
Exploiting Temporal–Spatial Feature Correlations for Sequential Spacecraft Depth Completion


Abstract
:1. Introduction
- (1)
- A novel video depth completion framework is proposed, which can fully exploit spatiotemporal coherence in sequential frames while not requiring prior scene transformation information as an extra input.
- (2)
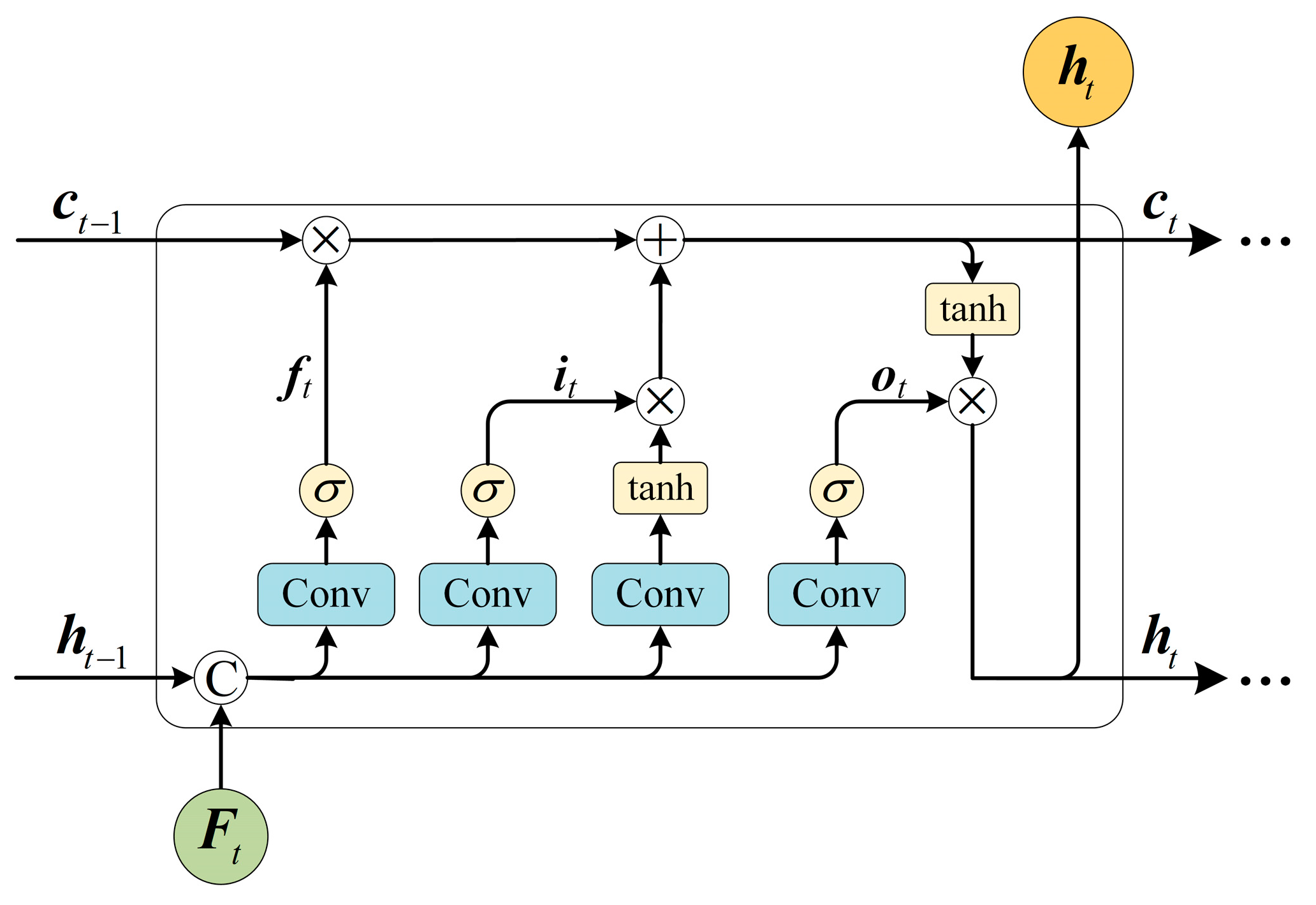
- Convolutional long short-term memory (ConvLSTM) networks were incorporated into the standard decoder hierarchically to model temporal feature distribution shifts, helping the network exploit temporal–spatial feature correlations and predict more accurate and temporally consistent depth results.
