


Data Preparation Impact on Semantic Segmentation of 3D Mobile LiDAR Point Clouds Using Deep Neural Networks


Abstract
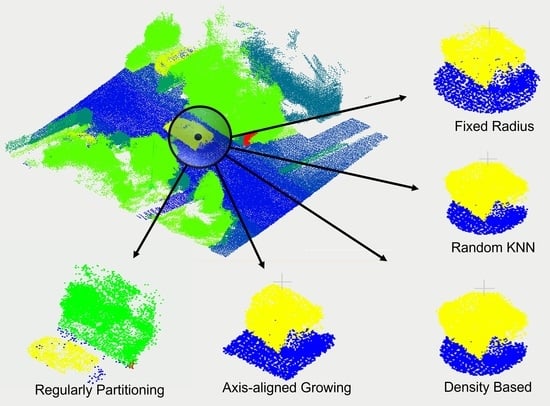
1. Introduction
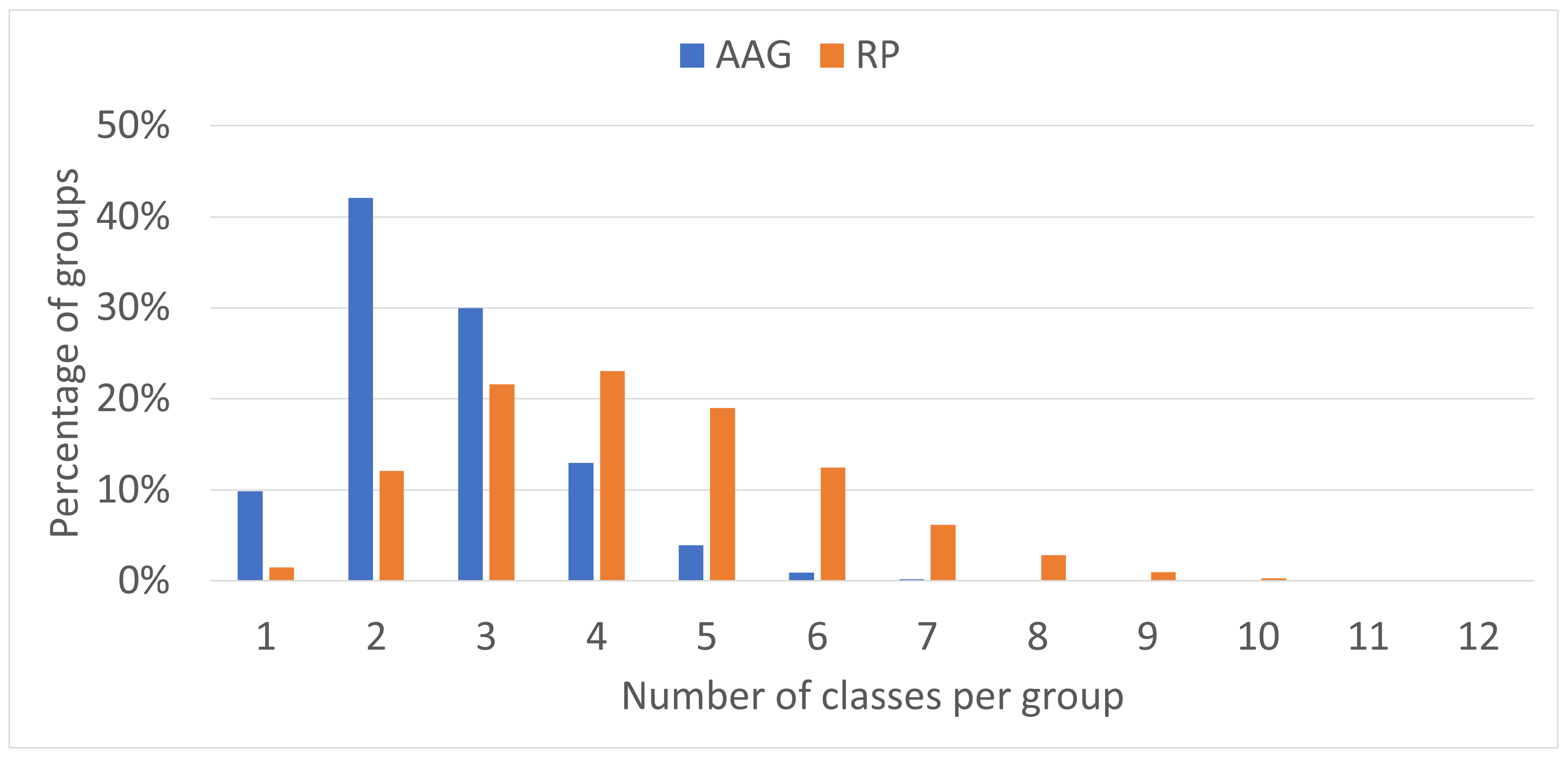
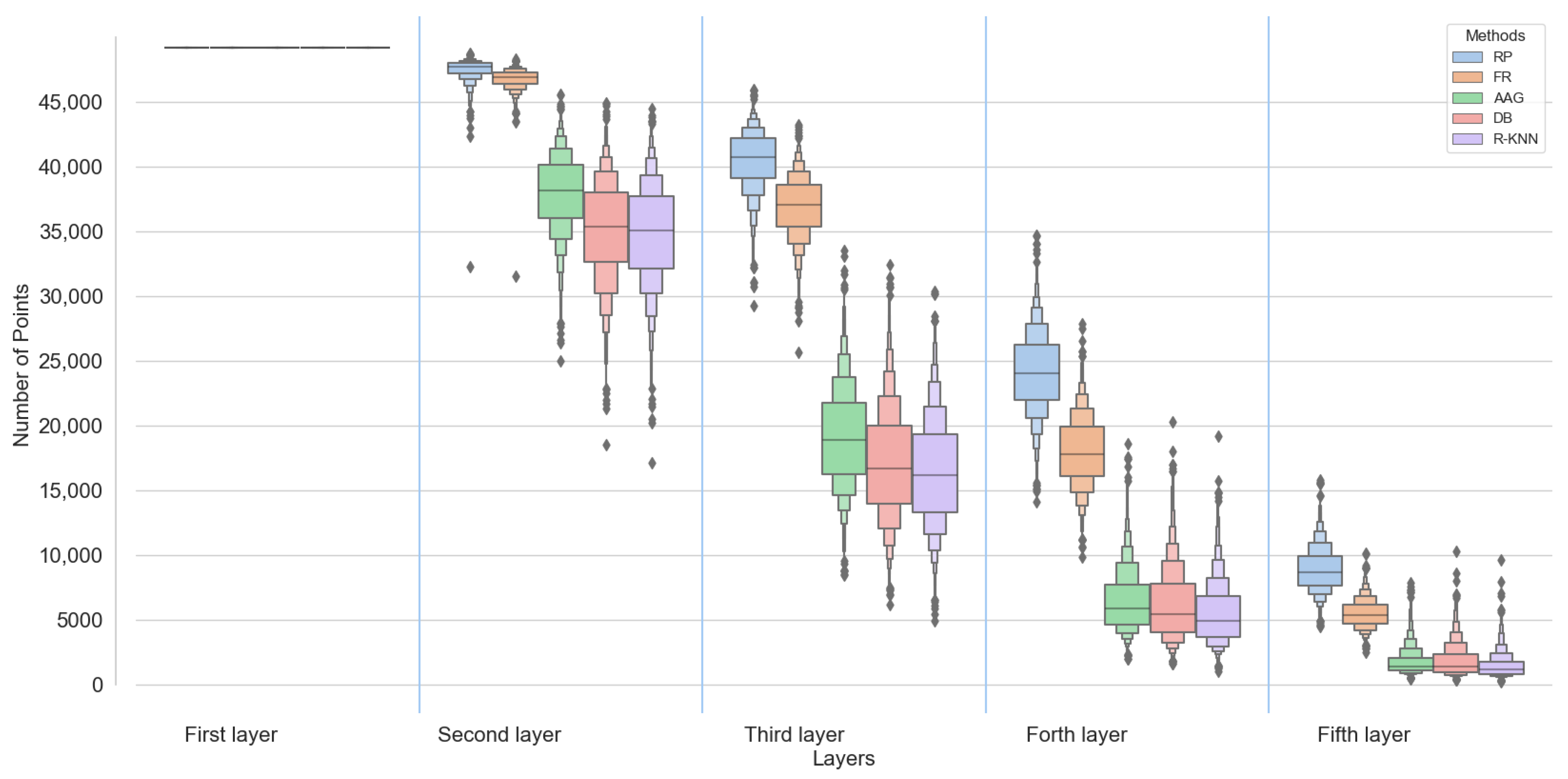
- New insights into the impacts of the data preparation choices on deep neural networks. These insights were gained by comparing different grouping methods for different sequences of the dataset, analyzing the number of points per group in different layers of KPConv, the comparison of different sampling methods, and comparing the number of classes per group in different data preparation methods.
