
Distinguishing Buildings from Vegetation in an Urban-Chaparral Mosaic Landscape with LiDAR-Informed Discriminant Analysis

 and
and
Abstract
1. Introduction
2. Materials and Methods
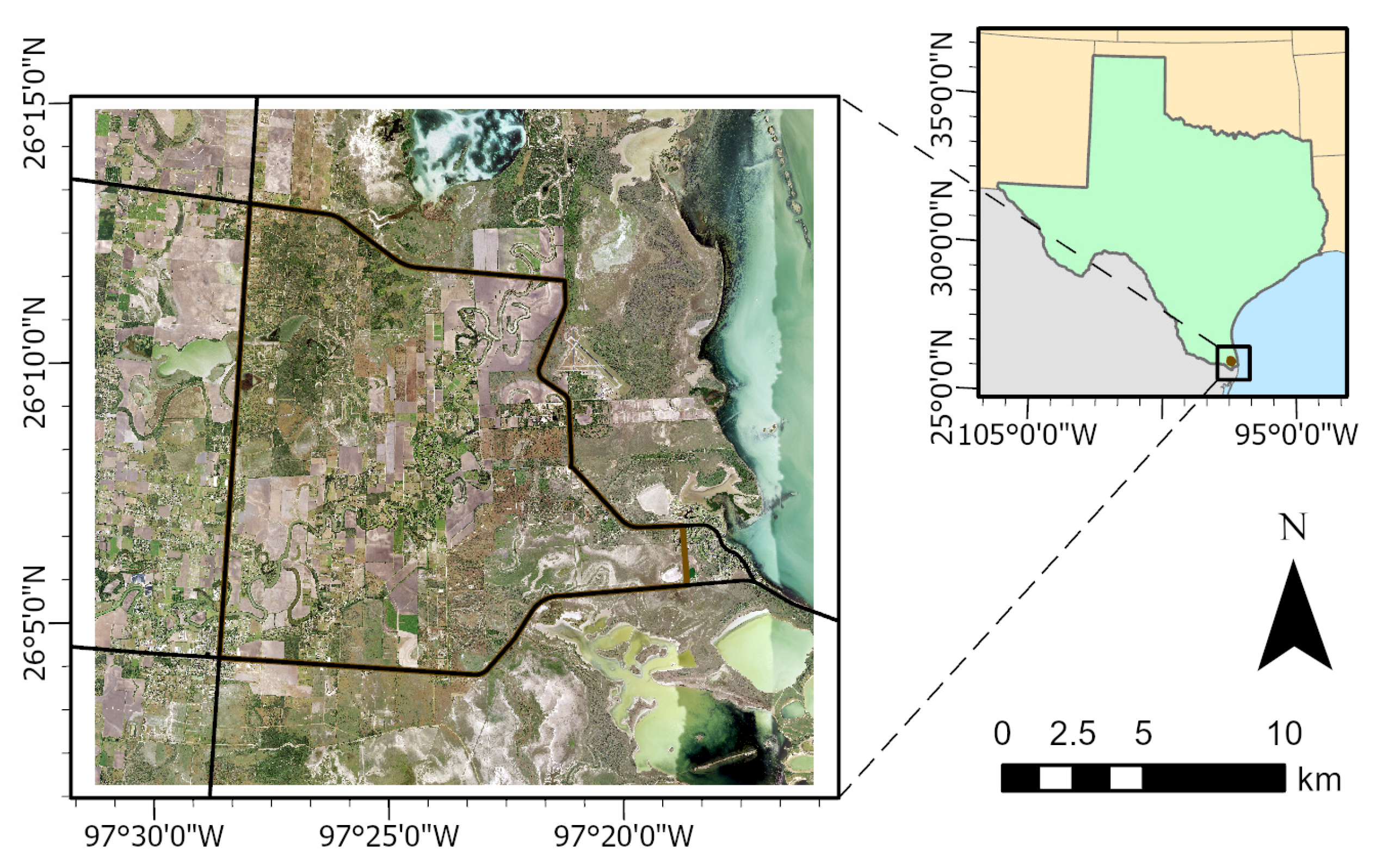
2.1. Study Area
2.2. LiDAR Point Cloud
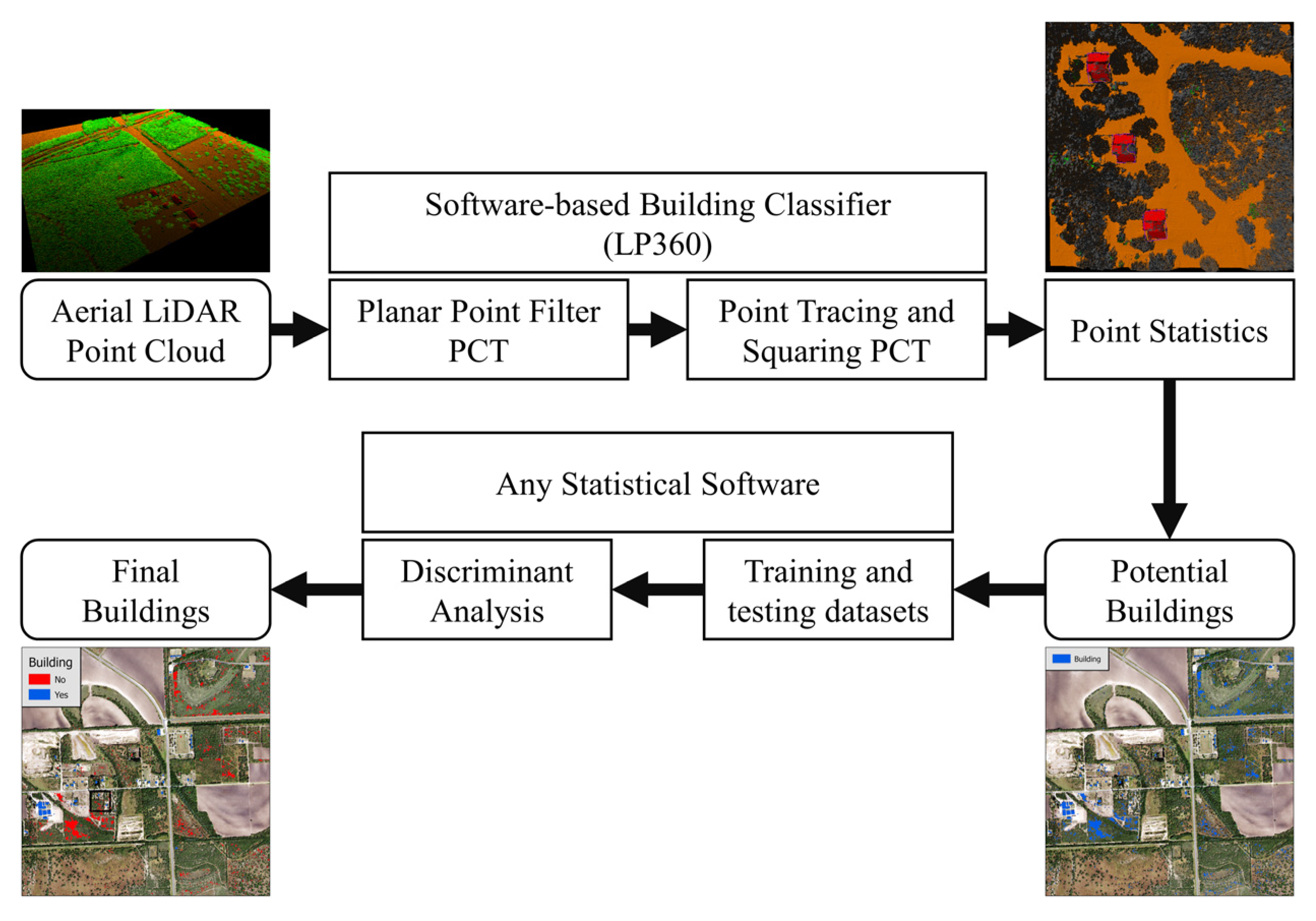
2.3. Building Classification
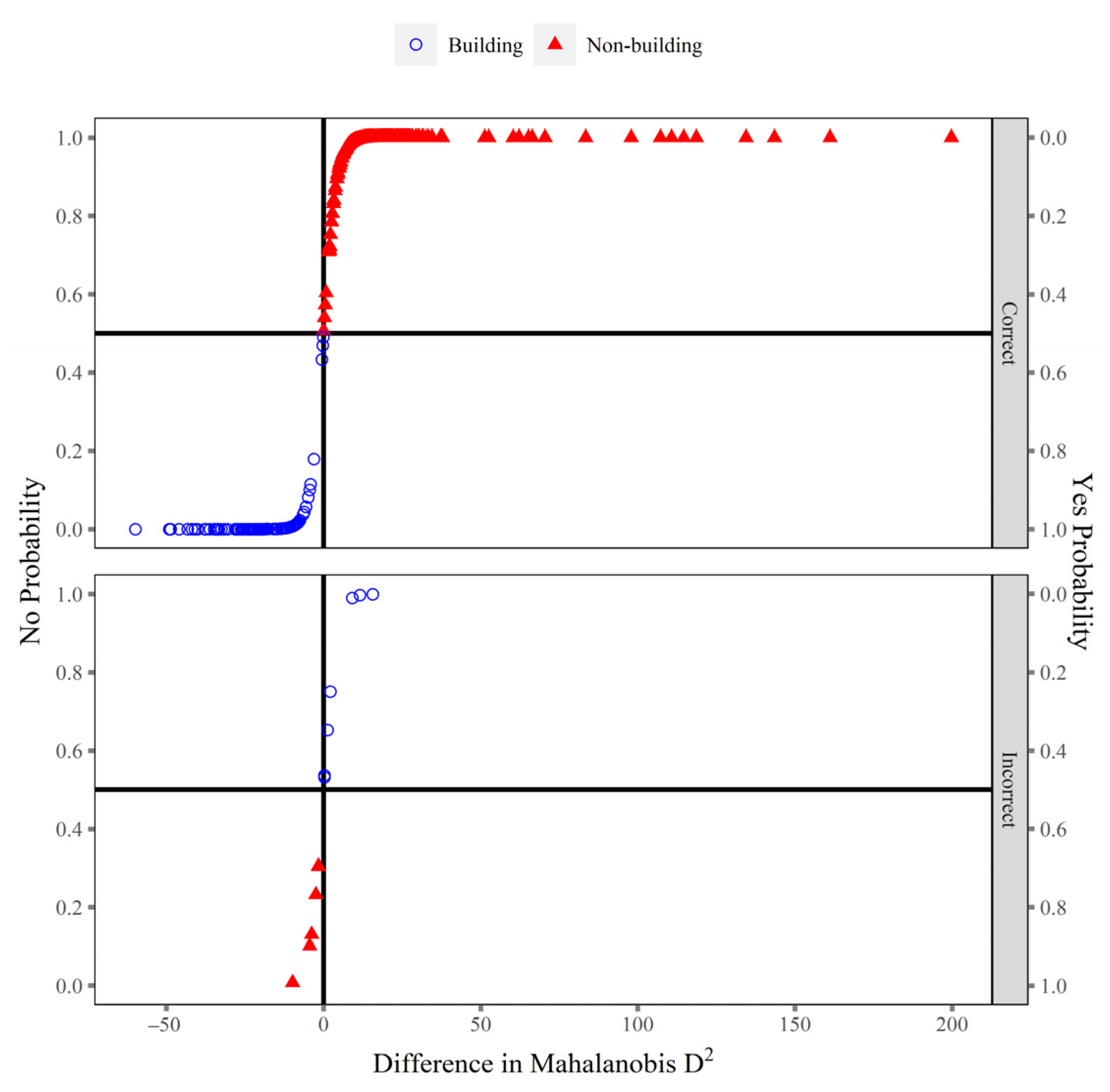
2.4. Discriminant Analysis
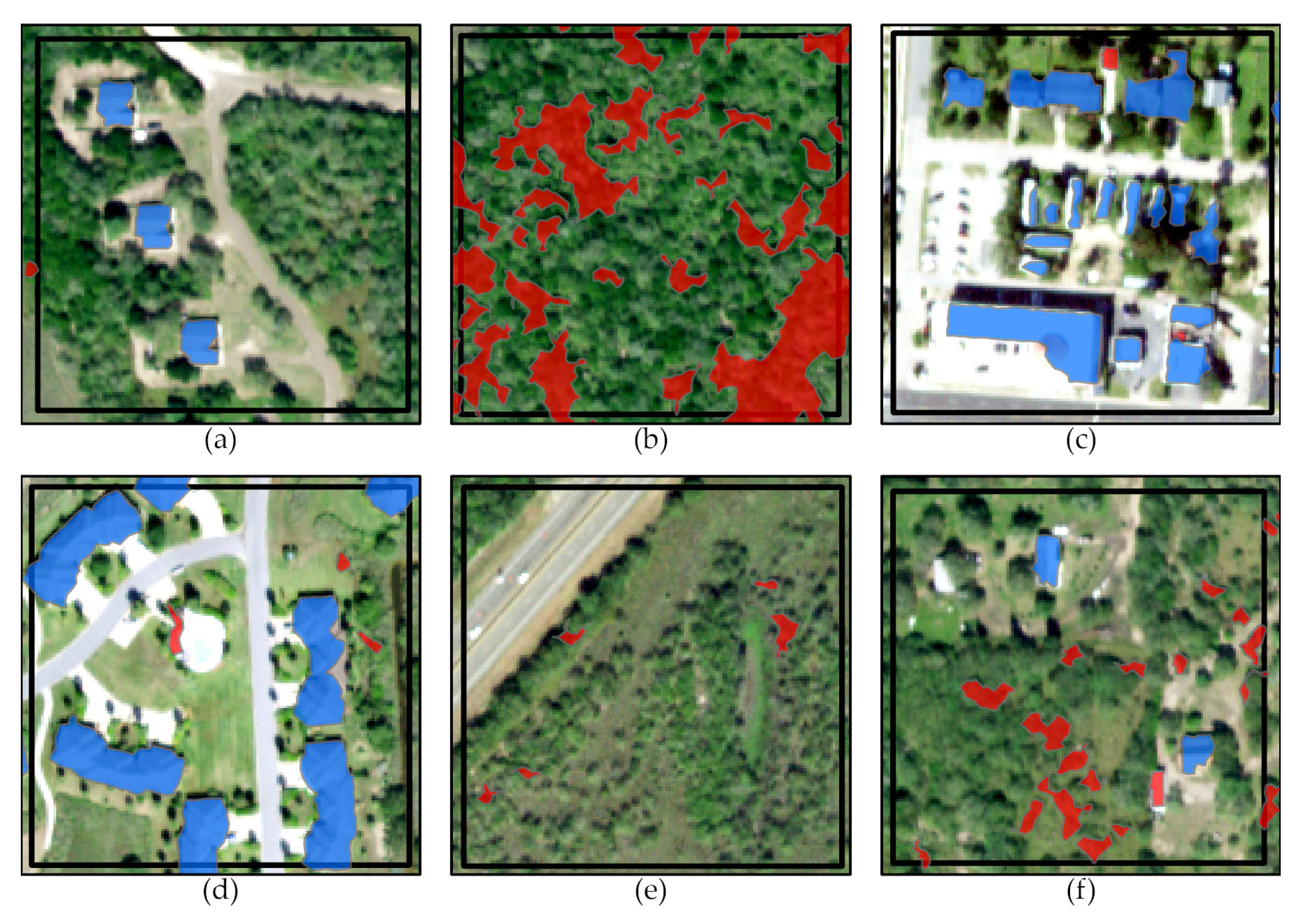
3. Results
4. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Part 1: Processing LiDAR Data
Appendix A.2. Part 2: Discriminant Analysis
Appendix A.3. Sample Code for Quadratic Discriminant Analysis in R and SAS




References
- Kerle, N.; Janssen, L.L.F.; Huurneman, G.C. Principles of Remote Sensing, 3rd ed.; The International Institute for Geo-Information Science and Earth Observation (ITC): Enchede, The Netherlands, 2004. [Google Scholar]
- Abburu, S.; Golla, S.B. Satellite Image Classification Methods and Techniques: A Review. Int. J. Comput. Appl. 2015, 119, 20–25. [Google Scholar] [CrossRef]
- Kamusoko, C.; Aniya, M. Hybrid classification of Landsat data and GIS for land use/cover change analysis of the Bindura district, Zimbabwe. Int. J. Remote Sens. 2009, 30, 97–115. [Google Scholar] [CrossRef]
- Lee, D.H.; Lee, K.M.; Lee, S.U. Fusion of Lidar and Imagery for Reliable Building Extraction. Photogramm. Eng. Remote Sens. 2008, 74, 215–225. [Google Scholar] [CrossRef]
