
An Unsupervised Band Selection Method via Contrastive Learning for Hyperspectral Images



Abstract
:
1. Introduction
2. Related Works
2.1. Contrastive Learning
2.2. Attention Mechanism
3. Proposed Method
3.1. Band Attention-Based Contrastive Learning Network
3.2. Loss Function of a Contrastive Learning-Based BS Network
3.3. Band Selection Based on Contrastive Learning
| Algorithm 1: ContrastBS Algorithm |
Input: Raw HSI , ContrastBS hyper-parameters, and the number of selected bands k. Step 1: Preprocess HSI and produce training samples . Step 2: Train the contrastive learning network. while Model is convergent or maximum iteration is met do 1: Sample a batch of . 2: Random data augmentation: . 3: Process two augmented views with the attention encoder: . 4: Transform the output of one view with the predictor and match it to the other: . 5: Optimize Equation (9) using SGD. end while Step 3: Compute average band weights based on Equation (10). Step 4: Select k bands with the largest weights. Output: k selected bands. |
4. Results
4.1. Experimental Setup
4.1.1. Comparison Methods
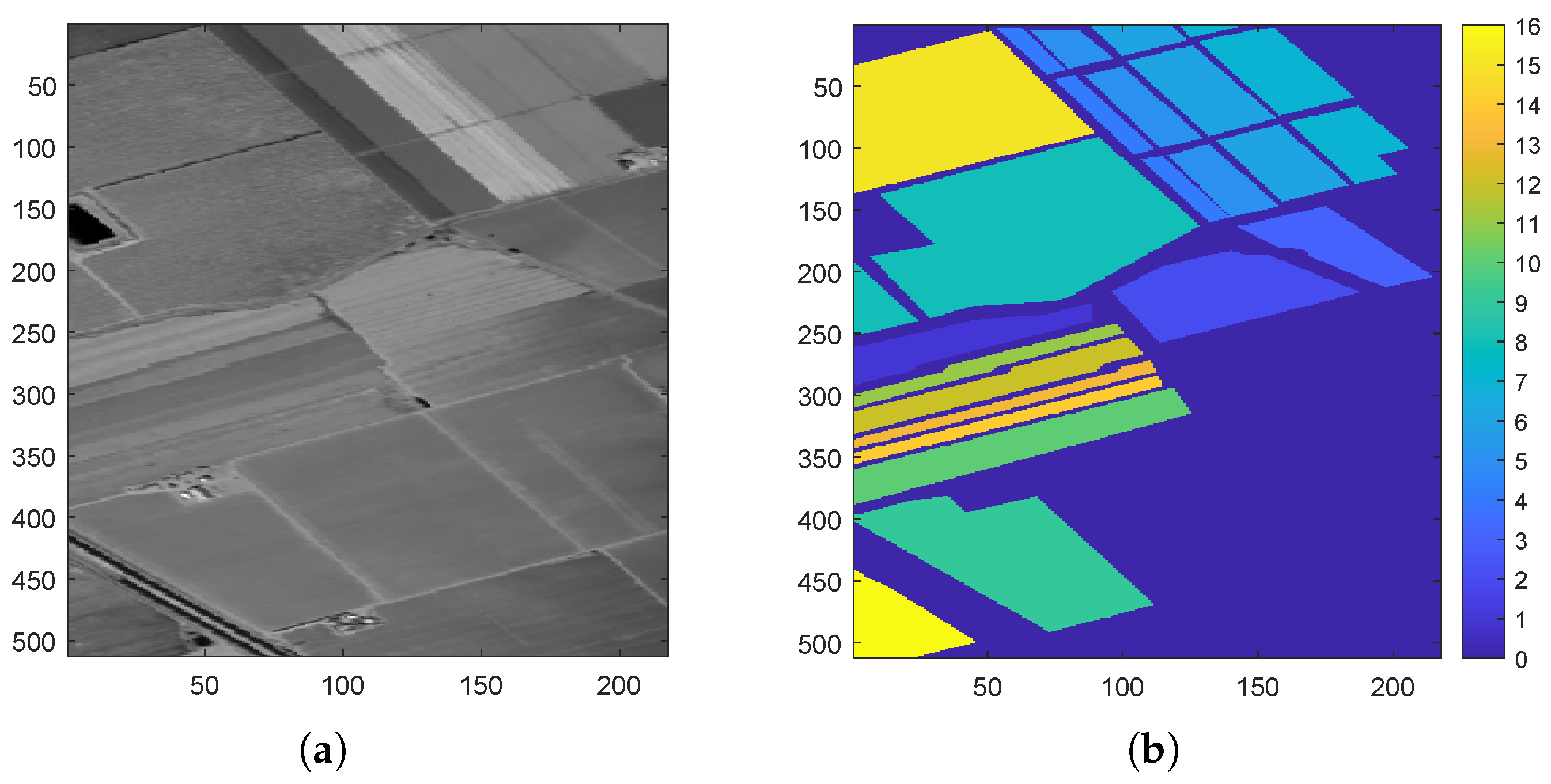
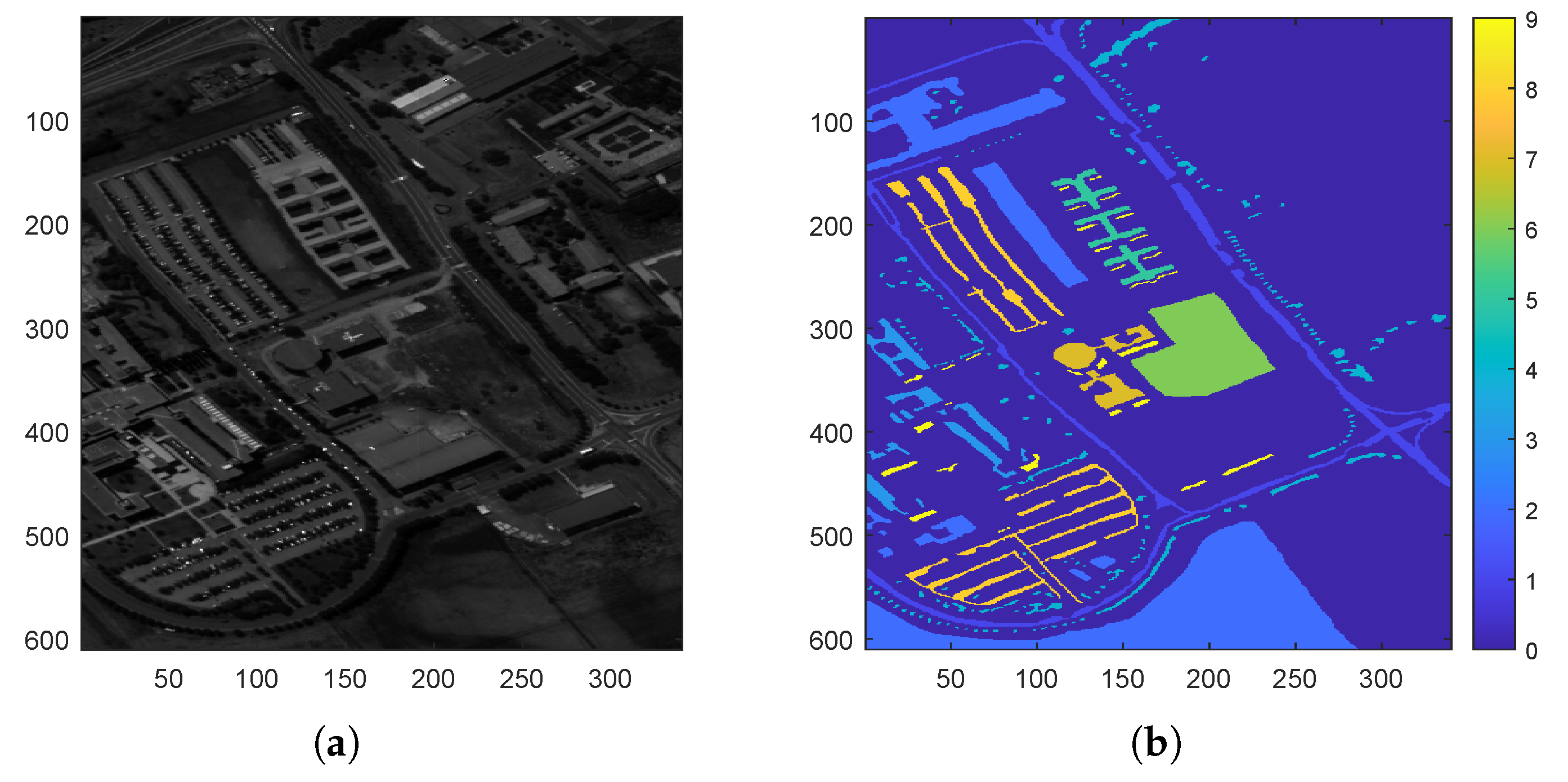
4.1.2. Datasets
4.1.3. Classifier and Classification Evaluation Metrics
4.1.4. Hyper-Parameter Settings
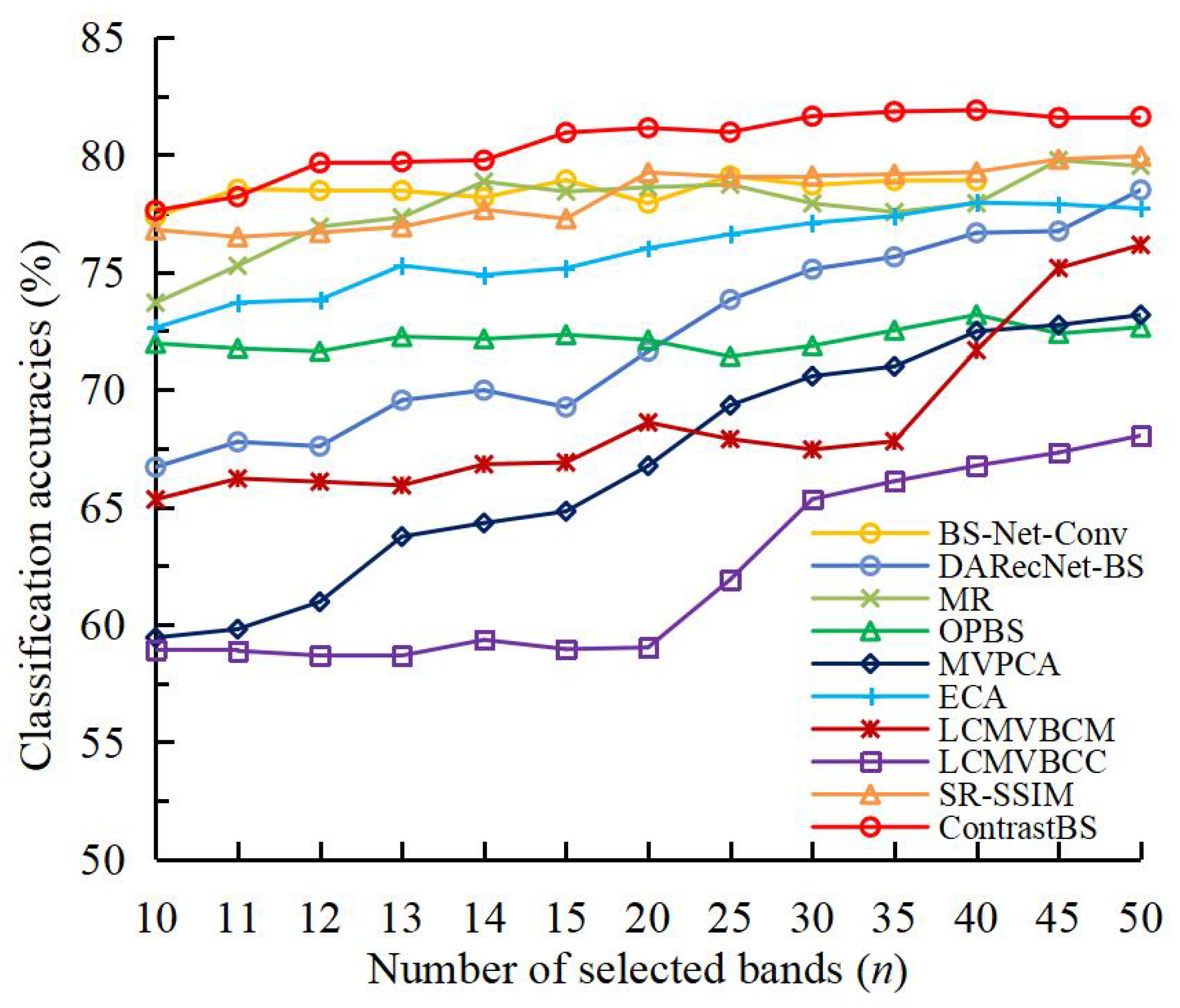
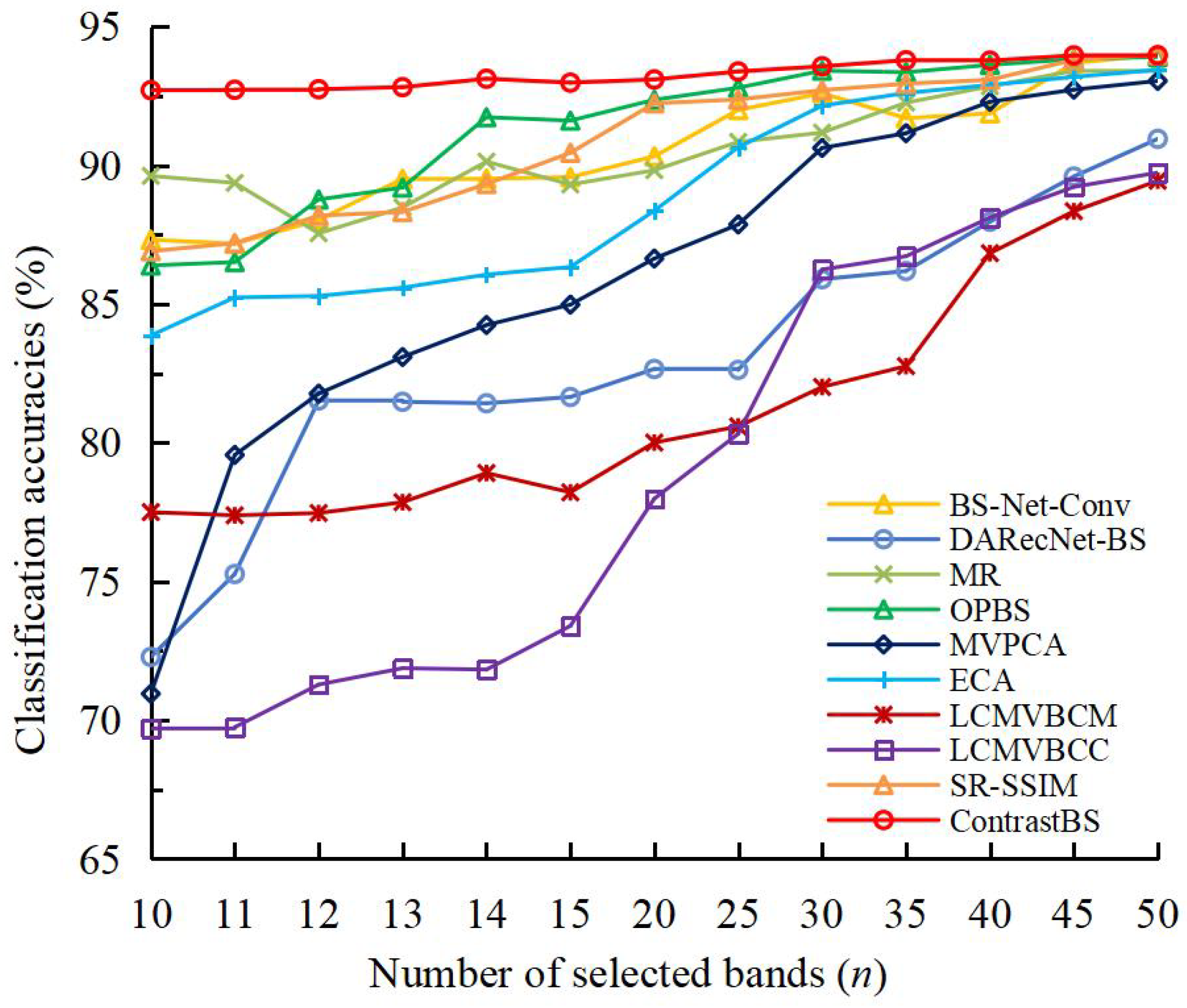
4.2. Classification Performance Comparison with Other BS Methods
4.2.1. IP Dataset
4.2.2. PU Dataset
4.2.3. SA Dataset
4.3. Analysis of Computational Time
4.4. Analysis of Data Augmentation Strategies
4.5. Ablation Study of the Loss Function
