
Deep Learning-Based Enhanced ISAR-RID Imaging Method

Abstract
:1. Introduction
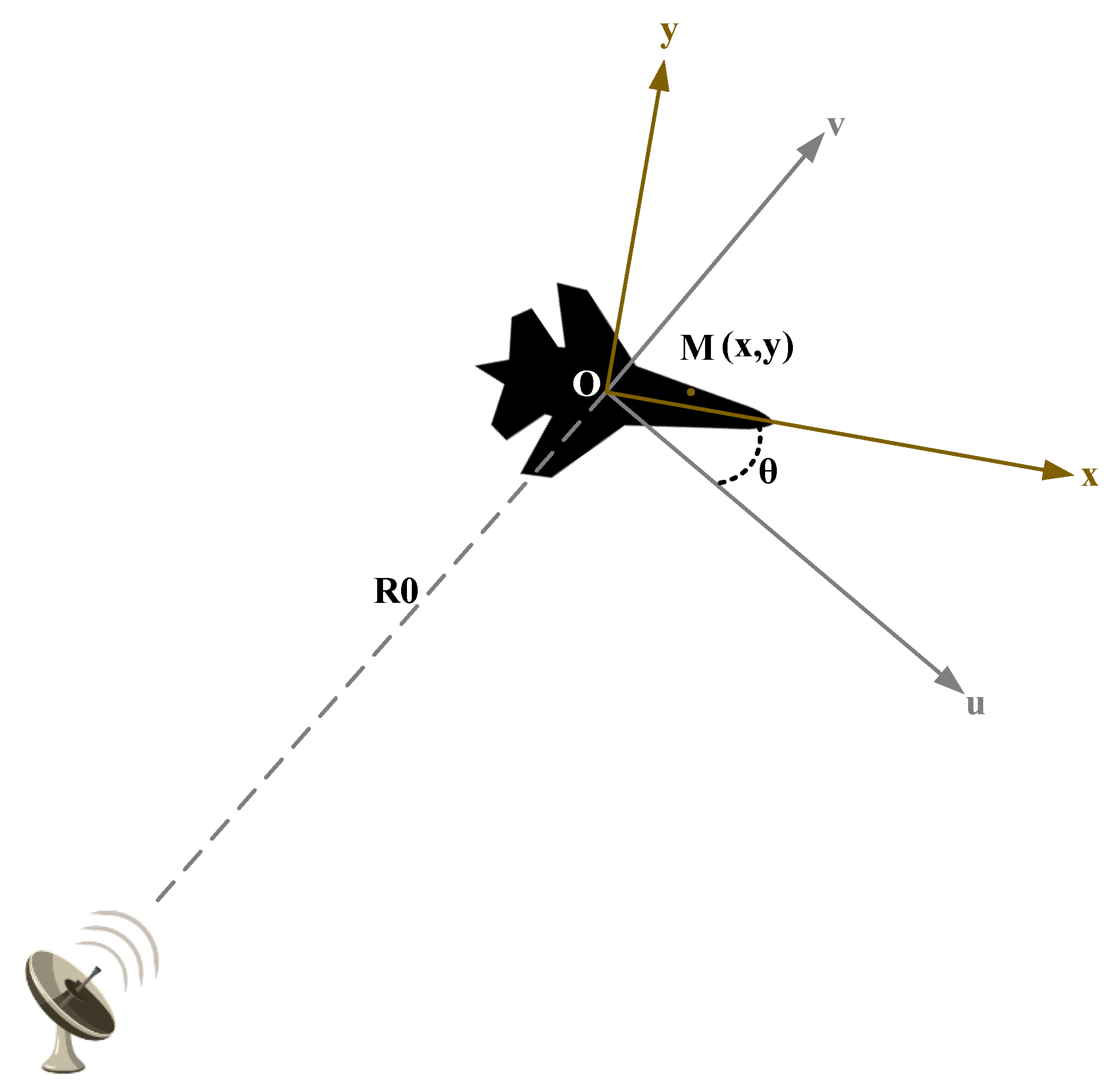
2. Turntable Model and the Imaging Principle
2.1. Two-Dimensional (2D) ISAR Imaging Turntable Model
2.2. RID Imaging Theorem
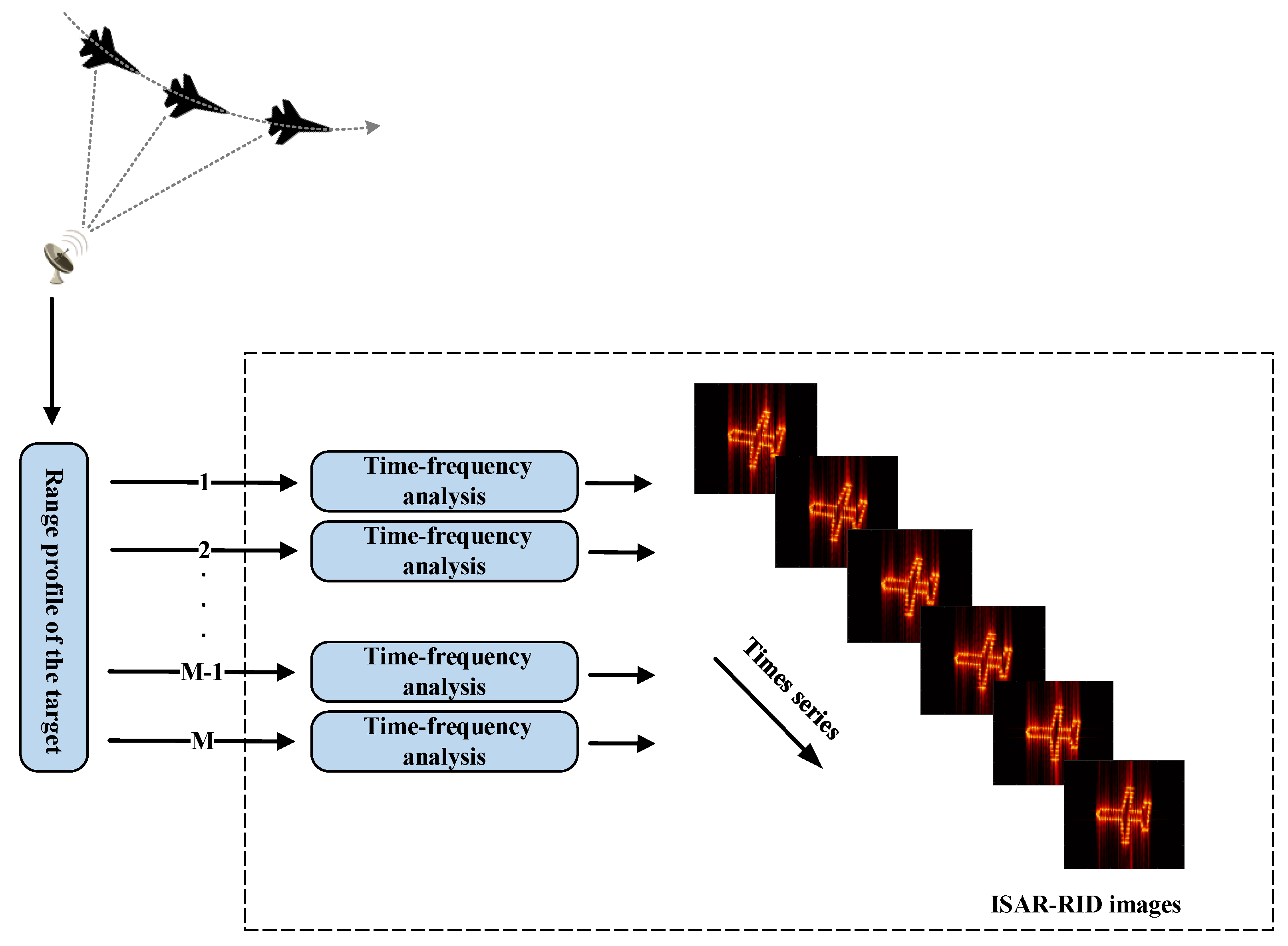
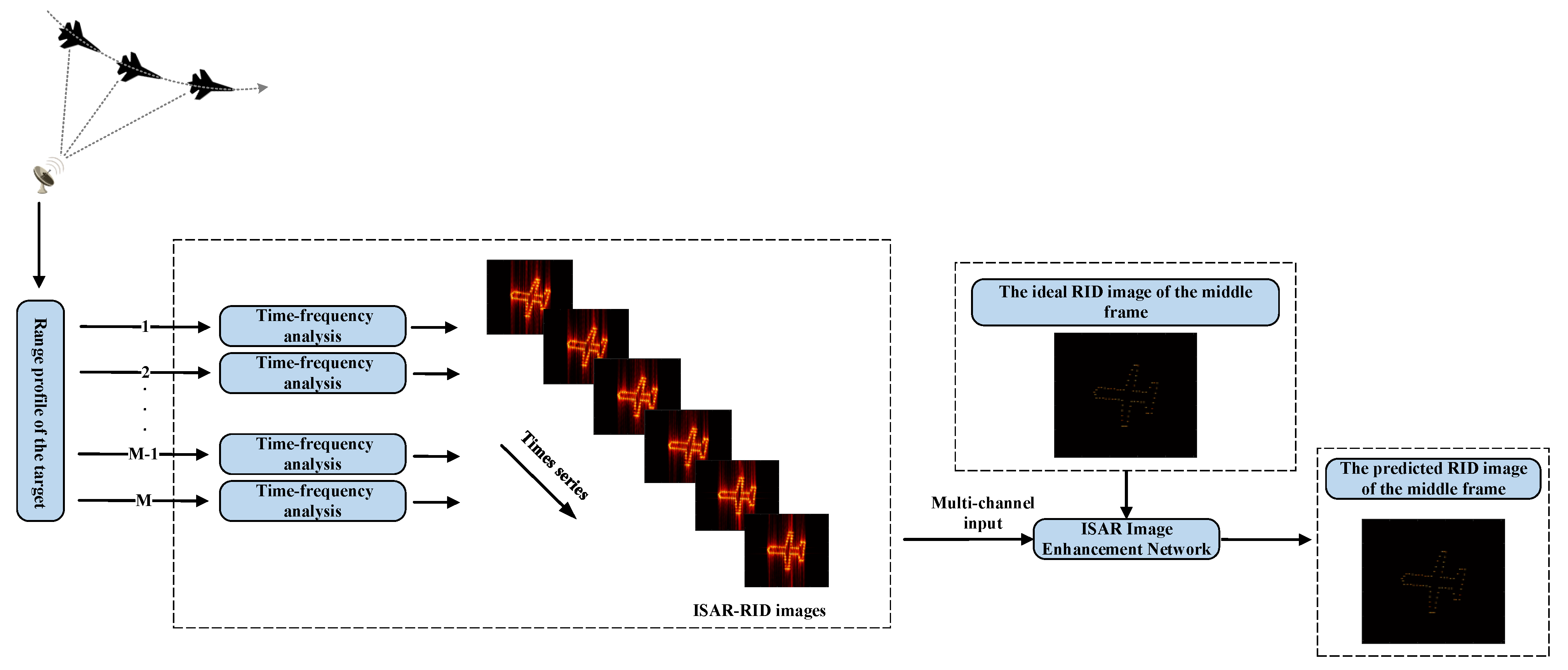
3. Method of ISAR Image Enhancement Using Neural Networks
3.1. Flow of RID Image Enhancement
3.2. Multi-Frame RID Network Structure
3.3. Generation of Sample-Label Pairs
3.4. Design of Non-Equilibrium Loss Function
3.5. Evaluation Indices
3.5.1. Mean Squared Error (MSE)
3.5.2. Peak Signal-to-Noise Ratio (PSNR)
3.5.3. Image Entropy
3.5.4. Contrast
4. Experimental Results
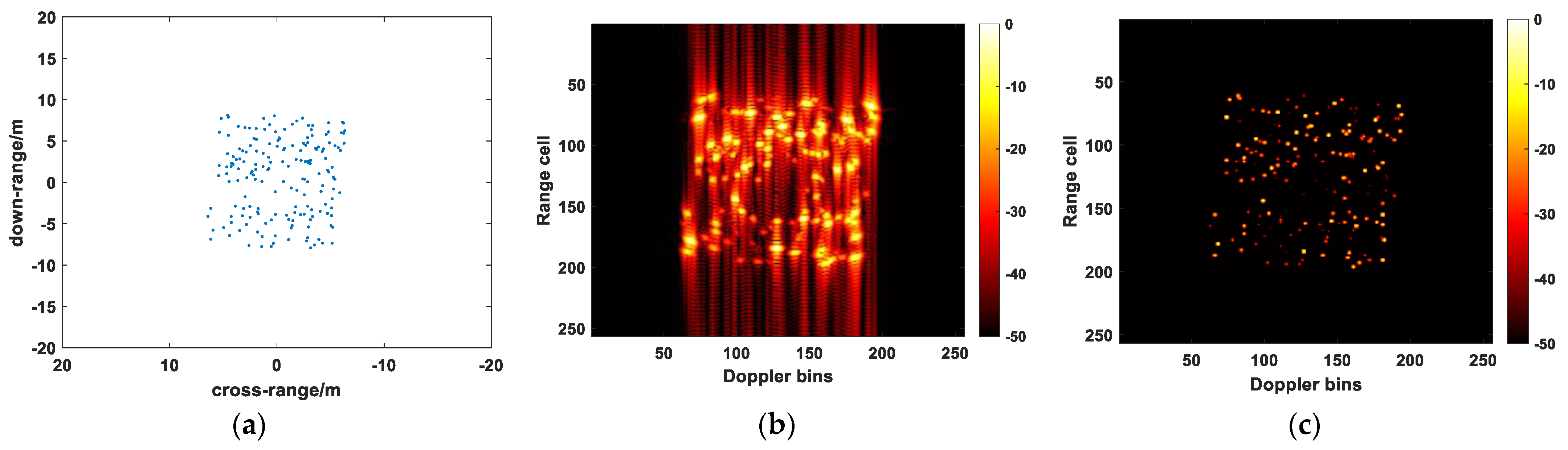
4.1. Predicted Results of Point Targets
4.2. Input Data Settings
4.3. Robustness Verification against Noise
4.4. Predicted Results of Full-Wave Simulated Data
4.4.1. Full Data Validation
4.4.2. Down-Sampled Data Validation
5. Discussion
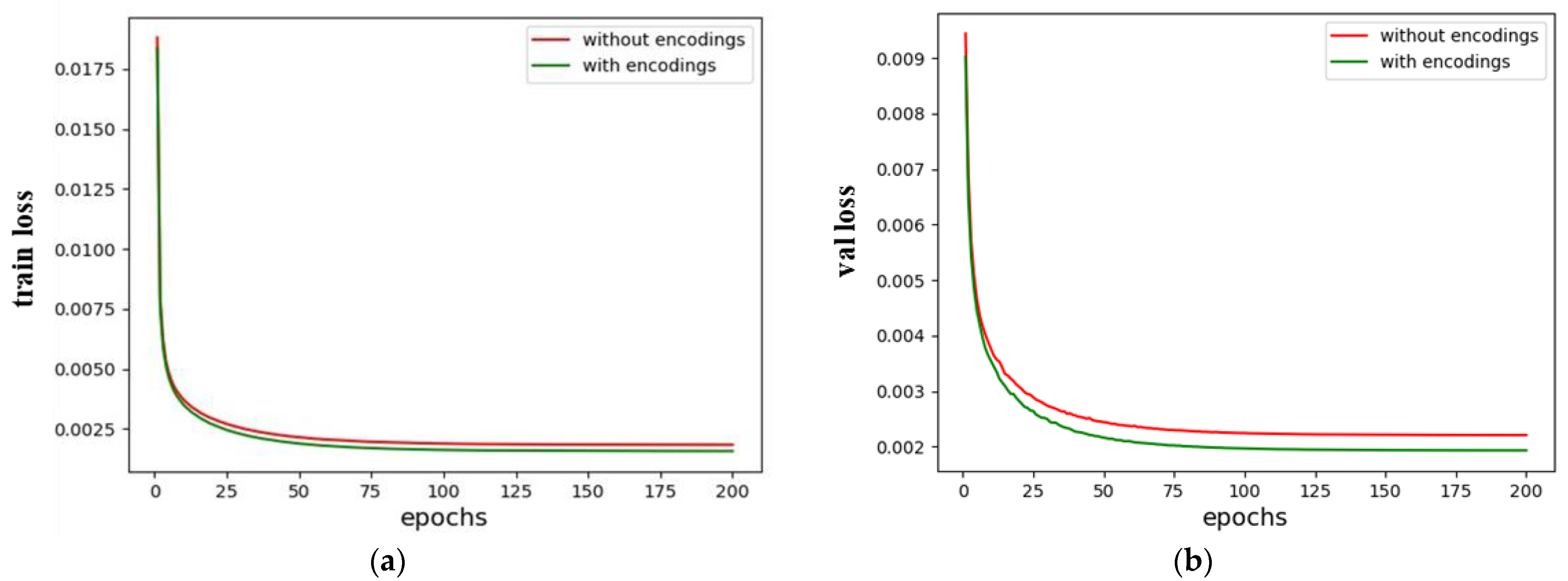
- The results shown in Figure 9 demonstrate the effectiveness of the positional encoding we proposed in our study. We independently train networks with and without positional encoding in Section 4.2, producing training and validation loss curves. During training, the network with positional encoding converges more quickly. The network displays lower loss values when its training stabilizes, and the validation set shows the same trend. This experimental finding suggests that positional encoding can be designed for the ISAR image-enhancement task in a way that effectively identifies the position of pixels based on the variable degrees of defocusing at various locations in ISAR images. This discovery significantly impacts our following study on the defocusing of ISAR;
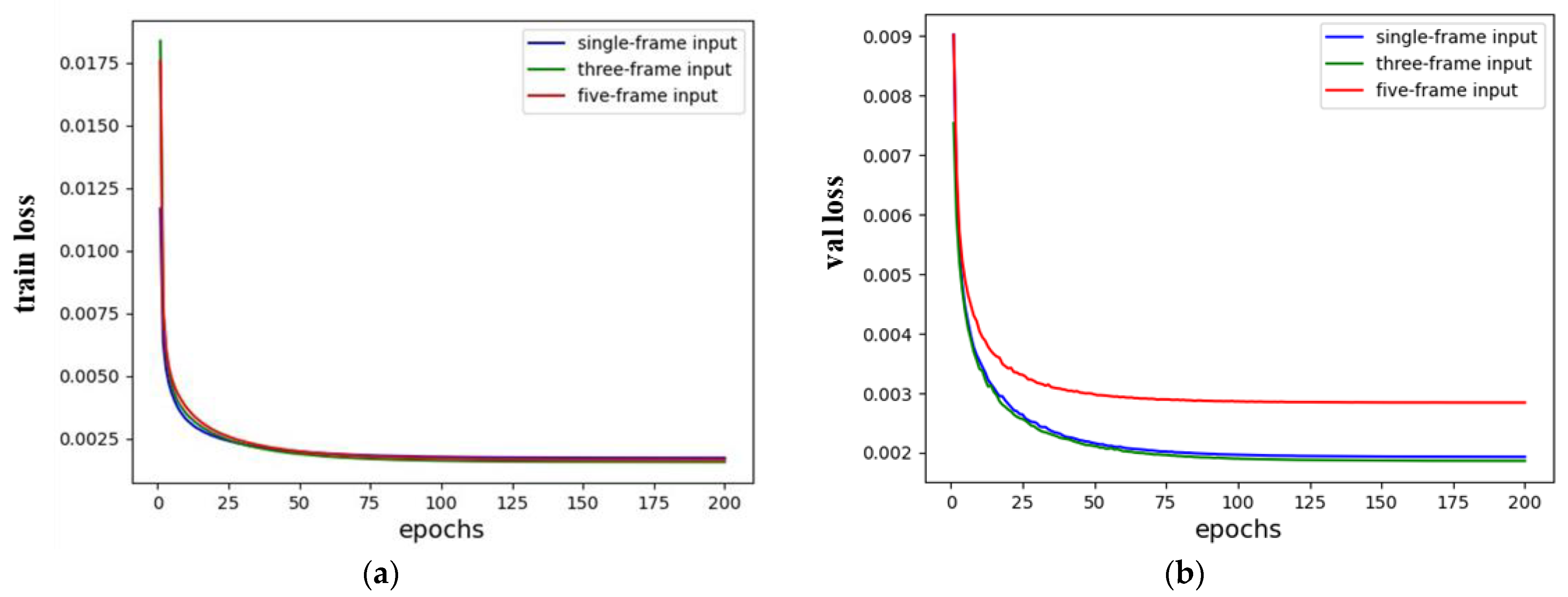
- Figure 10 demonstrates the benefits of using the three-frame input method suggested in this paper for our ISAR-RID image-enhancement task. This is explained by the fact that the multi-frame input approach, as opposed to the single-frame input method, gives the network more information about the target, allowing the network to understand the features of the target better. On the other hand, the five-frame input method introduces excessive redundant information relative to the three-frame input method, leading to the network’s inability to precisely learn the target’s features. Therefore, the three-frame input method is better suited to our task;