- (3)
- A large-scale dataset was constructed based on 126 satellite models for the satellite video depth completion task, which provided sequential gray images, LIDAR data, and corresponding ground truth depth maps.
2. Related Works
3. Material and Methods
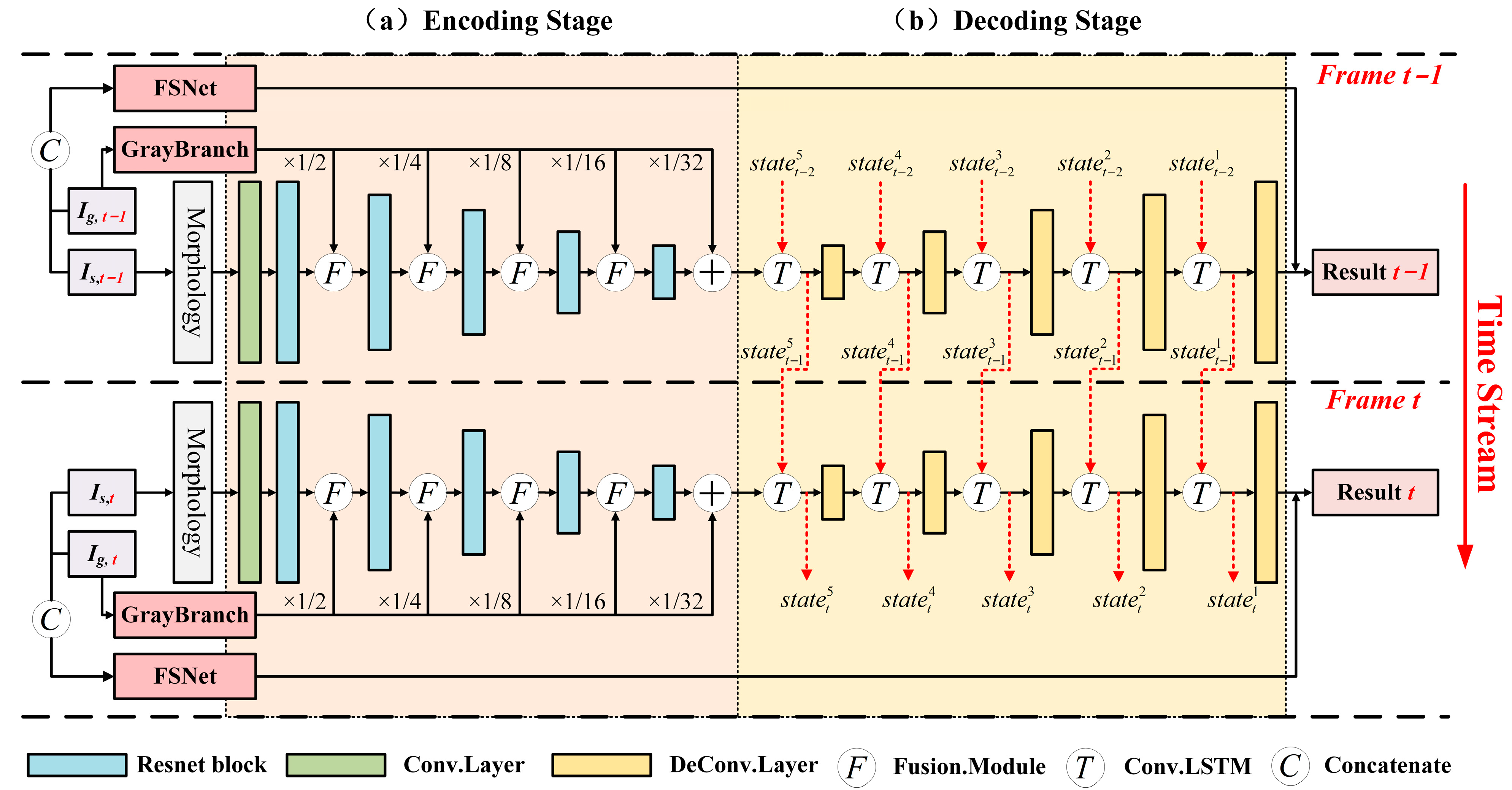
3.1. Model Overview
3.2. Encoding Stage
3.3. Decoding Stage
3.4. Loss Functions
