1. Introduction
Object tracking is one of the most important research fields in computer vision [
1] and has been widely developed in the past decade and successfully employed in many applications [
2], such as video surveillance [
3], artificial intelligence [
4], intelligent traffic control [
5], and autonomous driving [
6]. It is a challenging task that requires constantly tracking the object in the video subsequences due to the fast motion, occlusion and interference from similar appearances, to name a few. Most of the existing methods merely obtain color intensities, texture, semantic information, and deep representation features to track the object in the limitations of imaging technology, which are not suitable for HSVs tracking. Thanks to the advent of the hyperspectral imager, object tracking has been extended to hyperspectral images, which is some of the best research because hyperspectral images have a large amount of spectral information. Many efforts have been made to improve the performance of hyperspectral video tracking in recent year; however, the performance of hyperspectral video tracking is still unsatisfactory in complex scenarios in that the spectral information of hyperspectral images is not fully utilized in the existing object tracking methods.
Spectral reflectance preserved in hyperspectral images contains a unique feature of the hyperspectral object potentially, which is not available in other types of images [
7,
8,
9]. Hyperspectral images record high-dimensional spectral information [
10,
11,
12], which is advantageous for the discriminative feature extraction of objects in challenging tracking extraction such as similar appearances, and scale change. Previous studies revealed that [
13] spatial–spectral information can increase inter-object separability and discriminability to handle the tracking drift. At present, traditional trackers focus on optical feature extraction, which is not suitable for hyperspectral video tracking. However, the performance of existing hyperspectral video trackers is still unsatisfactory in typical complex scenarios. The first reason is that the existing hyperspectral trackers have not fully explored the spectral–spatial information to describe HSVs [
14]. Chen et al. [
13] proposed a fast spectral–spatial convolution kernel feature-extraction method to extract the discriminative feature of hyperspectral images. However, the proposed method merely tends to extract efficient encoding of local spectral–spatial information rather than the global feature maps. Therefore, the performance of the proposed method is still poor in challenging scenarios on account of the lack of global interactivity of data. Meanwhile, the proposed method is most appropriate for specific public datasets, while the tracking results display poor generalization ability. The second reason is that high-dimensional spectral information is a double-edged sword, which will bring difficulties to the feature extraction and high computational costs due to the enhancement of the bands. Xiong et al. [
