1. Introduction
Hyperspectral images (HSI) generally contain hundreds of subdivided spectral bands captured at a continuous wavelength [
1]. Compared with multispectral images, HSI significantly increases the spectral dimension while retaining the spatial dimension. With rich spectral information, HSI enables the detection, identification, and discrimination of target materials at a more detailed level [
2] and is widely used in geology [
3,
4], agriculture [
5,
6], environmental studies [
7,
8], quantitative inversion [
9,
10] and other fields [
11]. Due to its powerful spectral characterization ability, HSI has also served as one of the most significant data sources in the remote sensing community, especially for some classification or identification applications, such as Land Use and Land Cover (LULC) mapping [
12,
13]. This rich spectral information brings unique advantages to HSI, but it also presents challenges for image processing. On the one hand, the HSI band number and data dimension have a geometric multiple increase compared with those of traditional multispectral images, which leads to a significant increase in the calculation as well as the curse of dimensionality [
14]. The increased data volume also requires more samples to support, and the acquisition of refined labels is difficult [
15]. On the other hand, the adjacent bands of remote sensing images are more strongly correlated to closer bands. The interval between bands in HSI is significantly reduced, resulting in strong redundancy and band correlation [
16], which increases the difficulty of mining hidden information from HSI. Therefore, for HSI classification, it is vital to identify a method that can effectively use the rich spectral information.
Spectral information is typically represented by a spectral curve in an HSI. Thus, a large number of single curve analysis techniques are proposed to describe the spectral characteristics, and most of them contain the idea of dimensionality reduction. (1) Some methods use band selection to pick up the characteristics of the original spectral curve with a series of standards (e.g., spectral distance [
17], spectral divergence [
18] and spectral variance [
19]) for subsequent processing. Demir et al. [
20] used feature-weighting algorithms to obtain weights for all bands and selected bands with higher weights for classification. (2) Feature extraction methods describe and calculate the curve features, such as shape and variation, by designing a series of indices for classification (e.g., the spectral angle mapper (SAM)). Chen et al. [
21] combined the SAM feature and maximum likelihood classification (MLC) with the magnitude and shape features for classification. They discovered that adding SAM could improve accuracy. He et al. [
22] proposed a handcrafted feature extraction method based on multiscale covariance maps. The spectral features were obtained by computing the covariance matrices of the central pixels at various scales, where the values were the covariance of the spectral band pairs. They found that using the multiscale covariance maps as input features could greatly improve the classification accuracy. (3) In order to suppress the redundant information and highlight the useful information for a better description of the spectral curve, spectral transformation methods convert the original spectral space to another feature space via mathematical transformations. The most typical spectral transformation method is the principal component analysis (PCA). Jiang et al. [
23] proposed a superpixel-wise PCA (SuperPCA) approach that considers the diversity in different homogeneous regions and was able to incorporate spatial context information. Although SuperPCA is an unsupervised method, its performance is comparable to supervised approaches. Fu et al. [
24] proposed a PCA and segmented PCA (SPCA)-based multiscale 2-D-singular spectrum analysis (2-D-SSA) fusion method for joint spectral–spatial HSI feature extraction and classification. The method can extract multiscale spectral–spatial features and outperform other state-of-the-art feature-extraction methods. However, the above spectral information utilization methods describe the spectral characteristics based on manual design, which are generally limited in type and quantity, and it is also difficult to extract deeper and more representative information [
25]. Thus, these methods have limitations in the face of the complex spectral information in HSI, and they are difficult to fully use the spectral information to describe the characteristics of the targets. In recent years, breakthroughs have been made in artificial intelligence. Data-driven deep learning methods can automatically learn features at different levels of the data for classification and have achieved remarkable success in the field of computer vision. As a typical deep learning model, convolutional neuronal network (CNN) has also been widely used to analyze the spectral curve [
26] and has been shown to have the potential to surpass traditional methods that utilize manually designed features [
27,
28]. The 1D CNN uses 1D convolution kernels to extract features on the single spectral curve and combines them through a deep network structure. Hu et al. [
29] built a 1D CNN consisting of five layers with weights for HSI classification. The experimental results demonstrated the effectiveness of the proposed method when compared with traditional methods such as SVM.
However, the linearly arranged single spectral curve limited the expression of spectral relationship because the spectral information cannot be effectively aggregated in this structure. In order to utilize more information, there are some methods that treat the spectral information as non-curve data for feature extraction and classification. Some methods consider the spectral information as a cube. The 2D CNN methods use 2D convolution kernels on a 3D HSI cube for feature extraction, mainly for better use of spatial information. Kussul et al. [
30] compared the performances of 1D CNNs and 2D CNNs for land cover and crop classification. They showed that 2D CNNs outperformed 1D CNNs, although some small objects in the classification maps provided by 2D CNNs were smoothed and misclassified. Song et al. [
31] proposed a deep 2D CNN based on residual learning and fused the outputs of different hierarchical layers. Their proposed network can extract deeper features and achieve state-of-the-art performance. The 3D CNN methods use 3D convolution kernels on a 3D HSI cube for feature extraction to fuse both spatial and spectral information effectively. Hamida et al. [
32] introduced a 3D CNN for jointly processing spectral and spatial features, as well as establishing low-cost imaging. They also proposed a set of 3D CNN schemes and evaluated their feasibility. Li et al. [
33] proposed a novel 3D CNN that takes full advantage of both spectral and spatial features. In addition, there are also some 3D CNNs mixed with other convolutional kernels to complement their advantages [
34,
35]. These CNN methods use a convolution operation to extract spectral features. However, the convolution operation focuses on extracting the features of adjacent data owing to their local perception characteristics. As a result, these methods mainly extract the local spectral features (LSF) for classification. The LSF reflect the local statistical information of the spectrum and describe the relationship between adjacent bands in a local neighborhood (i.e., the local change rate of the original curve). The advantage of LSF is that they can effectively express the characteristics of spectral changes as the wavelength gradually increases and reduces the noise interference. However, the spectral curve is expressed sequentially in a one-dimensional manner, and the distance between bands increases linearly with the increase in wavelength, which leads to the possibility that the distance between effective bands (features) may be large. Thus, the disadvantage of LSF is that they are limited to processing the long-distance spectral relationship, resulting in insufficient expression of complete spectral information. To address this issue, there are some methods that consider the spectral information as an image. Yuan et al. [
36] reshaped the 1D spectral vector into a 2D spectral image. In the 2D spectral image, the long-distance spectra from the original 1D spectral vector can be aligned closely or even directly connected, which significantly expands the spectral coverage of the feature extraction window and is conducive to obtaining more spectral feature patterns. This method is conducive to constructing another feature, which is opposite to LSF and describes the relationship between non-adjacent bands in a long-distance span (i.e., the global shape of the original curve), named global spectral features (GSF). The advantage of GSF is that they can selectively construct spectral relationships between arbitrary bands to reflect the characteristics of targets (e.g., the Normalized Difference Water Index uses the long-distance spectral relationship of the green and near-infrared bands to describe the characteristics of water). However, it is challenging to identify a suitable band combination for GSF extraction among a large number of bands in an HSI.
