

A Novel Deep Learning Model for Mining Nonlinear Dynamics in Lake Surface Water Temperature Prediction



Abstract
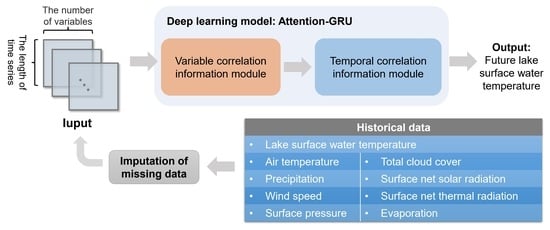
:
1. Introduction
- (1)
- A novel deep learning model (Attention-GRU) for surface water temperature prediction is established. The proposed model outperforms the Air2water model in surface water temperature prediction for Qinghai Lake and achieves the best prediction results, which indicates that the proposed model can mine the nonlinear dynamics of the research problem.
- (2)
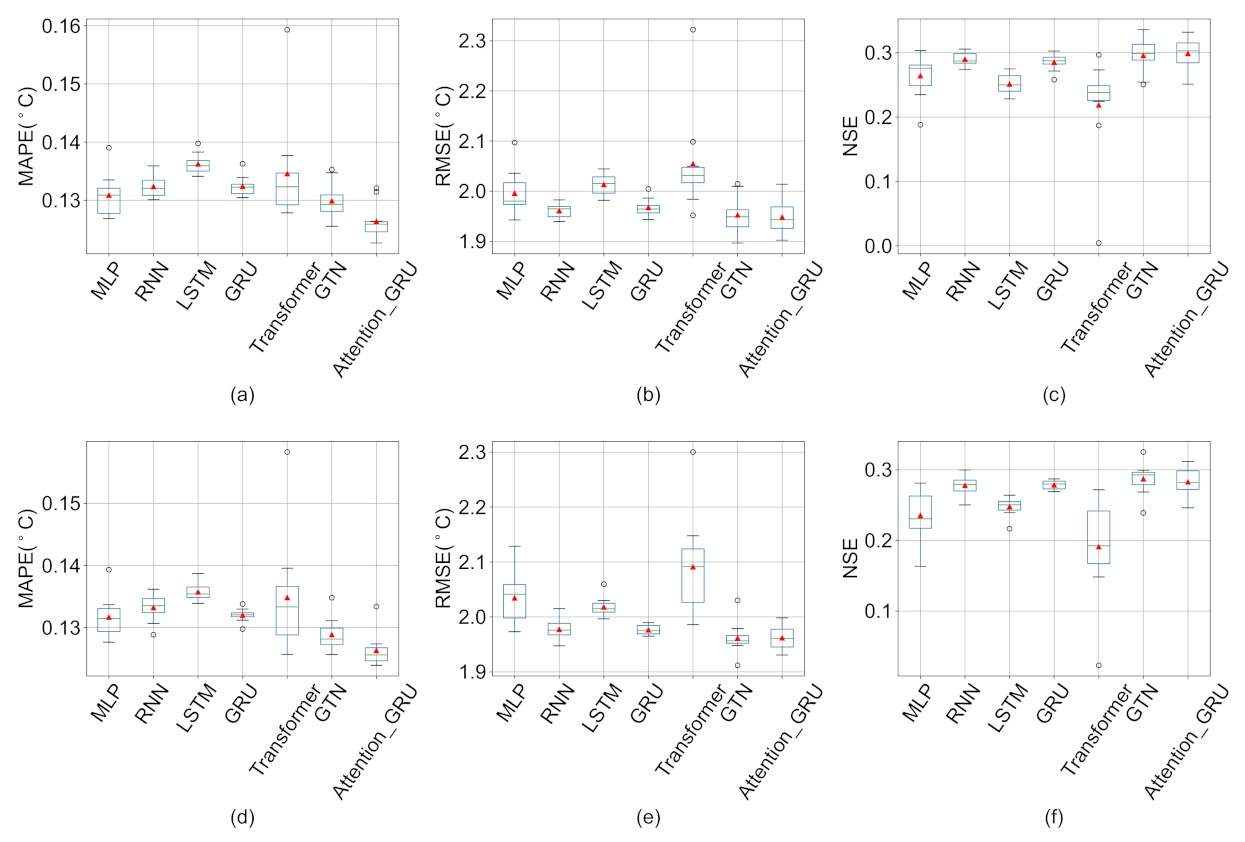
- We show the results of ten experiments with each deep learning model, indicating that the results of the proposed model are relatively stable, and through ablation experiments, we verify the effectiveness of the proposed model structure.
- (3)
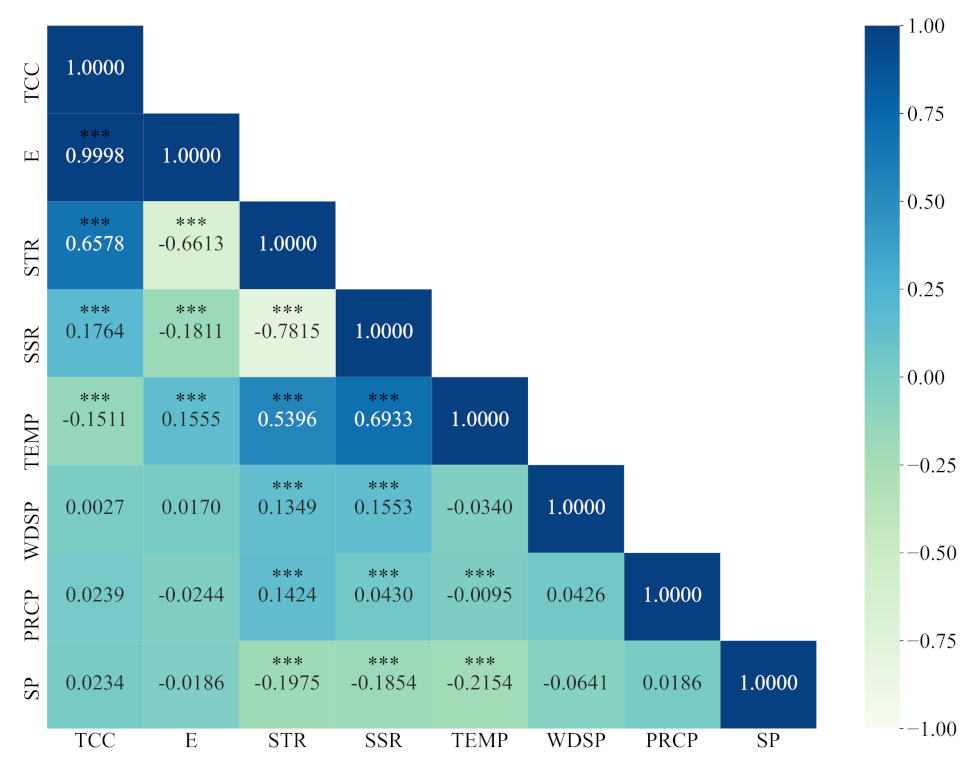
- By calculating the partial correlation coefficient, the influencing factors of surface water temperature in Qinghai Lake were analyzed. Climate variables have direct or indirect effects on the surface water temperature of Qinghai Lake in different degrees, and the dominant factor is air temperature.
- (4)
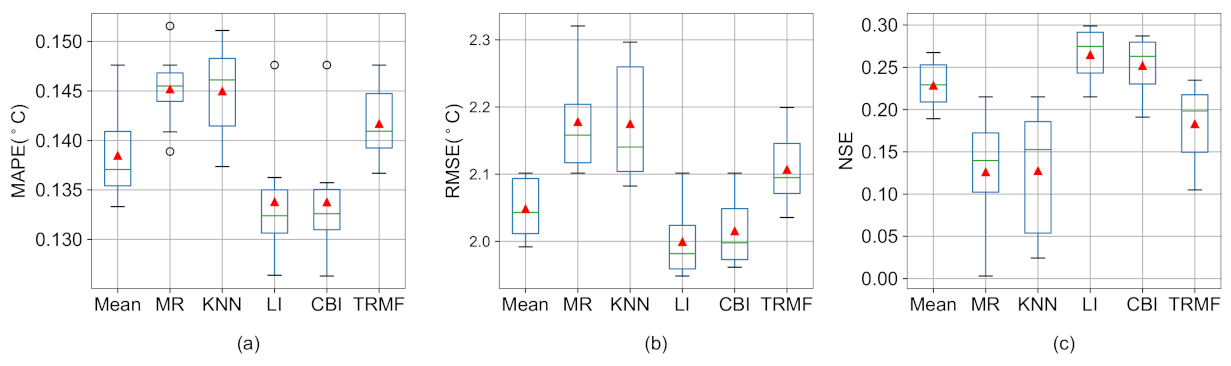
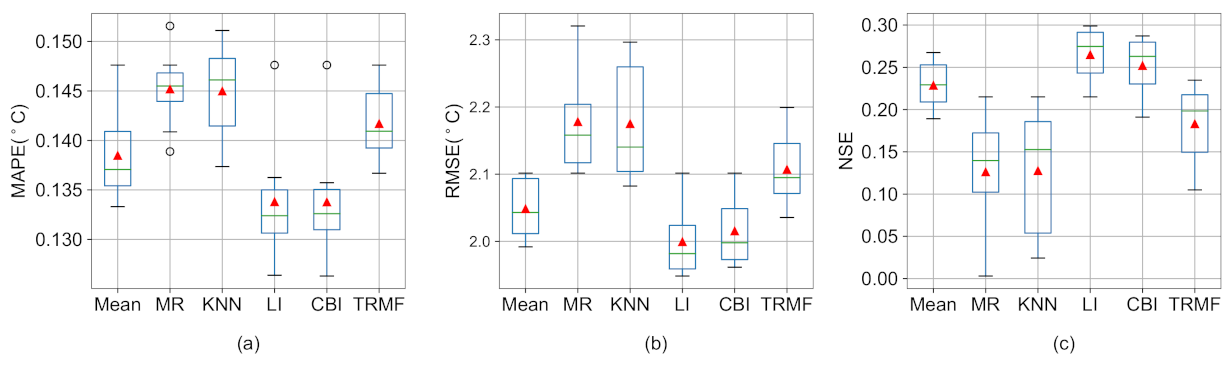
- There are a lot of missing values in the LSWT data of Qinghai Lake, and we used six common missing value imputation methods to fill in the missing data. By comparing the filling effects of different missing value imputation methods, the validity of the proposed model on multiple data sets is verified, and the dependence of deep learning models on data quality is shown.
