

Revealing the Potential of Deep Learning for Detecting Submarine Pipelines in Side-Scan Sonar Images: An Investigation of Pre-Training Datasets


Abstract
:1. Introduction
2. Applied CNN Model
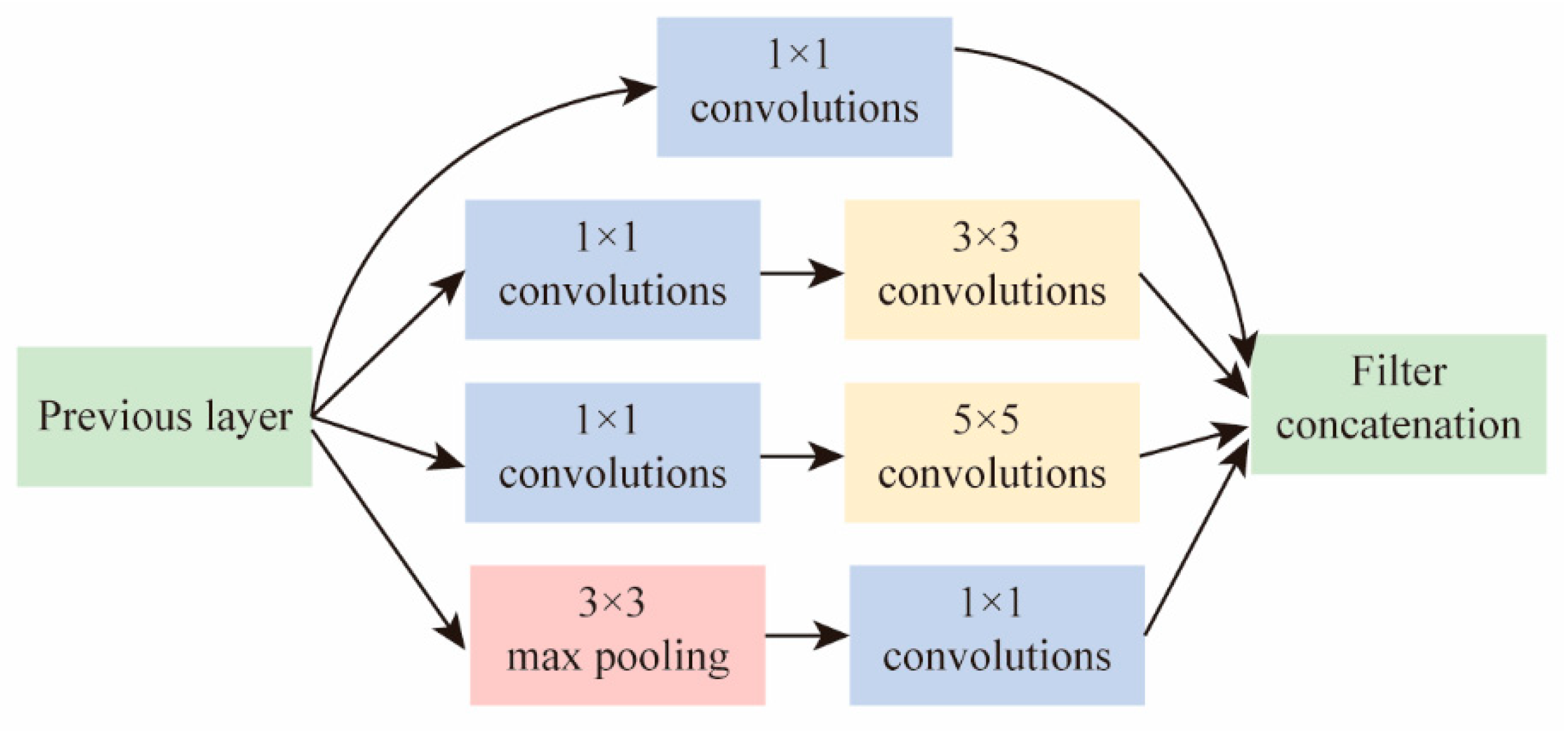
2.1. GoogleNet
2.2. Transfer Learning
3. Materials and Methods
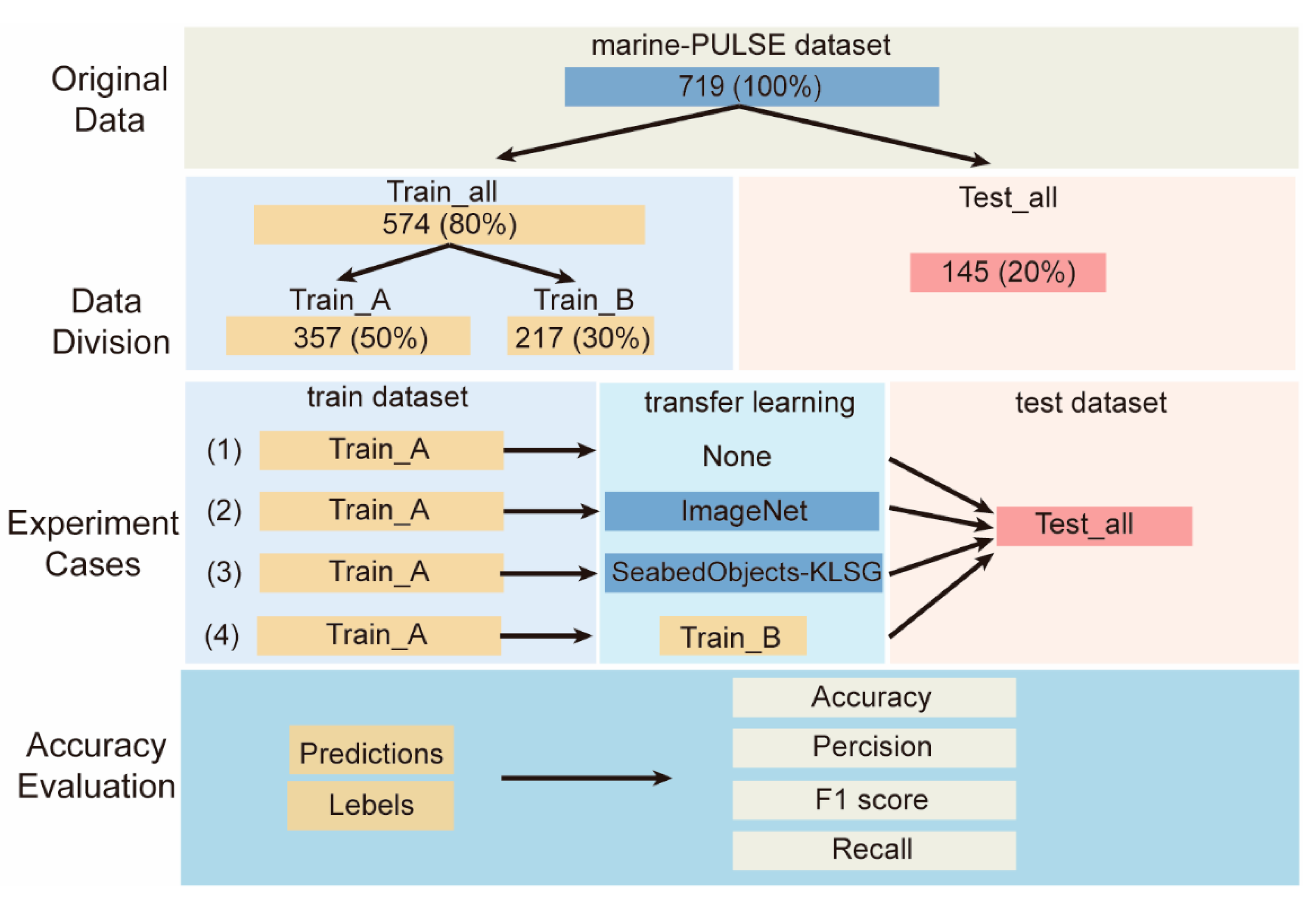
