Abstract
We propose a mathematical study of the statistics of chlorophyll fluorescence indices. While most of the literature assumes Gaussian distributions for these indices, we demonstrate their fundamental non-Gaussian nature. Indeed, while the noise in the raw fluorescence images can be assumed as Gaussian additive, the deterministic ratio between them produces nonlinear non-Gaussian distributions. We investigate the states in which this non-Gaussianity can affect the statistical estimation when wrongly approached with linear estimators. We provide an expectation–maximization estimator adapted to the non-Gaussian distributions. We illustrate the interest of this estimator with simulations from images of chlorophyll fluorescence indices.. We demonstrate the benefits of our approach by comparison with the standard Gaussian assumption. Our expectation–maximization estimator shows low estimation errors reaching seven percent for a more pronounced deviation from Gaussianity compared to Gaussianity assumptions estimators rising to more than 70 percent estimation error. These results show the importance of considering rigorous mathematical estimation approaches in chlorophyll fluorescence indices. The application of this work could be extended to various vegetation indices also made up of a ratio of Gaussian distributions.
1. Introduction
Chlorophyll fluorescence imaging is a well-established imaging technique for plant phenotyping [1,2,3,4,5,6]. In this imaging technique, flashes of light are sent onto leaves and the resulting emitted fluorescence is captured with grayscaled images. Images acquired during the illumination protocols are then combined to provide chlorophyll fluorescence indices. These indices are directly related to the availability of electrons in the tissue and therefore are related to their chemical content and indirectly also to the physiology of the tissue at the time of the acquisition. Chlorophyll fluorescence imaging has been widely reported to monitor plant growth and response to stress [5]. While used already, investigations on chlorophyll fluorescence continue to be extended in various directions including the search for new sequences of illumination protocols [7], the physiological interpretation of image signature [8], the genetic determinism associated with chlorophyll fluorescence signals [9,10] or the fundamental biomolecular mechanisms at work [9,11]. We position this article in this trend of further investigations of chlorophyll fluorescence but here at the level of the mathematical modeling of the statistics observed in chlorophyll fluorescence indices.
Chlorophyll fluorescence indices are mainly built with differences and ratios of images which are basically corrupted with various amounts of Gaussian additive noise. The nonlinear derministic combination of these images trivially produces images with non-Gaussian noise. An estimation of the distribution of gray levels in the resulting indices is then performed. Surprisingly, the non-Gaussianity of the chlorophyll fluorescence indices has only recently been highlighted empirically [12]. In most of the literature, Gaussianity is assumed, and therefore, one resorts to the linear associated estimators of average and standard deviation to characterize the chlorophyll fluorescence indices [13,14,15,16,17,18,19,20,21,22,23,24,25,26]. This assumption may not be an issue for the phenotyping situations considered in the literature where a measure of a biomarker is not the aim but rather a difference between a reference (genotype or control conditions) and another plant (other genotype or various stress conditions). From a methodological and mathematical point of view, it is not rigorous to systematically have this Gaussian assumption since the possible negative impact on the estimation of chlorophyll fluorescence distribution parameters is not known.
In this article, we further investigate this non-Gaussianity mathematically. We demonstrate the states where Gaussianity assumptions can be made, and we design appropriate statistical estimators of generic value in the Gaussian and non-Gaussian cases. We illustrate the advantages of our approach using simulations and on images of chlorophyll fluorescence indices.
The paper is organized as follows. We describe the empirical data sets of chlorophyll fluorescence images of diseased plants (Section 2). From the statistical analysis of these data sets, we then propose a statistical model for chlorophyll fluorescence indices (Section 3). We derive two Bayesian estimators of the resulting non-Gaussian distributions. The performance of these estimators is compared with the standard Gaussian approximation on synthetic data simulating the empirical data set (Section 4). We conclude with the importance of considering the non-Gaussianity of chlorophyll fluorescence indices. We provide mathematical proofs of the properties related to the various expressions in the Appendix A.
2. Material
2.1. Arabidopsis thaliana Inoculated by a Bacteria
We consider chlorophyll fluorescence imaging on rosettes of Arabidopsis thaliana ecotype Col0. The experiment consisted of 36 pots of four plants each. Half of the pots were inoculated with water, and the other half with the virulent DC300, a tomato bacteria. We attribute ‘Healthy’ to the pots inoculated with water and ‘Diseased’ to the ones with the bacteria. Chlorophyll fluorescence imaging was realized during six days of the experiment: D0, D2, D5, D6, D7, and D8. The same data set was used for automated disease segmentation [13,27]. A full description of the experiment is in these two papers. We got interested in , the fluorescence after saturating actinic flash, and , the basal fluorescence before the flash. To build a statistical model of and we manually selected areas located in the limb of the leaves as illustrated in Figure 1. The physical interpretation of the distribution observed is the thermal noise of the camera, which is expected to be Gaussian with an additive coupling.
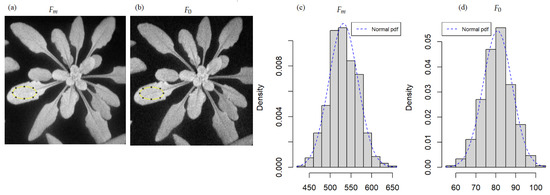
Figure 1.
Example of chlorophyll fluorescence images of Arabidopsis thaliana inoculated by a bacteria, at day 2, pot 19, a healthy pot (inoculated with water): (a) maximum fluorescence and (b) minimum fluorescence. The histograms (c,d) are the associated frequency distribution of pixel counts inside the region of interest drawn in a solid yellow line in (a,b), respectively. The dashed blue line in the histograms is the fit with a normal probability density function (pdf).
Therefore, we verified the adequacy of and to a normal distribution with the D’Agostino test [28]. We chose the D’Agostino test among other normality tests since it is the recommended test in case of the presence of ex-aequo in the variable. It’s our case with the number of pixels data. We sample four pots from Healthy and Diseased for each day of the experiment, and we select areas located in the limb of the leaves as illustrated in Figure 1. Table 1 shows the mean and the standard deviation of these four p-values associated with the D’Agostino test of normality on the resulting pixel counts of the selections. From Table 1, all p-values are higher than 0.05. Consequently, we do not reject the null hypothesis that and follow a normal distribution in either healthy or diseased tissues. We extracted the mean and the standard deviation of healthy and diseased pixels from and parameters for the six days of the experiment. The results are in Table 2. It is noticeable that the standard deviation of the Gaussian distribution is relatively stable for healthy and diseased plants over the experiment. This observation is compatible with the interpretation of randomness due mainly to the stationary thermal noise of the camera.

