Figure 1.
Symmetric auto-completion of patches: patches which partly fall outside the domain of the input image are filled with a mirrored version of the image content inside the patch. This avoids unwanted artifacts.
Figure 1.
Symmetric auto-completion of patches: patches which partly fall outside the domain of the input image are filled with a mirrored version of the image content inside the patch. This avoids unwanted artifacts.
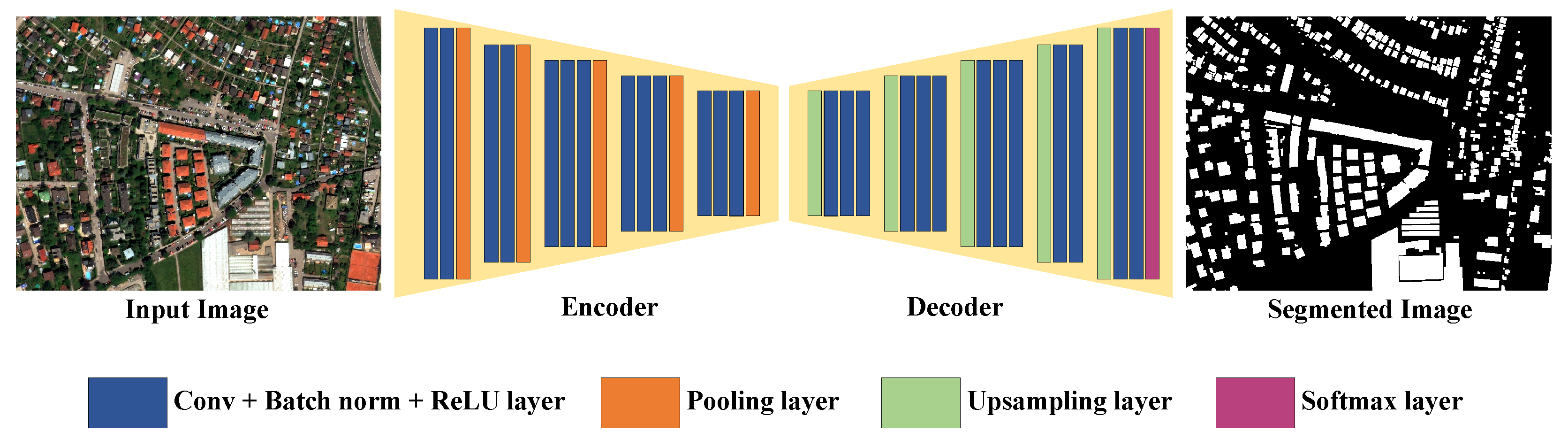
Figure 2.
The encoder–decoder network architecture of SegNet.
Figure 2.
The encoder–decoder network architecture of SegNet.
Figure 3.
The network architecture of Mask R-CNN.
Figure 3.
The network architecture of Mask R-CNN.
Figure 4.
Unwanted effects in satellite imagery for BFP extraction: (a) example of VHR data with suboptimal solar azimuth angle; (b) cutout of tile with large off-nadir angle leading to a tilted view.
Figure 4.
Unwanted effects in satellite imagery for BFP extraction: (a) example of VHR data with suboptimal solar azimuth angle; (b) cutout of tile with large off-nadir angle leading to a tilted view.
Figure 5.
Example images from the INRIA dataset (a–c) and from the ISPRS dataset (d,e).
Figure 5.
Example images from the INRIA dataset (a–c) and from the ISPRS dataset (d,e).
Figure 6.
Visual example of buildings with different predominant styles (SFB: single family buildings (a), MFB: multiple family buildings (b) and IB: industrial buildings (c)).
Figure 6.
Visual example of buildings with different predominant styles (SFB: single family buildings (a), MFB: multiple family buildings (b) and IB: industrial buildings (c)).
Figure 7.
Example patches of areas with different densities: sparse detached structure, SDS (a), block structure, BS (b), and dense detached structure, DDS (c), together with their ground truth (second row).
Figure 7.
Example patches of areas with different densities: sparse detached structure, SDS (a), block structure, BS (b), and dense detached structure, DDS (c), together with their ground truth (second row).
Figure 8.
Impact of training set size (RQ1): two examples (Ex. 1, Ex. 2) from (small test set with unseen cities) and the predicted segmentation masks obtained by our models: (a) input image; (b) ground truth; (c) SegNet trained on a small training set; (d) SegNet trained on full training data; (e) Mask R-CNN trained on a small training set; (f) Mask R-CNN trained on full training data.