- Lefsky, M.A.; Cohen, W.B.; Parker, G.G.; Harding, D.J. Lidar Remote Sensing for Ecosystem Studies: Lidar, an emerging remote sensing technology that directly measures the three-dimensional distribution of plant canopies, can accurately estimate vegetation structural attributes and should be of particular interest to forest, landscape, and global ecologists. BioScience 2002, 52, 19–30. [Google Scholar] [CrossRef]
- Canaz Sevgen, S.; Karsli, F. An improved RANSAC algorithm for extracting roof planes from airborne lidar data. Photogramm. Rec. 2020, 35, 40–57. [Google Scholar] [CrossRef]
- Yi, Z.; Wang, H.; Duan, G.; Wang, Z. An Airborne LiDAR Building-Extraction Method Based on the Naive Bayes–RANSAC Method for Proportional Segmentation of Quantitative Features. J. Indian Soc. Remote Sens. 2021, 49, 393–404. [Google Scholar] [CrossRef]
- Maltezos, E.; Doulamis, A.; Doulamis, N.; Ioannidis, C. Building Extraction From LiDAR Data Applying Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 155–159. [Google Scholar] [CrossRef]
- Liu, M.; Shao, Y.; Li, R.; Wang, Y.; Sun, X.; Wang, J.; You, Y. Method for extraction of airborne LiDAR point cloud buildings based on segmentation. PLoS ONE 2020, 15, e0232778. [Google Scholar] [CrossRef]
- Huang, X.; Cao, R.; Cao, Y. A Density-Based Clustering Method for the Segmentation of Individual Buildings from Filtered Airborne LiDAR Point Clouds. J. Indian Soc. Remote Sens. 2019, 47, 907–921. [Google Scholar] [CrossRef]
