1. Introduction
As an indispensable earth observation technology, remote sensing can capture high-precision data, which provides an important scientific basis for urban planning, disaster assessment and environmental remediation. In recent years, with the increasing advancement of observation platforms and sensors, the captured remote sensing data products are evolving in a diversified direction. Currently, diverse sensors can acquire the features at different levels of the ground, such as hyperspectral sensors that capture the spectral features of an object, and LiDAR sensors that obtain three-dimensional information about the ground. Both data sources have been widely used in the task of ground object classification.
With the richness of waveband information and the characteristic of image-spectrum merging [
1], hyperspectral images have been widely used in research fields such as feature classification [
2,
3,
4,
5,
6], anomaly detection [
7,
8,
9,
10], and image segmentation [
11,
12,
13,
14,
15], etc. However, utilization of spectral information alone is prone to misclassification, as the hyperspectral images do not contain the elevation information of ground objects [
16] and are susceptible to the issues caused by “synonyms spectrum” and mixed pixels. As an active earth observation method, LiDAR can rapidly capture three-dimensional spatial information of the ground targets [
17], which are perceived to be an effective supplement to hyperspectral observations. The fusion of the above two types of data helps to achieve the complementary advantages of both, thus improving the classification accuracy of ground objects [
18].
So far, the research on fusing HSI and LiDAR data has been extensively carried out in different fields by numerous scholars. Dalponte et al. [
19] classified tree species in complex forest areas by fusing HSI and LiDAR data, and the results showed that the fusion of two kinds of data could achieve the high-precision classification of tree species. Hartfield et al. [
20] conducted a study on the classification of land cover types by fusing elevation information from LiDAR and spectral information from HSI, and the results showed that the classification accuracy of land cover types could be improved by fusing two kinds of data. For the classification of ground objects in urban areas, M. Khodadadzadeh et al. [
21] proposed a multi-feature learning method that combined HSI and LiDAR data jointly, and the classification accuracy was significantly improved. The above studies indicate that the fusion of multi-source data can achieve complementary advantages and compensate for the limitations of a single data source, thus improving the classification accuracy of ground objects.
The fusion methods of multi-source data can be classified as pixel-level fusion, feature-level fusion, and decision-level fusion. Considering the data structure differences between HSI and LiDAR, the two data are more suitable for fusion at the feature level or decision level. Currently, feature-level fusion is mostly implemented using feature overlay and model-based processing. Based on the extended morphological attribute profiles (EAPs), Pedergnana et al. [
22] extracted features from hyperspectral and LiDAR data, respectively, which were then fused using feature overlay with the original hyperspectral images. Rasti B et al. [
23] first used extinction profiles (EPs) to extract spectral and elevation information from hyperspectral and LiDAR data and then performed model fusion using total variation component analysis. In the feature-level fusion process of HSI and LiDAR, simple concatenation or stacking of high-dimensional features may lead to the Hughes phenomenon [
21]. To cope with this issue, principal component analysis (PCA) is often adopted in most studies to reduce the data dimension of hyperspectral images [
24]. Decision-level fusion methods mainly include voting and statistical models [
25]. Liao et al. [
26] used SVM to classify the spectral features, spatial features, elevation features and fusion features, respectively, and then based on these four classification results, the decision-level fusion can thus be accomplished by weighted voting. Zhang et al. [
27] fused the classification results of different data by combining the soft and hard decision fusion strategies. Zhong et al. [
28] first used three classifiers, maximum likelihood estimation, SVM and polynomial logistic regression, to classify the features, respectively, and then fused all these different classification results at the decision level.
Although both feature-level fusion and decision-level fusion methods can achieve effective fusion of features, they both require considerable effort to design suitable feature extractors. Compared with traditional feature extraction methods, deep learning can mine high-level semantic features from data in an end-to-end manner [
29,
30]. On this basis, previous studies have shown that using deep learning to fuse HSI and LiDAR for classification can yield better classification results. By treating the LiDAR data as an additional spectral band of HSI, Morchhale et al. [
31] directly input the augmented HSI to Convolutional Neural Networks (CNNs) for feature learning. Chen et al. [
32] designed a two-branch network in which a CNN module was introduced in each branch to extract the features from HSI and LiDAR, respectively, and then a fully connected network was employed to fuse these extracted features. Li et al. [
33] designed a dual-channel spatial, spectral, and multi-scale attention convolutional long short-term memory neural network to fuse the multiple features extracted from HSI and LiDAR data through a composite attentional learning mechanism combined with a three-level fusion module. Li et al. [
34] fused the spatial, spectral and elevation information extracted from HSI and LiDAR, respectively, by designing a three-branch residual network. Zhang et al. [
35] proposed an interleaving perception convolutional neural network IP-CNN, which reconstructed HSI and LiDAR data by a bi-directional self-encoder and fused the multi-source heterogeneous features extracted from these two kinds of data in an interleaved joint manner.
The multi-branch structure is an effective framework for multi-source data fusion based on deep learning. As a classical two-branch structured network, the Siamese Network [
36] consists of two neural networks with the same structure and shared weights. Compared with conventional two-branch networks, Siamese Networks are often used to measure the similarity of pairs of samples by connecting two sub-networks together through a distance metric loss function, which allows the features extracted from different sub-networks to have a higher similarity. With the advantages of fewer parameters, faster calculation speed and strong correlation between branches, Siamese Networks have been widely used in the field of computer vision, such as object tracking, etc. However, the weight -sharing mechanism in Siamese Networks restricts to some extent that the difference between the two sub-branch networks cannot be too large. In other words, directly using the Siamese Network to fuse HSI and LiDAR cannot take into consideration the differences in the structure of HSI and LiDAR data, so it is necessary to achieve the multi-source heterogeneous data fusion by constructing some Pseudo-Siamese Network with superior performance.
As a popular method in the field of natural language processing and computer vision in recent years, the attention mechanism can achieve automatic focus on the target region based on the degree of feature saliency, weakening the impact caused by unnecessary features. Therefore, it is necessary to equip deep learning models with the attention mechanism to improve classification accuracy. Because the attention mechanism can adaptively assign different weights to each spectral channel and spatial region, characterizing their different levels of contribution to the classification task. At present, the attention mechanisms mainly include Non-local [
37], channel attention mechanism [
38], spatial attention mechanism [
39], self-attention mechanisms [
40], etc. Specifically, the channel attention mechanisms and spatial attention mechanisms are favored in the field of image processing due to their ability to focus on salience information in the channel and spatial domains, respectively, and both have a small number of parameters.
