
ISTD-PDS7: A Benchmark Dataset for Multi-Type Pavement Distress Segmentation from CCD Images in Complex Scenarios

Abstract
1. Introduction
- A large-scale extendable DIS dataset—ISTD-PDS7—containing 18,527 CCD images and 7 types of pavement distress, was built and annotated manually by 4 experts in the field of pavement distress detection. Finally, highly detailed binary segmentation masks were generated. The dataset was analyzed in detail from three aspects: image dimension, image complexity, and annotation complexity.
- Based on the new ISTD-PDS7 dataset, we compared the cutting-edge segmentation models with different network structures and made a comprehensive evaluation and analysis of their pavement distress segmentation performance. These results will serve as the baseline results for future works.
- We briefly review the numerous previously published datasets. We also describe the detailed evaluation and comparative experiments conducted between these datasets and ISTD-PDS7, and propose their comparison results in crack segmentation.
2. Related Work
2.1. Automated Crack Detection
2.2. Multi-Type Distress Segmentation Approaches
2.3. Existing Datasets for Pavement Distress Segmentation
- CrackTree260 [30]: The CrackTree260 dataset consists of 260 pavement crack images with a size of 800 × 600 pixels, for which the pavement images were captured by an area-array camera under visible light illumination.
- CrackLS315 [30]: The CrackLS315 dataset contains 315 road pavement images captured under laser illumination. These images were captured by a linear-array camera, at the same ground sampling distance.
- CRKWH100 [30]: The CRKWH100 dataset contains 100 road pavement images captured by a linear-array camera under visible light illumination. The linear-array camera captures the pavement at a ground sampling distance of 1 mm.
- CFD [37]: The CFD dataset consists of 118 iPhone 5 images of cracks in the urban pavement of Beijing in China, where each image is manually labeled with the ground-truth contour and the size is adjusted to 480 × 320 pixels. The dataset also includes a few images that are contaminated by small oil spots and water stain noise.
- Crack500 [38]: The Crack500 dataset consists of 500 2000 × 1500 pixel crack images, with a few containing oil spots and shadow noise.
- AigleRN [39]: The AigleRN dataset contains 38 preprocessed grayscale images of pavements in France, with the size of one half of the AigleRN dataset being 991 × 462 pixels, and the size of the other half being 311 × 462 pixels.
- GAPs [53]: In 2017, a freely available large pavement distress detection dataset called the German Asphalt Pavement (GAPs) dataset was released by Eisenbach et al. [51], which has since received considerable attention from several research groups (e.g., [54,55,56]). The GAPs dataset was the first attempt at creating a standard benchmark pavement distress image dataset for DL applications. It includes 1969 grayscale pavement images (1418 for training, 51 for validation, and 500 for testing) with various distress types, including cracks (longitudinal/transverse, alligator, sealed/filled), potholes, patches, open joints, and bleeding [53]. Unfortunately, the method of bounding box annotation is not very friendly for semantic segmentation tasks. To solve this problem, Yang et al. [38] selected and annotated 384 crack images from the GAPs dataset at the pixel level and built a new segmented dataset called GAPs384. It is worth noting that all the images in the GAPs dataset were collected from the pavements of three different German federal highways. The shooting conditions were dry and warm, so the GAPs dataset is suitable for studying the segmentation and extraction problems of pavement distress in urban highways and expressways with good highway conditions. More recently, Stricker et al. [22] released the publicly available GAPs-10 m dataset for semantic segmentation. This dataset contains 20 high-resolution images (5030 × 11505 pixels, each corresponding to 10 m of highway pavement) that cover 200 m of asphalt roads with different asphalt surface types and a wide variety of distress classes [22]. The corresponding multi-class distress labels were annotated by experts; this dataset is currently the only publicly available dataset with high-resolution images.
- Others: Although some of the larger datasets recently published, such as the dataset made up of 700K Google Street View images [57] or the Global Road Damage Detection Challenge (GRDDC) 2020 dataset [58], are mostly used for object detection tasks in severely damaged images as they do not have the resolution level required for highway damage condition assessment.
3. ISTD-PDS7 Dataset
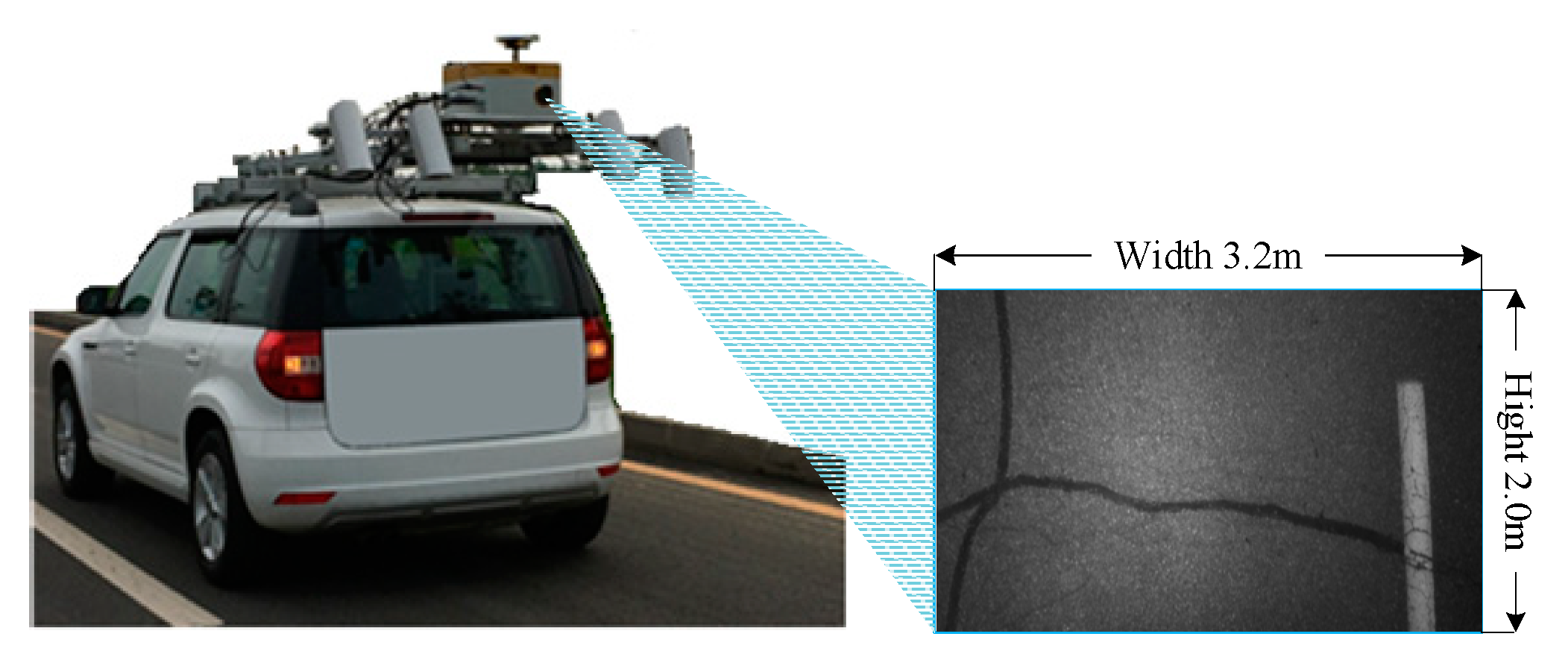
3.1. Data Collection and Annotation
- We covered more categories while reducing the number of “redundant” samples with simple structures that are already included in the other existing datasets. The focus was on increasing the scene richness of each type of distress sample, which is crucial for improving the reasoning ability of the network model. As shown in Figure 3, we screened seven types of distress sample images, where each type of distress covered nine types of complex scenes (Figure 4).