- New general guidelines to intelligently select, that is adapted to the characteristics of the point clouds, a meaningful neighborhood and manage large-scale outdoor 3D LiDAR point clouds at the input of deep neural networks.
- Two novel data preparation methods, namely Density Based (DB) and Axis Axis-Aligned Growing (AAG), which are compatible with outdoor 3D LiDAR point clouds and achieved the best results among the investigated data preparation methods for both KPConv and PointNet++.
2. Related Works
3. Materials and Methods
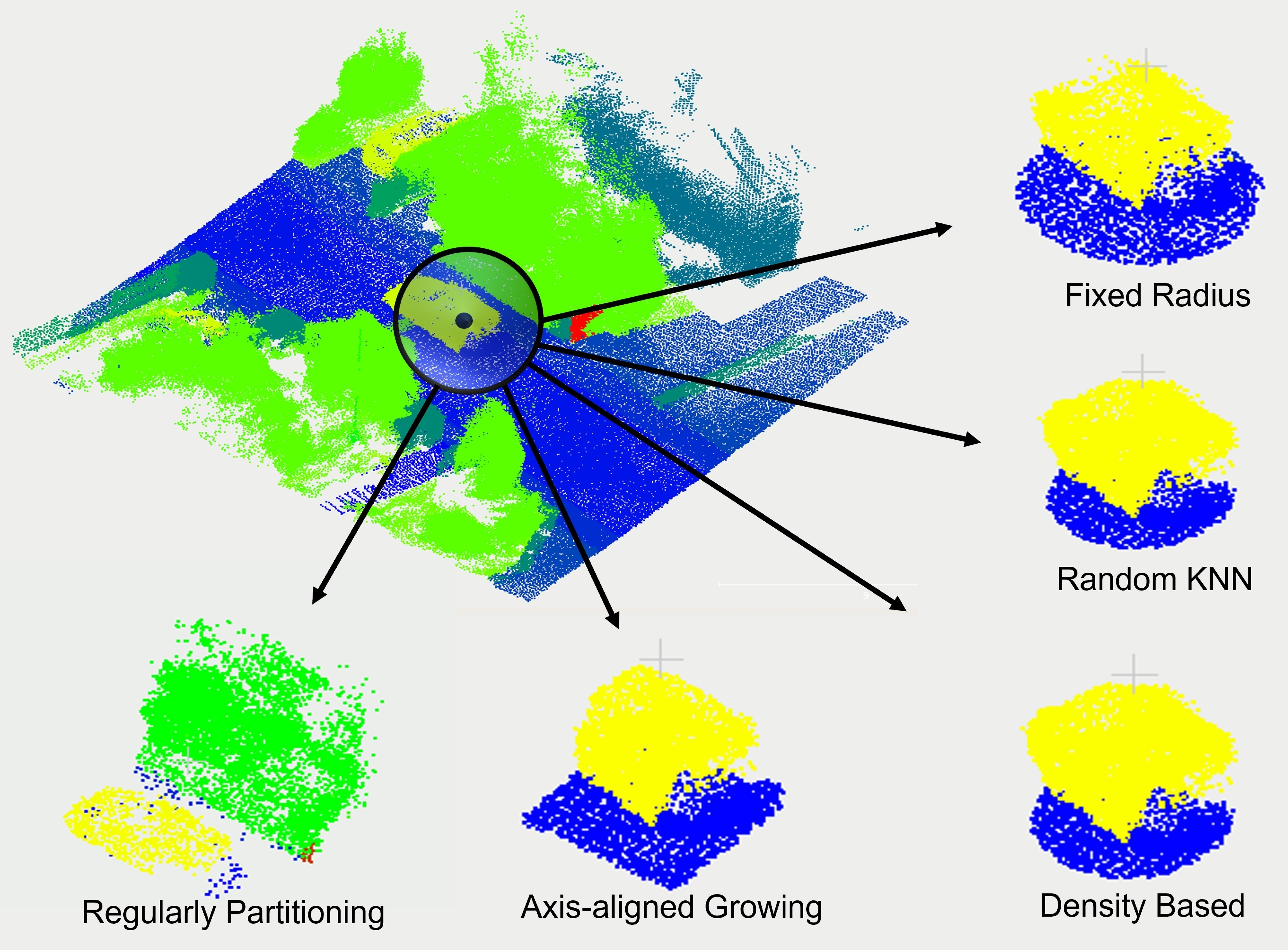
3.1. Random-KNN (R-KNN)
3.2. Fixed Radius (FR)
| Algorithm 2 FR. |
|
3.3. Axis-Aligned Growing (AAG)
3.4. Density-Based (DB)
| Algorithm 3 AAG. |
|
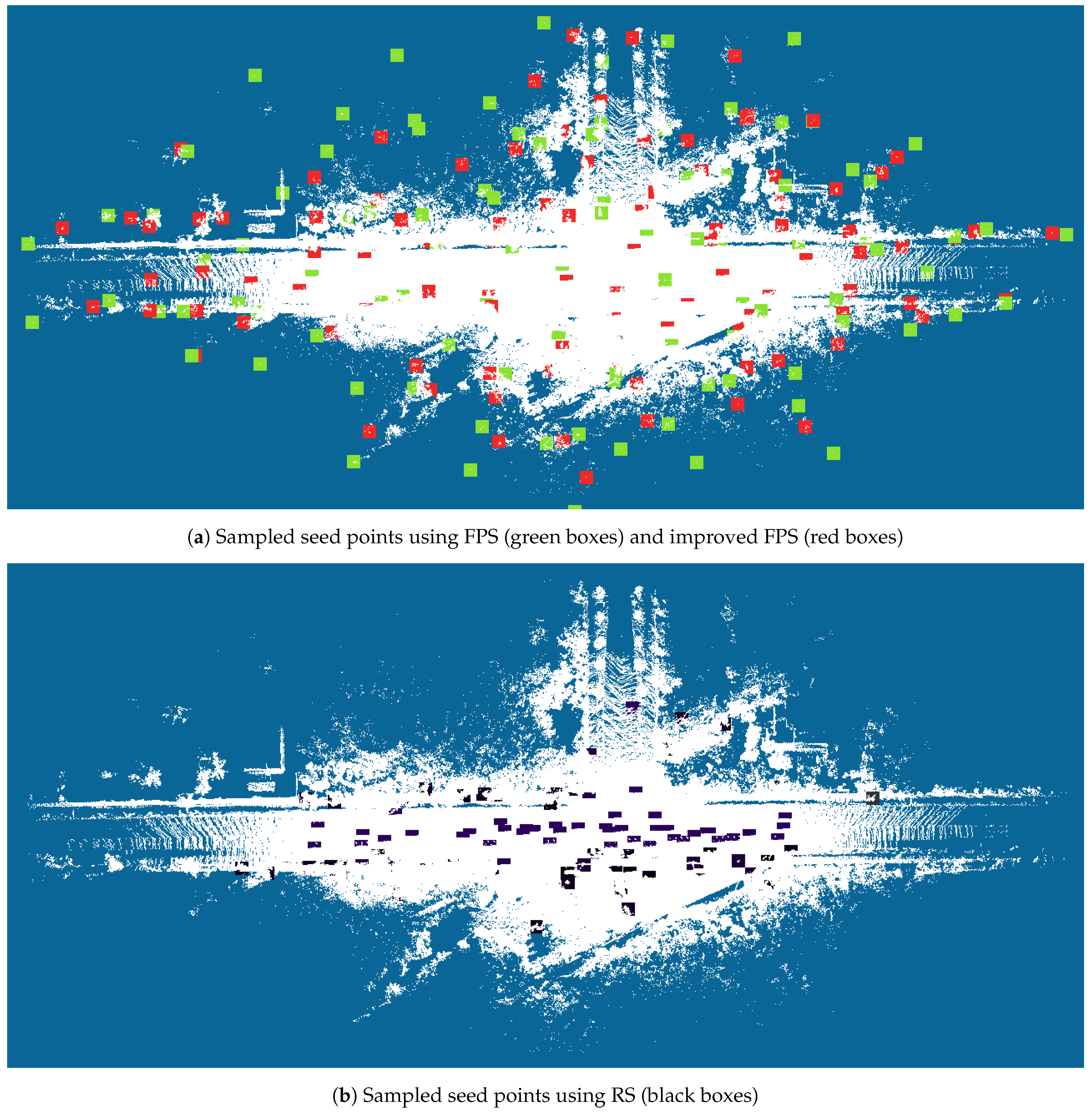
| Algorithm 4 FPS. |
|
| Algorithm 5 DB. |
|
3.5. Regularly Partitioning (RP)
4. Results
4.1. Dataset and Implementation Configuration
4.2. Semantic Segmentation Using the Data Preparation Methods
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Kernel Point Convolution (KPConv) |
| Fixed Radius (FR) |
| Random Sampling (RS) |
| K-Nearest Neighbors (KNN) |
| Density-Based (DB) |
| Axis-Aligned Growing (AAG) |
| Random-KNN (R-KNN) |
| Regularly Partitioning (RP) |
| Kernel Density Estimation (KDE) |
| Farthest Point Sampling (FPS) |
| mean Intersection over Union (mIoU) |
References
- Otepka, J.; Ghuffar, S.; Waldhauser, C.; Hochreiter, R.; Pfeifer, N. Georeferenced Point Clouds: A Survey of Features and Point Cloud Management. ISPRS Int. J. -Geo-Inf. 2013, 2, 1038–1065. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Yousefhussien, M.; Kelbe, D.J.; Ientilucci, E.J.; Salvaggio, C. A multi-scale fully convolutional network for semantic labeling of 3D point clouds. ISPRS J. Photogramm. Remote. Sens. 2018, 143, 191–204. [Google Scholar] [CrossRef]