Table 1.
Mean ± the standard deviation of four p-values associated with the D’Agostino test of normality in the limb of the Arabidopsis thaliana inoculated by a bacteria for maximum fluorescence and minimum fluorescence. D0, …, and D8 are the six days of the acquisition of chlorophyll fluorescence images.
Table 2.
Mean , and standard deviation, , values on Healthy and Diseased tissues of chlorophyll fluorescence parameters (minimum fluorescence) and (maximum fluorescence) for images of plants inoculated with bacteria. D0, …, and D8 are the six days of the acquisition of chlorophyll fluorescence images.
2.2. Arabidopsis thaliana Infected with a Fungal Pathogen
We considered a second study aiming to score the development of fungal pathogen symptoms (Botrytis cinerea) on the Arabidopsis thaliana plant [12]. This is currently the only public data set on chlorophyll fluorescence imaging with diseased plants that we found. The data set can be found in [29]. It is composed of chlorophyll fluorescences images and RGB images acquired during 96 h post-infection at 0 h, 24 h, 72 h, and 98 h. After checking successfully (not shown) the Gaussianity of the distribution of gray levels in limbs of and images, we computed like for the previous data set the mean and standard deviation associated. The value obtained is provided in Table 3. Here again, one can notice that the standard deviation of the Gaussian distribution is relatively stable over the experiment but only for the healthy plants. For this fungal disease, spores progressively appear at the surface of the leaves. These spores act as a multiplicative filter that absorbs the incident light. The emergence of these spores may add another source of randomness here.
Table 3.
Mean , and standard deviation, , values on Healthy and Diseased tissues of chlorophyll fluorescence parameters (minimum fluorescence) and (maximum fluorescence) for the data set of plants infected with fungal pathogen data. 0 h, …, 96 h are the five times of the acquisition of chlorophyll fluorescence images.
In the following sections, we will refer to the bacteria data set, the chlorophyll fluorescence images associated with the Arabidopsis thaliana inoculated by a bacteria and by fungal pathogen data set, the chlorophyll fluorescence images of the Arabidopsis thaliana infected with a fungal pathogen.
3. Methods
3.1. Statistical Model of Fv/Fm
In the chlorophyll fluorescence imaging technique, the raw images and are not directly used [30,31]. Instead, they are combined to produce some indices, which serve as a biomarker. We focus on the most common of these indices, known as the maximum quantum yield of photosystem II (PSII) [32]:
This ratio is an indicator of plant stress and is among the most used chlorophyll fluorescence parameter. It serves as a biomarker to assess the normal or abnormal photosynthetic activity of plant tissue with a threshold applied to the distributions. The choice of this parameter is made without loss of generality as all of the indices in chlorophyll fluorescence are based on ratios of images with variations concerning the timing of the flash of light and the wavelength.
We have shown that both and can be modeled as Gaussian distribution in the previous section.
Since the Gaussian distribution is alpha-stable, the difference between the two Gaussian distributions is known to be a Gaussian distribution. Consequently, the distribution of can be modeled in the following way. Let us consider the variables X and Y as and , respectively, where X and Y are two identical and independent normal distributions:
The probability density function, , of the ratio is given by [33,34]:
with ; ; ; , and .
We can write this otherwise using the confluent hypergeometric function, [35]:
with , the confluent hypergeometric function, also known as Kummer’s function and defined as follow:
where the Pochhammer symbol indicates the nth rising factorial of a, i.e.,
If , . The demonstration of the second form of the given by Equation (3) is presented in Appendix A.1.
An approximation of the distribution of Z by a normal distribution has been proposed by [34]. Most authors defined conditions on the parameters, , and resulting from empirical or simulation works and showed the switch from a normal distribution to a bimodal distribution under certain values [36,37,38]. This is illustrated with simulation for different values of , and in Figure 2. We draw the distribution of the ratio for three different values of the parameters and we add the normal approximation proposed by [34].
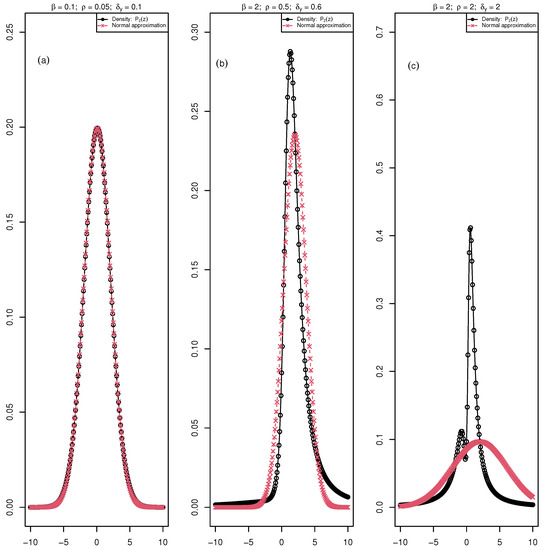
Figure 2.
The black curve with circle points is the distribution of the ratio ( maximum fluorescence and , minimum fluorescence) for an increasing values of the parameters, , , and and the red curve with crossed points is the normal approximation of the distribution in each of these cases. (a) A case with perfect fit of the ratio density and the normal approximation; (b) a deviation from normal distribution; (c) a case where the ratio density is bimodal and the normal approximation is not appropriate.
In the first case (, , ), we see a perfect fit of the normal approximation. In the second case (, , ), we start to see the deviation from normality, whereas for (, , ), the distribution of the ratio is bimodal. Therefore, supposing a normal distribution of will be more or less wrong depending on the values of , , and .
There is not a sufficient amount of public sets of chlorophyll fluorescence images to determine if the normal assumption can always be done in estimation of statistical parameters. Therefore, it is necessary to design estimators adapted for the non-Gaussianity of Z in general.
3.2. Estimation of the PZ Parameters
We now present two estimators of the non-Gaussian distribution Z modeling the Maximum Quantum Yield . The first estimator is based on the Bayesian estimation and the second one follows the expectation maximization (EM) algorithm. The Bayesian estimation is chosen here with the hypothesis that two parameters are known according to some prior information and we need to estimate only one parameter. For the EM algorithm, all the parameters are unknown and need to be estimated. We consider that the latter is a more general approach than the former.
