
A Novel Deep Nearest Neighbor Neural Network for Few-Shot Remote Sensing Image Scene Classification

Abstract
1. Introduction
2. Related Work
2.1. Few-Shot Scene Classification of Remote Sensing Images
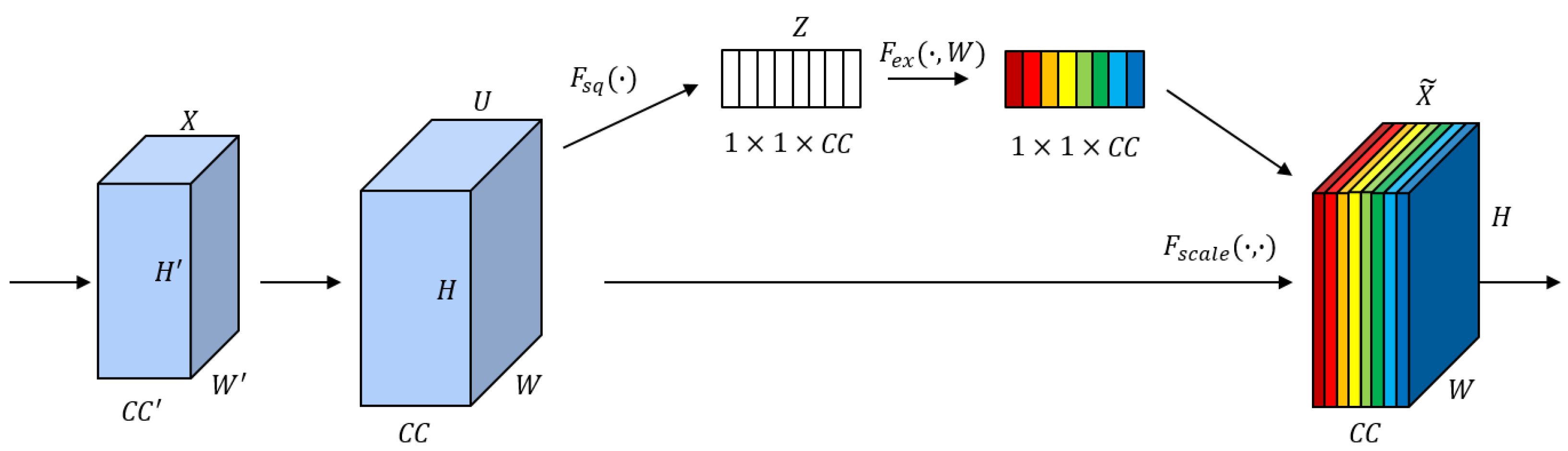
2.2. Channel Attention Mechanism
2.3. Deep Nearest Neighbor Neural Network
3. Methods
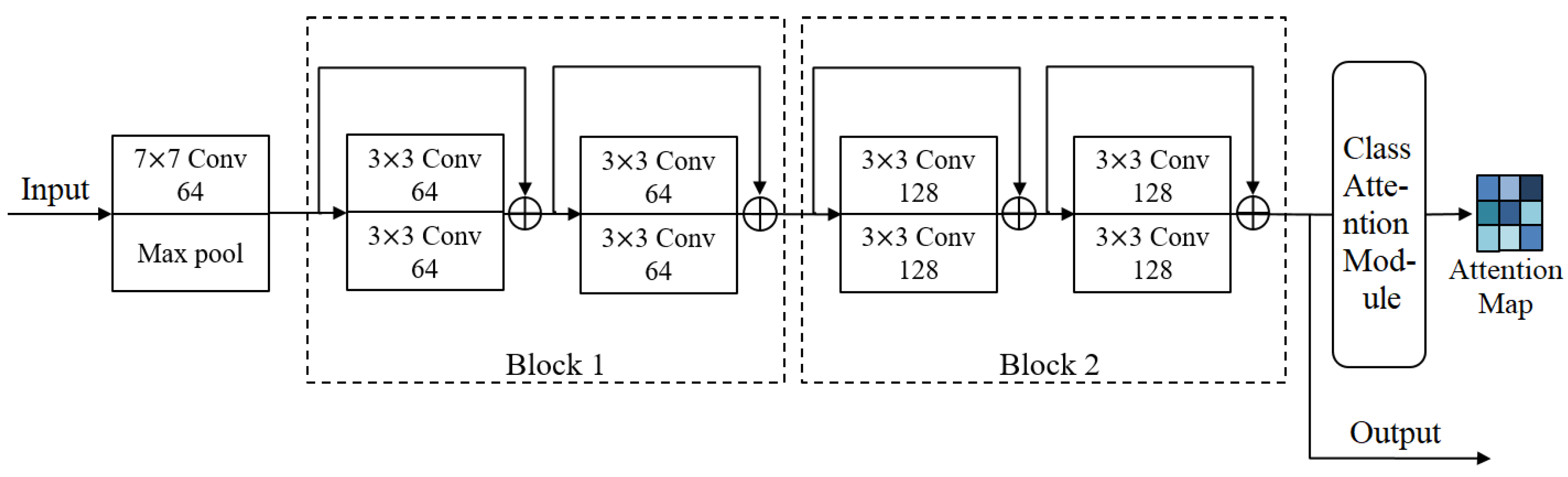
3.1. Architecture
3.2. Attention-Based Deep Embedding Module
3.3. Metric Module
4. Experiment and Discussion
4.1. Dataset Description
4.1.1. NWPU-RESISC45 Dataset
4.1.2. UC Merced Dataset
4.1.3. WHU-RS19 Dataset
4.2. Experimental Setting
4.2.1. Experimental Software and Hardware Environment
4.2.2. Experimental Design
4.2.3. Evaluating Indicator
4.3. Experimental Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bai, T.; Wang, H.; Wen, B. Targeted Universal Adversarial Examples for Remote Sensing. Remote Sens. 2022, 14, 5833. [Google Scholar] [CrossRef]
- Muhammad, U.; Hoque, M.; Wang, W.; Oussalah, M. Patch-Based Discriminative Learning for Remote Sensing Scene Classification. Remote Sens. 2022, 14, 5913. [Google Scholar] [CrossRef]
- Chen, X.; Zhu, G.; Liu, M. Remote Sensing Image Scene Classification with Self-Supervised Learning Based on Partially Unlabeled Datasets. Remote Sens. 2022, 14, 5838. [Google Scholar] [CrossRef]
- Jiang, N.; Shi, H.; Geng, J. Multi-Scale Graph-Based Feature Fusion for Few-Shot Remote Sensing Image Scene Classification. Remote Sens. 2022, 14, 5550. [Google Scholar] [CrossRef]
- Xing, S.; Xing, J.; Ju, J.; Hou, Q.; Ding, X. Collaborative Consistent Knowledge Distillation Framework for Remote Sensing Image Scene Classification Network. Remote Sens. 2022, 14, 5186. [Google Scholar] [CrossRef]
- Xiong, Y.; Xu, K.; Dou, Y.; Zhao, Y.; Gao, Z. WRMatch: Improving FixMatch with Weighted Nuclear-Norm Regularization for Few-Shot Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Wang, X.; Xu, H.; Yuan, L.; Dai, W.; Wen, X. A remote-sensing scene-image classification method based on deep multiple-instance learning with a residual dense attention ConvNet. Remote Sens. 2022, 14, 5095. [Google Scholar] [CrossRef]
- Gao, Y.; Sun, X.; Liu, C. A General Self-Supervised Framework for Remote Sensing Image Classification. Remote Sens. 2022, 14, 4824. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, J.; Yang, J.; Wu, Z. Remote Sensing Image Scene Classification via Self-Supervised Learning and Knowledge Distillation. Remote Sens. 2022, 14, 4813. [Google Scholar] [CrossRef]