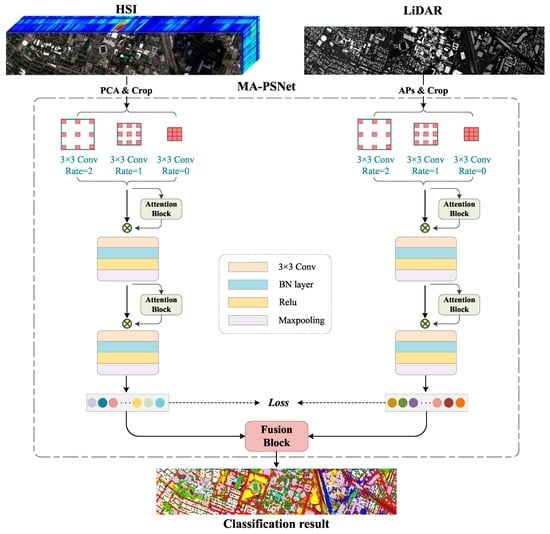
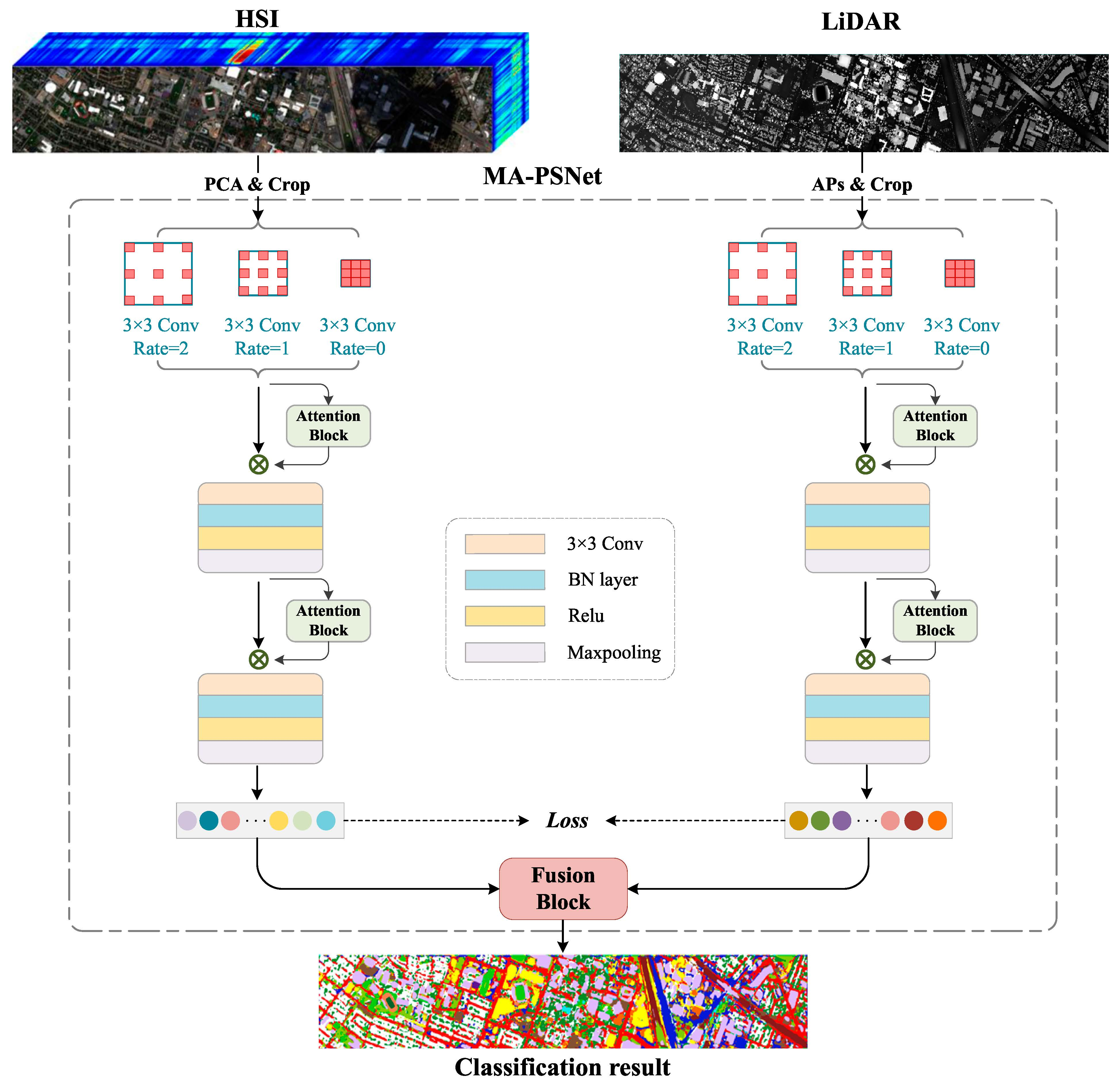
To fully integrate HSI and LiDAR, this paper proposes a multi-scale Pseudo-Siamese Network with an attention mechanism. This network consists of two sub-branch networks, which extract the features from HSI and LiDAR, respectively, thus further achieving decision-level data fusion of HSI spectral features, LiDAR elevation information, and the fused features of both. The main contributions of this study are given as follows:
Considering that the distance loss function in the Pseudo-Siamese Network can enhance the correlation between different data sources, which is helpful to improve the fusion effect, this study applies Pseudo-Siamese Network to multi-source heterogeneous data fusion for the first time.
To extract the multi-scale features of the two heterogeneous data, a multi-scale dilated convolution module is elaborately designed. The module consists of three convolutions with different dilated rates, which can consider local neighborhood information without significantly increasing the number of parameters.
By introducing the convolutional block attention module (CBAM), each spectral channel and spatial region can be endowed with different weights adaptively to characterize their different contributions to the classification task. Therefore, the Pseudo-Siamese Network training can be more targeted based on the degree of feature saliency, enabling the model classification performance to be improved.
The rest of this article is organized as follows.
Section 2 introduces the detailed architecture of the MA-PSNet. The descriptions of data sets and experimental results are given in
Section 3. Then,
Section 4 is devoted to the discussion of model validity. Finally,
Section 5 concludes this article.