- Gamal, A.; Wibisono, A.; Wicaksono, S.B.; Abyan, M.A.; Hamid, N.; Wisesa, H.A.; Jatmiko, W.; Ardhianto, R. Automatic LIDAR building segmentation based on DGCNN and euclidean clustering. J. Big Data 2020, 7, 102. [Google Scholar] [CrossRef]
- Zhao, C.; Jensen, J.; Weng, Q.; Currit, N.; Weaver, R. Application of airborne remote sensing data on mapping local climate zones: Cases of three metropolitan areas of Texas, U.S. Comput. Environ. Urban Syst. 2019, 74, 175–193. [Google Scholar] [CrossRef]
- McNamara, D.; Mell, W.; Maranghides, A. Object-based post-fire aerial image classification for building damage, destruction and defensive actions at the 2012 Colorado Waldo Canyon Fire. Int. J. Wildland Fire 2020, 29, 174–189. [Google Scholar] [CrossRef]
- Prerna, R.; Singh, C.K. Evaluation of LiDAR and image segmentation based classification techniques for automatic building footprint extraction for a segment of Atlantic County, New Jersey. Geocarto Int. 2016, 31, 694–713. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- McLachlan, G.J. Discriminant Analysis and Statistical Pattern Recognition; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1992. [Google Scholar]
- Elliott, L.F.; Diamond, D.D.; True, D.; Blodgett, C.F.; Pursell, D.; German, D.; Treuer-Kuehn, A. Ecological Mapping Systems of Texas: Summary Report; Texas Parks & Wildlife Department: Austin, TX, USA, 2014. [Google Scholar]