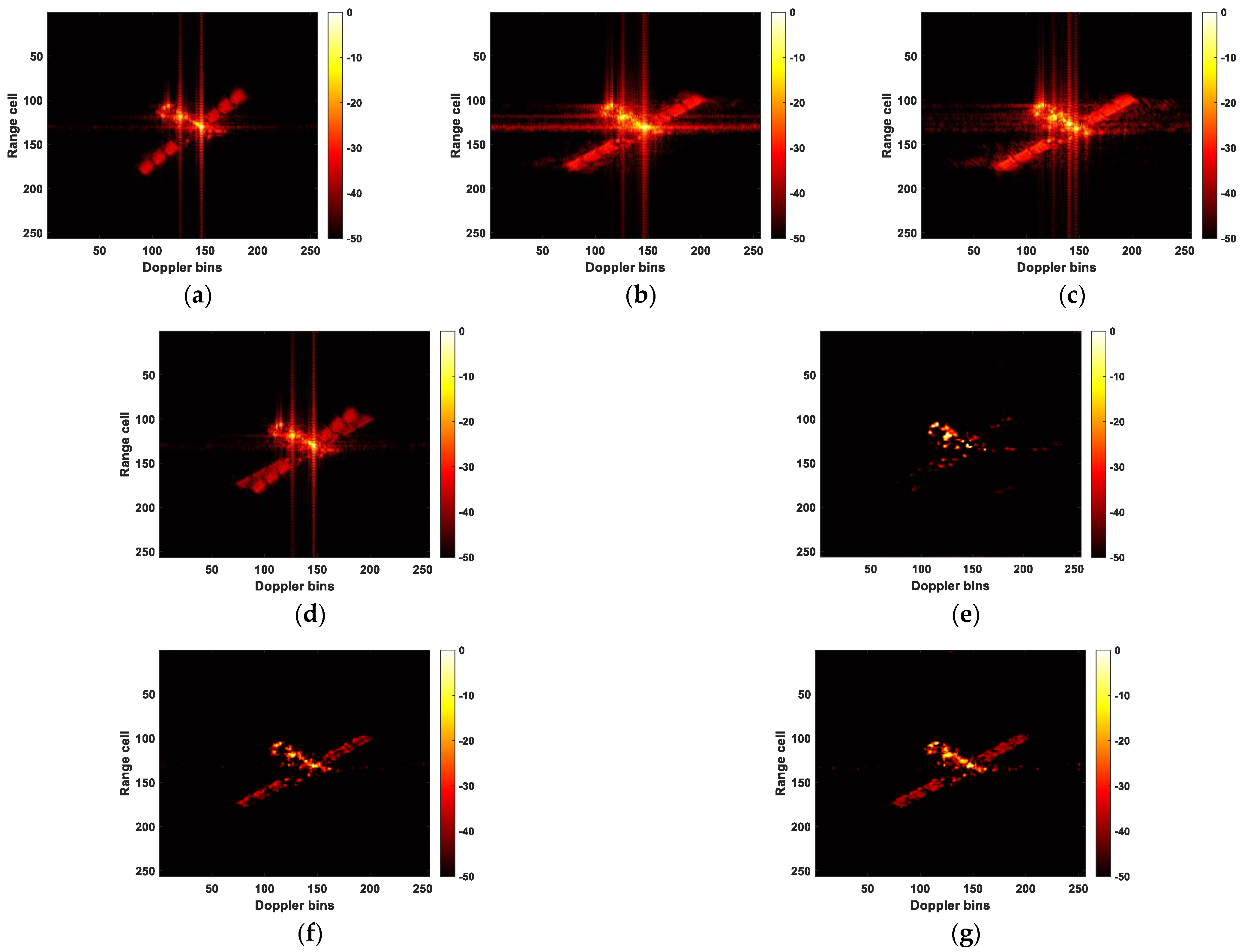
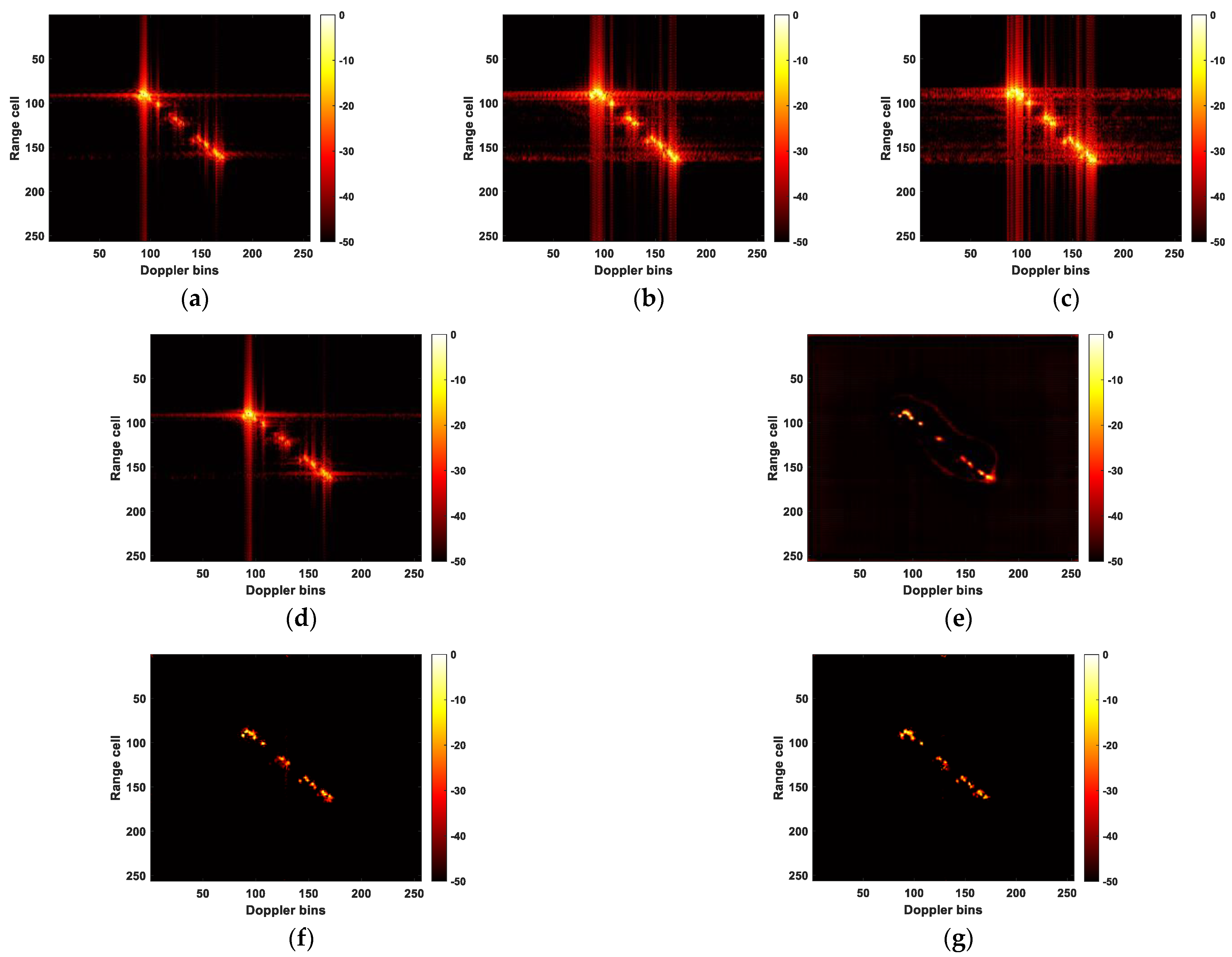
- The experimental results clearly show that the approach provided in this research works better than the one in [50]. Figure 8f exhibits significant noise interference and excessive enhancement of the target points, surpassing the pixel values in the ideal image. It is precisely because of the excessive enhancement of strong scattering points that U-NET performs the best in terms of entropy and contrast in Table 2. In Figure 12e, the target is incompletely recovered, while in Figure 13e, although the target is recovered, it lacks fine details. Moreover, noticeable noise interference is present around the target in Figure 13e. These three experiments collectively demonstrate that the proposed method, regardless of whether MSE or IMSE is used as the loss function during network training, achieves superior results in terms of target recovery and noise elimination compared to [50]. Thus, this also validates the effectiveness of the proposed three-frame RID image input method and position encoding. It is crucial to highlight that the U-Net exhibits the fastest runtime, more than twice as speedy as the other two methods. Furthermore, the MSE loss function is marginally quicker compared to the IMSE. This underscores that the proposed method comes at the expense of processing time, which is a challenge we must tackle in our future research endeavors;
- To address the characteristics of ISAR images, this paper proposes an improved loss function. By emphasizing the regression of pixel intensities within the target region during the training process, it overcomes the inherent limitations of the MSE loss function, which treats all pixels equally. This improvement ensures that the network focuses more effectively on the target itself rather than non-target areas. The resolution of the target in Figure 8h surpasses that in Figure 8g. Figure 12g recovers more target information compared to Figure 12f. There is slight clutter noise around the target in Figure 13f, resulting in a slightly inferior predictive performance compared to Figure 13g. These three experiments collectively highlight the significance of the proposed loss function in this paper, as it encourages the neural network to concentrate more on accurately estimating the target area within ISAR images. Certainly, as depicted in Table 2, the