2. Methods
This paper proposes a multi-scale Pseudo-Siamese Network with an attention mechanism. Based on the pseudo-twin network framework, the network uses two sub-branch networks to extract the features of HSI and LiDAR respectively, which can not only consider the differences between the two data structures of HSI and LiDAR but also make the extracted two features have higher similarity, thus enhancing the connection between spectral and elevation information. In addition, to enlarge the receptive field of the image, a multi-scale cavity convolution module is introduced to obtain the feature information of the image at different scales. At the same time, a convolutional attention module is added to the network to highlight the significant information of the objects to be concerned. This module can give different weights to the features in both the channel and spatial dimensions according to their importance, thus improving the classification effect of the network model. The specific process of the method proposed in this paper is shown in
Figure 1.
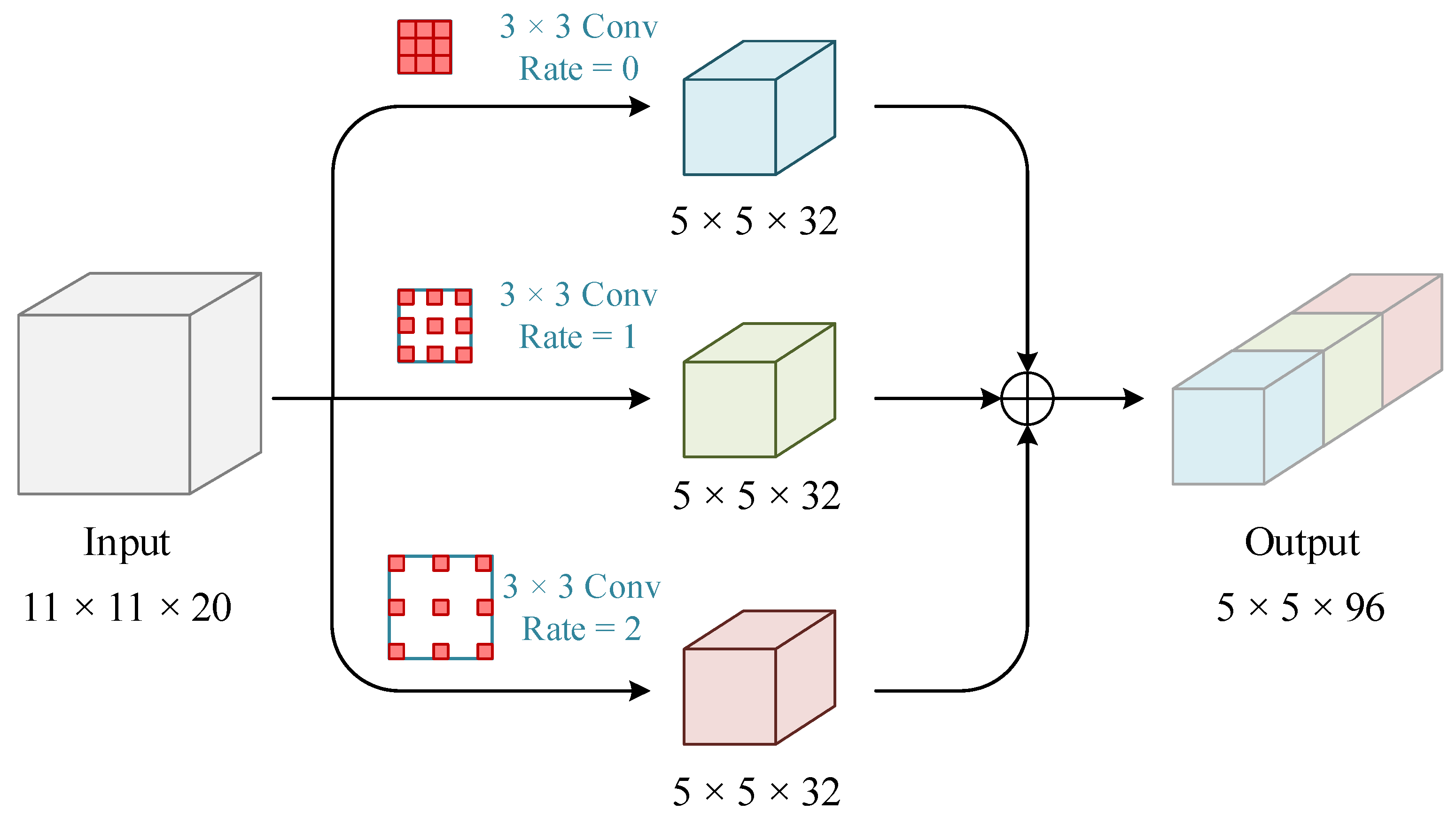
2.1. Multi-Scale Cavity Convolution Module
The existing feature extraction models are unable to extract the spectral and spatial features fully, the convolution scale is usually single, and the spatial context information is not sufficiently utilized during feature extraction. Thus, a multi-scale cavity convolution module is designed to capture local features at different scales in an image in light of its advantages, including increased receptive field and low computational effort. As shown in
Figure 2, the module uses three convolutions with different dilated rates to extract the multi-scale feature information, and the dilated rates are set to {0, 1, 2} in this paper.
Specifically, the pre-processed HSI and LiDAR are first fed into the above multi-scale dilated convolution layers, respectively, for the multi-scale feature extraction, and the proposed features are spliced as input for the subsequent convolution layers. The introduction of dilated convolution module for multi-scale feature extraction can effectively avoid the loss of information caused by the difference in object scale.