- Shindle, D.B.; Tewes, M.E. Woody Species Composition of Habitats used by Ocelots (Leopardus pardalis) in the Tamaulipan Biotic Province. Southwest. Nat. 1998, 43, 273–279. [Google Scholar]
- United States Geologic Survey. South Texas Lidar; United States Geologic Survey: Washington, DC, USA, 2018. [Google Scholar]
- Heidemann, H.K. Lidar Base Specification; 11-B4; U.S. Geological Survey: Reston, VA, USA, 2012; p. 114. [Google Scholar]
- Zavorka, S.; Perrett, J.J. Minimum Sample Size Considerations for Two-Group Linear and Quadratic Discriminant Analysis with Rare Populations. Commun. Stat. Simul. Comput. 2014, 43, 1726–1739. [Google Scholar] [CrossRef]
- NCSS Statistical Software. Discriminant Analysis. Available online: https://www.ncss.com/wp-content/themes/ncss/pdf/Procedures/NCSS/Discriminant_Analysis.pdf (accessed on 2 May 2022).
- Morrison, M.L. Influence of Sample Size on Discriminant Function Analysis of Habitat use by Birds. J. Field Ornithol. 1984, 55, 330–335. [Google Scholar]
- Williams, B.K.; Titus, K. Assessment of Sampling Stability in Ecological Applications of Discriminant Analysis. Ecology 1988, 69, 1275–1285. [Google Scholar] [CrossRef]
- United States Department of Agriculture. Texas NAIP Imagery; United States Department of Agriculture: Washington, DC, USA, 2016. [Google Scholar]
