1. Introduction
As a digital representation of the regional terrain surface, the digital elevation model (DEM) is inherently multi-scale in nature, and various geological analyses and simulations based on DEMs are also highly scale-dependent [
1,
2]. However, the prevailing multiscale DEM data suffer from scale fragmentation, scale discontinuity, data redundancy, and other challenges, which are unable to meet the demand of multiscale terrain analysis [
3,
4]. Recently, high-resolution DEMs have been obtained from costly high-precision sensors [
5] and other dense image-matching techniques to generate high-resolution DEMs [
6], but methods for generating higher-resolution DEMs from low-resolution DEMs without extra sensors and cameras are rarely discussed. Furthermore, when part of the high-resolution DEM data is missing or only a small region of data with similar topography can be obtained, as
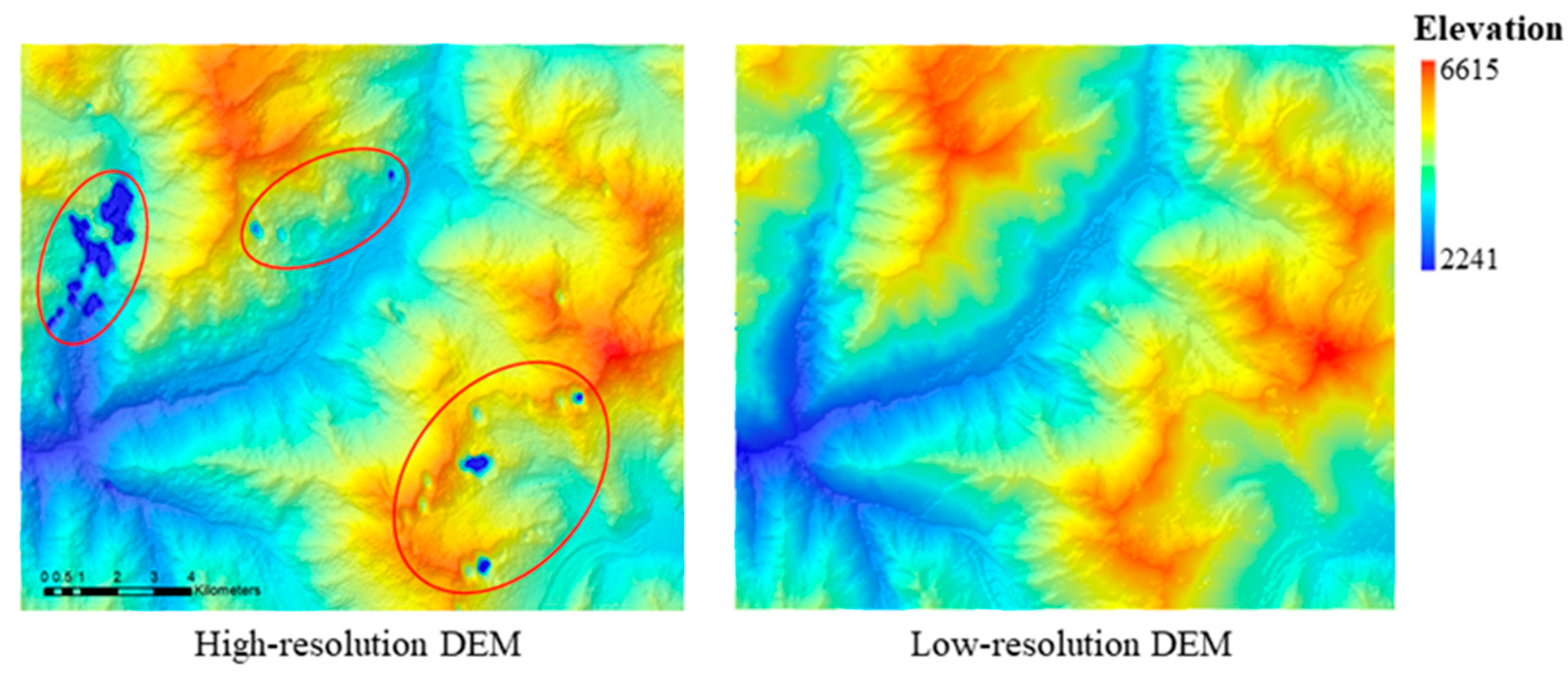
Figure 1 demonstrates, effectively enhancing the resolution of DEMs and improving the quality of DEM data to reconstruct large-scale DEMs based on existing data may yield new benefits [
7,
8,
9].
DEM super-resolution (SR) represents restoring the scale of DEM data from low-resolution DEM data [
10]. The main SR methods based on DEM data can be divided into learning-based methods, traditional approaches that contain interpolation-based methods [
11,
12], and data fusion-based methods [
13,
14,
15]. Traditional interpolation methods, such as inverse distance weighted (IDW), kriging, and bilinear interpolation, are the most widely used approaches because of their speed and simplicity, but the generated DEMs may suffer smoothing issues due to the lack of exploitation of non-local information about disjoint regions when applied to large-scale DEM reconstruction. The data fusion-based methods are applied to fill gaps between a variety of data sources and obtain high-quality DEMs with the constraint of many hyper-parameters. However, the inefficiency and low accuracy of the traditional methods make them inferior to deep-learning methods, which can reconstruct large-scale DEM data after being trained using several small areas of the region with similar topography.
