
Deep Learning for Remote Sensing Image Scene Classification: A Review and Meta-Analysis




Abstract
:
1. Introduction
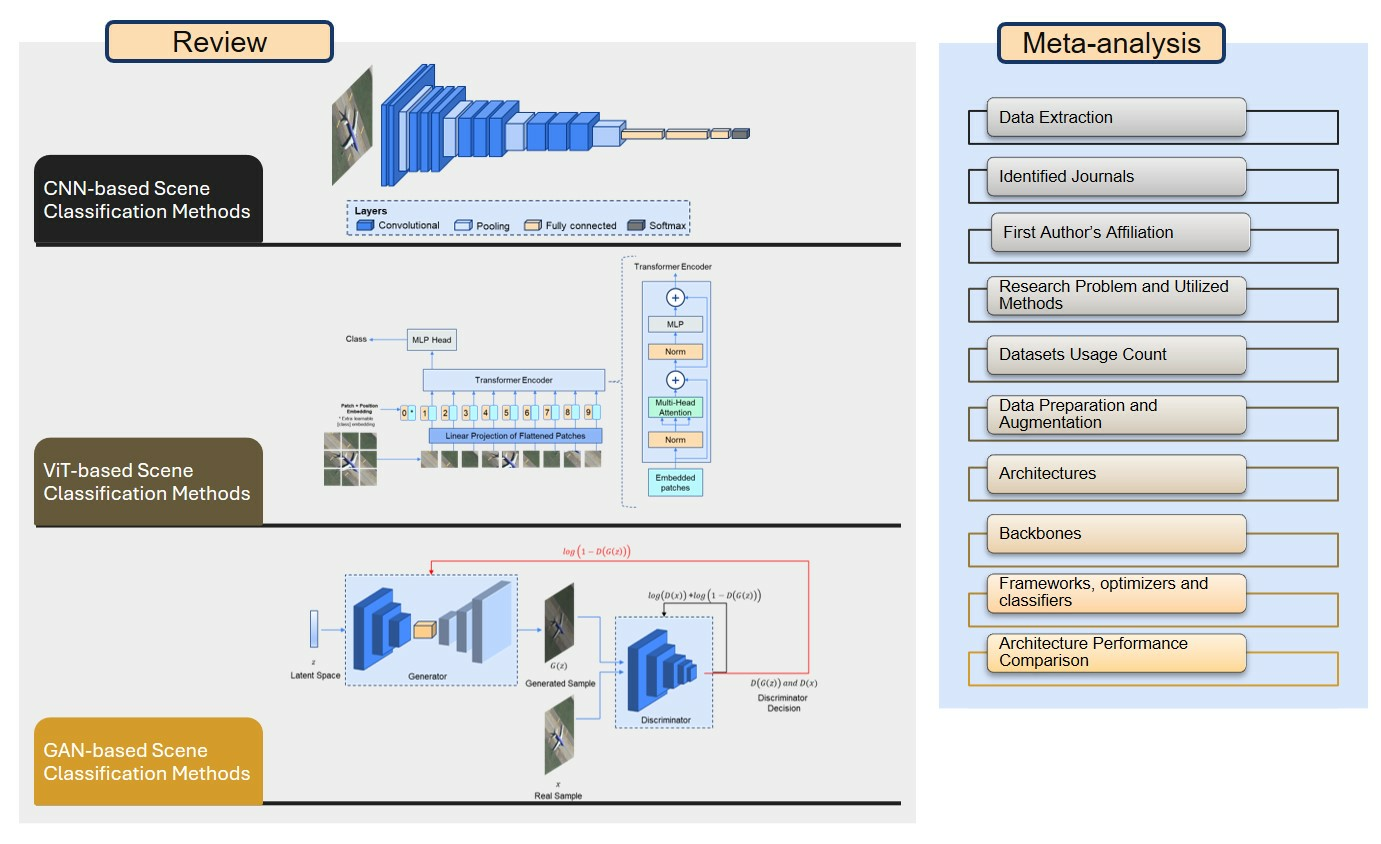
- We present an up-to-date review offering insights into remote sensing scene datasets and DL feature extraction methods, encompassing CNN-based, ViT-based and GAN-based approaches, through a comprehensive examination of relevant studies.
- We conduct a novel meta-analysis of 50 peer-reviewed articles in the DL-driven remote sensing scene classification domain. We pinpoint the critical problems and recognize emerging trends and paradigm shifts in this field.
- We identify and discuss key challenges in this domain while also providing valuable insights into future research directions.
2. Understanding Remote Sensing Image Scene and Deep Learning Feature Extraction
2.1. High-Resolution Scene Classification Datasets
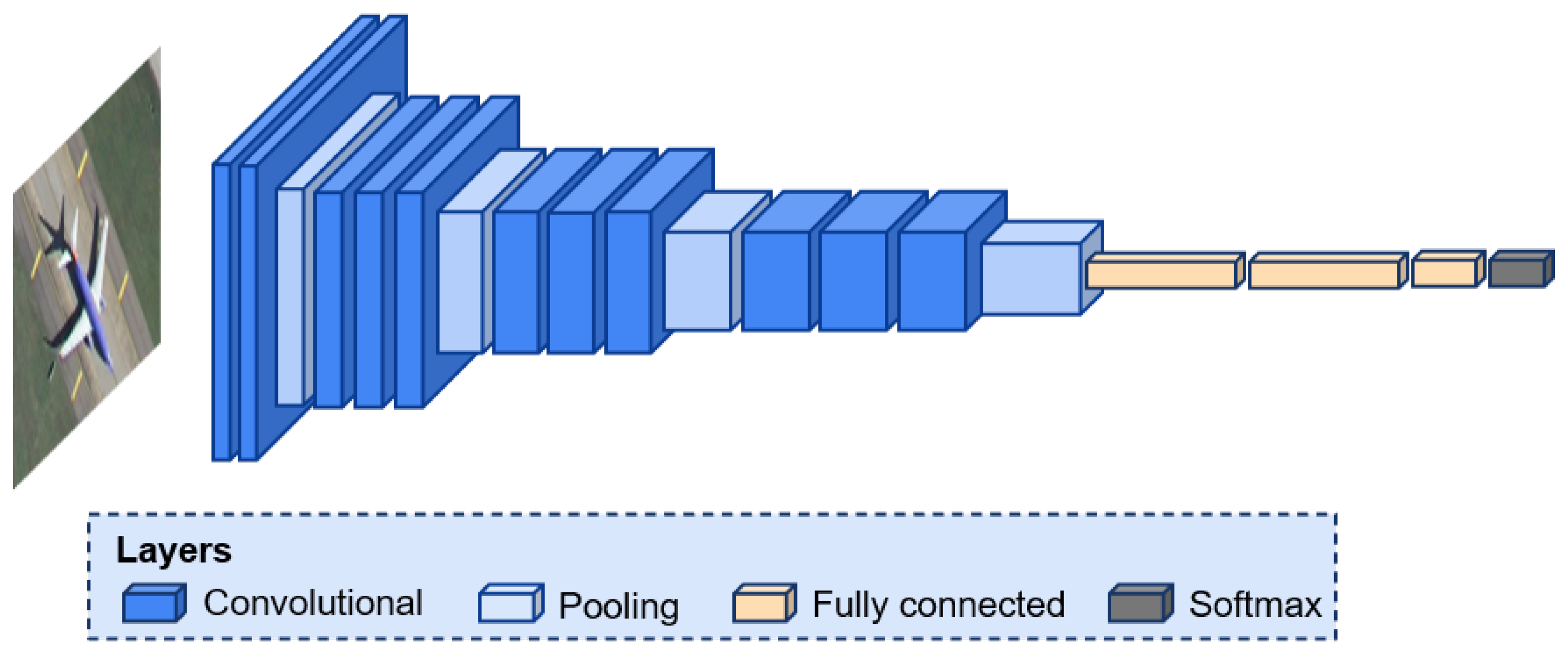
2.2. CNN-Based Scene Classification Methods
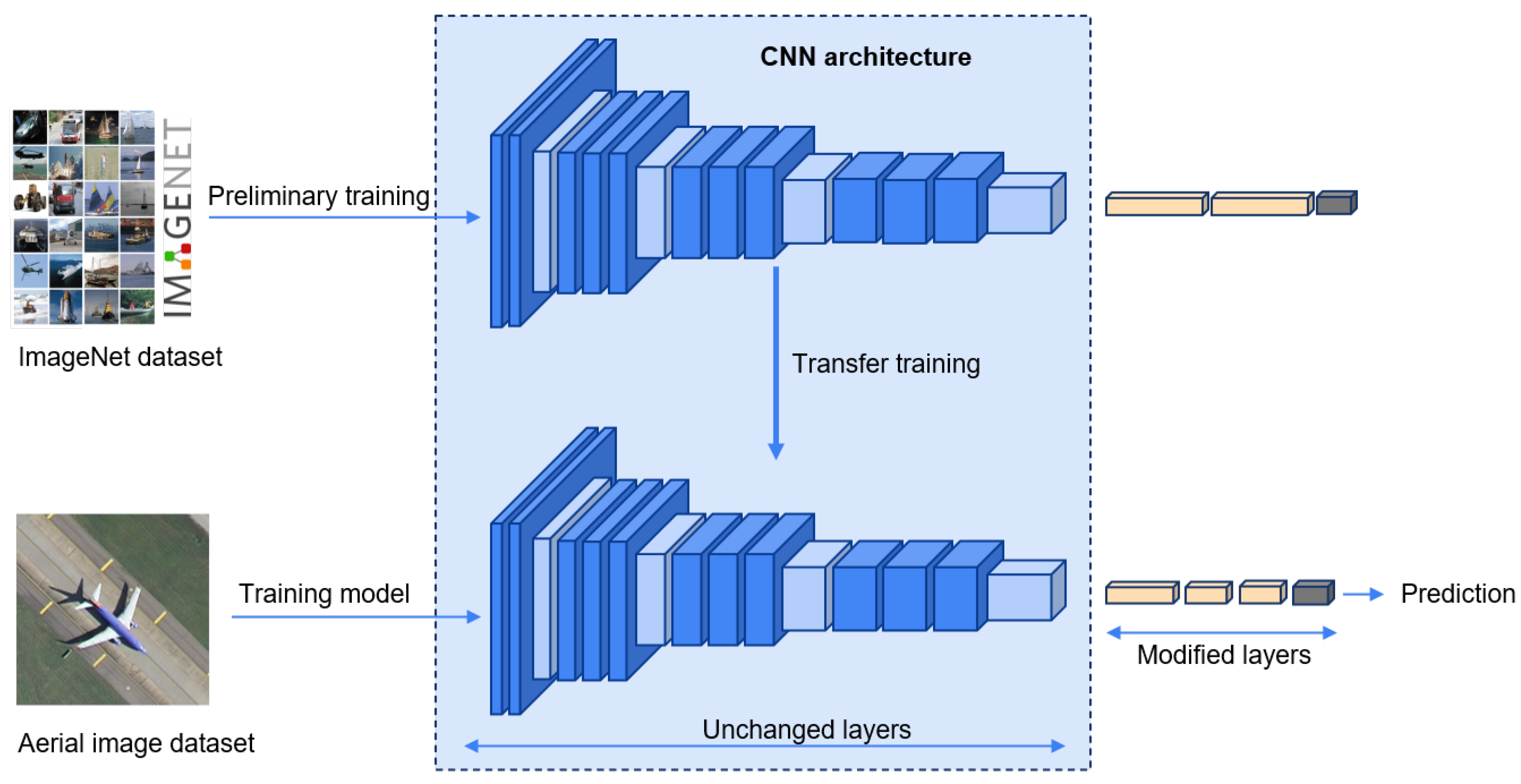
2.2.1. Pretrained CNNs for Feature Extraction
2.2.2. CNNs Trained from Scratch
2.3. Vision Transformer-Based Scene Classification Methods
2.4. GAN-Based Scene Classification Methods
3. Meta-Analysis
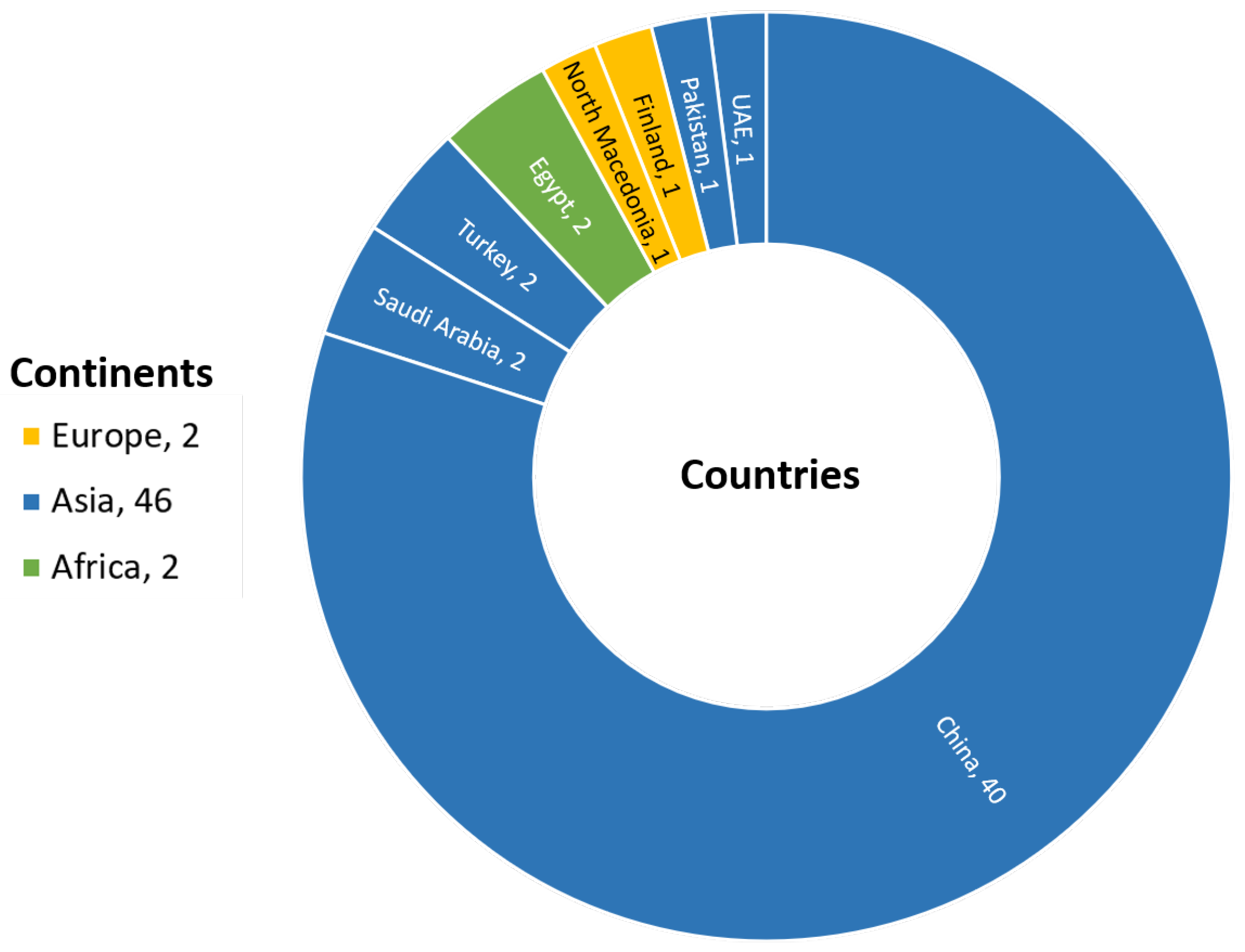
3.1. Data Extraction
3.2. Research Problem and Utilized Research Techniques
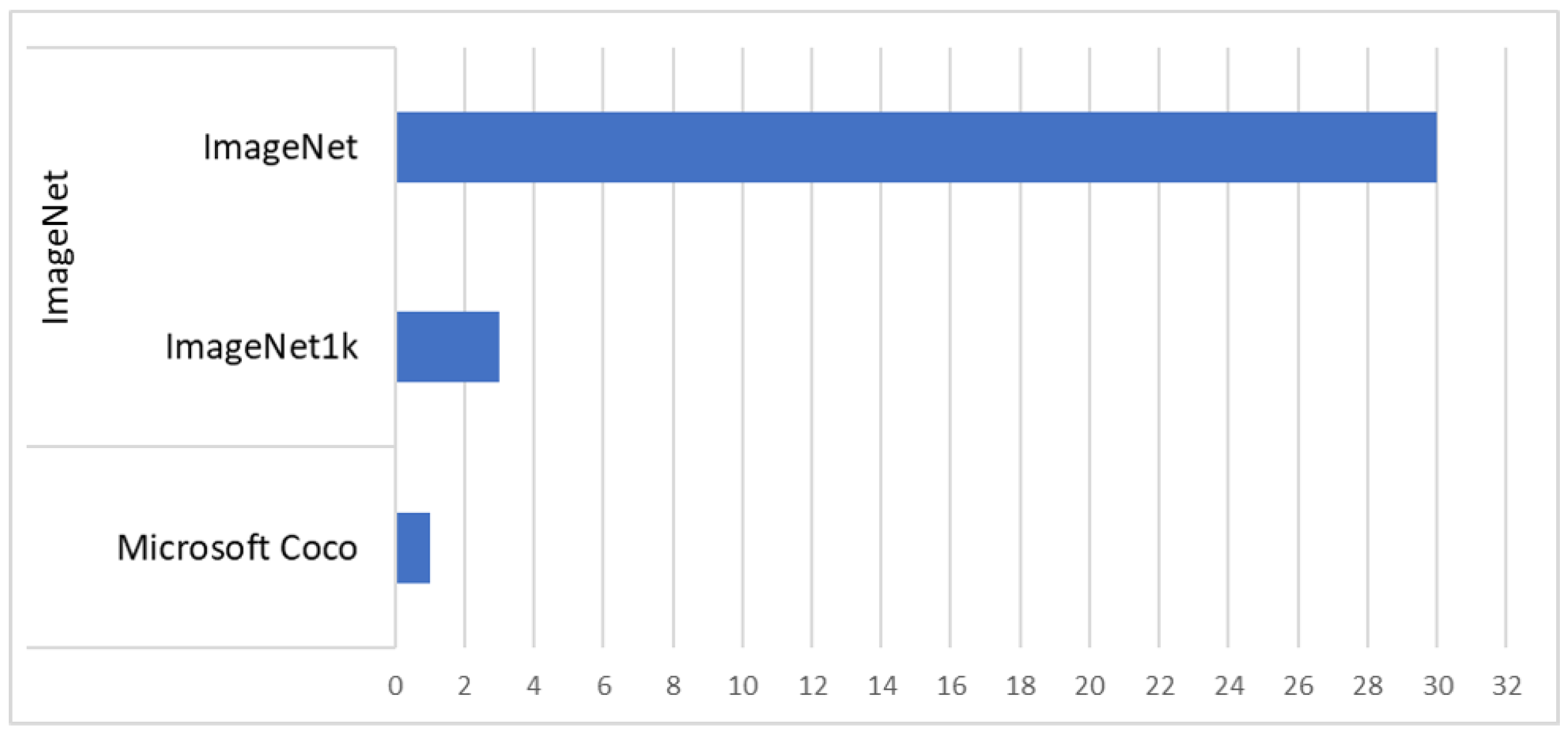
3.3. Dataset Usage Frequency
3.4. Data Preparation and Augmentation
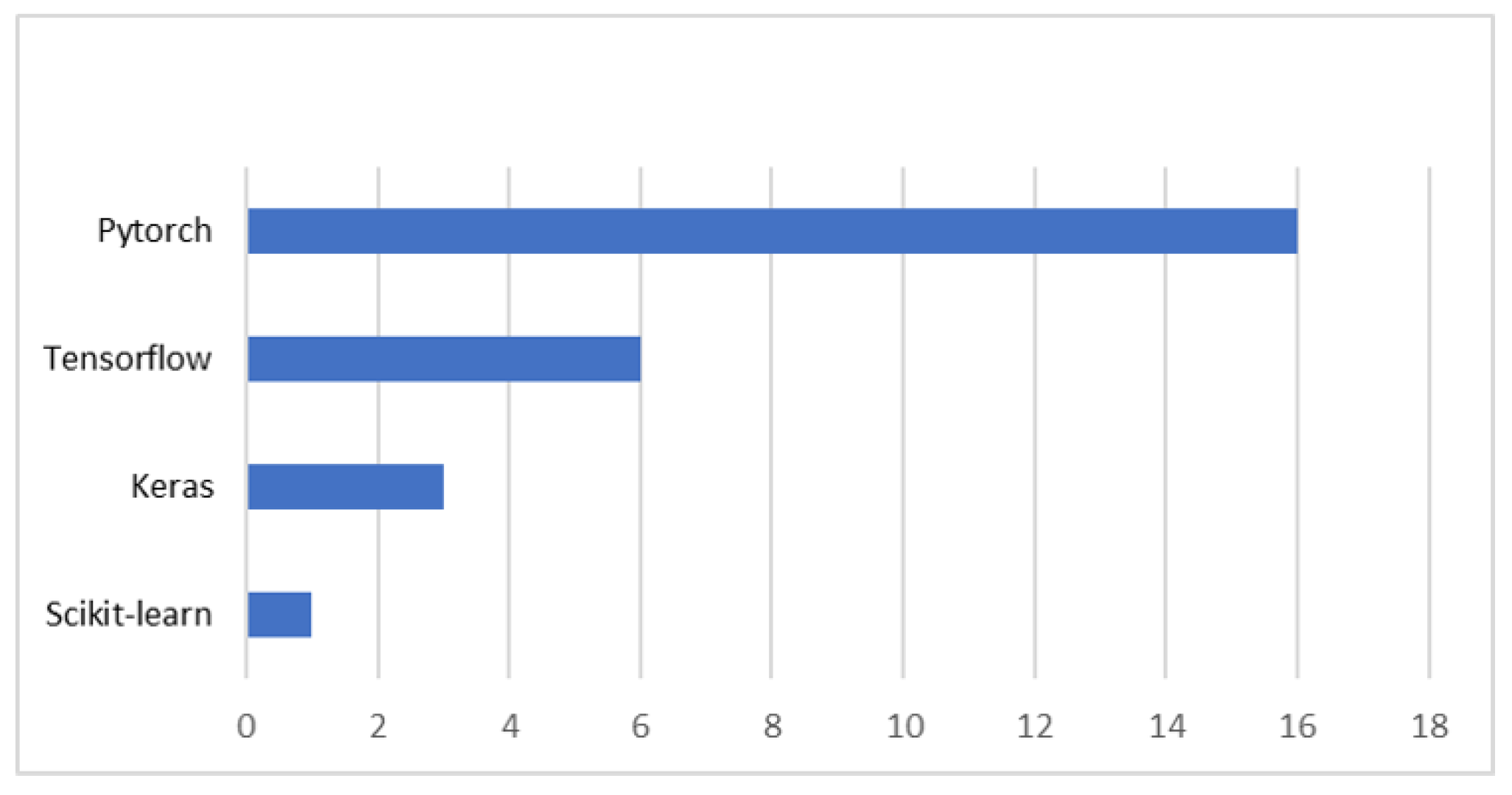
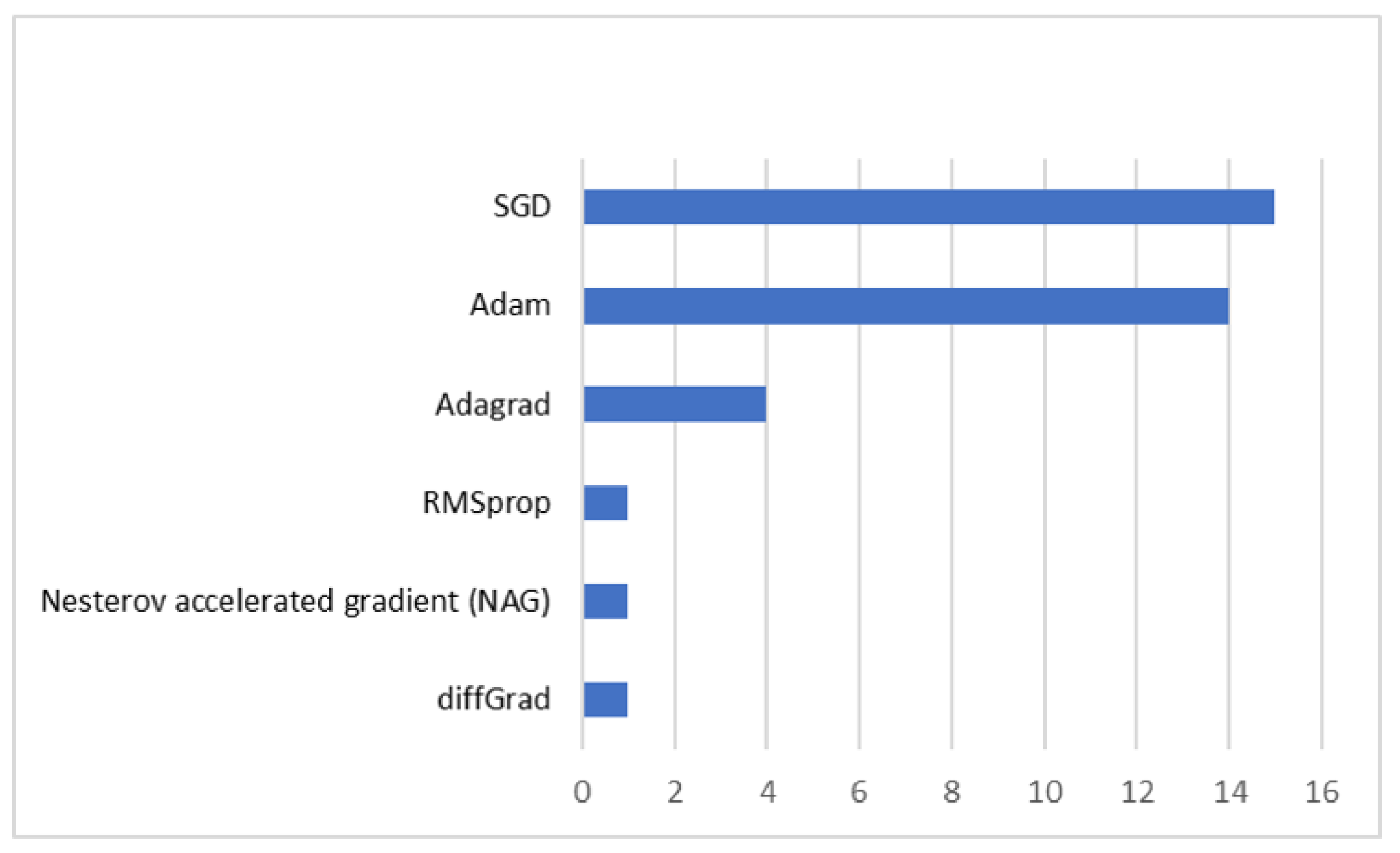
3.5. Training Details
3.6. Architecture Performance Comparison
4. Discussion
4.1. DL’s Performance Dependency on Datasets
4.2. Low Accuracy in GAN-Based Methods
4.3. Shift of Paradigm in Scene Classification Architectures
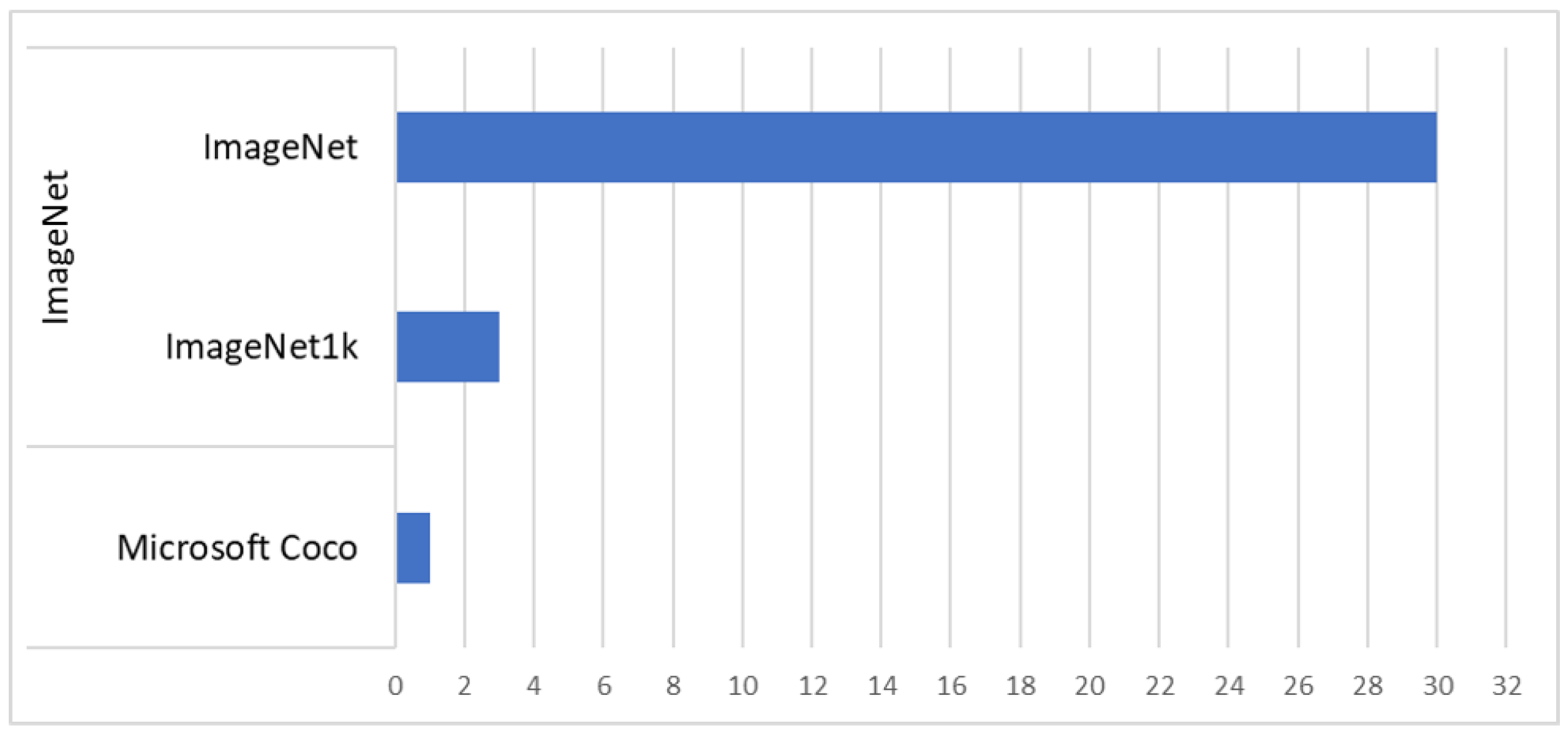
4.4. Dependency on Pretrained Models
4.5. Challenges and Future Opportunities
4.5.1. Requirement of Large Annotated Datasets
4.5.2. Preservation of Local-Global Features
4.5.3. Self-Supervised Learning for Scene Classification
4.5.4. Learning with Few Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
| DL | Deep Learning |
| GAN | Generative Adversarial Network |
| VHR | Very High-Resolution |
| LULC | Land Use and Land Cover |
| SIFT | Scale-Invariant Feature Transform |
| LBP | Local Binary Pattern |
| CH | Color Histogram |
| GLCM | Grey Level Co-occurrence Matrix |
| HOG | Histogram of Oriented Gradients |
| BoVW | Bag-of-visual-words |
| ResNet | Residual Network |
| UCM/UC-Merced | UC Merced Land Use Dataset |
| USGS | United States Geological Survey |
| AID | Aerial Image Dataset |
| ReLU | Rectified Linear Unit |
| FC | Fully Connected |
| SGD | Stochastic Gradient Descent |
| MCPSF | Multi-level convolutional pyramid semantic fusion |
| PMS | Parallel Multi-stage |
| DCNN | Deep Convolutional Neural Network |
| BLS | Broad Learning System |
| iBoVW | Improved Bag-of-visual words |
| FPN | Feature Pyramid Network |
| COCO | Common Objects in Context |
| RDB | Residual Dense Network |
| MSA-Network | Multiscale Attention Network |
| CPA | Channel and Position Attention |
| MVFL | Multi-view Feature Learning Network |
| EAM | Enhanced Attention Module |
| MINet | Multilevel Inheritance Network |
| TRS | Remote Sensing Transformer |
| MHSA | Multi-Head Self-Attention |
| STB | Swin Transformer Block |
| CSA | Channel-Spatial Attention |
| ViT | Vision Transformer |
| CSAT | Channel-Spatial Attention Transformers |
| EMTCAL | Efficient Multiscale Transformer and Cross-level Attention learning |
| DeiT | Data-efficient Image Transformer |
| CL | Contrastive Learning |
| LG-ViT | Local–global Interactive ViT |
| SCCov | Skip-connected covariance |
| MSA | Multi-head Self-Attention |
| MLP | Multi-layer Perceptron |
| LN | Layernorm |
| GELU | Gaussian Error Linear Unit |
| MARTA GANs | Multiple-layer Feature-matching Generative Adversarial Networks |
| SELU | Scaled Exponential Linear Unit |
| MF-WGANs | Multilayer Feature Fusion Wasserstein Generative Adversarial Networks |
| MIL | Multiple Instance Learning |
| DCA | Discriminant Correlation Analysis |
| NAG | Nesterov accelerated gradient |
| SVM | Support Vector Machine |
| OA | Overall Accuracy |
| LCPP | Local and Convolutional Pyramid based Pooling-stretched |
| AGOS | All Grains, One Scheme |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Link |
|---|---|
| UCM | http://weegee.vision.ucmerced.edu/datasets/landuse.html (accessed on 24 July 2023) |
| AID | www.lmars.whu.edu.cn/xia/AID-project.html (accessed on 24 July 2023) |
| WHU-RS19 | http://gpcv.whu.edu.cn/data (accessed on 24 July 2023) |
| NWPU-RESISC45 | https://gcheng-nwpu.github.io (accessed on 24 July 2023) |
| PatternNet | https://sites.google.com/view/zhouwx/dataset (accessed on 24 July 2023) |
| OPTIMAL-31 | https://1drv.ms/u/s!Ags4cxbCq3lUguxW3bq0D0wbm1zCDQ (accessed on 24 July 2023) |
| SIRI-WHU | https://figshare.com/articles/dataset/SIRI_WHU_Dataset/8796980 (accessed on 24 July 2023) |
| RSSCN7 | https://sites.google.com/site/qinzoucn/documents (accessed on 24 July 2023) |
| RSI-CB | https://github.com/lehaifeng/RSI-CB (accessed on 24 July 2023) |
| KSA | [59] |
| Corel | https://archive.ics.uci.edu/dataset/119/corel+image+features (accessed on 24 July 2023) |
| IP | https://purr.purdue.edu/publications/1947/1 (accessed on 24 July 2023) |
Appendix B
| S.N | Paper Ref. | Datasets Used | Data Preparation | Data Augmentation | Architectures Used | Backbone | Backbones Pre-Trained on | Framework | Optimizer | Classifier |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | [49] | NWPU-RESISC45 | Fine-tuned AlexNet, VGG-16 and GoogLeNet | AlexNet, VGG-16 and GoogLeNet | ImageNet | SVM | ||||
| 2 | [78] | UCM, WHU-RS, AID and NWPU-RESISC45 | Images are resized according to the size of the receptive field of the selected CNN model. | No | CaffeNet, VGG-Net-16 and GoogleNet | CaffeNet, VGG-Net-16 and GoogleNet | ImageNet | |||
| 3 | [79] | UCM and AID | UCM data expands from 2100 to 252,000 images. Each image rotated ±7° from each 90° rotated image (15 rotations for each 90° basic rotation) and expanded to 30 images. Rotations exceeding ±7° range from the 0°, 90°, 180°, and 270°, each image expanded to 120 images. | GoogleNet | GoogleNet | ImageNet | SVM | |||