- Yu, T.; Meng, J.; Yuan, J. Multi-view Harmonized Bilinear Network for 3D Object Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Yang, Z.; Wang, L. Learning Relationships for Multi-View 3D Object Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Boulch, A.; Guerry, J.; Le Saux, B.; Audebert, N. SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks. Comput. Graph. 2018, 71, 189–198. [Google Scholar] [CrossRef]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. SEMANTIC3D.NET: A new large-scale point cloud classification benchmark. In ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences; Copernicus GmbH: Göttingen, Germany, 2017. [Google Scholar]
- Huang, J.; You, S. Point cloud labeling using 3d convolutional neural network. In Proceedings of the IEEE International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2670–2675. [Google Scholar]
- Riegler, G.; Ulusoy, A.O.; Geiger, A. OctNet: Learning Deep 3D Representations at High Resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July–26 July 2017. [Google Scholar]
- Wang, P.S.; Liu, Y.; Guo, Y.X.; Sun, C.Y.; Tong, X. O-CNN: Octree-based Convolutional Neural Networks for 3D Shape Analysis. ACM Trans. Graph. 2017, 36, 1–11. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer VISION and Pattern recognition, Honolulu, HI, USA, 21 July–26 July 2017; pp. 652–660. [Google Scholar]
- Engelmann, F.; Kontogianni, T.; Hermans, A.; Leibe, B. Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Griffiths, D.; Boehm, J. A Review on Deep Learning Techniques for 3D Sensed Data Classification. Remote. Sens. 2019, 11, 1499. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
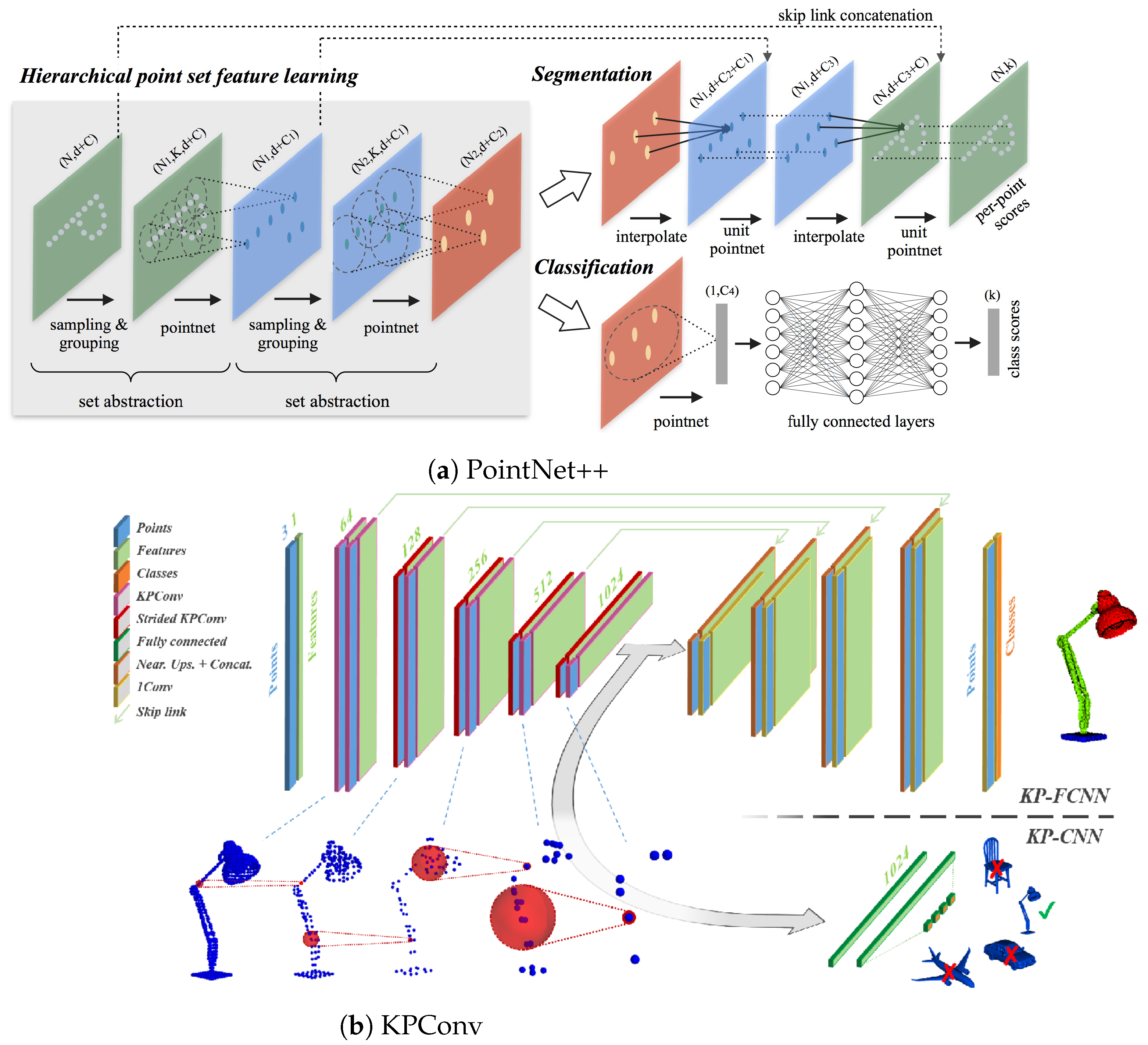
