
Scene Classification Based on Heterogeneous Features of Multi-Source Data


Abstract

1. Introduction
- Traditional approaches design some representative features according to the characteristics of images and the task of classification [13], such as color histograms (CH) [14] and scale-invariant feature transform (SIFT) [15]. The above features are not necessarily independent of one another and some approaches involve two or more features [16].
- This model is designed to accurately capture the complex and changeable features in the scene target object, which is projected into the parameter space or dictionary to learn more effective middle-level features to classify the scene, such as bag-of-visual-words (BoVW) [17]. Later, to solve the problem of high-dimensional feature vector, scholars proposed probabilistic topic model (PTM), such as Latent Dirichlet Allocation model (LDA) [18] and Probabilistic Latent Semantic Analysis (PLSA) [19].
- Classification models based on high-level features: Artificial intelligence and computer vision technologies represented by deep learning (such as convolutional neural network (CNN) [20]) further improve the accuracy of remote sensing image scene classification [8,9,21,22]. In the high spatial remote sensing image scene classification, Xu et al. [9] proposed a novel lightweight and robust Lie Group and CNN joint representation scene classification model, which improved the classification accuracy. Xu et al. [12] proposed a Lie Group spatial attention mechanism to complete high spatial remote sensing image scene classification.
- 1.
- How to distinguish the socio-economic attributes of scenes with the same or similar spatial layouts. The different socio-economic attributes are difficult to express in HRRSI. As shown in Figure 1, the two land parcels in the scenario have several office buildings, one of which are enterprise, while the other is a government agency. It is hard to differentiate the one from the other.
- 2.
- How to solve the visual-semantic differences caused by the matching between the features learned by the model and the corresponding semantic categories. As shown in Figure 2, an airport scenario consists of airplanes and runways, a railway scenario consists of railway stations and railways, and a bridge may belong to freeways. These three categories can be regarded as three layers: the first layer (i.e., transportation), the second layer (i.e., airports, bridges, and railways), and the third layer (i.e., runways) [29]. The second and third layers are easier to classify, while the first layer requires more discriminative features. However, most of the existing models can learn high-level features [30], but they cannot be well integrated with high-level semantics well into category labels [31].
- 3.
- How to resolve low between-class separability (also known as high interclass similarity). As shown in Figure 3, dense residential, medium residential, and sparse residential all contain the same two modalities (houses and trees). These categories have high intraclass similarities. Most of the existing models ignore the diversity between classes and higher intraclass similarity of the scene, most of the existing models are mainly applied to the scene classification dominated by single-modality-dominated scenes, which has limitations when encountering multimodality-dominated scenes.
- To solve the problem of scenes with the same or similar spatial layout, but with different socio-economic attributes. We propose a classification model based on heterogeneous characteristics of multi-source data. This model makes full use of the heterogeneous characteristics of multi-source data, including the external physical structure features in previous studies and the internal socio-economic semantic features of the scene, enriching the features of the scene.
- To resolve the problem of visual-semantic discrepancies, in our proposed model, multi-scale grid sampling is carried out on HRRSI to learn different degrees of multigrained features, and the attention mechanism is introduced. The Lie Group covariance matrix with different granularity is constructed based on the maxout module to extract the second-order features of the latent ontological essence of the HRRSI.
- To resolve the problem of the high interclass similarity, the weighted adaptive fusion module is adopted in our proposed model to fuse the features extracted from different granularity, and a Lie Group Fisher scene classification algorithm is proposed. By calculating the intrinsic mean of the fused Lie Group features of each category, a geodesic is found in the Lie Group manifold space, and the samples are mapped to the geodesic, minimizing intra-class and maximizing inter-class.