- Cheng, G.; Guo, L.; Zhao, T.; Han, J.; Li, H.; Fang, J. Automatic landslide detection from remote-sensing imagery using a scene classification method based on BoVW and pLSA. Int. J. Remote Sens. 2013, 34, 45–59. [Google Scholar] [CrossRef]
- Lv, Z.; Shi, W.; Zhang, X.; Benediktsson, J. Landslide inventory mapping from bitemporal high-resolution remote sensing images using change detection and multiscale segmentation. IEEE J. Sel. Top. Appl. Earth Observ. 2018, 11, 1520–1532. [Google Scholar] [CrossRef]
- Longbotham, N.; Chaapel, C.; Bleiler, L.; Padwick, C.; Emery, W.; Pacifici, F. Very high resolution multiangle urban classification analysis. IEEE Trans. Geosci. Remote Sens. 2011, 50, 1155–1170. [Google Scholar] [CrossRef]
- Tayyebi, A.; Pijanowski, B.; Tayyebi, A. An urban growth boundary model using neural networks, GIS and radial parameterization: An application to Tehran, Iran. Landscape Urban Plan. 2011, 100, 35–44. [Google Scholar] [CrossRef]
- Huang, X.; Wen, D.; Li, J.; Qin, R. Multi-level monitoring of subtle urban changes for the megacities of China using high-resolution multi-view satellite imagery. Remote Sens. Environ. 2017, 196, 56–75. [Google Scholar] [CrossRef]
- Zhang, T.; Huang, X. Monitoring of urban impervious surfaces using time series of high-resolution remote sensing images in rapidly urbanized areas: A case study of Shenzhen. IEEE J. Sel. Top. Appl. Earth Observ. 2018, 11, 2692–2708. [Google Scholar] [CrossRef]
- Li, X.; Shao, G. Object-based urban vegetation mapping with high-resolution aerial photography as a single data source. Int. J. Remote Sens. 2013, 34, 771–789. [Google Scholar] [CrossRef]
- Rußwurm, M.; Körner, M. Multi-temporal land cover classification with sequential recurrent encoders. ISPRS Int. J. Geo-Inf. 2018, 7, 129. [Google Scholar] [CrossRef]
- Lowe, D. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Swain, M.; Ballard, D. Color indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Hinton, G.; Salakhutdinov, R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Olshausen, B.; Field, D. Sparse coding with an over-complete basis set: A strategy employed by V1? Vis. Res. 1997, 37, 3311–3325. [Google Scholar] [CrossRef]