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Komarichev, A.; Zhong, Z.; Hua, J. A-CNN: Annularly Convolutional Neural Networks on Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, E.; Yang, M.H.; Kautz, J. SPLATNet: Sparse Lattice Networks for Point Cloud Processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph Attention Convolution for Point Cloud Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Engelmann, F.; Kontogianni, T.; Schult, J.; Leibe, B. Know What Your Neighbors Do: 3D Semantic Segmentation of Point Clouds. In Proceedings of the IEEE European Conference on Computer Vision—ECCV Workshops, Long Beach, CA, USA, 16–21 June 2019. [Google Scholar]
- Xu, Y.; Fan, T.; Xu, M.; Zeng, L.; Qiao, Y. SpiderCNN: Deep Learning on Point Sets with Parameterized Convolutional Filters. In Proceedings of the IEEE European Conference on Computer Vision, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. In Proceedings of the Neural Inf. Process. Syst. (NIPS). arXiv 2018, arXiv:1801.07791. [Google Scholar]
- Groh, F.; Wieschollek, P.; Lensch, H.P.A. Flex-Convolution (Million-Scale Point-Cloud Learning Beyond Grid-Worlds). In Proceedings of the IEEE Asian Conference on Computer Vision (ACCV), Perth, Australia, 2–6 December 2018. [Google Scholar]
- Wang, S.; Suo, S.; Ma, W.C.; Pokrovsky, A.; Urtasun, R. Deep Parametric Continuous Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Thomas, H.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Gall, Y.L. Semantic Classification of 3D Point Clouds with Multiscale Spherical Neighborhoods. In Proceedings of the IEEE International Conference on 3D Vision, Verona, Italy, 5–8 September 2018. [Google Scholar]
- Hermosilla, P.; Ritschel, T.; Vázquez, P.P.; Vinacua, À.; Ropinski, T. Monte Carlo convolution for learning on non-uniformly sampled point clouds. ACM Trans. Graph. 2019, 37, 1–12. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Scott, D.W. Multivariate Density Estimation: Theory, Practice, and Visualization; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Roynard, X.; Deschaud, J.E.; Goulette, F. Paris-Lille-3D: A large and high-quality ground truth urban point cloud dataset for automatic segmentation and classification. Int. J. Robot. Res. 2018, 37, 545–557. [Google Scholar] [CrossRef]