Nowadays, in the SR domain, most of the approaches are aimed at natural pictures in computer vision (CV) [
16,
17,
18,
19] and remote sensing images [
20,
21]. The super resolution convolutional neural network (SRCNN) [
16] was the first end-to-end SR algorithm and provided better performance when compared to more conventional approaches. Motivated by pioneering work, the deeper Very Deep Convolutional Networks (VDSR) [
22] and Deeply-Recursive Convolutional Network (DRCN) [
23] with 20 layers were designed based on residual learning. However, the interpolated feature maps are computationally intensive and consume a lot of memory, leading to the deconvolutional layer in FSRCNN [
24] and the sub-pixel layer in the efficient sub-pixel CNN [
25] inserted at the end of the architecture to make a more lightweight SR network. Moreover, removing the batch normalization layer in the enhanced deep residual network (EDSR) [
17] further reduced the parameters of the network, resulting in better performance of a network containing the same parameters. Therefore, the total number and the complexity of the stackable modules can be improved to obtain more representations [
19]. Retrieved from attention mechanisms widely used in the CV domain [
26,
27,
28,
29], and residual structures that exert an enormous influence on feature aggregation [
18], some attention-based modules have been integrated with a residual block to further improve the SR network performance. The residual channel attention module in the residual channel attention network (RCAN) [
30], the channel-wise and spatial feature module in the channel-wise and spatial feature modulation network (CSFM) [
31], the second-order attention module in the second-order attention network (SAN) [
32], and the enhanced spatial attention module in the residual feature aggregation network (RFAN) [
18] can all obtain more powerful feature representation than the ordinary residual block.
Although significant improvements have been made in single-image SR (SISR), existing state-of-the-art learning-based models suffer from several constraints. Generally, a network for SR contains a series of