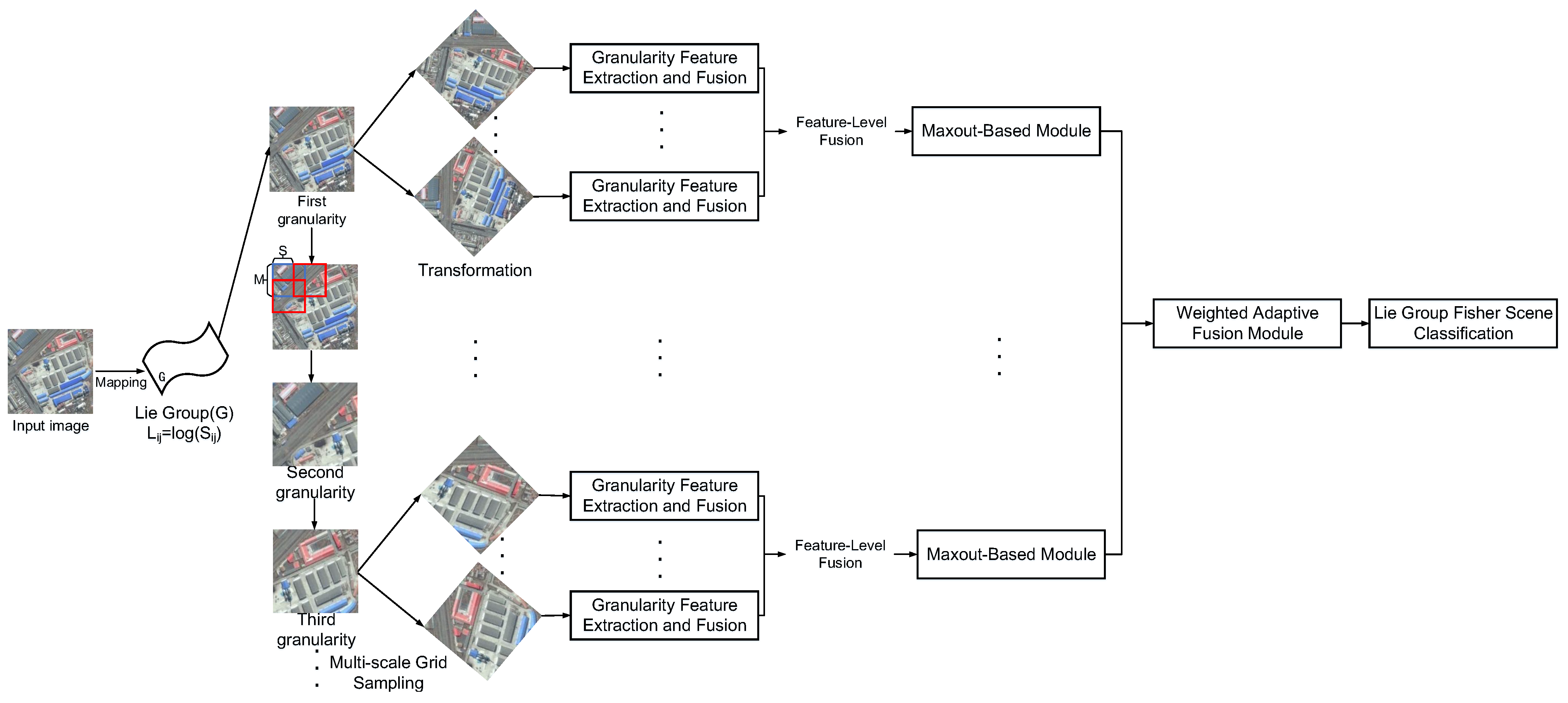
2. Materials and Methods
2.1. Sample Mapping
2.2. Multi-Scale Grid Sampling
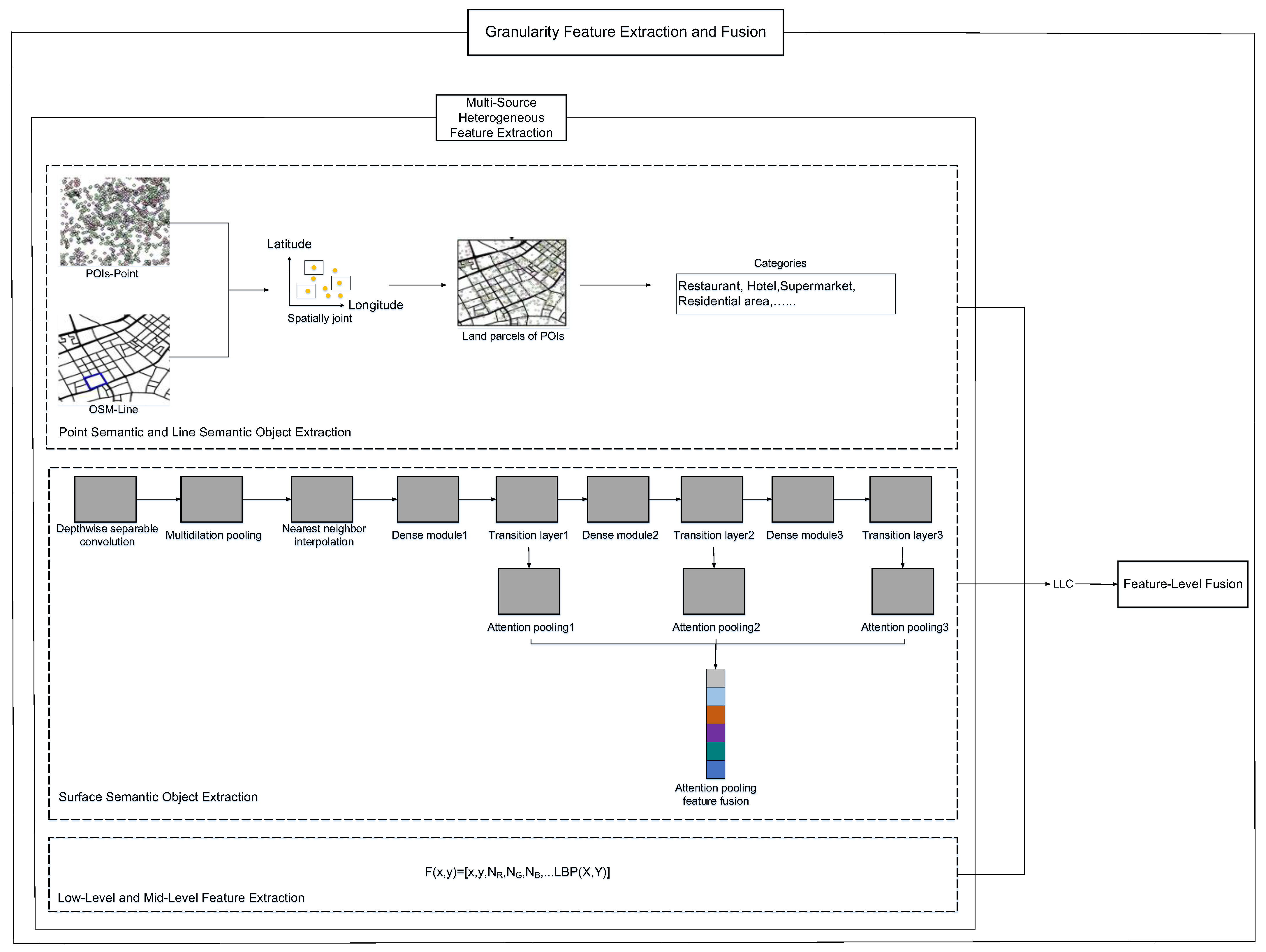
2.3. Granularity Feature Extraction and Fusion
2.3.1. Multi-Source Heterogeneous Feature Extraction
2.3.2. Feature-Level Fusion
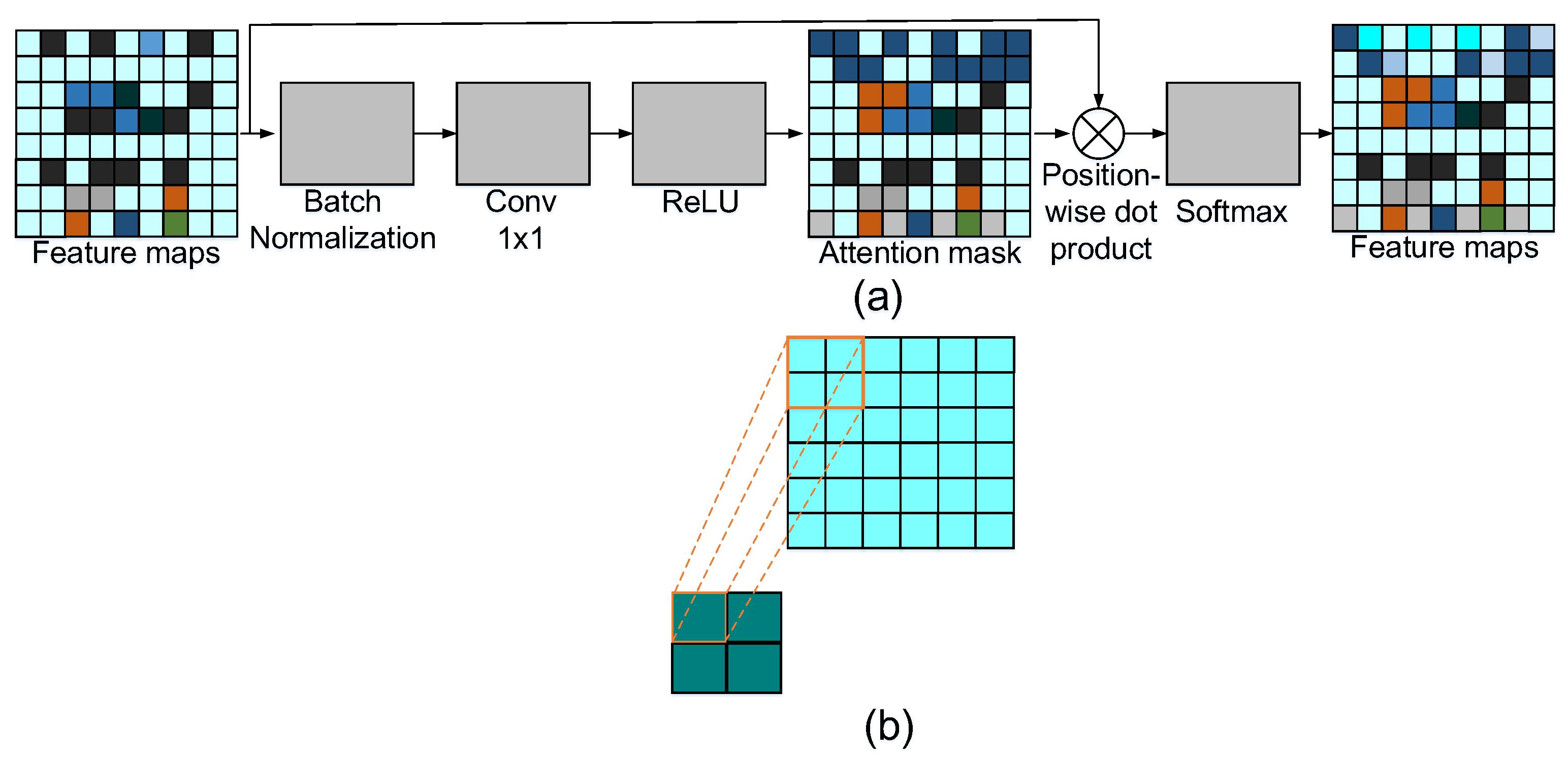
2.4. Maxout-Based Module
2.5. Weighted Adaptive Fusion Module
2.6. Lie Group Fisher Scene Classification
3. Results
3.1. Experimental Datasets
3.2. Experiment Setup
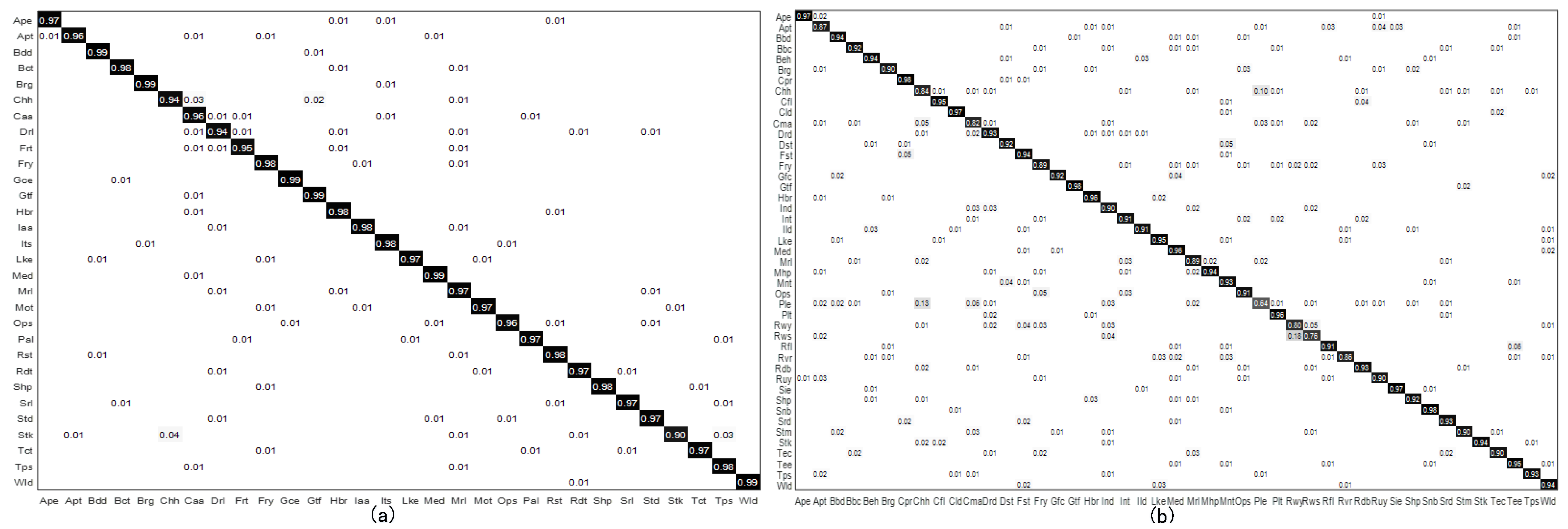
3.3. Experimental Results and Analysis
4. Discussion
4.1. Evaluation of Traditional Upsampling Method and Nearest Neighbor Interpolation Sampling Method
4.2. Evaluation of Granularity Extraction Modules
4.3. Evaluation of Socio-Economic Semantic Features and Shallower Features
4.4. Evaluation of Feature-Level Fusion Module
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AID | Aerial Image Dataset |
| BN | Batch Normalization |
| CBAM | Convolutional Block Attention Module |
| CH | Color Histogram |
| CNN | Convolutinal Neural Network |
| DCA | Discriminant Correlation Analysis |
| DCCNN | Dense Connected Convolutional Neural Network |
| DepConv | Depth separable Convolutions |
| F1 | F1 score |
| FLDA | Fisher Linear Discriminant Analysis |
| HRRSI | High-resolution Remote Sensing Images |
| KC | Kappa Coefficient |
| LGDL | Lie Group Deep Learning |
| LGML | Lie Group Machine Learning |
| LGMS | Lie Group Manifold Space |
| LGRIN | Lie Group Regional Influence Network |
| LLC | Locality-constrained Linear Coding |
| OA | Overall Accuracy |
| OSM | OpenStreetMap |
| PGA | Principal Geodesic Analysis |
| POI | Points of Interest |
| PTM | Probabilistic Topic Models |
| ReLU | Rectified Linear Units |
| SD | Standard Deviation |
| SGD | Stochastic Gradient Descent |
| UCM | UC Merced |
| VGI | Volunteered Geographic Information |
References
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Martha, T.R.; Kerle, N.; van Westen, C.J.; Jetten, V.; Kumar, K.V. Segment optimization and data-driven thresholding for knowledge-based landslide detection by object-based image analysis. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4928–4943. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Ghazouani, F.; Farah, I.R.; Solaiman, B. A multi-level semantic scene interpretation strategy for change interpretation in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8775–8795. [Google Scholar] [CrossRef]