2. A Novel Deep Learning Model: Attention-GRU
2.1. The Preliminaries
2.1.1. The Self-Attention
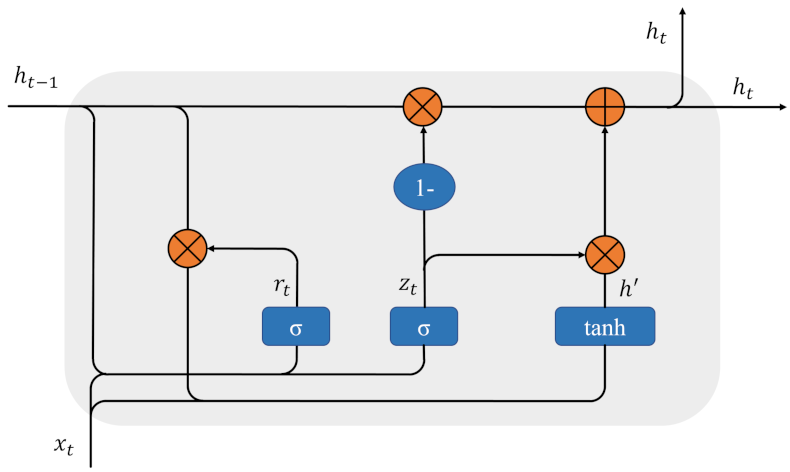
2.1.2. The GRU
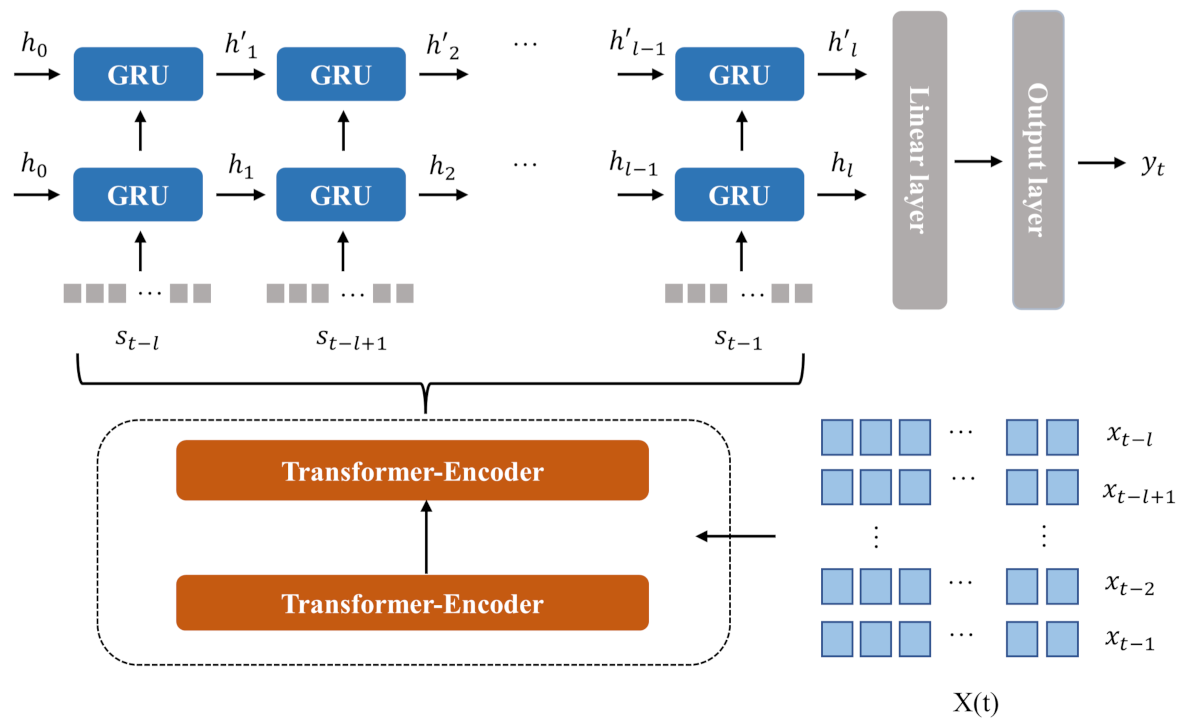
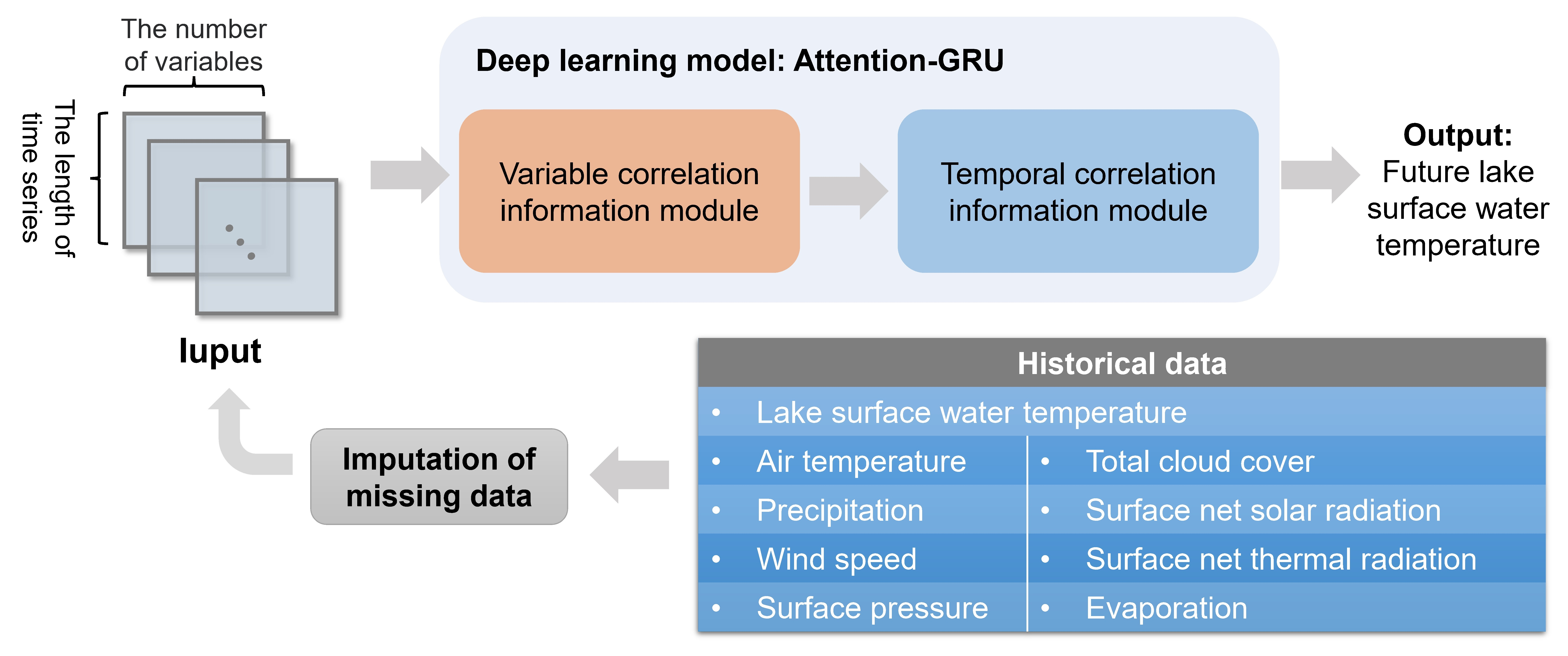
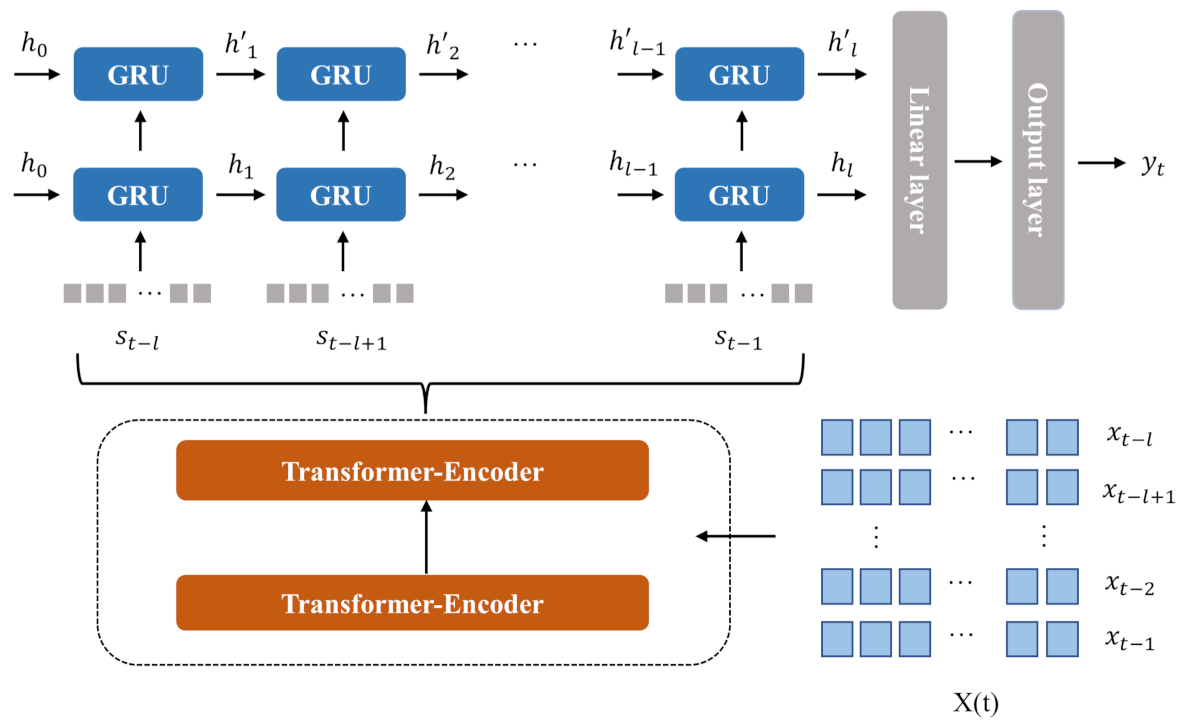
2.2. The Proposed Model: Attention-GRU
| Algorithm 1: Attention-GRU |
 |
3. Experiments
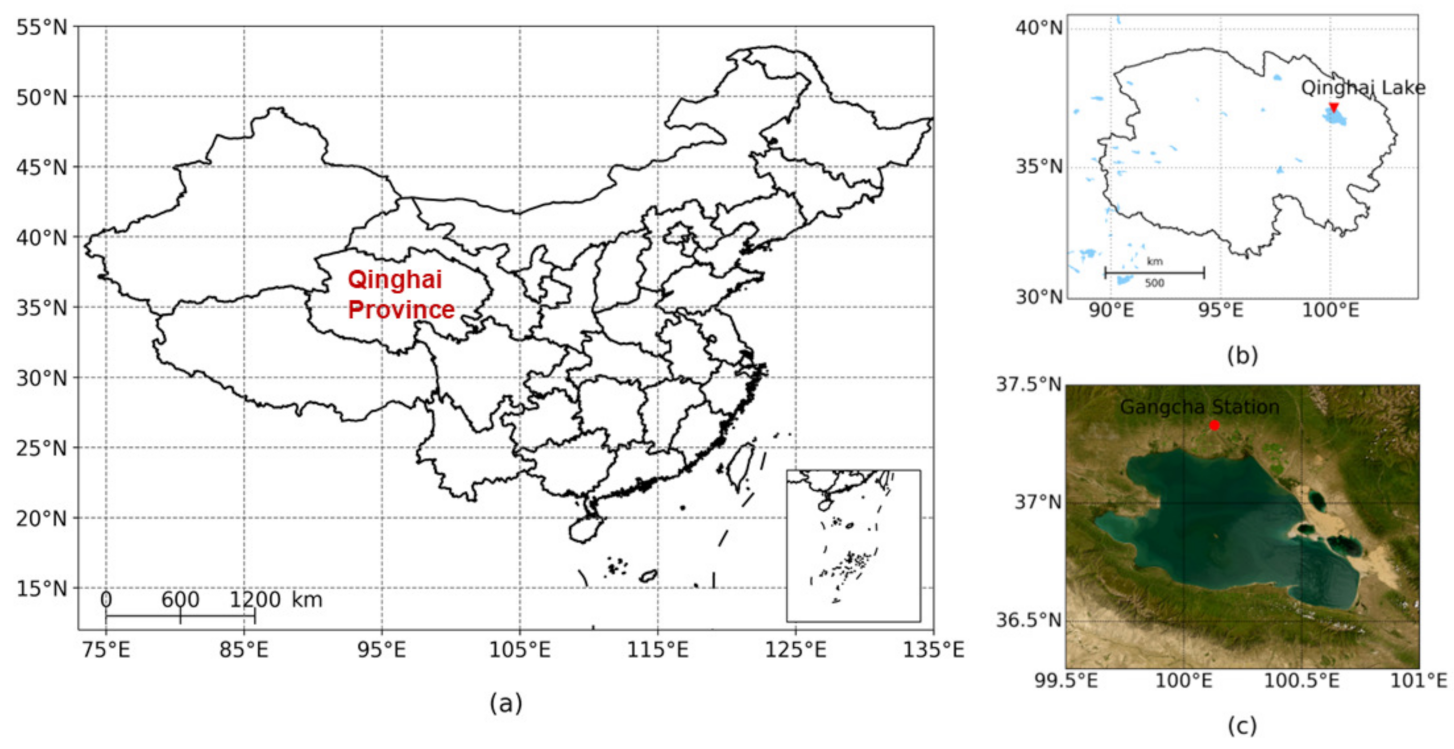
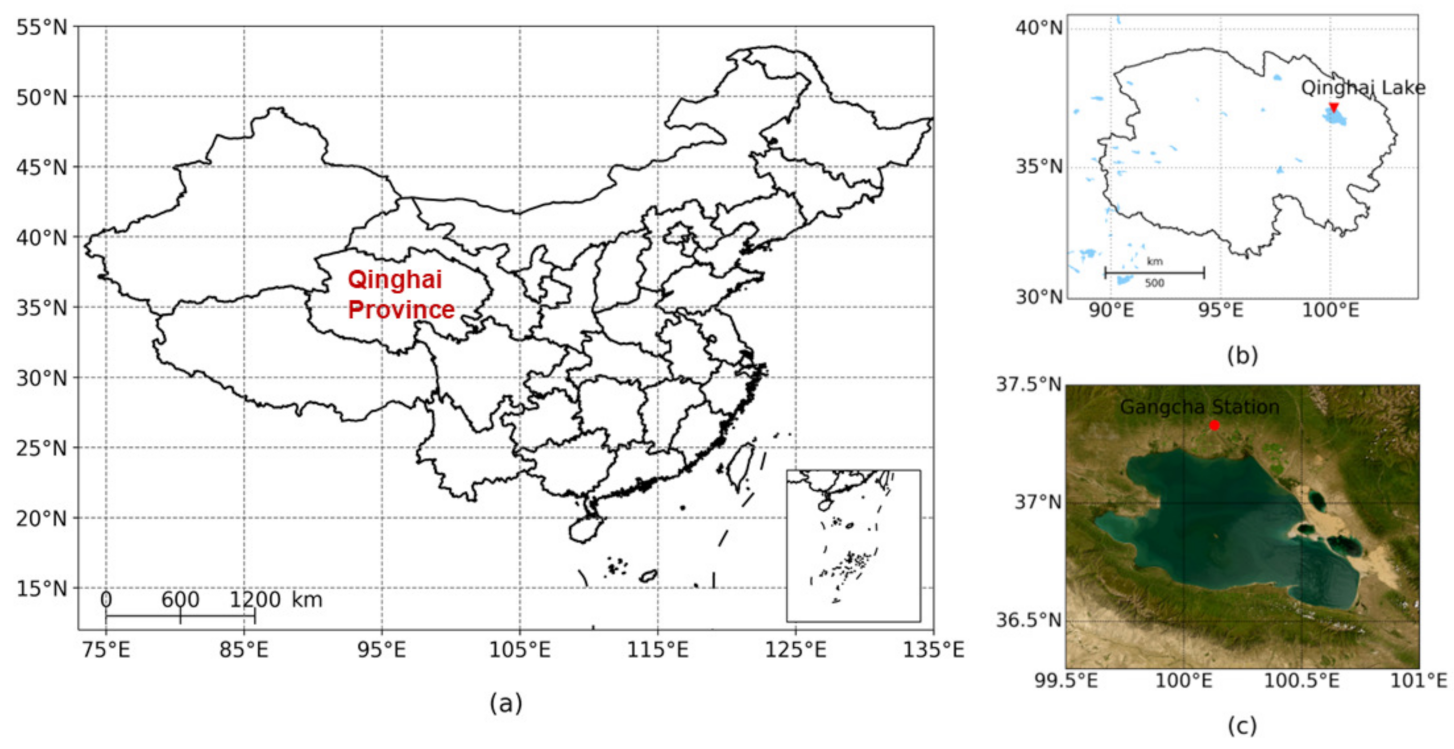
3.1. Data Sources
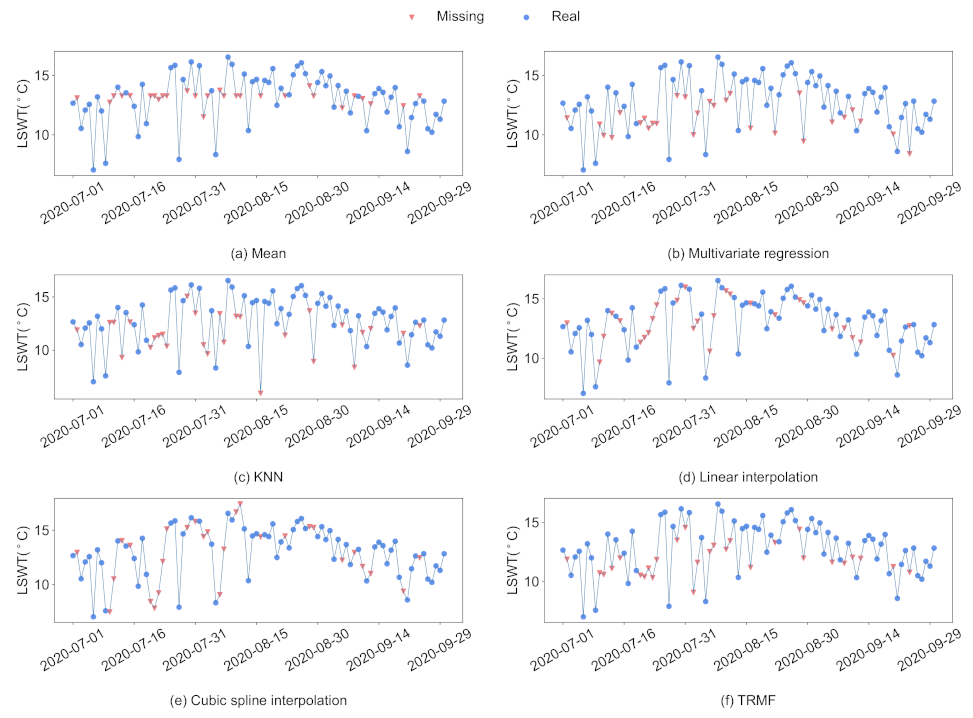
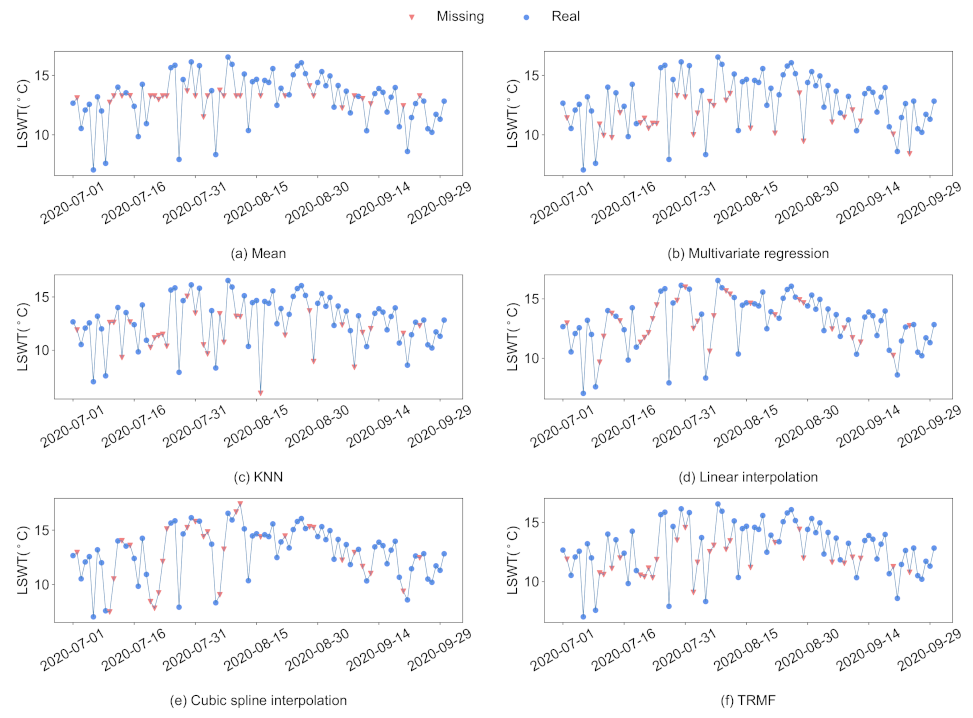
3.2. Imputation of Missing Data
3.3. Experiments Settings
3.4. Evaluation Metric
4. Results
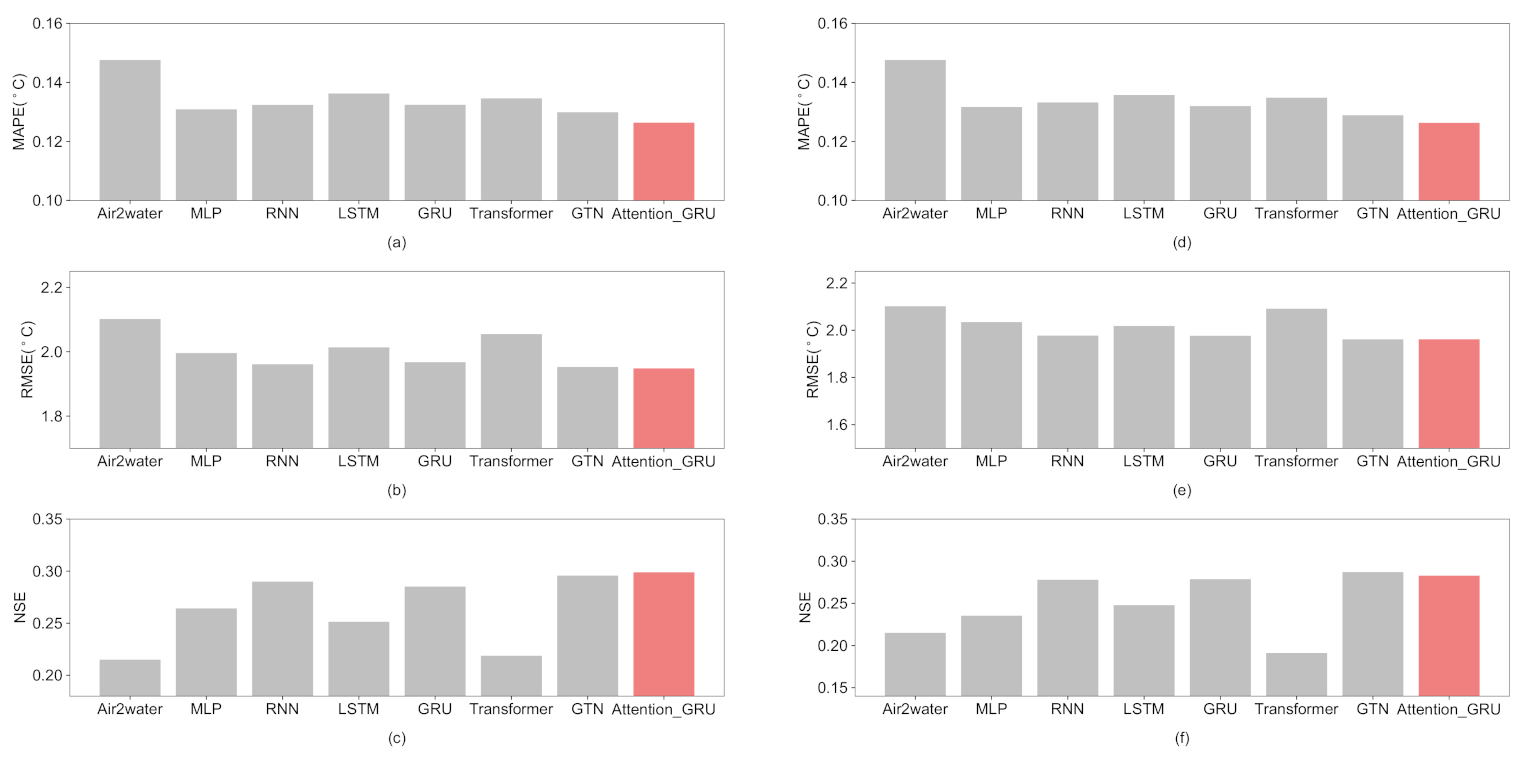
4.1. Comparison with Air2water
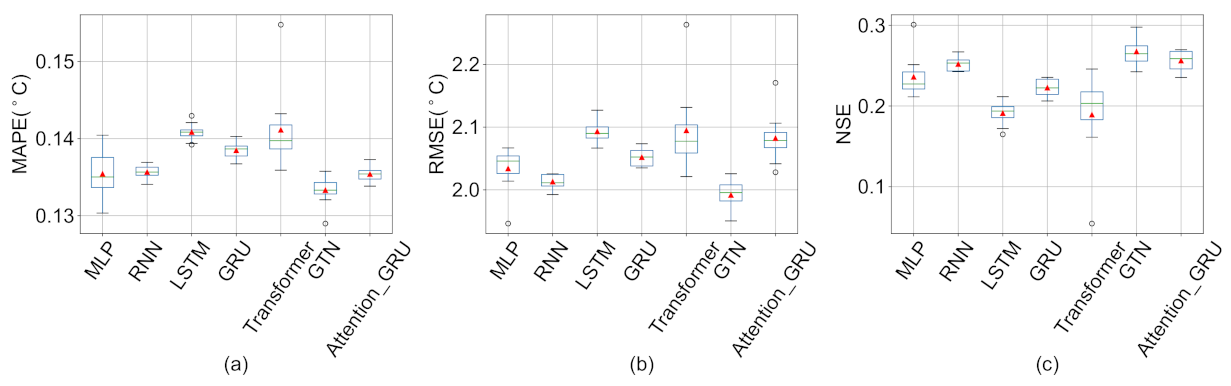
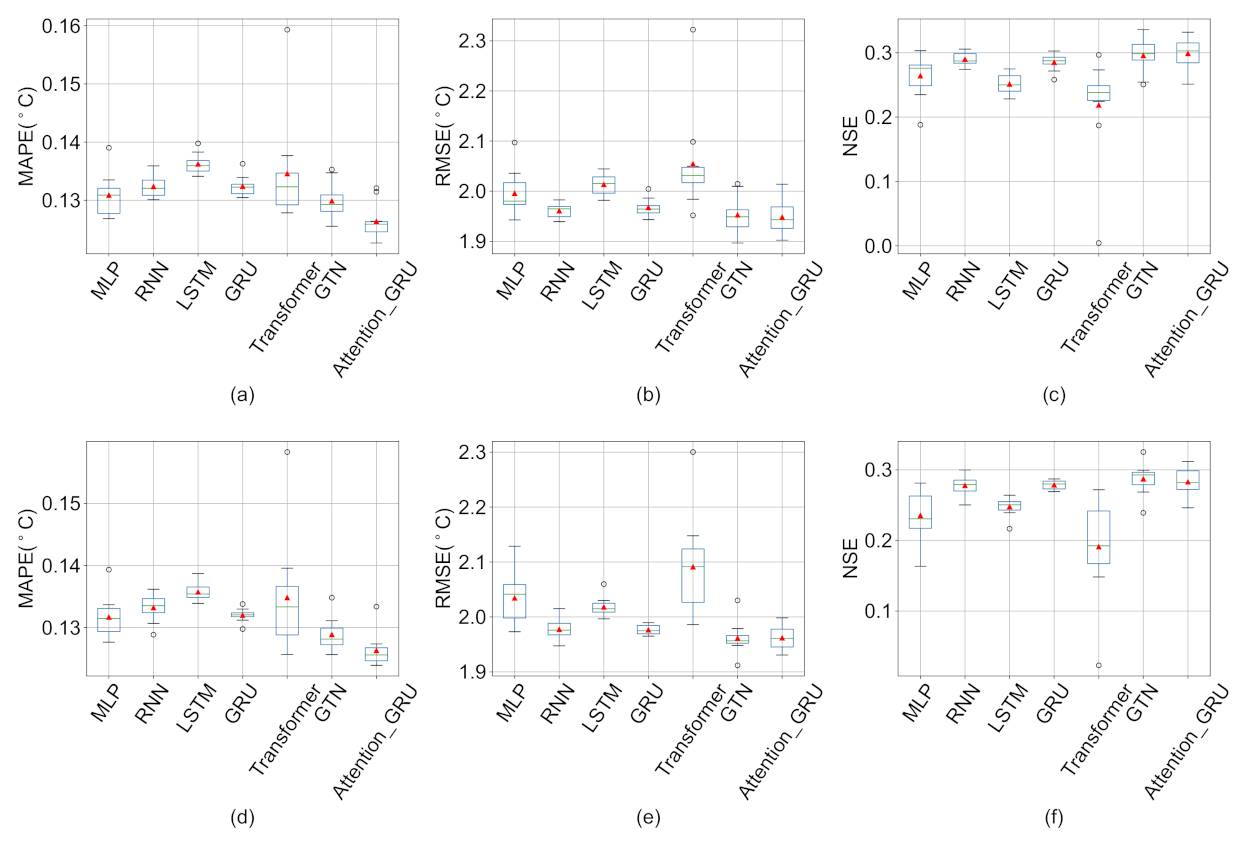
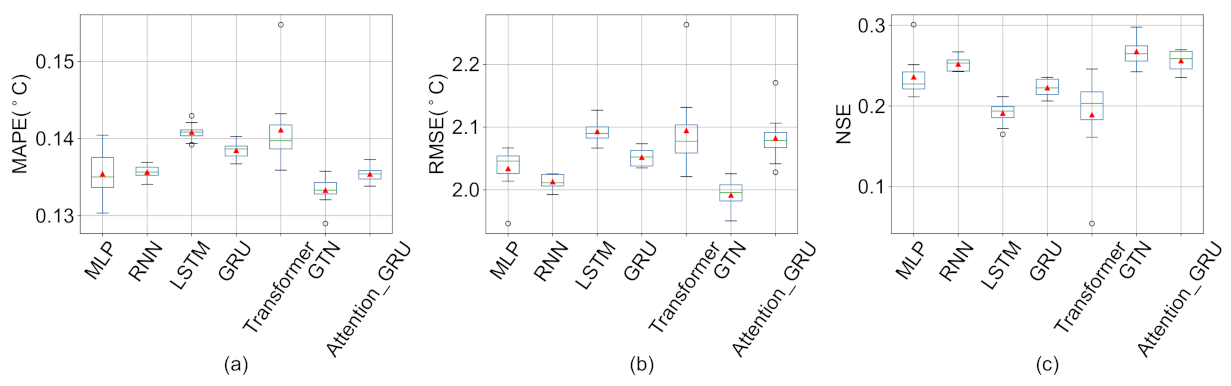
4.2. Comparison with Other Deep Learning Methods
5. Discussion
5.1. Analysis of Influencing Factors of Lake Surface Water Temperature
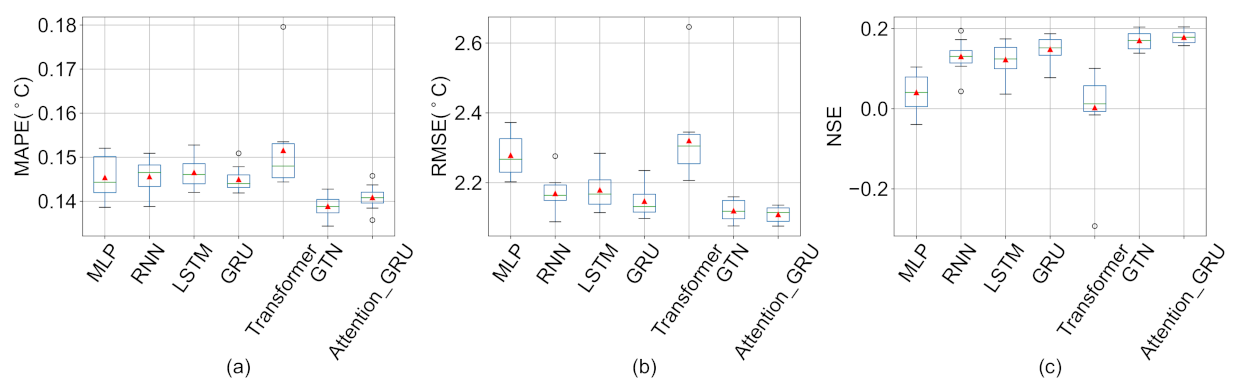
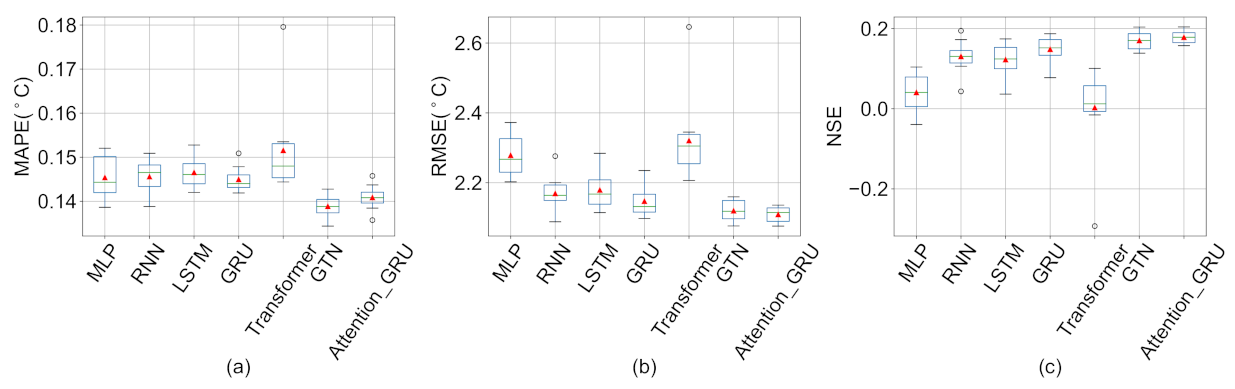
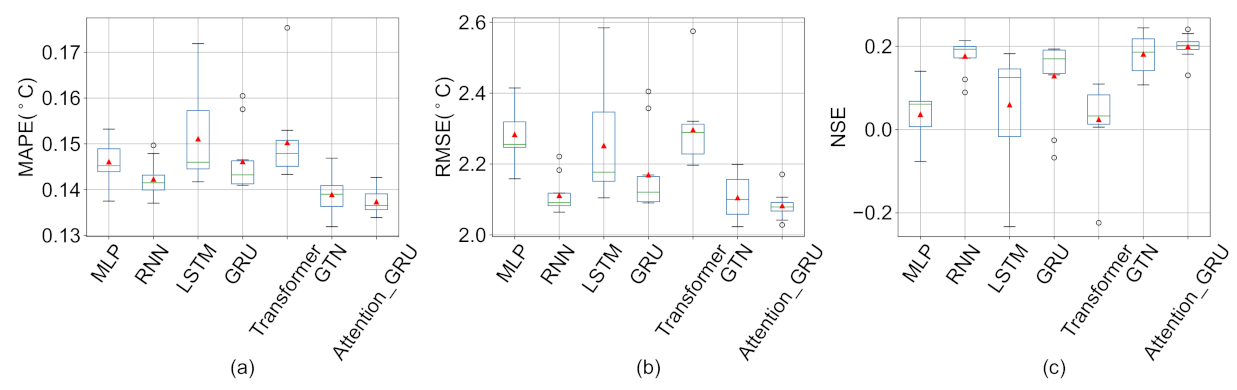
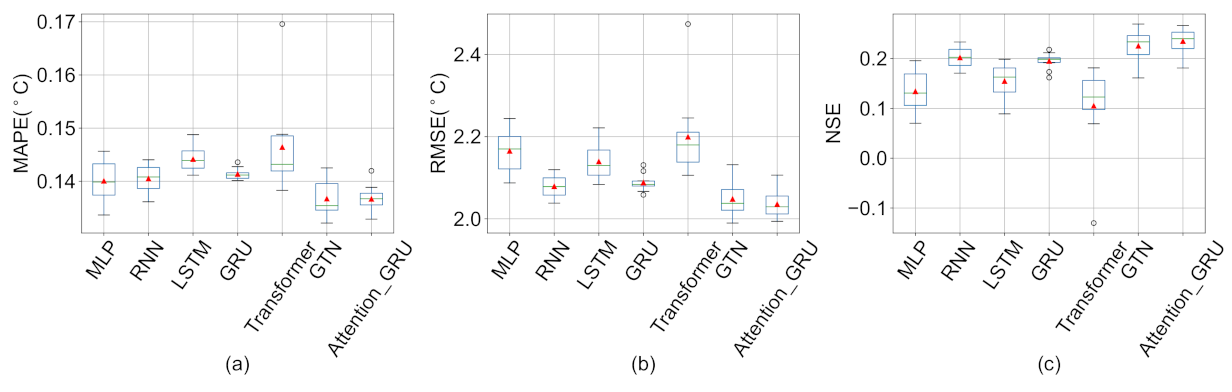
5.2. Influence of Imputation Methods on Prediction Results
5.3. Limitations and Future Works
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Experimental Configuration
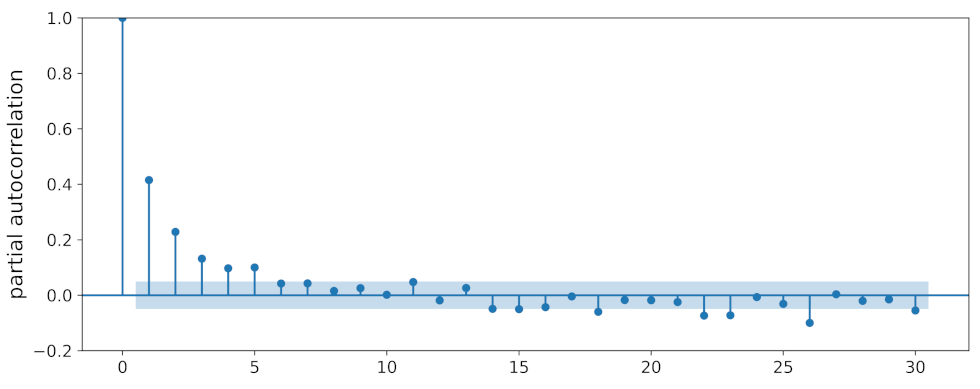
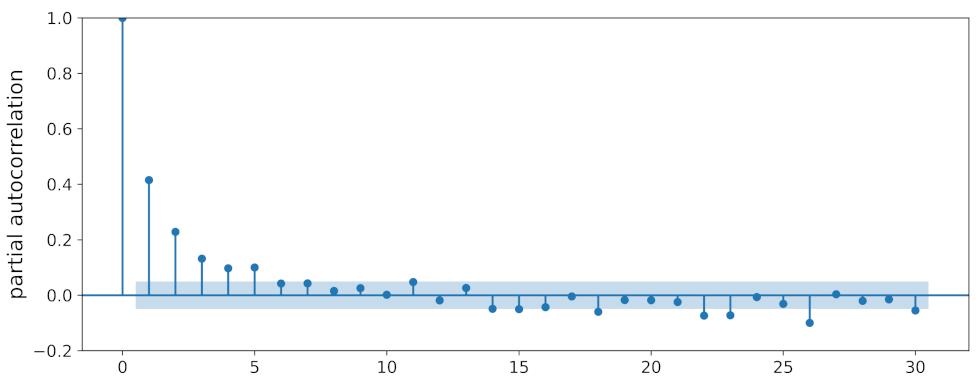
Appendix B. Partial Autocorrelation of Qinghai Lake Lswt
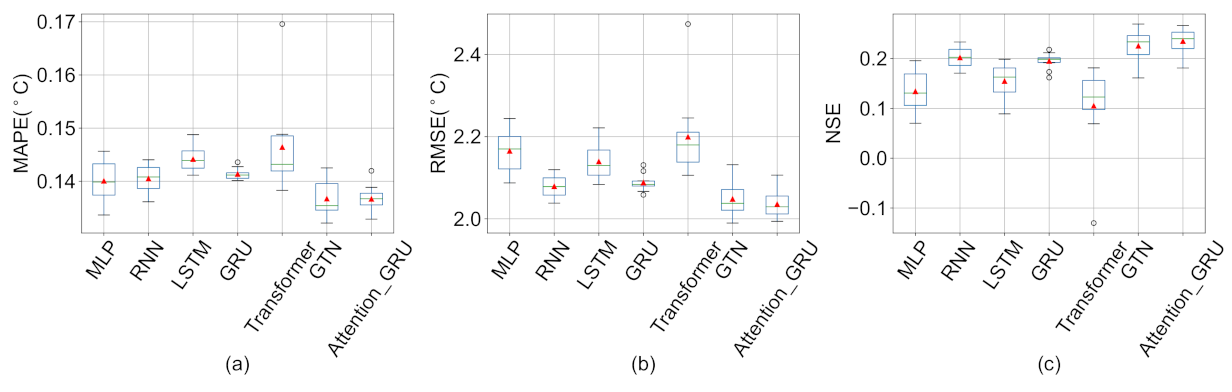
Appendix C. Box Plots of Deep Learning with Other Missing Value Imputation Methods

References
- O’Reilly, C.M.; Sharma, S.; Gray, D.K.; Hampton, S.E.; Read, J.S.; Rowley, R.J.; Schneider, P.; Lenters, J.D.; McIntyre, P.B.; Kraemer, B.M.; et al. Rapid and highly variable warming of lake surface waters around the globe. Geophys. Res. Lett. 2015, 42, 10–773. [Google Scholar] [CrossRef]
- Piccolroaz, S.; Woolway, R.I.; Merchant, C.J. Global reconstruction of twentieth century lake surface water temperature reveals different warming trends depending on the climatic zone. Clim. Chang. 2020, 160, 427–442. [Google Scholar] [CrossRef]