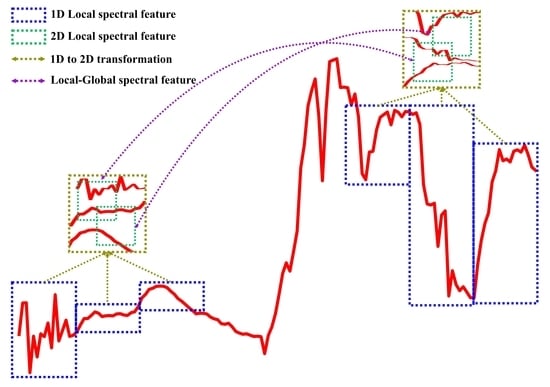
In general, the LSF and GSF describe the spectral information at local and global levels, respectively, and are the embodiment of the characteristics of the targets in different aspects. Thus, for the feature extraction method, the LSF and GSF should be fully considered to effectively express and utilize spectral information. Considering the importance of LSF and GSF when utilizing spectral information, a local-global spectral feature (LGSF) extraction and optimization method is proposed in this study to effectively combine both LSF and GSF for HSI classification. First, we analyzed the limitations of the traditional spectral feature extraction strategy that uses the 1D spectral vector as input, and to obtain more diverse spectral features, the 1D spectral vector was transformed into a 2D spectral image for feature extraction. Second, to extract the LSF, convolution was used as a local feature descriptor to aggregate adjacent spectral statistical information. Third, to extract the GSF, all spectral bands were combined in pairs and modeled automatically by the fully connected layers to introduce the distance-independent GSF upon the LSF, and further fused to form the LGSF. Fourth, to increase the effectiveness of LGSF in classification, LGSF was optimized by maximizing the difference between classes and increasing feature separability. Fifth, based on the LGSF of each pixel, a dilated convolution-based network with multiple receptive fields was designed for classification, and the pixel class was obtained. Moreover, we noticed the importance of spatial information for HSI classification and enhanced the LGSF with spatial relation to comprehensively utilize spectral and spatial information. To demonstrate the efficiency of the proposed method, we evaluated it on four widely used HSI datasets with several comparison methods. The experimental results demonstrated that the proposed method significantly enhanced the classification accuracy with a more comprehensive use of spectral features.
The contributions of this study are as follows:
A hyperspectral image classification method combining the local and global spectral features is proposed in this paper.
We transformed the original spectrum from a 1D spectral curve into a 2D spectral image for feature extraction. The spectral reorganization enhances the spectral connection and is beneficial to obtain more diverse spectral features.
The image processing and feature extraction methods for the 2D image were used to analyze the spectral information, which could extract more sufficient and stable spectral features with higher class separability.
The rest of this article is organized as follows: In
Section 2, the proposed method is introduced in detail. In
Section 3, the experiment details are introduced, including the datasets, modeling parameters and comparison methods. In
Section 4, the experiment results are analyzed and discussed. In
Section 5, the content of the article is concluded.
2. Methods
2.1. Overview of the Proposed Method
The HSI contains rich spectral information and has a great potential for classifying targets. However, the hidden complex spectral features within HSI increase the difficulty of effectively using them. Although CNN can learn to extract features automatically, its local perception characteristic limits the extracted features to cover only the local spectral range (i.e., LSF) and ignores the long-distance global spectral range (i.e., GSF). Thus, in this study, both the LSF and GSF were extracted, combined, and optimized for HSI classification.
Figure 1 shows an overview of the proposed method. The spectral information of each pixel in the HSI corresponds to a 1D spectral vector or spectral curve. In this study, to increase the correlation between spectra, the original 1D spectral vector of each pixel was transformed into a more compact 2D spectral image for subsequent feature extraction and classification. Next, the local spectral feature extraction module (LSFEM) was designed to extract the LSF from the 2D spectral image, and the global spectral feature extraction module (GSFEM) was designed to extract the GSF from the extracted LSF and to join them to obtain the LGSF. Moreover, the loss function for spectral feature optimization (SFOL) was designed to further optimize the effectiveness of the extracted LGSF automatically, based on the idea of maximizing the separability between classes. Finally, the LGSF of each pixel was input into a classification network built using dilated convolutions to determine the category of the corresponding pixel. To improve the robustness of classification, we also introduced a spatial relation to enhance the LGSF of the pixels to be classified.
The proposed method consists of six parts, and their corresponding sections are as follows: (1) transformation from a 1D spectral vector into a 2D spectral image (
Section 2.2); (2) extraction of LSF (
Section 2.3); (3) extraction of GSF and combination of LGSF (
Section 2.4); (4) optimization of LGSF (
Section 2.5); (5) structure of classification network (
Section 2.6); (6) spatial enhancement of the LGSF (
Section 2.7).
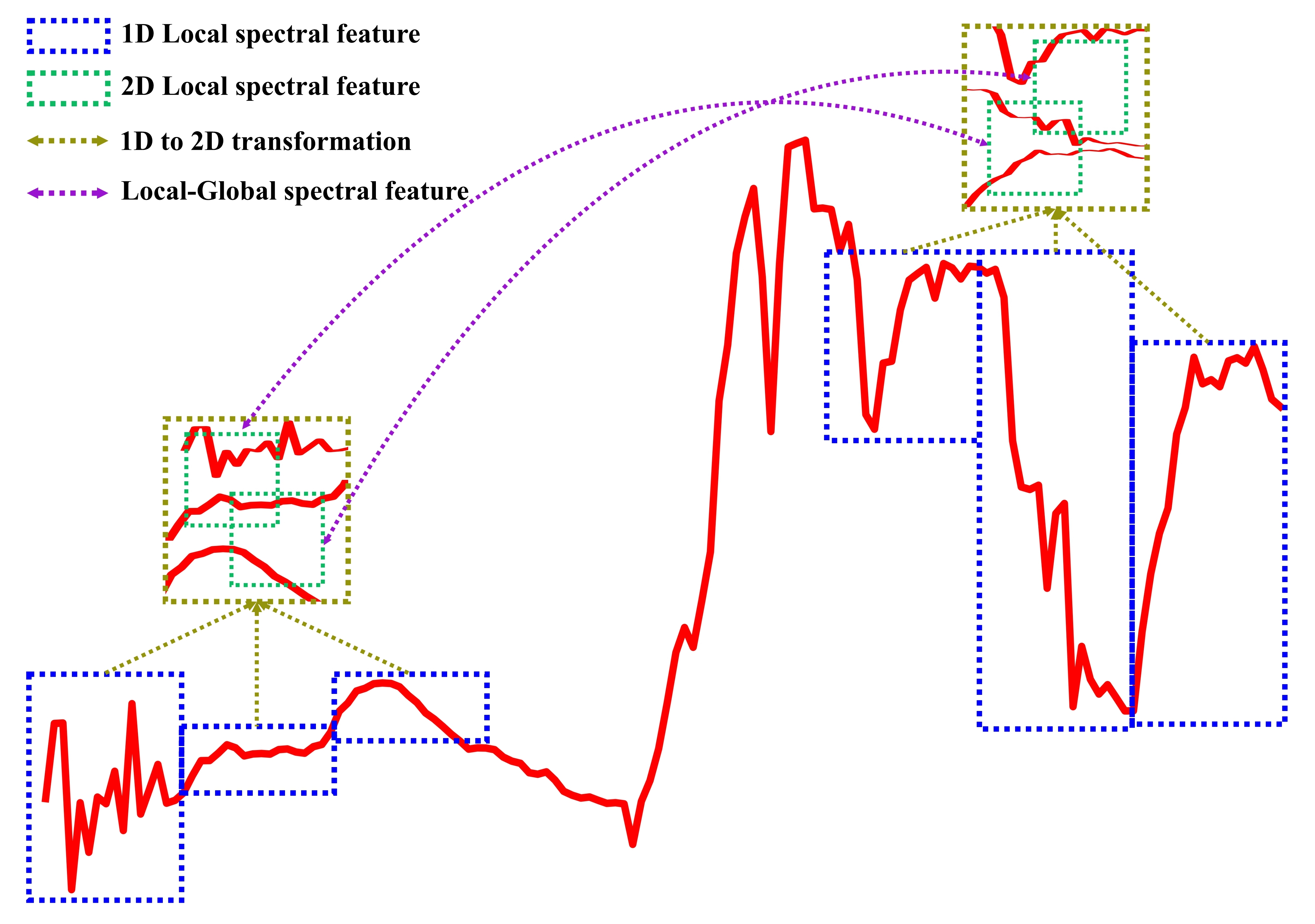
2.2. Transformation of Spectrum from 1D to 2D
To enhance the spectral connection and obtain more complex and diverse spectral features, in this study, the spectral information represented by 1D form in HSI was first converted into 2D. The details of the transformation and feature comparison between 1D and 2D are as follows.
