
Multi-Swin Mask Transformer for Instance Segmentation of Agricultural Field Extraction

 ,
,  , , ,
, , ,
Abstract
1. Introduction
- (1)
- Edge-based methods. These methods mainly use filters (such as Sobel, Canny [8], etc.) to extract the edges in the image, and use the extracted edges as the field boundary [9]. In order to obtain more accurate edges, some methods are assisted by NDVI [10]. There are many problems in this method. Firstly, the edge detection operator is susceptible to high-frequency noise. Even after Gaussian smoothing, the image will still have noise so that clean edge extraction cannot be achieved. The stronger the texture of the field, the greater the interference. Secondly, the results of edge detection are not connected, resulting in an inability to obtain closed fields. Finally, this method cannot be used independently. Usually, a remote sensing image contains more extra information than fields. Therefore, the field/non-field classification is required before edge extraction, resulting in a very cumbersome process.
- (2)
- Region-based methods such as selective search [11], the watershed algorithm [12], region growing, etc. There are many region based algorithms, which are usually integrated into the OpenCV tool library or implemented by software such as eCognition [13]. These methods group the adjacent pixels by feature (color, texture, etc.), and then, divide the image into several groups by continuously merging the surrounding pixels into one group and setting the super parameter as the loop termination condition. Watkins et al. realized the extraction of a farmland boundary through the watershed segmentation algorithm and some post-processing [14]. The defect of this method is also obvious. The region-based algorithm relies on the relevant segmentation algorithm, which tends to over-segment fields with high internal variability and under-segment small adjacent fields [6].
- (3)
- Machine learning-based methods. With the development of machine learning, especially deep learning, traditional image processing algorithms are being replaced. There are many machine learning methods, such as random forest, support vector machine, and the more popular convolutional neural network model [15,16,17]. Convolutional neural networks have been proven to be very effective in the field of computer vision, and have excellent performance in semantic segmentation, object detection, instance segmentation, and other tasks. For example, Wang et al. succeeded in the automatic detection of pothole distress and pavement cracks using an improved convolutional neural network [18,19]. Especially in recent years, with the development of the Transformer, deep learning has been pushed to a new height [20]. A Transformer is used for automatic pavement image classification [21], remote sensing imagery semantic segmentation [22], hyperspectral image classification [23], etc. In the task of field extraction, the deep learning method is gradually used. For example, the method of semantic segmentation is used to extract the farmland area and the ridge area, respectively, and then the results are combined [6]. Zhao et al. used the Hybrid Task Cascade (HTC) network to segment remote sensing images, and combined this with an overlapping and tiling strategy for post-processing [24,25]. Instance segmentation is very suitable for the intensive segmentation task of field extraction, because there is hardly any post-processing of the results. Thus, the focus of this study is on instance segmentation.
- The MSMTransformer network is proposed, which proves that the multi-scale shift window can effectively extract information in the process of self-attention, thereby improving the accuracy of instance segmentation. Additionally, we achieve a new state-of-the-art for instance segmentation using the iFLYTEK dataset [24].
- A process for integrating all felids at each image patch into one shape file is proposed for post-processing to avoid incomplete or overlapping results due to cropping.