- Wang, S.; He, Y.; Hu, S.; Ji, F.; Wang, B.; Guan, X.; Piccolroaz, S. Enhanced Warming in Global Dryland Lakes and Its Drivers. Remote Sens. 2021, 14, 86. [Google Scholar] [CrossRef]
- Woolway, R.I.; Merchant, C.J. Worldwide alteration of lake mixing regimes in response to climate change. Nat. Geosci. 2019, 12, 271–276. [Google Scholar] [CrossRef]
- Yang, K.; Yu, Z.; Luo, Y.; Yang, Y.; Zhao, L.; Zhou, X. Spatial and temporal variations in the relationship between lake water surface temperatures and water quality-A case study of Dianchi Lake. Sci. Total Environ. 2018, 624, 859–871. [Google Scholar] [CrossRef]
- Woolway, R.I.; Kraemer, B.M.; Lenters, J.D.; Merchant, C.J.; O’Reilly, C.M.; Sharma, S. Global lake responses to climate change. Nat. Rev. Earth Environ. 2020, 1, 388–403. [Google Scholar] [CrossRef]
- Toffolon, M.; Piccolroaz, S.; Majone, B.; Soja, A.M.; Peeters, F.; Schmid, M.; Wüest, A. Prediction of surface temperature in lakes with different morphology using air temperature. Limnol. Oceanogr. 2014, 59, 2185–2202. [Google Scholar] [CrossRef]
- Piccolroaz, S.; Toffolon, M.; Majone, B. The role of stratification on lakes’ thermal response: The case of Lake Superior. Water Resour. Res. 2015, 51, 7878–7894. [Google Scholar] [CrossRef]
- Javaheri, A.; Babbar-Sebens, M.; Miller, R.N. From skin to bulk: An adjustment technique for assimilation of satellite-derived temperature observations in numerical models of small inland water bodies. Adv. Water Resour. 2016, 92, 284–298. [Google Scholar] [CrossRef]
- Piccolroaz, S. Prediction of lake surface temperature using the air2water model: Guidelines, challenges, and future perspectives. Adv. Oceanogr. Limnol. 2016, 7, 36–50. [Google Scholar] [CrossRef]
- Piccolroaz, S.; Healey, N.; Lenters, J.; Schladow, S.; Hook, S.; Sahoo, G.; Toffolon, M. On the predictability of lake surface temperature using air temperature in a changing climate: A case study for Lake Tahoe (USA). Limnol. Oceanogr. 2018, 63, 243–261. [Google Scholar] [CrossRef]