Traditional spectral feature extraction is generally based on a 1D spectral vector. However, in such a sequential 1D structure, the distance between bands increases linearly with the increase in wavelength, which leads to a long distance between the small and large wavelength bands. Because convolution is a local feature extractor, the long-distance relationships are difficult to capture based on the 1D structure. To solve this problem, we transformed the 1D spectral vector of the center pixel in the HSI patch into a 2D spectral image (shown by the black dotted lines in
Figure 2) and used it as the basic spectral input data for the subsequent feature extraction. In the 2D spectral image, each band can be adjacent to more bands, which can be seen as the addition of a large number of shortcuts between long-distance bands in the 1D spectral vector. The green lines in
Figure 2 show the feature extraction of the 1D spectral vector and 2D spectral image using the corresponding 1D and 2D convolution kernels. Theoretically, compared with the 1D combination, there are more spectral bands and larger spectral coverage in the 2D combination, which makes it more convenient to obtain complex and diverse spectral features.
Notably, the conversion of 1D spectral vector into the 2D spectral image requires square numbers of bands. If the size of the 1D spectral vector is 1 × b, we first interpolate the original 1D spectral vector to modify the band number to a specific square number, denoted as l2 (l ∈ Z), and then transform it into a 2D spectral image with size l × l.
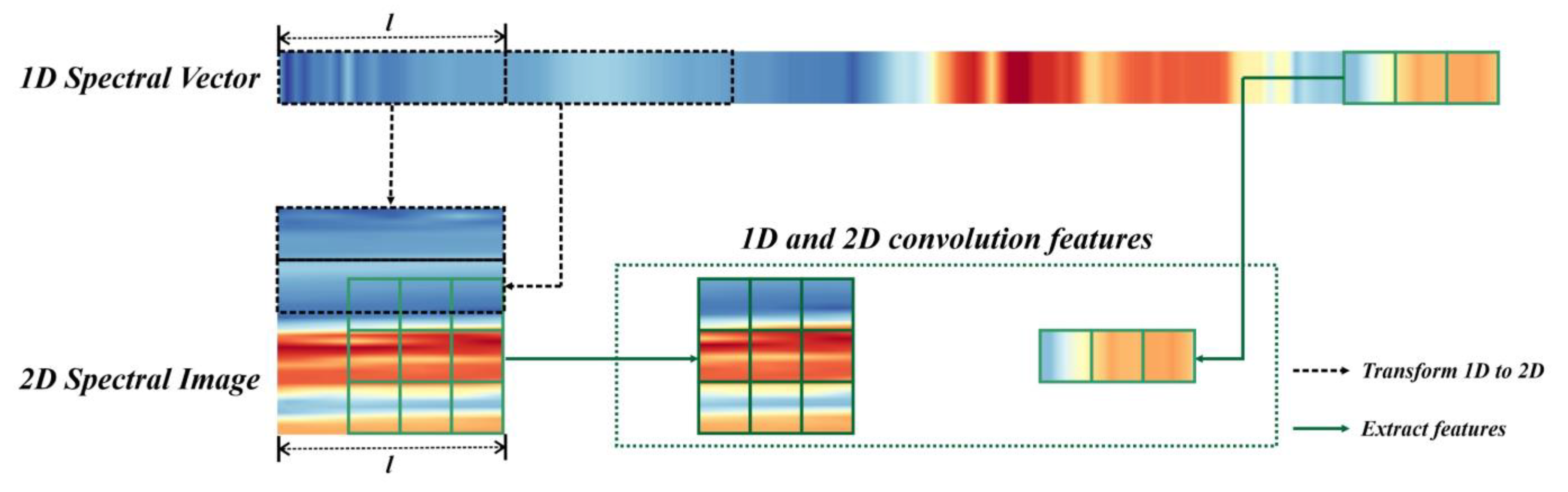
2.3. Local Spectral Feature Extraction Module
LSF is an effective spectral feature that aggregates adjacent spectra and describes the local variation of the spectral curve. To extract the LSF, the LSFEM was proposed and its characteristics are presented below.
Considering that the convolution operation is a widely used local feature extractor that meets the requirements of LSF extraction, in this study, the LSFEM utilizes convolutions to extract LSF, as shown in
Figure 3.
The input of the LSFEM is a 2D spectral image, denoted as
I2D. Two groups of 2D convolution kernels were used to aggregate the local spectra upon
I2D and obtain the LSF. The LSFEM calculation is express in Equation (1):
where
Conv1,
Conv2,
Conv3, and
Conv4 are four convolution groups with
N kernels;
B is the batch normalization and ReLU operation; while
LSF1 and
LSF2 are two groups of LSF with both sizes of
N ×
l ×
l.
N is a hyperparameter and was set to 4 in this study.