- We enlarged the intra-type dissimilarities of the selected distress types by adding more diversified intra-type images (see Figure 4). First, the same distress type may appear with different lengths, widths, and topologies, due to the diversity of the distress formation mechanisms in rural pavements. Second, the appearance of road pavement distress is greatly affected by dust accumulation and humidity. For example, the black appearance of the crack and the white appearance of the crack shown in the first row of Figure 4. Finally, the vibration during the shooting also affects the clarity of the distress in the imagery.
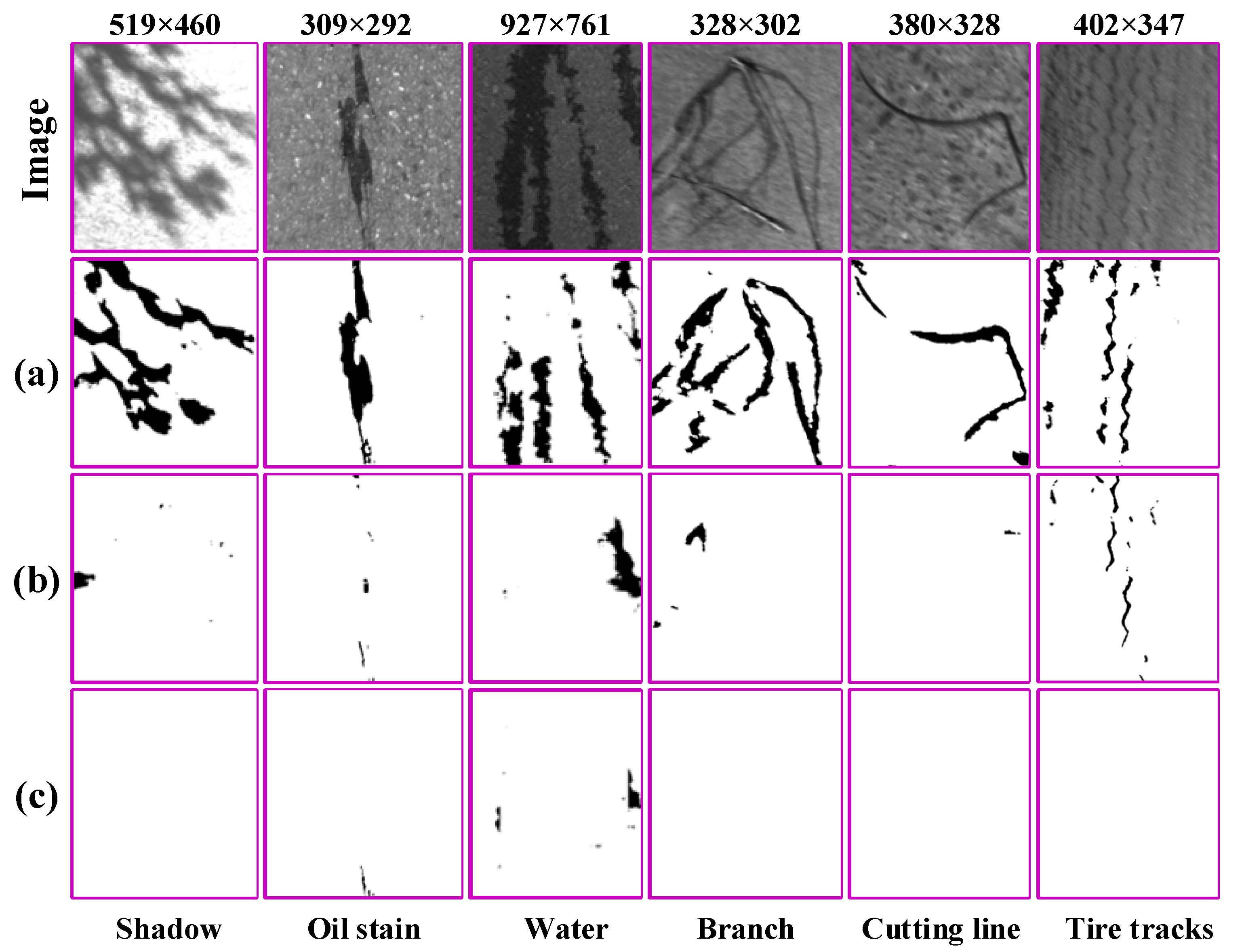
- We included more images that are highly similar to the road surface distress in terms of gray-level and texture characteristics, which are called negative samples, such as shadows, water or oil stains, dropped objects, pavement appendages, etc. (Figure 5). These are common in actual distress detection tasks, but they are ignored by the other datasets due to their complex types or collection difficulties.
3.2. Data Analysis
- For a deeper insight into the ISTD-PDS7 dataset, we compared the dataset with seven other related datasets: three crack segmentation datasets annotated by a single-pixel width, i.e., CrackLS315, CrackWH100, and CrackTree260 [30], and four datasets annotated manually by the actual width of the crack, i.e., AigleRN [39], CFD [37], CRACK500 [38], and GAPs384 [38]. The comparison was made mainly from the four metrics of image number, image dimension, image complexity, and annotation complexity, and they are described as follows: Image dimension is crucial to the segmentation task, as it directly affects the accuracy, efficiency, and computational cost of the segmentation [40].
- Image Complexity is described by the image information entropy (), which can quantitatively represent the difficulty of object recognition or extraction in complex scenes [60]. The (), where represents the proportion of pixels whose gray value is in the image measures the information contained in the aggregation features of the gray-level distribution in an image from the perspective of information theory. The greater the in an image, the more information the image contains [61,62].
- Annotation Complexity is described by the three metrics of the isoperimetric inequality quotient () [63,64,65], the number of distress contours (), and the number of points marked (). Among these metrics, , where and denote the distress perimeter and the region area, respectively. The represents the structural complexity of the labeled distress types. The is the number of closed contours involved in the labeling, which can quantitatively reflect the complexity of the topological structure of the distress. The metric is the number of labeling points needed to delineate the outline of the distress example [66], which can quantitatively reflect the fineness of the labeling and the labor cost.
3.3. Dataset Splitting
4. Baseline Methods
4.1. Methods
- SegNet [49]: The SegNet network achieves end-to-end learning and segmentation by sequentially using an encoder network and a decoder network. It can process input images of any size. VGG16 [67] without the fully connected layer is used as the encoding phase to achieve feature extraction. The sizes of the input images and the network parameters are reduced step by step through maximum pooling, and the pooling index position in the image is recorded at the same time. The decoding phase restores the resolution of the image through multiple upsampling. Finally, the semantic segmentation results are output by the SoftMax classifier.
- PSPNet [68]: The PSPNet network uses a pyramid pooling module (PPM) to aggregate contextual information from different regions to improve the ability to obtain global information. This network came first in the ImageNet Scene Parsing Challenge 2016, the PASCAL VOC Challenge 2012, and the Cityscapes test (2016).
- DeepLabv3+ [69]: At the decoder stage, atrous convolution is introduced to increase the receptive field, and atrous spatial pyramid pooling (ASPP) is used to extract multi-scale information. DeepLabv3+ achieved a test set performance of 89% and 82.1% without any post-processing on the PASCAL VOC Challenge 2012 and Cityscapes test (2018).
- U-Net [44]: The U-Net network performs skip-layer fusion for end-to-end boundary segmentation and formulates the training target with a single loss function. This model is the most commonly used model in medical image segmentation. We modified the padding mode to be the “same” so that the input and output image sizes remained the same.