| 4 | [46] | UCM, WHU-RS19, RSSCN7 and AID | Images are resized to 224 × 224 pixels for both VGG-M and ResNet-50. | Tex-Net | VGG-M and Resnet-50 | ImageNet | SVM | |||
| 5 | [83] | UCM, AID and NWPU-RESISC45 | GoogleNet | GoogleNet | ImageNet | Tensorflow | ELM | |||
| 6 | [146] | UCM, WHU-RS19, AID and NWPU-RESISC45 | Images are resized to meet the input are of each CNN (224 × 224 or 227 × 227). | CaffeNet, GoogLeNet, VGG-F, VGG-S, VGG-M, VGG-16, VGG-19 and ResNet-50 | CaffeNet, GoogLeNet, VGG-F, VGG-S, VGG-M, VGG-16, VGG-19 and ResNet-50 | ImageNet | SVM | |||
| 7 | [73] | UCM, AID, NPWU, PatternNet and a new multiple domain dataset created from four heterogeneous scene datasets | For suitability of datasets suitable for multisource domain adaption, only 12 shared classes are considered. | MB-Net | ResNet-50 | ImageNet | Adam | |||
| 8 | [84] | UCM and AID | Images are resized to 300 × 300 pixels. | Rotation (90°, 180°, and 270°) and flip (horizontal and vertical). Texture images rotation (90°, 180°, and 270°). | CTFCNN | CaffeNet | ImageNet | SVM | ||
| 9 | [95] | UCM, AID, OPTIMAL-31 and NWPU-RESISC45 | Accept image that are different sizes. | Color transformation, brightness transformation, contrast transformation, and sharpness transformation | DenseNet | DenseNet | ImageNet | PyTorch0.4.1 | SGD | Softmax |
| 10 | [33] | UCM, AID and NWPU-RESISC45 | AID dataset images are resized to 256 × 256 pixels. | CNN-CapsNet | VGG-16 and Inception-V3 | ImageNet | Keras | Adam | CapsNet | |
| 11 | [153] | AID and NWPU-RESISC45 | InceptionNet and DenseNet (for heterogeneous used combined) | InceptionNet and DenseNet | MLP | |||||
| 12 | [155] | UCM, NWPU-RESISC45 and SIRI-WHU | Inception-LSTM | Inception-V3 | Adagrad or RMSprop | Softmax | ||||
| 13 | [86] | NWPU-RESISC45, AID and OPTIMAL-31 | Random flips in vertical and horizontal directions, random zooming and random shifts over different image crops. | VGG-16+FPN and DenseNet+FPN | VGG-16, DenseNet and ResNet-101 | VGG-16 and DenseNet-161 pretrained on ImageNet. FPN (ResNet-101) pretrained on Microsoft COCO dataset | ||||
| 14 | [135] | UCM and NWPU-RESISC45 | Flip (horizontal and vertical) and rotation (90°, 180°, 270°) | MARTA-GAN | GAN | Not pretrained | Adam | SVM | ||
| 15 | [147] | UCM, AID and NWPU-RESISC45 | Random-scale cropping with crop ratio set to [0.6, 0.8], and the number of patches cropped from each original image is set to 20. | CaffeNet, VGG-VD16 and GoogLeNet | CaffeNet, VGG-VD16 and GoogLeNet, | Tensorflow | SGD | Softmax | ||
| 16 | [80] | NWPU-RESISC45 | FDPResNet | ResNet-101 | ImageNet | SVM | ||||
| 17 | [96] | UCM, AID and NWPU-RESISC45 | Rotation clockwise (90°, 180°, and 270°), flip (horizontal and vertical) to expand the training data six-fold. | biMobileNet | MobileNet-v2 | ImageNet | PyTorch | SGD | SVM | |
| 18 | [100] | UCM and AID | Images are resized to 224 × 224 pixels. | Rotation (0°, 90°, 180°, and 270°) and mirror operations on these four angles to expand the data to eight times the original data, | RDN + CBAM | DenseNet | ImageNet | PyTorch | Adam | Softmax |
| 19 | [134] | UCM, AID and NWPU-RESISC45 | AID dataset images are resized to 256 × 256 pixels as input for the model. | Expand the UCM dataset with 90° of horizontal and vertical rotation, increasing the training samples to 6800. | MF-WGAN | GAN | Not pretrained | MLP | ||
| 20 | [89] | AID and NWPU-RESISC45 | Images of the datasets are resized according to the requirements of CNN: 224 × 224 for ResNet-50 and DenseNet-121, and 299 × 299 for Inception-V3 and Xception. | Data augmentation used. | ResNet-50, Inception-V3, Xception and DenseNet-121 | ResNet-50, Inception-V3, Xception and DenseNet-121 | ImageNet | SGD | Softmax | |
| 21 | [103] | AID and NWPU-RESISC45 | Images are resized to 224 × 224 to train the attention network. | VGG-VD16 chosen as a attention network, and AlexNet and VGG-VD16 used to learn feature representation obtained from attention network | AlexNet and VGG-VD16 | ImageNet | PyTorch | SGD | ||
| 22 | [75] | UCM, AID and NWPU-RESISC45 | Images are resized to 299 × 299 for the pre-trained CNNs. | Rotation (90° and 180°), zoom (random) and flip (horizontal and vertical) | CNN-MLP | Xception | ImageNet | Adagrad | MLP | |
| 23 | [136] | AID and NWPU-RESISC45 | Images are resized to 224 × 224 pixels before training. | Rotation (90°, 180°, and 270°), flip (horizontally and vertically) and crop (from each side by 0 to 12 pixels). For testing, rotation transformation (90°, 180°, and 270°) to obtain 4 images. | MF2Net | VGG-16 | ImageNet | PyTorch | SGD | Softmax |
| 24 | [104] | UCM, AID and NWPU-RESISC45 | Random rotation, flip, and cropping. | MSA-Network | ResNet-18, ResNet-34, ResNet-50 and ResNet-101 | ImageNet | Tensorflow | Adam | ||
| 25 | [148] | UCM, RSSCN, SIRI-WHU, Corel-1K and Corel-15K | Fine-tuned ResNet-50 | ResNet-50 | ImageNet | SGD | ||||
| 26 | [77] | UCM and AID | Images are resized to 224 × 224 for both datasets. | MCPSF | VGG-19 | ImageNet | Tensorflow | SVM | ||
| 27 | [10] | NWPU-RESISC45 and SIRI-WHU | Accept image that are different sizes. | LW-CNN | VGG-16 | Keras | SGD | Softmax | ||
| 28 | [105] | UCM, WHU-RS, AID and OPTIMAL-31 | Rotation, flip, scaling, and translation. | Dual model architecture includes ResNet-50 and DenseNet-121 fused | ResNet-50 and DenseNet-121 | ImageNet | SGD | |||
| 29 | [157] | UCM, WHU-RS19, RSSCN7, AID and NWPU-RESISC45 | Images are resized to 224 × 224 pixels. | Random crops, horizontal flips, and RGB color jittering | VGG | VGG | Not pretrained | SVM | ||
| 30 | [158] | AID, RSI-CB, IP | PDDE-Net | DenseNet | Keras and Tensorflow | SGD | Softmax | |||
| 31 | [150] | UCM, WHU-RS, AID and NWPU-RESISC45 | Images are resized to 299 × 299 pixels. | Xception | Xception | Python | Adagrad | MLP | ||
| 32 | [106] | AID, NWPU-RESISC45 and UCMerced | Images are resized to 224 × 224 pixels. | MVFLN | AlexNet [17] and VGG-16 [33] | ImageNet | PyTorch | SGD | ||
| 33 | [139] | AID and NWPU-RESISC45 | Images are resized to 224 × 224 pixels. | DS-CapsNet | 4 novel convolution layers used | PyTorch | ||||
| 34 | [124] | UCM, AID, NWPU-RESISC45 and OPTIMAL-31 | Images are resized for UCM, NWPU, and OPTIMAL-31 into 224 × 224 pixels. For AID, images are resized to 600 × 600 pixels. | TRS | ResNet-50 | ImageNet1k | Adam | Softmax | ||