predictions produced by the proposed IMSE consistently outperform MSE in the initial four evaluation metrics: MSE, PSNR, Entropy, and Contrast. This further strengthens the evidence of its effectiveness as a loss function. However, it is worth noting that the use of IMSE does come with the trade-off of increased computational time. This is indeed a limitation of the method and is an issue that we need to address in our future work;
- The proposed method demonstrates a certain level of robustness to noise and incomplete data. As demonstrated in Figure 11 and Figure 14, within a certain range of noise and down-sampling conditions, the trained network is still capable of accurately predicting ISAR images. Specifically, in the robustness test against noise, our network is trained on samples without noise. However, it achieved accurate and high-resolution predictions at SNRs of −10 dB and −20 dB. Even at −30 dB, although the predicted image contains noise, the target’s contour is still clearly discernible. For the robustness experiment against incomplete data, we separately use the network trained on the full dataset and the network trained on the dataset down-sampled at 5% to predict data down-sampled at different rates. It can be observed that both networks exhibit a certain level of robustness. However, the network trained on the down-sampled data yields slightly better-predicted results. This finding suggests that using training data specific to different scenarios or imaging conditions can improve the network’s prediction performance and make it more practical.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yang, S.; Li, S.; Jia, X.; Cai, Y.; Liu, Y. An Efficient Translational Motion Compensation Approach for ISAR Imaging of Rapidly Spinning Targets. Remote Sens. 2022, 14, 2208. [Google Scholar] [CrossRef]
- Zhu, X.; Jiang, Y.; Liu, Z.; Chen, R.; Qi, X. A Novel ISAR Imaging Algorithm for Maneuvering Targets. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Liu, F.; Huang, D.; Guo, X.; Feng, C. Unambiguous ISAR Imaging Method for Complex Maneuvering Group Targets. Remote Sens. 2022, 14, 2554. [Google Scholar] [CrossRef]