stackable residual modules to enhance the feature representation extraction, such that a shallow feature can only exert a main influence on the next module, and the shallow feature has a lengthy path to exert influence on the ultimate feature. With the increase in the complexity and depth of the network, the features in the stackable modules will be layered with different perceptual fields and cannot be taken full advantage of in the representation of the intermediate layers of most of the existing learning-based models.
Moreover, these natural and remote sensing images are different from single-band DEMs, so typical SR techniques cannot be directly applied to DEM data [
33,
34], the main purpose of which is to obtain accurate elevation values. As for the learning-based algorithms, the CNN was first transferred from image SR to single-band DEM SR in 2016 [
10]. Subsequently, innovations have gradually led to improved outcomes in the DEM SR domain. Ref. [
8] enhanced the EDSR model by integrating gradient prior knowledge and transfer learning, which achieved excellent performance. Considering the current single scale in DEM SR, Ref. [
33] designed a multiscale DEM reconstruction architecture to generate high-resolution DEMs using multiscale supervision. Moreover, taking a mountain area into account, Ref. [
35] combined the residual block and VDSR to reconstruct the DEM with obvious undulation characteristics. Ref. [
36] refined the ESPCN and proposed the Recursive Sub-pixel Convolutional Neural Network (RSPCN) to generate finer-scale DEMs from low-resolution DEMs. In addition, other visual quality-oriented methods represented by generative adversarial networks (GANs) have also been developed in the DEM SR field. A conditional encoder–decoder generative adversarial network (CEDGAN) [
37] was proposed to combine the encoder–decoder structure with adversarial learning for spatial interpolation. Then, the topographical features were gradually combined with DEM SR networks. Ref. [
34] designed a loss function integrating the qualitative topographic knowledge of valley lines and ridge lines to complete the generation of gap DEMs. Explicit terrain feature-aware optimization was integrated into the loss module of the network [