15] proposed two spectral–spatial feature extractors, namely, local spectral–spatial histogram of multidimensional gradient (SSHMG) and spatial distribution of materials (MHT). The former method captures spectral–spatial texture information using gradient orientations, and the latter method obtains two visual feature descriptors, namely end-members and abundances, yielding material to track. Nevertheless, the most attention in the MHT is concentrated on spectral extraction, resulting in spending massive computation costs to extract the feature information, which is not suitable for real-time tracking.
In recent years, Uzkent et al. [
14] produced a synthetic aerial hyperspectral dataset with the digital imaging and remote sensing image generation (DIRSIG) software. However, the dataset is generated at 1.42 fps, leading to the difficulty of tracking objects which change rapidly in a short period of time. Thanks to the development of hyperspectral imaging technology, hyperspectral video has been widely obtained in various scenarios. The existing two types of hyperspectral video datasets are collected by [
13,
15], named IMEC16 and IMEC25, respectively. Accordingly, hyperspectral trackers have been developed rapidly.
Among the present hyperspectral trackers, correlation filters (CF) [
14,
16] and discriminative correlation filters (DCF) [
17,
18] have achieved much success in terms of tracking. These trackers learn an object prediction model for location in video subsequences by using the correlation-minimizing object function, which integrates both foreground and background knowledge, providing effective features responding to the model. Xiong et al. [
15] proposed two spectral–spatial feature extractors, namely SSHMG and MHT, which are embedded into background-aware correlation filters to track specific objects. SSHMG is designed to capture local spectral–spatial histograms of multidimensional gradients, while MHT is proposed to represent material information, and uses fractional abundances to encode the material distribution. Liu et al. [
19] introduced a spectral classification branch into the anchor-free Siamese network to enhance the representation of objects in HSVs. Lei et al. [
20] employed a spatial–spectral cross-correlation embedded dual-transfer network (SSDT-Net) to extract high-dimensional characteristics of HSVs. Meanwhile, a spatial–spectral cross-correlation module is designed to capture material information and spatial distribution with two branches of the Siamese network. Zhang et al. [
21] proposed spectral matching reduction features and adaptive-scale 3D hog features to track the objects to confront scale variation, where adaptive-scale 3D hog features mainly consist of cube-level features at three different scales. Zhao et al. [
22] proposed a feature fusion network for the synchronous extraction of the spatial and spectral features of hyperspectral data, where the color intensity feature and the modality-specific feature are mixed to assist the tracker in accurate positioning. However, the method also displays limitations in that the severe inductive bias of CF and DCF is imposed on the model, which leads to poor generalization performance. Consequently, the model is only suitable for the object in available data but it could not integrate any learned priors. At present, several deep learning-based methods have gradually presented. Liu et al. [