- Yang, Z.; Li, D.; Tan, X.; Liu, H.; Liao, G. An Efficient ISAR Imaging Approach for Highly Maneuvering Targets Based on Subarray Averaging and Image Entropy. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Huang, P.; Xia, X.G.; Zhan, M.; Liu, X.; Jiang, X. ISAR Imaging of a Maneuvering Target Based on Parameter Estimation of Multicomponent Cubic Phase Signals. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Jiang, Y.; Sun, S.; Yuan, Y.; Yeo, T. Three-dimensional aircraft isar imaging based on shipborne radar. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 2504–2518. [Google Scholar] [CrossRef]
- Yang, Z.; Li, D.; Tan, X.; Liu, H.; Liu, Y.; Liao, G. ISAR Imaging for Maneuvering Targets with Complex Motion Based on Generalized Radon-Fourier Transform and Gradient-Based Descent under Low SNR. Remote Sens. 2021, 13, 2198. [Google Scholar] [CrossRef]
- Wang, T.; Wang, X.; Chang, Y.; Liu, J.; Xiao, S. Estimation of Precession Parameters and Generation of ISAR Images of Ballistic Missile Targets. IEEE Trans. Aerosp. Electron. Syst. 2010, 46, 1983–1995. [Google Scholar] [CrossRef]
- Jin, X.; Su, F.; Li, H.; Xu, Z.; Deng, J. Automatic ISAR Ship Detection Using Triangle-Points Affine Transform Reconstruction Algorithm. Remote Sens. 2023, 15, 2507. [Google Scholar] [CrossRef]
- Maki, A.; Fukui, K. Ship identification in sequential ISAR imagery. Mach. Vis. Appl. 2004, 15, 149–155. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, Y.; Ding, W. A Fast Recognition Method for Space Targets in ISAR Images Based on Local and Global Structural Fusion Features with Lower Dimensions. Int. J. Aerosp. Eng. 2020, 2020, 3412582. [Google Scholar] [CrossRef]
- Pui, C.Y.; Ng, B.; Rosenberg, L.; Cao, T.-T. 3D-ISAR for an Along Track Airborne Radar. IEEE Trans. Aerosp. Electron. Syst. 2021, 58, 2673–2686. [Google Scholar] [CrossRef]
- Ni, P.; Liu, Y.; Pei, H.; Du, H.; Li, H.; Xu, G. CLISAR-Net: A Deformation-Robust ISAR Image Classification Network Using Contrastive Learning. Remote Sens. 2022, 15, 33. [Google Scholar] [CrossRef]
- Lee, S.J.; Lee, M.J.; Kim, K.T.; Bae, J.H. Classification of ISAR Images Using Variable Cross-Range Resolutions. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 2291–2303. [Google Scholar] [CrossRef]
- Walker, J.L. Range-Doppler Imaging of Rotating Objects. IEEE Trans. Aerosp. Electron. Syst. 1980, 16, 23–52. [Google Scholar] [CrossRef]
- Hu, R.; Rao, B.S.M.R.; Alaee-Kerahroodi, M.; Ottersten, B. Orthorectified Polar Format Algorithm for Generalized Spotlight SAR Imaging with DEM. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3999–4007. [Google Scholar] [CrossRef]
- Jiang, J.; Li, Y.; Yuan, Y.; Zhu, Y. Generalized Persistent Polar Format Algorithm for Fast Imaging of Airborne Video SAR. Remote Sens. 2023, 15, 2807. [Google Scholar] [CrossRef]