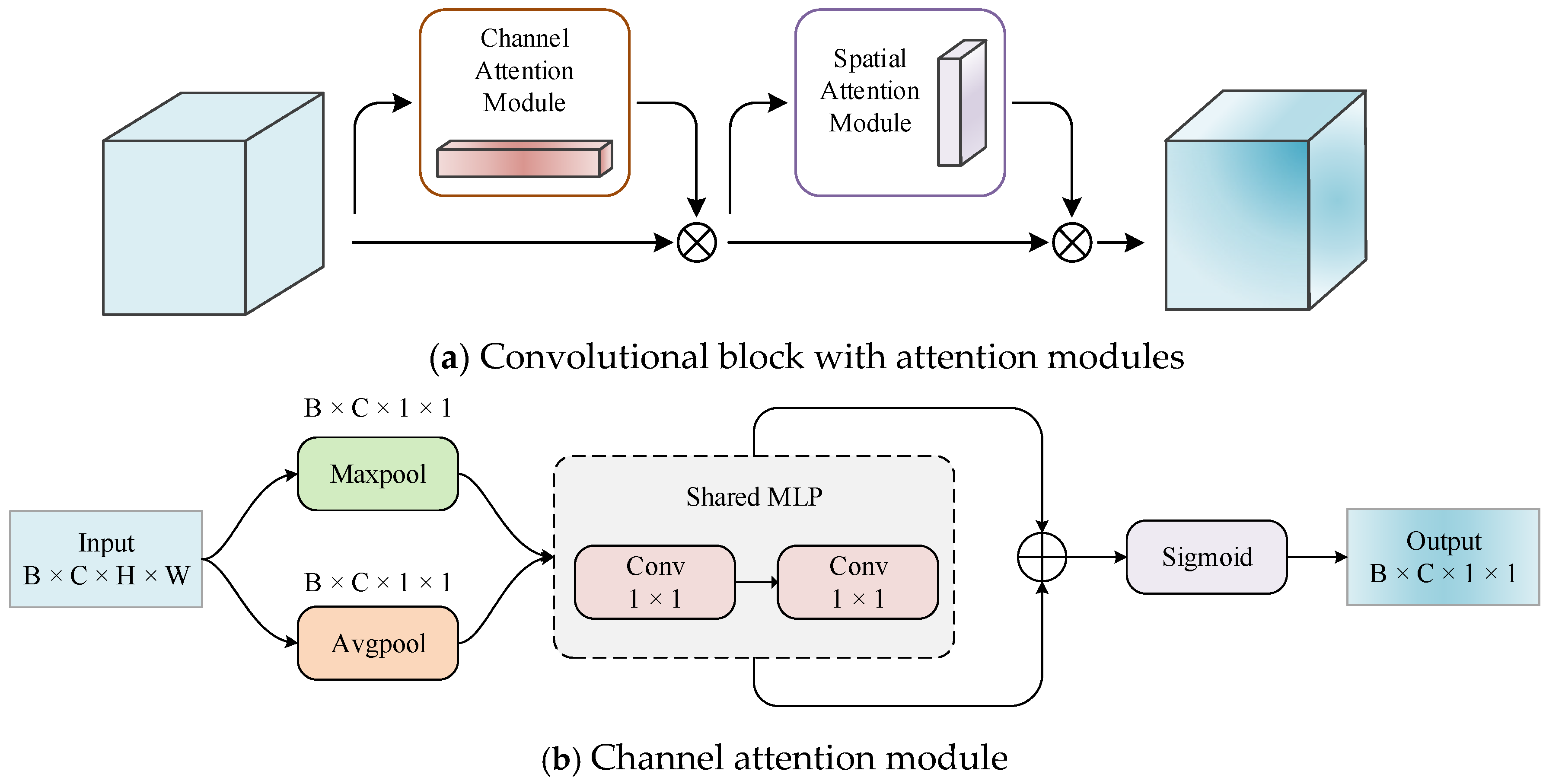
2.2. Convolutional Block Attention Module
The Convolutional Block Attention Module (CBAM) is a lightweight feedforward convolutional neural network attention module consisting of channel and spatial attention mechanisms. Its structure is shown in
Figure 3. The channel attention module and spatial attention module are combined with each other in sequential order [
39] and can easily be integrated into the CNN architecture (accessed after each convolutional layer) for end-to-end training. They can effectively improve the ability of the convolutional layer to extract key features and suppress unimportant features.
The channel attention module identifies the differences in the importance of different channels in the feature map.
Specifically, the Max pooling and Average pooling are firstly conducted upon each channel of the feature map , yielding two channel features and with dimensions of . Then, these two channel features are respectively fed into a shared fully connected neural network composed of a multi-layer perceptron () and a hidden layer for subsequent processing. Finally, the two processed feature maps are added together and activated by the Sigmoid function to produce the channel attention map .
The above workflow of the channel attention module can be summarized as Equation (1), where
denotes the sigmoid function, and
,
are the weights of
.
Further, the channel attention map obtained above is then multiplied with by each element to generate , which will be the input to the spatial attention module.
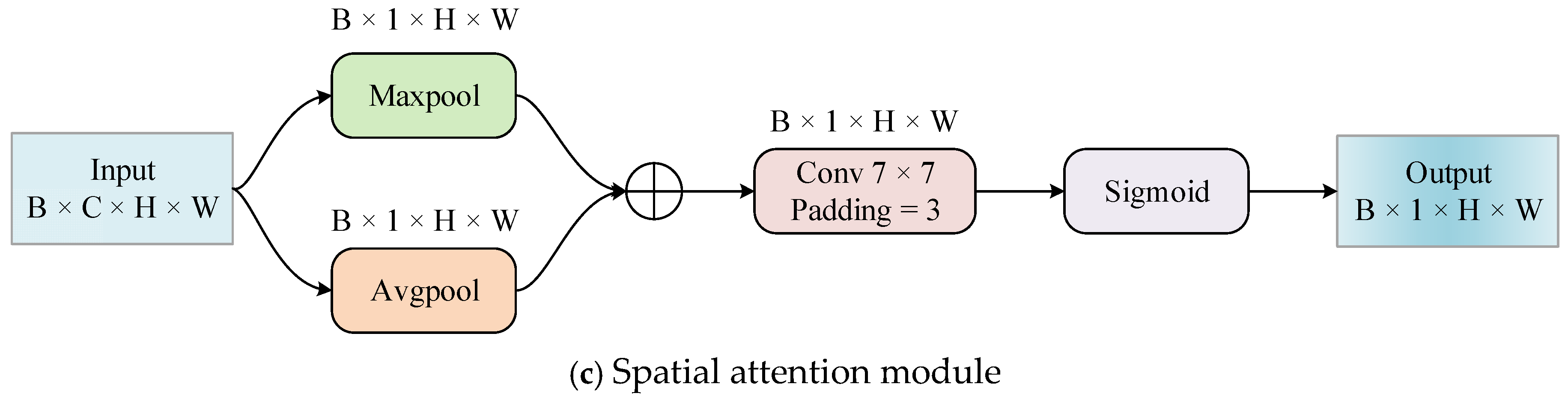
The spatial attention module is introduced to identify the difference in importance of different regions in the feature map. Its specific process is given as follows:
Firstly, the global max pooling and global average pooling are performed on each channel of
to obtain the feature maps of
and
, respectively. Later, these two feature maps are spliced together and processed by a convolution with kernel size of
. After one more step of activation by the sigmoid function, the spatial attention feature map
is finally produced. The above process can be summarized as Equation (2), where
and
represent the activation function and convolution layer with
convolution kernel, respectively.
At this point, the ultimate feature map can thus be obtained by multiplying the corresponding elements of and .
The whole CBAM process above can be equivalent to Equation (3), where the symbol
denotes the element-by-element multiply operation.