23] proposed a dual deep Siamese network framework with a pretrained RGB tracker and spatial–spectral cross-attention learning. Afterward, they [
24] proposed unsupervised deep learning-based object tracking framework, and a new hyperspectral dataset was collected. Nonetheless, the aforementioned methods are merely verified on a public hyperspectral video dataset [
15]. The further generalization ability of these models must be investigated for generating a universal hyperspectral video tracker. Although Chen et al. [
25] proposed a feature descriptor using a Histogram Oriented Mosaic Gradient (HOMG) to gain spatial–spectral features directly from mosaic spectral images on two datasets, the performance of the tracker displays a preference for IMEC25. On the contrary, transformers have shown a strong global reasoning capability across multiple frames, which is a great advantage for video tracking. Specifically, the self-attention and the cross-attention mechanism can capture the global interaction of the video with considerable success [
26,
27,
28]. However, the existing transformer-based methods specially designed for natural scenes merely focus on extracting spatial features, and are not suitable for hyperspectral video tracking due to the ignorance of spectral information. An effective approach to address this issue is integrating spectral information into RGB trackers to achieve multi-modal tracking. For example, Zhao et al. [
29] proposed a tracker named TMTNet to efficiently transfer the information of multi-modality data composed of RGB and the hyperspectrum in the hyperspectral tracking process. Nevertheless, these methods rely on consistent, aligned RGB and hyperspectral images, which are generally unavailable in practice in real scenes.
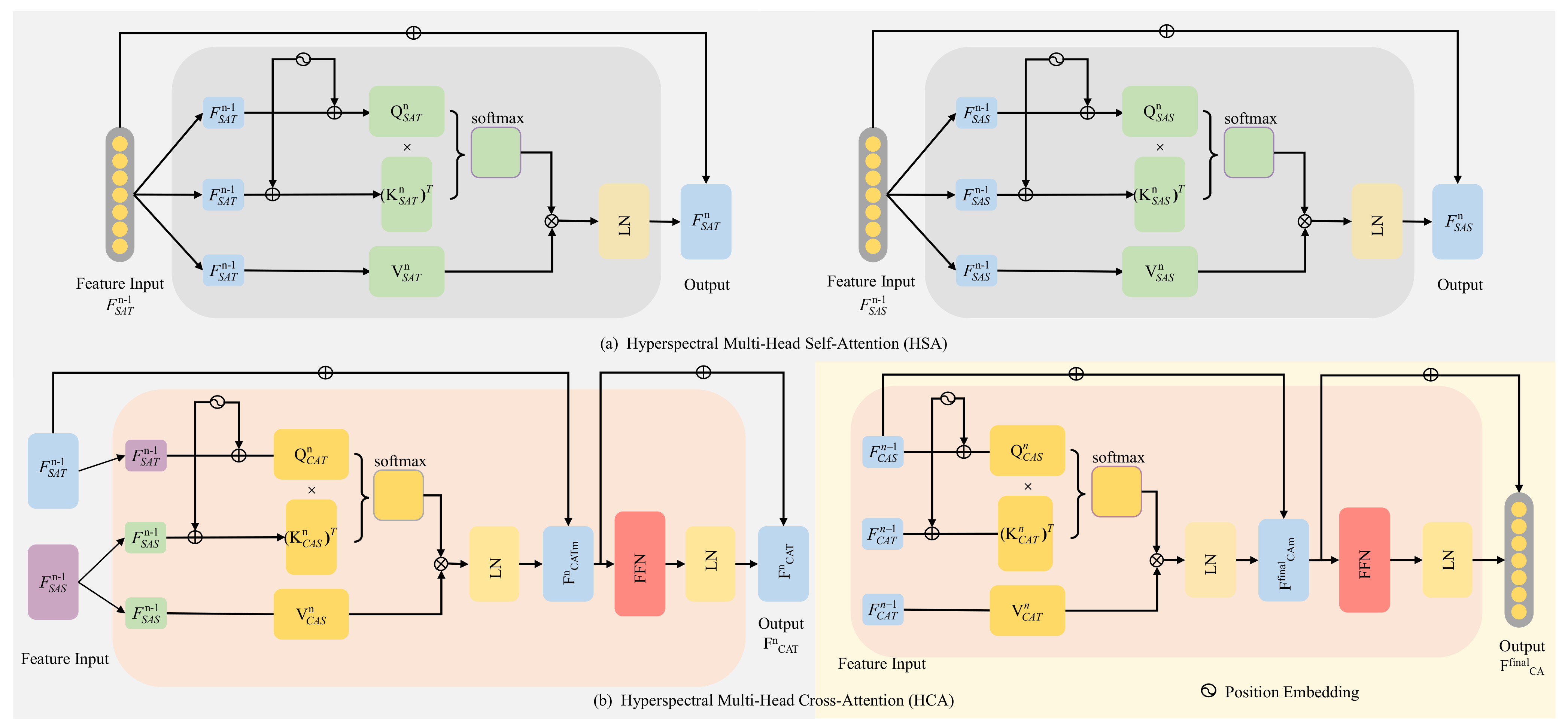
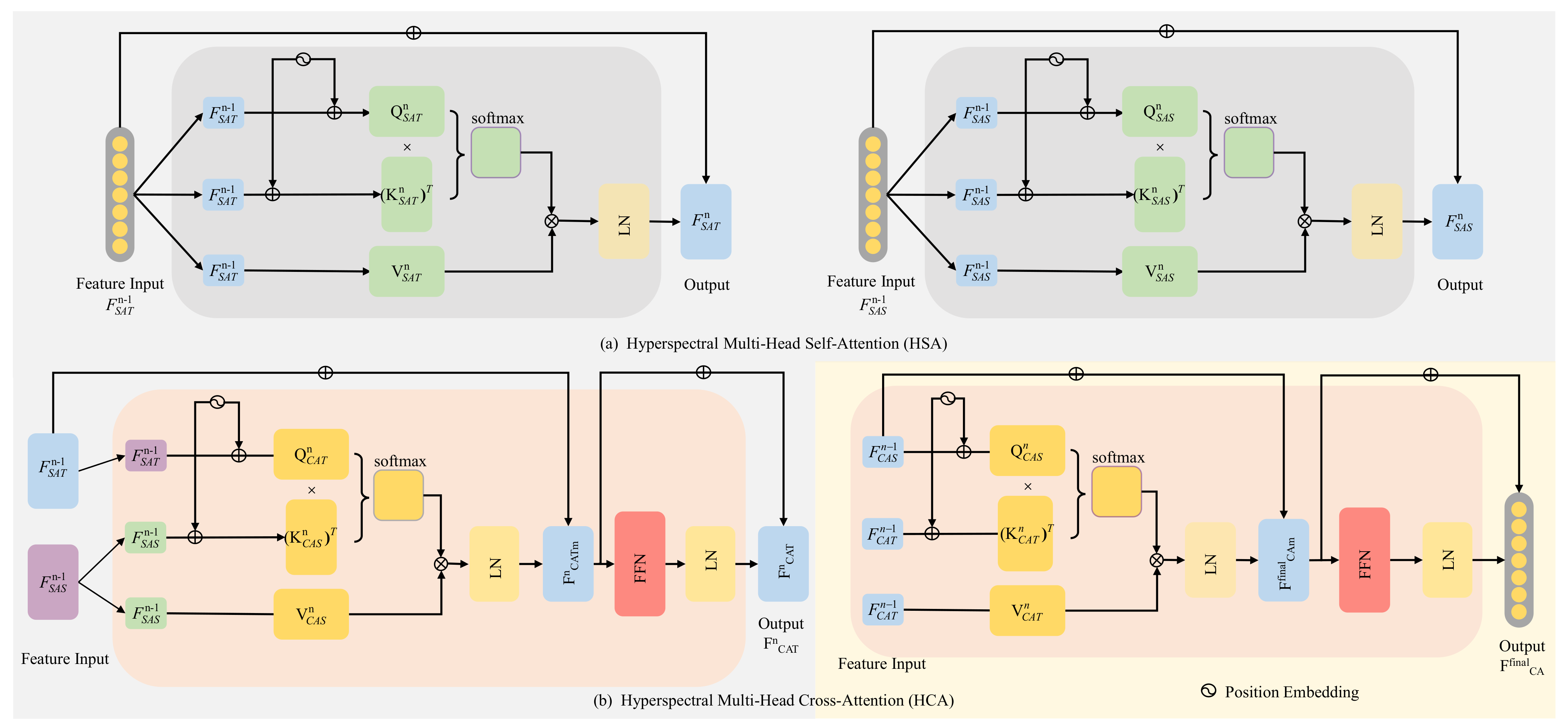
The transformer, benefiting from excellent global interaction ability and generalization performance, has been introduced to improve the accuracy of tracking. It is worth noting that the transformer is a novel structure that has not been applied to universal hyperspectral video tracking. It is necessary to illustrate that the transformer could be utilized to extract the spectral–spatial features of hyperspectral video sequences. The transformer was first introduced by Vaswani et al. [
30] to deal with sequential tasks. It is customary that the sequences-to-sequences structures are isomorphic across layers, and the success of multi-head self-attentions (MSAs) for computer vision is now indisputable [
31]. The self-attentions [
32] aggregate spatial tokens that can be unified into a single function:
where
, and
V are defined as query, key, and value, respectively.
d is the dimension of the query and key, Equation (
1) is a simple function that can be used to calculate the attention score of the image token. A single-head self-attention layer limits the ability to focus on one or more specific positions. Multi-head attention is a mechanism that can be used to boost the performance of the self-attention layer [
33]. The multi-head self-attention process is as follows:
where
(
) is the concatenation of the query (key, value) vectors of all heads,
is the projection matrix of the output and
, and
are the projection matrices of the query, key, and value, respectively.