- Liu, X.; He, J.; Yao, Y.; Zhang, J.; Liang, H.; Wang, H.; Hong, Y. Classifying urban land use by integrating remote sensing and social media data. Int. J. Geogr. Inf. Sci. 2017, 31, 1675–1696. [Google Scholar] [CrossRef]
- Zhong, Y.; Su, Y.; Wu, S.; Zheng, Z.; Zhao, J.; Ma, A.; Zhu, Q.; Ye, R.; Li, X.; Pellikka, P.; et al. Open-source data-driven urban land-use mapping integrating point-line-polygon semantic objects: A case study of Chinese cities. Remote Sens. Environ. 2020, 247, 111838. [Google Scholar] [CrossRef]
- Sun, H.; Li, S.; Zheng, X.; Lu, X. Remote sensing scene classification by gated bidirectional network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 82–96. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G.; Shu, J. A Combination of Lie Group Machine Learning and Deep Learning for Remote Sensing Scene Classification Using Multi-Layer Heterogeneous Feature Extraction and Fusion. Remote Sens. 2022, 14, 1445. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G.; Shu, J. A Lightweight and Robust Lie Group-Convolutional Neural Networks Joint Representation for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G.; Shu, J. Robust Joint Representation of Intrinsic Mean and Kernel Function of Lie Group for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2020, 118, 796–800. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G.; Shu, J. A Lightweight Intrinsic Mean for Remote Sensing Classification With Lie Group Kernel Function. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1741–1745. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G.; Shu, J. Lie Group spatial attention mechanism model for remote sensing scene classification. Int. J. Remote Sens. 2022, 43, 2461–2474. [Google Scholar] [CrossRef]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2011, 33, 2395–2412. [Google Scholar] [CrossRef]
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Avramović, A.; Risojević, V. Block-based semantic classification of high-resolution multispectral aerial images. Signal Image Video Process. 2016, 10, 75–84. [Google Scholar] [CrossRef]
- Chaib, S.; Liu, H.; Gu, Y.; Yao, H. Deep feature fusion for VHR remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4775–4784. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Hofmann, T. Unsupervised learning by probabilistic latent semantic analysis. Mach. Learn. 2001, 42, 177–196. [Google Scholar] [CrossRef]