- Armeni, I.; Sener, O.; Zamir, A.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3D semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.; Schindler, K.; Pollefeys, M. SEMANTIC3D.NET: A new large-scale point cloud classification benchmark. arXiv 2017, arXiv:1704.03847. [Google Scholar] [CrossRef]
- Matrone, F.; Lingua, A.; Pierdicca, R.; Malinverni, E.S.; Paolanti, M.; Grilli, E.; Remondino, F.; Murtiyoso, A.; Landes, T. A Benchmark For Large-Scale Heritage Point Cloud Semantic Segmentation. Int. Arch.Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 1419–1426. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Boulch, A.; Puy, G.; Marlet, R. FKAConv: Feature-Kernel Alignment for Point Cloud Convolution. In Proceedings of the IEEE Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Choy, C.; JunYoung Gwak, S.S. 4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Tor, P.; Koltu, V. Point Transformer. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Seed Selection | Grouping | S.0 | S.1 | S.2 | S.3 | S.4 | S.5 | S.6 | S.7 | S.9 | S.10 | Mean | Std |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RP (baseline) | Not used | Not used | 22.1 | 23.0 | 15.1 | 24.7 | 20.8 | 23.6 | 17.6 | 23.8 | 23.6 | 22.1 | 21.6 | 3.04 |
| R-KNN | RS | KNN | 45.7 | 22.1 | 29.5 | 40.0 | 26.5 | 42.5 | 31.5 | 45.6 | 42.0 | 36.5 | 36.2 | 8.36 |
| FR | RS | Fixed radius | 45.2 | 25.7 | 26.4 | 44.9 | 30.7 | 44.6 | 31.0 | 43.6 | 42.5 | 36.0 | 37.1 | 8.02 |
| AAG (ours) | RS | Growing box | 47.7 | 25.2 | 31.7 | 42.8 | 26.4 | 48.2 | 34.0 | 45.9 | 42.4 | 39.0 | 38.3 | 8.54 |
| DB (ours) | FPS | KNN | 46.6 | 28.6 | 28.9 | 38.7 | 32.7 | 43.9 | 31.2 | 44.1 | 40.0 | 36.7 | 37.1 | 6.59 |