Figure 8.
Impact of training set size (RQ1): two examples (Ex. 1, Ex. 2) from (small test set with unseen cities) and the predicted segmentation masks obtained by our models: (a) input image; (b) ground truth; (c) SegNet trained on a small training set; (d) SegNet trained on full training data; (e) Mask R-CNN trained on a small training set; (f) Mask R-CNN trained on full training data.
Figure 9.
Impact of pretraining and fine-tuning (RQ3): two images from the INRIA (top row) and ISPRS (bottom row) test sets and the predicted masks by our models: (a) input image, (b) ground truth, (c) SegNet trained on INRIA/ISPRS, respectively; (d) SegNet trained on GBDX only; (e) SegNet pretrained on GBDX and fine-tuned on INRIA/ISPRS; (f) Mask R-CNN trained on INRIA/ISPRS, (g) Mask R-CNN trained on GBDX only, (h) Mask R-CNN pretrained on GBDX and fine-tuned on INRIA/ISPRS.
Figure 9.
Impact of pretraining and fine-tuning (RQ3): two images from the INRIA (top row) and ISPRS (bottom row) test sets and the predicted masks by our models: (a) input image, (b) ground truth, (c) SegNet trained on INRIA/ISPRS, respectively; (d) SegNet trained on GBDX only; (e) SegNet pretrained on GBDX and fine-tuned on INRIA/ISPRS; (f) Mask R-CNN trained on INRIA/ISPRS, (g) Mask R-CNN trained on GBDX only, (h) Mask R-CNN pretrained on GBDX and fine-tuned on INRIA/ISPRS.
Figure 10.
Generalization across continents (RQ4): two images from the test sets from Europe (EU) and North America (NAM) together with the predicted masks by our models: (a) input image; (b) ground truth; (c) SegNet trained on EU; (d) SegNet trained on NAM; (e) Mask R-CNN trained on EU; (f) Mask R-CNN trained on NAM.
Figure 10.
Generalization across continents (RQ4): two images from the test sets from Europe (EU) and North America (NAM) together with the predicted masks by our models: (a) input image; (b) ground truth; (c) SegNet trained on EU; (d) SegNet trained on NAM; (e) Mask R-CNN trained on EU; (f) Mask R-CNN trained on NAM.
Figure 11.
Robustness to different building structures (RQ5): three image examples from the test sets with single family buildings (SFB), multiple family buildings (MFB), and industrial buildings (IB) together with the predicted masks by the models: (a) input image; (b) ground truth; (c) SegNet trained on SFB; (d) SegNet trained on MFB; (e) SegNet trained on IB; (f) Mask R-CNN trained on SFB; (g) Mask R-CNN trained on MFB; (h) Mask R-CNN trained on IB.
Figure 11.
Robustness to different building structures (RQ5): three image examples from the test sets with single family buildings (SFB), multiple family buildings (MFB), and industrial buildings (IB) together with the predicted masks by the models: (a) input image; (b) ground truth; (c) SegNet trained on SFB; (d) SegNet trained on MFB; (e) SegNet trained on IB; (f) Mask R-CNN trained on SFB; (g) Mask R-CNN trained on MFB; (h) Mask R-CNN trained on IB.
Figure 12.
Robustness to different building density (RQ6): three example images from the test sets of , , and , together with the predicted masks by the models: (a) input image; (b) ground truth; (c) SegNet trained on SDS; (d) SegNet trained on BS; (e) SegNet trained on DDS; (f) Mask R-CNN trained on SDS; (g) Mask R-CNN trained on BS; (h) Mask R-CNN trained on DDS.
Figure 12.
Robustness to different building density (RQ6): three example images from the test sets of , , and , together with the predicted masks by the models: (a) input image; (b) ground truth; (c) SegNet trained on SDS; (d) SegNet trained on BS; (e) SegNet trained on DDS; (f) Mask R-CNN trained on SDS; (g) Mask R-CNN trained on BS; (h) Mask R-CNN trained on DDS.
Figure 13.
Receiver operating and precision-recall curves for the two largest test sets in our study: and together with the respective areas under the curve (AUC) values: (a) receiver operating curve (ROC) for , AUC = 0.964, (b) receiver operating curve (ROC) for , AUC = 0.944; (c) precision-recall curve (PRC) for , AUC = 0.872; (d) precision-recall curve (PRC) for , AUC = 0.838.