- Xie, J.; He, N.; Fang, L.; Plaza, A. Scale-free convolutional neural network for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6916–6928. [Google Scholar] [CrossRef]
- Peng, F.; Lu, W.; Tan, W.; Qi, K.; Zhang, X.; Zhu, Q. Multi-Output Network Combining GNN and CNN for Remote Sensing Scene Classification. Remote Sens. 2022, 14, 1478. [Google Scholar] [CrossRef]
- Zhu, Q.; Lei, Y.; Sun, X.; Guan, Q.; Zhong, Y.; Zhang, L.; Li, D. Knowledge-guided land pattern depiction for urban land use mapping: A case study of Chinese cities. Remote Sens. Environ. 2022, 272, 112916. [Google Scholar] [CrossRef]
- Ji, J.; Zhang., T.; Jiang., L.; Zhong., W.; Xiong., H. Combining multilevel features for remote sensing image scene classification with attention model. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1647–1651. [Google Scholar] [CrossRef]
- Marandi, R.N.; Ghassemian, H. A new feature fusion method for hyperspectral image classification. Proc. Iran. Conf. Electr. Eng. (ICEE) 2017, 17, 1723–1728. [Google Scholar] [CrossRef]
- Jia, S.; Xian, J. Multi-feature-based decision fusion framework for hyperspectral imagery classification. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 5–8. [Google Scholar] [CrossRef]
- Zheng, Z.; Cao, J. Fusion High-and-Low-Level Features via Ridgelet and Convolutional Neural Networks for Very High-Resolution Remote Sensing Imagery Classification. IEEE Access 2019, 7, 118472–118483. [Google Scholar] [CrossRef]
- Fang, Y.; Li, P.; Zhang, J.; Ren, P. Cohesion Intensive Hash Code Book Co-construction for Efficiently Localizing Sketch Depicted Scenes. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar]
- Sun, Y.; Feng, S.; Ye, Y.; Li, X.; Kang, J.; Huang, Z.; Luo, C. Multisensor Fusion and Explicit Semantic Preserving-Based Deep Hashing for Cross-Modal Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Ungerer, F.; Schmid, H.J. An introduction to cognitive linguistics. J. Chengdu Coll. Educ. 2006, 17, 1245–1253. [Google Scholar] [CrossRef]
- Wang, J.; Zhong, Y.; Zheng, Z.; Ma, A.; Zhang, L. RSNet: The search for remote sensing deep neural networks in recognition tasks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2520–2534. [Google Scholar] [CrossRef]
- Zeng, Z.; Chen, X.; Song, Z. MGFN: A Multi-Granularity Fusion Convolutional Neural Network for Remote Sensing Scene Classification. IEEE Access 2021, 9, 76038–76046. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Fei-Fei, L.; Perona, P. A Bayesian hierarchical model for learning natural scene categories. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 522, pp. 524–531. [Google Scholar] [CrossRef]