- Sun, C.; Wang, B.; Fang, Y.; Yang, K.; Song, Z. High-resolution ISAR imaging of maneuvering targets based on sparse reconstruction. Signal Process. 2015, 108, 535–548. [Google Scholar] [CrossRef]
- Giusti, E.; Cataldo, D.; Bacci, A.; Tomei, S.; Martorella, M. ISAR Image Resolution Enhancement: Compressive Sensing Versus State-of-the-Art Super-Resolution Techniques. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 1983–1997. [Google Scholar] [CrossRef]
- Zheng, B.; Wei, Y. Improvements of autofocusing techniques for ISAR motion compensation. Acta Electron. Sin. 1996, 24, 74–79. [Google Scholar]
- Sun, S.; Liang, G. ISAR imaging of complex motion targets based on Radon transform cubic chirplet decomposition. Int. J. Remote Sens. 2018, 39, 1770–1781. [Google Scholar] [CrossRef]
- Kang, M.S.; Lee, S.H.; Kim, K.T.; Bae, J.H. Bistatic ISAR Imaging and Scaling of Highly Maneuvering Target with Complex Motion via Compressive Sensing. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 2809–2826. [Google Scholar] [CrossRef]
- Xia, X.G.; Wang, G.; Chen, V.C. Quantitative SNR analysis for ISAR imaging using joint time-frequency analysis-Short time Fourier transform. IEEE Trans. Aerosp. Electron. Syst. 2002, 38, 649–659. [Google Scholar] [CrossRef]
- Peng, Y.; Ding, Y.; Zhang, J.; Jin, B.; Chen, Y. Target Trajectory Estimation Algorithm Based on Time–Frequency Enhancement. IEEE Trans. Instrum. Meas. 2023, 72, 1–7. [Google Scholar] [CrossRef]
- Xing, M.; Wu, R.; Li, Y.; Bao, Z. New ISAR imaging algorithm based on modified Wigner-Ville distribution. IET Radar Sonar Navig. 2008, 3, 70–80. [Google Scholar] [CrossRef]
- Huang, P.; Liao, G.; Yang, Z.; Xia, X.; Ma, J.; Zhang, X. A Fast SAR Imaging Method for Ground Moving Target Using a Second-Order WVD Transform. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1940–1956. [Google Scholar] [CrossRef]
- Ryu, B.-H.; Lee, I.-H.; Kang, B.-S.; Kim, K.-T. Frame Selection Method for ISAR Imaging of 3-D Rotating Target Based on Time–Frequency Analysis and Radon Transform. IEEE Sens. J. 2022, 22, 19953–19964. [Google Scholar] [CrossRef]
- Shi, S.; Shui, P. Sea-Surface Floating Small Target Detection by One-Class Classifier in Time-Frequency Feature Space. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6395–6411. [Google Scholar] [CrossRef]