Figure 13.
Receiver operating and precision-recall curves for the two largest test sets in our study: and together with the respective areas under the curve (AUC) values: (a) receiver operating curve (ROC) for , AUC = 0.964, (b) receiver operating curve (ROC) for , AUC = 0.944; (c) precision-recall curve (PRC) for , AUC = 0.872; (d) precision-recall curve (PRC) for , AUC = 0.838.
Figure 14.
Sensitivity of the individual performance metrics on the actual value of the decision threshold. The optimal decision threshold with respect to DICE (=F1) score is 0.44 for and 0.47 for : (a) threshold sensitivity for ; (b) threshold sensitivity for .
Figure 14.
Sensitivity of the individual performance metrics on the actual value of the decision threshold. The optimal decision threshold with respect to DICE (=F1) score is 0.44 for and 0.47 for : (a) threshold sensitivity for ; (b) threshold sensitivity for .
Table 1.
Overview of the compiled GBDX dataset: European (EU) and North American (NAM) cities in the dataset together with the number of tiles and patches generated from the tiles for BFP extraction.
Table 1.
Overview of the compiled GBDX dataset: European (EU) and North American (NAM) cities in the dataset together with the number of tiles and patches generated from the tiles for BFP extraction.
| EU Cities | Tiles | Patches | NAM Cities | Tiles | Patches |
|---|
| Athens | 13 | 832 | Raleigh | 24 | 1536 |
| Berlin | 7 | 448 | Santa | 36 | 2304 |
| Madrid | 7 | 448 | Houston1 | 10 | 640 |
| Oslo | 14 | 896 | Peoria | 25 | 1600 |
| Vienna | 15 | 960 | Philadelphia | 23 | 1472 |
| Copenhagen | 53 | 3392 | Detroit1 | 20 | 1280 |
| Hamburg | 22 | 1408 | Houston2 | 19 | 1216 |
| London | 44 | 2816 | San Jose | 23 | 1472 |
| Munich | 45 | 2880 | Detroit | 20 | 1280 |
| Zagreb | 17 | 1088 | Vancouver | 9 | 576 |
| Amsterdam | 15 | 960 | | | |
| Brussels | 10 | 640 | | | |
| Copenhagen1 | 17 | 1088 | | | |
| Helsinki | 20 | 1280 | | | |
| Paris | 16 | 1024 | | | |
| Warsaw | 15 | 960 | | | |
| Belgrade | 10 | 640 | | | |
| Total | 340 | 21,760 | Total | 209 | 13,376 |
Table 2.
Overview of all three datasets used in our study. The GDBX dataset has the largest diversity in terms of different cities. ISPRS stands out in resolution, and INRIA overall has the largest number of patches.
Table 2.
Overview of all three datasets used in our study. The GDBX dataset has the largest diversity in terms of different cities. ISPRS stands out in resolution, and INRIA overall has the largest number of patches.
| Dataset | Source | Resolution | No. of Cities | Tile Size (px) | No. of Tiles | No. of Patches |
|---|
| GBDX | aerial | 30 cm | 24 | 1080 × 1440 | 549 | 35,136 |
| ISPRS | aerial | 5–9 cm | 2 | 6000 × 6000 | 15 | 45,229 |
| INRIA | aerial | 30 cm | 5 | 5000 × 5000 | 180 | 228,780 |
Table 3.
Overview of the different partitions of the GDBX dataset necessary to answer the individual research questions. GDBX Partition 4 has been performed directly on a patch level, all others on a tile level. Note that for answering RQ3 (transfer learning), we employ the publicly available datasets INRIA and ISPRS (not listed here).
Table 3.
Overview of the different partitions of the GDBX dataset necessary to answer the individual research questions. GDBX Partition 4 has been performed directly on a patch level, all others on a tile level. Note that for answering RQ3 (transfer learning), we employ the publicly available datasets INRIA and ISPRS (not listed here).
| Partition | Naming | No. of Tiles | No. of Patches |
|---|
| GDBX Partition 1 (RQ1 & RQ2) | | 215 | 13,760 |
| 320 | 20,480 |
| GDBX Partition 2 (RQ4) | | 340 | 21,760 |
| 209 | 13,120 |
| GDBX Partition 3 (RQ5) | | 183 | 11,776 |
| 190 | 12,160 |
| 88 | 5632 |
| GDBX Partition 4 (RQ6) | | - | 10,858 |
| - | 8588 |
| - | 6381 |
Table 4.