- Li, L.; Han, J.; Yao, X.; Cheng, G.; Guo, L. DLA-MatchNet for few-shot remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7844–7853. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556v6. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, CA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 5–9. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Gui, R.; Xu, X.; Yang, R.; Wang, L.; Pu, F. Statistical scattering component-based subspace alignment for unsupervised cross-domain PolSAR image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5449–5463. [Google Scholar] [CrossRef]
- Zhou, H.; Du, X.; Li, S. Self-Supervision and Self-Distillation with Multilayer Feature Contrast for Supervision Collapse in Few-Shot Remote Sensing Scene Classification. Remote Sens. 2022, 14, 3111. [Google Scholar] [CrossRef]
- Huang, W.; Yuan, Z.; Yang, A.; Tang, C.; Luo, X. TAE-Net: Task-Adaptive Embedding Network for Few-Shot Remote Sensing Scene Classification. Remote Sens. 2022, 14, 111. [Google Scholar] [CrossRef]
- Kim, J.; Chi, M. AFFNet: Self-Attention-Based Feature Fusion Network for Remote Sensing Few-Shot Scene Classification. Remote Sens. 2021, 13, 2532. [Google Scholar] [CrossRef]
- Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; Luo, J. Revisiting Local Descriptor Based Image-To-Class Measure for Few-Shot Learning. arXiv 2019, arXiv:1903.12290v2. [Google Scholar]
- Boiman, O.; Shechtman, E.; Irani, M. In defense of nearest-neighbor based image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3630–3638. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Fukunaga, K.; Narendra, P. A branch and bound algorithm for computing k-nearest neighbors. IEEE Trans. Comput. 1975, 100, 750–753. [Google Scholar] [CrossRef]
- Wei, Y.; Yen, C.; Zsolt, K.; Yu, C.; Frank, W.; Jia, B. A closer look at few-shot classification. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019; pp. 1–17. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.; Hospedales, T. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-sgd: Learning to learn quickly for few-shot learning. arXiv 2017, arXiv:1707.09835v2. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. arXiv 2019, arXiv:1910.03151. [Google Scholar]
- Yang, L.; Zhang, R.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning (ICML), Online, 18–24 July 2021; pp. 11863–11874. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware Environment | CPU | Intel(R) Core(TM) i7-7800X CPU @ 3.50 GHz 32 GB |
| GPU | NVIDIA Geforce RTX 2080Ti 11 GB | |