- Korkmaz, S.; Goksuluk, D.; Zararsiz, G. MVN: An R Package for Assessing Multivariate Normality. R J. 2014, 6, 151–162. [Google Scholar] [CrossRef]
- Mecklin, C.J.; Mundfrom, D.J. A Monte Carlo comparison of the Type I and Type II error rates of tests of multivariate normality. J. Stat. Comput. Simul. 2005, 75, 93–107. [Google Scholar] [CrossRef]
- Bulut, H. An R Package for multivariate hypothesis tests: MVTests. Technol. Appl. Sci. (NWSATAS) 2019, 14, 132–138. [Google Scholar] [CrossRef]
- Layard, M.W.J. A Monte Carlo Comparison of Tests for Equality of Covariance Matrices. Biometrika 1974, 61, 461–465. [Google Scholar] [CrossRef]
- Lachenbruch, P.A. Discriminant Analysis; Hafner Press: New York, NY, USA, 1975. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S; Springer: New York, NY, USA, 2002. [Google Scholar]
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Conover, W.J. Practical Nonparametric Statistics, 3rd ed.; John Wiley & Sons, Inc.: New York, NY, USA, 1999. [Google Scholar]
- Mongus, D.; Lukač, N.; Žalik, B. Ground and building extraction from LiDAR data based on differential morphological profiles and locally fitted surfaces. ISPRS J. Photogramm. Remote Sens. 2014, 93, 145–156. [Google Scholar] [CrossRef]
- Graham, L. LP360 (Advanced): Planar Point Filter User Guide; QCoherent Software, LLC: Madison, AL, USA, 2013. [Google Scholar]