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, X.; Shen, X.; Pang, H.; Fu, X. Multiple Band Prioritization Criteria-Based Band Selection for Hyperspectral Imagery. Remote Sens. 2022, 14, 5679. [Google Scholar] [CrossRef]
- Liu, K.H.; Chen, Y.K.; Chen, T.Y. A Band Subset Selection Approach Based on Sparse Self-Representation and Band Grouping for Hyperspectral Image Classification. Remote Sens. 2022, 14, 5686. [Google Scholar] [CrossRef]
- Wang, X.; Qian, L.; Hong, M.; Liu, Y. Dual Homogeneous Patches-Based Band Selection Methodology for Hyperspectral Classification. Remote Sens. 2023, 15, 3841. [Google Scholar] [CrossRef]
- Song, M.; Shang, X.; Wang, Y.; Yu, C.; Chang, C.I. Class Information-Based Band Selection for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8394–8416. [Google Scholar] [CrossRef]
- Sun, W.; Yang, G.; Peng, J.; Meng, X.; He, K.; Li, W.; Li, H.C.; Du, Q. A Multiscale Spectral Features Graph Fusion Method for Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Chang, C.I.; Kuo, Y.M.; Chen, S.; Liang, C.C.; Ma, K.Y.; Hu, P.F. Self-Mutual Information-Based Band Selection for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5979–5997. [Google Scholar] [CrossRef]
- Liu, Y.; Li, X.; Xu, Z.; Hua, Z. BSFormer: Transformer-Based Reconstruction Network for Hyperspectral Band Selection. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Xu, B.; Li, X.; Hou, W.; Wang, Y.; Wei, Y. A Similarity-Based Ranking Method for Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9585–9599. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Niu, S.; Cao, Z.; Zhao, L. Kernel-OPBS Algorithm: A Nonlinear Feature Selection Method for Hyperspectral Imagery. IEEE Geosci. Remote Sens. Lett. 2020, 17, 464–468. [Google Scholar] [CrossRef]