| 35 | [107] | UCM, AID and NWPU-RESISC-45 | Images are resized to 256 × 256 pixels. | GoogLeNet, VGG-16, ResNet-50, and ResNet-101 | GoogLeNet, VGG-16, ResNet-50, and ResNet-101 | ImageNet | NAG | |||
| 36 | [143] | RSSCN7 and WHU-RS19 | Images are resized to 256 × 256 pixels. | CAW | Swin transformer module and VAN module concatenated together | PyTorch 3.7 | Adam | |||
| 37 | [142] | UCM, AID and NWPU-RESISC45 | AGOS | ResNet-50, ResNet-101 and DenseNet-121 | ImageNet | Tensorflow | Adam | |||
| 38 | [125] | AID and NWPU | Images are resized to 224 × 224 pixels. | Random horizontal flipping | Swin Transformer | Swin Transformer | ImageNet | PyTorch | Adam | Softmax |
| 39 | [54] | UCM, AID, NWPU-RESISC45 and merged RS dataset | For labeled data, patches of 224 × 224 pixels are randomly cropped from the original images. | Labelled data: horizontal flipping.Unlabeled data: random cropping, random rotation, and color jitter. | SS_RCSN | ResNet-18 | Adam | |||
| 40 | [140] | AID and NWPU-RESISC45 | Confused images are selected as input pairs for the network. For each batch, 30 classes of images are selected in the AID dataset, 45 classes of images are selected in the NWPU-RESISC45 dataset, and six images are randomly selected for each class. | Random rotation by 30°, and flip (horizontal and vertical). | PCNet | ResNet-50 | PyTorch | SGD | Softmax | |
| 41 | [144] | AID and NWPU-RESISC45 | Images are resized to 256 × 256 pixels. | Random flip and rotation. | CTNet | ResNet-34 and MobileNet_v2 in C-stream, and pretrained VIT model in T-stream | ImageNet1k | PyTorch | SGD | Softmax |
| 42 | [108] | AID, WHU-RS19 and NWPU-RESISC45 | Images are resized to 224 × 224 pixels. | MINet | ResNet-50 | ImageNet | PyTorch | SGD | ||
| 43 | [145] | AID and NWPU | GLDBS | ResNet-18 and ResNet-34 combined | PyTorch | Adam | ||||
| 44 | [149] | AID and NWPU-RESISC45 | Input images are resized to 224 × 224 pixels. | MRHNet | ResNet-50 and ResNet-101 | PyTorch 1.3.1 | diffGrad | |||
| 45 | [71] | NWPU-RESISC45 | Rotation clockwise (90°, 180°, and 270°) and horizontal and vertical refections of the images. | DenseNet-121-Full and Half | DenseNet-121 | ImageNet | ||||
| 46 | [137] | UCM, AID, RSSCN7 and NWPU-RESISC45 | Images are resized to 224 × 224 pixels for all four datasets. | No augmentation. | DFAGCN | VGG-16 | ImageNet | PyTorch framework with PyTorch-Geometric (PYG) is employed for the construction of GCN model | Adam | |
| 47 | [127] | UCM, AID and NWPU-RESISC45 | Images are resized to 224 × 224 pixels. | CSAT | ImageNet1K | PyTorch | Adam | MLP | ||
| 48 | [122] | UCM, AID and NWPU | LG-ViT | LG-ViT | ImageNet | Adam | ||||
| 49 | [159] | AID and NWPU | STAIRS | ResNet-50 | SGD | |||||
| 50 | [151] | UCM, AID, WHU-RS19, PatterNet and KSA | EfficientNet-V2L for global feature extraction and ResNet-101V2 for co-saliency feature extraction and fusion using DCA algorithm | EfficientNet-V2L and ResNet-101V2 | Adagrad | MLP |
References
- Gómez-Chova, L.; Tuia, D.; Moser, G.; Camps-Valls, G. Multimodal classification of remote sensing images: A review and future directions. Proc. IEEE 2015, 103, 1560–1584. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, Z.; Yu, J.G.; Zhang, Y. Learning deep cross-modal embedding networks for zero-shot remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10590–10603. [Google Scholar] [CrossRef]
- Cheng, G.; Guo, L.; Zhao, T.; Han, J.; Li, H.; Fang, J. Automatic landslide detection from remote-sensing imagery using a scene classification method based on BoVW and pLSA. Int. J. Remote Sens. 2013, 34, 45–59. [Google Scholar] [CrossRef]
- Othman, E.; Bazi, Y.; Alajlan, N.; Alhichri, H.; Melgani, F. Using convolutional features and a sparse autoencoder for land-use scene classification. Int. J. Remote Sens. 2016, 37, 2149–2167. [Google Scholar] [CrossRef]
- Kunlun, Q.; Xiaochun, Z.; Baiyan, W.; Huayi, W. Sparse coding-based correlaton model for land-use scene classification in high-resolution remote-sensing images. J. Appl. Remote Sens. 2016, 10, 042005. [Google Scholar] [CrossRef]
- Zhao, L.; Tang, P.; Huo, L. A 2-D wavelet decomposition-based bag-of-visual-words model for land-use scene classification. Int. J. Remote Sens. 2014, 35, 2296–2310. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, B.; Su, H.; Li, W.; Wang, L. Land-use scene classification using multi-scale completed local binary patterns. Signal, Image Video Process. 2016, 10, 745–752. [Google Scholar] [CrossRef]
- Weng, Q.; Mao, Z.; Lin, J.; Liao, X. Land-use scene classification based on a CNN using a constrained extreme learning machine. Int. J. Remote Sens. 2018, 39, 6281–6299. [Google Scholar] [CrossRef]
- Qi, K.; Wu, H.; Shen, C.; Gong, J. Land-use scene classification in high-resolution remote sensing images using improved correlatons. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2403–2407. [Google Scholar]
- Xia, J.; Ding, Y.; Tan, L. Urban remote sensing scene recognition based on lightweight convolution neural network. IEEE Access 2021, 9, 26377–26387. [Google Scholar] [CrossRef]
- Janssen, L.L.; Middelkoop, H. Knowledge-based crop classification of a Landsat Thematic Mapper image. Int. J. Remote Sens. 1992, 13, 2827–2837. [Google Scholar] [CrossRef]
- Ji, M.; Jensen, J.R. Effectiveness of subpixel analysis in detecting and quantifying urban imperviousness from Landsat Thematic Mapper imagery. Geocarto Int. 1999, 14, 33–41. [Google Scholar] [CrossRef]
- Tuia, D.; Ratle, F.; Pacifici, F.; Kanevski, M.F.; Emery, W.J. Active learning methods for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2218–2232. [Google Scholar] [CrossRef]
- Blaschke, T.; Strobl, J. What’s wrong with pixels? Some recent developments interfacing remote sensing and GIS. Z. Geoinformationssyst. 2001, 4, 12–17. [Google Scholar]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Blaschke, T.; Lang, S.; Hay, G. Object-Based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Hay, G.J.; Blaschke, T.; Marceau, D.J.; Bouchard, A. A comparison of three image-object methods for the multiscale analysis of landscape structure. ISPRS J. Photogramm. Remote Sens. 2003, 57, 327–345. [Google Scholar] [CrossRef]