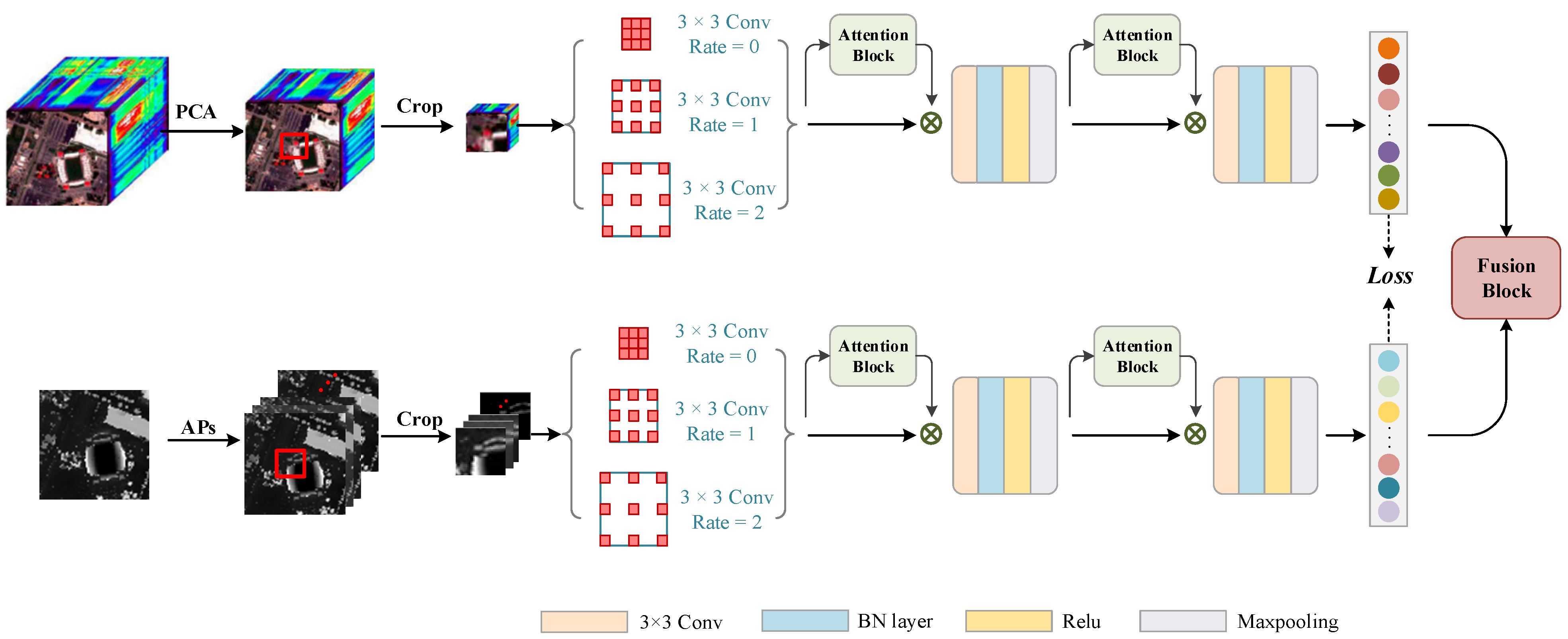
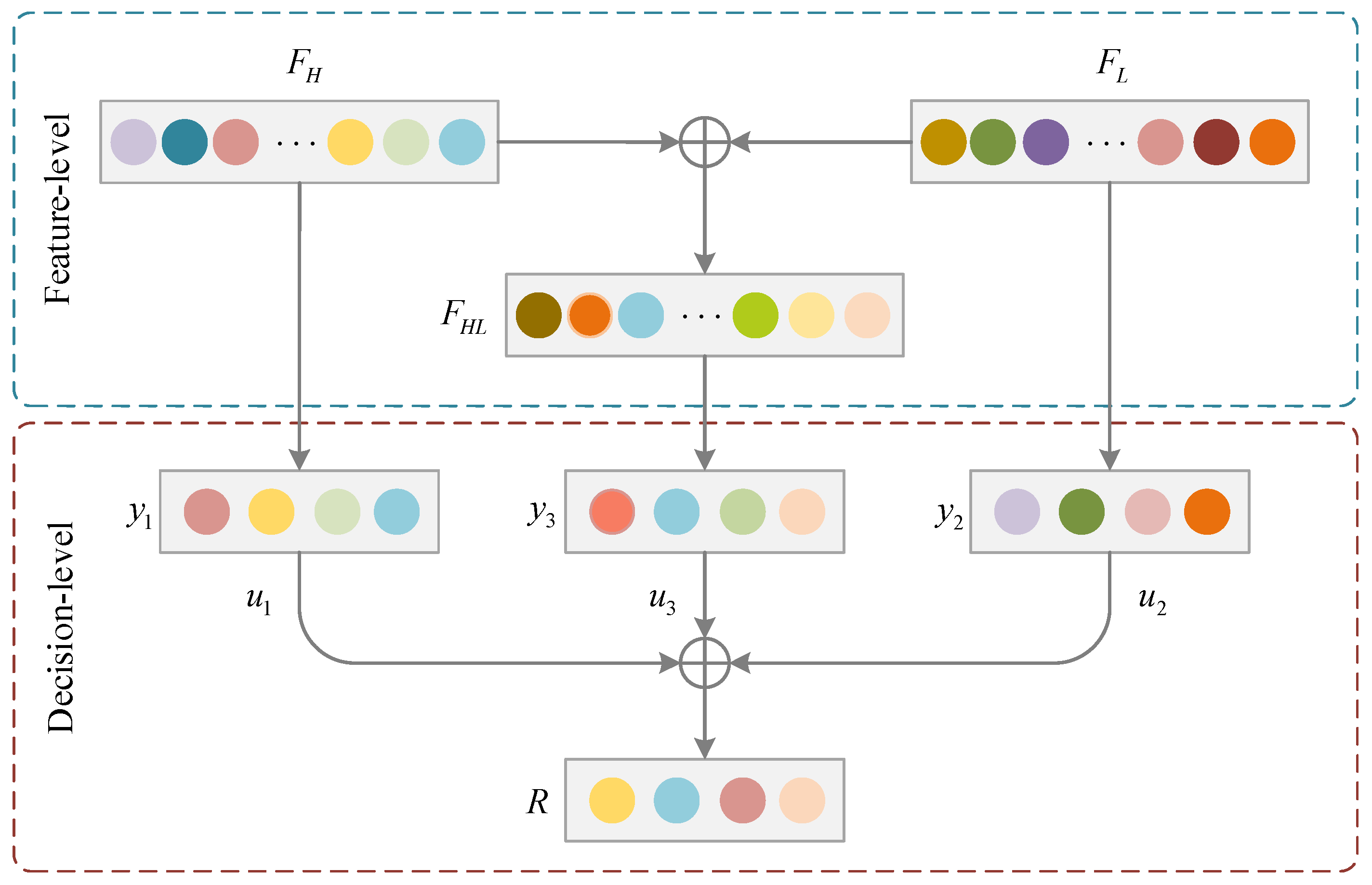
2.3. Fusion Strategy
Relevant studies have confirmed that the fusion of spectral features from HSI with elevation information from LiDAR can effectively improve the ability of ground target classification [
41]. Existing deep learning models typically perform feature fusion by usually stacking the extracted features together and then processing them by means of several fully connected layers to achieve the final feature fusion. However, due to a large number of parameters in the fully connected layer, the insufficient number of training samples will lead to increased difficulty in model training. To this end, this paper develops a fusion strategy based on a combination of feature-level and decision-level fusions for achieving better classification results. The logical structure of this fusion strategy is shown in
Figure 4.