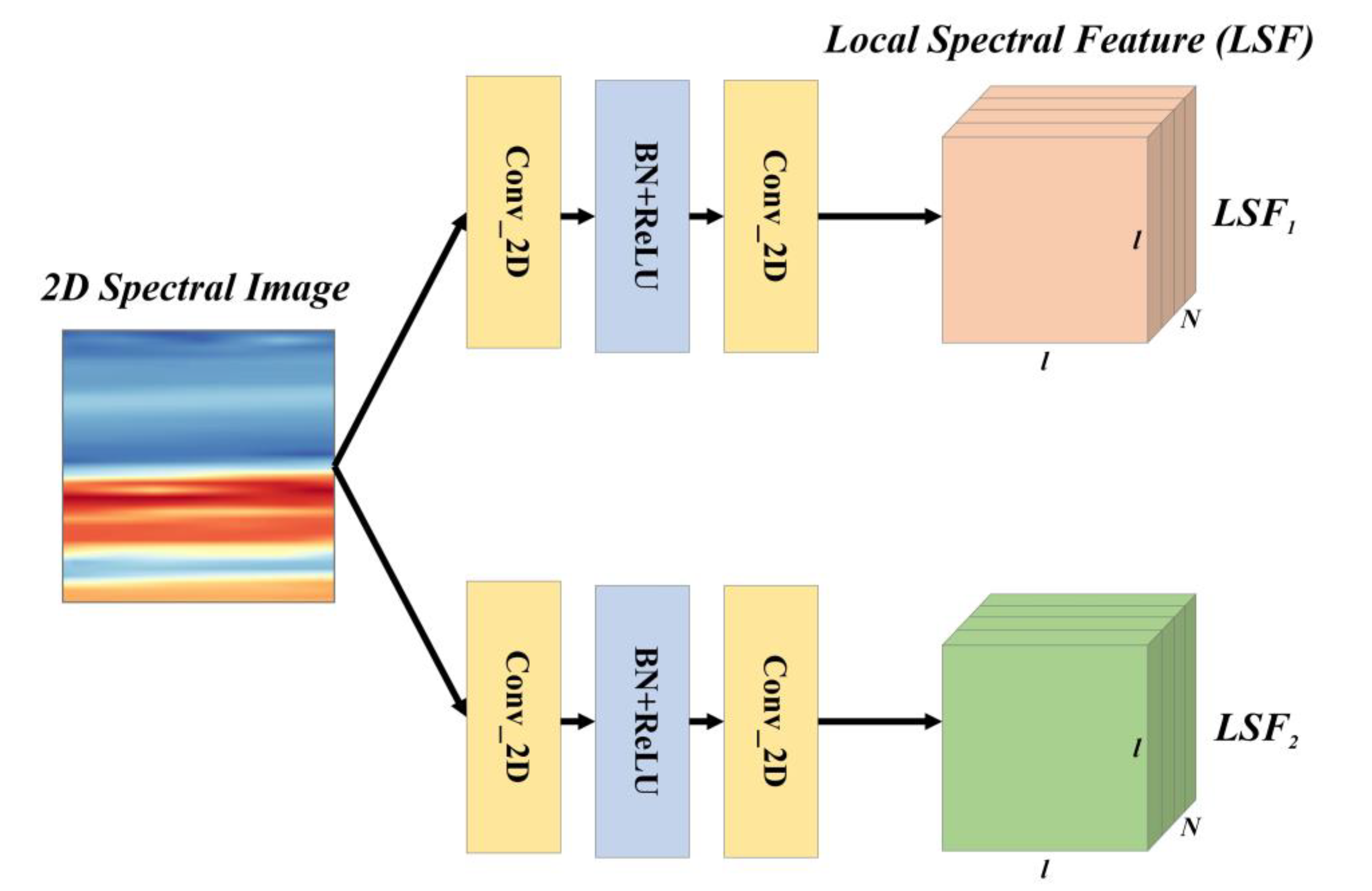
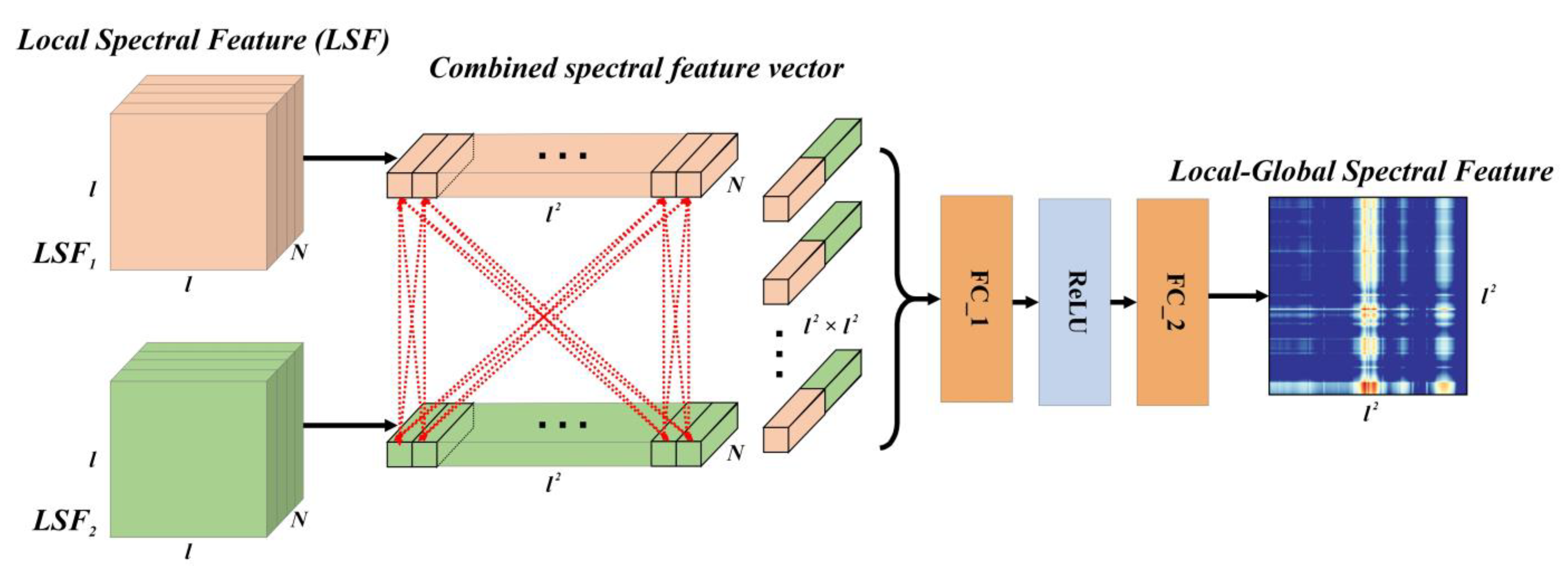
2.4. Global Spectral Feature Extraction Module
GSF is another effective spectral feature that connects bands with spans and describes the relative shape of the spectral curve. To extract the GSF, the GSFEM was proposed and its characteristics are presented below.
Considering the characteristics of GSF, which only depend on the spectral values between bands and are independent of the distance, in the GSFEM, the spectral bands were scattered and combined in pairs. Due to the relationship complexity between bands, in the GSFEM, the data-driven method was used to directly and automatically learn the construction of inter-band features, rather than a manually designed method, as shown in
Figure 4.
The input of the GSFEM is
LSF1 and
LSF2 and was obtained using the LSFEM, where each pixel represents an
N-D feature of one band. Pixels in
LSF1 and
LSF2 were combined to model GSF. If the pixel of row
i and column
j in
LSF1 is
Pij, and the pixel of row
i′ and column
j′ in
LSF2 is
P′
i′j′, the combined spectral feature vector of these two pixels (bands) would be
PP′
ii′jj′, whose size is 2 ×
N.
PP′
ii′jj′ represents an input into a network with two fully connected (FC) layers to compute the GSF of the two target bands. By traversing all combinations of bands in
LSF1 and
LSF2 and modeling them using the network, a feature map with a size of
l2 ×
l2 can be obtained. The generation of this map includes the extraction of LSF and GSF and their fusion, which gives the map the potential to express local as well as global spectral features. Thus, we refer to it as LGSF. Equation (2) shows the modeling process of the pixels of rows
a and
b in LGSF from
Pij and
P′
i′j′ in
LSF1 and
LSF2, where
is the concatenation operation,
FC1 and
FC2 are the two FC layers, and
R is the ReLU layer. Equation (3) shows the correspondence between subscript parameters.
2.5. The Loss Function for Spectral Feature Optimization
In LSFEM, the LSF is extracted through the convolution operation, whereas in GSFEM, the GSF is further superimposed on the LSF to obtain the final LGSF that contains both local and global feature information. Obviously, the quality of LGSF depends on the feature extraction from the LSFEM and GSFEM, and is controlled by internal learnable parameters. For classification tasks, an effective feature is supposed to have a high inner-class similarity but a low inter-class similarity. To move towards this goal, in this study, inspired by info noise contrastive estimation loss (infoNCE loss) in the contrastive learning domain, we designed the SFOL to constrain the update direction of parameters in LSFEM and GSFEM.
LGSF was considered as the input of a CNN (introduced in
Section 2.6) for classification with a batch size of
B. After a series of convolutions, pooling, and global average pooling layers, a group of feature vectors (FVs) with a size of
B ×
K was obtained, where
K is the channel number of the last convolution layer. The FVs are high-level abstract representations of LGSF and are directly input into a classifier (e.g., the FC layer) to determine the final classification result. Thus, it is necessary to maximize the differences between the classes of the FVs.