- Li, H.; Gu, H.; Han, Y.; Yang, J. Object-oriented classification of high-resolution remote sensing imagery based on an improved colour structure code and a support vector machine. Int. J. Remote Sens. 2010, 31, 1453–1470. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Feitosa, R.Q.; Van der Meer, F.; Van der Werff, H.; Van Coillie, F.; et al. Geographic object-based image analysis–towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef]
- Blaschke, T.; Burnett, C.; Pekkarinen, A. Image segmentation methods for object-based analysis and classification. In Remote Sensing Image Analysis: Including the Spatial Domain; Springer: Berlin/Heidelberg, Germany, 2004; pp. 211–236. [Google Scholar]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Z.; Yao, X.; Guo, L.; Wei, Z. Remote sensing image scene classification using bag of convolutional features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1735–1739. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Zhong, Y.; Cui, M.; Zhu, Q.; Zhang, L. Scene classification based on multifeature probabilistic latent semantic analysis for high spatial resolution remote sensing images. J. Appl. Remote Sens. 2015, 9, 095064. [Google Scholar] [CrossRef]
- Li, X.; Guo, Y. Multi-level adaptive active learning for scene classification. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part VII. pp. 234–249. [Google Scholar]
- Wang, X.; Duan, L.; Ning, C. Global context-based multilevel feature fusion networks for multilabel remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11179–11196. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Comparing SIFT descriptors and Gabor texture features for classification of remote sensed imagery. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 1852–1855. [Google Scholar]
- dos Santos, J.A.; Penatti, O.A.; Torres, R.d.S. Evaluating the potential of texture and color descriptors for remote sensing image retrieval and classification. In Proceedings of the International Conference on Computer Vision Theory and Applications, Angers, France, 17–21 May 2010; Volume 2, pp. 203–208. [Google Scholar]
- Luo, B.; Jiang, S.; Zhang, L. Indexing of remote sensing images with different resolutions by multiple features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1899–1912. [Google Scholar] [CrossRef]
- Penatti, O.A.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Yang, A.Y.; Wright, J.; Ma, Y.; Sastry, S.S. Unsupervised segmentation of natural images via lossy data compression. Comput. Vis. Image Underst. 2008, 110, 212–225. [Google Scholar] [CrossRef]
- Carreira, J.; Sminchisescu, C. CPMC: Automatic object segmentation using constrained parametric min-cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1312–1328. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classification using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef]
- Zhou, L.; Zhou, Z.; Hu, D. Scene classification using a multi-resolution bag-of-features model. Pattern Recognit. 2013, 46, 424–433. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.S.; Zhang, L. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Zhao, L.J.; Tang, P.; Huo, L.Z. Land-use scene classification using a concentric circle-structured multiscale bag-of-visual-words model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4620–4631. [Google Scholar] [CrossRef]
- Jogin, M.; Madhulika, M.S.; Divya, G.D.; Meghana, R.K.; Apoorva, S. Feature extraction using convolution neural networks (CNN) and deep learning. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 18–19 May 2018; pp. 2319–2323. [Google Scholar]
- Scarpa, G.; Gargiulo, M.; Mazza, A.; Gaetano, R. A CNN-based fusion method for feature extraction from sentinel data. Remote Sens. 2018, 10, 236. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed]
- Thapa, A.; Neupane, B.; Horanont, T. Object vs Pixel-based Flood/Drought Detection in Paddy Fields using Deep Learning. In Proceedings of the 2022 12th International Congress on Advanced Applied Informatics (IIAI-AAI), Kanazawa, Japan, 2–7 July 2022; pp. 455–460. [Google Scholar]
- Thapa, A.; Horanont, T.; Neupane, B. Parcel-Level Flood and Drought Detection for Insurance Using Sentinel-2A, Sentinel-1 SAR GRD and Mobile Images. Remote Sens. 2022, 14, 6095. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, X.; Niu, X.; Wang, F.; Zhang, X. Scene classification of high-resolution remotely sensed image based on ResNet. J. Geovisualization Spat. Anal. 2019, 3, 16. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Wang, Q.; Huang, W.; Xiong, Z.; Li, X. Looking closer at the scene: Multiscale representation learning for remote sensing image scene classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 1414–1428. [Google Scholar] [CrossRef]
- Xie, J.; He, N.; Fang, L.; Plaza, A. Scale-free convolutional neural network for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6916–6928. [Google Scholar] [CrossRef]
- Anwer, R.M.; Khan, F.S.; Van De Weijer, J.; Molinier, M.; Laaksonen, J. Binary patterns encoded convolutional neural networks for texture recognition and remote sensing scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 138, 74–85. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Scene classification using multi-scale deeply described visual words. Int. J. Remote Sens. 2016, 37, 4119–4131. [Google Scholar] [CrossRef]
- Sitaula, C.; KC, S.; Aryal, J. Enhanced Multi-level Features for Very High Resolution Remote Sensing Scene Classification. arXiv 2023, arXiv:2305.00679. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Xia, G.S.; Yang, W.; Delon, J.; Gousseau, Y.; Sun, H.; Maître, H. Structural High-resolution Satellite Image Indexing. In Proceedings of the ISPRS TC VII Symposium—100 Years ISPRS, Vienna, Austria, 5–7 July 2010; Volume XXXVIII, pp. 298–303. [Google Scholar]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Miao, W.; Geng, J.; Jiang, W. Semi-supervised remote-sensing image scene classification using representation consistency siamese network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5616614. [Google Scholar] [CrossRef]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS J. Photogramm. Remote Sens. 2018, 145, 197–209. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Xia, G.S.; Zhang, L. Dirichlet-derived multiple topic scene classification model for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2015, 54, 2108–2123. [Google Scholar] [CrossRef]