- Liu, Y.; Li, X.; Hua, Z.; Xia, C.; Zhao, L. A Band Selection Method with Masked Convolutional Autoencoder for Hyperspectral Image. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Zhao, L. Discovering the Representative Subset with Low Redundancy for Hyperspectral Feature Selection. Remote Sens. 2019, 11, 1341. [Google Scholar] [CrossRef]
- Singh, P.S.; Karthikeyan, S. Enhanced classification of remotely sensed hyperspectral images through efficient band selection using autoencoders and genetic algorithm. Neural Comput. Appl. 2022, 34, 21539–21550. [Google Scholar] [CrossRef]
- Liu, Y.; Li, X.; Feng, Y.; Zhao, L.; Zhang, W. Representativeness and Redundancy-Based Band Selection for Hyperspectral Image Classification. Int. J. Remote Sens. 2021, 42, 3534–3562. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Dou, Y.; Zhao, L. A geometry-based band selection approach for hyperspectral image analysis. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4318–4333. [Google Scholar] [CrossRef]
- Chang, C.I.; Wang, S. Constrained band selection for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1575–1585. [Google Scholar] [CrossRef]
- Sun, K.; Geng, X.; Ji, L. Exemplar component analysis: A fast band selection method for hyperspectral imagery. IEEE Geosci. Remote Sens. Lett. 2015, 12, 998–1002. [Google Scholar]
- Chang, C.I.; Du, Q.; Sun, T.L.; Althouse, M.L. A joint band prioritization and band-decorrelation approach to band selection for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2631–2641. [Google Scholar] [CrossRef]
- Wang, Q.; Lin, J.; Yuan, Y. Salient band selection for hyperspectral image classification via manifold ranking. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 1279–1289. [Google Scholar] [CrossRef]