9]. However, topographic specificity and consistent maintenance of terrain features both need to be considered sufficiently.
Moreover, in terms of the current different scales of DEMs, the degradation model and the blurred kernel are often unknown, and the low-resolution DEMs are not simply obtained using interpolation-based methods from the high-resolution DEMs. Therefore, the network trained with paired data generated using interpolation-based methods only simply fits the inverse process of interpolation, which lacks practical significance in the real world. However, the significance of taking real-world low-resolution DEM datasets as training datasets instead of data obtained using downsampling from high-resolution data has been overlooked thus far [
38].
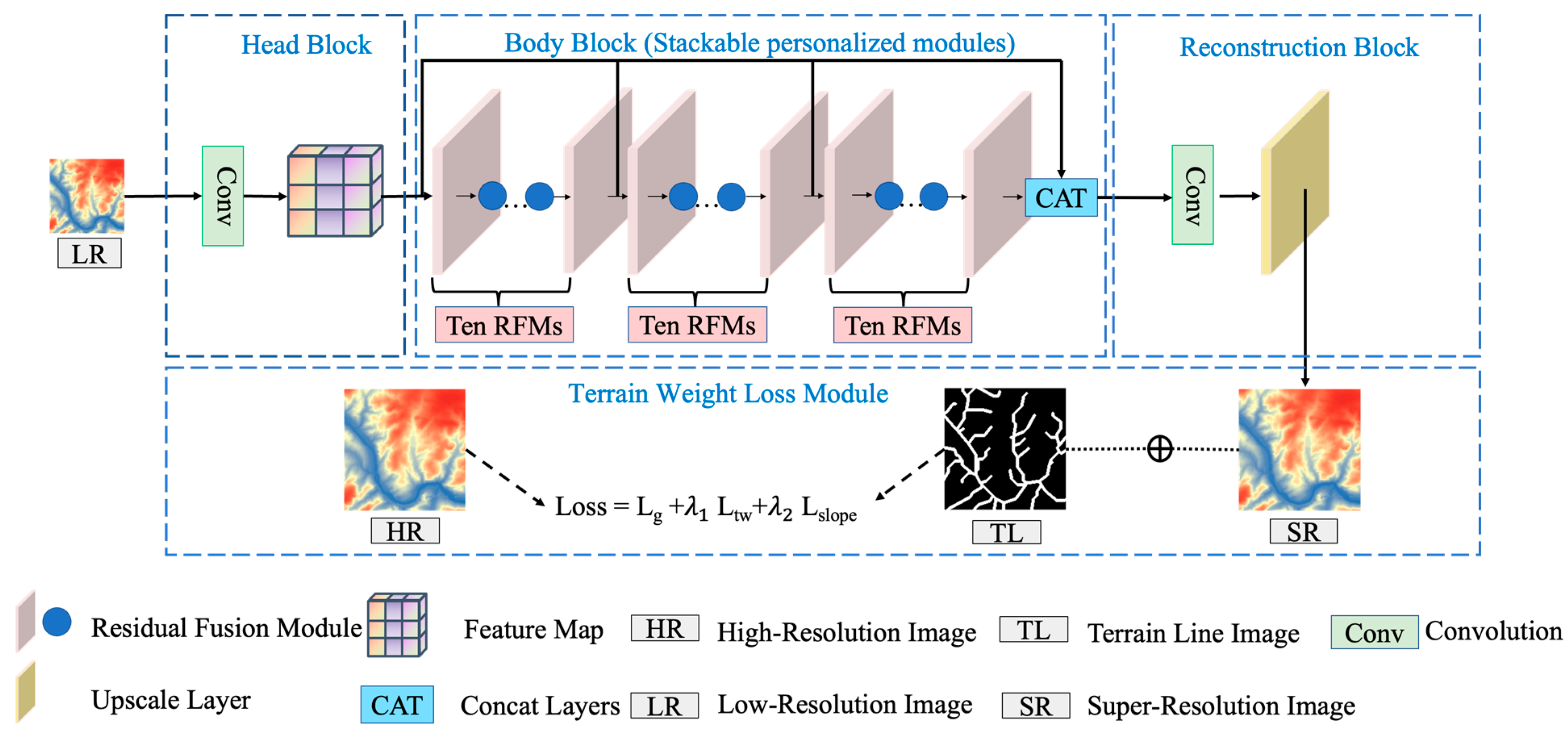
Therefore, in this paper, an enhanced residual feature fusion network (ERFFN), is designed to address the three issues depicted above: the lack of the exploitation of residual