3.2.1. Bayesian Estimation
We suppose that and are known, and we aim to estimate using Bayesian inference. We consider the results for the first day of the experiment as our observed data to get and values. The next step is to define the prior probability for . We recall that . Since only the parameters of the first day are known (), we simulate N samples of Y associated to the first day: . The ratio of the standard deviation to the mean value of these N samples leads to one value. We repeat this simulation a couple of times (let us say S times) and we define ), with and the mean and standard deviation of the values obtained with the S simulations. The posterior distribution is therefore given by:
where
and
with , N ratios of N samples of two normal distributions , and . Last step is to determine the posterior mean estimator of , which is given by [39]:
It is not obvious to compute the above integral since it contains the confluent hypergeometric function. In this case, we use the Monte Carlo (MC) method to numerically approximate this integral. The approximation of using Monte-Carlo is detailed in Algorithm 1. The resulting quantity is an estimator without bias and highly consistent with . The only drawback of using the MC method is that it is time-consuming. More iterations lead to better consistency but to more simulation time.
3.2.2. EM Estimation of the Parameters
Knowing that the pdf of Z is the result of the ratio of two independent normal distributions N() and N(), respectively, we estimate first the parameters by performing the expectation maximization (EM) algorithm. Thereafter, the parameters can be deduced from the following relations:
Consider N independent and identically distributed realizations of a random variable Z distributed according to the written with the confluent hypergeometric function (3). This form of the is more adequate to the estimation parameter procedure using the EM algorithm.
The pdf associated to the ratio Z depends on the set of unknown parameters: . The maximum likelihood estimator of the set parameter , is given by:
| Algorithm 1: MC estimation of . |
|
In the absence of an explicit solution of the maximum likelihood Equation (9), the Expectation–Maximization (EM) algorithm is used to find an estimation given a current estimate of . We suppose that for each observed an unobserved and hidden data is associated. The sequence is also supposed to be independent and identically distributed.
Let and . By using the fact that:
then (10) can be maximized separately in respect to the set of parameters and as follows:
By developing these two equations, and differentiating with respect to , , and (Appendix A.2), we provide the estimate and :
where and are the posterior expectation values dependent of the distribution of Y given by:
and
with and .
The proof of both these expressions is also in Appendix A.2. This leads to the following iterative Algorithm 2 for solving the maximum likelihood problem:
3.3. Comparison with Normal Assumptions Baseline
To show the benefit of using the Bayesian and EM estimations with the distribution, we compare them with a standard normal distribution assumption and the normal approximation proposed in [34].
3.4. Numerical Experiments
We now present the metrics used to establish the value of the proposed non-Gaussian estimator for . We then describe the numerical simulation undertaken with these metrics.
| Algorithm 2: EM algorithm. |
|
3.4.1. Fractional Moments
Dividing two normal distributions lead to a high variability of the mean value. This problem has been raised in agricultural research [40]. For a coefficient of variation of Y () strictly lower than 0.2, the mean value of the ratio is stable. The coefficient of variation of Y is equal to : the ratio of the standard deviation to the mean of Y. Thus, we used interchangeably or . For the bacteria data set, values are between 0.2 and 0.3 (see Table 4), and for the fungal pathogen data set, values are between 0.8 and 1.3 (see Table 5). Therefore, we are not in a situation with a stable mean ratio. We propose an alternative for the mean value in these cases. We suggest using the mean of the fractional moment.
Table 4.
The values of , and associated with the fluorescence data on Healthy and Diseased plants of the bacteria data set. D0, …, and D8 are the six days of the acquisition of chlorophyll fluorescence images.
Table 5.
The values of , and associated with the fluorescence data on Healthy and Diseased plants of the fungal pathogen data set. 0 h, …, 96 h are the five times of the acquisition of chlorophyll fluorescence images.
We give the expression for these moments that benefits from the independence of the variability of the denominator. The fractional moments expression is given by:
with . The proof of this expression is given in Appendix A.4 for .
3.4.2. Monte Carlo Experiments
To have ground truth in the evaluation of the value of the estimator of , we resorted to the use of simulation of the two empirical data sets both in the healthy and diseased plants. We considered the size of the smallest leaves and the largest ones on our two data sets. We found 10 pixels for the smallest leaves and 80 for the largest ones. Generation of Gaussian distribution for and mimicking the experimental observation of our two experimental data sets given in Table 2 and Table 3. The resulting observations of were computed. The two proposed non-Gaussian estimators and the Gaussian baselines estimator described in the previous section were computed. Simulations were repeated 5000 times to compute average performance and associated standard deviations. The end point of our experiments is the relative error:
The measured value is the exact value of the fractional moment, and the estimated value is obtained with one of the compared estimators. This comparison is made at all dates of the experimental data used for the simulation. The prior values used in our proposed methods are initialized with the values of the first day of the experiment.
4. Results
We are now ready to assess the importance of non-Gaussianity in chlorophyll fluorescence images via the comparison of the relative error of our two proposed statistical estimators against the standard estimator under Gaussian assumptions.
4.1. Arabidopsis thaliana Inoculated by a Bacteria
To illustrate the non-Gaussianity of the bacteria data set, we provide the distribution of for the mean values of , , and over the six days of our real experimental data set both for Healthy and Diseased in Figure 3. The normal approximation is added. One can observe a small deviation from Gaussianity.
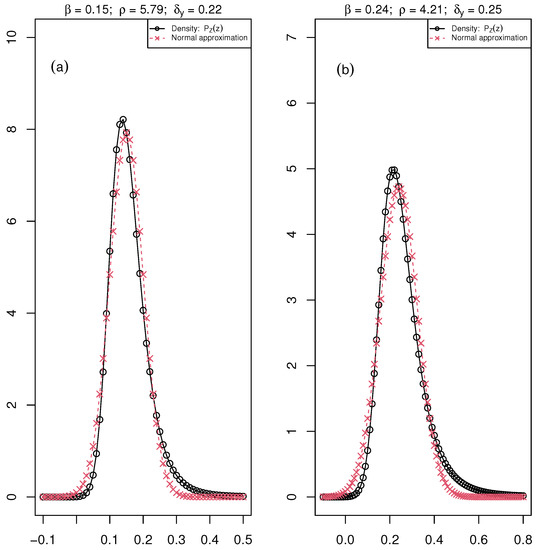
Figure 3.
The distribution of the ratio ( maximum fluorescence and , minimum fluorescence) is the black curve with circle points, and the normal approximation is the red curve with crossed points. The parameters , , and of the distribution are associated with the mean value of these parameters over the six days of the acquisition of chlorophyll fluorescence images for (a) Healthy: , and and (b) Diseased: , and plants of the bacteria data set.