- Soliman, A.; Soltani, K.; Yin, J.; Padmanabhan, A.; Wang, S. Social sensing of urban land use based on analysis of twitter users’ mobility patterns. PLoS ONE 2017, 14, e0181657. [Google Scholar] [CrossRef] [PubMed]
- Tang, A.Y.; Adams, T.M.; Lynn Usery, E. A spatial data model design for feature-based geographical information systems. Int. J. Geogr. Inf. Syst. 1996, 10, 643–659. [Google Scholar] [CrossRef]
- Yao, Y.; Li, X.; Liu, X.; Liu, P.; Liang, Z.; Zhang, J.; Mai, K. Sensing spatial distribution of urban land use by integrating points-of-interest and Google Word2Vec model. Int. J. Geogr. Inf. Sci. 2017, 31, 825–848. [Google Scholar] [CrossRef]
- Fonte, C.C.; Minghini, M.; Patriarca, J.; Antoniou, V.; See, L.; Skopeliti, A. Generating up-to-date and detailed land use and land cover maps using openstreetmap and GlobeLand30. ISPRS Int. J. Geo-Inform. 2017, 6, 125. [Google Scholar] [CrossRef]
- Chen, C.; Du, Z.; Zhu, D.; Zhang, C.; Yang, J. Land use classification in construction areas based on volunteered geographic information. In Proceedings of the International Conference on Agro-Geoinformatics, Tianjin, China, 18–20 July 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 15–17 June 2018; pp. 4510–4520. [Google Scholar]
- Li, E.; Xia, J.; Du, P.; Lin, C.; Samat, A. Integrating multilayer features of convolutional neural networks for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5653–5665. [Google Scholar] [CrossRef]
- Anwer, R.M.; Khan, F.S.; van de Weijer, J.; Molinier, M.; Laaksonen, J. Binary patterns encoded convolutional neural networks for texture recognition and remote sensing scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 138, 74–85. [Google Scholar] [CrossRef]
- Wang, X.; Xu, M.; Xiong, X.; Ning, C. Remote Sensing Scene Classification Using Heterogeneous Feature Extraction and Multi-Level Fusion. IEEE Access 2020, 8, 217628–217641. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Wang, Z.; Huang, X.; Zhang, L.; Sun, H. Unsupervised feature learning via spectral clustering of multidimensional patches for remotely sensed scene classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2015, 8, 2015–2030. [Google Scholar] [CrossRef]
- Du, B.; Xiong, W.; Wu, J.; Zhang, L.; Zhang, L.; Tao, D. Stacked convolutional denoising auto-encoders for feature representation. IEEE Trans. Cybern. 2017, 47, 1017–1027. [Google Scholar] [CrossRef]