features, insufficient integration of terrain features, and the lack of practical significance of application scenarios. The ERFFN achieves superior results compared to the other state-of-the-art SR methods for DEM imagery. The main contributions of our study are summarized as follows:
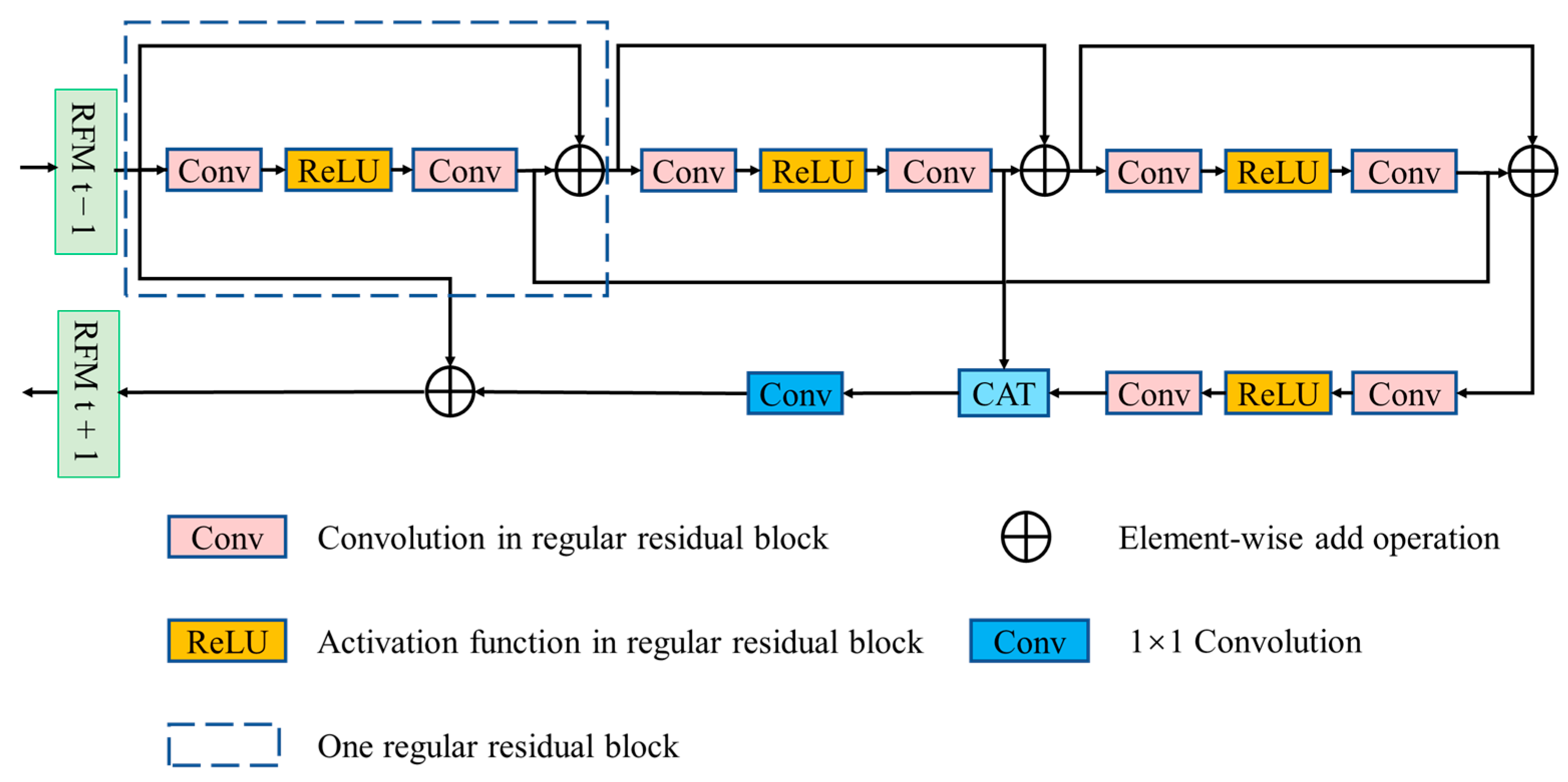
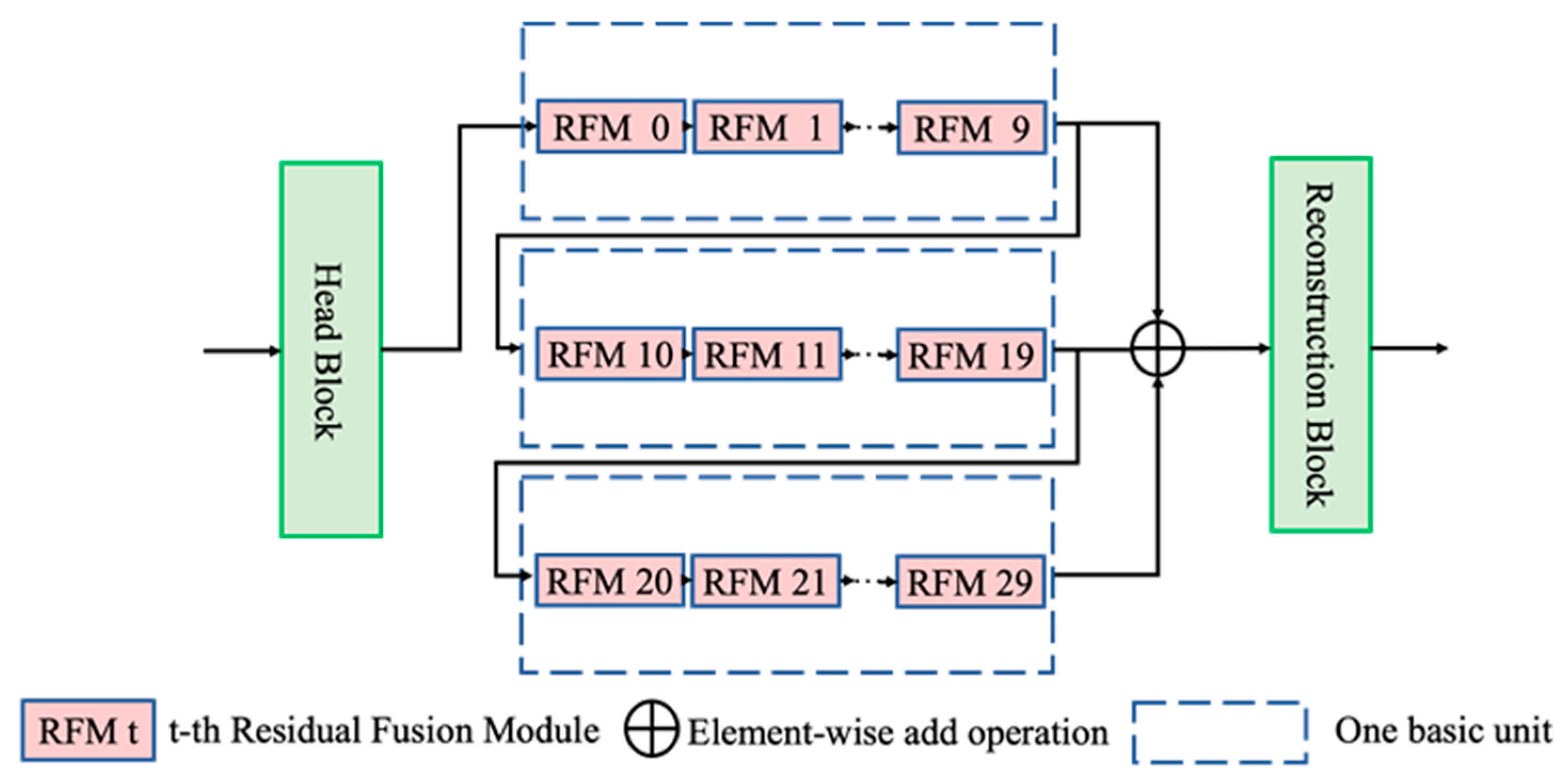
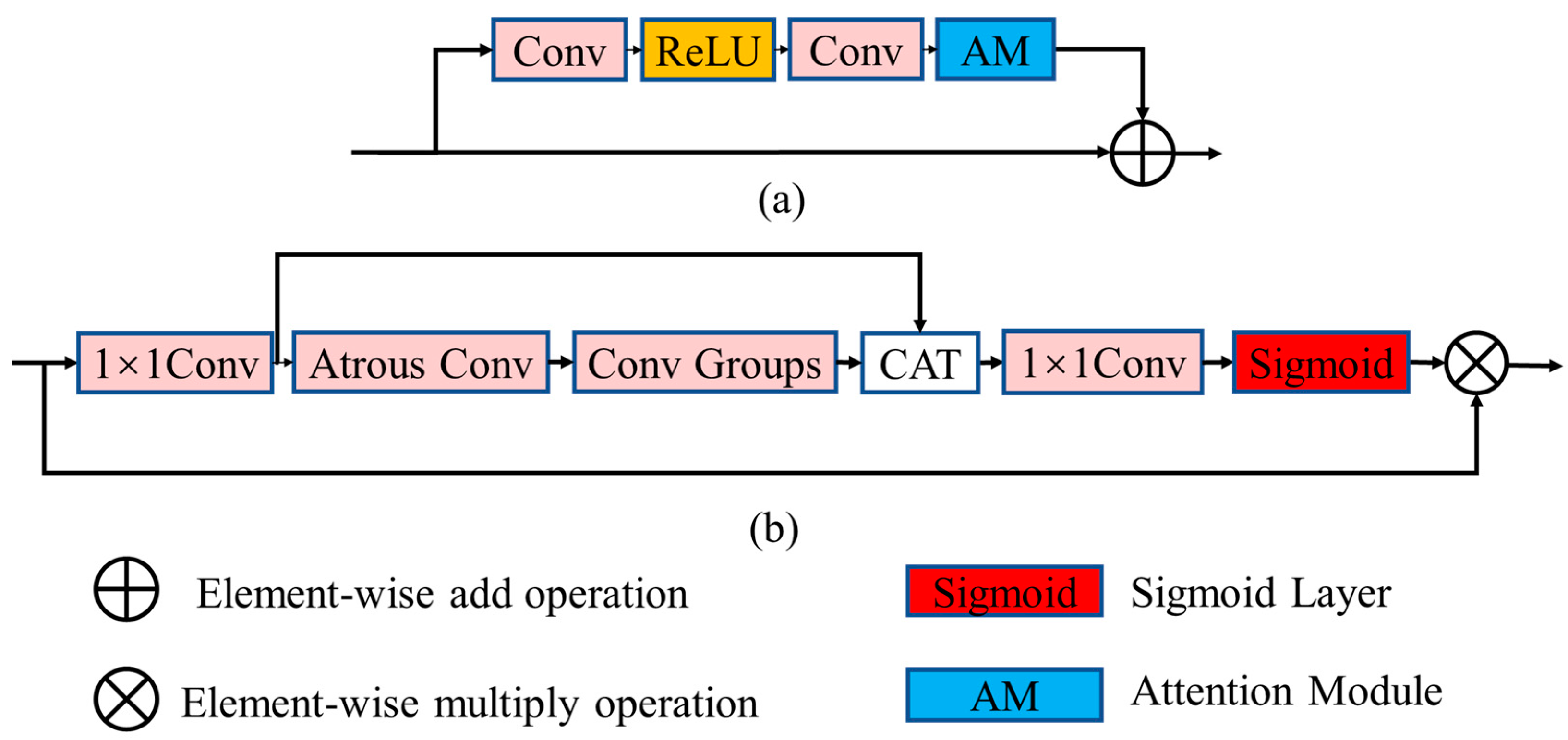
To enhance the utilization of residual features, a residual fusion module (RFM) is proposed for DEM SR. Our approach can propagate the influence of the intermediate features at a fraction of the cost, thus leading to effective feature extraction with a strong representation from DEM images and achieving a better trade-off between efficiency and performance.
Considering the relevance of residual features in the exploitation of feature representation, we refine the residual structure by inserting a lightweight enhanced spatial residual attention module (ESRAM) into each basic residual block to further strengthen the reconstruction accuracy of our proposed network.