The feature-level fusion is to obtain a new feature
by fusing features
and
, which are learned from HSI and LiDAR, respectively. These two features are fused by summing their corresponding pixels, as in Equation (4).
As presented in
Figure 4, suppose
,
and
are the output results corresponding to the above three features
,
and
. Moreover, the final classification results are obtained through the decision-level fusion, which is achieved using the weighted summation, as shown in Equation (5).
where the symbol
denotes the element-based product operator.
,
and
are the weights corresponding to the three output results, respectively.
The whole fusion process above can be expressed as Equation (6):
where
represents the final output of the fusion module, and
denotes the decision-level fusion;
,
,
are the three output layers, and
,
,
are their corresponding weights.
2.4. Loss Function
By enhancing the connection between spectral information and elevation information, the ground object features expressed based on multi-source data can have higher similarity, thus contributing to improving the subsequent feature fusion effect. As shown in
Figure 1, the proposed method introduces a distance loss function
into feature fusion to supervise the feature learning similarity using two kinds of data.
Assuming that
and
are the input samples of HSI and LiDAR respectively, and
,
are the vectors corresponding to
and
in the feature space, the loss value of their similarity can thus be calculated as follows:
Assuming that
are the three outputs corresponding to each sample
, then their loss values can be calculated through the cross-entropy loss function as follows.
where
, and
is the number of training samples.
According to Equation (8) above, three loss values
,
and
can be calculated. Thereinto,
and
are responsible for supervising the process of HSI and LiDAR feature learning, respectively, and
is used for the process of HSI and LiDAR data fusion. The final total loss
is actually a weighted combination of
,
,
and
, as expressed in Equation (9).
where
,
,
and
represent the weight parameters of
,
,
and
, respectively. In this method,
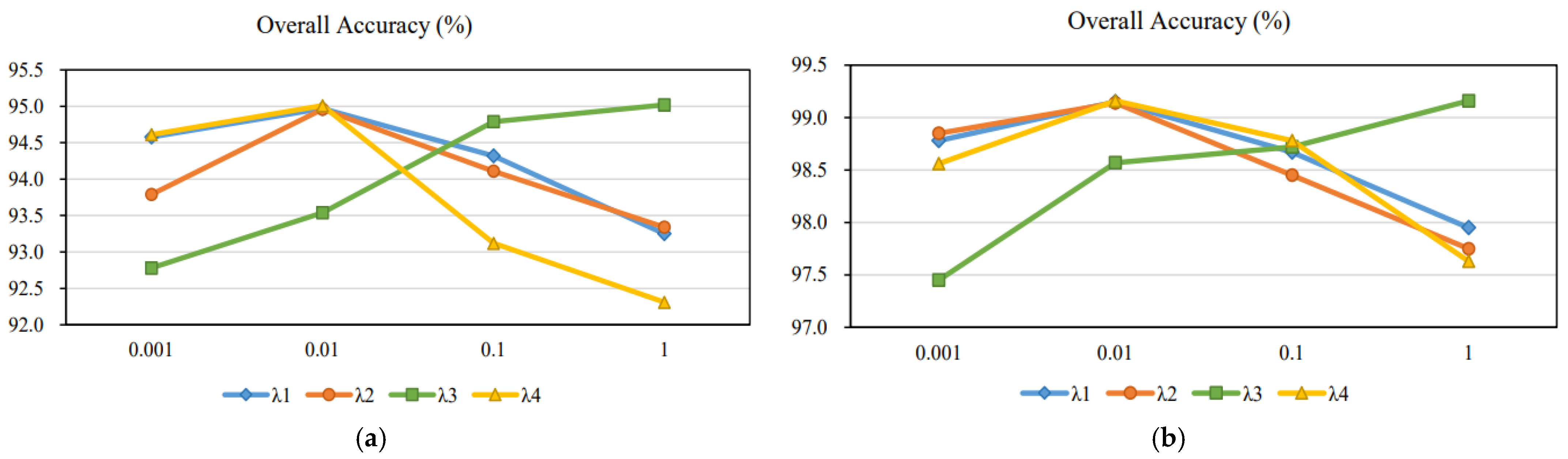
,
and
is set to 0.01 while
is set to 1.
During the implementation process, can optimize the network using the backpropagation algorithm. Moreover, , and can also be served as the regularization terms for , as such practice can widely reduce the overfitting risk in the process of network training. In the end, the test set is input into the trained network for classification prediction so as to accomplish the classification of ground objects.