- Berizzi, F.; Mese, E.D.; Diani, M.; Martorella, M. High-resolution ISAR imaging of maneuvering targets by means of the range instantaneous Doppler technique: Modeling and performance analysis. IEEE Trans. Image Process. 2001, 10, 1880–1890. [Google Scholar] [CrossRef]
- Kamble, A.; Ghare, P.H.; Kumar, V. Deep-Learning-Based BCI for Automatic Imagined Speech Recognition Using SPWVD. IEEE Trans. Instrum. Meas. 2023, 72, 1–10. [Google Scholar] [CrossRef]
- Tani, L.F.K.; Ghomari, A.; Tani, M.Y.K. Events Recognition for a Semi-Automatic Annotation of Soccer Videos: A Study Based Deep Learning. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 135–141. [Google Scholar] [CrossRef]
- Li, Y.; Fan, B.; Zhang, W.; Ding, W.; Yin, J. Deep Active Learning for Object Detection. Inform. Sci. 2021, 579, 418–433. [Google Scholar] [CrossRef]
- Chen, Y.; Butler, S.; Xing, L.; Han, B.; Bagshaw, H.P. Patient-Specific Auto-Segmentation of Target and OARs via Deep Learning on Daily Fan-Beam CT for Adaptive Prostate Radiotherapy. Int. J. Radiat. Oncol. Biol. Phys. 2022, 114, e553–e554. [Google Scholar] [CrossRef]
- Sun, W.; Zhou, S.; Yang, J.; Gao, X.; Ji, J.; Dong, C. Artificial Intelligence Forecasting of Marine Heatwaves in the South China Sea Using a Combined U-Net and ConvLSTM System. Remote Sens. 2023, 15, 4068. [Google Scholar] [CrossRef]
- Bethel, B.J.; Sun, W.; Dong, C.; Wang, D. Forecasting hurricane-forced significant wave heights using a long short-term memory network in the Caribbean Sea. Ocean Sci. 2022, 18, 419–436. [Google Scholar] [CrossRef]
- Zhou, S.; Xie, W.; Lu, Y.; Wang, Y.; Zhou, Y.; Hui, N.; Dong, C.; Dong, C. ConvLSTM-Based Wave Forecasts in the South and East China Seas. Front. Mar. Sci. 2021, 8, 680079. [Google Scholar] [CrossRef]
- Han, L.; Ji, Q.; Jia, X.; Liu, Y.; Han, G.; Lin, X. Significant Wave Height Prediction in the South China Sea Based on the ConvLSTM Algorithm. J. Mar. Sci. Eng. 2022, 10, 1683. [Google Scholar] [CrossRef]
- Cen, H.; Jiang, J.; Han, G.; Lin, X.; Liu, Y.; Jia, X.; Ji, Q.; Li, B. Applying Deep Learning in the Prediction of Chlorophyll-a in the East China Sea. Remote Sens. 2022, 14, 5461. [Google Scholar] [CrossRef]
- Xu, G.; Xu, G.; Xu, G.; Xie, W.; Xie, W.; Dong, C.; Dong, C.; Dong, C.; Gao, X.; Gao, X. Application of Three Deep Learning Schemes Into Oceanic Eddy Detection. Front. Mar. Sci. 2021, 8, 672334. [Google Scholar] [CrossRef]
- Qin, D.; Gao, X. Enhancing ISAR Resolution by a Generative Adversarial Network. IEEE Geosci. Remote Sens. Lett. 2021, 18, 127–131. [Google Scholar] [CrossRef]