Next, if
m and
n are two training samples in one batch, the category consistency as well as similarity of their FVs were computed. By traversing all sample pairs, a matrix of category consistency (
Mcc) and a matrix of similarity of FVs (
Msim) can be obtained as described by Equations (4) and (5), whose sizes are both
B ×
B.
C,
Norm, and
represent the class of samples, normalized operations, and matrix multiplication, respectively.
Sample pairs with the same category were defined as positive samples, while those with different categories were defined as negative samples. Based on
Mcc and
Msim, the similarity between positive samples (
SSpos) and negative samples (
SSneg) can be computed using Equations (6) and (7):
where
I is the identity matrix used to eliminate the influence of sample pairs composed of the same sample (diagonal elements).
The
SSpos was averaged and concatenated with the
SSneg to form a new similarity vector (SV). In SV, the first element is the average similarity of all positive samples, and the other elements are the similarities of the negative samples. To increase the similarity between positive samples and reduce the similarity between negative samples, the value of the first element of the SV should approach 1, whereas that of the other elements should approach 0. This is similar to the use of a one-hot code to represent the first class in a classification task. Therefore, we created a pseudo-classification task, whose input is the SV divided by a normalized parameter (i.e., the temperature parameter in the infoNCE loss and was set to 0.07, which is widely used in relevant studies [
37]), and label is the one-hot code of the first class, to auxiliary optimize the parameters with the cross-entropy loss. In addition, the length of the SV may change significantly because the number of negative samples is not fixed in a batch. To fix the SV length, the top 20 negative samples with the highest similarity were selected because the negative samples with higher similarity were more likely to confuse the classifier and need more attention.
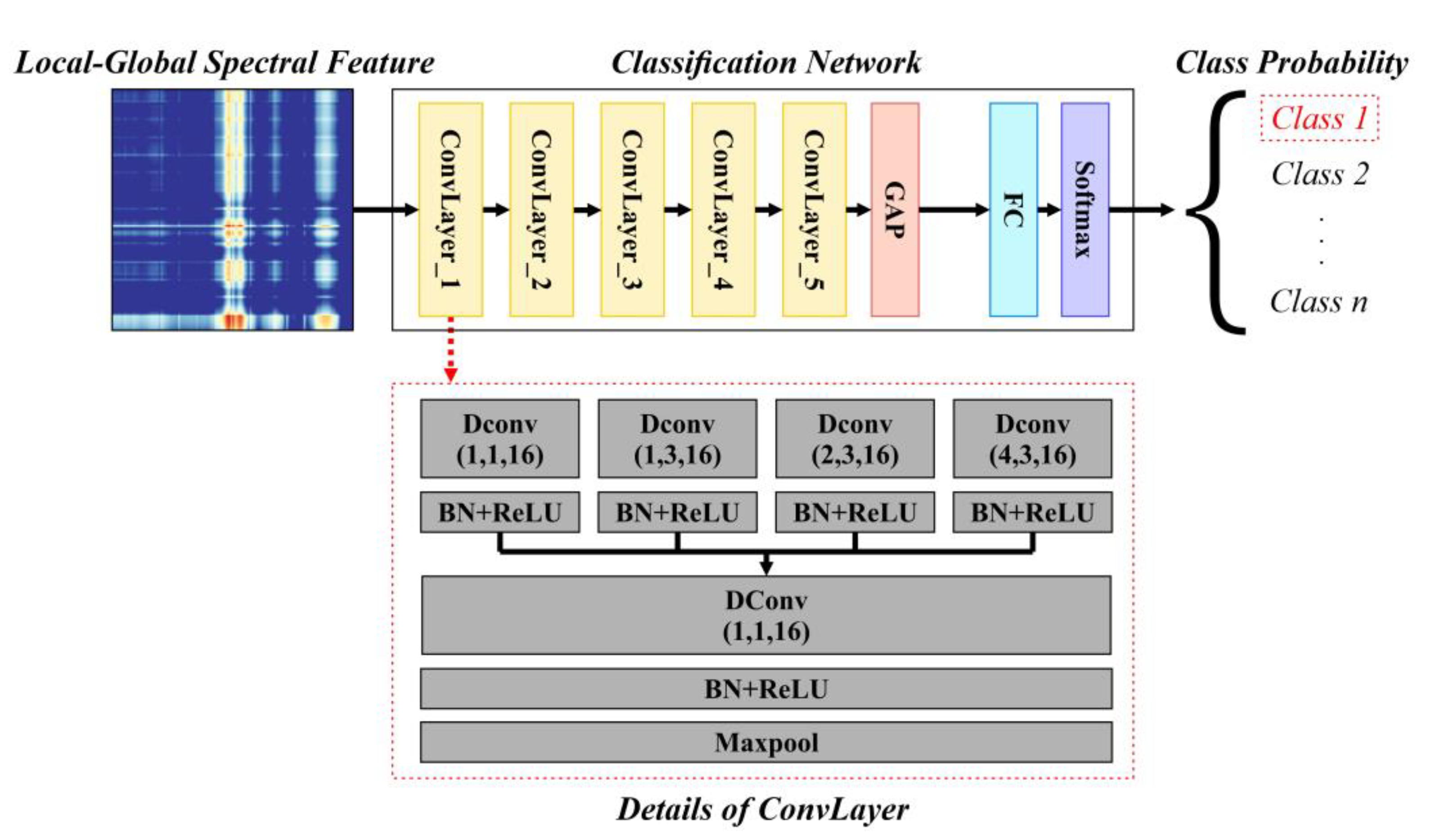
2.6. Dilated Convolution-Based Network
After the processing steps in
Section 2.2,
Section 2.3,
Section 2.4 and
Section 2.5 the spectral vector (spectral curve) of a single pixel is represented by a 2D LGSF image. This LGSF image was further classified to obtain the pixel categories. To better utilize the information hidden in the LGSF, a CNN based on dilated convolution was designed and used for classification, as the dilated convolution can significantly enlarge the receptive field and extract multiscale image features [
38].
The overall architecture of the CNN is shown in
Figure 5, which takes the LGSF as input and consists of five convolution layers (‘ConvLayer’ in
Figure 5), one global average pooling layer (‘GAP’ in
Figure 5), one fully connected layer (‘FC’ in
Figure 5), and one softmax layer (‘Softmax’ in
Figure 5). Each ConvLayer contains four dilated convolutions (‘Dconv’ in
Figure 5, the numbers in parentheses represent the dilation rate, kernel size and output channel, respectively) with various dilation rates and kernel sizes but the same number of output channels to extract multiscale features. Following batch normalization and ReLU (‘BN + ReLU’ in
Figure 5), these features were concatenated and fused by another dilated convolution. Max pool (‘Maxpool’ in
Figure 5) was used to decrease the feature size, whose results are the output of the current ConvLayer as well as the input of the next ConvLayer. The features after the five ConvLayers as well as the GAP layer were fed into a FC layer for classification, which contains one linear layer with an input size of 16 and an output size that is the same as the class number. The cross-entropy loss function was used for optimization.