- HRNet [70]: Differing from the above four methods, HRNet is a network model that breaks away from the traditional encoder-decoder architecture. HRNet maintains high-resolution representation by connecting high-resolution to low-resolution convolution in parallel and enhancing the high-resolution representations by repeatedly performing multi-resolution fusion across parallel convolution. In this way, it can learn high-resolution representations that are more sensitive to location.
- Swin-Unet [71]: Swin-Unet is a UNet-like pure transformer for image segmentation, using a transformer-based U-shaped encoder-decoder architecture with skip connections for local-global semantic feature learning.
- SegFormer [72]: An efficient encoder-decoder architecture for image segmentation, using multiple layers Transformer-Encoder to get multiscale features. At the same time, a lightweight multilayer perceptron (MLP) is used to aggregate semantic information of different layers. SegFormer has shown a state-of-the-art performance on the ADE20K dataset, performing better than the Segmentation Transformer (SETR) model [73], Auto-DeepLabv3+ [69], and OCRNet [74].
4.2. Loss Function Selection
4.3. Evaluation Metrics
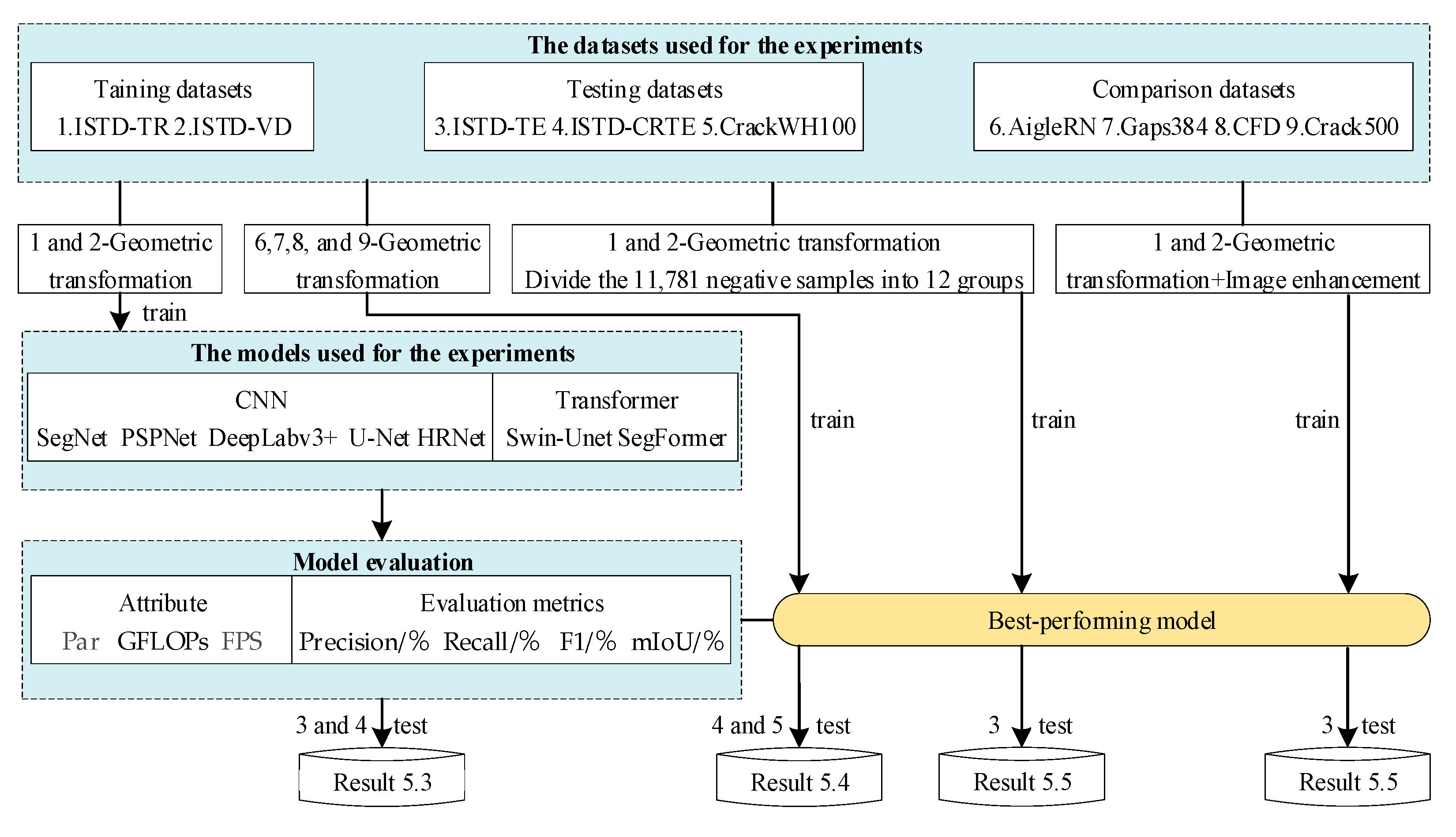
5. Experiments and Results
5.1. Implementation Details
5.2. Dataset Setup
- Baseline evaluation of datasets: As described in Section 3.3, ISTD-TR and ISTD-VD were used for the training and validation of the baseline evaluation networks. Data augmentation was performed to enlarge the number of distress samples in the training set, including vertical flip, horizontal flip, and flip and transpose, to balance the ratio of positive and negative samples. After the data augmentation, we obtained a training set of 30,475 images in total, containing 14,620 distress samples and 11,974 negative samples. It is worth noting that the data augmentation was not applied to the ISTD-TE or ISTD-CRTE. All the baseline models used ISTD-TE and ISTD-CRTE as the test sets to evaluate their performance in the multi-type of distress DIS task and crack segmentation task in complex scenarios.
- Dataset comparison: In this study, the best-performing model from the baseline assessment was used as the evaluation tool to make cross-dataset evaluations [80] of CFD [37], CRACK500 [38], AigleRN [39], and GAPs384 [38], which are labeled with the actual crack width. In order to ensure the fairness of the evaluation, we used the same data enhancement methods described above, and increased the training data size to about 14,600 pieces. CrackWH100 [30] and ISTD-CRTE were selected as the test sets. It must be noted that the images in the CrackWH100 dataset were acquired by a linear CCD camera, and we re-annotated their ground truth by the actual pixel width of the crack using LabelMe.