3.1. Dataset
3.2. Experimental Steps
3.2.1. Data Preprocessing
3.2.2. Data Augmentation
3.2.3. Establishing CNN Models
3.2.4. Model Evaluation
3.3. Experimental Environment
4. Results and Analysis
4.1. Accuracy of GoogleNet for SSS Image Recognition of POCs
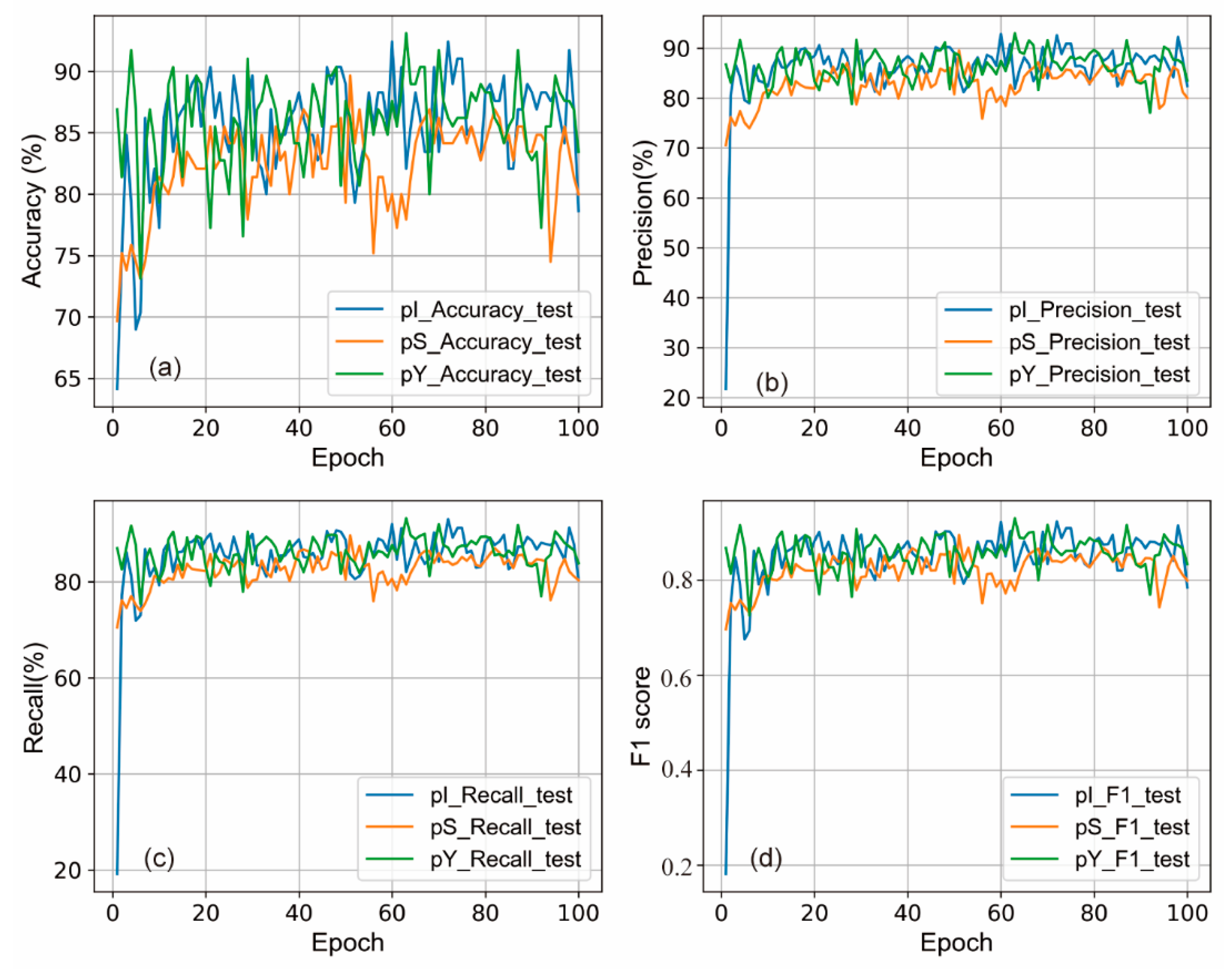