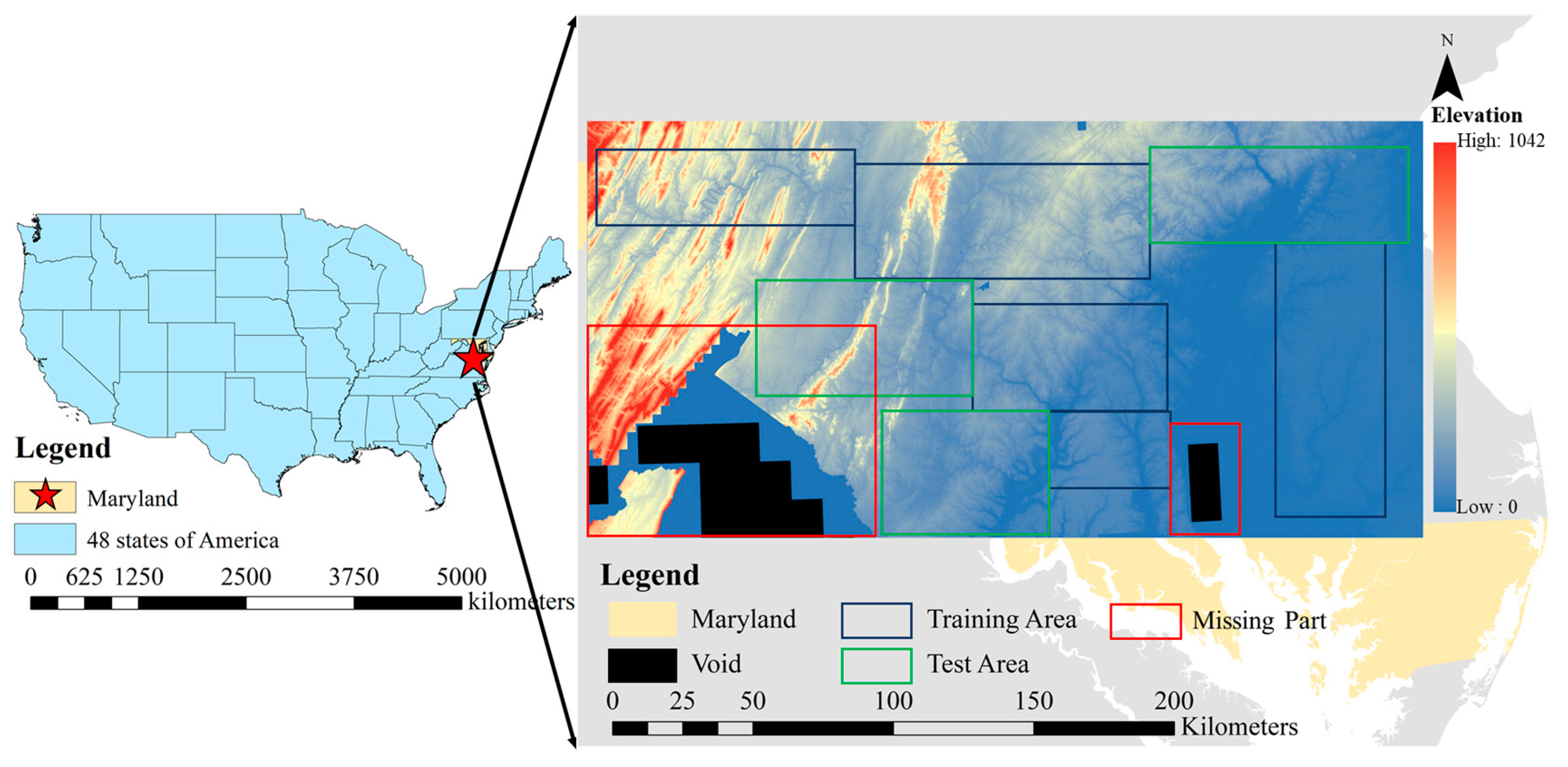
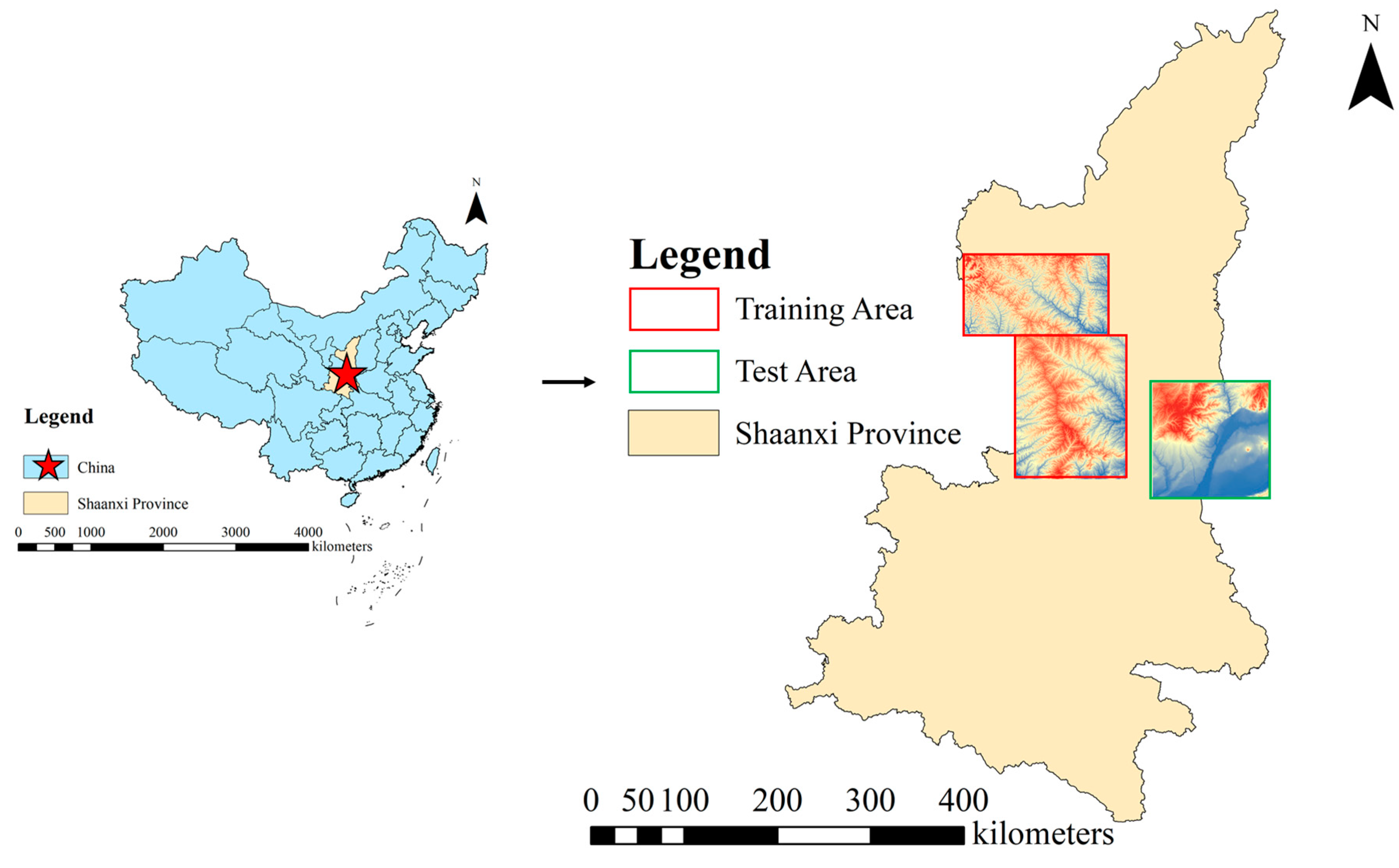
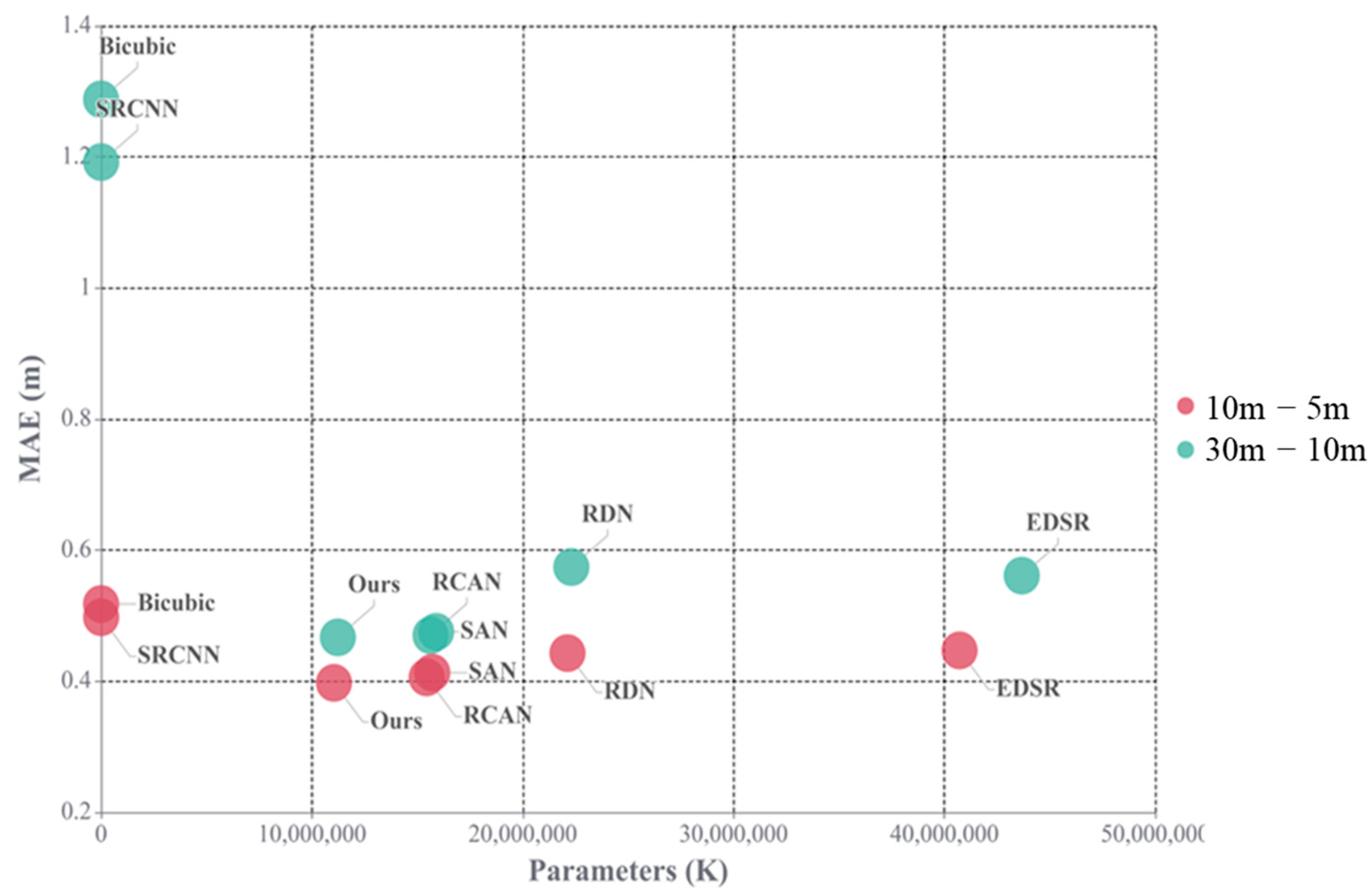
To sufficiently maintain continuity of the terrain features, a terrain weight loss module that incorporates slope loss and terrain feature loss is designed to learn strongly discriminative and topographic feature representations. Simultaneously, the proposed method is trained and evaluated using two large-scale DEM datasets for different reconstruction scales, and we deploy the trained model to reconstruct a missing part of the current high-resolution DEMs, which improves practical significance.
The remainder of this paper is organized as follows.
Section 2 presents the proposed architecture based on DEM data and the implementation details. The experimental data and training details are presented in
Section 3. The results are discussed in
Section 4 and finally, some conclusions are presented in
Section 5.



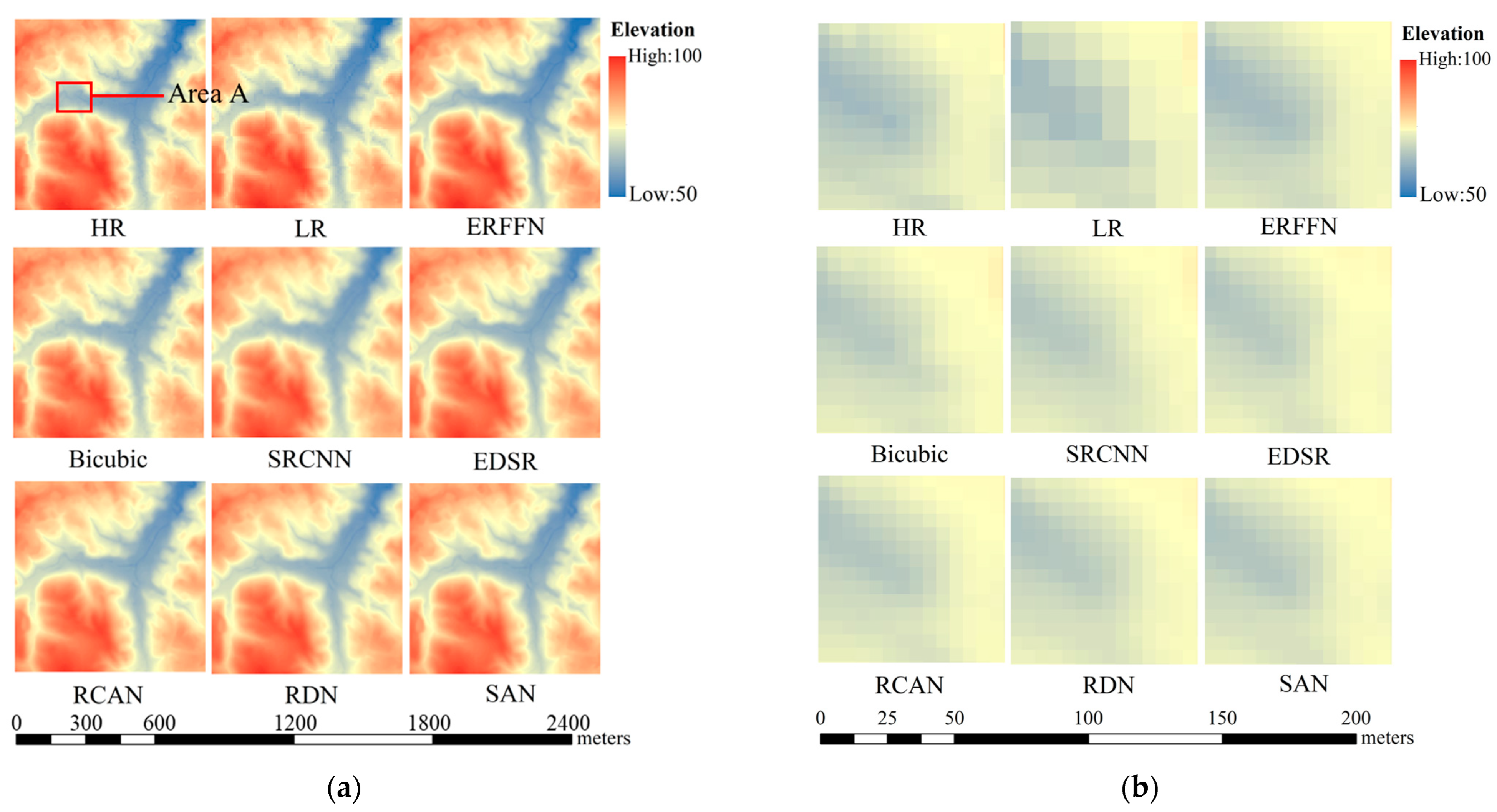
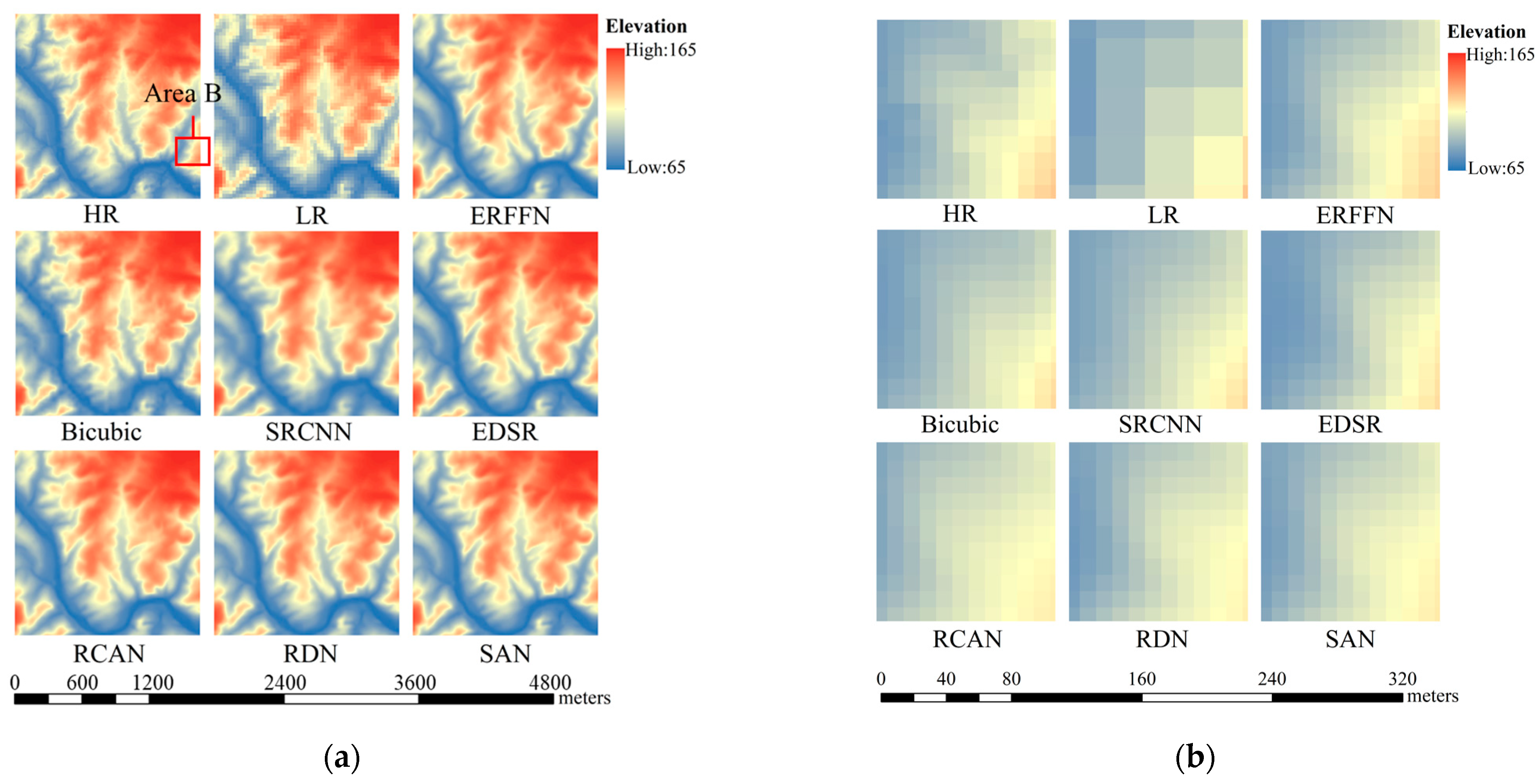




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}