- Li, H.; Tao, C.; Wu, Z.; Chen, J.; Gong, J.; Deng, M. RSI-CB: A large scale remote sensing image classification benchmark via crowdsource data. arXiv 2017, arXiv:1705.10450. [Google Scholar]
- Othman, E.; Bazi, Y.; Melgani, F.; Alhichri, H.; Alajlan, N.; Zuair, M. Domain adaptation network for cross-scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4441–4456. [Google Scholar] [CrossRef]
- Liu, Y.H. Feature extraction and image recognition with convolutional neural networks. J. Phys. Conf. Ser. 2018, 1087, 062032. [Google Scholar] [CrossRef]
- Coşkun, M.; Uçar, A.; Yildirim, Ö.; Demir, Y. Face recognition based on convolutional neural network. In Proceedings of the 2017 International Conference on Modern Electrical and Energy Systems (MEES), Kremenchuk, Ukraine, 15–17 November 2017; pp. 376–379. [Google Scholar]
- Guo, P.; Valanarasu, J.M.J.; Wang, P.; Zhou, J.; Jiang, S.; Patel, V.M. Over-and-under complete convolutional rnn for mri reconstruction. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Part VI. pp. 13–23. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the COMPSTAT’2010: 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning deep features for scene recognition using places database. Adv. Neural Inf. Process. Syst. 2014, 27, 487–495. [Google Scholar]
- Wang, G.; Fan, B.; Xiang, S.; Pan, C. Aggregating rich hierarchical features for scene classification in remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4104–4115. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Sen, O.; Keles, H.Y. A Hierarchical Approach to Remote Sensing Scene Classification. PFG- Photogramm. Remote Sens. Geoinf. Sci. 2022, 90, 161–175. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Al Rahhal, M.M.; Bazi, Y.; Abdullah, T.; Mekhalfi, M.L.; AlHichri, H.; Zuair, M. Learning a multi-branch neural network from multiple sources for knowledge adaptation in remote sensing imagery. Remote Sens. 2018, 10, 1890. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shawky, O.A.; Hagag, A.; El-Dahshan, E.S.A.; Ismail, M.A. Remote sensing image scene classification using CNN-MLP with data augmentation. Optik 2020, 221, 165356. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Sun, X.; Zhu, Q.; Qin, Q. A multi-level convolution pyramid semantic fusion framework for high-resolution remote sensing image scene classification and annotation. IEEE Access 2021, 9, 18195–18208. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. A two-stream deep fusion framework for high-resolution aerial scene classification. Comput. Intell. Neurosci. 2018, 2018, 8639367. [Google Scholar] [CrossRef]
- Ye, L.; Wang, L.; Sun, Y.; Zhao, L.; Wei, Y. Parallel multi-stage features fusion of deep convolutional neural networks for aerial scene classification. Remote Sens. Lett. 2018, 9, 294–303. [Google Scholar] [CrossRef]
- Dong, R.; Xu, D.; Jiao, L.; Zhao, J.; An, J. A fast deep perception network for remote sensing scene classification. Remote Sens. 2020, 12, 729. [Google Scholar] [CrossRef]
- Chen, C.P.; Liu, Z. Broad learning system: An effective and efficient incremental learning system without the need for deep architecture. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 10–24. [Google Scholar] [CrossRef]
- Mäenpää, T.; Pietikäinen, M. Texture analysis with local binary patterns. In Handbook of Pattern Recognition and Computer Vision; World Scientific: Singapore, 2005; pp. 197–216. [Google Scholar]
- Yu, Y.; Liu, F. Dense connectivity based two-stream deep feature fusion framework for aerial scene classification. Remote Sens. 2018, 10, 1158. [Google Scholar] [CrossRef]
- Huang, H.; Xu, K. Combing triple-part features of convolutional neural networks for scene classification in remote sensing. Remote Sens. 2019, 11, 1687. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, Mountain View, CA, USA, 18–19 June 2014; pp. 675–678. [Google Scholar]
- Yang, X.; Yan, W.; Ni, W.; Pu, X.; Zhang, H.; Zhang, M. Object-guided remote sensing image scene classification based on joint use of deep-learning classifier and detector. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2673–2684. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part V. pp. 740–755. [Google Scholar]
- Petrovska, B.; Atanasova-Pacemska, T.; Corizzo, R.; Mignone, P.; Lameski, P.; Zdravevski, E. Aerial scene classification through fine-tuning with adaptive learning rates and label smoothing. Appl. Sci. 2020, 10, 5792. [Google Scholar] [CrossRef]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the 2017 IEEE winter conference on applications of computer vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv 2015, arXiv:1508.00092. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. Adv. Neural Inf. Process. Syst. 2015, 28, 1135–1143. [Google Scholar]
- Whittaker, G.; Confesor, R.E.; Di Luzio, M.; Arnold, J.G. Detection of overparameterization and overfitting in an automatic calibration of SWAT. Trans. ASABE 2010, 53, 1487–1499. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Zhang, J.; Lu, C.; Li, X.; Kim, H.J.; Wang, J. A full convolutional network based on DenseNet for remote sensing scene classification. Math. Biosci. Eng. 2019, 16, 3345–3367. [Google Scholar] [CrossRef] [PubMed]
- Yu, D.; Xu, Q.; Guo, H.; Zhao, C.; Lin, Y.; Li, D. An efficient and lightweight convolutional neural network for remote sensing image scene classification. Sensors 2020, 20, 1999. [Google Scholar] [CrossRef] [PubMed]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Lin, T.Y.; RoyChowdhury, A.; Maji, S. Bilinear CNN models for fine-grained visual recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1449–1457. [Google Scholar]
- Lihua, Y.; Lei, W.; Wenwen, Z.; Yonggang, L.; Zengkai, W. Deep metric learning method for high resolution remote sensing image scene classification. Acta Geod. Cartogr. Sin. 2019, 48, 698. [Google Scholar]
- Zhao, X.; Zhang, J.; Tian, J.; Zhuo, L.; Zhang, J. Residual dense network based on channel-spatial attention for the scene classification of a high-resolution remote sensing image. Remote Sens. 2020, 12, 1887. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ji, J.; Zhang, T.; Jiang, L.; Zhong, W.; Xiong, H. Combining multilevel features for remote sensing image scene classification with attention model. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1647–1651. [Google Scholar] [CrossRef]