Results for RQ1, RQ2: performance for test sets with previously seen and unseen cities for SegNet and Mask R-CNN trained on different large training sets, i.e., (a) and (b) the full training data and . ‘Acc’ stands for accuracy, ‘Pr’ for precision, and ‘Re’ for recall. The best results are highlighted in bold. This clearly shows that SegNet outperforms Mask R-CNN. The latter architecture can only outperform SegNet in recall (Re), however, at the cost of precision (Pr), leading to overall lower performance (see DICE, which is in the case of binary segmentation equivalent to F1-score).
Table 4.
Results for RQ1, RQ2: performance for test sets with previously seen and unseen cities for SegNet and Mask R-CNN trained on different large training sets, i.e., (a) and (b) the full training data and . ‘Acc’ stands for accuracy, ‘Pr’ for precision, and ‘Re’ for recall. The best results are highlighted in bold. This clearly shows that SegNet outperforms Mask R-CNN. The latter architecture can only outperform SegNet in recall (Re), however, at the cost of precision (Pr), leading to overall lower performance (see DICE, which is in the case of binary segmentation equivalent to F1-score).
| | SegNet | Mask R-CNN |
|---|
| | IoU | DICE | Acc | Pr | Re | IoU | DICE | Acc | Pr | Re |
|---|
| (a) small train set | | | | | | | | | | |
| 0.56 | 0.69 | 0.87 | 0.81 | 0.62 | 0.46 | 0.61 | 0.78 | 0.49 | 0.84 |
| 0.52 | 0.67 | 0.92 | 0.85 | 0.59 | 0.43 | 0.59 | 0.82 | 0.45 | 0.86 |
| 0.55 | 0.70 | 0.89 | 0.83 | 0.63 | 0.49 | 0.65 | 0.82 | 0.54 | 0.87 |
| 0.55 | 0.70 | 0.87 | 0.82 | 0.63 | 0.47 | 0.62 | 0.75 | 0.52 | 0.86 |
| (b) full train set | | | | | | | | | | |
| 0.63 | 0.75 | 0.94 | 0.79 | 0.77 | 0.55 | 0.68 | 0.90 | 0.69 | 0.78 |
| 0.64 | 0.78 | 0.94 | 0.80 | 0.77 | 0.52 | 0.68 | 0.89 | 0.61 | 0.80 |
| 0.65 | 0.77 | 0.91 | 0.58 | 0.82 | 0.58 | 0.72 | 0.89 | 0.71 | 0.77 |
| 0.61 | 0.75 | 0.87 | 0.73 | 0.80 | 0.55 | 0.70 | 0.85 | 0.67 | 0.77 |
Table 5.
Impact of transfer learning (RQ3), i.e., pretraining and fine-tuning. DICE scores of SegNet and Mask R-CNN for the test sets of INRIA/ISPRS when trained on (a) INRIA/ISPRS, (b) GBDX, and (c) pretrained on GBDX and fine-tuned on INRIA/ISPRS.
Table 5.
Impact of transfer learning (RQ3), i.e., pretraining and fine-tuning. DICE scores of SegNet and Mask R-CNN for the test sets of INRIA/ISPRS when trained on (a) INRIA/ISPRS, (b) GBDX, and (c) pretrained on GBDX and fine-tuned on INRIA/ISPRS.
| SegNet | Mask R-CNN |
|---|
| | (a) Self | (b) GBDX | (c) Finetuning | | (a) Self | (b) GBDX | (c) Finetuning |
|---|
| INRIA | 0.61 | 0.43 | 0.63 | INRIA | 0.48 | 0.56 | 0.44 |
| ISPRS | 0.84 | 0.43 | 0.73 | ISPRS | 0.49 | 0.62 | 0.71 |
Table 6.
Generalization across continents (RQ4): DICE scores of SegNet and Mask R-CNN trained on European data (EU) and North American data (NAM) and tested for test sets of both continents.
Table 6.
Generalization across continents (RQ4): DICE scores of SegNet and Mask R-CNN trained on European data (EU) and North American data (NAM) and tested for test sets of both continents.
| SegNet | Mask R-CNN |
|---|
| | Test: NAM | Test: EU | | Test: NAM | Test: EU |
|---|
| Train: NAM | 0.62 | 0.66 | Train: NAM | 0.71 | 0.67 |
| Train: EU | 0.71 | 0.73 | Train: EU | 0.70 | 0.69 |
Table 7.