- Sun, W.; Peng, J.; Yang, G.; Du, Q. Fast and Latent Low-Rank Subspace Clustering for Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3906–3915. [Google Scholar] [CrossRef]
- Cai, Y.; Liu, X.; Cai, Z. BS-Nets: An End-to-End Framework for Band Selection of Hyperspectral Image. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1969–1984. [Google Scholar] [CrossRef]
- Zhang, H.; Sun, X.; Zhu, Y.; Xu, F.; Fu, X. A Global-Local Spectral Weight Network Based on Attention for Hyperspectral Band Selection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Roy, S.K.; Das, S.; Song, T.; Chanda, B. DARecNet-BS: Unsupervised Dual-Attention Reconstruction Network for Hyperspectral Band Selection. IEEE Geosci. Remote Sens. Lett. 2021, 18, 2152–2156. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3733–3742. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Galassi, A.; Lippi, M.; Torroni, P. Attention in natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4291–4308. [Google Scholar] [CrossRef]
- Subakan, C.; Ravanelli, M.; Cornell, S.; Bronzi, M.; Zhong, J. Attention Is All You Need In Speech Separation. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 21–25. [Google Scholar] [CrossRef]
- Sun, H.; Zheng, X.; Lu, X.; Wu, S. Spectral–Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3232–3245. [Google Scholar] [CrossRef]
- Li, X.; Ding, J. Spectral–Temporal Transformer for Hyperspectral Image Change Detection. Remote Sens. 2023, 15, 3561. [Google Scholar] [CrossRef]