3.5. Dataset Construction
4. Experiment Results and Discussion
4.1. Architecture Details
4.2. Experiment Setup
4.3. Evaluation Metrics
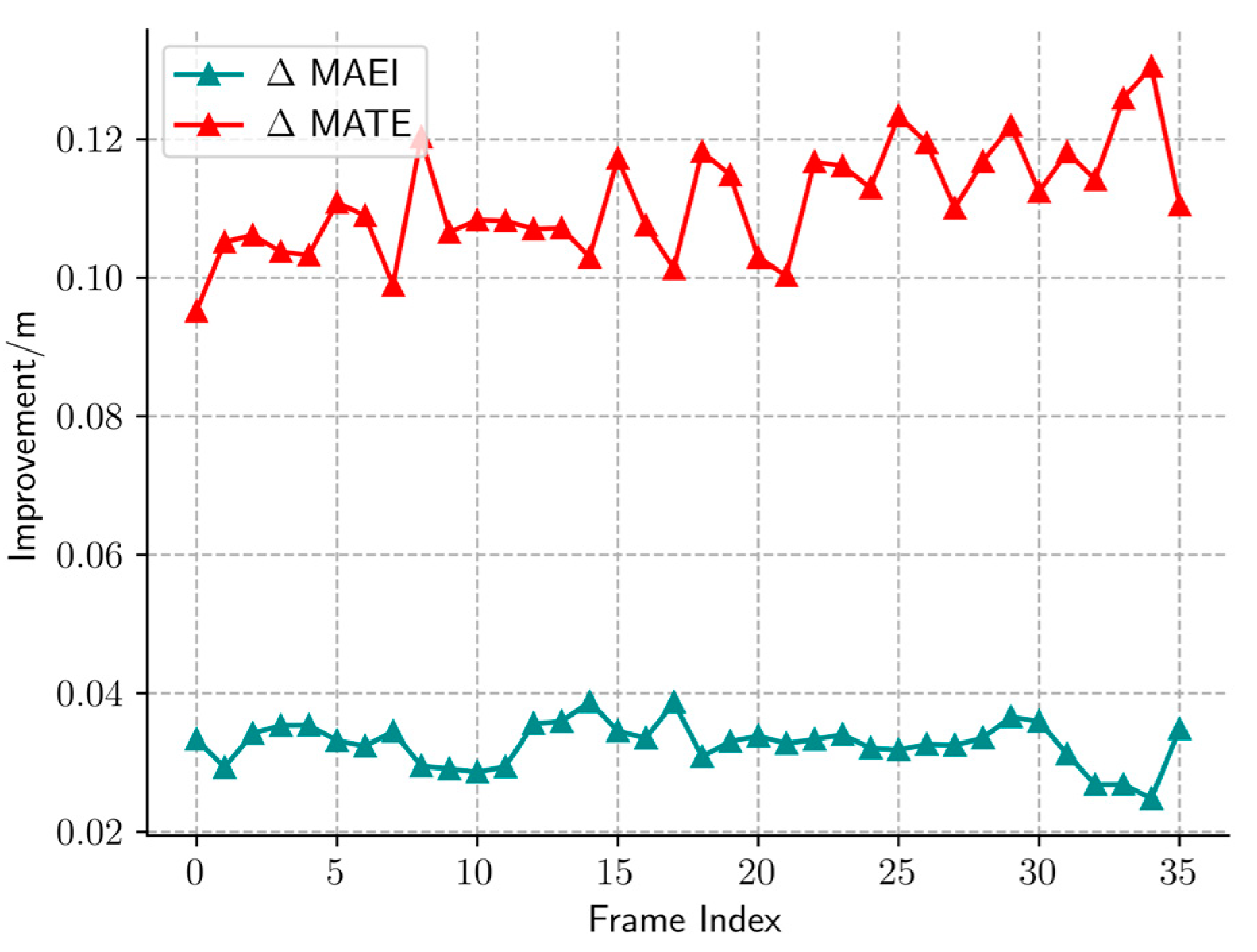
4.4. Results and Discussion
4.5. Ablation Studies
- ConvLSTM utilizes the encoder-generated feature map as input, with its output contributing to subsequent feature decoding (referred to as E-SS modeling).