We considered the second-order fractional moment of for this first data set since it led to stable results of the mean of fractional moments for the values of between 0.3 and 1 (see Appendix A.5). We calculated these second-order fractional moments of for each day of the experiment (Table 6). These are the measured values to which we will compare the estimated values obtained with the Monte Carlo simulations with 10 and 80 samples. The results of the Monte Carlo simulation are given in Table 7. The normal distribution and the normal approximation are the methods of estimation when assuming a normal distribution of . Bayesian and EM estimation are the two proposed non-Gaussian estimators with distribution.
Table 6.
Second-order fractional moment of distribution of the ratio for the healthy and diseased leaves of the bacteria data set. D0, …., and D8 are the six days of the acquisition of chlorophyll fluorescence images.
Table 7.
The mean value () and the associated standard deviation () of the second-order fractional moment of the Monte Carlo simulation for 10 and 80 sample sizes, with the first day of the experiment as a reference value, with the assumptions of Gaussian probability density function and the Gaussian approximation proposed in [34] and with the two non-Gaussian estimators, Bayesian and EM.
With both measured (Table 6) and estimated values (Table 7), we calculate the relative error for each day of the experiment. The mean value of the relative error over the six days of the experiment is given in Table 8, for Healthy and Diseased plants, and per sample size.
Table 8.
Mean value of the relative error ( % ) for the five days of the experiment per method of estimation and per sample size, N, for Healthy and Diseased plants of the bacteria data set.
The maximum value of the relative error was not high: 6% with normal assumptions. The relative error is lower for Healthy compared to Diseased plants. Overall, we have a lower error with Bayesian and EM estimations compared to the normal distribution and normal approximation.
4.2. Arabidopsis thaliana Infected with a Fungal Pathogen
We apply the same analysis to the fluorescence images of Arabidopsis thaliana infected with a fungal pathogen. We start with a representation of the distribution of associated with the mean values of , , and over the five dates of the empirical data set for both Healthy and Diseased plants, Figure 4.
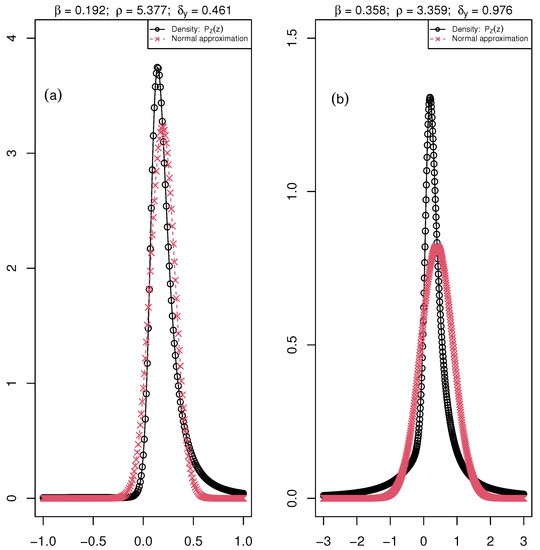
Figure 4.
The distribution of the ratio ( maximum fluorescence and , minimum fluorescence) is the black curve with circle points, and the normal approximation is the red curve with crossed points. The parameters , , and of the distribution are associated with the mean value of these parameters over the six days of the acquisition of chlorophyll fluorescence images for (a) Healthy: , and and (b) Diseased: , and plants of the fungal pathogen data set.
The deviation from normality is more pronounced with this data set. We calculate the measured values of the fourth-order fractional moment of for each date of the experiment (Table 9). The choice to use the fourth order is due to the higher values of in this data set. Thus, a lower value of the fractional moment was more appropriate (cf. simulation of in Appendix A.5). We then calculate the mean value of the fourth-order fractional moment with the Monte-Carlo simulations for 10 and 80 sample sizes. The simulation results are in Table 10. The mean values represent the estimated fourth-order fractional moment with the four methods of estimation: normal distribution assumption, the normal approximation, and the two non-Gaussian estimators, Bayesian and EM.
Table 9.
Fourth-order fractional moment of distribution of the ratio for the Healthy and Diseased plants of the fungal pathogen data set. 0 h, …, 96 h are the five times of the acquisition of chlorophyll fluorescence images.
Table 10.
The mean value () and the associated standard deviation () of the fourth-order fractional moment of the Monte Carlo simulation with 24 h as a reference value.
We calculate the relative error per time of experiment with the measured value of the fourth-order fractional moment (Table 9) and the estimated values (Table 10). We give in Table 11 the mean value of the relative error over all the experiment acquisition times.
Table 11.
Mean value of the relative error (%) for the five times of the experiment per method of estimation and per number of observations for Healthy and Diseased plants of the fungal pathogen data set.
We see clearly on the fungal data set that the relative error is much higher if one supposes a normal distribution of the ratio: 26% for healthy () and 82% for diseased () v.s around 6% and 7% for Bayesian and EM estimations. Thus, these results show that using a normal distribution or normal approximation of the ratio leads to more or less wrong results depending on how pronounced is the deviation from Gaussianity.
5. Discussion
We have quantified the importance of considering the non-Gaussianity in the maximum quantum yield of photosystem II. This non-Gaussianity was only recently highlighted empirically in [12]. In most of the recent studies using the maximum quantum yield of photosystem II as phenotyping characteristic [14,15,17,18,19,20,21,22,24,25,26], the results are presented with average and standard deviation. Our mathematical study shows that this may not be the most appropriate approach especially when the distribution of the gray levels in strongly deviates from Gaussianity. This advocate for the use of box plots like in [23] to easily visualize the non-Gaussianity. The only use of average and standard deviation in [14,15,17,18,19,20,21,22,24,25,26] was not problematic as the maximum quantum yield of photosystem II is not used as a biomarker for its absolute value but rather to differentiate different phenotypes. However, our mathematical models show that the distribution can be nonsymmetric with heavy tails. This may explain why advanced models have been used in the literature for decision making with decisions trees [41,42] or Gaussian mixtures [12,13] for decision making. We focus on estimation in this article which is distinct from detection. It could be an interesting perspective to compare the advanced approaches [12,13,41,42] with a simple single threshold to be applied to the non-Gaussian distribution considered in our work.