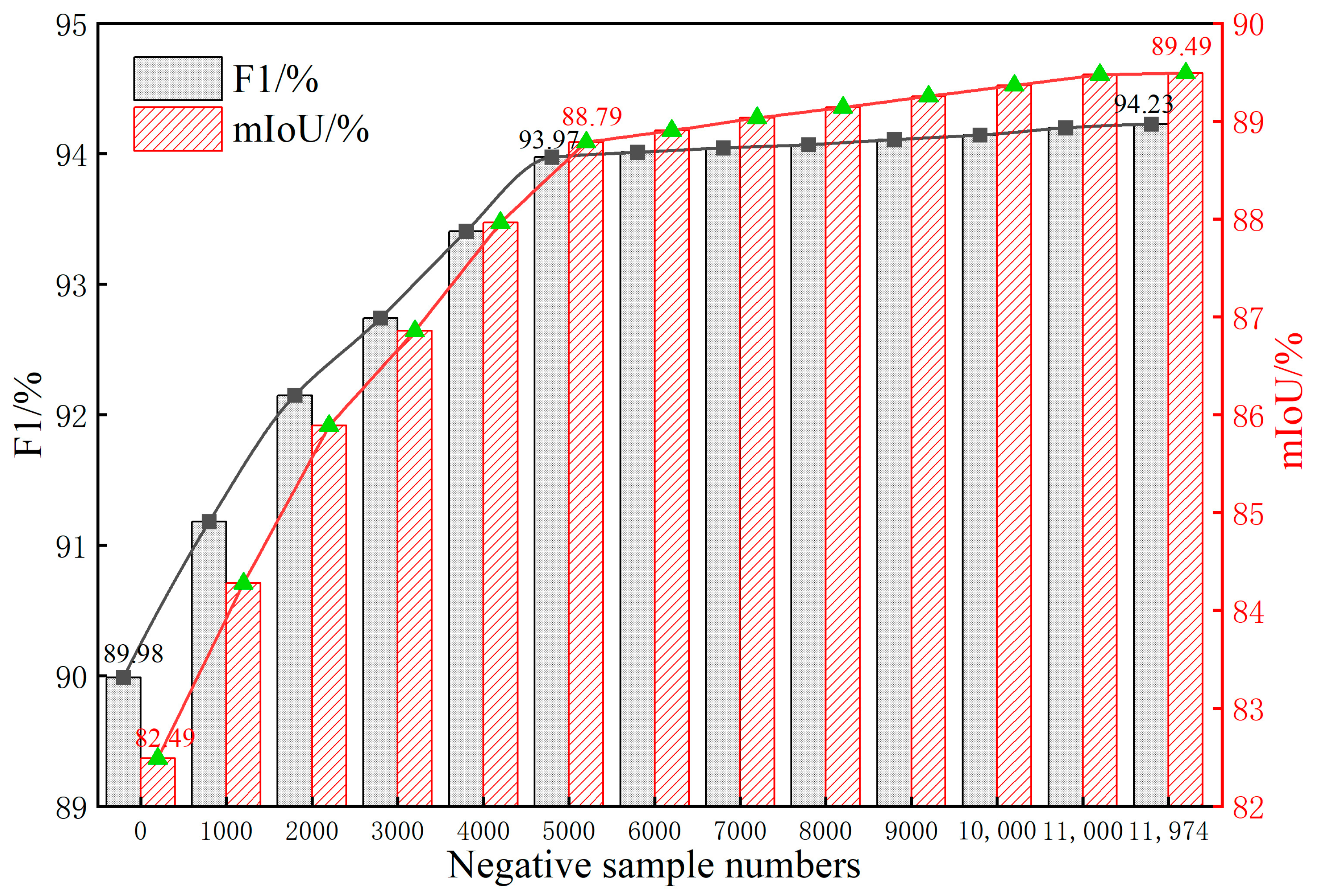
- Influence of negative samples and different data augmentation methods: We took the best-performing model in the baseline assessment as the experimental tool, randomly divided the 11,781 negative samples into 12 groups with roughly 1000 images per group and added one group of negative samples each time to participate in the model training. Then, we use two data augmentation methods, geometric transformation (vertical flip, horizontal flip, and flip and transpose) and image enhancement (shift scale rotate, random contrast, random brightness, blur, and CLAHE), on the training set to explore the influence of different data augmentation methods on the performance of the distress segmentation. Image geometric transformation simulates the change of direction and angle when an image is taken. Blur change takes into account the possible instability of the imaging camera when the light is low and the lens is unfocused. Brightness transition mainly enhances or weakens the illumination, considering the unstable situations that may occur in the case of insufficient light or severe exposure during shooting. The ISTD-TE dataset was taken as the test set in this part.
5.3. ISTD-PDS7 Benchmark
5.3.1. Quantitative Evaluation
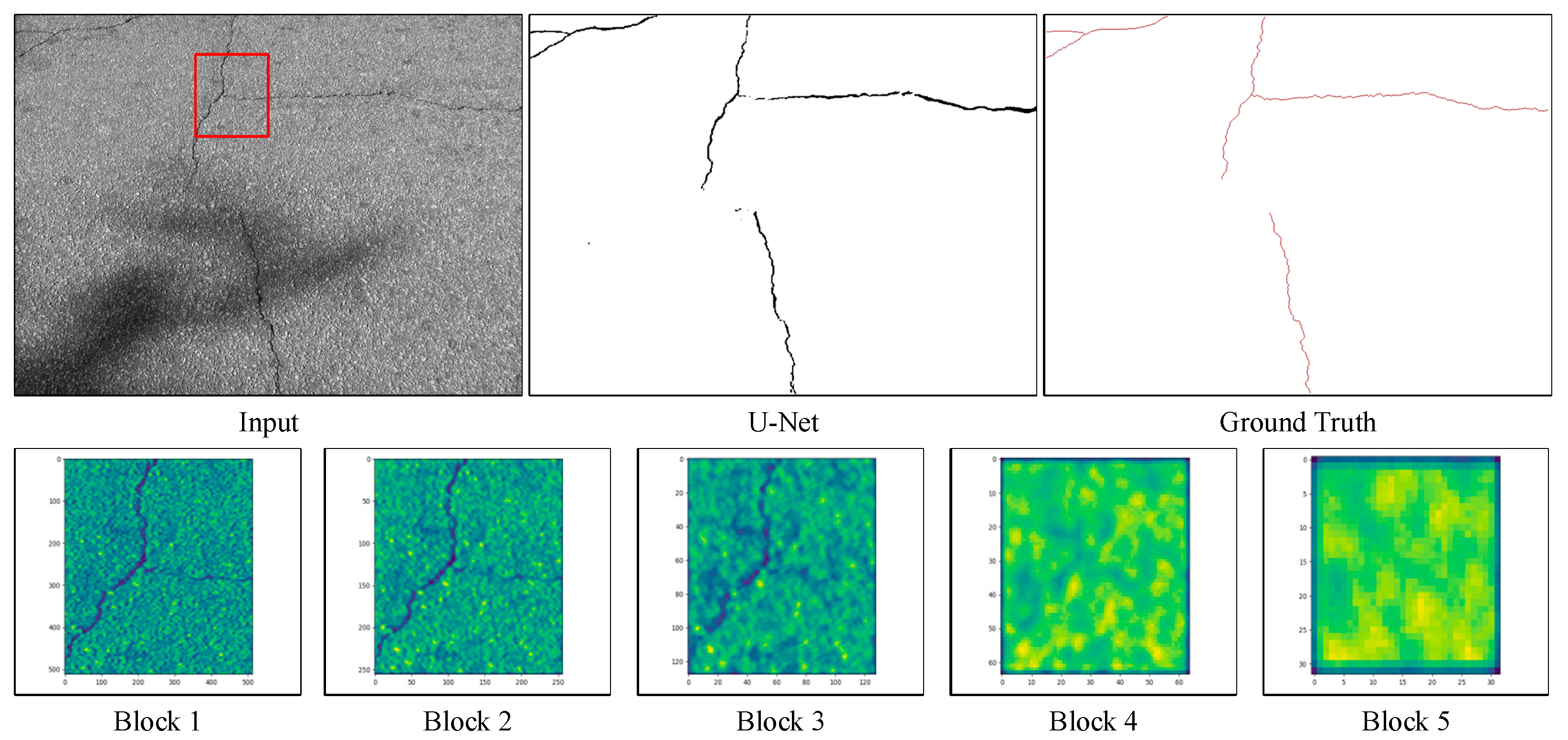
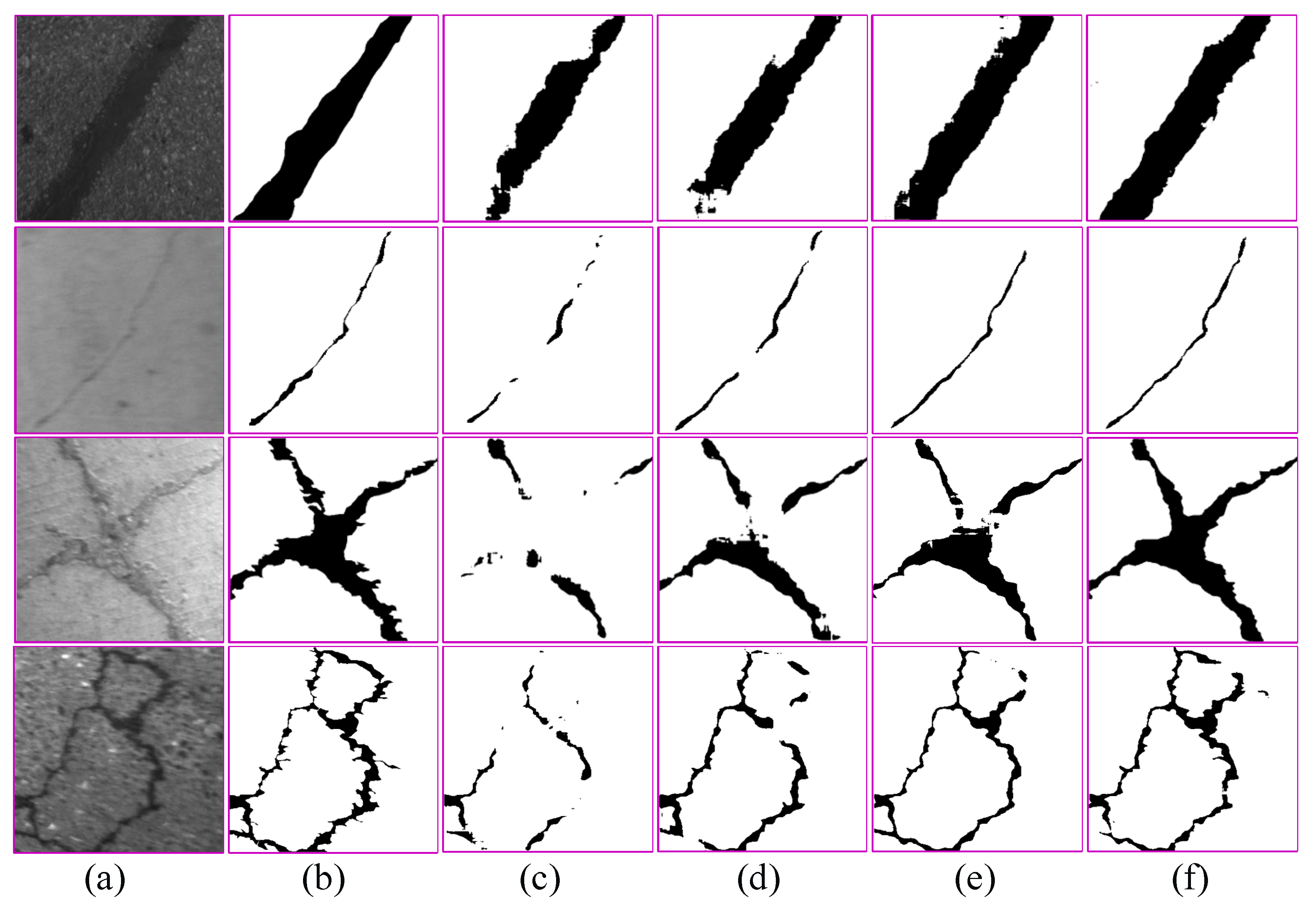
5.3.2. Qualitative Evaluation
5.4. Comparison with the Public Datasets
5.5. Influence of Negative Samples and Data Augmentation Methods
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xiao, C.; Zhang, X.F.; Li, B.; Ren, M.; Zhou, B. A new method for automated monitoring of road pavement aging conditions based on recurrent neural network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 24510–24523. [Google Scholar]
- Babkov, V.F. Road Conditions and Traffic Safety; Mir Publishers: Portsmouth, NH, USA, 1975. [Google Scholar]
- Elghriany, A.F. Investigating Correlations of Pavement Conditions with Crash Rates on In-Service U.S. Highways; University of Akron: Akron, OH, USA, 2016. [Google Scholar]
- Hao, Y.R. 2021 Statistical Bulletin on the Development of the Transportation Industry [WWW Document]. Available online: http://www.gov.cn/shuju/2022-05/25/content_5692174.htm (accessed on 25 May 2022).
- Mei, Q.; Gul, M. A Cost Effective solution for pavement crack inspection using cameras and deep neural networks. Constr. Build. Mater. 2020, 256, 119397. [Google Scholar] [CrossRef]
- Cheng, H.; Shi, X.J.; Glazier, C. Real-Time image thresholding based on sample space reduction and interpolation approach. J. Comput. Civ. Eng. 2003, 17, 264–272. [Google Scholar] [CrossRef]
- Ayenu-Prah, A.Y.; Attoh-Okine, N.O. Evaluating pavement cracks with bidimensional empirical mode decomposition. EURASIP J. Adv. Signal Process. 2008, 2008, 861701. [Google Scholar] [CrossRef]
- He, Y.Q.; Qiu, h.x; Jian, W.; Wei, Z.; Xie, J.F. Studying of road crack image detection method based on the mathematical morphology. In Proceedings of the 2011 4th International Congress on Image and Signal Processing, Shanghai, China, 15–17 October 2011; Volume 2, pp. 967–969. [Google Scholar]
- Amhaz, R.; Chambon, S.; Idier, J.; Baltazart, V. Automatic crack detection on Two-Dimensional pavement images: An algorithm based on minimal path selection. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2718–2729. [Google Scholar] [CrossRef]
- Zhang, D.J.; Li, Q.T.; Chen, Y.; Cao, M.; He, L.; Zhang, B.L. An efficient and reliable coarse-to-fine approach for asphalt pavement crack detection. Image Vis. Comput. 2017, 57, 130–146. [Google Scholar] [CrossRef]
- Li, N.N.; Hou, X.D.; Yang, X.Y.; Dong, Y.F. Automation recognition of pavement surface distress based on support vector machine. In Proceedings of the 2009 Second International Conference on Intelligent Networks and Intelligent Systems, Tianjian, China, 1–3 November 2009; pp. 346–349. [Google Scholar]
- Carvalhido, A.G.; Marques, S.; Nunes, F.D.; Correia, P.L. Automatic Road Pavement Crack Detection Using SVM. Master’s Thesis, Instituto Superior Técnico, Lisbon, Portugal, 2012. [Google Scholar]
- Ai, D.H.; Jiang, G.Y.; Siew Kei, L.; Li, C.W. Automatic Pixel-Level pavement crack detection using information of Multi-Scale neighborhoods. IEEE Access 2018, 6, 24452–24463. [Google Scholar] [CrossRef]
- Hoang, N. An artificial intelligence method for asphalt pavement pothole detection using least squares support vector machine and neural network with steerable Filter-Based feature extraction. Adv. Civ. Eng. 2018, 2018, 7419058. [Google Scholar] [CrossRef]