5. Conclusions
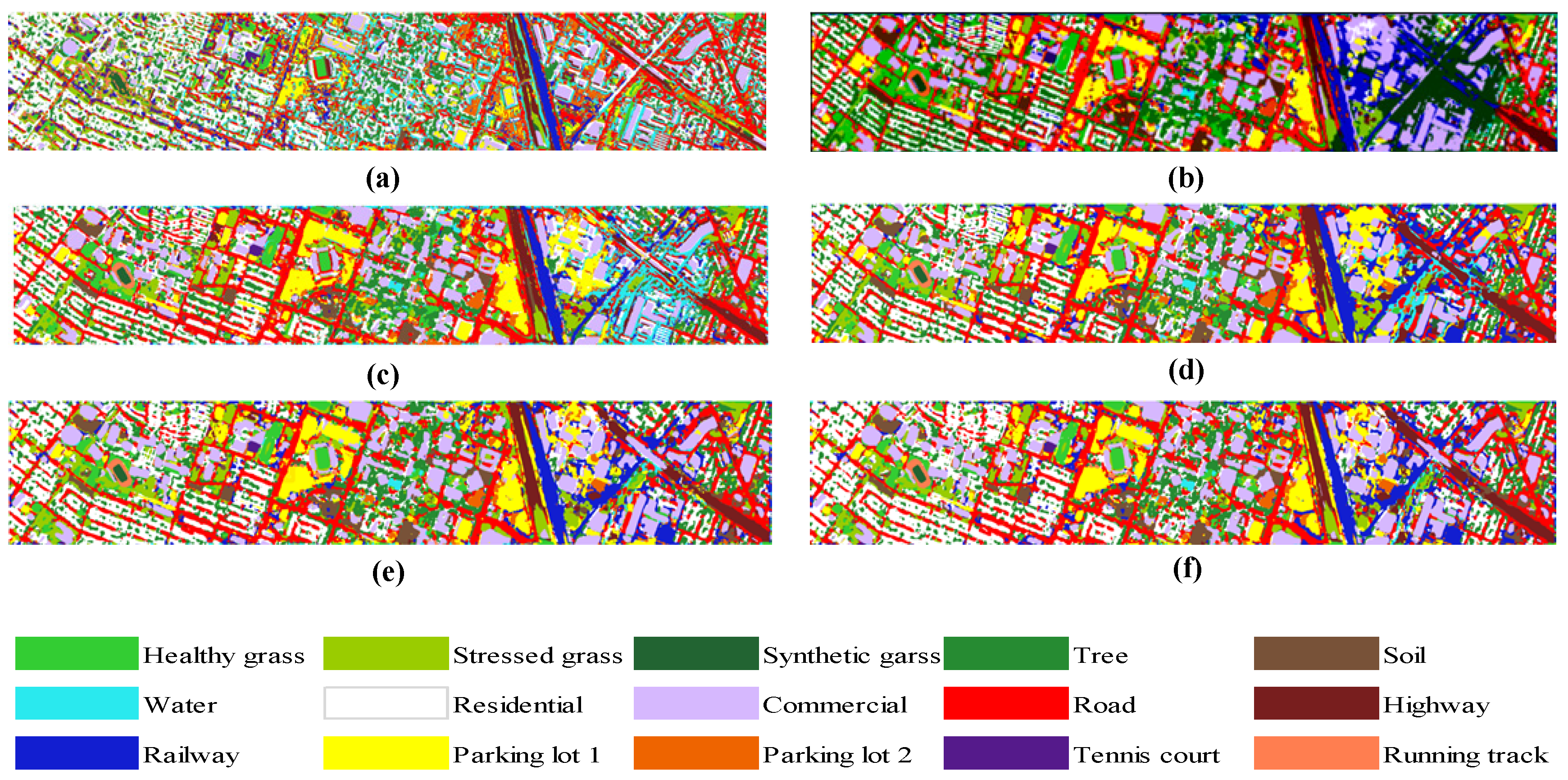
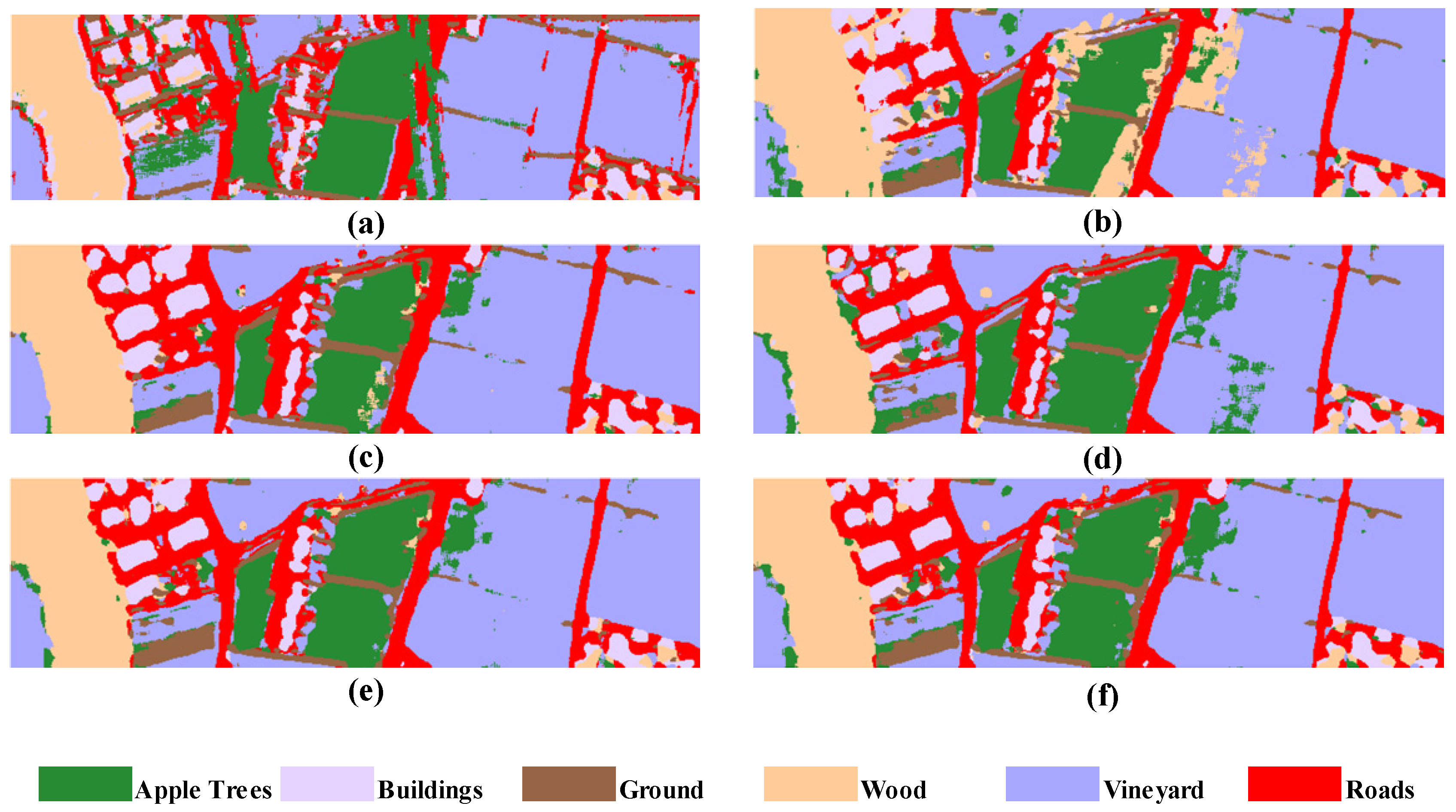
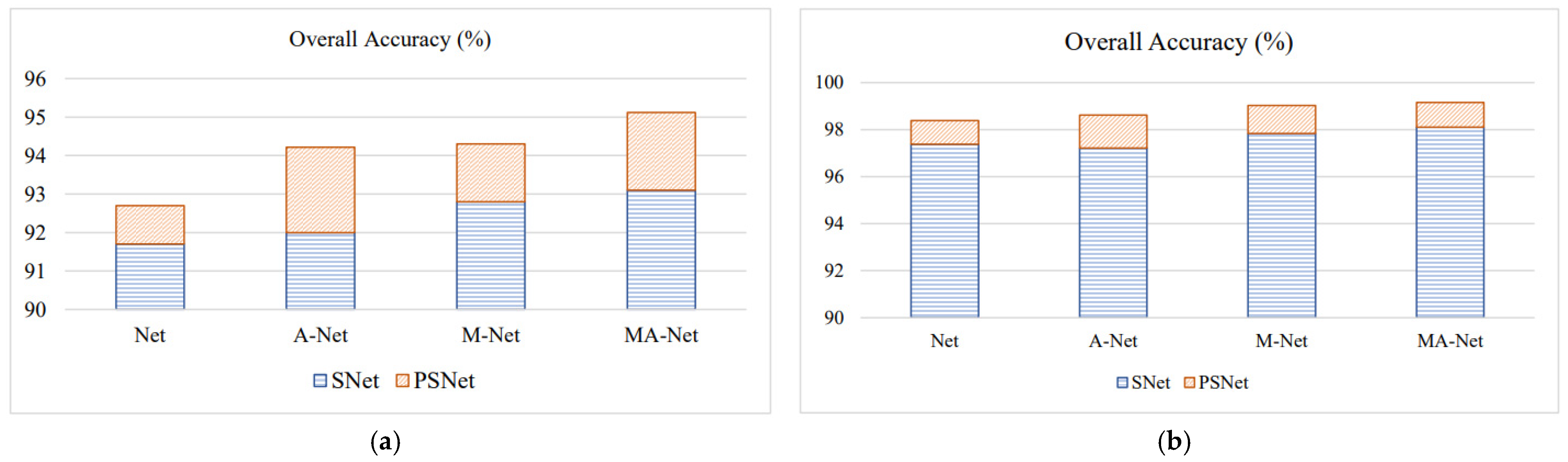
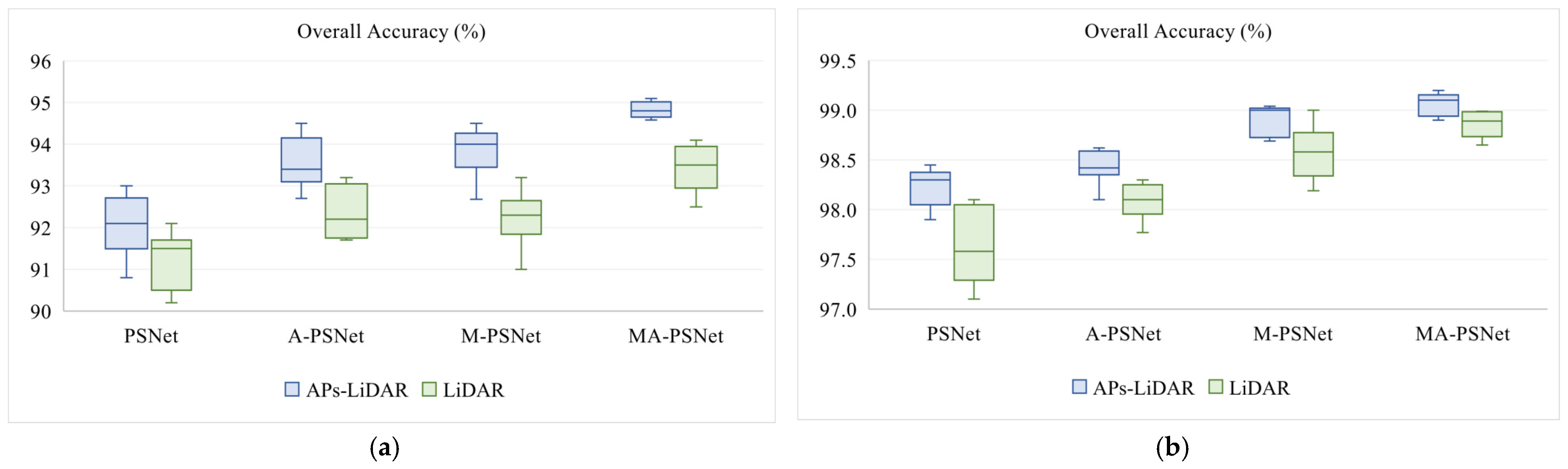
To achieve multi-source data fusion classification, a multi-scale Pseudo-Siamese Network with an attention mechanism is proposed in this paper. The network consists of two branch networks, which implement feature extraction for HSI and LiDAR, respectively, and correlate the two sub-networks by establishing a loss function characterizing the similarity of the two data features. During the feature extraction stage, the feature information at different scales is first mined by the multi-scale feature learning module, which is then concatenated with two consecutive convolutional layers so as to ensure that the network model can extract multi-level feature information of ground objects. At the same time, the channel attention module and spatial attention module are introduced in the network to achieve the adaptive setting of weights for each channel layer and different spatial regions of the feature map, respectively, highlighting the salience information of the objects to be concerned. So that the network model can carry out more purposeful learning and training, thus improving the ultimate classification performance of the network. During the feature fusion stage, a combination of feature-level fusion and decision-level fusion is adopted, which can not only compress the information but also eliminate the errors caused by a single classifier so as to realize the full fusion of multi-source data and finally improve the accuracy and reliability of land cover classification. Finally, the validity of the proposed model was assessed on two multi-source datasets (i.e., Houston 2013, Trento datasets) by using competitive classification experiments. Meanwhile, the proposed method is compared with several state-of-the-art models such as MLRsub, OTVCA, SLRCA, DeepFusion, CResNet-AUX and EndNet. The experimental results show that the proposed method can effectively fuse multi-source data for feature classification and perform the best in the accuracy indexes of , and coefficient, respectively. Considering the variability in the effects of different data fusion procedures on the classification results, it is necessary to explore a more effective multi-level data fusion model in follow-up studies.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}