6. Conclusions
In this article, we have demonstrated the importance to consider mathematically the non-Gaussianity of vegetation indices composed of a ratio of images corrupted by Gaussian noises. This was illustrated and detailed with chlorophyll fluorescence images. We have designed estimators adapted to this non-Gaussianity under the hypothesis of independence of the distribution of the images used in the ratio. Despite the simplicity of this model, the benefits of this approach by comparison with the usual Gaussian assumption was demonstrated.
In this work, we focused on estimating the distribution parameters of the ratio used in chlorophyll fluorescence indices. In the two chlorophyll fluorescence, infected plants data sets that we considered, the distribution of this ratio didn’t follow a normal distribution. If more chlorophyll fluorescence data sets are available, it could be interesting to have a range of the parameters for the density distribution of the ratio and to identify the intervals for these parameters where normality is verified.
This work could be extended in various directions. Many vegetation indices include a ratio of images and therefore could benefit from the approach proposed in the article. With the two empirical data sets considered, the deviation from Gaussianity was limited, but it was enough to show the importance to use adapted non-Gaussian models. Theoretically, the deviation from Gaussianity can be severe. Therefore, it is fundamentally important to have mathematically grounded estimators. The assumption of independence of the images is a current limitation of our approach that produced lower error but yet biased estimators, especially for small leaves (with a small number of observations). It would be interesting to design models of covariance between images used in the vegetation indices ratio in order to propose possibly unbiased estimators independently of the size of the leaves.
Author Contributions
Conceptualization, D.R., A.E.G. and N.B.; methodology, D.R., A.E.G. and N.B.; software, A.E.G. and N.B.; validation, A.E.G. and N.B.; formal analysis, A.E.G. and N.B.; investigation, A.E.G.; resources, D.R.; data curation, A.E.G., N.B. and N.S.; writing—original draft preparation, A.E.G., D.R. and N.B.; writing—review and editing, A.E.G., N.B., N.S. and D.R.; visualization, A.E.G.; supervision, D.R.; project administration, D.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Available under reasonable request.
Acknowledgments
Authors gratefully acknowledge the PHENOTIC platform node of the French national infrastructure on plant phenotyping ANR PHENOME 11-INBS-0012 and thank Tristan Boureau from Platform PHENOTIC for the fluorescence images acquisition of Arabidopsis plants infected by a bacteria.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| Probability distribution function | |
| Probability density function of the ratio |
Appendix A
Appendix A.1. Ratio Distribution
The aim of this appendix is to show the passage from the distribution of the ratio written as Equation (2) to the distribution of the ratio written with the hypergeometric function Equation (3). We start by recalling two equalities that will be used hereinafter in the proof.
Since function is an odd function, it follows:
Prerequisite A2 ([43], Section 3.462, Equation (1)).
with the parabolic cylinder function defined as follow:
is the gamma function and is the confluent hypergeometric function.
Proof.
Set and . We will start by proving the probability distribution of the ratio since, at one step of the proof, the switch to the hypergeometric function will be realised. We denote by the pdf of the joint two random variables . It is given as following:
where the Jacobian determinant of the change of variables is given by and calculated as follow: .
Therefore,
The probability distribution of the ratio , denoted , is given by:
Since the two random variables X and Y are independent then . The expression of is then given by
By a direct application of Prerequisite A1, with: and , then, .
Setting: , , and , we have the three following equations:
The probability distribution of the ratio, is then given by:
This probability distribution could be written differently using the Prerequisite A2. In fact, the integral in (A1) is a particular form of the integral in (A3). We can then write the Equation (A2) considering as follow:
Since ∀ real , we have:
Therefore
and
Since , it’s obvious that .
In summary, the final expression of is given by:
□
Appendix A.2. EM Algorithm Estimations
We recall that the aim of this appendix is to find the estimations of and associated to the maximisation problem:
Estimation of :
Since
by replacing (A18) in (A16), differentiating with respect to and , and setting the result to zero:
However,
Thus
In summary
where and are the posterior expectation values dependent of the distribution of Y.
Estimation of :
Since
by replacing (A26) in (A17), differentiating with respect to and , and setting the result to zero:
Determination of and :
The posterior expectation and are given by:
Both these equations depends on the posterior distribution given by:
with and .
Therefore, the posterior expectation is equal to:
Since ∀ we have
and , the new expression of the posterior expectation is then given by
As for the posterior expectation, , we have:
In summary
Appendix A.3. Mean Value of the Ratio
Set and . We show in this appendix that the expectation of the ratio, where is given by
with and .
We start by developing the mathematical expectation of the ratio, :
Since , the new variable flows the reciprocal normal distribution with a pdf defined as follow
The mean of T doesn’t exist since is not Lebesgue integrable. We propose here the expectation of the variable T by computing the Cauchy principal value of given as follows:
Using the following property (see [43], Section 3.562)
under the conditions and , and using Equation (A4), we can deduce:
Thus,
In the case , the above equation becomes:
Knowing that then . As a consequence,
By applying this result to Equation (A38), we get then after identification:
The last equation is obtained using the property (see [43], Section 9.212):
We have therefore proven that:
Appendix A.4. Fractional Moments of the Absolute Value of the Ratio
Set and . We provide in this appendix the fractional absolute moments given by
Set . We calculate then :
Using the following property(see [43], Section 3.562):
And knowing that
We deduce:
Substituting this last property in Equation (A47) leads to:
After simplification, we have:
We deduce the case of X:
To conclude:
with .
Appendix A.5. Simulation of the CVY
We investigate at first the variation of the mean value of the fractional moments for values between 0.2 and 0.3. These values correspond to of the bacteria data set. We simulate as follows: repeat 5000 times the calculation of the second-order fractional moments mean for ten pairs of observations , where and , under varying coefficients of variation, with . This corresponds to . Deduce the standard deviation associated with these 5000 values of the fractional means. The choice of does not impact the simulation as pointed out in [40]. Nevertheless, we chose a value close to the bacteria data for this first simulation. The simulation results of are in Table A1.
Table A1.
Simulation of the ratio distribution: mean values of the fractional moment of the second order and standard deviations (in brackets) for 5000 values of 10 pairs of observations , where and , under varying coefficients of variation of Y and X, with .
Table A1.