| Methods | Seed Selection | Grouping | S.0 | S.1 | S.2 | S.3 | S.4 | S.5 | S.6 | S.7 | S.9 | S.10 | Mean | Std |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RP (baseline) | Not used | Not used | 40.2 | 21.2 | 27.1 | 36.3 | 30.4 | 38.5 | 30.5 | 39.4 | 38.3 | 35.4 | 33.8 | 6.24 |
| R-KNN | RS | KNN | 48.0 | 29.5 | 35.0 | 43.8 | 37.1 | 44.6 | 40.8 | 47.3 | 43.2 | 42.5 | 41.2 | 5.78 |
| FR | RS | Fixed radius | 47.2 | 31.3 | 30.5 | 44.5 | 38.7 | 48.1 | 36.2 | 45.1 | 44.2 | 38.0 | 40.4 | 6.38 |
| AAG (ours) | RS | Growing box | 48.9 | 29.8 | 34.3 | 45.8 | 37.2 | 46.8 | 41.4 | 48.9 | 44.5 | 44.8 | 42.2 | 6.48 |
| DB (ours) | FPS | KNN | 50.5 | 32.0 | 36.0 | 44.2 | 38.1 | 46.8 | 42.7 | 48.3 | 45.0 | 44.7 | 42.8 | 5.77 |
| Sequences | mIoU FR PointNet++ (%) | mIoU R-KNN PointNet++ (%) | mIoU FR KPConv (%) | mIoU R-KNN KPConv (%) | Grouping Methods Providing the Best mIoU | Ratio of Low-Density Points (%) |
|---|---|---|---|---|---|---|
| S. 0 | 45.2 | 45.7 | 47.2 | 48.0 | KNN | 38 |
| S. 1 | 25.7 | 22.1 | 31.3 | 29.5 | FR | 31 |
| S. 2 | 26.4 | 29.5 | 30.5 | 35.0 | KNN | 42 |
| S. 3 | 44.9 | 40.0 | 44.5 | 43.8 | FR | 32 |
| S. 4 | 30.7 | 26.5 | 38.7 | 37.1 | FR | 33 |
| S. 5 | 44.6 | 42.5 | 48.1 | 44.6 | FR | 31 |
| S. 6 | 31.0 | 31.5 | 36.2 | 40.8 | KNN | 38 |
| S. 7 | 43.6 | 45.6 | 45.1 | 47.3 | KNN | 42 |
| S. 9 | 42.5 | 42.0 | 44.2 | 43.2 | FR | 33 |
| S. 10 | 36.0 | 36.5 | 38.0 | 42.5 | KNN | 38 |
| Classes | S.1 | S.2 | ||||
|---|---|---|---|---|---|---|
| R-KNN | FR | Original | R-KNN | FR | Original | |
| Unlabeled | 3.08 | 1.11 | 3.65 | 1.48 | 1.40 | 1.89 |
| Car | 0.00 | 0.00 | 0.74 | 2.32 | 2.08 | 2.23 |
| Bicycle | 0.00 | 0.00 | 0.00 | 0.003 | 0.002 | 0.002 |
| Motorcycle | 0.00 | 0.00 | 0.00 | 0.01 | 0.01 | 0.01 |
| Other Vehicles | 0.00 | 0.00 | 0.06 | 0.05 | 0.03 | 0.05 |
| Person | 0.00 | 0.00 | 0.00 | 0.003 | 0.004 | 0.01 |
| Road | 40.17 | 45.95 | 40.51 | 19.51 | 19.30 | 19.66 |
| Parking | 0.00 | 0.00 | 0.00 | 2.17 | 2.27 | 2.19 |