- Li, G.; Zhao, X.X.; Du, K.; Ru, F.; Zhang, Y.B. Recognition and evaluation of bridge cracks with modified active contour model and greedy search-based support vector machine. Autom. Constr. 2017, 78, 51–61. [Google Scholar] [CrossRef]
- Majidifard, H.; Adu-Gyamfi, Y.; Buttlar, W.G. Deep machine learning approach to develop a new asphalt pavement condition index. arXiv 2020, arXiv:2004.13314. [Google Scholar] [CrossRef]
- Mei, A.; Zampetti, E.; Di Mascio, P.; Fontinovo, G.; Papa, P.; D’Andrea, A. ROADS—Rover for bituminous pavement distress survey: An unmanned ground nehicle (UGV) prototype for pavement distress evaluation. Sensors 2022, 22, 3414. [Google Scholar] [CrossRef] [PubMed]
- He, K.M.; Zhang, X.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Cao, W.; Liu, Q.F.; He, Z.Q. Review of Pavement Defect Detection Methods. IEEE Access 2020, 8, 14531–14544. [Google Scholar] [CrossRef]
- Xu, Z.S.; Guan, H.; Kang, J.N.; Lei, X.D.; Ma, L.F.; Yu, Y.T.; Chen, Y.P.; Li, J. Pavement crack detection from CCD images with a locally enhanced transformer network. Int. J. Appl. Earth Obs. Geoinf. 2022, 110, 102825. [Google Scholar] [CrossRef]
- Song, W.D.; Jia, G.H.; Jia, D.; Zhu, H. Automatic pavement crack detection and classification using multiscale feature attention network. IEEE Access 2019, 7, 171001–171012. [Google Scholar] [CrossRef]
- Stricker, R.; Aganian, D.; Sesselmann, M.; Seichter, D.; Engelhardt, M.; Spielhofer, R.; Gross, H.M. Road surface segmentation—pixel-perfect distress and object detection for road assessment. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 1789–1796. [Google Scholar]
- Zhang, C.; Nateghinia, E.; Miranda-Moreno, L.; Sun, L. Pavement distress detection using convolutional neural network (CNN): A case study in Montreal, Canada. Int. J. Transp. Sci. Technol. 2021, 11, 298–309. [Google Scholar] [CrossRef]
- Dung, C.V.; Sekiya, H.; Hirano, S.; Okatani, T.; Miki, C. A vision-based method for crack detection in gusset plate welded joints of steel bridges using deep convolutional neural networks. Autom. Constr. 2019, 102, 217–229. [Google Scholar] [CrossRef]
- Xu, H.Y.; Su, X.; Wang, Y.; Cai, H.Y.; Cui, K.A.; Chen, X.D. Automatic bridge crack detection using a convolutional neural network. Appl. Sci. 2019, 9, 2867. [Google Scholar] [CrossRef]
- Li, H.T.; Xu, H.Y.; Tian, X.; Wang, Y.; Cai, H.Y.; Cui, K.A.; Chen, X.D. Bridge crack detection based on SSENets. Appl. Sci. 2020, 10, 4230. [Google Scholar] [CrossRef]
- Tran, T.S.; Tran, V.P.; Lee, H.J.; Flores, J.M.; Le, V.P. A two-step sequential automated crack detection and severity classification process for asphalt pavements. Int. J. Pavement Eng. 2020, 23, 2019–2033. [Google Scholar] [CrossRef]
- Wu, Z.Y.; Kalfarisi, R.; Kouyoumdjian, F.; Taelman, C. Applying deep convolutional neural network with 3D reality mesh model for water tank crack detection and evaluation. Urban Water J. 2020, 17, 682–695. [Google Scholar] [CrossRef]
- Jeong, D. Road damage detection using YOLO with smartphone images. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5559–5562. [Google Scholar]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. DeepCrack: Learning hierarchical convolutional features for crack detection. IEEE Trans. Image Process. 2019, 28, 1498–1512. [Google Scholar] [CrossRef] [PubMed]
- Ouma, Y.O.; Hahn, M. Wavelet-morphology based detection of incipient linear cracks in asphalt pavements from RGB camera imagery and classification using circular Radon transform. Adv. Eng. Inform. 2016, 30, 481–499. [Google Scholar] [CrossRef]
- Siriborvornratanakul, T. An automatic road distress visual inspection system using an onboard In-Car camera. Adv. Multim. 2018, 2018, 2561953. [Google Scholar] [CrossRef]
- Fan, D.P.; Ji, G.P.; Cheng, M.M.; Shao, L. Concealed object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6024–6042. [Google Scholar] [CrossRef]
- Liew, J.H.; Cohen, S.D.; Price, B.L.; Mai, L.; Feng, J. Deep interactive thin object selection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2021; pp. 305–314. [Google Scholar]
- Lin, S.C.; Yang, L.J.; Saleemi, I.; Sengupta, S. Robust High-Resolution video matting with temporal guidance. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2022; pp. 3132–3141. [Google Scholar]
- Wang, L.J.; Lu, H.C.; Wang, Y.F.; Feng, M.Y.; Wang, D.; Yin, B.C.; Ruan, X. Learning to Detect Salient Objects with Image-Level Supervision. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3796–3805. [Google Scholar]