- Dou, Z.; Gao, K.; Zhang, X.; Wang, H.; Han, L. Band selection of hyperspectral images using attention-based autoencoders. IEEE Geosci. Remote Sens. Lett. 2020, 18, 147–151. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Chanussot, J.; Benediktsson, J.A. Segmentation and classification of hyperspectral images using watershed transformation. Pattern Recognit. 2010, 43, 2367–2379. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Zhao, L. A Fast Hyperspectral Feature Selection Method Based on Band Correlation Analysis. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1750–1754. [Google Scholar] [CrossRef]
- Sui, C.; Li, C.; Feng, J.; Mei, X. Unsupervised Manifold-Preserving and Weakly Redundant Band Selection Method for Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1156–1170. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Pixel | Band | Class |
|---|---|---|---|
| Indian Pines | 145 × 145 | 185 | 16 |
| Salinas | 512 × 217 | 224 | 16 |
| Pavia University | 610 × 340 | 103 | 9 |
| Class | ||
|---|---|---|
| 1. Alfalfa | 5 | 49 |
| 2. Corn-notill | 143 | 1291 |
| 3. Corn-mintill | 83 | 751 |
| 4. Corn | 23 | 221 |
| 5. Grass/pasture | 49 | 448 |
| 6. Grass/trees | 74 | 673 |
| 7. Grass/pasture-mowed | 2 | 24 |
| 8. Hay-windrowed | 48 | 441 |
| 9. Oats | 2 | 18 |
| 10. Soybeans-notill | 96 | 872 |
| 11. Soybeans-mintill | 246 | 2222 |
| 12. Soybeans-clean | 61 | 553 |
| 13. Wheat | 21 | 191 |
| 14. Woods | 129 | 1165 |
| 15. Buildings-grass-trees-drives | 38 | 342 |
| 16. Stone-steel towers | 9 | 86 |
| Class | ||
|---|---|---|
| 1. Asphalt | 663 | 5968 |
| 2. Meadows | 1000 | 17,649 |
| 3. Gravel | 209 | 1890 |
| 4. Trees | 306 | 2758 |
| 5. Painted metal sheets | 134 | 1211 |
| 6. Bare soil | 502 | 4527 |
| 7. Bitumen | 133 | 1197 |