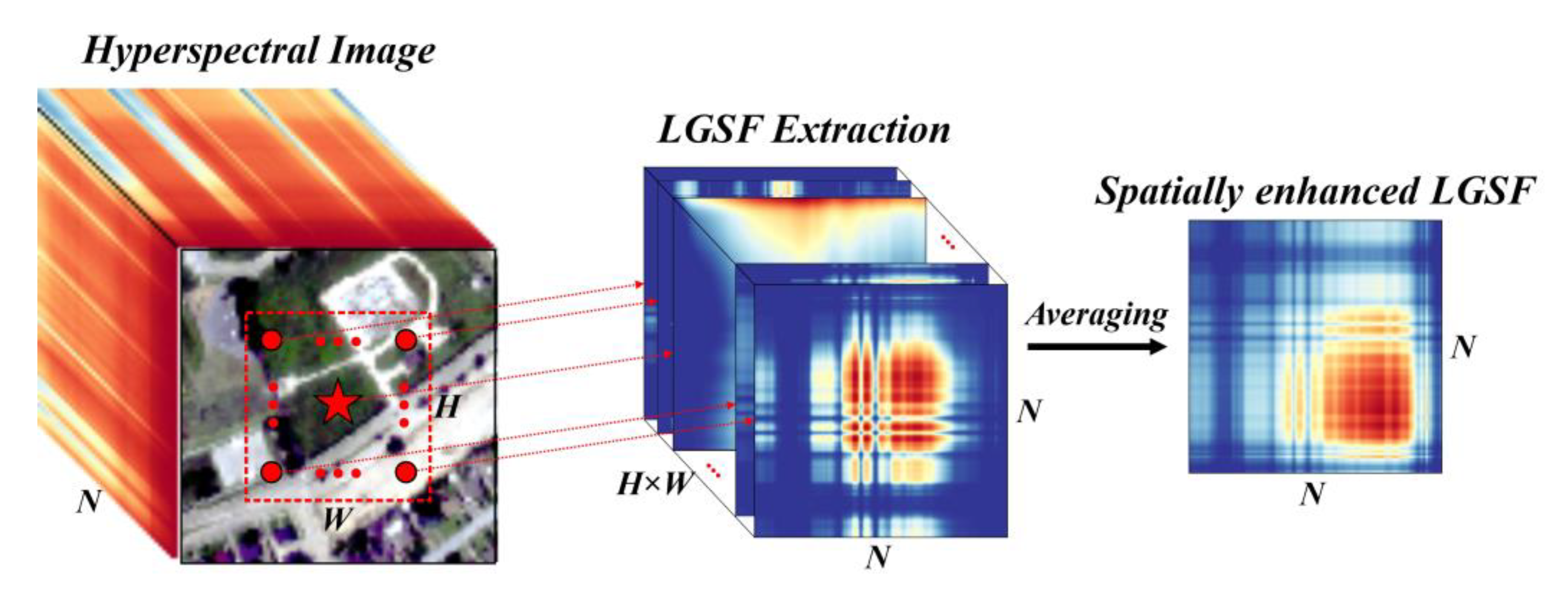
2.7. Enhancement of LGSF with Spatial Relation
In the above sections, we introduced the process of extracting the LGSF and using a CNN to obtain the classification results. However, this pattern is applicable only when the input is the spectral vector of a single pixel. Considering the noise interference in HSI, introducing spatial constraints on the LGSF has a significant positive effect on improving robustness.
To enhance the LGSF at the spatial level, we defined a spatial window in the HSI, and the LGSF of each pixel in the spatial window was combined. Suppose that the size of the HSI patch in the spatial window is
H ×
W ×
N, where
H and
W are the height and width of the spatial window, respectively, and
N is the band number of the HSI. The LGSF for each pixel in the HSI patch was extracted to a size of
N ×
N ×
HW. We used a simple and effective fusion method, namely averaging, to directly combine and fuse the LGSF and obtain the spatially enhanced LGSF with a size of
N ×
N × 1, as shown in
Figure 6. The spatially enhanced LGSF was used as an input feature of the network introduced in
Section 2.6 for classification, the result of which represents the class of the center pixel in the HSI patch.
4. Results and Discussion
Each method listed above was trained and modeled until convergence, and the PA, OA, AA, and KC were used to measure their accuracies. The PA describes the accuracy of each class, and a higher PA indicates a more accurate result for the corresponding class. The OA describes the accuracy of all pixels, and a higher OA indicates that more pixels are classified correctly. However, OA can be affected by classes in large numbers. AA is the average PA of each class, and a higher AA indicates a better accuracy in all classes. KC is a comprehensive evaluation index, and a higher KC indicates not only a higher accuracy but also less misclassification of each class.
Table 5,
Table 6,
Table 7 and
Table 8 report the PA, OA, AA, and KC of all methods on the Houston 2013, Houston 2018, Pavia University, and Salinas Valley datasets, respectively. The highest accuracies are highlighted in bold. Overall, our proposed LGSF outperforms all comparison methods and has the highest OA, AA, and KC on the four datasets. The SVM has the lowest accuracy among the comparison methods. By combining the results of these methods with their characteristics, we observed that sufficiently describing the spectral features leads to a higher accuracy. Moreover, the comparison results show that introducing spatial information can promote the classification accuracy greatly. However, we also discovered that the spatial and spectral features are suitable for different classes, which means that spatial and spectral features should be selectively used according to class characteristics.
4.1. Comparison of Different Datasets
For the Houston 2013 dataset, the OA, AA, and KC of our LGSF were 85.30%, 87.17%, and 84.09%, respectively (
Table 5). Compared with all baselines, LGSF showed great advantages in terms of overall statistical metrics. There were seven classes in which LGSF surpassed the other methods. Most classes in this dataset achieved 80% accuracy using LGSF, except for synthetic grass and water soil. The highest accuracy of these two classes was obtained using R2D and SVM, which are both methods based only on spectral information. Houston 2013 is a city dataset whose classes cover a wide range, and the spectral properties of classes vary greatly. Thus, this dataset was suitable for testing the applicability of these methods. Classification methods have poor applicability when they show high accuracy on a few classes, but low accuracy on other classes, such as SVM. Our LGSF surpassed the other methods on seven classes and has the highest AA, which reveals its effectiveness.
For the Houston 2018 dataset, the OA, AA, and KC of our LGSF were 76.09%, 65.24%, and 70.41%, respectively (
Table 6), which were the highest among the evaluated methods. There were 12 classes in which LGSF surpassed the other methods, which was also the highest among all methods. In the Houston 2018 dataset, the accuracy fluctuated greatly among different methods, with a 50% difference between the highest and lowest accuracy, and there was one class in which each method had an accuracy of less than 10%. The reason may be that this dataset is relatively complex owing to its numerous classes and small band number, which is insufficient spectral information for distinguishing targets. The superiority of our method on such datasets verifies the effectiveness of the proposed method for spectral utilization.
For the Pavia University dataset, the OA, AA, and KC of our LGSF were 98.94%, 97.95%, and 98.59%, respectively (
Table 7), which were the highest among the evaluated methods. There were six classes in which LGSF surpassed the other methods and the accuracies of the remaining classes were very close to the highest accuracy. The LGSF accuracy on each class was greater than 95%, which shows great advantages compared with other methods. The accuracy for this dataset was much higher than that for the Houston 2013 and Houston 2018 datasets, which are under the city scenario. The reason may be that the spatial coverage and category numbers of this dataset are both smaller than those of the above two datasets.
For the Salinas Valley dataset, the OA, AA, and KC of our LGSF were 98.23%, 99.13%, and 98.03%, respectively (
Table 8). In this dataset, a few classes achieved 100% accuracy using various methods. LGSF had the best accuracy for nine classes, and the accuracies of most class were close to 99%. This may be because this dataset is a vegetation dataset, which is relatively simple compared to the above three datasets under the complex city scenario. Moreover, sufficient spectral information in this dataset (containing most bands among the four datasets) is also helpful for classification.