- Shi, Y.; Cui, L.M.; Qi, Z.Q.; Meng, F.; Chen, Z.S. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.J.; Prokhorov, D.V.; Mei, X.; Ling, H.B. Feature pyramid and hierarchical boosting network for pavement crack detection. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1525–1535. [Google Scholar] [CrossRef]
- Chambon, S.; Moliard, J. Automatic road pavement assessment with image processing: Review and Comparison. Int. J. Geophys. 2011, 2011, 989354. [Google Scholar] [CrossRef]
- Qin, X.B.; Dai, H.; Hu, X.B.; Fan, D.P.; Shao, L.; Gool, A.L. Highly accurate dichotomous image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE. 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.N.; Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. arXiv 2017, arXiv:1505.04597. [Google Scholar]
- Jenkins, M.D.; Carr, T.A.; Iglesias, M.I.; Buggy, T.W.; Morison, G. A deep convolutional neural network for semantic Pixel-Wise segmentation of road and pavement surface cracks. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Roma, Italy, 3–7 September 2018; pp. 2120–2124. [Google Scholar]
- Lau, S.L.; Chong, E.K.; Yang, X.; Wang, X. Automated pavement crack segmentation using U-Net-Based convolutional neural network. IEEE Access 2018, 8, 114892–114899. [Google Scholar] [CrossRef]
- Escalona, U.; Arce, F.; Zamora, E.; Azuela, J.H. Fully convolutional networks for automatic pavement crack segmentation. Comput. Sist. 2019, 23, 451–460. [Google Scholar] [CrossRef]
- Polovnikov, V.; Alekseev, D.; Vinogradov, I.; Lashkia, G.V. DAUNet: Deep augmented neural network for pavement crack segmentation. IEEE Access 2021, 9, 125714–125723. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional Encoder-Decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Fan, R.; Bocus, M.J.; Zhu, Y.; Jiao, J.; Wang, L.; Ma, F.; Cheng, S.; Liu, M. Road crack detection using deep convolutional neural network and adaptive thresholding. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 474–479. [Google Scholar]
- Xu, Z.C.; Sun, Z.Y.; Huyan, J.; Wang, F.P. Pixel-level pavement crack detection using enhanced high-resolution semantic network. Int. J. Pavement Eng. 2021, 23, 4943–4957. [Google Scholar] [CrossRef]
- Lõuk, R.; Riid, A.; Pihlak, R.; Tepljakov, A. Pavement defect segmentation in orthoframes with a pipeline of three convolutional neural networks. Algorithms 2020, 13, 198. [Google Scholar] [CrossRef]
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Groß, H. How to get pavement distress detection ready for deep learning? A systematic approach. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2039–2047. [Google Scholar]
- Riid, A.; Lõuk, R.; Pihlak, R.; Tepljakov, A.; Vassiljeva, K. Pavement distress detection with deep learning using the orthoframes acquired by a mobile mapping system. Appl. Sci. 2019, 9, 4829. [Google Scholar] [CrossRef]
- Augustauskas, R.; Lipnickas, A. Improved Pixel-Level Pavement-Defect segmentation using a deep autoencoder. Sensors 2020, 20, 2557. [Google Scholar] [CrossRef]
- Minhas, M.S.; Zelek, J.S. Defect detection using deep learning from minimal annotations. VISIGRAPP 2020, 4, 506–513. [Google Scholar] [CrossRef]
- Ma, K.; Hoai, M.; Samaras, D. Large-scale continual road inspection: Visual Infrastructure assessment in the wild. In Proceedings of the British Machine Vision Conference 2017, London, UK, 4–7 September 2017. [Google Scholar]
- Maeda, H.; Kashiyama, T.; Sekimoto, Y.; Seto, T.; Omata, H. Generative adversarial network for road damage detection. Comput. Aided Civ. Infrastruct. Eng. 2020, 36, 47–60. [Google Scholar] [CrossRef]
- Everingham, M.; Gool, L.V.; Williams, C.K.; Winn, J.M.; Zisserman, A. The pascal visual object classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Perju, V.L.; Casasent, D.P.; Mardare, I. Image complexity matrix for pattern and target recognition based on Fourier spectrum analysis. Def. Commer. Sens. 2009, 7340, 73400. [Google Scholar]
- Lihua, Z. Trademark retrieval based on image information entropy. Comput. Eng. 2000, 26, 86–87. [Google Scholar]
- Yang, L.; Zhou, Y.; Yang, J.; Chen, L. Variance WIE based infrared images processing. Electron. Lett. 2006, 42, 857–859. [Google Scholar] [CrossRef]
- Osserman, R. The isoperimetric inequality. Bull. Am. Math. Soc. 2008, 84, 1182–1238. [Google Scholar] [CrossRef]
- Watson, A. Perimetric complexity of binary digital images. Math. J. 2012, 14, ARC-E-DAA-TN3185. [Google Scholar] [CrossRef]