| 8. Self-blocking bricks | 368 | 3314 |
| 9. Shadows | 94 | 853 |
| Class | ||
|---|---|---|
| 1. Weeds_1 | 200 | 1809 |
| 2. Weeds_2 | 372 | 3354 |
| 3. Fallow | 197 | 1779 |
| 4. Fallow_rough_plow | 139 | 1255 |
| 5. Fallow_smooth | 267 | 2411 |
| 6. Stubble | 395 | 3564 |
| 7. Celery | 357 | 3222 |
| 8. Grapes_untrained | 1000 | 10,271 |
| 9. Soil_vinyard_develop | 620 | 5583 |
| 10. Corn_senesced_green_weeds | 327 | 2951 |
| 11. Lettuce_romaine_4wk | 106 | 962 |
| 12. Lettuce_romaine_5wk | 192 | 1735 |
| 13. Lettuce_romaine_6wk | 91 | 825 |
| 14. Lettuce_romaine_7wk | 107 | 963 |
| 15. Vinyard_untrained | 726 | 6542 |
| 16. Vinyard_vertical_trellis | 180 | 1627 |
| OA (%) | AA (%) | Kappa | |
|---|---|---|---|
| 1. BS-Net-Conv | 78.91 | 72.27 | 0.7591 |
| 2. DARecNet-BS | 69.25 | 61.90 | 0.6467 |
| 3. MR | 78.42 | 71.24 | 0.7391 |
| 4. OPBS | 72.33 | 62.97 | 0.6832 |
| 5. MVPCA | 64.81 | 50.83 | 0.5960 |
| 6. ECA | 75.16 | 65.25 | 0.7159 |
| 7. LCMVBCM | 66.90 | 60.98 | 0.6186 |
| 8. LCMVBCC | 58.95 | 49.74 | 0.5241 |
| 9. SR-SSIM | 74.06 | 65.73 | 0.7396 |
| 10. ContrastBS | 80.94 | 74.01 | 0.7821 |
| OA (%) | AA (%) | Kappa | |
|---|---|---|---|
| 1. BS-Net-Conv | 87.31 | 77.11 | 0.8306 |
| 2. DARecNet-BS | 72.28 | 62.01 | 0.6248 |
| 3. MR | 89.61 | 79.03 | 0.8442 |
| 4. OPBS | 86.39 | 76.28 | 0.8182 |
| 5. MVPCA | 70.95 | 55.99 | 0.6129 |
| 6. ECA | 83.86 | 71.88 | 0.7841 |
| 7. LCMVBCM | 77.50 | 67.97 | 0.6896 |
| 8. LCMVBCC | 69.70 | 63.76 | 0.5803 |
| 9. SR-SSIM | 86.90 | 77.60 | 0.8244 |
| 10. ContrastBS | 92.70 | 82.01 | 0.9025 |
| OA(%) | AA (%) | Kappa | |
|---|---|---|---|
| 1. BS-Net-Conv | 90.27 | 89.07 | 0.8916 |
