
Vector Decomposition-Based Arbitrary-Oriented Object Detection for Optical Remote Sensing Images





Abstract
:
1. Introduction
- We propose a novel vector-decomposition-based representation for an oriented bounding box, which requires fewer parameters (). Compared to similar algorithms, the proposed representation method is significantly simpler, making it easier to implement and understand. Moreover, it addresses the issues of corner cases in BBAVectors and the problem of focal disappearing in AEDet, which are common in other existing methods.
- We propose the angle-to-vector encode (ATVEncode) and vector-to-angle decode (VTADecode) modules to improve the implementation of converting between angle-based representation and the proposed representation. The conversion process of the ATVEncode and VTADecode modules converts all oriented bounding boxes of a batch of images simultaneously into the form of a matrix, eliminating the need for one-by-one processing. This significantly shortens the data-processing time and accelerates the training of the object-detection network
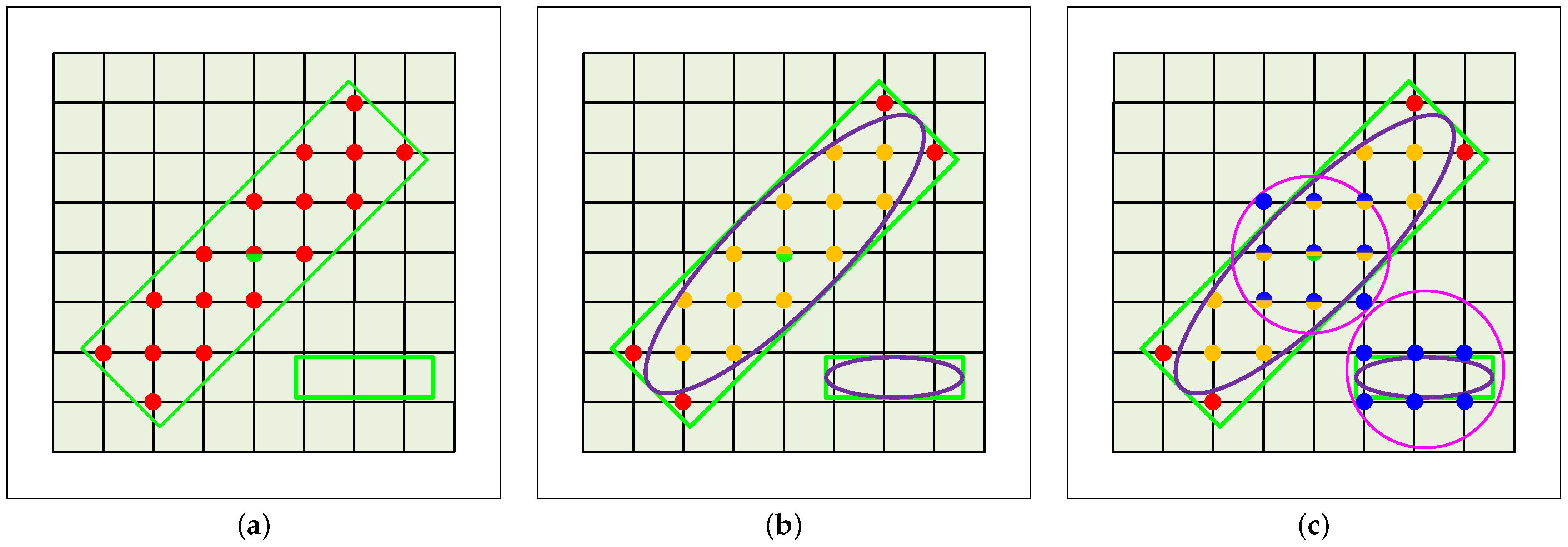
- We propose an AdaCFPS module to dynamically select the most-suitable positive samples. The AdaCFPS module initially identifies coarse positive samples based on the ground-truth-oriented bounding box. Subsequently, the Kullback–Leibler divergence loss [13] is utilized to assess the matching degree between the ground-truth-oriented bounding box and the coarse-positive-oriented bounding box. Finally, the positive samples that exhibit the highest matching degree are dynamically selected.
- We developed the anchor-free vector-object-detection (VODet) model based on the proposed representation method and modules. VODet’s outstanding performance in object detection was demonstrated through experiments on the HRSC2016 [14], DIOR-R [15], and DOTA [16] datasets, showcasing its effectiveness. Additionally, the experimental results revealed that VODet boasts several advantages, including a fast processing speed, fewer parameters, and high precision. When compared to similar algorithms, VODet achieved the best results, highlighting the superiority of our vector-decomposition-based arbitrarily oriented object-detection method.