- Baker, A. Matrix Groups: An Introduction to Lie Group Theory; Springer Science & Business Media: Cham, Switzerland, 2012. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Hensman, P.; Masko, D. The Impact of Imbalanced Training Data for Convolutional Neural Networks; Degree Project in Computer Science; KTH Royal Institute of Technology: Stockholm, Sweden, 2015. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Ma, A.; Yu, N.; Zheng, Z.; Zhong, Y.; Zhang, L. A Supervised Progressive Growing Generative Adversarial Network for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Sun, X.; Zhu, Q.; Qin, Q. A Multi-Level Convolution Pyramid Semantic Fusion Framework for High-Resolution Remote Sensing Image Scene Classification and Annotation. IEEE Access 2021, 9, 18195–18208. [Google Scholar] [CrossRef]
- Zheng, J.; Wu, W.; Yuan, S.; Zhao, Y.; Li, W.; Zhang, L.; Dong, R.; Fu, H. A Two-Stage Adaptation Network (TSAN) for Remote Sensing Scene Classification in Single-Source-Mixed-Multiple-Target Domain Adaptation (S²M²T DA) Scenarios. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Liu, M.; Jiao, L.; Liu, X.; Li, L.; Liu, F.; Yang, S. C-CNN: Contourlet convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2636–2649. [Google Scholar] [CrossRef] [PubMed]
- Bi, Q.; Qin, K.; Zhang, H.; Xie, J.; Li, Z.; Xu, K. APDC-Net: Attention pooling-based convolutional network for aerial scene classification. Remote Sens. Lett. 2019, 9, 1603–1607. [Google Scholar] [CrossRef]
- Li, W.; Wang, Z.; Wang, Y.; Wu, J.; Wang, J.; Jia, Y.; Gui, G. Classification of high spatial resolution remote sensing scenes methodusing transfer learning and deep convolutional neural network. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 13, 1986–1995. [Google Scholar] [CrossRef]
- Aral, R.A.; Keskin, Ş.R.; Kaya, M.; Hacıömeroğlu, M. Classification of trashnet dataset based on deep learning models. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1986–1995. [Google Scholar] [CrossRef]
- Pan, H.; Pang, Z.; Wang, Y.; Wang, Y.; Chen, L. A New Image Recognition and Classification Method Combining Transfer Learning Algorithm and MobileNet Model for Welding Defects. IEEE Access 2020, 8, 119951–119960. [Google Scholar] [CrossRef]