4.2. Model Performance with and without Transfer Learning
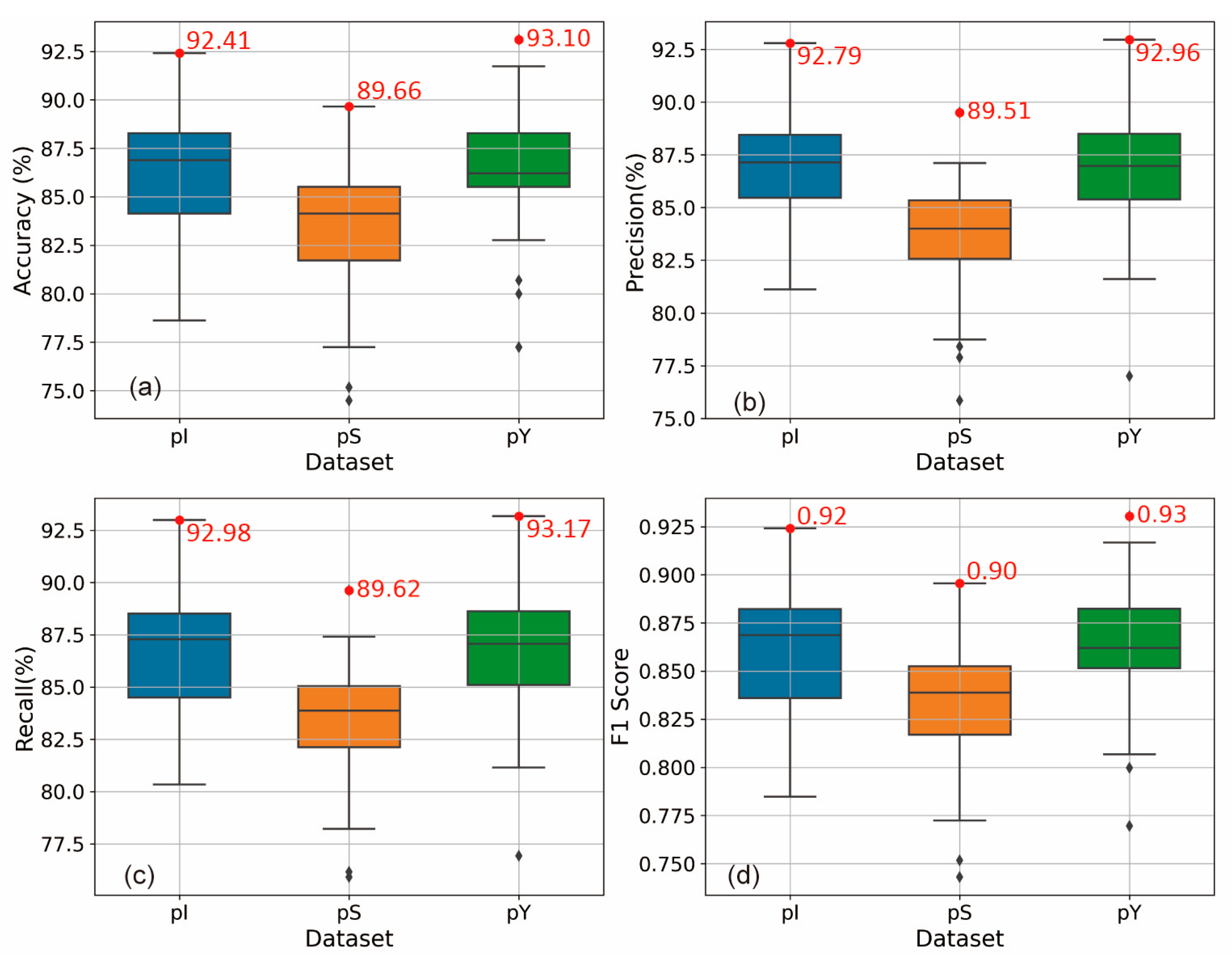
4.3. Performance Comparison Using Different Pre-Training Datasets
5. Discussion
6. Conclusions
- (1)
- Utilizing GoogleNet modeling permitted efficient identification of SSS images of underwater pipelines, with accuracy and precision rates exceeding 90%.
- (2)
- Transfer learning significantly enhanced the accuracy of the model. The model could reach up to 80% accuracy without pre-training. Following pre-training with the ImageNet dataset, the model’s prediction accuracy could be boosted by approximately 10% compared to when there was no pre-training.