- Heddam, S.; Ptak, M.; Zhu, S. Modelling of daily lake surface water temperature from air temperature: Extremely randomized trees (ERT) versus Air2Water, MARS, M5Tree, RF and MLPNN. J. Hydrol. 2020, 588, 125130. [Google Scholar] [CrossRef]
- Zhu, S.; Ptak, M.; Yaseen, Z.M.; Dai, J.; Sivakumar, B. Forecasting surface water temperature in lakes: A comparison of approaches. J. Hydrol. 2020, 585, 124809. [Google Scholar] [CrossRef]
- Piccolroaz, S.; Toffolon, M.; Majone, B. A simple lumped model to convert air temperature into surface water temperature in lakes. Hydrol. Earth Syst. Sci. 2013, 17, 3323–3338. [Google Scholar] [CrossRef]
- Sharma, S.; Walker, S.C.; Jackson, D.A. Empirical modelling of lake water-temperature relationships: A comparison of approaches. Freshw. Biol. 2008, 53, 897–911. [Google Scholar] [CrossRef]
- Zhu, S.; Nyarko, E.K.; Hadzima-Nyarko, M. Modelling daily water temperature from air temperature for the Missouri River. PeerJ 2018, 6, e4894. [Google Scholar] [CrossRef]
- Piotrowski, A.P.; Napiorkowski, J.J. Simple modifications of the nonlinear regression stream temperature model for daily data. J. Hydrol. 2019, 572, 308–328. [Google Scholar] [CrossRef]
- Zhu, S.; Piotrowski, A.P. River/stream water temperature forecasting using artificial intelligence models: A systematic review. Acta Geophys. 2020, 68, 1433–1442. [Google Scholar] [CrossRef]
- Piotrowski, A.P.; Napiorkowski, M.J.; Napiorkowski, J.J.; Osuch, M. Comparing various artificial neural network types for water temperature prediction in rivers. J. Hydrol. 2015, 529, 302–315. [Google Scholar] [CrossRef]
- Piotrowski, A.P.; Napiorkowski, J.J.; Piotrowska, A.E. Impact of deep learning-based dropout on shallow neural networks applied to stream temperature modelling. Earth-Sci. Rev. 2020, 201, 103076. [Google Scholar] [CrossRef]
- Yang, K.; Yu, Z.; Luo, Y. Analysis on driving factors of lake surface water temperature for major lakes in Yunnan-Guizhou Plateau. Water Res. 2020, 184, 116018. [Google Scholar] [CrossRef] [PubMed]
- Seo, Y.; Kim, S.; Kisi, O.; Singh, V.P. Daily water level forecasting using wavelet decomposition and artificial intelligence techniques. J. Hydrol. 2015, 520, 224–243. [Google Scholar] [CrossRef]