| Software Environment | OS | Linux Ubuntu 18,04 LTS |
| Programing Language | python 3.6 | |
| Deep Learning Framework | Pytorch 1.4.0 | |
| CUDA | Cuda 10.0 |
| Method | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|
| MatchingNet | 54.46% ± 0.77% | 67.87% ± 0.59% |
| RelationNet | 58.61% ± 0.83% | 78.63% ± 0.52% |
| MAML | 37.36% ± 0.69% | 45.94% ± 0.68% |
| Meta-SGD | 60.63% ± 0.90% | 75.75% ± 0.65% |
| DLA-MatchNet | 68.80% ± 0.70% | 81.63% ± 0.46% |
| DN4 | 66.39% ± 0.86% | 83.24% ± 0.87% |
| Our Method | 70.75% ± 0.81% | 86.79% ± 0.51% |
| Method | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|
| MatchingNet | 46.16% ± 0.71% | 66.73% ± 0.56% |
| RelationNet | 48.89% ± 0.73% | 64.10% ± 0.54% |
| MAML | 43.65% ± 0.68% | 58.43% ± 0.64% |
| Meta-SGD | 50.52% ± 2.61% | 60.82% ± 2.00% |
| DLA-MatchNet | 53.76% ± 0.62% | 63.01% ± 0.51% |
| DN4 | 57.25% ± 1.01 | 79.74% ± 0.78% |
| Our Method | 65.49% ± 0.72% | 85.73% ± 0.47% |
| Method | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|
| MatchingNet | 60.60% ± 0.68% | 82.99% ± 0.40% |
| RelationNet | 60.54% ± 0.71% | 76.24% ± 0.34% |
| MAML | 46.72% ± 0.55% | 79.88% ± 0.41% |
| Meta-SGD | 51.54% ± 2.31% | 61.74% ± 2.02% |
| DLA-MatchNet | 68.27% ± 1.83% | 79.89% ± 0.33% |
| DN4 | 82.14% ± 0.80% | 96.02% ± 0.33% |
| Our Method | 85.05% ± 0.52% | 96.94% ± 0.21% |
| Method | ||||
|---|---|---|---|---|
| Our Method | 86.65% | 86.69% | 86.79% | 86.88% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Li, Y.; Mao, H.; Chai, X.; Jiao, L. A Novel Deep Nearest Neighbor Neural Network for Few-Shot Remote Sensing Image Scene Classification. Remote Sens. 2023, 15, 666. https://doi.org/10.3390/rs15030666
Chen Y, Li Y, Mao H, Chai X, Jiao L. A Novel Deep Nearest Neighbor Neural Network for Few-Shot Remote Sensing Image Scene Classification. Remote Sensing. 2023; 15(3):666. https://doi.org/10.3390/rs15030666
Chicago/Turabian StyleChen, Yanqiao, Yangyang Li, Heting Mao, Xinghua Chai, and Licheng Jiao. 2023. "A Novel Deep Nearest Neighbor Neural Network for Few-Shot Remote Sensing Image Scene Classification" Remote Sensing 15, no. 3: 666. https://doi.org/10.3390/rs15030666
APA StyleChen, Y., Li, Y., Mao, H., Chai, X., & Jiao, L. (2023). A Novel Deep Nearest Neighbor Neural Network for Few-Shot Remote Sensing Image Scene Classification. Remote Sensing, 15(3), 666. https://doi.org/10.3390/rs15030666