- Zhang, G.; Xu, W.; Zhao, W.; Huang, C.; Yk, E.N.; Chen, Y.; Su, J. A multiscale attention network for remote sensing scene images classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9530–9545. [Google Scholar] [CrossRef]
- Shen, J.; Zhang, T.; Wang, Y.; Wang, R.; Wang, Q.; Qi, M. A dual-model architecture with grouping-attention-fusion for remote sensing scene classification. Remote Sens. 2021, 13, 433. [Google Scholar] [CrossRef]
- Guo, Y.; Ji, J.; Shi, D.; Ye, Q.; Xie, H. Multi-view feature learning for VHR remote sensing image classification. Multimed. Tools Appl. 2021, 80, 23009–23021. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, J.; Luo, Z.; Li, J.; Chen, C. Remote sensing image scene classification based on an enhanced attention module. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1926–1930. [Google Scholar] [CrossRef]
- Hu, J.; Shu, Q.; Pan, J.; Tu, J.; Zhu, Y.; Wang, M. MINet: Multilevel inheritance network-based aerial scene classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, B.; Zhang, Y.; Wang, S. A lightweight and discriminative model for remote sensing scene classification with multidilation pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2636–2653. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, J.; Plaza, A. Skip-connected covariance network for remote sensing scene classification. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1461–1474. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Du, B.; Zhang, L. Scene classification via a gradient boosting random convolutional network framework. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1793–1802. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Bashmal, L.; Bazi, Y.; Al Rahhal, M. Deep vision transformers for remote sensing scene classification. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 2815–2818. [Google Scholar]
- Bi, M.; Wang, M.; Li, Z.; Hong, D. Vision transformer with contrastive learning for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 738–749. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Xu, K.; Deng, P.; Huang, H. Vision transformer: An excellent teacher for guiding small networks in remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5618715. [Google Scholar] [CrossRef]
- Peng, T.; Yi, J.; Fang, Y. A Local-global Interactive Vision Transformer for Aerial Scene Classification. IEEE Geosci. Remote. Sens. Lett. 2023, 20, 6004405. [Google Scholar] [CrossRef]
- Tang, X.; Li, M.; Ma, J.; Zhang, X.; Liu, F.; Jiao, L. EMTCAL: Efficient multiscale transformer and cross-level attention learning for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5626915. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, H.; Li, J. TRS: Transformers for remote sensing scene classification. Remote Sens. 2021, 13, 4143. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, N.; Liu, W.; Chen, H.; Xie, Y. MFST: A Multi-Level Fusion Network for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6516005. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Guo, J.; Jia, N.; Bai, J. Transformer based on channel-spatial attention for accurate classification of scenes in remote sensing image. Sci. Rep. 2022, 12, 15473. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Neupane, B.; Horanont, T.; Aryal, J. Deep learning-based semantic segmentation of urban features in satellite images: A review and meta-analysis. Remote Sens. 2021, 13, 808. [Google Scholar] [CrossRef]
- Lin, D.; Fu, K.; Wang, Y.; Xu, G.; Sun, X. MARTA GANs: Unsupervised representation learning for remote sensing image classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2092–2096. [Google Scholar] [CrossRef]
- Xu, S.; Mu, X.; Chai, D.; Zhang, X. Remote sensing image scene classification based on generative adversarial networks. Remote Sens. Lett. 2018, 9, 617–626. [Google Scholar] [CrossRef]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-normalizing neural networks. Adv. Neural Inf. Process. Syst. 2017, 30, 971–980. [Google Scholar]
- Ma, D.; Tang, P.; Zhao, L. SiftingGAN: Generating and sifting labeled samples to improve the remote sensing image scene classification baseline in vitro. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1046–1050. [Google Scholar] [CrossRef]
- Wei, Y.; Luo, X.; Hu, L.; Peng, Y.; Feng, J. An improved unsupervised representation learning generative adversarial network for remote sensing image scene classification. Remote Sens. Lett. 2020, 11, 598–607. [Google Scholar] [CrossRef]
- Yan, P.; He, F.; Yang, Y.; Hu, F. Semi-supervised representation learning for remote sensing image classification based on generative adversarial networks. IEEE Access 2020, 8, 54135–54144. [Google Scholar] [CrossRef]
- Xu, K.; Huang, H.; Li, Y.; Shi, G. Multilayer feature fusion network for scene classification in remote sensing. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1894–1898. [Google Scholar] [CrossRef]
- Xu, K.; Huang, H.; Deng, P.; Li, Y. Deep feature aggregation framework driven by graph convolutional network for scene classification in remote sensing. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 5751–5765. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. Adv. Neural Inf. Process. Syst. 2017, 30, 3859–3869. [Google Scholar]
- Wang, C.; Wu, Y.; Wang, Y.; Chen, Y. Scene recognition using deep softpool capsule network based on residual diverse branch block. Sensors 2021, 21, 5575. [Google Scholar] [CrossRef]
- Zhang, Y.; Zheng, X.; Lu, X. Pairwise comparison network for remote-sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 6505105. [Google Scholar] [CrossRef]
- Dietterich, T.G.; Lathrop, R.H.; Lozano-Pérez, T. Solving the multiple instance problem with axis-parallel rectangles. Artif. Intell. 1997, 89, 31–71. [Google Scholar] [CrossRef]
- Bi, Q.; Zhou, B.; Qin, K.; Ye, Q.; Xia, G.S. All Grains, One Scheme (AGOS): Learning Multigrain Instance Representation for Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5629217. [Google Scholar] [CrossRef]
- Wang, W.; Wen, X.; Wang, X.; Tang, C.; Deng, J. CAW: A Remote-Sensing Scene Classification Network Aided by Local Window Attention. Comput. Intell. Neurosci. 2022, 2022, 2661231. [Google Scholar] [CrossRef]
- Deng, P.; Xu, K.; Huang, H. When CNNs meet vision transformer: A joint framework for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8020305. [Google Scholar] [CrossRef]