Several transformer-based trackers [
1,
26,
28] have been proposed to deal with the tracking task. The transformers are typically employed to predict discriminative features to localize the object. Cao et al. [
34] designed an adaptive temporal transformer to encode temporal knowledge effectively before the temporal knowledge is decoded for accurate adjustment of the similarity map. Mayer et al. [
35] proposed a transformer-based tracker, where transformers obtain global relations with a weak induction bias, allowing the prediction of more powerful target models. Bin et al. [
27] proposed an encoder-decoder transformer without using any proposals or predefined anchors to estimate the corners of objects directly, where the prediction head is a simple fully convolutional network. Wang et al. [
26] separated the transformer encoder and decoder into two parallel branches designed within the Siamese-like tracking. The encoder promotes the target templates via attention-based feature reinforcement, while the decoder propagates the tracking cues from previous templates to the current frame.
Existing transformer-based trackers are mainly designed for optical (red, blue, and green) videos or multi-modal videos. In hyperspectral videos, there is abundant spectral information and context semantics among successive frames, which have been largely overlooked in transformer-based trackers. Therefore, it is significant to design a transformer-based tracker to deal with the hyperspectral video tracking task.
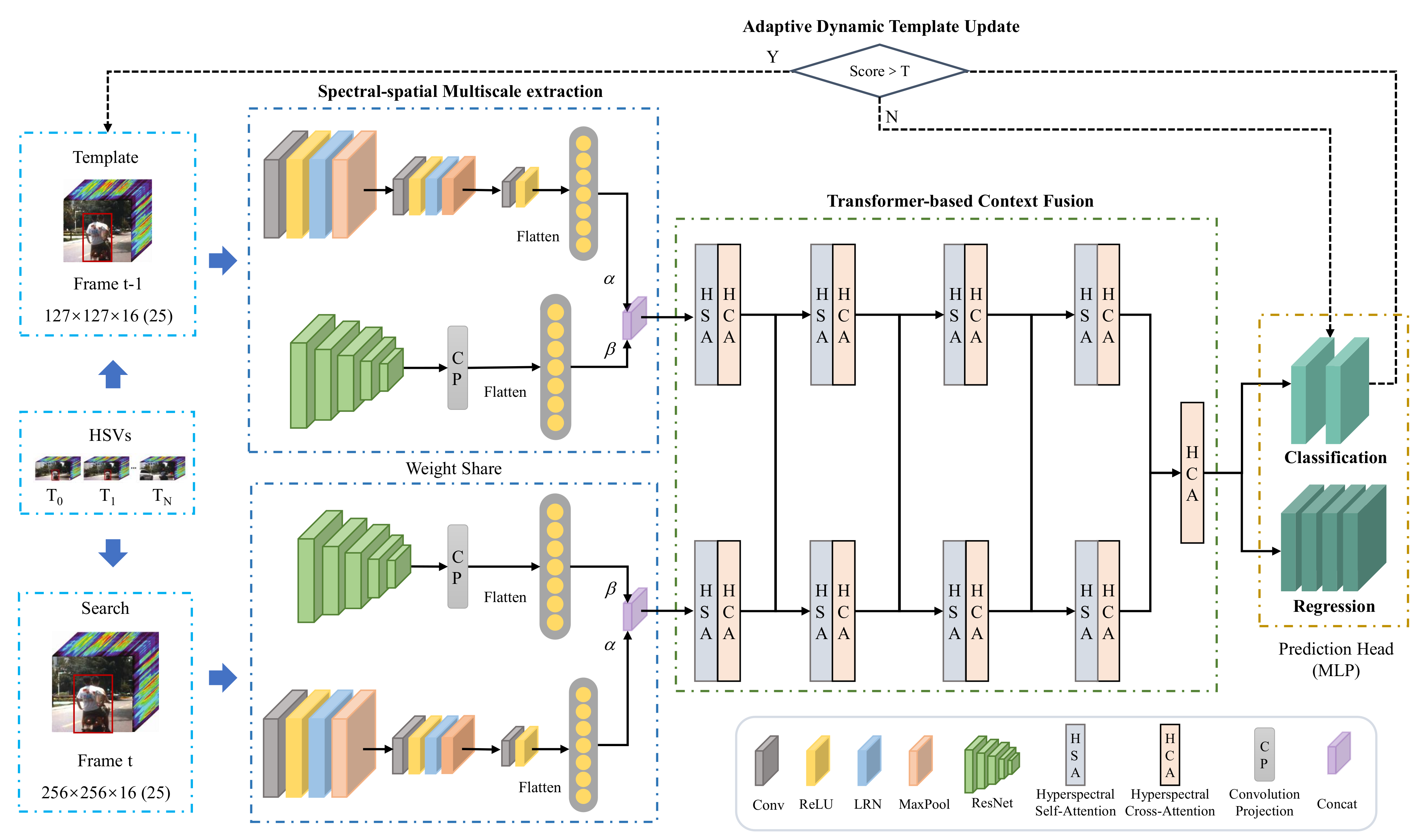
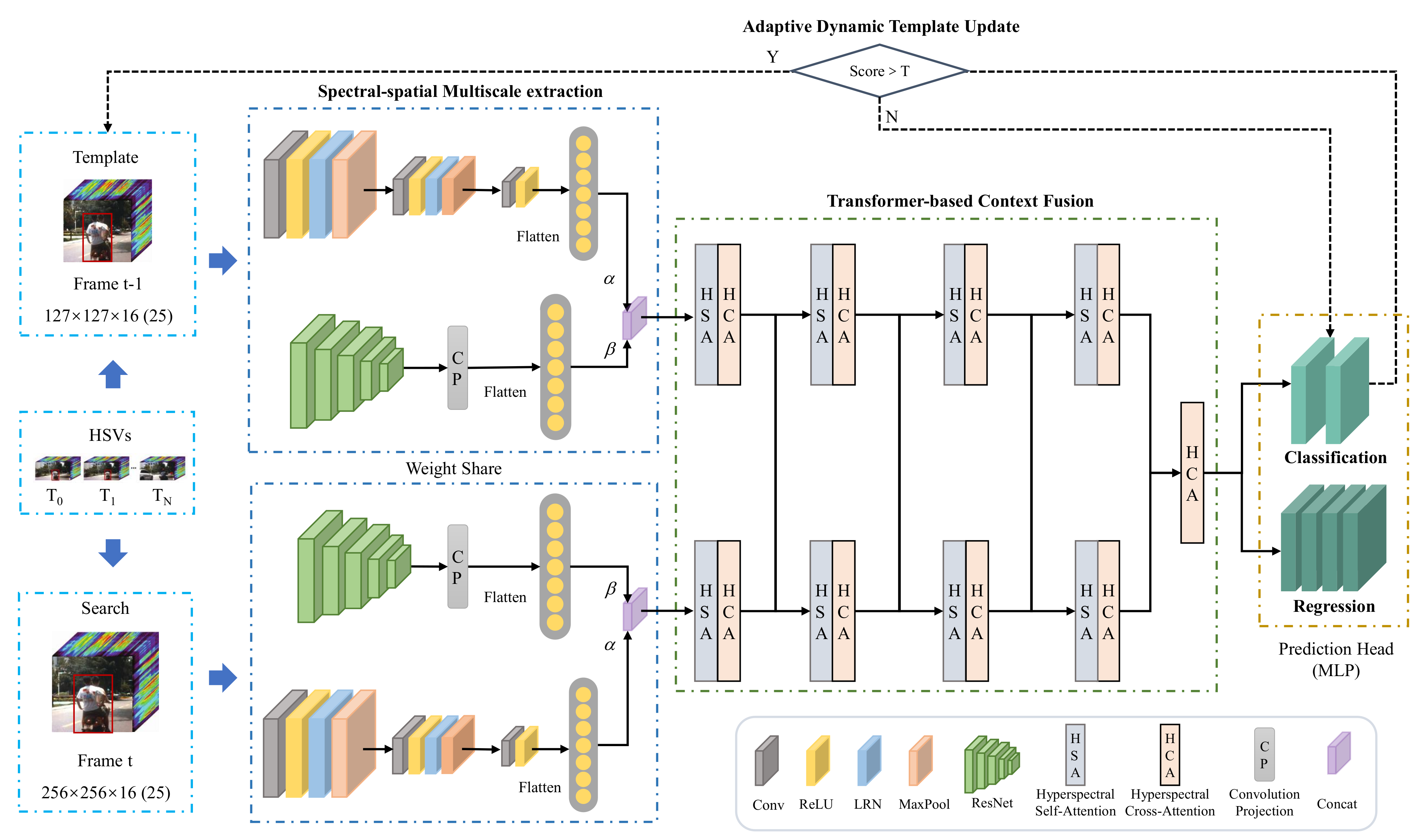
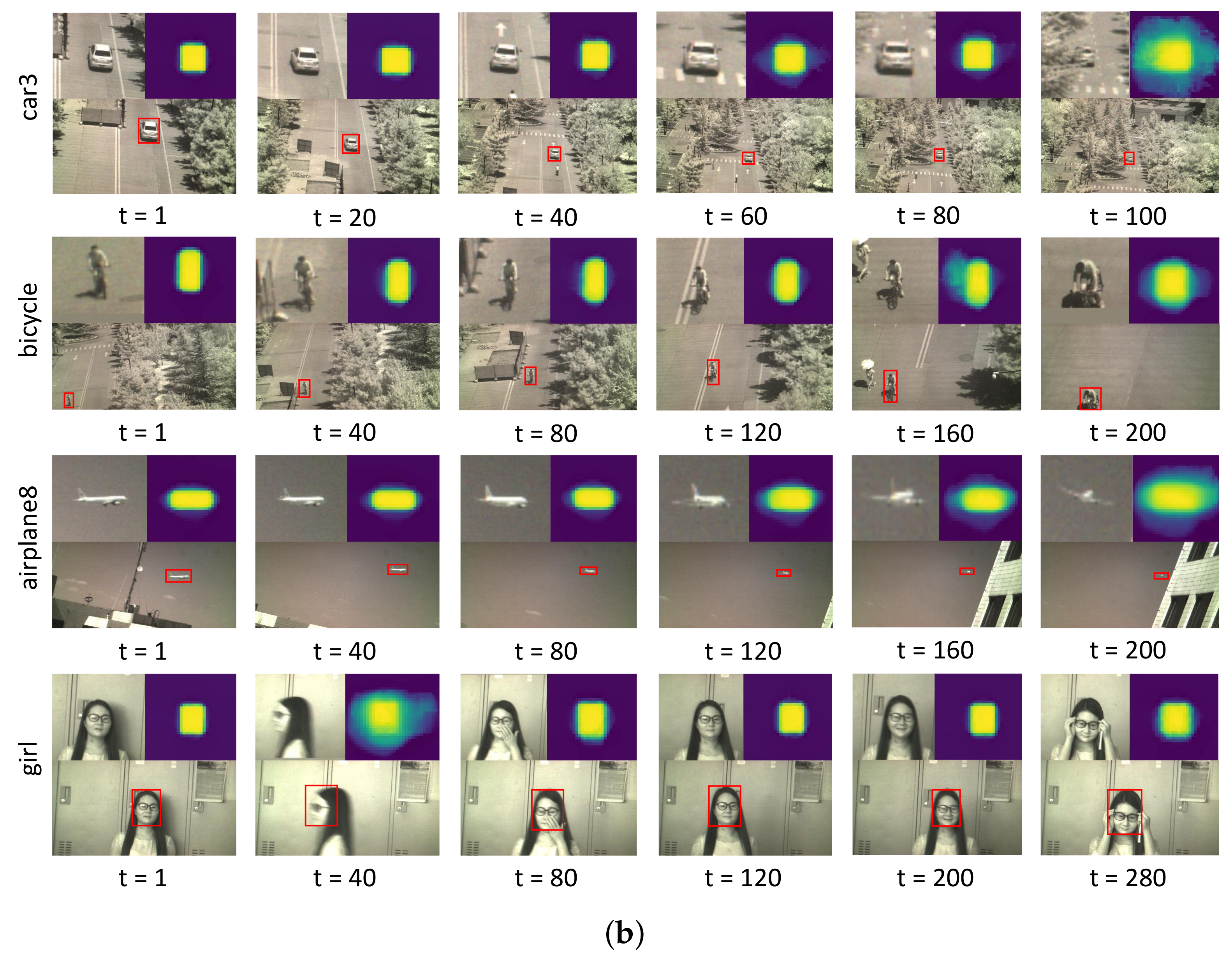
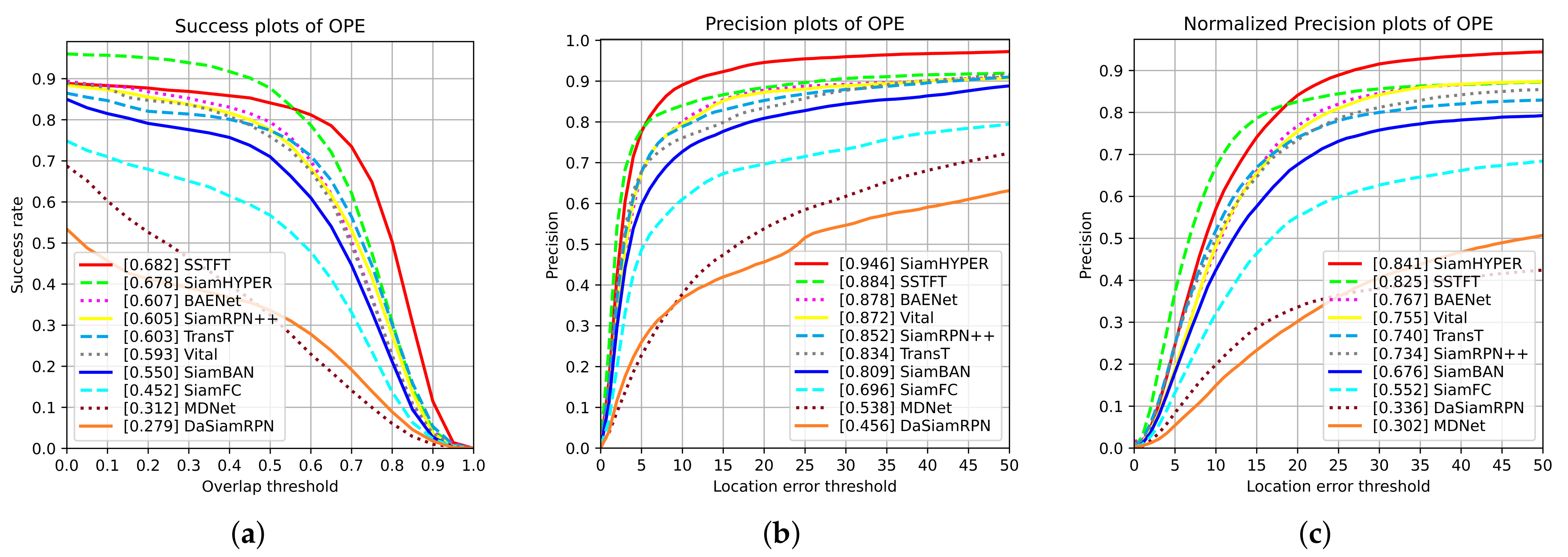
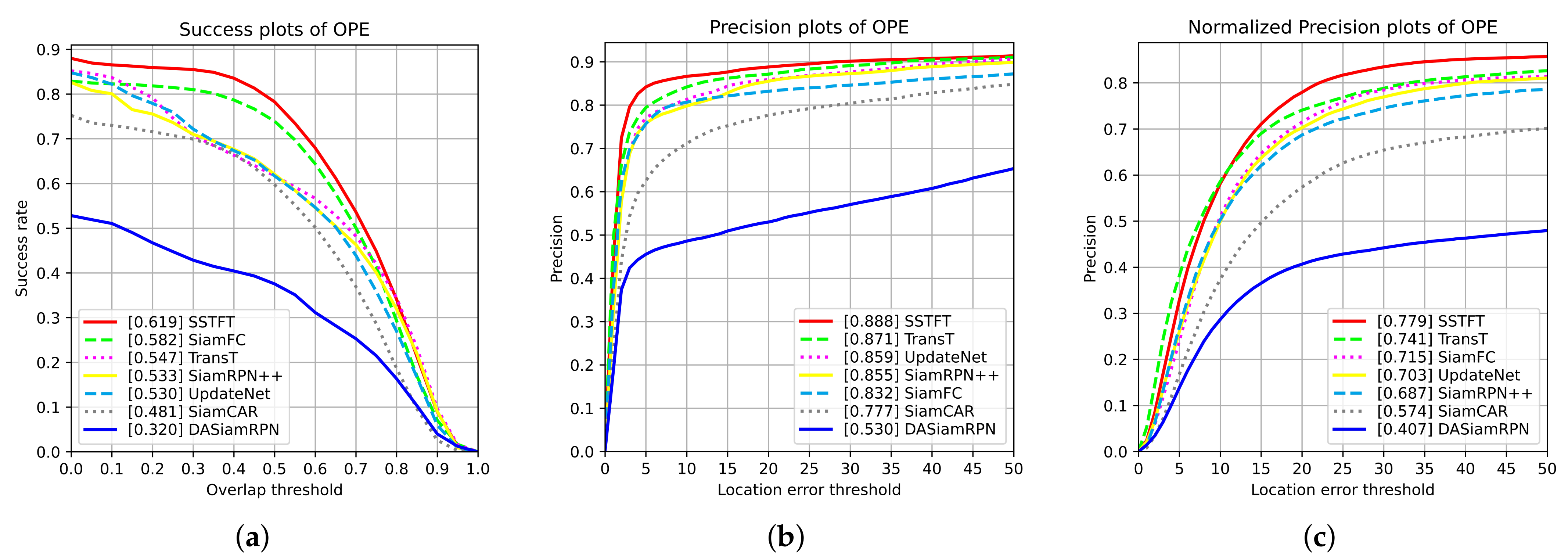