- Graf, R.; Zhu, S.; Sivakumar, B. Forecasting river water temperature time series using a wavelet–neural network hybrid modelling approach. J. Hydrol. 2019, 578, 124115. [Google Scholar] [CrossRef]
- Sang, Y.F. A review on the applications of wavelet transform in hydrology time series analysis. Atmos. Res. 2013, 122, 8–15. [Google Scholar] [CrossRef]
- Mironov, D.V. Parameterization of Lakes in Numerical Weather Prediction. Part 1: Description of a Lake Model; German Weather Service: Offenbach am Main, Germany, 2005. [Google Scholar]
- Mironov, D.; Heise, E.; Kourzeneva, E.; Ritter, B.; Schneider, N.; Terzhevik, A. Implementation of the lake parameterisation scheme FLake into the numerical weather prediction model COSMO. Boreal Environ. Res. 2010, 15, 218–230. [Google Scholar]
- Huang, L.; Wang, X.; Sang, Y.; Tang, S.; Jin, L.; Yang, H.; Ottlé, C.; Bernus, A.; Wang, S.; Wang, C.; et al. Optimizing lake surface water temperature simulations over large lakes in China with FLake model. Earth Space Sci. 2021, 8, e2021EA001737. [Google Scholar] [CrossRef]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Gao, W.; Gao, J.; Yang, L.; Wang, M.; Yao, W. A novel modeling strategy of weighted mean temperature in China using RNN and LSTM. Remote Sens. 2021, 13, 3004. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Xie, J.; Zhang, J.; Yu, J.; Xu, L. An adaptive scale sea surface temperature predicting method based on deep learning with attention mechanism. IEEE Geosci. Remote Sens. Lett. 2019, 17, 740–744. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Liu, M.; Ren, S.; Ma, S.; Jiao, J.; Chen, Y.; Wang, Z.; Song, W. Gated transformer networks for multivariate time series classification. arXiv 2021, arXiv:2103.14438. [Google Scholar]
- Adrian, R.; O’Reilly, C.M.; Zagarese, H.; Baines, S.B.; Hessen, D.O.; Keller, W.; Livingstone, D.M.; Sommaruga, R.; Straile, D.; Van Donk, E.; et al. Lakes as sentinels of climate change. Limnol. Oceanogr. 2009, 54, 2283–2297. [Google Scholar] [CrossRef] [PubMed]