2. Related Work
2.1. Angle-Based Methods
2.2. Keypoint-Based Methods
2.3. Other Methods
3. The Proposed Method
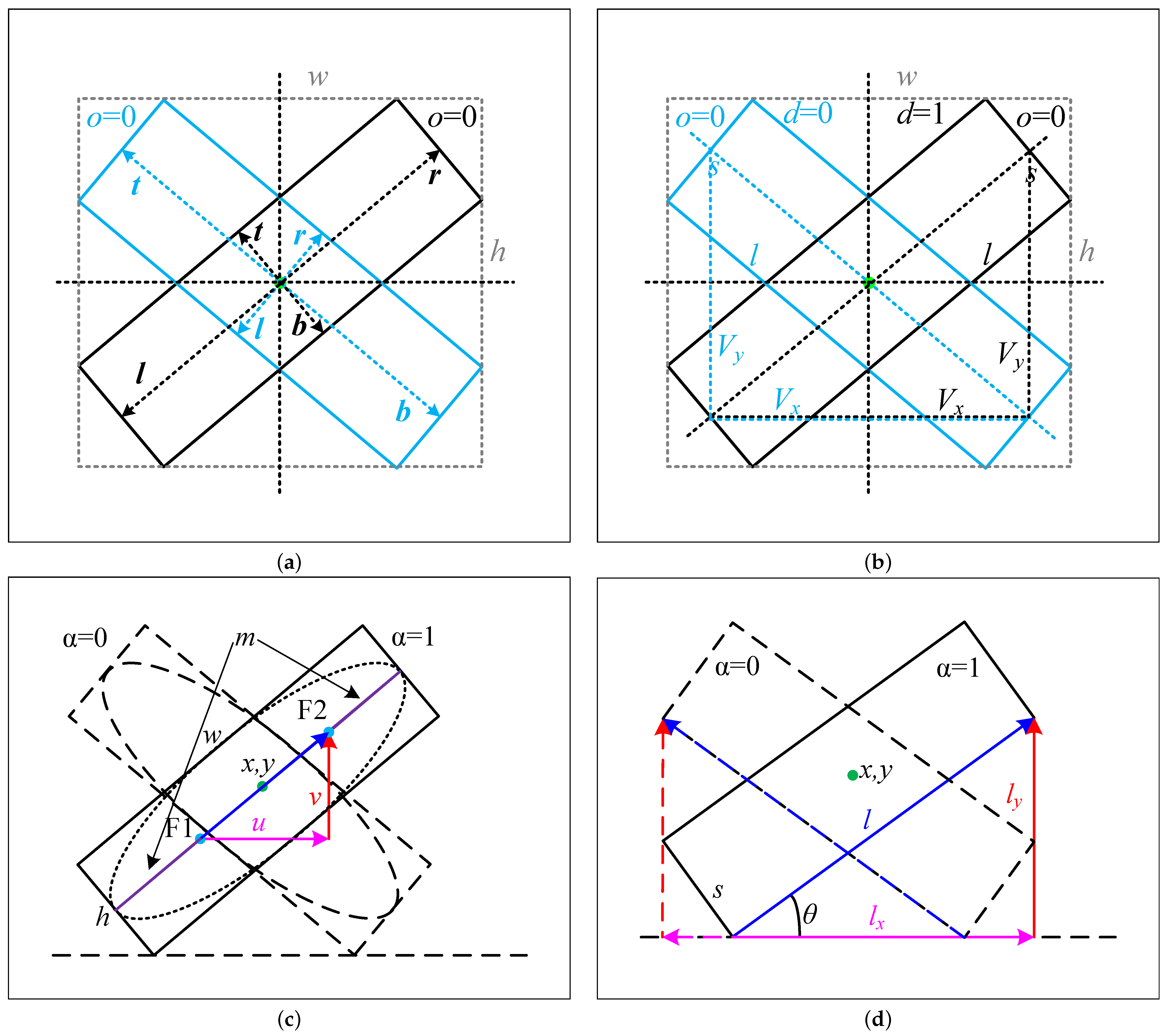
3.1. The Representation of Oriented Bounding Box
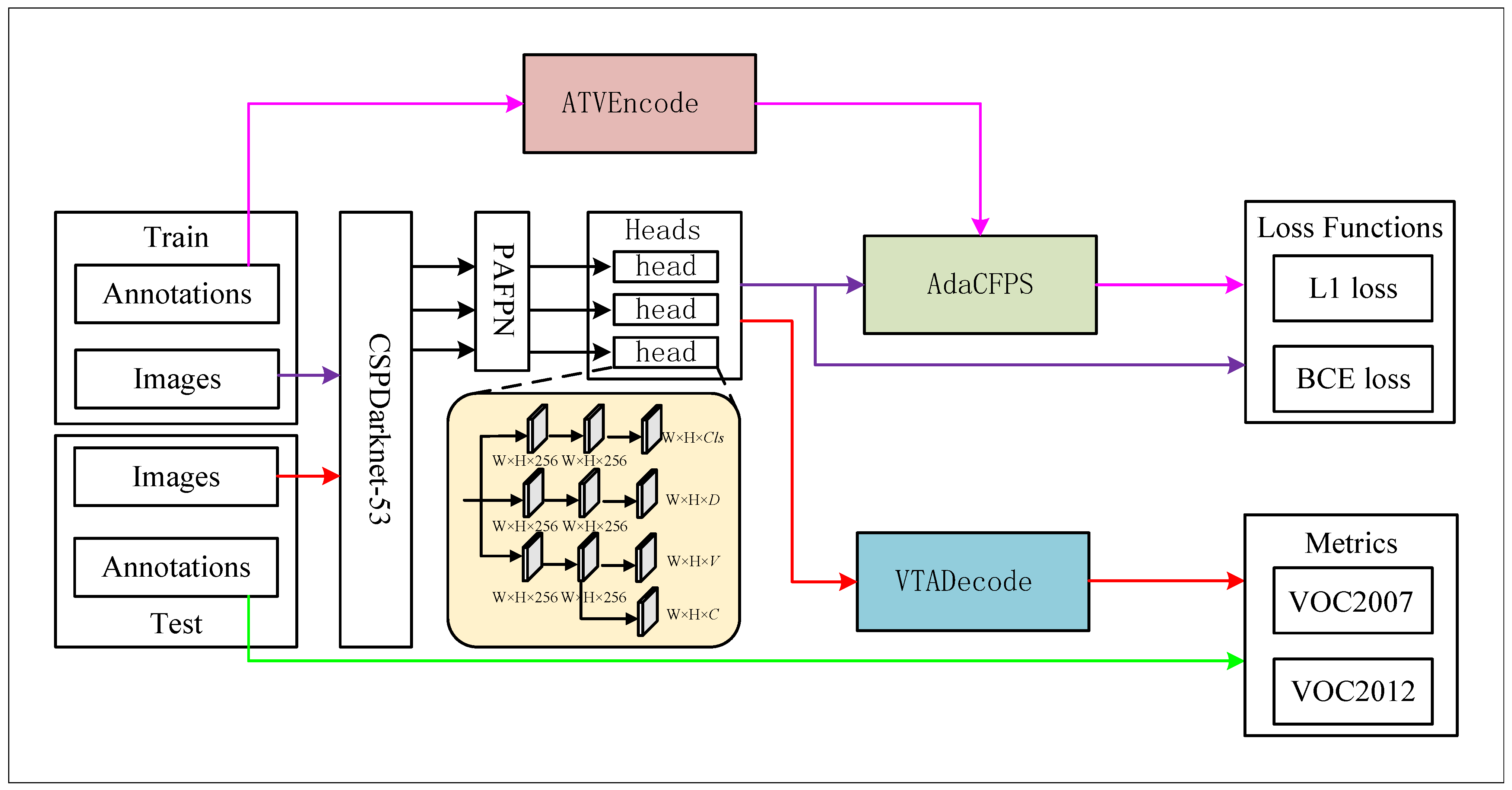
3.2. The Overall Structure of Proposed Method
3.3. The Proposed ATVEncode Module
| Algorithm 1 Angle-to-vector encode (Pytorch-style) |
|
|
3.4. The Proposed AdaCFPS Module
| Algorithm 2 Adaptive coarse-to-fine positive sample selection (Pytorch style) |
| Input: , which is an matrix; n means the number of ground truth bounding boxes; |
| means the long edge representation vector with the angle, i.e., (); |
| , which is a feature map with stride ; are the coordinates of . For |
| simplicity, is reshaped to , where n means the number of ground truth |
| bounding boxes; 2 means and ; |
| , which is an matrix; means the number of predicted bounding boxes; |
| means the predicted vector with vector decomposition, i.e., (); |
| , which is an matrix; n means the number of ground truth bounding boxes; “1” |
| indicates the category to which the ground truth bounding box belongs; |
| , which is an matrix; means the number of predicted bounding boxes; |
| c indicates the number of object categories. |
| Output: , which is a matrix; d means the number of predicted fine positive bounding |
| boxes; means the representation vector with the angle, i.e., () |
|
3.5. The Proposed VTADecode Module
| Algorithm 3 Vector-to-angle decode (Pytorch style) |
| Input: , which is an matrix; n means the number of predicted bounding boxes; |
| means the predicted vector with vector decomposition, i.e., () |
| Output: , which is an matrix; n means the number of predicted bounding boxes; |
| means the representation vector with the angle, i.e., () |
|
4. Experiments and Analysis
4.1. Experiment Settings
4.2. Experiment Datasets
4.2.1. HRSC2016
4.2.2. DOTA
4.2.3. DIOR-R
4.3. Experiments on HRSC2016
4.4. Experiments on DOTA
4.5. Experiments on DIOR-R
4.6. Ablation Experiments
4.7. The Comparison to Related Algorithms
4.8. Model Parameters and Inference Time
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, X.; Yan, J. Arbitrarily oriented object detection with circular smooth label. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 677–694. [Google Scholar]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L. Dynamic anchor learning for arbitrarily oriented object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 2355–2363. [Google Scholar]
- Fu, K.; Chang, Z.; Zhang, Y.; Sun, X. Point-based estimator for arbitrarily oriented object detection in aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4370–4387. [Google Scholar] [CrossRef]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking rotated object detection with gaussian wasserstein distance loss. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 11830–11841. [Google Scholar]
- Qian, W.; Yang, X.; Peng, S.; Yan, J.; Guo, Y. Learning modulated loss for rotated object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 2458–2466. [Google Scholar]
