1. Introduction
Automated mapping of the built environment using remote sensing data is a rapidly growing field. This growth is driven by recent advances in machine learning, the increasing availability of high-quality data, and shifts in patterns of human habitation [
1]. In particular, approaches that take advantage of recently developed machine learning techniques and multiple data modalities (e.g., Light Detection And Ranging [LiDAR], synthetic aperture radar [SAR], high-resolution imaging, imaging spectroscopy) are currently the focus of intensive research [
2]. In this paper we develop, describe, test, and apply a method that takes advantage of the complementary information contained in LiDAR and spectroscopic data. The method combines a convolutional neural network and gradient boosting trees to locate residential buildings in a wide variety of landscape types. We use this method to produce maps of buildings over 3200 km
2 of Hawai’i Island, and we demonstrate that it yields high-quality results.
As an island with three active volcanoes, an accurate inventory of Hawai’i Island’s built environment is essential for emergency planning and disaster response [
3]. In addition, much development on the island has taken the form of scattered, rural construction. Since this ‘rural residential development’ (RRD) can affect wildlife habitat, biotic interactions, and ecological processes [
4], it is important to establish methodologies for mapping and monitoring RRD in Hawai’i and elsewhere. Moreover, many of the ~70,000 households on the island have on-site wastewater disposal systems (OSDS; cesspools or septic tanks) that pose a threat to groundwater and the marine environment [
5,
6]. Maps of houses and, by extension, their OSDS are needed to enable, for example, spatially explicit, hydrogeological modeling of wastewater transport to nearshore waters. Here, we focus on mapping residential buildings in three large regions of Hawai’i Island that are a particular focus of efforts to develop data-driven tools to support ridge-to-reef stewardship for the island.
The literature on remote sensing-based building detection and urban land cover classification contains much methodology that may be relevant to mapping Hawai’i Island’s buildings. That body of work can be categorized in terms of several characteristics: input data, setting (e.g., urban, rural), spatial scale, final product (pixel-wise classification vs. database of discrete objects), and analysis approach (traditional/feature engineering vs. deep learning). In feature engineering, a human carries out the process of selecting, manipulating and transforming raw data into features that can be used for machine learning. Random forests, support vector machines (SVMs), and gradient boosting with decision trees are common feature engineering applications. Deep learning, a subset of machine learning, omits the feature engineering step and instead uses nonlinear processing to extract features from data and transform the data into different levels of abstraction. Convolutional neural networks (CNNs) are an example of a deep learning method.
Regarding input data, high-resolution (<1 m) remotely sensed RGB images are widely available, and various kinds of RGB image have been used extensively in the development of deep learning models for computer vision tasks. High-resolution imaging and deep neural networks have thus been used to produce the largest-scale databases of building footprints, which are now available for the African continent [
1], the United States [
7,
8], and indeed over much of the world [
9]. The dataset produced by [
8] includes footprints for 65,224 buildings on Hawai’i Island. However, that database is based on satellite imagery of unspecified vintage (mean year = 2012), and omits numerous buildings constructed since its release.
To produce updated maps for Hawai’i Island, we opted to use high-resolution (1–2 m) airborne LiDAR and imaging spectroscopy data collected over a large fraction of the island since 2016. In general, combining multiple types of data allows for the incorporation of different kinds of information. Here, LiDAR reveals the 3D structure of objects in the landscape, while imaging spectroscopy gives information about their 2D shape and material composition [
10]. Rather than attempting to maximize detection rates and minimize contamination using either data type alone, it should be possible to use each one to compensate for any weaknesses of the other.
However, three key knowledge gaps needed to be addressed in order to use these data modalities for detecting buildings in the context of this study. First, the 3200 km
2 area of interest covers a wide variety of environments. These environments are highly heterogeneous, differing in terms of building density, land cover (from dense vegetation to bare rock), and other characteristics. In contrast, LiDAR and imaging spectroscopy datasets have mainly been used to detect objects or produce pixel-based land cover maps for relatively small, urban areas (<few km
2). Second, deep learning-based methods for image segmentation and object detection that have proven effective in other contexts have only been applied to LiDAR and imaging spectroscopy data, separately, within the last decade [
11,
12]. Third, analyzing data from a combination of remote sensing modalities using deep learning techniques is now an active area of research [
2]. We now briefly review some of the literature that is relevant to analyzing LiDAR and imaging spectroscopy data, and multi-modal data using deep learning approaches. Then, we devise a method that is effective over large, heterogeneous areas.