- Pour, A.M.; Seyedarabi, H.; Jahromi, S.H.A.; Javadzadeh, A. Automatic Detection and Monitoring of Diabetic Retinopathy using Efficient Convolutional Neural Networks and Contrast Limited Adaptive Histogram Equalization. IEEE Access 2020, 8, 136668–136673. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. A two-stream deep fusion framework for high-resolution aerial scene classification. Comput. Intell. Neurosci. 2018, 2018, 1986–1995. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Zhang, Y.; Wang, S. A Lightweight and Discriminative Model for Remote Sensing Scene Classification With Multidilation Pooling Module. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 2636–2653. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.; Ding, L. Scene classification based on two-stage deep feature fusion. IEEE Geosci. Remote Sens. Lett. 2018, 15, 183–186. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Content |
|---|---|
| Processor | Inter Core i7-4700 CPU with 2.70 GHz |
| Memory | 64 GB |
| Operating system | CentOS 7.8 64 bit |
| Hard disk | 1T |
| GPU | NVIDIA Titan-X |
| Python | 3.7.2 |
| PyTorch | 1.4.0 |
| CUDA | 10.0 |
| Learning rate | |
| Momentum | 0.9 |
| Weight decay | |
| Batch | 16 |
| Saturation | 1.5 |
| Subdivisions | 64 |
| Models | Training Ratios | |
|---|---|---|
| 20% | 50% | |
| GIST [47] | ||
| LBP [47] | ||
| CH [47] | ||
| BoVM [47] | ||
| LLC [47] | ||
| BoVM+SPM [47] | ||
| AlexNet [51] | ||
| GoogLeNet [51] | ||
| VGG-D [51] | ||
| MGFN [31] | ||
| Proposed | ||
| Models | Training Ratios | |
|---|---|---|
| 20% | 50% | |
| CaffeNet [32] | ||
| VGG-VD-16 [32] | ||
| GoogLeNet [32] | ||
| Fusion by addition [17] | − | |
| LGRIN [9] | ||
| TEX-Net-LF [41] | ||
| DS-SURF-LLC+Mean-Std-LLC+ MO-CLBP-LLC [42] | ||
| LiG with RBF kernel [11] | ||
| ADPC-Net [56] | ||
| VGG19 [57] | ||
| ResNet50 [57] | ||
| InceptionV3 [57] | ||
| DenseNet121 [58] | ||
| DenseNet169 [58] | ||
| MobileNet [59] | ||
| EfficientNet [60] | ||
| Two-Stream Deep Fusion Framework [61] | ||
| Fine-tune MobileNet V2 [62] | ||
| SE-MDPMNet [62] | ||
| Two-Stage Deep Feature Fusion [63] | − | |
| Contourlet CNN [55] | − | |
| LCPP [53] | ||
| RSNet [30] | ||
| SPG-GAN [52] | ||
| TSAN [54] | ||
| LGDL [8] | ||
| Proposed | ||
| Models | OA (50%) | Kappa (%) | SD |
|---|---|---|---|
| CaffeNet [32] | |||
| VGG-VD-16 [32] | |||
| GoogLeNet [32] | |||
| Fusion by addition [17] | |||
| LGRIN [9] | |||
| TEX-Net-LF [41] | |||
| DS-SURF-LLC+Mean-Std-LLC+MO-CLBP-LLC [42] | |||
| LiG with RBF kernel [11] | |||
| ADPC-Net [56] | |||
| VGG19 [57] | |||
| ResNet50 [57] | |||
| InceptionV3 [57] | |||
| DenseNet121 [58] | |||
| DenseNet169 [58] | |||