| 2. DARecNet-BS | 90.95 | 89.99 | 0.8990 |
| 3. MR | 89.94 | 88.84 | 0.8970 |
| 4. OPBS | 92.04 | 90.10 | 0.9111 |
| 5. MVPCA | 84.91 | 84.10 | 0.8316 |
| 6. ECA | 92.01 | 90.23 | 0.9109 |
| 7. LCMVBCM | 89.62 | 89.21 | 0.8659 |
| 8. LCMVBCC | 87.88 | 87.82 | 0.8554 |
| 9. SR-SSIM | 92.55 | 90.60 | 0.9169 |
| 10. ContrastBS | 93.00 | 90.80 | 0.9220 |
| MR | OPBS | MVPCA | ECA | LCMVBCM | LCMVBCC | SR-SSIM | BS-Net-Conv | DARecNet-BS | ContrastBS | |
|---|---|---|---|---|---|---|---|---|---|---|
| Training Time (s) | 4.79 | 0.74 | 0.13 | 1.97 | 1.64 | 3.18 | 35.91 | 18,050.45 | 3211.74 | 110.91 |
| Inference Time (s) | 0.0004 | 0.0137 | 0.0004 |
| Symmetric | Sparsity | OA (%) | AA (%) | Kappa |
|---|---|---|---|---|
| ✔ | 67.17 | 60.30 | 0.6215 | |
| ✔ | 53.83 | 39.46 | 0.4569 | |
| ✔ | ✔ | 80.94 | 74.01 | 0.7821 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Liu, Y.; Hua, Z.; Chen, S. An Unsupervised Band Selection Method via Contrastive Learning for Hyperspectral Images. Remote Sens. 2023, 15, 5495. https://doi.org/10.3390/rs15235495
Li X, Liu Y, Hua Z, Chen S. An Unsupervised Band Selection Method via Contrastive Learning for Hyperspectral Images. Remote Sensing. 2023; 15(23):5495. https://doi.org/10.3390/rs15235495
Chicago/Turabian StyleLi, Xiaorun, Yufei Liu, Ziqiang Hua, and Shuhan Chen. 2023. "An Unsupervised Band Selection Method via Contrastive Learning for Hyperspectral Images" Remote Sensing 15, no. 23: 5495. https://doi.org/10.3390/rs15235495
APA StyleLi, X., Liu, Y., Hua, Z., & Chen, S. (2023). An Unsupervised Band Selection Method via Contrastive Learning for Hyperspectral Images. Remote Sensing, 15(23), 5495. https://doi.org/10.3390/rs15235495