- ConvLSTM modules are incorporated into the encoding stage with the multi-scale scheme (referred to as E-MS modeling).
- ConvLSTM modules are incorporated into the decoding stage with the multi-scale scheme (referred to as D-MS modeling).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Santos, R.; Rade, D.; Fonseca, D. A machine learning strategy for optimal path planning of space robotic manipulator in on-orbit servicing. Acta Astronaut. 2022, 191, 41–54. [Google Scholar] [CrossRef]
- Henshaw, C. The darpa phoenix spacecraft servicing program: Overview and plans for risk reduction. In Proceedings of the International Symposium on Artificial Intelligence, Robotics and Automation in Space (I-SAIRAS), Montreal, QC, Canada, 17–19 June 2014. [Google Scholar]
- Liu, Y.; Xie, Z.; Liu, H. Three-line structured light vision system for non-cooperative satellites in proximity operations. Chin. J. Aeronaut. 2020, 33, 1494–1504. [Google Scholar] [CrossRef]
- Guo, J.; He, Y.; Qi, X.; Wu, G.; Hu, Y.; Li, B.; Zhang, J. Real-time measurement and estimation of the 3D geometry and motion parameters for spatially unknown moving targets. Aerosp. Sci. Technol. 2020, 97, 105619. [Google Scholar] [CrossRef]
- Liu, X.; Wang, H.; Chen, X.; Chen, W.; Xie, Z. Position Awareness Network for Noncooperative Spacecraft Pose Estimation Based on Point Cloud. IEEE Trans. Aerosp. Electron. Syst. 2022, 59, 507–518. [Google Scholar] [CrossRef]
- Wei, Q.; Jiang, Z.; Zhang, H. Robust spacecraft component detection in point clouds. Sensors 2018, 18, 933. [Google Scholar] [CrossRef] [PubMed]
- De, J.; Jordaan, H.; Van, D. Experiment for pose estimation of uncooperative space debris using stereo vision. Acta Astronaut. 2020, 168, 164–173. [Google Scholar]
- Jacopo, V.; Andreas, F.; Ulrich, W. Pose tracking of a noncooperative spacecraft during docking maneuvers using a time-of-flight sensor. In Proceedings of the AIAA Guidance, Navigation, and Control Conference (GNC), San Diego, CA, USA, 4–8 January 2016. [Google Scholar]
- Liu, X.; Wang, H.; Yan, Z.; Chen, Y.; Chen, X.; Chen, W. Spacecraft depth completion based on the gray image and the sparse depth map. IEEE Trans. Aerosp. Electron. Syst. 2023, in press. [CrossRef]
- Ma, F.; Karaman, S. Sparse-to-dense: Depth prediction from sparse depth samples and a single image. In Proceedings of the International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018. [Google Scholar]
- Imran, S.; Long, Y.; Liu, X.; Morris, D. Depth coefficients for depth completion. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Teixeira, L.; Oswald, M.; Pollefeys, M.; Chli, M. Aerial single-view depth completion with image-guided uncertainty estimation. IEEE Robots. Autom. Lett. 2020, 5, 1055–1062. [Google Scholar] [CrossRef]
- Luo, Z.; Zhang, F.; Fu, G.; Xu, J. Self-Guided Instance-Aware Network for Depth Completion and Enhancement. In Proceedings of the International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Chen, Y.; Yang, B.; Liang, M.; Urtasun, R. Learning joint 2d-3d representations for depth completion. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Tang, J.; Tian, F.; Feng, W.; Li, J.; Tan, P. Learning guided convolutional network for depth completion. IEEE Trans. Image Process. 2020, 30, 1116–1129. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Song, X.; Lyu, X.; Diao, J.; Wang, M.; Liu, Y.; Zhang, L. Fcfr-net: Feature fusion based coarse-to-fine residual learning for depth completion. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Vancouver, BC, Canada, 2–9 February 2021. [Google Scholar]
