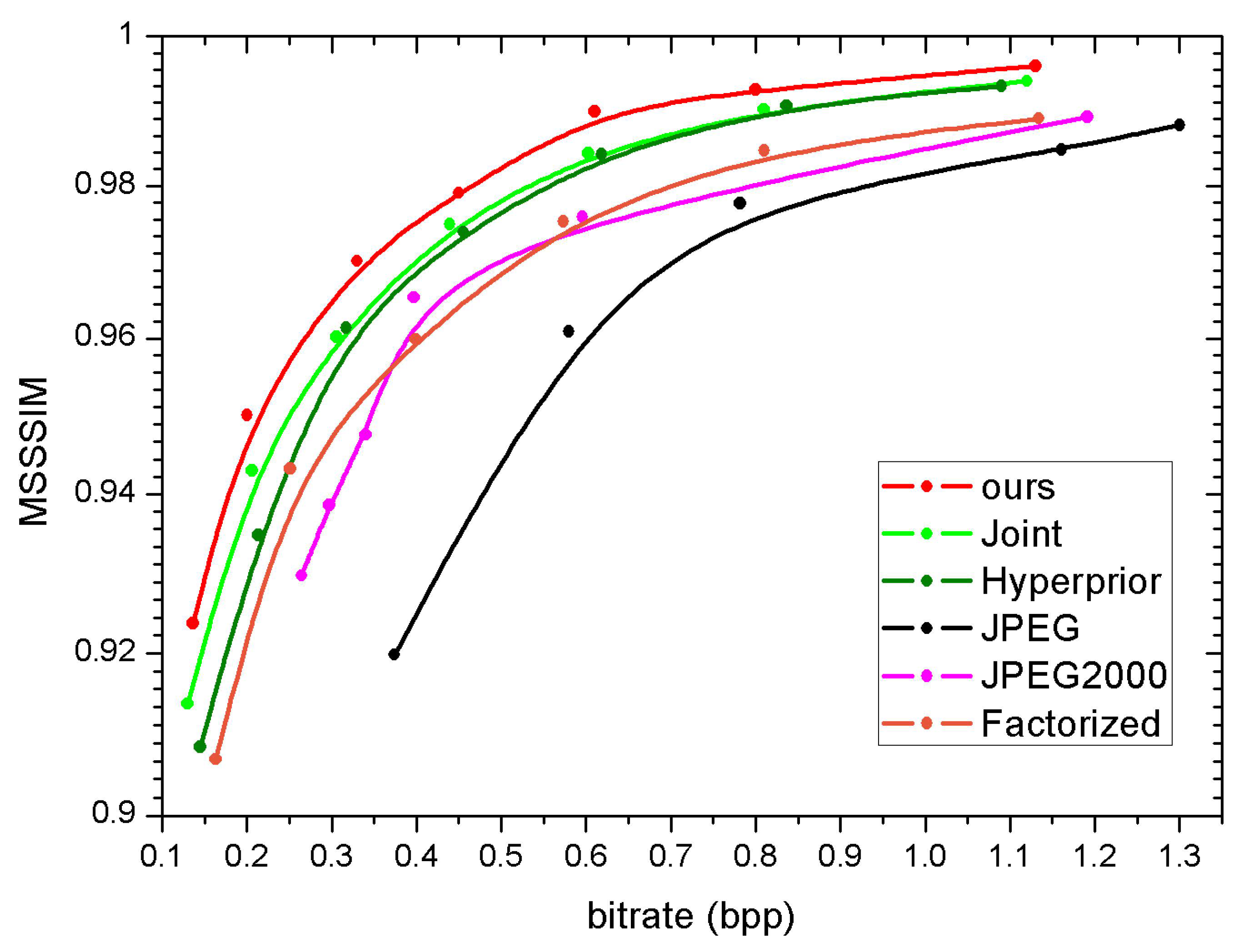
4.4. Experimental Result and Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Guo, T.; Luo, F.; Zhang, L.; Tan, X.; Liu, J.; Zhou, X. Target detection in hyperspectral imagery via sparse and dense hybrid representation. IEEE Geosci. Remote Sens. Lett. 2019, 17, 716–720. [Google Scholar] [CrossRef]
- Guo, T.; Luo, F.; Zhang, L.; Zhang, B.; Tan, X.; Zhou, X. Learning Structurally Incoherent Background and Target Dictionaries for Hyperspectral Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3521–3533. [Google Scholar] [CrossRef]
- Wang, Z.; Du, B.; Zhang, L.; Zhang, L.; Jia, X. A novel semisupervised active-learning algorithm for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3071–3083. [Google Scholar] [CrossRef]
- Zhou, S.; Deng, C.; Zhao, B.; Xia, Y.; Li, Q.; Chen, Z. Remote sensing image compression: A review. In Proceedings of the 2015 IEEE International Conference on Multimedia Big Data, Beijing, China, 20–22 April 2015; pp. 406–410. [Google Scholar]
- Rusyn, B.; Lutsyk, O.; Lysak, Y.; Lukenyuk, A.; Pohreliuk, L. Lossless image compression in the remote sensing applications. In Proceedings of the 2016 IEEE First International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 23–27 August 2016; pp. 195–198. [Google Scholar] [CrossRef]
- Wang, H.; Babacan, S.D.; Sayood, K. Lossless hyperspectral-image compression using context-based conditional average. IEEE Trans. Geosci. Remote Sens. 2007, 45, 4187–4193. [Google Scholar] [CrossRef]
- Luo, F.; Zou, Z.; Liu, J.; Lin, Z. Dimensionality reduction and classification of hyperspectral image via multistructure unified discriminative embedding. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Luo, F.; Zhou, T.; Liu, J.; Guo, T.; Gong, X.; Ren, J. Multi-Scale Diff-changed Feature Fusion Network for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]
- Liu, R.; Zhu, X. Endmember Bundle Extraction Based on Multiobjective Optimization. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8630–8645. [Google Scholar] [CrossRef]
- Hu, Y.; Yang, W.; Ma, Z.; Liu, J. Learning end-to-end lossy image compression: A benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4194–4211. [Google Scholar] [CrossRef]
- Guo, Y.; Tao, Y.; Chong, Y.; Pan, S.; Liu, M. Edge-Guided Hyperspectral Image Compression with Interactive Dual Attention. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Wallace, G.K. The Jpeg Still Picture Compression Standard. IEEE Trans. Consum. Electron. 1992, 38, xviii–xxxiv. [Google Scholar] [CrossRef]
- Christopoulos, C.; Skodras, A.; Ebrahimi, T. The JPEG2000 still image coding system: An overview. IEEE Trans. Consum. Electron. 2000, 46, 1103–1127. [Google Scholar] [CrossRef]
- Hou, P.; Petrou, M.; Underwood, C.; Hojjatoleslami, A. Improving JPEG performance in conjunction with cloud editing for remote sensing applications. IEEE Trans. Geosci. Remote Sens. 2000, 38, 515–524. [Google Scholar] [CrossRef]