- Yang, C.L.; Wang, Y.L.; Zhang, J.M.; Zhang, H.; Lin, Z.L.; Yuille, A.L. Meticulous object segmentation. arXiv 2020, arXiv:2012.07181. [Google Scholar]
- Ramer, U. An iterative procedure for the polygonal approximation of plane curves. Comput. Graph. Image Process 1972, 1, 244–256. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for Large-Scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhao, H.S.; Shi, J.P.; Qi, X.J.; Wang, X.G.; Jia, J.Y. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Chen, L.C.; Zhu, Y.K.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, J.D.; Sun, K.; Cheng, T.H.; Jiang, B.R.; Deng, C.R.; Zhao, Y.; Liu, D.; Mu, Y.D.; Tan, M.K.; Wang, X.G.; et al. Deep High-Resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 3349–3364. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.Y.; Chen, J.; Jiang, D.S.; Zhang, X.P.; Tian, Q.; Wang, M.N. Swin-Unet: Unet-like pure transformer for medical image segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Xie, E.; Wang, W.H.; Yu, Z.D.; Anandkumar, A.; Álvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Zheng, S.X.; Lu, J.C.; Zhao, H.S.; Zhu, X.T.; Luo, Z.K.; Wang, Y.B.; Fu, Y.W.; Feng, J.F.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a Sequence-to-Sequence perspective with transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6877–6886. [Google Scholar]
- Yuan, Y.H.; Chen, X.L.; Wang, J.D. Object-Contextual representations for semantic segmentation. arXiv 2019, arXiv:1909.11065. [Google Scholar]
- Xie, S.N.; Tu, Z.W. Holistically-Nested edge detection. Int. J. Comput. Vis. 2015, 125, 3–18. [Google Scholar] [CrossRef]
- Liu, Y.; Cheng, M.M.; Hu, X.; Wang, K.; Bai, X. Richer convolutional features for edge detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5872–5881. [Google Scholar]
- Li, X.Y.; Sun, X.F.; Meng, Y.X.; Liang, J.J.; Wu, F.; Li, J.W. Dice loss for Data-Imbalanced NLP tasks. arXiv 2019, arXiv:1911.02855. [Google Scholar]
- Zhou, Z.Y.; Huang, H.; Fang, B.H. Application of weighted Cross-Entropy loss function in intrusion detection. J. Comput. Commun. 2021, 9, 1–21. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Torralba, A.; Efros, A.A. Unbiased look at dataset bias. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1521–1528. [Google Scholar]
- Sandler, M.; Howard, A.G.; Zhu, M.L.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for image recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Dataset | Illumination | Proportion of Pavement Type/% | Equipment |
|---|---|---|---|---|
| Crack segmentation | CrackLS315 [30] | Laser | AP: 100.0% | Area-array camera |
| CRKWH100 [30] | Visible light | AP: 100.0% | Linear-array camera | |
| CrackTree260 [30] | Visible light | AP: 100.0% | Area-array camera | |
| AigleRN [39] | Visible light | AP: 100.0% | Area-array camera | |
| CFD [37] | Visible light | CCP: 1.7%; AP: 98.3% | Smartphone | |
| CRACK500 [38] | Visible light | CCP: 2.4%; AP: 97.6% | Smartphone | |
| GAPs384 [38] | Laser | AP: 100.0% | Linear-array camera | |
| Multi-type distress DIS | ISTD-PDS7 | HID lamp | CCP: 29.4%; AP: 70.6% | Area-array camera |
| Task | Dataset | Number | Image Dimension | Image Complexity | Annotation Complexity | Annotation Method | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| I num | H | W | D | IE | IPQ | Cnum | Pnum | |||
| Crack | CrackLS315 [6] | 315 | 512.00 ± 0.00 | 512.00 ± 0.00 | 724.00 ± 0.00 | 50.12 ± 11.46 | 297.70 ± 199.48 | 3.40 ± 2.60 | 618.29 ± 415.57 | Single-pixel width |
| CrackWH100 [6] | 100 | 512.00 ± 0.00 | 512.00 ± 0.00 | 724.00 ± 0.00 | 36.72 ± 9.15 | 432.68 ± 452.24 | 2.90 ± 4.27 | 855.45 ± 887.29 | ||
| CrackTree260 [6] | 260 | 624.92 ± 48.77 | 833.23 ± 65.03 | 1041.54 ± 81.29 | 53.45 ± 12.15 | 1122.18 ± 996.63 | 8.64 ± 16.07 | 2551.08 ± 2195.26 | ||
| AigleRN [38] | 38 | 522.35 ± 151.02 | 692.05 ± 280.26 | 890.23 ± 244.33 | 32.18 ± 9.27 | 437.02 ± 416.94 | 17.40 ± 14.62 | 1374.35 ± 1014.11 | Actual width | |
| CFD [36] | 118 | 320.00 ± 0.00 | 480.00 ± 0.00 | 577.00 ± 0.00 | 36.42 ± 9.36 | 106.60 ± 56.30 | 3.69 ± 4.19 | 661.78 ± 457.74 | ||
| CRACK500 [37] | 500 | 1568.38 ± 313.60 | 2594.61 ± 240.45 | 3042.13 ± 303.57 | 59.66 ± 13.21 | 91.24 ± 95.42 | 18.11 ± 25.92 | 3603.03 ± 2065.43 | ||
| GAPs384 [37] | 384 | 551.65 ± 99.43 | 540.00 ± 0.00 | 775.15 ± 69.60 | 55.29 ± 12.19 | 48.44 ± 40.89 | 5.26 ± 5.57 | 452.22 ± 286.27 | ||