4.2. Comparison of Different Methods
Comparing the performances of methods that only use spectral information (i.e., SVM, 1D CNN, and R2D), we saw that the accuracy increases significantly with the refinement of the design of spectral features (SVM with no LSF, 1D CNN with LSF, and R2D with optimized LSF) on all datasets, which emphasizes the importance of LSF as well as the effectiveness of transforming the 1D spectral vector into a 2D spectral image.
Comparing the performances of methods that contain spatial information (i.e., 2D CNN, 3D CNN, MCM, and LGSF), it is surprising that 2D CNN has a better accuracy than 3D CNN on all datasets, which implies that simply combining spatial and spectral information using 3D convolution may not be optimal. We noticed that the difference in network structure (e.g., layer number and feature number) can also lead to this situation; however, it also means that 3D CNN requires a more refined design than 2D CNN.
Comparing the performance of methods with and without spatial information, we observed that there is considerable salt and pepper noise in the classification results of methods with no spatial information (
Figure 7c–e,
Figure 8c–e,
Figure 9c–e and
Figure 10c–e), whereas the classification results of methods with spatial information (
Figure 7f–i,
Figure 8f–i,
Figure 9f–i and
Figure 10f–i) are smoother. This demonstrates that introducing spatial information can improve robustness.
Comparing the performance of the LGSF with other methods, we observed that the MCM and LGSF exhibited the top two accuracies on almost all datasets. The common point between them is the use of GSF, highlighting its importance. LGSF surpasses MCM on all datasets, and MCM has an abnormal drop in the Houston 2013 dataset, which may be due to the lack of LSF or the limitation of manually designed GSF in MCM. It can be concluded that with the combination of LSF, GSF, and spatial information, our LGSF can obtain better accuracy of HSI classification. Moreover, in the Houston 2013 dataset, there was a large dark area caused by clouds (marked with a red box, where most classes were related to urban scenes). The spectral information of ground objects is strongly changed in this area, and most methods misclassified this area into classes that appear dark in the image, such as water (
Figure 7d,e) or synthetic grass (
Figure 7c,f,g). However, LGSF (
Figure 7i) classified this area into residential and parking lots, which are close to the original classes (all belong to the urban scene). This may be because the GSF in LSGF describes the relative shape of the spectral curve, which shows a certain similarity between the urban classes. This also means that LGSF has a better spectrum understanding ability. A similar situation also appears in the stadium seat class (marked with a red box) in the Houston 2018 dataset. Most comparison methods misclassified these pixels into classes with similar artificial materials, such as cars and trains (
Figure 8c,e–g), or even water (
Figure 8d,h), because of the existence of shadows. Our LGSF (
Figure 8i) retained a good classification ability and classified this area with high accuracy.
4.3. Comparison of Different Land Use Classes
The above datasets can be roughly divided into four common land use classes: artificial targets, vegetation, water, and bare soil.
For the artificial targets, most road classes (e.g., road and highway in Houston 2013, and roads, sidewalks, crosswalks, and highways in Houston 2018) are associated with higher accuracy when using methods that contain spatial information (e.g., 2D CNN) than those methods that rely only on spectral information (e.g., SVM, 1D CNN, and R2D). This may be due to the strong spectral similarities of these artificial roads, while their spatial texture features are more distinguishable than the spectral features. Thus, for road classes, the use of spatial features is more beneficial than spectral features. The same principles apply to residential classes whose spectral information can be messy and whose spatial information is more representative. However, for other artificial targets made of unique materials (e.g., the railway in Houston 2013 and Houston 2018), spectral-based methods have better classification capabilities than spatial-based methods.
For vegetation, mainly in the Salinas Valley and Pavia University datasets, we discovered that the difference in accuracy between methods is much smaller than that of other classes, which indicates that the classification accuracy of vegetation will not be too poor using any of the methods to classify the vegetation. However, under the demands of refined vegetation classification, it is still important to design appropriate spectral features to reflect the characteristics of different vegetation types. For example, the Lettuce_romaine_wk series in the Salinas Valley dataset has an accuracy of over 90% for most methods. However, methods that use LSF or GSF have more stable and accurate results.
For water, SVM obtained the highest accuracy in Houston 2013 (e.g., water soil) and Houston 2018 (e.g., water). However, the OA, AA, and KC of SVM were the lowest for both datasets. This is an interesting phenomenon, and it indicates that the water class has completely different characteristics from those of the other classes. MCM and LGSF obtained the second highest accuracy for the water class in Houston 2013 and Houston 2018, respectively, both of which contain GSF. Considering that SVM uses the original spectral curve and the GSF is a description of the overall shape of the spectral curve, we believe that more global spectral information (complete spectral information or GSF) should be used to classify water, rather than the local spectral information.
For bare soil (the soil in the Houston 2013, the bare earth in the Houston 2018, and bare soil in the Pavia University dataset), MCM and LGSF obtained the best results. In particular, the accuracy of MCM was the lowest in the Houston 2013 dataset; however, its accuracy for soil was over 99%. Both MCM and LGSF contain GSF, which means that GSF is a necessary feature for identifying bare land. Moreover, we also noticed that introducing spatial information is helpful for improving the accuracy of bare soil, as the accuracies of 2D CNN and 3D CNN were higher than those of SVM, 1D CNN, and R2D. This may be because the heterogeneity of bare soil is relatively high, and there are numerous pixels belonging to other classes in the bare soil, such as grass, which confuse classifiers. The above analysis shows that the classification of bare soil should rely on spatial information as well as GSF.
4.4. Comparison of Ablation Experiments
To further demonstrate the effectiveness and contribution of each component in this paper, a series of ablation experiments were conducted, details shown in
Table 9. The AE_LGSF contained the complete components of this paper. Based on AE_LGSF, the AE_2D removed the 2D transformation and used the original 1D spectral vector; the AE_LSF removed the LSFEM; the AE_GSF removed the GSFEM; the AE_SFOL removed the SFOL and used only cross-entropy loss for classification; the AE_DCBN used the traditional convolution-based network instead of the dilated convolution-based network (DCBN) for classification with same number of feature maps in each layer; the AE_SPAT removed the spatial enhancement. By comparing each ablation experiment that removed a specific component with the AE_LGSF, the contribution of the removed component to the classification results can be verified. The results of these ablation experiments on four datasets are shown in
Table 10,
Table 11,
Table 12 and
Table 13. It can be seen from the tables, when any component is removed, that the classification accuracy decreases to a certain extent. In the following, we discuss the results from three perspectives (data input, feature extraction and feature classification), which cover the entire process of HSI classification.
For the data input part, the directly related experiment is the AE_SPAT. There is a large decrease in accuracy of AE_SPAT, which indicates the importance of spatial enhancement. The reason is that the extraction of spectral features is the statistical induction based on stable spectral patterns. However, the ubiquitous noise information in HSI makes the spectral value of a single pixel fluctuate within a certain range, resulting in a lack of stable characterization. Therefore, by introducing the spatial constraints and establishing a relationship between the spectra of surrounding pixels and central pixels, the effect of noise can be reduced and the statistical nature of the spectrum can be enhanced, thereby extracting more stable features and improving classification accuracy. Thus, it is important to using the spatial information to enhance and stabilize spectral information before feature extraction in HSI classification.