- Zemliachenko, A.N.; Kozhemiakin, R.A.; Abramov, S.K.; Lukin, V.V.; Vozel, B.; Chehdi, K.; Egiazarian, K.O. Prediction of Compression Ratio for DCT-Based Coders with Application to Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 257–270. [Google Scholar] [CrossRef]
- Gonzalez-Conejero, J.; Bartrina-Rapesta, J.; Serra-Sagrista, J. JPEG2000 Encoding of Remote Sensing Multispectral Images with No-Data Regions. IEEE Geosci. Remote Sens. Lett. 2010, 7, 251–255. [Google Scholar] [CrossRef]
- Akam Bita, I.P.; Barret, M.; Pham, D.T. On optimal transforms in lossy compression of multicomponent images with JPEG2000. Signal Process. 2010, 90, 759–773. [Google Scholar] [CrossRef]
- Du, Q.; Fowler, J.E. Hyperspectral Image Compression Using JPEG2000 and Principal Component Analysis. IEEE Geosci. Remote Sens. Lett. 2007, 4, 201–205. [Google Scholar] [CrossRef]
- Báscones, D.; González, C.; Mozos, D. Hyperspectral image compression using vector quantization, PCA and JPEG2000. Remote Sens. 2018, 10, 907. [Google Scholar] [CrossRef]
- Yeh, P.S.; Armbruster, P.; Kiely, A.; Masschelein, B.; Moury, G.; Schaefer, C.; Thiebaut, C. The new CCSDS image compression recommendation. In Proceedings of the 2005 IEEE Aerospace Conference, Big Sky, MT, USA, 5–12 March 2005; pp. 4138–4145. [Google Scholar]
- Garcia-Vilchez, F.; Serra-Sagrista, J. Extending the CCSDS recommendation for image data compression for remote sensing scenarios. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3431–3445. [Google Scholar] [CrossRef]
- Machairas, E.; Kranitis, N. A 13.3 Gbps 9/7M Discrete Wavelet Transform for CCSDS 122.0-B-1 Image Data Compression on a Space-Grade SRAM FPGA. Electronics 2020, 9, 1234. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X.; Du, B. Compression of hyperspectral remote sensing images by tensor approach. Neurocomputing 2015, 147, 358–363. [Google Scholar] [CrossRef]
- Li, F.; Lukin, V.; Ieremeiev, O.; Okarma, K. Quality Control for the BPG Lossy Compression of Three-Channel Remote Sensing Images. Remote Sens. 2022, 14, 1824. [Google Scholar] [CrossRef]
- Makarichev, V.O.; Lukin, V.V.; Brysina, I.V.; Vozel, B. Spatial Complexity Reduction in Remote Sensing Image Compression by Atomic Functions. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Li, J.; Fu, Y.; Li, G.; Liu, Z. Remote sensing image compression in visible/near-infrared range using heterogeneous compressive sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4932–4938. [Google Scholar] [CrossRef]
- Makarichev, V.; Vasilyeva, I.; Lukin, V.; Vozel, B.; Shelestov, A.; Kussul, N. Discrete atomic transform-based lossy compression of three-channel remote sensing images with quality control. Remote Sens. 2022, 14, 125. [Google Scholar] [CrossRef]
- Wang, Z.; Du, B.; Guo, Y. Domain adaptation with neural embedding matching. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 2387–2397. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Gu, X.; Chen, J.; Wang, D.; Chen, Y.; Wang, L. Automatic recognition of pavement cracks from combined GPR B-scan and C-scan images using multiscale feature fusion deep neural networks. Autom. Constr. 2023, 146, 104698. [Google Scholar] [CrossRef]