| DIS | ISTD-PDS7 | 18527 | 375.47 ± 99.50 | 371.00 ± 114.44 | 529.45 ± 145.73 | 89.28 ± 13.63 | 134.82 ± 265.07 | 9.10 ± 16.95 | 1083.38 ± 1054.07 | |
| Class | ISTD-TR | ISTD-TR Percentage/% | ISTD-VD | ISTD-VD Percentage/% | ISTD-TE | ISTD-TE Percentage/% |
|---|---|---|---|---|---|---|
| Transverse crack | 1581 | 10.0% | 176 | 10.0% | 150 | 15.0% |
| Longitudinal crack | 921 | 5.8% | 102 | 5.8% | 126 | 12.6% |
| Alligator network crack | 236 | 1.5% | 26 | 1.5% | 249 | 24.9% |
| Patch | 763 | 4.8% | 85 | 4.8% | 88 | 8.8% |
| Pothole | 275 | 1.7% | 31 | 1.7% | 15 | 1.5% |
| Cement concrete crack | 1206 | 7.6% | 134 | 7.6% | 119 | 11.9% |
| Broken slab | 189 | 1.2% | 21 | 1.2% | 60 | 6.0% |
| Negative sample | 10,603 | 67.2% | 1178 | 67.2% | 193 | 19.3% |
| Total | 15,774 | 100.0% | 1753 | 100.0% | 1000 | 100.0% |
| Dataset | Metric | SegNet | PSPNet | DeepLabv3+ | U-Net | HRNet | Swin-Unet | SegFormer | ||
|---|---|---|---|---|---|---|---|---|---|---|
| [49] | [68] | [69] | [44] | [70] | [71] | [72] | ||||
| Attribute | Backbone | V16 | MV2 | R-50 | MV2 | X | V-16 | H-V2 | ST | MiT-B2 |
| Input size | 512 × 512 | 473 × 473 | 473 × 473 | 512 × 512 | 512 × 512 | 512 × 512 | 480 × 480 | 224 × 224 | 512 × 512 | |
| Par/M | 16.32 | 2.38 | 46.71 | 5.813 | 54.709 | 24.89 | 29.538 | 27.18 | 27.348 | |
| CC/GFLOPs | 601.78 | 5.28 | 118.43 | 52.87 | 166.841 | 450.602 | 79.915 | 52.56 | 113.427 | |
| Speed/FPS | 57.91 | 131.38 | 75.53 | 100.32 | 47.05 | 26.99 | 23.32 | 110.95 | 34.75 | |
| ISTD-VD | Precision/% | 74.84 | 86.31 | 82.69 | 83.41 | 86.87 | 87.05 | 87.22 | 85.02 | 88.39 |
| Recall/% | 57.12 | 82.83 | 80.2 | 80.05 | 80.43 | 87.81 | 83.66 | 77.33 | 89.69 | |
| F1/% | 64.79 | 84.53 | 81.43 | 81.70 | 83.53 | 87.43 | 85.40 | 80.99 | 89.04 | |
| mIoU/% | 54.15 | 75.72 | 72.08 | 72.64 | 74.33 | 79.47 | 76.80 | 71.3 | 81.67 | |
| ISTD-TE | Precision/% | 81.14 | 92.14 | 85.67 | 89.44 | 96.31 | 92.77 | 92.80 | 89.56 | 93.64 |
| Recall/% | 63.98 | 87.27 | 80.56 | 87.94 | 83.49 | 91.30 | 92.65 | 88.66 | 94.82 | |
| F1/% | 71.55 | 89.64 | 83.04 | 88.68 | 89.44 | 92.03 | 92.72 | 89.11 | 94.23 | |
| mIoU/% | 60.40 | 82.27 | 73.55 | 81.03 | 81.13 | 85.96 | 87.07 | 81.64 | 89.49 | |
| ISTD-CRTE | Precision/% | 87.31 | 79.16 | 76.08 | 84.46 | 90.62 | 85.17 | 84.15 | 82.79 | 87.22 |
| Recall/% | 60.45 | 68.78 | 73.11 | 79.64 | 70.42 | 86.67 | 86.02 | 76.93 | 87.06 | |
| F1/% | 71.44 | 73.61 | 74.57 | 81.98 | 79.25 | 85.91 | 85.07 | 79.75 | 87.14 | |
| mIoU/% | 57.05 | 63.50 | 65.00 | 72.66 | 67.50 | 77.50 | 76.43 | 70.12 | 79.12 | |
| Dataset | Metric | AigleRN [39] | Gaps384 [38] | CFD [37] | Crack500 [38] | ISTD-PDS7 |
|---|---|---|---|---|---|---|
| CrackWH100 [6] | Precision/% | 78.38 | 76.75 | 75.48 | 84.29 | 85.73 |
| Recall/% | 80.36 | 87.28 | 93.83 | 84.47 | 93.50 | |
| F1/% | 79.36 | 81.68 | 83.66 | 84.38 | 89.45 | |
| mIoU/% | 70.58 | 72.32 | 73.39 | 76.03 | 82.20 | |
| ISTD-CRTE | Precision/% | 89.86 | 71.65 | 75.72 | 78.16 | 87.22 |
| Recall/% | 55.67 | 84.58 | 88.81 | 90.26 | 87.06 | |
| F1/% | 68.75 | 77.58 | 81.74 | 83.78 | 87.14 | |
| mIoU/% | 53.47 | 66.40 | 71.12 | 73.77 | 79.12 |
| Method | Training Set | Precision/% | Recall/% | F1/% | mIoU/% |
|---|---|---|---|---|---|
| None | 17,147 | 92.04 | 89.3 | 90.65 | 83.89 |
| Image enhancement | 47,601 | 92.21 | 91.63 | 91.92 | 85.79 |
| Geometric transformation | 30,475 | 93.64 | 94.82 | 94.23 | 89.49 |
| All | 60,929 | 93.92 | 95.74 | 94.82 | 90.68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, W.; Zhang, Z.; Zhang, B.; Jia, G.; Zhu, H.; Zhang, J. ISTD-PDS7: A Benchmark Dataset for Multi-Type Pavement Distress Segmentation from CCD Images in Complex Scenarios. Remote Sens. 2023, 15, 1750. https://doi.org/10.3390/rs15071750
Song W, Zhang Z, Zhang B, Jia G, Zhu H, Zhang J. ISTD-PDS7: A Benchmark Dataset for Multi-Type Pavement Distress Segmentation from CCD Images in Complex Scenarios. Remote Sensing. 2023; 15(7):1750. https://doi.org/10.3390/rs15071750
Chicago/Turabian StyleSong, Weidong, Zaiyan Zhang, Bing Zhang, Guohui Jia, Hongbo Zhu, and Jinhe Zhang. 2023. "ISTD-PDS7: A Benchmark Dataset for Multi-Type Pavement Distress Segmentation from CCD Images in Complex Scenarios" Remote Sensing 15, no. 7: 1750. https://doi.org/10.3390/rs15071750
APA StyleSong, W., Zhang, Z., Zhang, B., Jia, G., Zhu, H., & Zhang, J. (2023). ISTD-PDS7: A Benchmark Dataset for Multi-Type Pavement Distress Segmentation from CCD Images in Complex Scenarios. Remote Sensing, 15(7), 1750. https://doi.org/10.3390/rs15071750