- Yang, X.; Hou, L.; Zhou, Y.; Wang, W.; Yan, J. Dense label encoding for boundary discontinuity free rotation detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 15819–15829. [Google Scholar]
- Yi, J.; Wu, P.; Liu, B.; Huang, Q.; Qu, H.; Metaxas, D. Oriented object detection in aerial images with box boundary-aware vectors. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Online, 5–9 January 2021; pp. 2150–2159. [Google Scholar]
- Wu, Q.; Xiang, W.; Tang, R.; Zhu, J. Bounding Box Projection for Regression Uncertainty in Oriented Object Detection. IEEE Access 2021, 9, 58768–58779. [Google Scholar] [CrossRef]
- He, X.; Ma, S.; He, L.; Ru, L.; Wang, C. Learning Rotated Inscribed Ellipse for Oriented Object Detection in Remote Sensing Images. Remote Sens. 2021, 13, 3622. [Google Scholar] [CrossRef]
- Zhou, K.; Zhang, M.; Zhao, H.; Tang, R.; Lin, S.; Cheng, X.; Wang, H. Arbitrarily oriented Ellipse Detector for Ship Detection in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 7151–7162. [Google Scholar] [CrossRef]
- Jiang, X.; Xie, H.; Chen, J.; Zhang, J.; Wang, G.; Xie, K. Arbitrary-Oriented Ship Detection Method Based on Long-Edge Decomposition Rotated Bounding Box Encoding in SAR Images. Remote Sens. 2023, 15, 673. [Google Scholar] [CrossRef]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning high-precision bounding box for rotated object detection via kullback-leibler divergence. Adv. Neural Inf. Process. Syst. 2021, 34, 18381–18394. [Google Scholar]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship rotated bounding box space for ship extraction from high-resolution optical satellite images with complex backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, J.; Li, K.; Xie, X.; Lang, C.; Yao, Y.; Han, J. Anchor-free oriented proposal generator for object detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Yang, L.; Chen, Y.; Song, S.; Li, F.; Huang, G. Deep Siamese networks based change detection with remote sensing images. Remote Sens. 2021, 13, 3394. [Google Scholar] [CrossRef]
- Zhu, Q.; Guo, X.; Deng, W.; Shi, S.; Guan, Q.; Zhong, Y.; Zhang, L.; Li, D. Land-use/land-cover change detection based on a Siamese global learning framework for high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 63–78. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, L.; Cheng, S.; Li, Y. SwinSUNet: Pure transformer network for remote sensing image change detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Rabbi, J.; Ray, N.; Schubert, M.; Chowdhury, S.; Chao, D. Small-object detection in remote sensing images with end-to-end edge-enhanced GAN and object detector network. Remote Sens. 2020, 12, 1432. [Google Scholar] [CrossRef]
- Zhou, K.; Zhang, M.; Lin, S.; Zhang, R.; Wang, H. Single-stage object detector with local binary pattern for remote sensing images. Int. J. Remote Sens. 2023, 44, 4137–4162. [Google Scholar] [CrossRef]