- You, Q.; Min, J.; Kang, S. Rapid warming in the Tibetan Plateau from observations and CMIP5 models in recent decades. Int. J. Climatol. 2016, 36, 2660–2670. [Google Scholar] [CrossRef]
- Zhang, G.; Yao, T.; Xie, H.; Yang, K.; Zhu, L.; Shum, C.; Bolch, T.; Yi, S.; Allen, S.; Jiang, L.; et al. Response of Tibetan Plateau lakes to climate change: Trends, patterns, and mechanisms. Earth-Sci. Rev. 2020, 208, 103269. [Google Scholar] [CrossRef]
- Tang, L.; Duan, X.; Kong, F.; Zhang, F.; Zheng, Y.; Li, Z.; Mei, Y.; Zhao, Y.; Hu, S. Influences of climate change on area variation of Qinghai Lake on Qinghai-Tibetan Plateau since 1980s. Sci. Rep. 2018, 8, 7331. [Google Scholar] [CrossRef]
- Wan, Z. MOD11A1 MODIS/Terra Land Surface Temperature/Emissivity Daily L3 Global 1 km SIN Grid V006. NASA EOSDIS Land Processes DAAC. 2015. Available online: https://lpdaac.usgs.gov/products/mod11a1v006/ (accessed on 28 November 2022). [CrossRef]
- Yu, H.F.; Rao, N.; Dhillon, I.S. Temporal regularized matrix factorization for high-dimensional time series prediction. Adv. Neural Inf. Process. Syst. 2016, 29, 847–855. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the The International Conference on Learning Representations (Poster), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | LSWT | LSWT_Day | LSWT_Night |
|---|---|---|---|
| unit | |||
| source | MOD11A1 | MOD11A1 | |
| Mean (Jul.~Sep.) | 13.413 | 14.829 | 11.558 |
| Maximum (Jul.~Sep.) | 21.903 | 21.903 | 17.644 |
| Minimum (Jul.~Sep.) | 1.770 | 0.130 | 0.005 |
| Standard deviation (Jul.~Sep.) | 2.530 | 2.402 | 3.416 |
| Name | TEMP | PRCP | WDSP | SP | TCC | SSR | STR | E |
|---|---|---|---|---|---|---|---|---|
| unit | mm | m/s | hPa | % | mm | |||
| source | GCS | GCS | GCS | GCS | ERA5 | ERA5 | ERA5 | ERA5 |
| Mean (Jul.~Sep.) | 10.326 | 3.214 | 2.909 | 683.283 | 0.588 | 784.025 | −322.333 | −3.603 |
| Maximum (Jul.~Sep.) | 21.111 | 55.118 | 7.407 | 691.100 | 1.000 | 1203.787 | −101.681 | −1.494 |
| Minimum (July~Sep.) | 0.889 | 0.000 | 0.617 | 676.600 | 0.000 | 178.670 | −515.127 | −5.963 |
| Standard deviation (Jul.~Sep.) | 3.291 | 5.559 | 0.816 | 2.063 | 0.267 | 231.458 | 89.291 | 0.001 |
| Name | LSWT | TEMP | PRCP | WDSP | SP | TCC | SSR | STR | E |