- Yan, Z.; Wang, K.; Li, X.; Zhang, Z.; Xu, B.; Li, J.; Yang, J. RigNet: Repetitive image guided network for depth completion. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Giang, K.; Song, S.; Kim, D.; Choi, S. Sequential Depth Completion with Confidence Estimation for 3D Model Reconstruction. IEEE Robots. Autom. Lett. 2020, 6, 327–334. [Google Scholar] [CrossRef]
- Nguyen, T.; Yoo, M. Dense-depth-net: A spatial-temporal approach on depth completion task. In Proceedings of the Region 10 Symposium (TENSYMP), Jeju, Korea, 23–25 August 2021. [Google Scholar]
- Chen, Y.; Zhao, S.; Ji, W.; Gong, M.; Xie, L. MetaComp: Learning to Adapt for Online Depth Completion. arXiv 2022, arXiv:2207.10623. [Google Scholar]
- Yang, Q.; Yang, R.; Davis, J.; Nister, D. Spatial-depth super resolution for range images. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Kopf, J.; Cohen, M.; Lischinski, D.; Uyttendaele, M. Joint bilateral upsampling. ACM Trans. Graph. 2007, 26, 96–101. [Google Scholar] [CrossRef]
- Ferstl, D.; Reinbacher, C.; Ranftl, R.; Ruther, M.; Bischof, H. Image guided depth upsampling using anisotropic total generalized variation. In Proceedings of the International Conference on Computer Vision (ICCV), Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar]
- Barron, J.; Poole, B. The fast bilateral solver. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Soohwan, S.; Sungho, J. 3D reconstruction using a sparse laser scanner and a single camera for outdoor autonomous vehicle. In Proceedings of the International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016. [Google Scholar]
- Liu, S.; Mello, D.; Gu, J.; Zhong, G.; Yang, M.; Kautz, J. Learning affinity via spatial propagation networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Cheng, X.; Wang, P.; Yang, R. Learning depth with convolutional spatial propagation network. IEEE Trans Pattern Anal. Mach. Intell. 2019, 42, 2361–2379. [Google Scholar] [CrossRef] [PubMed]
- Cheng, X.; Wang, P.; Guan, C.; Yang, R. Cspn++: Learning context and resource aware convolutional spatial propagation networks for depth completion. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Park, J.; Joo, K.; Hu, Z.; Liu, C.; So, K. Non-local spatial propagation network for depth completion. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, Scotland, UK, 23–28 August 2020. [Google Scholar]
- Lin, Y.; Cheng, T.; Zhong, Q.; Zhou, W.; Yang, H. Dynamic spatial propagation network for depth completion. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Virtual, 22 February–1 March 2022. [Google Scholar]
- Hu, M.; Wang, S.; Li, B.; Ning, S.; Fan, L.; Gong, X. Penet: Towards precise and efficient image guided depth completion. In Proceedings of the International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Li, Y.; Xu, Q.; Li, W.; Nie, J. Automatic clustering-based two-branch CNN for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7803–7816. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Y.; Chan, J. Hyperspectral and multispectral image fusion via deep two-branches convolutional neural network. Remote Sens. 2018, 10, 800. [Google Scholar] [CrossRef]
- Fu, Y.; Wu, X. A dual-branch network for infrared and visible image fusion. In Proceedings of the International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Li, Y.; Xu, Q.; He, Z.; Li, W. Progressive Task-based Universal Network for Raw Infrared Remote Sensing Imagery Ship Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]