- Wang, H.; Li, K.; Lu, X.; Zhang, Q.; Luo, Y.; Kang, L. ISAR Resolution Enhancement Method Exploiting Generative Adversarial Network. Remote Sens. 2022, 14, 1291. [Google Scholar] [CrossRef]
- Hu, C.; Wang, L.; Li, Z.; Loffeld, O. A Novel Inverse Synthetic Aperture Radar Imaging Method Using Convolutional Neural Networks. In Proceedings of the 2018 5th International Workshop on Compressed Sensing Applied to Radar, Multimodal Sensing, and Imaging (CoSeRa), Siegen, Germany, 10–13 September 2018. [Google Scholar]
- Li, X.; Bai, X.; Zhou, F. High-Resolution ISAR Imaging and Autofocusing via 2D-ADMM-Net. Remote Sens. 2021, 13, 2326. [Google Scholar] [CrossRef]
- Li, X.; Bai, X.; Zhang, Y.; Zhou, F. High-Resolution ISAR Imaging Based on Plug-and-Play 2D ADMM-Net. Remote Sens. 2022, 14, 901. [Google Scholar] [CrossRef]
- Huang, X.; Ding, J.; Xu, Z. Real-Time Super-Resolution ISAR Imaging Using Unsupervised Learning. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Yuan, H.; Li, H.; Zhang, Y.; Wang, Y.; Liu, Z.; Wei, C.; Yao, C. High-Resolution Refocusing for Defocused ISAR Images by Complex-Valued Pix2pixHD Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Qian, J.; Huang, S.; Wang, L.; Bi, G.; Yang, X. Super-Resolution ISAR Imaging for Maneuvering Target Based on Deep-Learning-Assisted Time-Frequency Analysis. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Wei, S.; Liang, J.; Wang, M.; Shi, J.; Zhang, X.; Ran, J. AF-AMPNet: A Deep Learning Approach for Sparse Aperture ISAR Imaging and Autofocusing. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Li, R.; Zhang, S.; Zhang, C.; Liu, Y.; Li, X. Deep Learning Approach for Sparse Aperture ISAR Imaging and Autofocusing Based on Complex-Valued ADMM-Net. IEEE Sens. J. 2021, 21, 3437–3451. [Google Scholar] [CrossRef]
- Li, W.; Li, K.; Kang, L.; Luo, Y. Wide-Angle ISAR Imaging Based on U-net Convolutional Neural Network. J. Air Force Eng. Univ. 2022, 23, 28–35. [Google Scholar]
- Shi, H.; Liu, Y.; Guo, J.; Liu, M. ISAR autofocus imaging algorithm for maneuvering targets based on deep learning and keystone transform. J. Syst. Eng. Electron. 2020, 31, 1178–1185. [Google Scholar]
- Munoz-Ferreras, J.M.; Perez-Martinez, F. On the Doppler Spreading Effect for the Range-Instantaneous-Doppler Technique in Inverse Synthetic Aperture Radar Imagery. IEEE Geosci. Remote Sens. Lett. 2010, 7, 180–184. [Google Scholar] [CrossRef]