For the feature extraction part, the directly related experiments are the AE_2D, AE_LSF, AE_GSF and AE_SFOL. (1) The decrease of AE_2D reveals the positive effect of 2D transformation on spectral feature extraction, which can be explained in two perspectives. From a row perspective, in the 2D spectral image, the LSF that extracted by 1D convolution are still preserved in the 2D receptive field. Moreover, the relationship between LSF in different rows can be further mined and combined, which means that the 2D pattern can obtain more diverse spectral features without losing the LSF obtained by 1D pattern. From a column perspective, in the 2D spectral image, the band combinations of columns are regular, and express another LSF (i.e., LSF of uniformly spaced K bands, where K is the width of 2D image). This is similar with the idea of dilated convolution that enlarge the receptive fields with the dilated rate. In this way, the 2D pattern is conducive to capturing a wider range of LSF, and produces more diverse spectral features. (2) Comparing with the AE_LSF and AE_GSF (using the GSF and LSF for classification respectively), the AE_LSF outperformances the AE_GSF in three datasets, which indicates that the GSF may have a greater impact on classification than LSF. Therefore, when using CNN for HSI classification, it is necessary to jump out of the local receptive field of convolutional kernels and effectively design long-distance or distance-independent global features. (3) The decrease of AE_SFOL demonstrates the contribution of SFOL, which guides the network to automatically optimize LGSF for better category separability.
For the feature classification part, the directly related experiment is the AE_DCBN. The decrease of AE_DCBN indicates that based on good features, it is also important to use a good classifier for analysis and classification.
4.5. The Analysis and Discussion of Local and Global Characteristics of LGSF
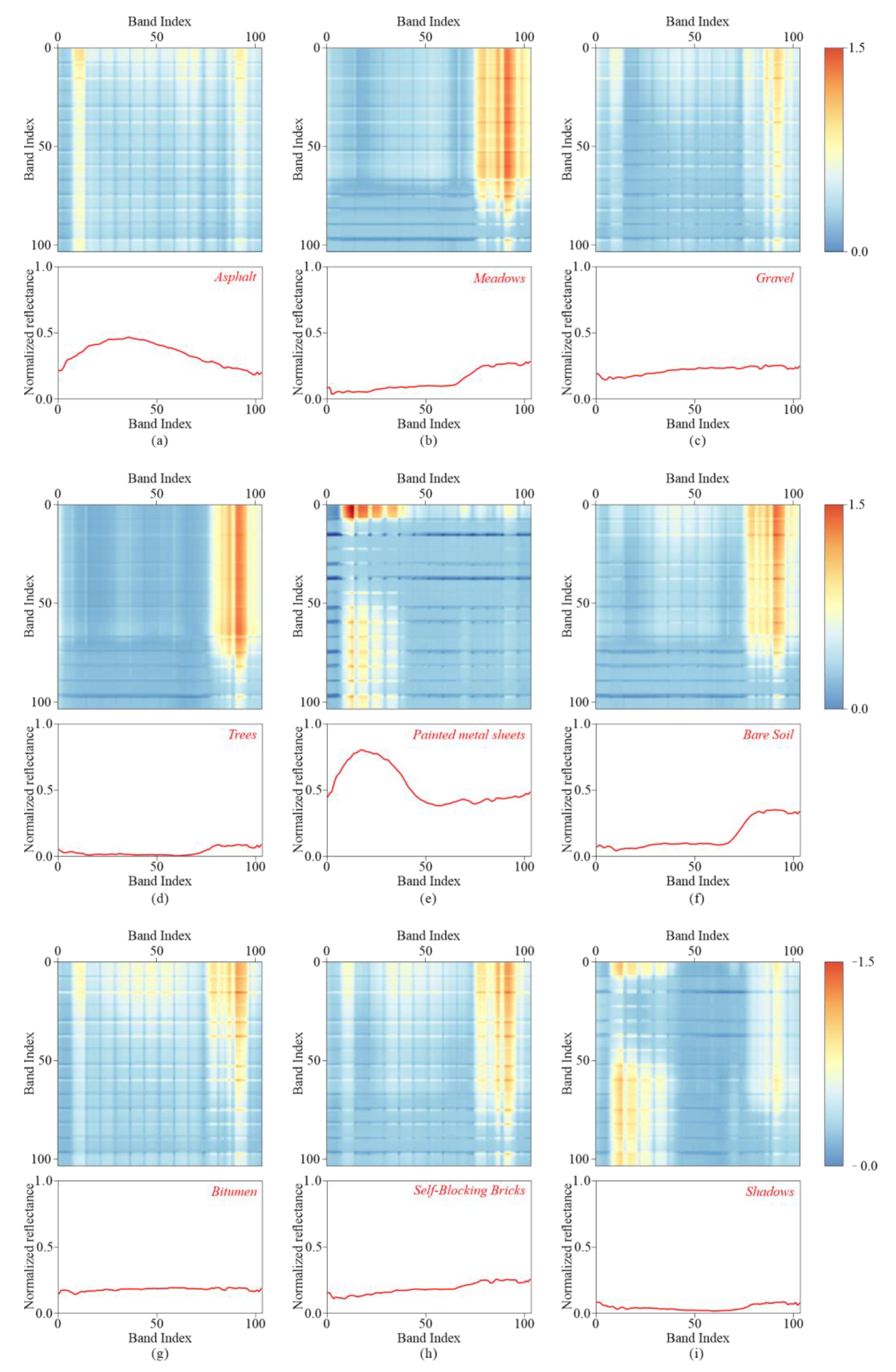
Figure 11 shows the Pavia University dataset as an example of the extracted LGSF with the original spectral curve of each class. In LGSF maps, the pixels in each row and column represent the relationship between the spectra of the corresponding bands. For example, the pixel in rows 1 and columns 2 represents the relationship between bands 1 and 2. The redder areas indicate high values and can be roughly considered as activated areas, which contain more important features.
Analyzing the LGSF maps from a local perspective, we found that a larger local variation in the spectral curve causes a higher activation value. In
Figure 11, the asphalt and gravel classes (
Figure 11a,c) show activation in the LGSF maps where the corresponding reflectivity in the spectral curves fluctuate, while the shadow class (
Figure 11i) activates the LGSF map on the left side of the spectral curve, where the reflectivity tends to decrease. This indicates that the local rapidly changing spectra in the spectral curve are more capable of representing the characteristics of the targets. This is consistent with the experience because the rapid change in a certain local part is generally caused by the unique nature of the targets. For example, for vegetation, the most typical feature is the rapid change in reflectivity between the red and near-infrared bands, which is also the basis of normalized difference vegetation index (NDVI). Bitumen is an interesting class (
Figure 11g), whose reflectivity is generally flat, with only a slight jitter at the front and end of the curve. Even so, our method can effectively extract spectral features to represent the characteristics of the spectral curve.
Analyzing the LGSF maps from a global perspective, we found that the larger global variation in the spectral curve has a higher activation value, which is most obvious in the painted metal sheet class (
Figure 11e). The spectral range of pixels with large activation values (on the left of the LGSF maps) corresponds to the reflection peak on the spectral curve. The spectra of the reflection peaks are greatly activated when combined with all other spectra, except for their adjacent spectra, because their values are similar to the surrounding spectra and differ greatly from others. The same phenomenon can also be observed in the meadows, trees, and bare soil classes (
Figure 11b,d,f). The self-blocking bricks (
Figure 11h) are a special class, whose reflectivity gradually increases with an increase in wavelength, which means that the farther the distance of the wavelength, the greater the difference in reflectivity. Therefore, in the LGSF maps, the activation value of the spectra with the farthest distance (the front and last bands) is the largest (the activation area on the top right), and the value gradually decreases with the decrease in spectral distance (the value gradually decreases from top to bottom and from right to left).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}