- Cheng, X.; Zhang, M.; Lin, S.; Zhou, K.; Zhao, S.; Wang, H. Two-Stream Isolation Forest Based on Deep Features for Hyperspectral Anomaly Detection. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Wang, M.; Wang, Q.; Hong, D.; Roy, S.K.; Chanussot, J. Learning tensor low-rank representation for hyperspectral anomaly detection. IEEE Trans. Cybern. 2022, 53, 679–691. [Google Scholar] [CrossRef]
- Lin, S.; Zhang, M.; Cheng, X.; Wang, L.; Xu, M.; Wang, H. Hyperspectral anomaly detection via dual dictionaries construction guided by two-stage complementary decision. Remote Sens. 2022, 14, 1784. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Lei, L.; Zou, H. Arbitrarily oriented vehicle detection in aerial imagery with single convolutional neural networks. Remote Sens. 2017, 9, 1170. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, J.; Weng, L.; Yang, Y. Rotated region based CNN for ship detection. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 900–904. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.S. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 3163–3171. [Google Scholar]
- Chen, Z.; Chen, K.; Lin, W.; See, J.; Yu, H.; Ke, Y.; Yang, C. Piou loss: Towards accurate oriented object detection in complex environments. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 195–211. [Google Scholar]
- Yang, X.; Yan, J. On the arbitrarily oriented object detection: Classification based approaches revisited. Int. J. Comput. Vis. 2022, 130, 1340–1365. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 2786–2795. [Google Scholar]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. CFC-Net: A critical feature capturing network for arbitrarily oriented object detection in remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Liao, W.; Yang, X.; Tang, J.; He, T. Scrdet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2384–2399. [Google Scholar] [CrossRef] [PubMed]
- Lu, D.; Li, D.; Li, Y.; Wang, S. OSKDet: Orientation-sensitive keypoint localization for rotated object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1182–1192. [Google Scholar]
- Li, W.; Chen, Y.; Hu, K.; Zhu, J. Oriented reppoints for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1829–1838. [Google Scholar]
- Guo, Z.; Liu, C.; Zhang, X.; Jiao, J.; Ji, X.; Ye, Q. Beyond bounding-box: Convex-hull feature adaptation for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8792–8801. [Google Scholar]
- Dai, P.; Yao, S.; Li, Z.; Zhang, S.; Cao, X. ACE: Anchor-free corner evolution for real-time arbitrarily-oriented object detection. IEEE Trans. Image Process. 2022, 31, 4076–4089. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Sun, X.; Wang, Z.; Fu, K. Oriented ship detection based on strong scattering points network in large-scale SAR images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Fu, K.; Fu, J.; Wang, Z.; Sun, X. Scattering-keypoint-guided network for oriented ship detection in high-resolution and large-scale SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11162–11178. [Google Scholar] [CrossRef]