- (3)
- Different pre-training datasets yielded varying impacts on model prediction accuracy. The datasets that enhanced the model prediction ability, ranked in descending order of effectiveness, were Marine-PULSE, ImageNet, and SeabedObjects-KLSG.
- (4)
- The type of pre-training dataset, the volume of data, and the consistency with the predicted data are crucial factors influencing the pre-training effect. When the consistency is very high, even a minimal amount of data can yield a satisfactory pre-training effect. Conversely, when consistency is low, a dataset with a large volume of data and good generalization should be selected.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gašparović, B.; Lerga, J.; Mauša, G.; Ivašić-Kos, M. Deep Learning Approach For Objects Detection in Underwater Pipeline Images. Appl. Artif. Intell. 2022, 36, 2146853. [Google Scholar] [CrossRef]
- Sung, M.; Kim, J.; Lee, M.; Kim, B.; Kim, T.; Kim, J.; Yu, S.-C. Realistic Sonar Image Simulation Using Deep Learning for Underwater Object Detection. Int. J. Control Autom. Syst. 2020, 18, 523–534. [Google Scholar] [CrossRef]
- Wang, H.; Gao, N.; Xiao, Y.; Tang, Y. Image Feature Extraction Based on Improved FCN for UUV Side-Scan Sonar. Mar. Geophys. Res. 2020, 41, 18. [Google Scholar] [CrossRef]
- Fan, X.; Lu, L.; Shi, P.; Zhang, X. A Novel Sonar Target Detection and Classification Algorithm. Multimed. Tools Appl. 2022, 81, 10091–10106. [Google Scholar] [CrossRef]
- Pouyan, S.; Pourghasemi, H.R.; Bordbar, M.; Rahmanian, S.; Clague, J.J. A Multi-Hazard Map-Based Flooding, Gully Erosion, Forest Fires, and Earthquakes in Iran. Sci. Rep. 2021, 11, 14889. [Google Scholar] [CrossRef]
- St. Denis, L.A.; Short, K.C.; McConnell, K.; Cook, M.C.; Mietkiewicz, N.P.; Buckland, M.; Balch, J.K. All-Hazards Dataset Mined from the US National Incident Management System 1999–2020. Sci. Data 2023, 10, 112. [Google Scholar] [CrossRef]
- Zhao, C.; Lu, Z. Remote Sensing of Landslides—A Review. Remote Sens. 2018, 10, 279. [Google Scholar] [CrossRef]
- Xu, S.; Dimasaka, J.; Wald, D.J.; Noh, H.Y. Seismic Multi-Hazard and Impact Estimation via Causal Inference from Satellite Imagery. Nat. Commun. 2022, 13, 7793. [Google Scholar] [CrossRef]
- Stanley, T.A.; Kirschbaum, D.B.; Sobieszczyk, S.; Jasinski, M.F.; Borak, J.S.; Slaughter, S.L. Building a Landslide Hazard Indicator with Machine Learning and Land Surface Models. Environ. Model. Softw. 2020, 129, 104692. [Google Scholar] [CrossRef]
- Ma, Z.; Mei, G. Deep Learning for Geological Hazards Analysis: Data, Models, Applications, and Opportunities. Earth-Sci. Rev. 2021, 223, 103858. [Google Scholar] [CrossRef]
- Mousavi, S.M.; Ellsworth, W.; Weiqiang, Z.; Chuang, L.; Beroza, G. Earthquake Transformer—An Attentive Deep-Learning Model for Simultaneous Earthquake Detection and Phase Picking. Nat. Commun. 2020, 11, 3952. [Google Scholar] [CrossRef]
- Rateria, G.; Maurer, B.W. Evaluation and Updating of Ishihara’s (1985) Model for Liquefaction Surface Expression, with Insights from Machine and Deep Learning. Soils Found. 2022, 62, 101131. [Google Scholar] [CrossRef]
- Jones, S.; Kasthurba, A.K.; Bhagyanathan, A.; Binoy, B.V. Landslide Susceptibility Investigation for Idukki District of Kerala Using Regression Analysis and Machine Learning. Arab. J. Geosci. 2021, 14, 838. [Google Scholar] [CrossRef]