- Xu, K.; Huang, H.; Deng, P. Remote sensing image scene classification based on global–local dual-branch structure model. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8011605. [Google Scholar] [CrossRef]
- Han, W.; Feng, R.; Wang, L.; Cheng, Y. A semi-supervised generative framework with deep learning features for high-resolution remote sensing image scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 145, 23–43. [Google Scholar] [CrossRef]
- Xue, W.; Dai, X.; Liu, L. Remote sensing scene classification based on multi-structure deep features fusion. IEEE Access 2020, 8, 28746–28755. [Google Scholar] [CrossRef]
- Shabbir, A.; Ali, N.; Ahmed, J.; Zafar, B.; Rasheed, A.; Sajid, M.; Ahmed, A.; Dar, S.H. Satellite and scene image classification based on transfer learning and fine tuning of ResNet50. Math. Probl. Eng. 2021, 2021, 5843816. [Google Scholar] [CrossRef]
- Li, C.; Zhuang, Y.; Liu, W.; Dong, S.; Du, H.; Chen, H.; Zhao, B. Effective multiscale residual network with high-order feature representation for optical remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 6003105. [Google Scholar] [CrossRef]
- Shawky, O.A.; Hagag, A.; El-Dahshan, E.S.A.; Ismail, M.A. A very high-resolution scene classification model using transfer deep CNNs based on saliency features. Signal, Image Video Process. 2021, 15, 817–825. [Google Scholar] [CrossRef]
- Aljabri, A.A.; Alshanqiti, A.; Alkhodre, A.B.; Alzahem, A.; Hagag, A. Extracting feature fusion and co-saliency clusters using transfer learning techniques for improving remote sensing scene classification. Optik 2023, 273, 170408. [Google Scholar] [CrossRef]
- Haghighat, M.; Abdel-Mottaleb, M.; Alhalabi, W. Discriminant correlation analysis: Real-time feature level fusion for multimodal biometric recognition. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1984–1996. [Google Scholar] [CrossRef]
- Dede, M.A.; Aptoula, E.; Genc, Y. Deep network ensembles for aerial scene classification. IEEE Geosci. Remote Sens. Lett. 2018, 16, 732–735. [Google Scholar] [CrossRef]
- Huang, G.; Li, Y.; Pleiss, G.; Liu, Z.; Hopcroft, J.E.; Weinberger, K.Q. Snapshot ensembles: Train 1, get m for free. arXiv 2017, arXiv:1704.00109. [Google Scholar]
- Dong, Y.; Zhang, Q. A combined deep learning model for the scene classification of high-resolution remote sensing image. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1540–1544. [Google Scholar] [CrossRef]
- Rachmadi, R.F.; Purnama, K. Large-Scale Scene Classification Using Gist Feature. In Proceedings of the Seminar on Intelligent Technology and Its Application, Surabaya, Indonesia, 22 May 2014; pp. 272–276. [Google Scholar]
- Anwer, R.M.; Khan, F.S.; Laaksonen, J. Compact deep color features for remote sensing scene classification. Neural Process. Lett. 2021, 53, 1523–1544. [Google Scholar] [CrossRef]
- Zhang, X.; Guo, Y.; Zhang, X. High-resolution remote sensing image scene classification by merging multilevel features of convolutional neural networks. J. Indian Soc. Remote Sens. 2021, 49, 1379–1391. [Google Scholar] [CrossRef]
- Jing, C.; Huang, L.; Cai, S.; Zhuang, Y.; Xiao, Z.; Huang, Y.; Ding, X. Interclass Similarity Transfer for Imbalanced Aerial Scene Classification. IEEE Geosci. Remote Sens. Lett. 2023, 20, 3502105. [Google Scholar] [CrossRef]
- Baumgardner, M.F.; Biehl, L.L.; Landgrebe, D.A. 220 band aviris hyperspectral image data set: June 12, 1992 indian pine test site 3. Purdue Univ. Res. Repos. 2015, 10, 991. [Google Scholar]
- Khalid, M.J.; Irfan, M.; Ali, T.; Gull, M.; Draz, U.; Glowacz, A.; Sulowicz, M.; Dziechciarz, A.; AlKahtani, F.S.; Hussain, S. Integration of discrete wavelet transform, DBSCAN, and classifiers for efficient content based image retrieval. Electronics 2020, 9, 1886. [Google Scholar] [CrossRef]
- Kaur, P.; Khehra, B.S.; Mavi, E.B.S. Data augmentation for object detection: A review. In Proceedings of the 2021 IEEE International Midwest Symposium on Circuits and Systems (MWSCAS), Lansing, MI, USA, 9–11 August 2021; pp. 537–543. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. {TensorFlow}: A system for {Large-Scale} machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Chollet, F. Deep Learning with Python; Simon and Schuster: New York, NY, USA, 2021. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Botev, A.; Lever, G.; Barber, D. Nesterov’s accelerated gradient and momentum as approximations to regularised update descent. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1899–1903. [Google Scholar]
- Dubey, S.R.; Chakraborty, S.; Roy, S.K.; Mukherjee, S.; Singh, S.K.; Chaudhuri, B.B. diffGrad: An optimization method for convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 4500–4511. [Google Scholar] [CrossRef]
- Steinwart, I.; Christmann, A. Support Vector Machines; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Hou, X.; Zhang, L. Saliency detection: A spectral residual approach. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Risojević, V.; Stojnić, V. Do we still need ImageNet pre-training in remote sensing scene classification? arXiv 2021, arXiv:2111.03690. [Google Scholar] [CrossRef]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- Li, X.; Pu, F.; Yang, R.; Gui, R.; Xu, X. AMN: Attention metric network for one-shot remote sensing image scene classification. Remote Sens. 2020, 12, 4046. [Google Scholar] [CrossRef]
- Yuan, Z.; Huang, W.; Li, L.; Luo, X. Few-shot scene classification with multi-attention deepemd network in remote sensing. IEEE Access 2020, 9, 19891–19901. [Google Scholar] [CrossRef]
- Zeng, Q.; Geng, J. Task-specific contrastive learning for few-shot remote sensing image scene classification. ISPRS J. Photogramm. Remote Sens. 2022, 191, 143–154. [Google Scholar] [CrossRef]
- Li, H.; Cui, Z.; Zhu, Z.; Chen, L.; Zhu, J.; Huang, H.; Tao, C. RS-MetaNet: Deep Metametric Learning for Few-Shot Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6983–6994. [Google Scholar] [CrossRef]

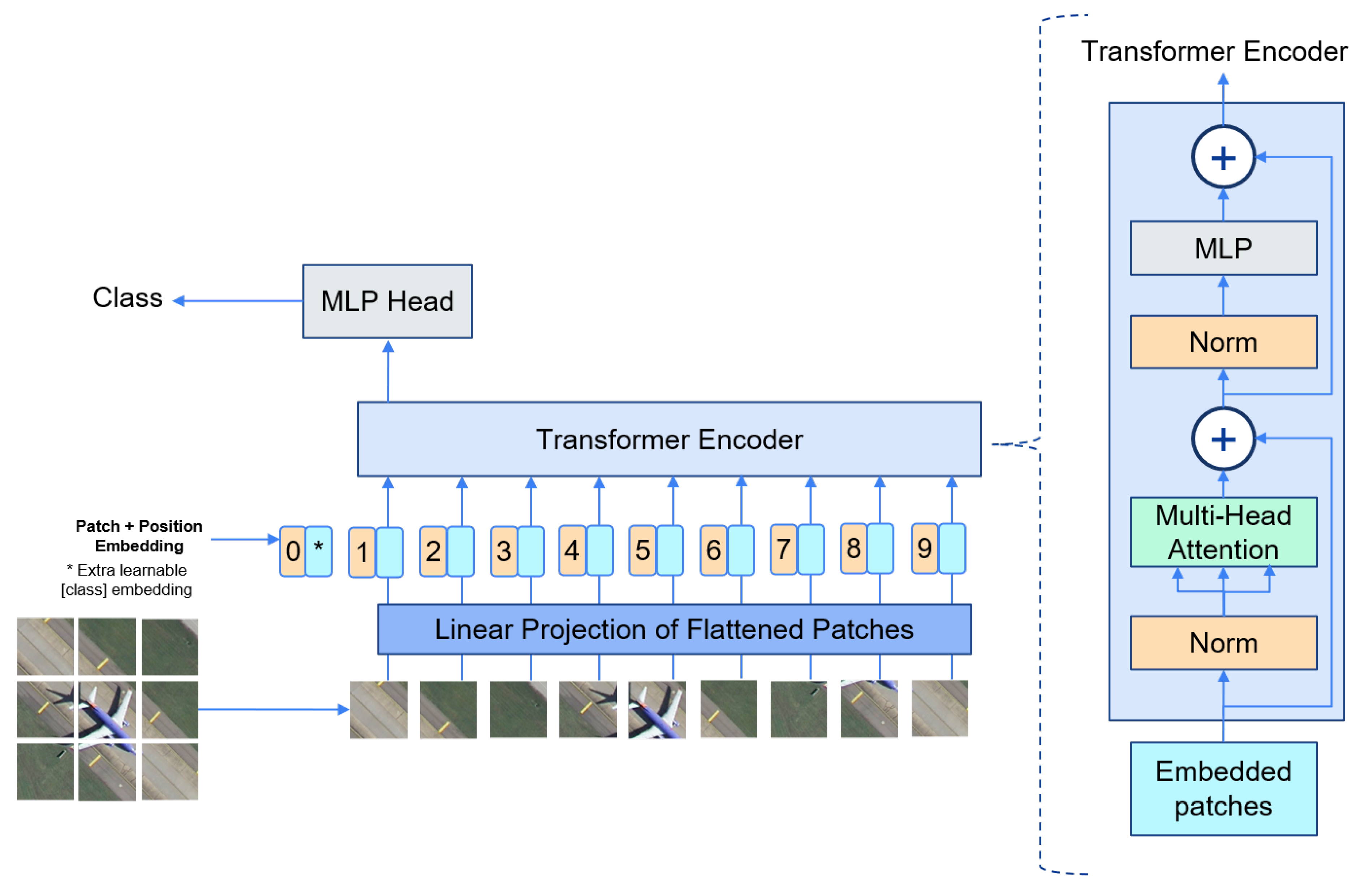

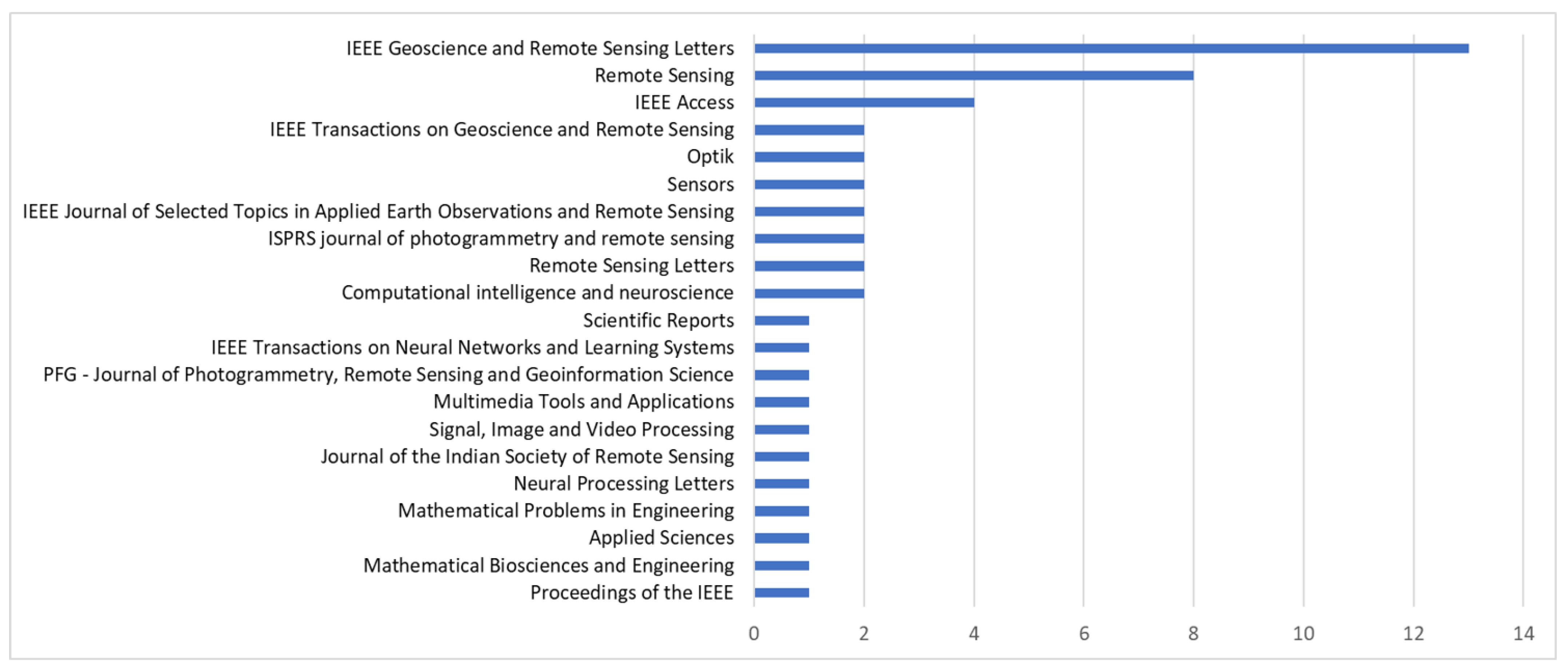

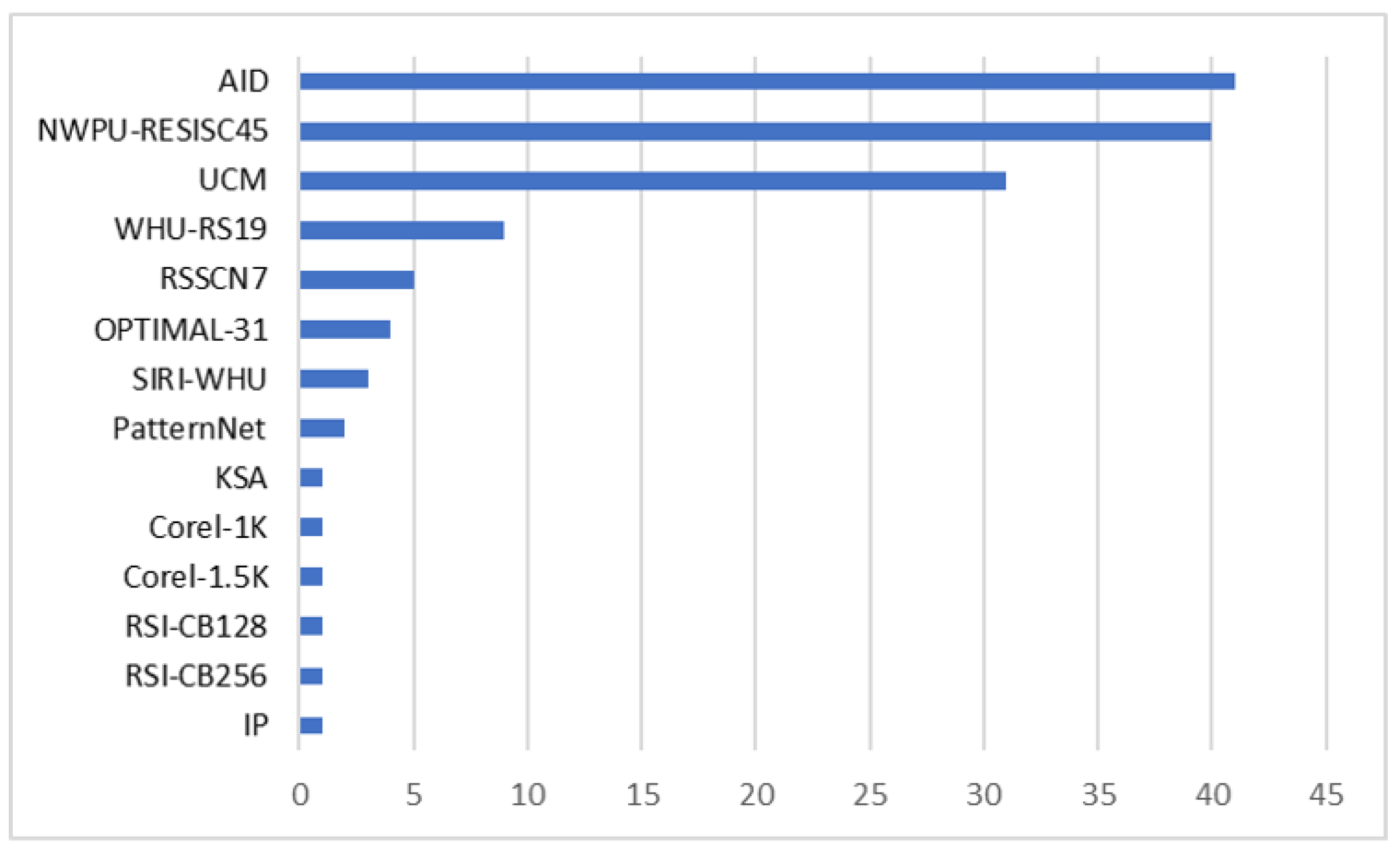
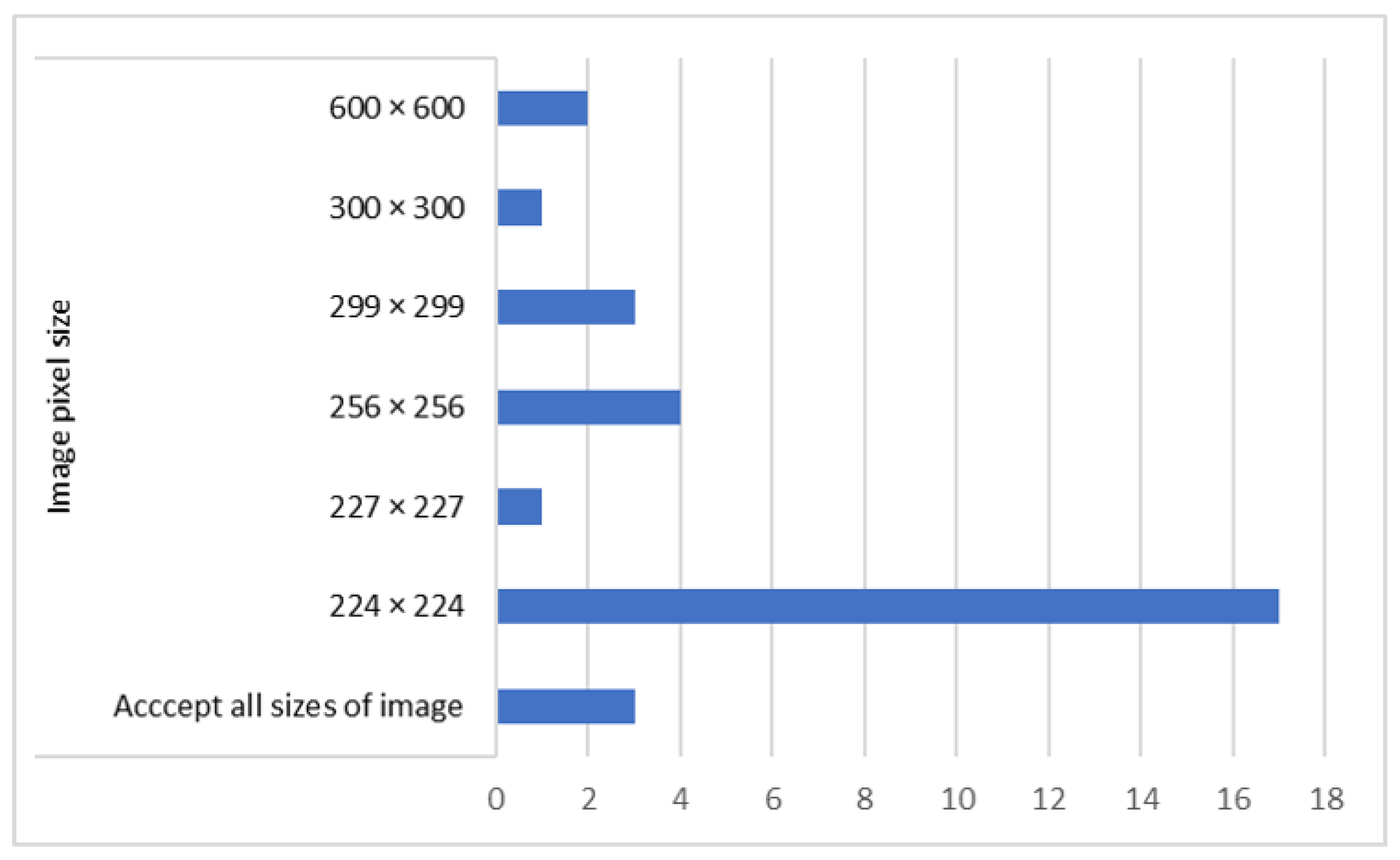
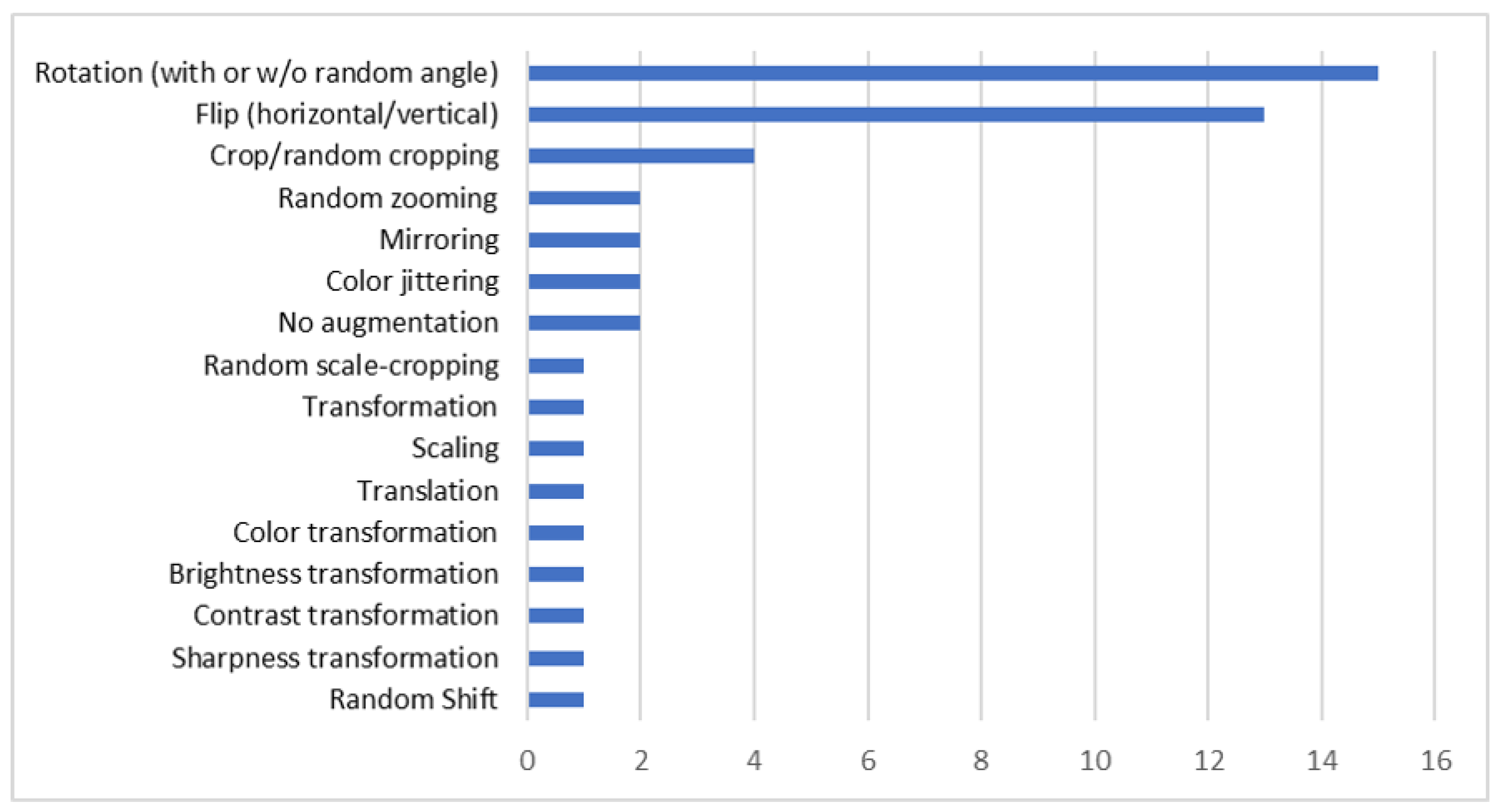
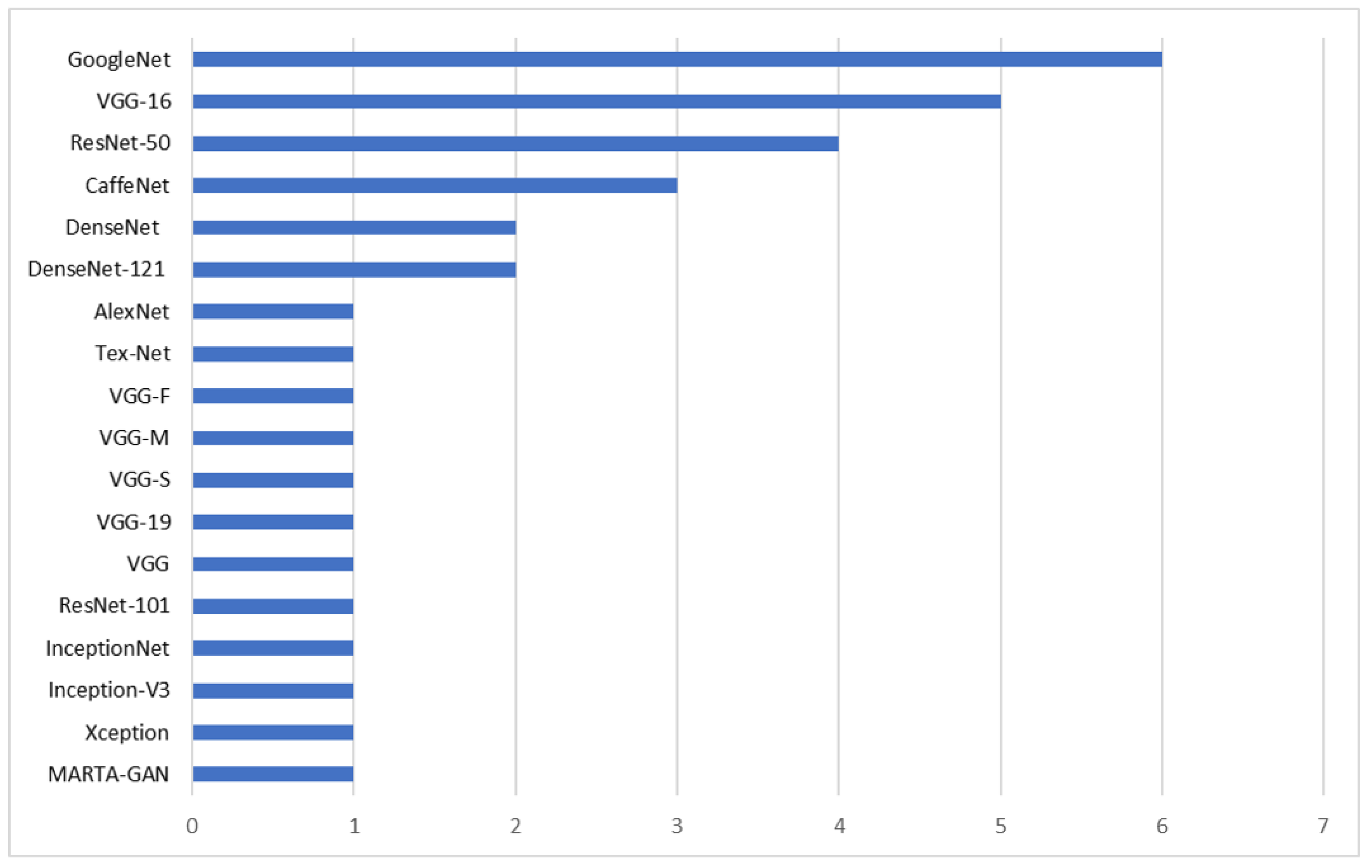
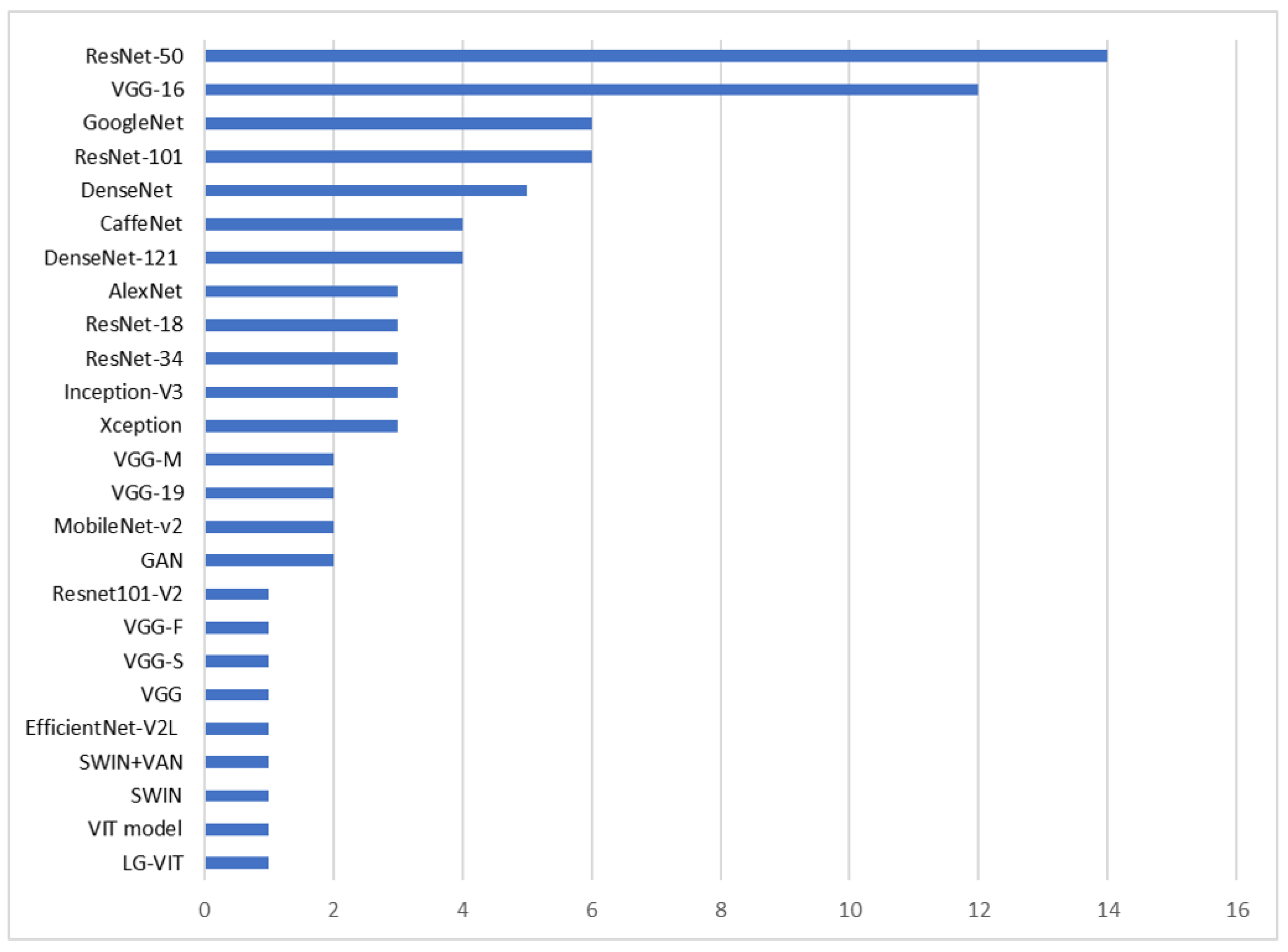
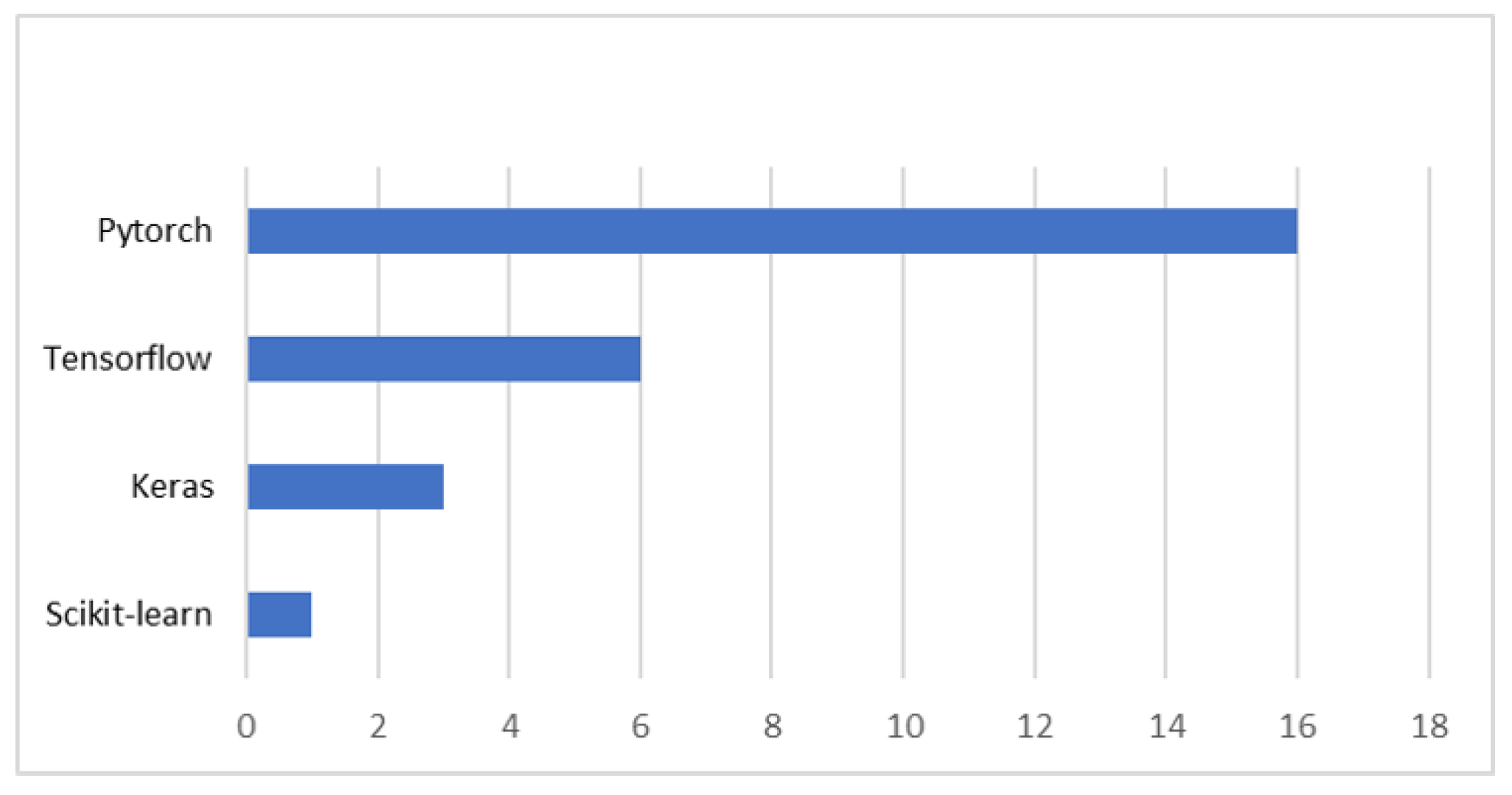