- Cui, Z.; Leng, J.; Liu, Y.; Zhang, T.; Quan, P.; Zhao, W. SKNet: Detecting rotated ships as keypoints in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8826–8840. [Google Scholar] [CrossRef]
- Chen, X.; Ma, L.; Du, Q. Oriented object detection by searching corner points in remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, R.; Zhao, W.; Shen, S.; Wang, N. APS-Net: An Adaptive Point Set Network for Optical Remote-Sensing Object Detection. IEEE Geosci. Remote Sens. Lett. 2022, 20, 1–5. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, X.; Zhou, S.; Wang, Y.; Hou, Y. Arbitrarily oriented ship detection through center-head point extraction. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar]
- Zhou, Q.; Yu, C. Point rcnn: An angle-free framework for rotated object detection. Remote Sens. 2022, 14, 2605. [Google Scholar] [CrossRef]
- Wang, J.; Yang, L.; Li, F. Predicting arbitrarily oriented objects as points in remote sensing images. Remote Sens. 2021, 13, 3731. [Google Scholar] [CrossRef]
- Wei, H.; Zhang, Y.; Chang, Z.; Li, H.; Wang, H.; Sun, X. Oriented objects as pairs of middle lines. ISPRS J. Photogramm. Remote Sens. 2020, 169, 268–279. [Google Scholar] [CrossRef]
- He, Y.; Gao, F.; Wang, J.; Hussain, A.; Yang, E.; Zhou, H. Learning polar encodings for arbitrarily oriented ship detection in SAR images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2021, 14, 3846–3859. [Google Scholar] [CrossRef]
- Zhou, L.; Wei, H.; Li, H.; Zhao, W.; Zhang, Y.; Zhang, Y. Arbitrarily oriented object detection in remote sensing images based on polar coordinates. IEEE Access 2020, 8, 223373–223384. [Google Scholar] [CrossRef]
- Zhao, P.; Qu, Z.; Bu, Y.; Tan, W.; Guan, Q. Polardet: A fast, more precise detector for rotated target in aerial images. Int. J. Remote Sens. 2021, 42, 5831–5861. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Yang, X.; Zhang, G.; Li, W.; Wang, X.; Zhou, Y.; Yan, J. H2RBox: Horizonal Box Annotation is All You Need for Oriented Object Detection. arXiv 2022, arXiv:2210.06742. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrarily oriented scene text detection via rotation proposals. IEEE Trans. Multimedia 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational region CNN for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Wang, J.; Yang, W.; Li, H.C.; Zhang, H.; Xia, G.S. Learning center probability map for detecting objects in aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4307–4323. [Google Scholar] [CrossRef]
- Liao, M.; Zhu, Z.; Shi, B.; Xia, G.S.; Bai, X. Rotation-sensitive regression for oriented scene text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5909–5918. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic refinement network for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11207–11216. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Cheng, G.; Yao, Y.; Li, S.; Li, K.; Xie, X.; Wang, J.; Yao, X.; Han, J. Dual-aligned oriented detector. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Yang, L.; Zheng, Z.; Wang, J.; Song, S.; Huang, G.; Li, F. An Adaptive Object Detection System based on Early-exit Neural Networks. IEEE Trans. Cogn. Dev. Syst. 2023. [Google Scholar] [CrossRef]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-insensitive and context-augmented object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2337–2348. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Yao, Y.; Cheng, G.; Wang, G.; Li, S.; Zhou, P.; Xie, X.; Han, J. On Improving Bounding Box Representations for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 61, 1–11. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Backbone | Size | mAP (VOC2007) | mAP (VOC2012) |
|---|---|---|---|---|
| Two-stage method | ||||
| Rotated RPN [56] | ResNet-101 | 800 × 800 | 79.08 | 85.64 |
| R2CNN [57] | ResNet-101 | 800 × 800 | 73.07 | 79.73 |
| RoI Transformer [28] | ResNet-101 | 512 × 800 | 86.20 | - |
| Gliding Vertex [4] | ResNet-101 | 512 × 800 | 88.20 | - |
| CenterMap-Net [58] | ResNet-50 | - | - | 92.80 |
| Oriented R-CNN [52] | ResNet-50 | - | 90.40 | 96.50 |
| FPN-CSL [1] | ResNet-101 | - | 89.62 | 96.10 |
| one-stage method | ||||
| R3Det [30] | ResNet-101 | 800 × 800 | 89.26 | 96.01 |
| DAL [2] | ResNet-101 | 800 × 800 | 89.77 | - |
| S2ANet [29] | ResNet-101 | 512 × 800 | 90.17 | 95.01 |
| RRD [59] | VGG16 | 384 × 384 | 84.30 | - |
| RetinaNet-O [60] | ResNet-101 | 800 × 800 | 89.18 | 95.21 |
| PIoU [31] | DLA-34 | 512 × 512 | 89.20 | - |
| DRN [61] | Hourglass-34 | 768 × 768 | - | 92.70 |
| CenterNet-O [62] | DLA-34 | - | 87.89 | - |
| AEDet [11] | CSPDarknet-53 | 800 × 800 | 90.45 | 96.90 |
| ours | ||||
| VODet | CSPDarknet-53 | 800 × 800 | 90.23 | 96.25 |
| Methods | Backbone | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| two-stage method | |||||||||||||||||
| CenterMap-Net [58] | ResNet-50 | 89.0 | 80.6 | 49.4 | 62.0 | 78.0 | 74.2 | 83.7 | 89.4 | 78.0 | 83.5 | 47.6 | 65.9 | 63.7 | 67.1 | 61.6 | 71.6 |
| SCRDet [63] | ResNet-101 | 90.0 | 80.7 | 52.1 | 68.4 | 68.4 | 60.3 | 72.4 | 90.9 | 87.9 | 86.9 | 65.0 | 66.7 | 66.3 | 68.2 | 65.2 | 72.6 |
| RoI Transformer [28] | ResNet-101 | 88.6 | 78.5 | 43.4 | 75.9 | 68.8 | 73.7 | 83.6 | 90.7 | 77.3 | 81.5 | 58.4 | 53.5 | 62.8 | 58.9 | 47.7 | 69.6 |
| FPN-CSL [1] | ResNet-152 | 90.3 | 85.5 | 54.6 | 75.3 | 70.4 | 73.5 | 77.6 | 90.8 | 86.2 | 86.7 | 69.6 | 68.0 | 73.8 | 71.1 | 68.9 | 76.2 |
| Gliding Vertex [4] | ResNet-101 | 89.6 | 85.0 | 52.3 | 77.3 | 73.0 | 73.1 | 86.8 | 90.7 | 79.0 | 86.8 | 59.6 | 70.9 | 72.9 | 70.9 | 57.3 | 75.0 |
| FR-Est [3] | ResNet-101 | 89.6 | 81.2 | 50.4 | 70.2 | 73.5 | 78.0 | 86.4 | 90.8 | 84.1 | 83.6 | 60.6 | 66.6 | 70.6 | 66.7 | 60.6 | 74.2 |
| DODet [64] | ResNet-50 | 89.3 | 84.3 | 51.4 | 71.0 | 79.0 | 82.9 | 88.2 | 90.9 | 86.9 | 84.9 | 62.7 | 67.6 | 75.5 | 72.2 | 45.5 | 75.5 |
| Oriented R-CNN [52] | ResNet-50 | 89.5 | 82.1 | 54.8 | 70.9 | 78.9 | 83.0 | 88.2 | 90.9 | 87.5 | 84.7 | 64.0 | 67.7 | 74.9 | 68.8 | 52.3 | 75.9 |