- Chen, V.C.; Miceli, W.J. Time-varying spectral analysis for radar imaging of manoeuvring targets. IEE Proc. Radar. Son. Nav. 1998, 145, 262–268. [Google Scholar] [CrossRef]
- Liu, S.; Cao, Y.; Yeo, T.-S.; Wu, W.; Liu, Y. Adaptive Clutter Suppression in Randomized Stepped-Frequency Radar. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 1317–1333. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. Facebook AI Res. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- The Communist Youth League of China; China Association for Science and Technology; Ministry of Education of the People’s Republic of China; Chinese Academy of Social Sciences; All-China Students’ Federation. “Challenge Cup” National Science and Technology College of Extra-Curricular Academic Competition Work. 8 June 2023. Available online: https://www.tiaozhanbei.net/ (accessed on 19 October 2023).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Number of Channels | Kernel Size | Number of Kernels |
|---|---|---|---|
| Conv_1_ReLU | 10 | 9 × 9 | 60 |
| Conv_2_ReLU | 64 | 3 × 3 | 124 |
| Conv_3_ReLU | 128 | 3 × 3 | 252 |
| Conv_4_ReLU | 256 | 3 × 3 | 124 |
| Conv_5_ReLU | 128 | 3 × 3 | 60 |
| Conv_6 | 64 | 5 × 5 | 1 |
| Loss Function | MSE | PSNR | Entropy | Contrast | Runtime |
|---|---|---|---|---|---|
| MSE | 0.0035 | 24.3612 | 36.5252 | 3.7185 | 0.4738 |
| IMSE (proposed) | 0.0019 | 27.1167 | 25.3929 | 6.7649 | 0.4799 |
| U-Net | 0.0049 | 23.0684 | 11.5343 | 11.4111 | 0.1940 |
| SNR (dB) | MSE | PSNR (dB) |
|---|---|---|
| No noise | 0.0019 | 27.1167 |
| −10 | 0.0019 | 27.1167 |
| −20 | 0.0022 | 26.5856 |
| −30 | 0.0025 | 26.1045 |
| −40 | 0.0032 | 24.9574 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Dai, Y.; Song, S.; Jin, T.; Huang, X. Deep Learning-Based Enhanced ISAR-RID Imaging Method. Remote Sens. 2023, 15, 5166. https://doi.org/10.3390/rs15215166
Wang X, Dai Y, Song S, Jin T, Huang X. Deep Learning-Based Enhanced ISAR-RID Imaging Method. Remote Sensing. 2023; 15(21):5166. https://doi.org/10.3390/rs15215166
Chicago/Turabian StyleWang, Xiurong, Yongpeng Dai, Shaoqiu Song, Tian Jin, and Xiaotao Huang. 2023. "Deep Learning-Based Enhanced ISAR-RID Imaging Method" Remote Sensing 15, no. 21: 5166. https://doi.org/10.3390/rs15215166
APA StyleWang, X., Dai, Y., Song, S., Jin, T., & Huang, X. (2023). Deep Learning-Based Enhanced ISAR-RID Imaging Method. Remote Sensing, 15(21), 5166. https://doi.org/10.3390/rs15215166