Simulation of the ratio distribution: mean values of the fractional moment of the second order and standard deviations (in brackets) for 5000 values of 10 pairs of observations , where and , under varying coefficients of variation of Y and X, with .
| 0.20 | 0.22 | 0.23 | 0.24 | 0.25 | 0.26 | 0.27 | 0.28 | 0.29 | 0.30 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.20 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.41 | 0.41 | 0.41 |
| (0.02) | (0.02) | (0.02) | (0.02) | (0.02) | (0.03) | (0.03) | (0.03) | (0.03) | (0.05) | |
| 0.21 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.41 | 0.41 | 0.41 |
| (0.02) | (0.02) | (0.02) | (0.02) | (0.04) | (0.02) | (0.03) | (0.04) | (0.03) | (0.05) | |
| 0.22 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.41 | 0.41 |
| (0.02) | (0.02) | (0.02) | (0.02) | (0.04) | (0.03) | (0.03) | (0.04) | (0.03) | (0.04) | |
| 0.23 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.41 | 0.41 |
| (0.02) | (0.02) | (0.02) | (0.02) | (0.02) | (0.03) | (0.03) | (0.03) | (0.04) | (0.04) | |
| 0.24 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.41 | 0.41 |
| (0.02) | (0.02) | (0.02) | (0.02) | (0.03) | (0.03) | (0.03) | (0.03) | (0.03) | (0.04) | |
| 0.25 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.41 | 0.41 |
| (0.02) | (0.02) | (0.02) | (0.02) | (0.02) | (0.03) | (0.03) | (0.04) | (0.03) | (0.08) | |
| 0.26 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.41 | 0.41 |
| (0.02) | (0.02) | (0.02) | (0.03) | (0.03) | (0.03) | (0.03) | (0.03) | (0.04) | (0.04) | |
| 0.27 | 0.39 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.41 | 0.41 |
| (0.02) | (0.02) | (0.02) | (0.03) | (0.03) | (0.06) | (0.03) | (0.03) | (0.04) | (0.08) | |
| 0.28 | 0.39 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.41 |
| (0.02) | (0.02) | (0.02) | (0.03) | (0.03) | (0.03) | (0.03) | (0.03) | (0.03) | (0.05) | |
| 0.29 | 0.39 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.41 |
| (0.02) | (0.02) | (0.03) | (0.03) | (0.03) | (0.03) | (0.03) | (0.04) | (0.04) | (0.04) | |
| 0.30 | 0.39 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.41 |
| (0.02) | (0.02) | (0.02) | (0.03) | (0.03) | (0.06) | (0.03) | (0.06) | (0.04) | (0.04) | |
The estimated values of are close to 0.39, and the standard deviations (in brackets) associated with the mean values of the fractional moments of the second order show a very low variation. Thus, we use the second-order fractional moment for the bacteria data set.
We secondly investigated the mean value of the fractional moment of the second order for the between 0.8 and 1.3. These values correspond to of the Fungal pathogen data set. It had a high variability for and a poor estimation of the mean value (we don’t show the results of this simulation for the sake of readability). We then simulated with a fractional moment of the fourth order (). This corresponds to . The results of this simulation are in Table A2.
Table A2.
Simulation of the ratio distribution: mean values of the fractional moment of the fourth order and standard deviations (in brackets) for 5000 values of 10 pairs of observations , where and , under varying coefficients of variation (CV), with .
Table A2.
Simulation of the ratio distribution: mean values of the fractional moment of the fourth order and standard deviations (in brackets) for 5000 values of 10 pairs of observations , where and , under varying coefficients of variation (CV), with .
| 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1 | 1.1 | 1.2 | 1.3 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.4 | 0.67 | 0.68 | 0.69 | 0.70 | 0.71 | 0.71 | 0.70 | 0.70 | 0.69 | 0.69 |
| (0.05) | (0.06) | (0.07) | (0.08) | (0.08) | (0.08) | (0.09) | (0.09) | (0.09) | (0.09) | |
| 0.5 | 0.66 | 0.68 | 0.69 | 0.70 | 0.70 | 0.70 | 0.70 | 0.69 | 0.69 | 0.68 |
| (0.06) | (0.07) | (0.08) | (0.08) | (0.09) | (0.09) | (0.09) | (0.09) | (0.09) | (0.09) | |
| 0.6 | 0.66 | 0.67 | 0.69 | 0.69 | 0.70 | 0.70 | 0.69 | 0.69 | 0.68 | 0.68 |
| (0.06) | (0.07) | (0.08) | (0.08) | (0.09) | (0.09) | (0.09) | (0.09) | (0.09) | (0.09) | |
| 0.7 | 0.65 | 0.67 | 0.69 | 0.69 | 0.69 | 0.69 | 0.69 | 0.69 | 0.68 | 0.67 |
| (0.06) | (0.07) | (0.08) | (0.08) | (0.09) | (0.09) | (0.09) | (0.09) | (0.09) | (0.09) | |
| 0.8 | 0.66 | 0.67 | 0.69 | 0.70 | 0.70 | 0.70 | 0.69 | 0.69 | 0.68 | 0.68 |
| (0.06) | (0.07) | (0.08) | (0.09) | (0.09) | (0.09) | (0.09) | (0.09) | (0.09) | (0.09) | |
| 0.9 | 0.66 | 0.67 | 0.69 | 0.70 | 0.70 | 0.70 | 0.69 | 0.69 | 0.69 | 0.68 |
| (0.06) | (0.07) | (0.09) | (0.09) | (0.10) | (0.09) | (0.10) | (0.09) | (0.09) | (0.09) | |
| 1 | 0.66 | 0.68 | 0.70 | 0.70 | 0.71 | 0.70 | 0.70 | 0.70 | 0.69 | 0.68 |
| (0.06) | (0.08) | (0.09) | (0.09) | (0.09) | (0.10) | (0.10) | (0.10) | (0.10) | (0.09) | |
| 1.1 | 0.67 | 0.69 | 0.70 | 0.71 | 0.71 | 0.71 | 0.71 | 0.71 | 0.70 | 0.69 |
| (0.06) | (0.08) | (0.09) | (0.09) | (0.09) | (0.10) | (0.10) | (0.10) | (0.10) | (0.10) | |
| 1.2 | 0.68 | 0.69 | 0.71 | 0.72 | 0.72 | 0.72 | 0.71 | 0.71 | 0.70 | 0.70 |
| (0.06) | (0.08) | (0.09) | (0.09) | (0.09) | (0.10) | (0.10) | (0.10) | (0.10) | (0.10) | |
| 1.3 | 0.68 | 0.70 | 0.71 | 0.72 | 0.72 | 0.72 | 0.72 | 0.72 | 0.71 | 0.71 |
| (0.06) | (0.08) | (0.09) | (0.09) | (0.09) | (0.10) | (0.10) | (0.10) | (0.10) | (0.11) | |
The standard deviations (in brackets) associated with the mean values of the fractional moments of the fourth order show a low variation, and the exact value of 0.65 is reasonably approximated. Therefore, we propose to use higher fractional moments for higher values of . In our data sets, we will use for the bacteria data set and for the fungal pathogen data set.