- Ku, J.; Harakeh, A.; Waslander, S. In defense of classical image processing: Fast depth completion on the CPU. In Proceedings of the Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 8–10 May 2018. [Google Scholar]
- Uhrig, J.; Schneider, N.; Schneider, L.; Franke, U.; Brox, T.; Geiger, A. Sparsity invariant CNNs. In Proceedings of the International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Wang, H.; Ning, Q.; Yan, Z.; Liu, X.; Lu, Y. Research on elaborate image simulation method for close-range space target. J. Mod. Opt. 2023, 70, 205–216. [Google Scholar] [CrossRef]
- Ma, Y.; Yu, D.; Wu, T.; Wang, H. PaddlePaddle: An open-source deep learning platform from industrial practice. Front. Data Comput. 2019, 1, 105–115. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor Type | Sensor Parameter | Value |
|---|---|---|
| optical camera | focal length | 50 mm |
| field of view | 7.38° × 7.38° | |
| sensor size | 6.449 mm × 6.449 mm | |
| color type | monochrome | |
| image size | 512 pixel × 512 pixel | |
| LIDAR | range | 2–280 m |
| horizontal angle resolution | 0.09° | |
| vertical angle resolution | 0.13° | |
| accuracy (1σ) | 30 mm |
| Layer Index | Layer Type | Layer Parameter/ (k, s, p) | Input Channel | Out Channel |
|---|---|---|---|---|
| 1 | Convolution | (5, 1, 2) | 2 | 16 |
| 2 | Convolution | (3, 2, 1) | 16 | 16 |
| 3 | Convolution | (3, 2, 1) | 16 | 32 |
| 4 | Convolution | (3, 2, 1) | 32 | 64 |
| 5 | Deconvolution | (3, 2, 1) | 64 | 32 |
| 6 | Deconvolution | (3, 2, 1) | 32 | 16 |
| 7 | Deconvolution | (3, 2, 1) | 16 | 16 |
| 8 | Convolution | (3, 1, 1) | 16 | 1 |
| Methods | MAEI/m | MATE/m | RMSEI/m | RMSTE/m | Inference Time/ms |
|---|---|---|---|---|---|
| Sparse-to-dense * [10] | 2.099 | 3.613 | 2.900 | 5.012 | 6.93 |
| CSPN [28] | 1.312 | 2.159 | 1.999 | 3.558 | 47.26 |
| PENet * [32] | 0.260 | 1.085 | 0.727 | 2.927 | 96.72 |
| DySPN * [31] | 0.452 | 0.805 | 0.735 | 2.304 | 45.48 |
| GuideNet * [15] | 0.395 | 0.881 | 1.068 | 2.380 | 39.46 |
| FCFRNet * [16] | 0.821 | 1.386 | 1.533 | 2.799 | 87.55 |
| RigNet * [17] | 0.299 | 1.529 | 0.871 | 3.525 | 53.95 |
| SDCNet [9] | 0.229 | 0.735 | 0.611 | 2.266 | 36.33 |
| S2DCNet (ours) | 0.192 | 0.645 | 0.511 | 2.106 | 42.87 |
| Versions | MAEI/m | MATE/m | RMSEI/m | RMSTE/m |
|---|---|---|---|---|
| baseline | 0.229 | 0.735 | 0.611 | 2.266 |
| E-SS modeling | 0.209 | 0.704 | 0.564 | 2.209 |
| E-MS modeling | 0.199 | 0.687 | 0.547 | 2.186 |
| D-MS modeling | 0.192 | 0.645 | 0.511 | 2.106 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Wang, H.; Chen, X.; Chen, W.; Xie, Z. Exploiting Temporal–Spatial Feature Correlations for Sequential Spacecraft Depth Completion. Remote Sens. 2023, 15, 4786. https://doi.org/10.3390/rs15194786
Liu X, Wang H, Chen X, Chen W, Xie Z. Exploiting Temporal–Spatial Feature Correlations for Sequential Spacecraft Depth Completion. Remote Sensing. 2023; 15(19):4786. https://doi.org/10.3390/rs15194786
Chicago/Turabian StyleLiu, Xiang, Hongyuan Wang, Xinlong Chen, Weichun Chen, and Zhengyou Xie. 2023. "Exploiting Temporal–Spatial Feature Correlations for Sequential Spacecraft Depth Completion" Remote Sensing 15, no. 19: 4786. https://doi.org/10.3390/rs15194786
APA StyleLiu, X., Wang, H., Chen, X., Chen, W., & Xie, Z. (2023). Exploiting Temporal–Spatial Feature Correlations for Sequential Spacecraft Depth Completion. Remote Sensing, 15(19), 4786. https://doi.org/10.3390/rs15194786