| AOPG [15] | ResNet-50 | 89.3 | 83.5 | 52.5 | 70.0 | 73.5 | 82.3 | 88.0 | 90.9 | 87.6 | 84.7 | 60.0 | 66.1 | 74.2 | 68.3 | 57.8 | 75.2 |
| one-stage method | |||||||||||||||||
| RetinaNet-O [60] | ResNet-50 | 88.7 | 77.6 | 41.8 | 58.2 | 74.6 | 71.6 | 79.1 | 90.3 | 82.2 | 74.3 | 54.8 | 60.6 | 62.6 | 69.6 | 60.6 | 68.4 |
| S2ANet [29] | ResNet-50 | 89.1 | 82.8 | 48.4 | 71.1 | 78.1 | 78.4 | 87.3 | 90.8 | 84.9 | 85.6 | 60.4 | 62.6 | 65.3 | 69.1 | 57.9 | 74.1 |
| R3Det [30] | ResNet-101 | 88.8 | 83.1 | 50.9 | 67.3 | 76.2 | 80.4 | 86.7 | 90.8 | 84.7 | 83.2 | 62.0 | 61.4 | 66.9 | 70.6 | 53.9 | 73.8 |
| DAL [2] | ResNet-50 | 88.7 | 76.6 | 45.1 | 66.8 | 67.0 | 76.8 | 79.7 | 90.8 | 79.5 | 78.5 | 57.7 | 62.3 | 69.1 | 73.1 | 60.1 | 71.4 |
| AEDet [11] | CSPDarknet-53 | 87.5 | 77.6 | 51.7 | 68.2 | 78.0 | 80.5 | 86.5 | 90.3 | 80.7 | 75.4 | 54.6 | 59.6 | 73.4 | 73.8 | 53.8 | 72.8 |
| DRN [61] | Hourglass-104 | 88.9 | 80.2 | 43.5 | 63.4 | 73.5 | 70.7 | 84.9 | 90.1 | 83.9 | 84.1 | 50.1 | 58.4 | 67.6 | 68.6 | 52.5 | 70.7 |
| RSDet [6] | ResNet-101 | 89.8 | 82.9 | 48.6 | 65.2 | 69.5 | 70.1 | 70.2 | 90.5 | 85.6 | 83.4 | 62.5 | 63.9 | 65.6 | 67.2 | 68.0 | 72.2 |
| ours | |||||||||||||||||
| VODet | CSPDarknet-53 | 86.3 | 80.0 | 52.4 | 67.9 | 79.3 | 83.9 | 87.9 | 90.8 | 87.6 | 85.6 | 63.3 | 61.2 | 75.8 | 78.9 | 54.5 | 75.7 |
| VODet | CSPDarknet-53 | 88.8 | 83.6 | 53.2 | 78.7 | 79.9 | 84.1 | 88.5 | 90.8 | 88.1 | 86.2 | 64.4 | 67.7 | 76.9 | 79.7 | 57.8 | 77.8 |
| Methods | Faster R-CNN-O [67] | RetinaNet-O [60] | Gliding Vertex [4] | RoI Transformer [28] | AOPG [15] | DODet [64] | QPDet [68] | AEDet [11] | VODet |
|---|---|---|---|---|---|---|---|---|---|
| Backbone | ResNet-50 | ResNet-50 | ResNet-50 | ResNet-50 | ResNet-50 | ResNet-50 | ResNet-50 | CSPDarknet-53 | CSPDarknet-53 |
| APL | 62.79 | 61.49 | 65.35 | 63.34 | 62.39 | 63.40 | 63.22 | 81.06 | 85.74 |
| APO | 26.80 | 28.52 | 28.87 | 37.88 | 37.79 | 43.35 | 41.39 | 48.09 | 53.15 |
| BF | 71.72 | 73.57 | 74.96 | 71.78 | 71.62 | 72.11 | 71.97 | 77.35 | 76.25 |
| BC | 80.91 | 81.17 | 81.33 | 87.53 | 87.63 | 81.32 | 88.55 | 89.66 | 89.41 |
| BR | 34.20 | 23.98 | 33.88 | 40.68 | 40.90 | 43.12 | 41.23 | 43.46 | 35.49 |
| CH | 72.57 | 72.54 | 74.31 | 72.60 | 72.47 | 72.59 | 72.63 | 76.42 | 72.47 |
| DAM | 18.95 | 19.94 | 19.58 | 26.86 | 31.08 | 33.32 | 28.82 | 27.46 | 31.30 |
| ETS | 66.45 | 72.39 | 70.72 | 78.71 | 65.42 | 78.77 | 78.90 | 71.83 | 74.31 |
| ESA | 65.75 | 58.20 | 64.70 | 68.09 | 77.99 | 70.84 | 69.00 | 79.60 | 81.82 |
| GF | 66.63 | 69.25 | 72.30 | 68.96 | 73.20 | 74.15 | 70.07 | 59.06 | 72.51 |
| GTF | 79.24 | 79.54 | 78.68 | 82.74 | 81.94 | 75.47 | 83.01 | 76.51 | 80.65 |
| HA | 34.95 | 32.14 | 37.22 | 47.71 | 42.32 | 48.00 | 47.83 | 45.40 | 46.26 |
| OP | 48.79 | 44.87 | 49.64 | 55.61 | 54.45 | 59.31 | 55.54 | 56.91 | 50.27 |
| SH | 81.14 | 77.71 | 80.22 | 81.21 | 81.17 | 85.41 | 81.23 | 88.50 | 89.15 |
| STA | 64.34 | 67.57 | 69.26 | 78.23 | 72.69 | 74.04 | 72.15 | 70.33 | 62.49 |
| STO | 71.21 | 61.09 | 61.13 | 70.26 | 71.31 | 71.56 | 62.66 | 68.55 | 73.25 |