Robustness to different building structures (RQ5). Test DICE scores of SegNet and Mask R-CNN trained on single family buildings (SFB), multiple family buildings (MFB), and industrial buildings (IB), respectively.
Table 7.
Robustness to different building structures (RQ5). Test DICE scores of SegNet and Mask R-CNN trained on single family buildings (SFB), multiple family buildings (MFB), and industrial buildings (IB), respectively.
| SegNet | Mask R-CNN |
|---|
| | Test: SFB | Test: MFB | Test: IB | | Test: SFB | Test: MFB | Test: IB |
|---|
| Train: SFB | 0.70 | 0.68 | 0.59 | Train: SFB | 0.47 | 0.54 | 0.46 |
| Train: MFB | 0.70 | 0.74 | 0.52 | Train: MFB | 0.47 | 0.55 | 0.52 |
| Train: IB | 0.64 | 0.71 | 0.73 | Train: IB | 0.33 | 0.41 | 0.39 |
Table 8.
Robustness to different building density (RQ6). Test set DICE scores of SegNet and Mask R-CNN trained on areas with sparse detached structure (SDS), block structure (BS), and dense detached structure (DDS), respectively. The test data contain cities already seen during training.
Table 8.
Robustness to different building density (RQ6). Test set DICE scores of SegNet and Mask R-CNN trained on areas with sparse detached structure (SDS), block structure (BS), and dense detached structure (DDS), respectively. The test data contain cities already seen during training.
| SegNet (Seen Cities) | Mask R-CNN (Seen Cities) |
|---|
| | Test: SDS | Test: BS | Test: DDS | | Test: SDS | Test: BS | Test: DDS |
|---|
| Train: SDS | 0.64 | 0.61 | 0.70 | Train: SDS | 0.32 | 0.30 | 0.34 |
| Train: BS | 0.55 | 0.81 | 0.65 | Train: BS | 0.27 | 0.59 | 0.45 |
| Train: DDS | 0.66 | 0.72 | 0.78 | Train: DDS | 0.50 | 0.62 | 0.63 |
Table 9.
Robustness to different building density (RQ6): test set DICE scores of SegNet and Mask R-CNN trained on areas with sparse detached structure (SDS), block structure (BS), and dense detached structure (DDS), respectively. The test data contain cities not seen during training.
Table 9.
Robustness to different building density (RQ6): test set DICE scores of SegNet and Mask R-CNN trained on areas with sparse detached structure (SDS), block structure (BS), and dense detached structure (DDS), respectively. The test data contain cities not seen during training.
| SegNet (Unseen Cities) | Mask R-CNN (Unseen Cities) |
|---|
| | Test: SDS | Test: BS | Test: DDS | | Test: SDS | Test: BS | Test: DDS |
|---|
| Train: SDS | 0.60 | 0.55 | 0.73 | Train: SDS | 0.30 | 0.28 | 0.33 |
| Train: BS | 0.52 | 0.77 | 0.66 | Train: BS | 0.22 | 0.56 | 0.39 |
| Train: DDS | 0.63 | 0.68 | 0.78 | Train: DDS | 0.46 | 0.58 | 0.61 |
Table 10.
Performance comparison of tile-level evaluation (after patch-level fusion) and patch-level evaluation (without fusion).
Table 10.
Performance comparison of tile-level evaluation (after patch-level fusion) and patch-level evaluation (without fusion).
| | Tile Level | Patch Level |
|---|
| Data Set | IoU | DICE | Acc | Pr | Re | IoU | DICE | Acc | Pr | Re |
|---|
| 0.63 | 0.75 | 0.94 | 0.79 | 0.77 | 0.64 | 0.75 | 0.94 | 0.80 | 0.78 |
| 0.64 | 0.78 | 0.94 | 0.80 | 0.77 | 0.59 | 0.71 | 0.93 | 0.80 | 0.71 |
| 0.65 | 0.77 | 0.91 | 0.58 | 0.82 | 0.62 | 0.73 | 0.92 | 0.76 | 0.79 |
| 0.61 | 0.75 | 0.87 | 0.73 | 0.80 | 0.59 | 0.71 | 0.90 | 0.73 | 0.78 |


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}