References
- Maxwell, K.; Johnson, G.N. Chlorophyll fluorescence—A practical guide. J. Exp. Bot. 2000, 51, 659–668. [Google Scholar] [CrossRef] [PubMed]
- Gorbe, E.; Calatayud, A. Applications of chlorophyll fluorescence imaging technique in horticultural research: A review. Sci. Hortic. 2012, 138, 24–35. [Google Scholar] [CrossRef]
- Kalaji, H.M.; Schansker, G.; Ladle, R.J.; Goltsev, V.; Bosa, K.; Allakhverdiev, S.I.; Brestic, M.; Bussotti, F.; Calatayud, A.; Dąbrowski, P.; et al. Frequently asked questions about in vivo chlorophyll fluorescence: Practical issues. Photosynth. Res. 2014, 122, 121–158. [Google Scholar] [CrossRef] [PubMed]
- Kalaji, H.M.; Schansker, G.; Brestic, M.; Bussotti, F.; Calatayud, A.; Ferroni, L.; Goltsev, V.; Guidi, L.; Jajoo, A.; Li, P.; et al. Frequently asked questions about chlorophyll fluorescence, the sequel. Photosynth. Res. 2017, 132, 13–66. [Google Scholar] [CrossRef] [PubMed]
- Pérez-Bueno, M.L.; Pineda, M.; Barón, M. Phenotyping plant responses to biotic stress by chlorophyll fluorescence imaging. Front. Plant Sci. 2019, 10, 1135. [Google Scholar] [CrossRef]
- Valcke, R. Can chlorophyll fluorescence imaging make the invisible visible? Photosynthetica 2021, 59, 381–398. [Google Scholar] [CrossRef]
- Küpper, H.; Benedikty, Z.; Morina, F.; Andresen, E.; Mishra, A.; Trtílek, M. Analysis of OJIP chlorophyll fluorescence kinetics and QA reoxidation kinetics by direct fast imaging. Plant Physiol. 2019, 179, 369–381. [Google Scholar] [CrossRef]
- McAusland, L.; Atkinson, J.A.; Lawson, T.; Murchie, E.H. High throughput procedure utilising chlorophyll fluorescence imaging to phenotype dynamic photosynthesis and photoprotection in leaves under controlled gaseous conditions. Plant Methods 2019, 15, 1–15. [Google Scholar] [CrossRef]
- Harbinson, J.; Croce, R.; van Grondelle, R.; van Amerongen, H.; van Stokkum, I. Chlorophyll fluorescence as a tool for describing the operation and regulation of photosynthesis in vivo. In Light Harvesting in Photosynthesis; CRC Press: Boca Raton, FL, USA, 2018; pp. 539–571. [Google Scholar]
- Schmierer, M.; Knopf, O.; Asch, F. Growth and photosynthesis responses of a super dwarf rice genotype to shade and nitrogen supply. Rice Sci. 2021, 28, 178–190. [Google Scholar] [CrossRef]
- Pleban, J.R.; Guadagno, C.R.; Mackay, D.S.; Weinig, C.; Ewers, B.E. Rapid chlorophyll a fluorescence light response curves mechanistically inform photosynthesis modeling. Plant Physiol. 2020, 183, 602–619. [Google Scholar] [CrossRef]
- Pavicic, M.; Overmyer, K.; Rehman, A.u.; Jones, P.; Jacobson, D.; Himanen, K. Image-Based Methods to Score Fungal Pathogen Symptom Progression and Severity in Excised Arabidopsis Leaves. Plants 2021, 10, 158. [Google Scholar] [CrossRef] [PubMed]
- Rousseau, C.; Belin, E.; Bove, E.; Rousseau, D.; Fabre, F.; Berruyer, R.; Guillaumès, J.; Manceau, C.; Jacques, M.A.; Boureau, T. High throughput quantitative phenotyping of plant resistance using chlorophyll fluorescence image analysis. Plant Methods 2013, 9, 17. [Google Scholar] [CrossRef] [PubMed]
- Leufen, G.; Noga, G.; Hunsche, M. Proximal sensing of plant-pathogen interactions in spring barley with three fluorescence techniques. Sensors 2014, 14, 11135–11152. [Google Scholar] [CrossRef] [PubMed]
- Su, L.; Dai, Z.; Li, S.; Xin, H. A novel system for evaluating drought–cold tolerance of grapevines using chlorophyll fluorescence. BMC Plant Biol. 2015, 15, 82. [Google Scholar] [CrossRef]
- Bresson, J.; Vasseur, F.; Dauzat, M.; Koch, G.; Granier, C.; Vile, D. Quantifying spatial heterogeneity of chlorophyll fluorescence during plant growth and in response to water stress. Plant Methods 2015, 11, 23. [Google Scholar] [CrossRef]
- Tatagiba, S.D.; DaMatta, F.M.; Rodrigues, F.Á. Leaf gas exchange and chlorophyll a fluorescence imaging of rice leaves infected with Monographella albescens. Phytopathology 2015, 105, 180–188. [Google Scholar] [CrossRef]
- Ajigboye, O.O.; Bousquet, L.; Murchie, E.H.; Ray, R.V. Chlorophyll fluorescence parameters allow the rapid detection and differentiation of plant responses in three different wheat pathosystems. Funct. Plant Biol. 2016, 43, 356–369. [Google Scholar] [CrossRef]
- Dias, C.S.; Araujo, L.; Chaves, J.A.A.; DaMatta, F.M.; Rodrigues, F.A. Water relation, leaf gas exchange and chlorophyll a fluorescence imaging of soybean leaves infected with Colletotrichum truncatum. Plant Physiol. Biochem. 2018, 127, 119–128. [Google Scholar] [CrossRef]
- Wen, Z.; Raffaello, T.; Zeng, Z.; Pavicic, M.; Asiegbu, F.O. Chlorophyll fluorescence imaging for monitoring effects of Heterobasidion parviporum small secreted protein induced cell death and in planta defense gene expression. Fungal Genet. Biol. 2019, 126, 37–49. [Google Scholar] [CrossRef]
- Polonio, Á.; Pineda, M.; Bautista, R.; Martínez-Cruz, J.; Pérez-Bueno, M.L.; Barón, M.; Pérez-García, A. RNA-seq analysis and fluorescence imaging of melon powdery mildew disease reveal an orchestrated reprogramming of host physiology. Sci. Rep. 2019, 9, 7978. [Google Scholar] [CrossRef]