- Chang, Z.; Du, Z.; Zhang, F.; Huang, F.; Chen, J.; Li, W.; Guo, Z. Landslide Susceptibility Prediction Based on Remote Sensing Images and GIS: Comparisons of Supervised and Unsupervised Machine Learning Models. Remote Sens. 2020, 12, 502. [Google Scholar] [CrossRef]
- Jena, R.; Pradhan, B.; Beydoun, G.; Al-Amri, A.; Sofyan, H. Seismic Hazard and Risk Assessment: A Review of State-of-the-Art Traditional and GIS Models. Arab. J. Geosci. 2020, 13, 50. [Google Scholar] [CrossRef]
- Du, X.; Sun, Y.; Song, Y.; Xiu, Z.; Su, Z. Submarine Landslide Susceptibility and Spatial Distribution Using Different Unsupervised Machine Learning Models. Appl. Sci. 2022, 12, 10544. [Google Scholar] [CrossRef]
- Abadi, S. Using Machine Learning in Ocean Noise Analysis during Marine Seismic Reflection Surveys. J. Acoust. Soc. Am. 2018, 144, 1744. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Raaza, A.; Rajendran, V.; Ravikumar, D. Side Scan Sonar Image Augmentation for Sediment Classification Using Deep Learning Based Transfer Learning Approach. Mater. Today Proc. 2023, 80, 3263–3273. [Google Scholar] [CrossRef]
- Nayak, N.; Nara, M.; Gambin, T.; Wood, Z.; Clark, C.M. Machine Learning Techniques for AUV Side-Scan Sonar Data Feature Extraction as Applied to Intelligent Search for Underwater Archaeological Sites. In Proceedings of the Field and Service Robotics; Ishigami, G., Yoshida, K., Eds.; Springer: Singapore, 2021; pp. 219–233. [Google Scholar]
- Pillay, T.; Cawthra, H.C.; Lombard, A.T. Integration of Machine Learning Using Hydroacoustic Techniques and Sediment Sampling to Refine Substrate Description in the Western Cape, South Africa. Mar. Geol. 2021, 440, 106599. [Google Scholar] [CrossRef]
- Juliani, C.; Juliani, E. Deep Learning of Terrain Morphology and Pattern Discovery via Network-Based Representational Similarity Analysis for Deep-Sea Mineral Exploration. Ore Geol. Rev. 2021, 129, 103936. [Google Scholar] [CrossRef]
- Pillay, T.; Cawthra, H.C.; Lombard, A.T. Characterisation of Seafloor Substrate Using Advanced Processing of Multibeam Bathymetry, Backscatter, and Sidescan Sonar in Table Bay, South Africa. Mar. Geol. 2020, 429, 106332. [Google Scholar] [CrossRef]
- Sircar, A.; Yadav, K.; Rayavarapu, K.; Bist, N.; Oza, H. Application of Machine Learning and Artificial Intelligence in Oil and Gas Industry. Pet. Res. 2021, 6, 379–391. [Google Scholar] [CrossRef]
- Jin, L.; Liang, H.; Yang, C. Accurate Underwater ATR in Forward-Looking Sonar Imagery Using Deep Convolutional Neural Networks. IEEE Access 2019, 7, 125522–125531. [Google Scholar] [CrossRef]
- Yulin, T.; Jin, S.; Bian, G.; Zhang, Y. Shipwreck Target Recognition in Side-Scan Sonar Images by Improved YOLOv3 Model Based on Transfer Learning. IEEE Access 2020, 8, 173450–173460. [Google Scholar] [CrossRef]
- Zhu, B.; Wang, X.; Chu, Z.; Yang, Y.; Shi, J. Active Learning for Recognition of Shipwreck Target in Side-Scan Sonar Image. Remote Sens. 2019, 11, 243. [Google Scholar] [CrossRef]
- Xiong, C.; Lian, S.; Chen, W. An Ensemble Method for Automatic Real-Time Detection, Evaluation and Position of Exposed Subsea Pipelines Based on 3D Real-Time Sonar System. J. Civil Struct. Health Monit. 2023, 13, 485–504. [Google Scholar] [CrossRef]