2. Materials and Methods
2.1. Jilin-1 Image Dataset
2.2. Transformer Reviewing
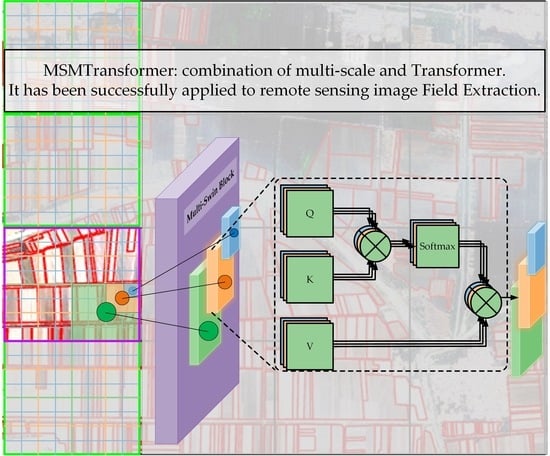
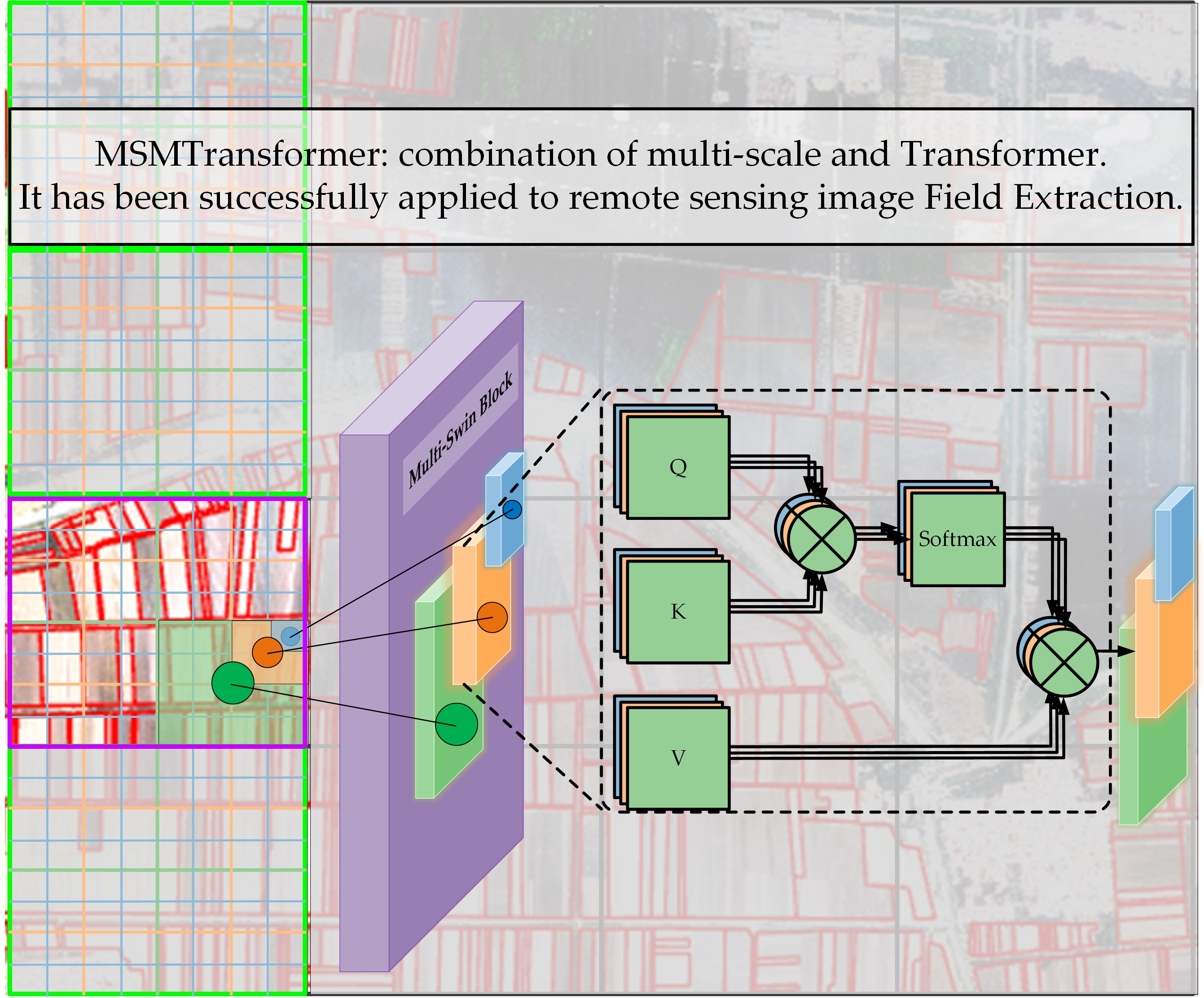
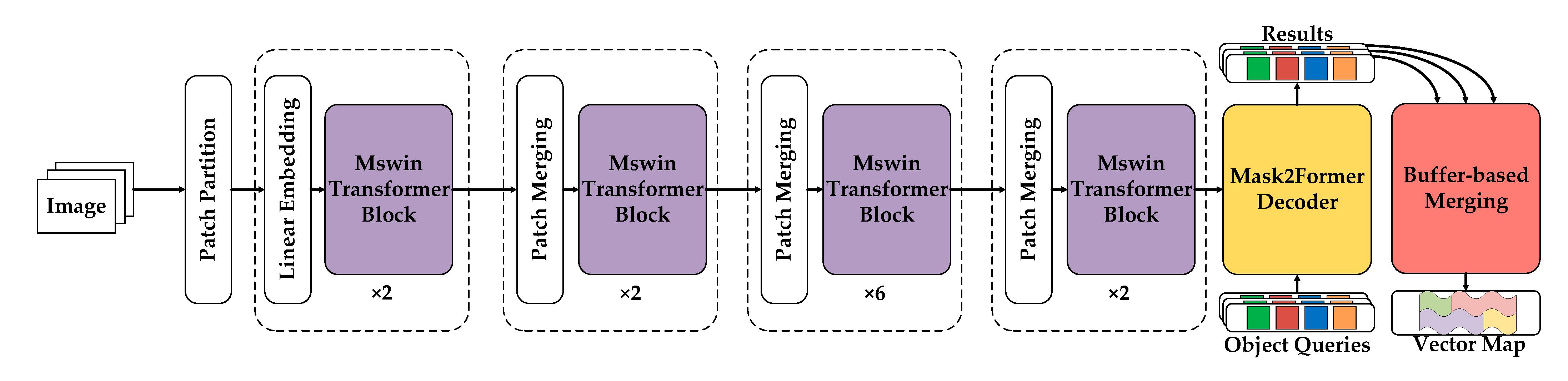
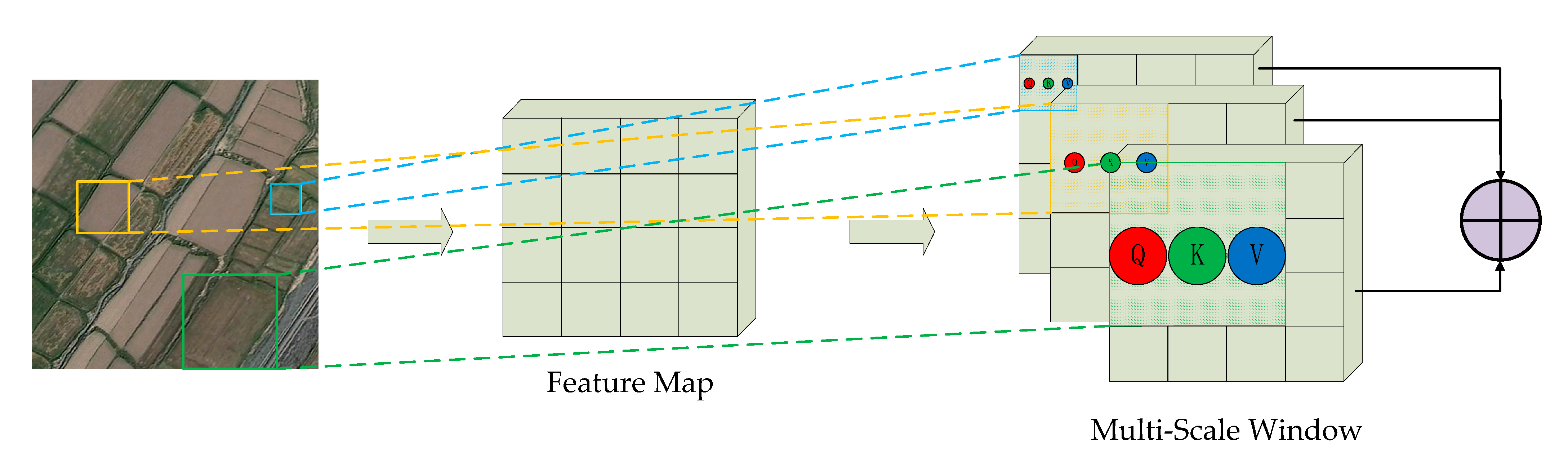
2.3. Details of the Multi-Swin Block
2.4. Details of Parameter Settings
3. Results
3.1. Quantitative Comparison
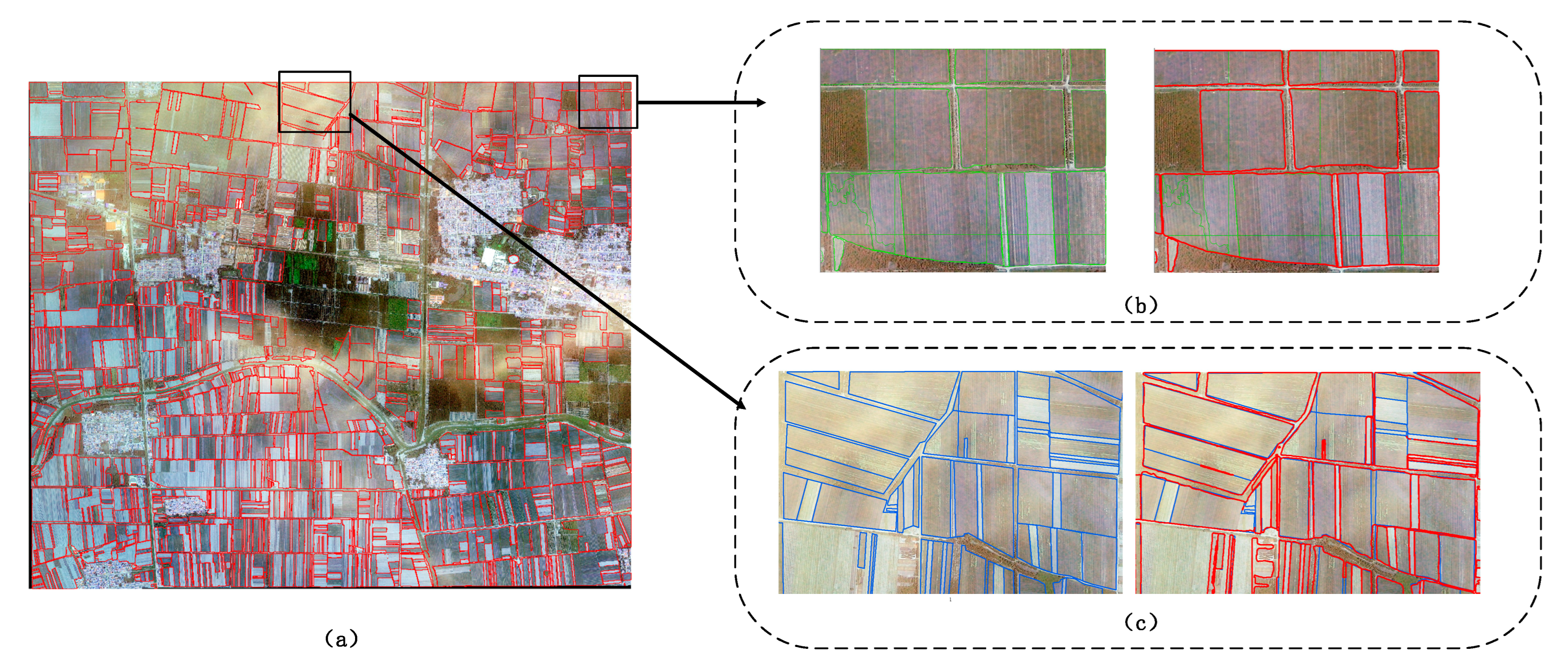
3.2. Visual Comparison
3.3. Multi-Scale Target Results
3.4. More Window Exploration
4. Discussion
4.1. Overlapping Problem
4.2. Merging the Outputted Small Images into One Single Vector File
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Carfagna, E.; Gallego, F.J. Using remote sensing for agricultural statistics. Int. Stat. Rev. 2005, 73, 389–404. [Google Scholar] [CrossRef]
- Graesser, J.; Ramankutty, N. Detection of cropland field parcels from Landsat imagery. Remote Sens. Environ. 2017, 201, 165–180. [Google Scholar] [CrossRef]
- Johnson, D.M. A 2010 map estimate of annually tilled cropland within the conterminous United States. Agric. Syst. 2013, 114, 95–105. [Google Scholar] [CrossRef]
- Rudel, T.K.; Schneider, L.; Uriarte, M.; Turner, B.L.; Grauj, R. Agricultural Intensification and Changes in Cultivated Areas. 2005. Available online: https://xueshu.baidu.com/usercenter/paper/show?paperid=c7de4819aa39593de58f99ec0510d8b6&site=xueshu_se&hitarticle=1 (accessed on 2 December 2022).