- Jesus, T.C.; Costa, D.G.; Portugal, P.; Vasques, F. A survey on monitoring quality assessment for wireless visual sensor networks. Future Internet 2022, 14, 213. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, W.; Jiang, B.; Tong, X.; Chai, K.; Yin, Y.; Wang, L.; Jia, J.; Chen, X. Reference-Based Super-Resolution Method for Remote Sensing Images with Feature Compression Module. Remote Sens. 2023, 15, 1103. [Google Scholar] [CrossRef]
- Huyan, L.; Li, Y.; Jiang, D.; Zhang, Y.; Zhou, Q.; Li, B.; Wei, J.; Liu, J.; Zhang, Y.; Wang, P.; et al. Remote Sensing Imagery Object Detection Model Compression via Tucker Decomposition. Mathematics 2023, 11, 856. [Google Scholar] [CrossRef]
- Zhai, G.; Min, X. Perceptual image quality assessment: A survey. Sci. China Inf. Sci. 2020, 63, 1–52. [Google Scholar] [CrossRef]
- Yang, Y.; Sun, J.; Li, H.; Xu, Z. ADMM-CSNet: A Deep Learning Approach for Image Compressive Sensing. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 521–538. [Google Scholar] [CrossRef]
- Wang, D.; Liu, Z.; Gu, X.; Wu, W.; Chen, Y.; Wang, L. Automatic Detection of Pothole Distress in Asphalt Pavement Using Improved Convolutional Neural Networks. Remote Sens. 2022, 14, 3892. [Google Scholar] [CrossRef]
- Tu, Z.; Li, H.; Zhang, D.; Dauwels, J.; Li, B.; Yuan, J. Action-stage emphasized spatiotemporal VLAD for video action recognition. IEEE Trans. Image Process. 2019, 28, 2799–2812. [Google Scholar] [CrossRef]
- Lan, M.; Zhang, J.; Wang, Z. Coherence-aware context aggregator for fast video object segmentation. Pattern Recognit. 2023, 136, 109214. [Google Scholar] [CrossRef]
- Duan, Y.; Luo, F.; Fu, M.; Niu, Y.; Gong, X. Classification via Structure Preserved Hypergraph Convolution Network for Hyperspectral Image. IEEE Trans. Geosci. Remote Sens. 2023, 61. [Google Scholar] [CrossRef]
- Fu, C.; Du, B.; Zhang, L. SAR Image Compression Based on Multi-Resblock and Global Context. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Li, J.; Liu, Z. Efficient compression algorithm using learning networks for remote sensing images. Appl. Soft Comput. 2021, 100, 106987. [Google Scholar] [CrossRef]
- Zhao, S.; Yang, S.; Gu, J.; Liu, Z.; Feng, Z. Symmetrical lattice generative adversarial network for remote sensing images compression. ISPRS J. Photogramm. Remote Sens. 2021, 176, 169–181. [Google Scholar] [CrossRef]
- Guo, Y.; Chong, Y.; Ding, Y.; Pan, S.; Gu, X. Learned Hyperspectral Compression Using a Student’s T Hyperprior. Remote Sens. 2021, 13, 4390. [Google Scholar] [CrossRef]
- Chong, Y.; Zhai, L.; Pan, S. High-Order Markov Random Field as Attention Network for High-Resolution Remote-Sensing Image Compression. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Xu, Q.; Xiang, Y.; Di, Z.; Fan, Y.; Feng, Q.; Wu, Q.; Shi, J. Synthetic Aperture Radar Image Compression Based on a Variational Autoencoder. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Di, Z.; Chen, X.; Wu, Q.; Shi, J.; Feng, Q.; Fan, Y. Learned Compression Framework with Pyramidal Features and Quality Enhancement for SAR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Ballé, J.; Minnen, D.; Singh, S.; Hwang, S.J.; Johnston, N. Variational image compression with a scale hyperprior. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Minnen, D.; Ballé, J.; Toderici, G.D. Joint autoregressive and hierarchical priors for learned image compression. Adv. Neural Inf. Process. Syst. 2018, 31, 10794–10803. [Google Scholar]