| TC | 81.44 | 81.46 | 81.49 | 81.61 | 81.49 | 81.52 | 89.05 | 90.23 | 90.28 |
| TS | 47.31 | 47.33 | 44.76 | 54.86 | 60.04 | 55.47 | 58.09 | 48.80 | 58.62 |
| VE | 50.46 | 38.01 | 47.71 | 43.27 | 52.38 | 51.86 | 43.38 | 59.00 | 58.92 |
| WM | 65.21 | 60.24 | 65.04 | 65.52 | 69.99 | 66.40 | 65.36 | 64.69 | 70.34 |
| mAP | 59.54 | 57.55 | 60.06 | 63.87 | 64.41 | 65.10 | 64.20 | 66.14 | 67.66 |
| MS_Train | SC_Crop | Focal Loss | AP | AP | AP |
|---|---|---|---|---|---|
| × | ✓ | ✓ | 44.34 | 72.90 | 46.84 |
| ✓ | ✓ | ✓ | 45.50 | 73.84 | 48.21 |
| ✓ | ✓ | × | 46.74 | 75.68 | 49.07 |
| ✓ | × | ✓ | 49.23 | 76.56 | 52.89 |
| ✓ | × | × | 49.65 | 77.76 | 54.41 |
| Methods | BBAVectors [8] | ProjBB [9] | RIE [10] | AEDet [11] | VODet | VODet |
|---|---|---|---|---|---|---|
| Backbone | ResNet-101 | ResNet-101 | HRGANet-W48 | CSPDarknet-53 | CSPDarknet-53 | CSPDarknet-53 |
| PL | 88.35 | 88.96 | 89.23 | 87.46 | 86.34 | 88.83 |
| BD | 79.96 | 79.32 | 84.86 | 77.64 | 79.95 | 83.58 |
| BR | 50.69 | 53.98 | 55.69 | 51.71 | 52.43 | 53.17 |
| GTF | 62.18 | 70.21 | 70.32 | 68.21 | 67.90 | 78.70 |
| SV | 78.43 | 60.67 | 75.76 | 77.99 | 79.32 | 79.88 |
| LV | 78.98 | 76.20 | 80.68 | 80.53 | 83.85 | 84.15 |
| SH | 87.94 | 89.71 | 86.14 | 86.53 | 87.87 | 88.55 |
| TC | 90.85 | 90.22 | 90.26 | 90.33 | 90.85 | 90.82 |
| BC | 83.58 | 78.94 | 80.17 | 80.75 | 87.57 | 88.12 |
| ST | 84.35 | 76.82 | 81.34 | 75.44 | 85.57 | 86.18 |
| SBF | 54.13 | 60.49 | 59.36 | 54.63 | 63.26 | 62.38 |
| RA | 60.24 | 63.62 | 63.24 | 59.64 | 61.19 | 67.65 |
| HA | 65.22 | 73.12 | 74.12 | 73.35 | 75.75 | 76.91 |
| SP | 64.28 | 71.43 | 70.87 | 73.76 | 78.87 | 79.69 |
| HC | 55.70 | 61.96 | 60.36 | 53.82 | 54.53 | 57.81 |
| mAP | 72.32 | 73.03 | 74.83 | 72.79 | 75.68 | 77.76 |
| Datasets | Methods | AP | Model Parameters (M) | Inference Time (ms) |
|---|---|---|---|---|
| DOTA | AEDet | 72.79 | 27.28 | 87.44 |
| VODet | 77.76 | 27.28 | 25.89 | |
| DIOR-R | AEDet | 66.14 | 27.29 | 69.86 |
| VODet | 67.66 | 27.29 | 18.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, K.; Zhang, M.; Dong, Y.; Tan, J.; Zhao, S.; Wang, H. Vector Decomposition-Based Arbitrary-Oriented Object Detection for Optical Remote Sensing Images. Remote Sens. 2023, 15, 4738. https://doi.org/10.3390/rs15194738
Zhou K, Zhang M, Dong Y, Tan J, Zhao S, Wang H. Vector Decomposition-Based Arbitrary-Oriented Object Detection for Optical Remote Sensing Images. Remote Sensing. 2023; 15(19):4738. https://doi.org/10.3390/rs15194738
Chicago/Turabian StyleZhou, Kexue, Min Zhang, Youqiang Dong, Jinlin Tan, Shaobo Zhao, and Hai Wang. 2023. "Vector Decomposition-Based Arbitrary-Oriented Object Detection for Optical Remote Sensing Images" Remote Sensing 15, no. 19: 4738. https://doi.org/10.3390/rs15194738
APA StyleZhou, K., Zhang, M., Dong, Y., Tan, J., Zhao, S., & Wang, H. (2023). Vector Decomposition-Based Arbitrary-Oriented Object Detection for Optical Remote Sensing Images. Remote Sensing, 15(19), 4738. https://doi.org/10.3390/rs15194738