- Taravat, A.; Wagner, M.P.; Bonifacio, R.; Petit, D. Advanced Fully Convolutional Networks for Agricultural Field Boundary Detection. Remote Sens. 2021, 13, 722. [Google Scholar] [CrossRef]
- Fw, A.; Fid, B. Deep learning on edge: Extracting field boundaries from satellite images with a convolutional neural network—ScienceDirect. Remote Sens. Environ. 2020, 245, 111741. [Google Scholar]
- De Wit, A.J.W.; Clevers, J.G.P.W. Efficiency and accuracy of per-field classification for operational crop mapping. International J. Remote Sens. 2004, 25, 4091–4112. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Hong, R.; Park, J.; Jang, S.; Shin, H.; Song, I. Development of a Parcel-Level Land Boundary Extraction Algorithm for Aerial Imagery of Regularly Arranged Agricultural Areas. Remote Sens. 2021, 13, 1167. [Google Scholar] [CrossRef]
- Cheng, T.; Ji, X.; Yang, G.; Zheng, H.; Ma, J.; Yao, X.; Zhu, Y.; Cao, W. DESTIN: A new method for delineating the boundaries of crop fields by fusing spatial and temporal information from WorldView and Planet satellite imagery—ScienceDirect. Comput. Electron. Agric. 2020, 178, 105787. [Google Scholar] [CrossRef]
- Uijlings, J.R.; Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Soille, P.J.; Ansoult, M.M. Automated basin delineation from digital elevation models using mathematical morphology. Signal Process. 1990, 20, 171–182. [Google Scholar] [CrossRef]
- Hossain, M.; Chen, D. Segmentation for Object-Based Image Analysis (OBIA): A review of algorithms and challenges from remote sensing perspective. ISPRS J. Photogramm. Remote Sens. 2019, 150, 115–134. [Google Scholar] [CrossRef]
- Watkins, B.; Niekerk, A.V. A comparison of object-based image analysis approaches for field boundary delineation using multi-temporal Sentinel-2 imagery. Comput. Electron. Agric. 2019, 158, 294–302. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention Mask Transformer for Universal Image Segmentation. arXiv 2021, arXiv:2112.01527. [Google Scholar]
- Wang, D.; Liu, Z.; Gu, X.; Wu, W.; Chen, Y.; Wang, L. Automatic Detection of Pothole Distress in Asphalt Pavement Using Improved Convolutional Neural Networks. Remote Sens. 2022, 14, 3892. [Google Scholar] [CrossRef]
- Liu, Z.; Gu, X.; Chen, J.; Wang, D.; Chen, Y.; Wang, L. Automatic recognition of pavement cracks from combined GPR B-scan and C-scan images using multiscale feature fusion deep neural networks. Autom. Constr. 2023, 146, 104698. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Gu, X.; Liu, Z.; Liang, J. A Fast Inference Vision Transformer for Automatic Pavement Image Classification and Its Visual Interpretation Method. Remote Sens. 2022, 14, 1877. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Xia, R.; Li, T.; Chen, Z.; Wang, X.; Xu, Z.; Lyu, X. Encoding Contextual Information by Interlacing Transformer and Convolution for Remote Sensing Imagery Semantic Segmentation. Remote Sens. 2022, 14, 4065. [Google Scholar] [CrossRef]
- Yang, L.; Yang, Y.; Yang, J.; Zhao, N.; Wu, L.; Wang, L.; Wang, T. FusionNet: A Convolution–Transformer Fusion Network for Hyperspectral Image Classification. Remote Sens. 2022, 14, 4066. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Y.; Zhang, G.; Tang, L.; Hu, X. The Winning Solution to the iFLYTEK Challenge 2021 Cultivated Land Extraction from High-Resolution Remote Sensing Image. In Proceedings of the 2022 14th International Conference on Advanced Computational Intelligence (ICACI), Wuhan, China, 15–17 July 2022. [Google Scholar] [CrossRef]