| MobileNet [59] | |||
| EfficientNet [60] | |||
| Two-Stream Deep Fusion Framework [61] | |||
| Fine-tune MobileNet V2 [62] | |||
| SE-MDPMNet [62] | |||
| Two-Stage Deep Feature Fusion [63] | |||
| Contourlet CNN [55] | |||
| LCPP [53] | |||
| RSNet [30] | |||
| SPG-GAN [52] | |||
| TSAN [54] | |||
| LGDL [8] | |||
| Proposed |
| Models | Acc (%) | Parameters (M) | GMACs(G) | Velocity (Samples/sec) |
|---|---|---|---|---|
| CaffeNet [32] | 88.91 | 60.97 | 3.6532 | 32 |
| GoogLeNet [32] | 85.67 | 7 | 0.7500 | 37 |
| VGG-VD-16 [32] | 89.36 | 138.36 | 7.7500 | 35 |
| LGRIN [9] | 97.65 | 4.63 | 0.4933 | 36 |
| MobileNet V2 [39] | 91.23 | 3.5 | 0.3451 | 39 |
| LiG with RBF kernel [11] | 96.22 | 2.07 | 0.2351 | 43 |
| ResNet50 [57] | 93.81 | 25.61 | 1.8555 | 38 |
| Inception V3 [57] | 94.97 | 45.37 | 2.4356 | 21 |
| SE-MDPMNet [62] | 97.23 | 5.17 | 0.9843 | 27 |
| Contourlet CNN [55] | 96.87 | 12.6 | 1.0583 | 35 |
| RSNet [30] | 96.78 | 2.997 | 0.2735 | 47 |
| SPG-GAN [52] | 94.53 | 87.36 | 2.1322 | 29 |
| TSAN [54] | 92.16 | 381.67 | 3.2531 | 32 |
| LGDL [8] | 97.29 | 2.107 | 0.4822 | 35 |
| Proposed | 98.75 | 3.216 | 0.3602 | 49 |
| Models | Training Ratios | |
|---|---|---|
| 20% | 50% | |
| Traditional upsampling | ||
| Nearest neighbor interpolation sampling | ||
| Models | Training Ratios | |
|---|---|---|
| 20% | 50% | |
| Without SE and SF | ||
| SF and without SE | ||
| SE and without SF | ||
| Both SE and SF | ||
| Metrics | Competing Feature Fusion Technique | Our Feature-Level Fusion Scheme |
|---|---|---|
| Dimensionality of the fused feature | 16,900 | 116 |
| Training time for classification(s) | 1352.37 | 16.53 |
| Testing time for classification(s) | 72.83 | 2.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, C.; Shu, J.; Zhu, G. Scene Classification Based on Heterogeneous Features of Multi-Source Data. Remote Sens. 2023, 15, 325. https://doi.org/10.3390/rs15020325
Xu C, Shu J, Zhu G. Scene Classification Based on Heterogeneous Features of Multi-Source Data. Remote Sensing. 2023; 15(2):325. https://doi.org/10.3390/rs15020325
Chicago/Turabian StyleXu, Chengjun, Jingqian Shu, and Guobin Zhu. 2023. "Scene Classification Based on Heterogeneous Features of Multi-Source Data" Remote Sensing 15, no. 2: 325. https://doi.org/10.3390/rs15020325
APA StyleXu, C., Shu, J., & Zhu, G. (2023). Scene Classification Based on Heterogeneous Features of Multi-Source Data. Remote Sensing, 15(2), 325. https://doi.org/10.3390/rs15020325