- Yan, J.; Meng, J.; Zhao, J. Bottom Detection from Backscatter Data of Conventional Side Scan Sonars through 1D-UNet. Remote Sens. 2021, 13, 1024. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, H.; Zhang, G.; Ren, J.; Xu, H.; Xu, C. DP-ViT: A Dual-Path Vision Transformer for Real-Time Sonar Target Detection. Remote Sens. 2022, 14, 5807. [Google Scholar] [CrossRef]
- Du, X.; Sun, Y.; Song, Y.; Sun, H.; Yang, L. A Comparative Study of Different CNN Models and Transfer Learning Effect for Underwater Object Classification in Side-Scan Sonar Images. Remote Sens. 2023, 15, 593. [Google Scholar] [CrossRef]
- Huo, G.; Wu, Z.; Li, J. Underwater Object Classification in Sidescan Sonar Images Using Deep Transfer Learning and Semisynthetic Training Data. IEEE Access 2020, 8, 47407–47418. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Bousmalis, K.; Trigeorgis, G.; Silberman, N.; Krishnan, D.; Erhan, D. Domain Separation Networks. arXiv 2016, arXiv:1608.06019. [Google Scholar]
- Pires de Lima, R.; Marfurt, K. Convolutional Neural Network for Remote-Sensing Scene Classification: Transfer Learning Analysis. Remote Sens. 2020, 12, 86. [Google Scholar] [CrossRef]
- Rostami, M.; Kolouri, S.; Eaton, E.; Kim, K. Deep Transfer Learning for Few-Shot SAR Image Classification. Remote Sens. 2019, 11, 1374. [Google Scholar] [CrossRef]
- Koga, Y.; Miyazaki, H.; Shibasaki, R. A Method for Vehicle Detection in High-Resolution Satellite Images That Uses a Region-Based Object Detector and Unsupervised Domain Adaptation. Remote Sens. 2020, 12, 575. [Google Scholar] [CrossRef]
- Du, X. Side-Scan Sonar Images of Marine Engineering Geology (Marine_PULSE Dataset); Zenodo: Geneva, Switzerland, 2023. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Label/True Label | Positive Sample (POC) | Negative Sample (Non-POC) |
|---|---|---|
| Positive Sample (POC) | TP | FN |
| Negative Sample (Non-POC) | FP | TN 1 |
| Dataset | Types/Categories | Volume/Size | Consistency 1 |
|---|---|---|---|
| ImageNet | 1000 | 150 GB | Low |
| SeabedObjects-KLSG | 2 | 67.5 M | Median |
| Marine-PULSE (train_B) | 2 | 22.2 M | Very High |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, X.; Sun, Y.; Song, Y.; Dong, L.; Zhao, X. Revealing the Potential of Deep Learning for Detecting Submarine Pipelines in Side-Scan Sonar Images: An Investigation of Pre-Training Datasets. Remote Sens. 2023, 15, 4873. https://doi.org/10.3390/rs15194873
Du X, Sun Y, Song Y, Dong L, Zhao X. Revealing the Potential of Deep Learning for Detecting Submarine Pipelines in Side-Scan Sonar Images: An Investigation of Pre-Training Datasets. Remote Sensing. 2023; 15(19):4873. https://doi.org/10.3390/rs15194873
Chicago/Turabian StyleDu, Xing, Yongfu Sun, Yupeng Song, Lifeng Dong, and Xiaolong Zhao. 2023. "Revealing the Potential of Deep Learning for Detecting Submarine Pipelines in Side-Scan Sonar Images: An Investigation of Pre-Training Datasets" Remote Sensing 15, no. 19: 4873. https://doi.org/10.3390/rs15194873
APA StyleDu, X., Sun, Y., Song, Y., Dong, L., & Zhao, X. (2023). Revealing the Potential of Deep Learning for Detecting Submarine Pipelines in Side-Scan Sonar Images: An Investigation of Pre-Training Datasets. Remote Sensing, 15(19), 4873. https://doi.org/10.3390/rs15194873