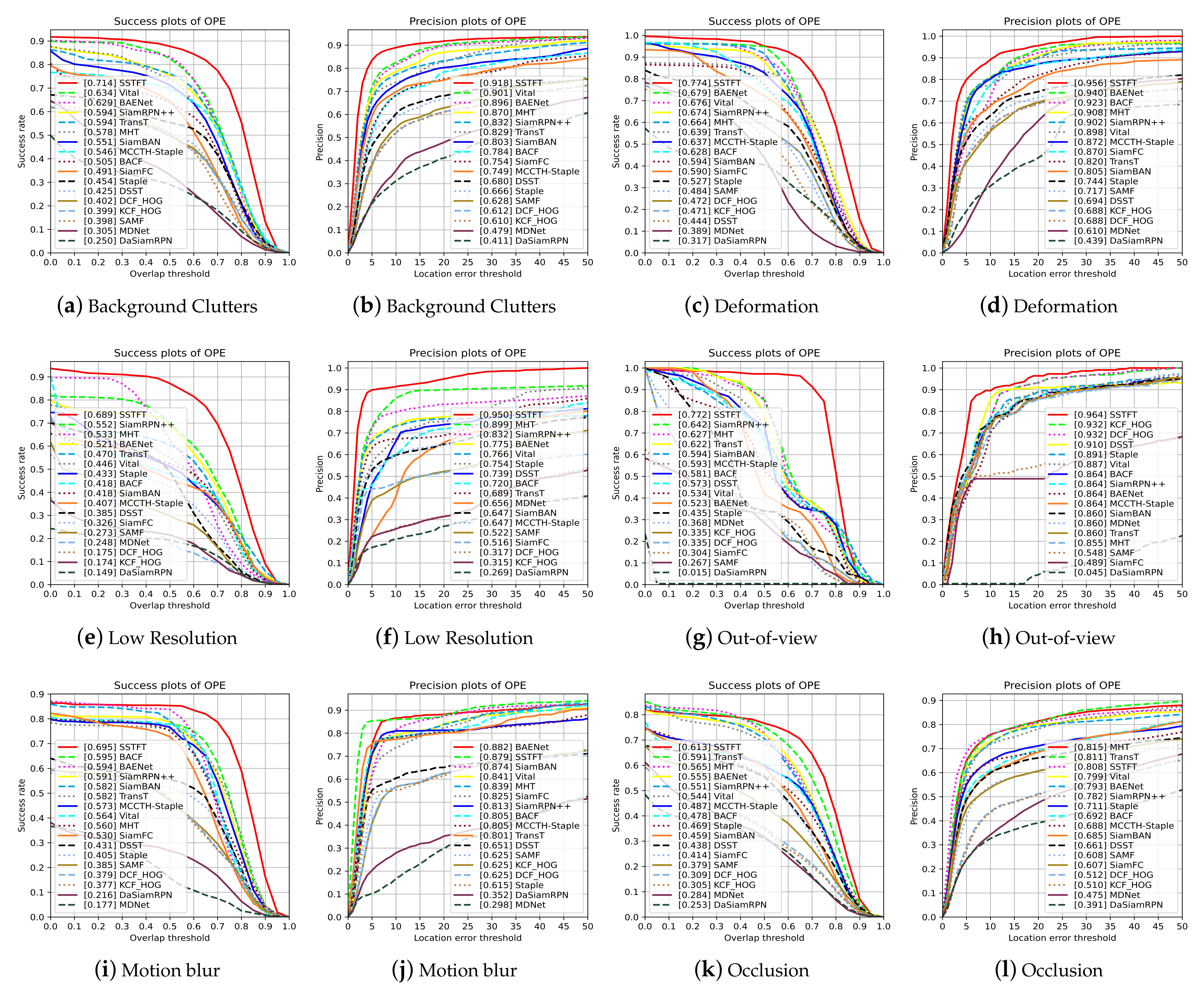
In this paper, a novel hyperspectral video tracker named Spectral-Spatial Transformer-based Feature Fusion Tracker (SSTFT) is proposed to address the aforementioned problems by adequately utilizing the spectral–spatial information of hyperspectral images. As the spectral–spatial information is separate in the original hyperspectral images, the proposed SSTFT adopts a shallow spectral–spatial (SSS) subbranch and a deep ResNet (DRN) subbranch to integrate multi-scale representations and promote preliminary interaction of information. On this basis, a transformer-based context fusion (TCF) module is designed to adequately fuse the template branch and the search branch features, which can effectively establish the context relationship of hyperspectral video sequences. Furthermore, an adaptive dynamic template update (ADTU) module is designed to deal with the problems of object drift in challenging conditions.
To summarize, compared with the existing hyperspectral object trackers, the main contributions of this paper are as follows.
A spectral–spatial multiscale feature extraction module is proposed for the adaptive fusion of multiple-level semantics of hyperspectral videos. Two parallel branches are designed to extract the features with full integration of spectral and spatial information, and each branch is further divided into multiple levels to extract the semantic information. The fusion strategy of coarse-grained and fine-grained features can effectively improve the completeness of the representation of objects and backgrounds.
A context fusion module based on the transformer is proposed to fuse the template branch and the search branch features, which can effectively establish the forward and backward frame-dependence relationship of hyperspectral video sequences with the ranking of prediction box confidence scores rather than cosine penalty. Meanwhile, the proposed method can capture the global interaction of the video with considerable success, improving the robustness performance of the hyperspectral tracker.
An adaptive dynamic template update strategy is proposed to handle the drift of object regression in challenging scenarios. The approach ensures the tracker can adapt to the changing environment and further improves the robustness of performance.
The rest of the paper is structured as follows. The proposed SSTFT tracker is detailed in
Section 2. The experimental results are presented in
Section 3. Finally, the conclusions are drawn in
Section 4.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}