|---|---|---|---|---|---|---|---|---|---|
| Missing ratio | 34.47% | 0.10% | 0.10% | 0.16% | 0.10% | 0.00% | 0.00% | 0.00% | 0.00% |
| Name | Year | Data Size |
|---|---|---|
| training set | 2000~2014 | 1380 |
| validation set | 2015~2017 | 276 |
| test set | 2018~2020 | 276 |
| Model | Mean | Multivariate Regression | KNN | Linear Interpolation | Cubic Spline Interpolation | TRMF |
|---|---|---|---|---|---|---|
| Air2water | 0.148 | |||||
| MLP | 0.135 (0.004) | 0.145 (0.005) | 0.146 (0.005) | 0.131 (0.004) | 0.132 (0.003) | 0.140 (0.004) |
| RNN | 0.136 (0.001) | 0.146 (0.004) | 0.142 (0.004) | 0.132 (0.002) | 0.133 (0.002) | 0.141 (0.003) |
| LSTM | 0.141 (0.001) | 0.147 (0.003) | 0.151 (0.010) | 0.136 (0.002) | 0.136 (0.001) | 0.144 (0.002) |
| GRU | 0.138 (0.001) | 0.145 (0.003) | 0.146 (0.007) | 0.132 (0.002) | 0.132 (0.001) | 0.141 (0.001) |
| Transformer | 0.141 (0.005) | 0.152 (0.010) | 0.150 (0.009) | 0.135 (0.009) | 0.135 (0.009) | 0.146 (0.009) |
| GTN | 0.133 (0.002) | 0.139 (0.003) | 0.139 (0.005) | 0.130 (0.003) | 0.129 (0.003) | 0.137 (0.004) |
| Attention-GRU | 0.135 (0.001) | 0.141 (0.003) | 0.137 (0.003) | 0.126 (0.003) | 0.126 (0.003) | 0.137 (0.003) |
| Model | Mean | Multivariate Regression | KNN | Linear Interpolation | Cubic Spline Interpolation | TRMF |
|---|---|---|---|---|---|---|
| Air2water | 2.102 | |||||
| MLP | 2.034 (0.035) | 2.279 (0.060) | 2.283 (0.075) | 1.996 (0.045) | 2.035 (0.046) | 2.165 (0.052) |
| RNN | 2.013 (0.012) | 2.169 (0.051) | 2.111 (0.052) | 1.961 (0.014) | 1.977 (0.019) | 2.079 (0.028) |
| LSTM | 2.093 (0.018) | 2.179 (0.054) | 2.252 (0.155) | 2.014 (0.021) | 2.018 (0.018) | 2.139 (0.042) |
| GRU | 2.052 (0.015) | 2.147 (0.044) | 2.169 (0.115) | 1.968 (0.018) | 1.976 (0.009) | 2.088 (0.022) |
| Transformer | 2.095 (0.067) | 2.321 (0.125) | 2.297 (0.107) | 2.055 (0.102) | 2.091 (0.093) | 2.199 (0.106) |
| GTN | 1.992 (0.024) | 2.120 (0.032) | 2.105 (0.062) | 1.953 (0.037) | 1.961 (0.028) | 2.048 (0.043) |
| Attention-GRU | 2.007 (0.018) | 2.109 (0.023) | 2.082 (0.039) | 1.948 (0.036) | 1.962 (0.022) | 2.036 (0.034) |