- Gray, J.T. Community Structure and Productivity in Ceanothus Chaparral and Coastal Sage Scrub of Southern California. Ecol. Monogr. 1982, 52, 415–434. [Google Scholar] [CrossRef]
- Frost, P. The ecology of miombo woodlands. In The Miombo in Transition: Woodlands and Welfare in Africa; Campbell, B., Ed.; Centre for International Forestry Research: Bogor, Indonesia, 1996; pp. 11–57. [Google Scholar]
- LaFrankie, J.V.; Ashton, P.S.; Chuyong, G.B.; Co, L.; Condit, R.; Davies, S.J.; Foster, R.; Hubbell, S.P.; Kenfack, D.; Lagunzad, D.; et al. Contrasting structure and composition of the understory in species-rich tropical rain forests. Ecology 2006, 87, 2298–2305. [Google Scholar] [CrossRef]
- Graham, L. Point Group Tracing and Squaring in LP360: A Heuristic Discussion of Parameter Settings; QCoherent Software, LLC: Madison, AL, USA, 2013. [Google Scholar]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 6th ed.; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 2007. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Point Cloud Task | Setting | Value |
|---|---|---|
| Planar Point Filter | Input Points | Last Returns Only |
| Minimum Height | 2 m | |
| Maximum Height | 65 m | |
| Minimum Slope | 0° | |
| Maximum Slope | 45° | |
| Minimum Plane Edge | 5.5 m | |
| Plane Fit | 0.20 standard deviations | |
| N Threshold | 0.025 m | |
| Maximum Grow Window | 500 (unitless) | |
| Point Tracing and Squaring | Grow Window | 1.7 m |