- Kim, J.H.; Bhandari, S.R.; Chae, S.Y.; Cho, M.C.; Lee, J.G. Application of maximum quantum yield, a parameter of chlorophyll fluorescence, for early determination of bacterial wilt in tomato seedlings. Hortic. Environ. Biotechnol. 2019, 60, 821–829. [Google Scholar] [CrossRef]
- Wang, S.; Leus, L.; Lootens, P.; Van Huylenbroeck, J.; Van Labeke, M.C. Germination Kinetics and Chlorophyll Fluorescence Imaging Allow for Early Detection of Alkalinity Stress in Rhododendron Species. Horticulturae 2022, 8, 823. [Google Scholar] [CrossRef]
- Suárez, J.C.; Vanegas, J.I.; Contreras, A.T.; Anzola, J.A.; Urban, M.O.; Beebe, S.E.; Rao, I.M. Chlorophyll Fluorescence Imaging as a Tool for Evaluating Disease Resistance of Common Bean Lines in the Western Amazon Region of Colombia. Plants 2022, 11, 1371. [Google Scholar] [CrossRef]
- Schlie, T.P.; Dierend, W.; Köpcke, D.; Rath, T. Detecting low-oxygen stress of stored apples using chlorophyll fluorescence imaging and histogram division. Postharvest Biol. Technol. 2022, 189, 111901. [Google Scholar] [CrossRef]
- Brigmon, R.L.; McLeod, K.W.; Doman, E.; Seaman, J.C. The impact of tritium phytoremediation on plant health as measured by fluorescence. J. Environ. Radioact. 2022, 255, 107018. [Google Scholar] [CrossRef]
- Sapoukhina, N.; Boureau, T.; Rousseau, D. Plant disease symptom segmentation in chlorophyll fluorescence imaging with a synthetic dataset. Front. Plant Sci. 2022, 13, 969205. [Google Scholar] [CrossRef]
- D’Agostino, R.; Pearson, E.S. Tests for Departure from Normality. Empirical Results for the Distributions of b2 and √b1. Biometrika 1973, 60, 613–622. [Google Scholar] [CrossRef]
- Pavicic, M. MDPI_leaf_infection. Available online: https://github.com/mipavici/MDPI_leaf_infection (accessed on 15 November 2022).
- Berger, S.; Benediktyová, Z.; Matouš, K.; Bonfig, K.; Mueller, M.J.; Nedbal, L.; Roitsch, T. Visualization of dynamics of plant–pathogen interaction by novel combination of chlorophyll fluorescence imaging and statistical analysis: Differential effects of virulent and avirulent strains of P. syringae and of oxylipins on A. thaliana. J. Exp. Bot. 2006, 58, 797–806. [Google Scholar] [CrossRef]
- Sánchez-Moreiras, A.M.; Graña, E.; Reigosa, M.J.; Araniti, F. Imaging of Chlorophyll a Fluorescence in Natural Compound-Induced Stress Detection. Front. Plant Sci. 2020, 11, 583590. [Google Scholar] [CrossRef]
- Genty, B.; Meyer, S. Quantitative Mapping of Leaf Photosynthesis Using Chlorophyll Fluorescence Imaging. Aust. J. Plant Physiol. 1995, 22, 277–284. [Google Scholar] [CrossRef]
- Marsaglia, G. Ratios of Normal Variables and Ratios of Sums of Uniform Variables. J. Am. Stat. Assoc. 1965, 60, 193–204. [Google Scholar] [CrossRef]
- Díaz-Francés, E.; Rubio, F. On the existence of a normal approximation to the distribution of the ratio of two independent normal random variables. Stat. Pap. 2013, 54, 309–323. [Google Scholar] [CrossRef]
- Pham-Gia, T.; Thanh, D.N. Hypergeometric Functions: From One Scalar Variable to Several Matrix Arguments, in Statistics and Beyond. Open J. Stat. 2016, 6, 951–994. [Google Scholar] [CrossRef]
- Hayya, J.; Armstrong, D.; Gressis, N. A Note on the Ratio of Two Normally Distributed Variables. Manag. Sci. 1975, 21, 1338–1341. [Google Scholar] [CrossRef]
- Kuethe, D.O.; Caprihan, A.; Gach, H.M.; Lowe, I.J.; Fukushima, E. Imaging obstructed ventilation with NMR using inert fluorinated gases. J. Appl. Physiol. 2000, 88, 2279–2286. [Google Scholar] [CrossRef]
- Marsaglia, G. Ratios of Normal Variables. J. Stat. Softw. 2006, 16, 1–10. [Google Scholar] [CrossRef]
- Marin, J.M.; Robert, C.P. Bayesian Essentials with R, 2nd ed.; Springer Texts in Statistics; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Qiao, C.G.; Wood, G.R.; Lai, C.D.; Luo, D.W. Comparison of two common estimators of the ratio of the means of independent normal variables in agricultural research. J. Appl. Math. Decis. Sci. 2006, 2006, 78375. [Google Scholar] [CrossRef]
- Foucher, J.; Ruh, M.; Briand, M.; Préveaux, A.; Barbazange, F.; Boureau, T.; Jacques, M.A.; Chen, N.W. Improving Common Bacterial Blight Phenotyping by Using Rub Inoculation and Machine Learning: Cheaper, Better, Faster, Stronger. Phytopathology® 2022, 112, 691–699. [Google Scholar] [CrossRef]
- Meline, V.; Delage, W.; Brin, C.; Li-Marchetti, C.; Sochard, D.; Arlat, M.; Rousseau, C.; Darrasse, A.; Briand, M.; Lebreton, G.; et al. Role of the acquisition of a type 3 secretion system in the emergence of novel pathogenic strains of Xanthomonas. Mol. Plant Pathol. 2019, 20, 33–50. [Google Scholar] [CrossRef]
- Zwillinger, D.; Moll, V. Preface to the Eighth Edition. In Table of Integrals, Series, and Products, 8th ed.; Zwillinger, D., Moll, V., Gradshteyn, I.S., Ryzhik, I.M., Eds.; Academic Press: Cambridge, MA, USA, 2014; p. xvii. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).