| Model | Mean | Multivariate Regression | KNN | Linear Interpolation | Cubic Spline Interpolation | TRMF |
|---|---|---|---|---|---|---|
| Air2water | 0.215 | |||||
| MLP | 0.236 (0.026) | 0.041 (0.051) | 0.036 (0.063) | 0.264 (0.034) | 0.235 (0.035) | 0.134 (0.032) |
| RNN | 0.252 (0.009) | 0.131 (0.041) | 0.176 (0.041) | 0.290 (0.010) | 0.278 (0.014) | 0.202 (0.022) |
| LSTM | 0.191 (0.014) | 0.123 (0.044) | 0.060 (0.133) | 0.251 (0.015) | 0.248 (0.013) | 0.155 (0.034) |
| GRU | 0.223 (0.011) | 0.149 (0.035) | 0.129 (0.095) | 0.285 (0.013) | 0.279 (0.006) | 0.195 (0.017) |
| Transformer | 0.189 (0.053) | 0.003 (0.112) | 0.024 (0.095) | 0.219 (0.081) | 0.191 (0.073) | 0.105 (0.089) |
| GTN | 0.267 (0.018) | 0.170 (0.025) | 0.181 (0.048) | 0.296 (0.027) | 0.287 (0.021) | 0.225 (0.033) |
| Attention-GRU | 0.256 (0.013) | 0.179 (0.018) | 0.199 (0.030) | 0.299 (0.026) | 0.283 (0.020) | 0.235 (0.025) |
| Name | pcorr | CI95% | p-Value |
|---|---|---|---|
| TEMP | 0.515 | [0.47,0.55] | 0.000 |
| STR | −0.228 | [−0.28,−0.18] | 0.000 |
| E | 0.225 | [0.17,0.28] | 0.000 |
| TCC | −0.220 | [−0.27,−0.17] | 0.000 |
| SP | 0.129 | [0.07,0.18] | 0.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, Z.; Li, W.; Wu, J.; Zhang, S.; Hu, S. A Novel Deep Learning Model for Mining Nonlinear Dynamics in Lake Surface Water Temperature Prediction. Remote Sens. 2023, 15, 900. https://doi.org/10.3390/rs15040900
Hao Z, Li W, Wu J, Zhang S, Hu S. A Novel Deep Learning Model for Mining Nonlinear Dynamics in Lake Surface Water Temperature Prediction. Remote Sensing. 2023; 15(4):900. https://doi.org/10.3390/rs15040900
Chicago/Turabian StyleHao, Zihan, Weide Li, Jinran Wu, Shaotong Zhang, and Shujuan Hu. 2023. "A Novel Deep Learning Model for Mining Nonlinear Dynamics in Lake Surface Water Temperature Prediction" Remote Sensing 15, no. 4: 900. https://doi.org/10.3390/rs15040900
APA StyleHao, Z., Li, W., Wu, J., Zhang, S., & Hu, S. (2023). A Novel Deep Learning Model for Mining Nonlinear Dynamics in Lake Surface Water Temperature Prediction. Remote Sensing, 15(4), 900. https://doi.org/10.3390/rs15040900