- Kai, C.; Pang, J.; Wang, J.; Yu, X.; Lin, D. Hybrid Task Cascade for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision & Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. arXiv 2017, arXiv:1712.00726. [Google Scholar] [CrossRef]
- Nicolas, C.; Francisco, M.; Gabriel, S.; Nicolas, U.; Alexander, K.; Sergey, Z. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 May 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Houlsby, N. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Technicolor, T.; Related, S.; Technicolor, T.; Related, S. ImageNet Classification with Deep Convolutional Neural Networks; ACM: New York, NY, USA, 2012; Volume 60, pp. 84–90. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. arXiv 2017, arXiv:1701.04128. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Liu, Z.; Yeoh, J.K.W.; Gu, X.; Dong, Q.; Chen, Y.; Wu, W.; Wang, L.; Wang, D. Automatic pixel-level detection of vertical cracks in asphalt pavement based on GPR investigation and improved mask R-CNN. Autom. Constr. 2023, 146, 104689. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | AP (bbox) | AP50 (bbox) | AP75 (bbox) | AP (segm) | AP50 (segm) | AP75 (segm) | Param (M) |
|---|---|---|---|---|---|---|---|
| Mask R-CNN | 0.433 | 0.682 | 0.460 | 0.401 | 0.653 | 0.429 | 44.12 |
| HTC * | 0.529 | 0.753 | 0.583 | 0.496 | 0.734 | 0.542 | 139.79 |
| Mask2Former (Swin-T-7) | 0.522 | 0.742 | 0.562 | 0.523 | 0.754 | 0.566 | 47.40 |
| Mask2Former (Swin-T-12) | 0.518 | 0.740 | 0.559 | 0.513 | 0.745 | 0.555 | 47.45 |
| Mask2Former (Swin-S-7) | 0.515 | 0.743 | 0.557 | 0.517 | 0.747 | 0.564 | 68.72 |
| Ours (5-7-11) | 0.535 | 0.749 | 0.583 | 0.527 | 0.758 | 0.575 | 64.76 |
| Model | Bounding Box AP | Segmentation AP | ||||
|---|---|---|---|---|---|---|
| Small | Medium | Large | Small | Medium | Large | |
| Mask2Former (Swin-T-7) | 0.210 | 0.554 | 0.636 | 0.198 | 0.546 | 0.656 |
| Mask2Former (Swin-T-12) | 0.210 | 0.554 | 0.626 | 0.195 | 0.531 | 0.650 |
| Mask2Former (Swin-S-7) | 0.195 | 0.553 | 0.623 | 0.187 | 0.541 | 0.657 |
| Ours (5-7-11) | 0.220 | 0.569 | 0.649 | 0.203 | 0.545 | 0.670 |
| Model | AP (bbox) | AP50 (bbox) | AP75 (bbox) | AP (segm) | AP50 (segm) | AP75 (segm) | Param (M) |
|---|---|---|---|---|---|---|---|
| Mask2Former (Swin-T-7) | 0.522 | 0.742 | 0.562 | 0.523 | 0.754 | 0.566 | 47.40 |
| Mask2Former (Swin-T-12) | 0.518 | 0.740 | 0.559 | 0.513 | 0.745 | 0.555 | 47.45 |
| Mask2Former (Swin-S-7) | 0.515 | 0.743 | 0.557 | 0.517 | 0.747 | 0.564 | 68.72 |
| Ours (5-7-11-13) | 0.527 | 0.748 | 0.570 | 0.525 | 0.759 | 0.569 | 73.49 |
| Ours (5-7-12-16) | 0.526 | 0.747 | 0.571 | 0.525 | 0.759 | 0.570 | 73.54 |
| Ours (5-7-11) | 0.535 | 0.749 | 0.583 | 0.527 | 0.758 | 0.575 | 64.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, B.; Wei, T.; Luo, X.; Du, B.; Hu, L.; Ao, K.; Yang, A.; Wu, J. Multi-Swin Mask Transformer for Instance Segmentation of Agricultural Field Extraction. Remote Sens. 2023, 15, 549. https://doi.org/10.3390/rs15030549
Zhong B, Wei T, Luo X, Du B, Hu L, Ao K, Yang A, Wu J. Multi-Swin Mask Transformer for Instance Segmentation of Agricultural Field Extraction. Remote Sensing. 2023; 15(3):549. https://doi.org/10.3390/rs15030549
Chicago/Turabian StyleZhong, Bo, Tengfei Wei, Xiaobo Luo, Bailin Du, Longfei Hu, Kai Ao, Aixia Yang, and Junjun Wu. 2023. "Multi-Swin Mask Transformer for Instance Segmentation of Agricultural Field Extraction" Remote Sensing 15, no. 3: 549. https://doi.org/10.3390/rs15030549
APA StyleZhong, B., Wei, T., Luo, X., Du, B., Hu, L., Ao, K., Yang, A., & Wu, J. (2023). Multi-Swin Mask Transformer for Instance Segmentation of Agricultural Field Extraction. Remote Sensing, 15(3), 549. https://doi.org/10.3390/rs15030549