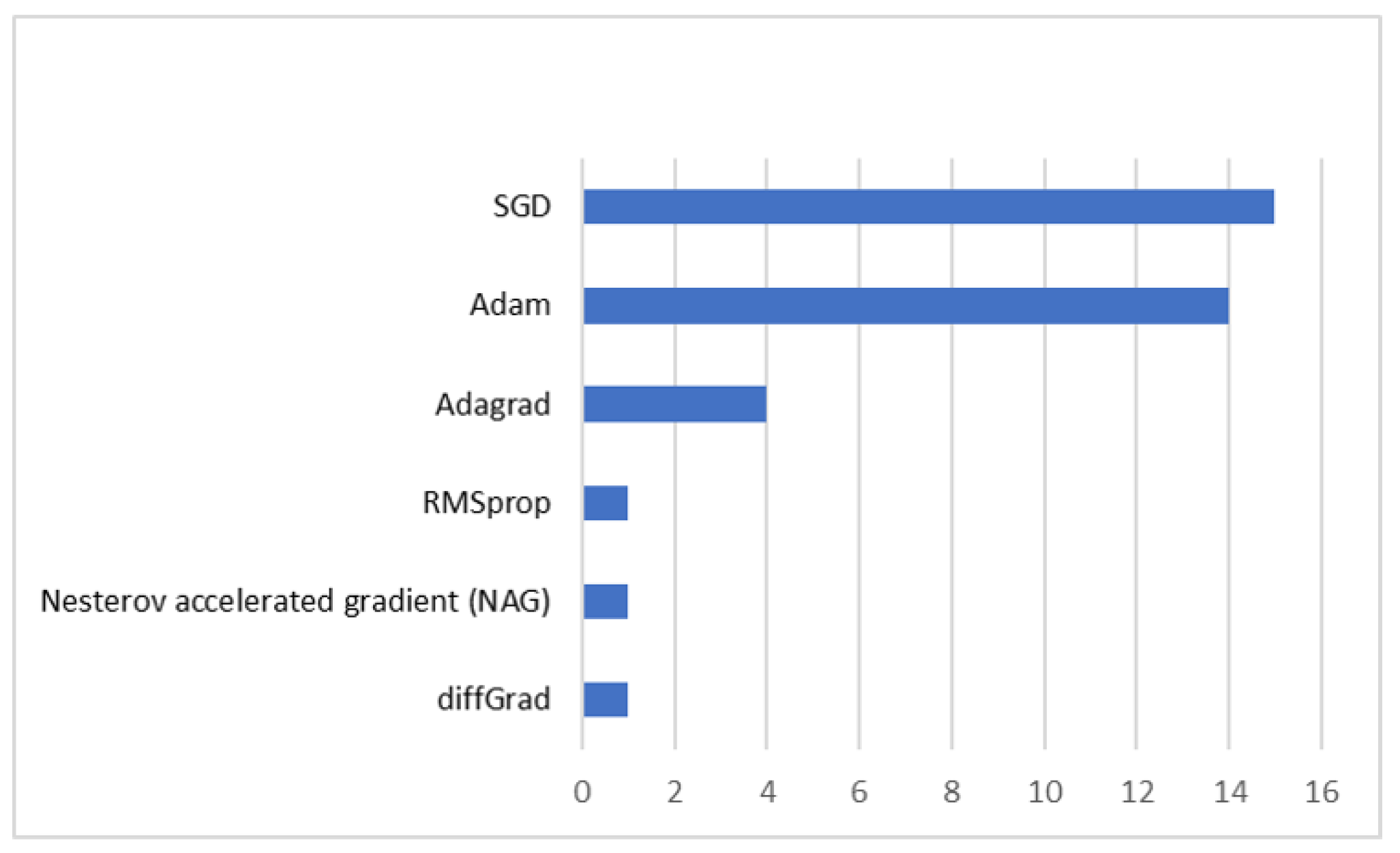

| Dataset | Number of Images | Classes | Image Size | Resolution (m) |
|---|---|---|---|---|
| UCM [51] | 2100 | 21 | 256 × 256 | 0.3 |
| AID [23] | 10,000 | 30 | 600 × 600 | 0.5–8 |
| WHU-RS19 [52] | 1005 | 19 | 600 × 600 | Up to 0.5 |
| NWPU-RESISC45 [49] | 31,500 | 45 | 256 × 256 | 0.2–30 |
| PatternNet [55] | 30,400 | 38 | 256 × 256 | 0.062–4.693 |
| OPTIMAL-31 [56] | 1860 | 31 | 256 × 256 | 0.3 |
| SIRI-WHU [57] | 2400 | 12 | 200 × 200 | 2 |
| RSSCN7 [53] | 2800 | 7 | 400 × 400 | - |
| RSI-CB256 [58] | >36,000 | 35 | 256 × 256 | 0.3–3 |
| RSI-CB128 [58] | >24,000 | 45 | 128 × 128 | 0.3–3 |
| KSA [59] | 3250 | 13 | 256 × 256 | 0.5–1 |
| Research Problem | Reference | Implemented Approaches |
|---|---|---|
| Capture more discriminative regions | [33,75,78,79,80,83,125,136,137,139,140] | Fuse processed images, multilayer fusion, FC replaced by CapsNet, pairwise comparison |
| Focus on the key information | [86,100,103,104,106,107,142] | Attention mechanism, classifier-detector, MIL |
| Learn local and global information | [122,124,127,143,144,145] | Transformer-based, Dual-branch network |
| Use unlabeled dataset | [54,134,135,146] | Semi-supervised learning |
| Improve texture recognition | [46,83,84] | LBP mapped image fused |
| Decrease the number of parameters | [10,95,96] | Lightweight CNN, DenseNet |
| Extract complementary features | [105,147] | Multi-structure features fusion |
| Fine-tune CNN | [89,148] | Fine-tune learning rate |
| Extract multi-scale feature maps effectively | [77,149] | Multilayer network |
| Reduce the effect of high intra-class diversity and high inter-class similarity in dataset | [71,106] | Triplet(Center) metric branch, re-organized classes in a two-layer hierarchy |
| Feature fusion to provide robust features | [150,151] | Discriminant correlation analysis (DCA) [152] |
| Introduce new large-scale dataset with image variations and diversity | [49] | NWPU-RESISC45 |
| Learn invariant feature representations | [73] | Multiple domain dataset |
| Cost-effective architecture | [153] | Snapshot ensembling [154] |
| Describe overall information | [155] | Combine GIST [156] on CNN |
| Integrate multiple color features | [157] | Deep color network fusion |
| Combine mid-level and deep-level information | [158] | Merge deep level feature and mid-level feature of encoder in decoder branch |
| Extract multilevel feature maps | [108] | Multilayer network |
| Improve performance in classifier learning | [159] | Statistical transfer via inter-class similarity |
| Dataset | Training Percentage(s) |
|---|---|
| NWPU-RESISC45 | 10% and 20% |
| AID | 20% and 50% |
| UCM | 50% and 80% |
| WHU-RS19 | 40% and 60% |
| RSSCN7 | 20% and 50% |
| Architectures | UCM (80%) | AID (50%) | NWPU (20%) | Year Indexed by Scopus | Categorized Approaches |
|---|---|---|---|---|---|
| TEX-Net-LF [46] | 97.72 | 95.73 | - | 2018 | LBP-based |
| SAL-TS-Net [83] | 98.90 | 95.99 | 87.01 | 2018 | |
| CTFCNN [84] | 98.44 | 94.91 | - | 2019 | |
| Fine-tuned VGG-16 [49] | - | - | 90.36 | 2016 | Fine-tuned |
| VGG-16-CapsNet [33] | 98.81 | 94.74 | 89.18 | 2019 | |
| Inception-V3-CapsNet [33] | 99.05 | 96.32 | 92.60 | 2019 | |
| DenseNet+FPN [86] | - | 97.13 | 95.11 | 2020 | |
| Petrovska et al. [89] | - | 98.03 | 93.60 | 2020 | |
| MF²Net [136] | - | 95.93 | 92.73 | 2020 | |
| Zhang et al. [95] | 99.50 | 97.44 | 94.98 | 2019 | Parameter reduction |
| BiMobileNet [96] | 99.03 | 96.87 | 94.08 | 2020 | |
| Yan et al. [135] | 94.05 | - | - | 2020 | GAN-based |
| MF-WGAN [134] | 98.40 | 80.35 | - | 2020 | |
| CBAM+RDN [100] | 99.82 | 99.08 | - | 2020 | Attention mechanism |
| Ji et al. [103] | 96.93 | 93.49 | 2020 | ||
| MSA-Network [104] | 98.96 | 96.01 | 93.52 | 2021 | |
| Shen et al. [105] | 99.52 | 96.12 | - | 2021 | |
| MVFLN+VGG-VD16 [106] | 99.52 | 97.30 | 94.46 | 2021 | |
| ResNet-101+EAM [107] | 99.21 | 97.06 | 94.29 | 2021 | |
| MINet [108] | - | 96.63 | 93.96 | 2022 | |
| TRS [124] | 99.52 | 98.48 | 95.56 | 2021 | Transformer-based |
| MFST [125] | - | 97.38 | 94.90 | 2022 | |
| CTNet(ResNet-34) [144] | - | 97.56 | 95.49 | 2022 | |
| CTNet(MobileNet_v2) [144] | - | 97.70 | 95.40 | 2022 | |
| CSAT [127] | 97.86 | 95.44 | 93.06 | 2022 | |
| LG-ViT [122] | 99.93 | 97.67 | 95.60 | 2023 | |
| CaffeNet [78] | 97.80 | 94.42 | 83.16 | 2018 | Miscellaneous * |
| VGG-Net-16 [78] | 98.02 | 94.58 | 83.02 | 2018 | |
| PMS [79] | 98.81 | 95.56 | - | 2018 | |
| Inception-DenseNet [153] | - | - | 96.01 | 2019 | |
| Inception-LSTM [155] | 98.61 | - | - | 2019 | |
| MSDFF [147] | 99.76 | 96.74 | 93.55 | 2020 | |
| FDPResNet [80] | - | - | 95.40 | 2020 | |
| CNN-MLP [75] | 99.86 | - | 97.40 | 2020 | |
| LCPP [77] | 97.54 | 93.12 | - | 2021 | |
| Anwer et al. [157] | - | 93.40 | - | 2021 | |
| Shawky et al. [150] | 99.48 | - | 96.08 | 2021 | |
| DS-CapsNet [139] | - | 95.58 | 91.62 | 2021 | |
| AGOS [142] | 99.88 | 97.43 | 94.91 | 2022 | |
| PCNet [140] | - | 96.70 | 94.59 | 2022 | |
| GLDBS [145] | - | 97.01 | 94.46 | 2022 | |
| MRHNet-50 [149] | - | 95.06 | 91.48 | 2022 | |
| MRHNet-101 [149] | - | 94.82 | 91.64 | 2022 | |
| DFAGCN [137] | 98.48 | 94.88 | 89.29 | 2022 |
| UCM (80%) | AID (50%) | NWPU-RESISC (20%) | |
|---|---|---|---|
| Average accuracy | 98.79 | 95.85 | 93.00 |
| Maximum accuracy | 99.93 | 99.08 | 97.40 |
| Minimum accuracy | 94.05 | 80.35 | 83.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thapa, A.; Horanont, T.; Neupane, B.; Aryal, J. Deep Learning for Remote Sensing Image Scene Classification: A Review and Meta-Analysis. Remote Sens. 2023, 15, 4804. https://doi.org/10.3390/rs15194804
Thapa A, Horanont T, Neupane B, Aryal J. Deep Learning for Remote Sensing Image Scene Classification: A Review and Meta-Analysis. Remote Sensing. 2023; 15(19):4804. https://doi.org/10.3390/rs15194804
Chicago/Turabian StyleThapa, Aakash, Teerayut Horanont, Bipul Neupane, and Jagannath Aryal. 2023. "Deep Learning for Remote Sensing Image Scene Classification: A Review and Meta-Analysis" Remote Sensing 15, no. 19: 4804. https://doi.org/10.3390/rs15194804
APA StyleThapa, A., Horanont, T., Neupane, B., & Aryal, J. (2023). Deep Learning for Remote Sensing Image Scene Classification: A Review and Meta-Analysis. Remote Sensing, 15(19), 4804. https://doi.org/10.3390/rs15194804