- Ballé, J.; Laparra, V.; Simoncelli, E.P. End-to-end optimized image compression. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Cheng, Z.; Sun, H.; Takeuchi, M.; Katto, J. Deep Residual Learning for Image Compression. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 17 June 2019. [Google Scholar]
- Cheng, Z.; Sun, H.; Takeuchi, M.; Katto, J. Learned image compression with discretized gaussian mixture likelihoods and attention modules. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7939–7948. [Google Scholar]
- Qian, Y.; Tan, Z.; Sun, X.; Lin, M.; Li, D.; Sun, Z.; Hao, L.; Jin, R. Learning Accurate Entropy Model with Global Reference for Image Compression. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017.
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10819–10829. [Google Scholar]
- Kitaev, N.; Kaiser, Ł.; Levskaya, A. Reformer: The efficient transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Agustsson, E.; Mentzer, F.; Tschannen, M.; Cavigelli, L.; Timofte, R.; Benini, L.; Gool, L.V. Soft-to-hard vector quantization for end-to-end learning compressible representations. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ballé, J.; Laparra, V.; Simoncelli, E.P. Density modeling of images using a generalized normalization transformation. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Guo, Z.; Zhang, Z.; Feng, R.; Chen, Z. Soft then hard: Rethinking the quantization in neural image compression. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 3920–3929. [Google Scholar]
- Yang, Y.; Bamler, R.; Mandt, S. Improving inference for neural image compression. Adv. Neural Inf. Process. Syst. 2020, 33, 573–584. [Google Scholar]
- Kingma, D.; Ba, L. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Bégaint, J.; Racapé, F.; Feltman, S.; Pushparaja, A. Compressai: A pytorch library and evaluation platform for end-to-end compression research. arXiv 2020, arXiv:2011.03029. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, C.; Du, B. Remote Sensing Image Compression Based on the Multiple Prior Information. Remote Sens. 2023, 15, 2211. https://doi.org/10.3390/rs15082211
Fu C, Du B. Remote Sensing Image Compression Based on the Multiple Prior Information. Remote Sensing. 2023; 15(8):2211. https://doi.org/10.3390/rs15082211
Chicago/Turabian StyleFu, Chuan, and Bo Du. 2023. "Remote Sensing Image Compression Based on the Multiple Prior Information" Remote Sensing 15, no. 8: 2211. https://doi.org/10.3390/rs15082211
APA StyleFu, C., & Du, B. (2023). Remote Sensing Image Compression Based on the Multiple Prior Information. Remote Sensing, 15(8), 2211. https://doi.org/10.3390/rs15082211