| Trace Window | 3.4 m | |
| Minimum Area | 25 m2 |
| Classification | Building | Non-Building |
|---|---|---|
| Ground | 0.333 ± 0.105 | 0.532 ± 0.196 |
| Unclassified | 0.455 ± 0.144 | 0.782 ± 0.141 |
| Building | 0.960 ± 0.153 | 0.464 ± 0.135 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yamashita, T.J.; Wester, D.B.; Tewes, M.E.; Young, J.H., Jr.; Lombardi, J.V. Distinguishing Buildings from Vegetation in an Urban-Chaparral Mosaic Landscape with LiDAR-Informed Discriminant Analysis. Remote Sens. 2023, 15, 1703. https://doi.org/10.3390/rs15061703
Yamashita TJ, Wester DB, Tewes ME, Young JH Jr., Lombardi JV. Distinguishing Buildings from Vegetation in an Urban-Chaparral Mosaic Landscape with LiDAR-Informed Discriminant Analysis. Remote Sensing. 2023; 15(6):1703. https://doi.org/10.3390/rs15061703
Chicago/Turabian StyleYamashita, Thomas J., David B. Wester, Michael E. Tewes, John H. Young, Jr., and Jason V. Lombardi. 2023. "Distinguishing Buildings from Vegetation in an Urban-Chaparral Mosaic Landscape with LiDAR-Informed Discriminant Analysis" Remote Sensing 15, no. 6: 1703. https://doi.org/10.3390/rs15061703
APA StyleYamashita, T. J., Wester, D. B., Tewes, M. E., Young, J. H., Jr., & Lombardi, J. V. (2023). Distinguishing Buildings from Vegetation in an Urban-Chaparral Mosaic Landscape with LiDAR-Informed Discriminant Analysis. Remote Sensing, 15(6), 1703. https://doi.org/10.3390/rs15061703