| Sidewalk | 0.0004 | 0.0005 | 0.0003 | 17.59 | 18.50 | 18.35 |
| Other Ground | 3.06 | 3.30 | 2.63 | 0.09 | 0.12 | 0.12 |
| Building | 0.22 | 0.00 | 0.20 | 5.81 | 5.62 | 5.87 |
| Fence | 15.30 | 15.64 | 14.35 | 9.08 | 9.62 | 8.58 |
| Vegetation | 23.56 | 21.12 | 23.57 | 35.28 | 34.90 | 34.38 |
| Trunk | 0.05 | 0.01 | 0.04 | 0.88 | 0.72 | 0.81 |
| Terrain | 14.18 | 12.57 | 13.83 | 5.51 | 5.21 | 5.62 |
| Pole | 0.20 | 0.19 | 0.22 | 0.18 | 0.19 | 0.20 |
| Traffic Sign | 0.19 | 0.11 | 0.20 | 0.02 | 0.01 | 0.02 |
| Sampling Methods | |||
|---|---|---|---|
| RS | 0.0016 | 0.013 | 0.24 |
| FPS | 29.85 | 298.37 | 3178.76 |
| FPS + DS (ours) | 0.97 | 9.19 | 103.47 |
| Methods | PointNet++ | KPConv | Number of Groups |
|---|---|---|---|
| RP (baseline) | 4 min | 30 min | 30,020 |
| R-KNN | 6 min | 21 min | 651,620 |
| FR | 6 min | 35 min | 582,574 |
| AAG | 6 min | 21 min | 661,342 |
| DB | 6 min | 21 min | 661,175 |
| Original Dataset | – | – | 347,568 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahmoudi Kouhi, R.; Daniel, S.; Giguère, P. Data Preparation Impact on Semantic Segmentation of 3D Mobile LiDAR Point Clouds Using Deep Neural Networks. Remote Sens. 2023, 15, 982. https://doi.org/10.3390/rs15040982
Mahmoudi Kouhi R, Daniel S, Giguère P. Data Preparation Impact on Semantic Segmentation of 3D Mobile LiDAR Point Clouds Using Deep Neural Networks. Remote Sensing. 2023; 15(4):982. https://doi.org/10.3390/rs15040982
Chicago/Turabian StyleMahmoudi Kouhi, Reza, Sylvie Daniel, and Philippe Giguère. 2023. "Data Preparation Impact on Semantic Segmentation of 3D Mobile LiDAR Point Clouds Using Deep Neural Networks" Remote Sensing 15, no. 4: 982. https://doi.org/10.3390/rs15040982
APA StyleMahmoudi Kouhi, R., Daniel, S., & Giguère, P. (2023). Data Preparation Impact on Semantic Segmentation of 3D Mobile LiDAR Point Clouds Using Deep Neural Networks. Remote Sensing, 15(4), 982. https://doi.org/10.3390/rs15040982