Zhou and Gong [
12] claimed to be the first to have combined LiDAR with deep learning for automated building detection. The paper addressed the identification of buildings before and after disasters. The authors ran digital surface models (DSMs) through a CNN trained using 10,000 manually labeled samples from NOAA’s Digital Coast dataset. They found that their method performed well compared to standard LiDAR building detection tools, especially for the post-hurricane data. Maltezos et al. [
13] found that performance improved when they added “additional information coming from physics” to DSMs, such as “height variation” and “distribution of normal vectors”. Gamal et al. [
14] directly analyzed the 3D LiDAR point cloud to avoid the loss of information involved in converting to a DSM.
Yuan et al. [
15] reviewed the literature on segmenting remote sensing imagery using deep learning methods, including applications to “non-conventional” data such as hyperspectral imaging. They pointed out that, compared to other computer vision applications, semantic segmentation of remote sensing data is distinguished by a need for pixel-level classification accuracy (in particular, accurate pixel classes around object boundaries) and a lack of labeled training data. Recent advances in analyzing hyperspectral imaging were discussed. These included using a 1D CNN to extract spectral features and a 2D CNN to extract spatial features then using the combined feature set for classification, and analyzing a 3D data cube with a CNN that performs 3D convolutions.
Different remote sensing modalities can be combined and analyzed in a number of ways, tailored to the available data and their characteristics. Recent reviews have highlighted three approaches: fusion of the data into a single data cube, separate extraction of features from each dataset followed by fusion, or combining decisions obtained from each dataset alone [
16]. As data types such as LiDAR and imaging spectroscopy possess distinct characteristics, much work has focused on feature extraction and fusion across different data types [
2,
16] (although see [
17] for an example of data-level fusion). Early work applied established algorithms to identify and fuse features, followed by classification using a CNN [
18]. More recent studies have identified neural network architectures that can improve feature extraction, selection, fusion, and classification [
19,
20,
21].
In addition to these ‘parallel’ methods, sequential approaches can be employed to integrate the complementary information present in different types of remote sensing data. Sequential approaches have been applied to single remote sensing data types, such as passing features identified by a CNN to an SVM for classification [
22]). They have also been used in conjunction with multimodal datasets, outside the context of deep learning [
23]. However, to the best of our knowledge, deep learning-based, sequential approaches to integrating LiDAR and imaging spectroscopy data have not yet been explored.
In this paper we investigate such an approach. First, we applied a U-NET-based CNN to LiDAR data to perform a preliminary segmentation. We then improved the initial pixel classifications using a gradient boosting model whose predictor variables included both the initial CNN-based map and the imaging spectroscopy data. Finally, we applied a set of vector operations to further refine the final maps. The method is described in detail in
Section 2. In
Section 3 we illustrate the rationale for this choice of sequence, and we show how and why the mapping evolves at each step. We also discuss the quality of the final maps and how they relate to comparable products that have been published. We close by discussing the broader applicability of this method and the maps it has produced.
This is one of just a few publications to date that explores how deep-learning-based techniques can be applied to LiDAR and spectroscopic data for the purpose of detecting buildings over large, diverse regions. The paper also shows that gradient boosting with decision trees can be useful even in situations involving great spectral heterogeneity. Furthermore, it determines the ways in which different spectral regions help to refine the initial CNN-based classification. The method described here has been implemented using freely-available software. Given the large amount of high-quality data becoming available, and its many potential applications, we hope this paper adds a useful and accessible option to the remote sensing toolbox.
2. Materials and Methods
This study used LiDAR and imaging spectroscopy data from the Global Airborne Observatory (GAO [
24]), obtained between 2016 and 2020. The GAO captured the LiDAR and spectroscopy data simultaneously, allowing tight alignment between the two instruments [
24]. The imaging spectrometer aboard the GAO measures reflected solar radiance in 428 bands between 380 nm and 2510 nm with 5 nm spectral sampling. At the 2000 m nominal flight altitude of the Hawai’i campaign, the imaging spectroscopy pixel size is 2 m.
The LiDAR point clouds were processed into a raster DSM by interpolating the regional maximum elevation of all returns from all pulses using the “translate” filter and “gdal” writer contained in the Point Data Abstraction Library software package version 2.0.1 [
25]. Window size was set to 1.0, with radius 0.71 and the “max” interpolation algorithm was used. This resulted in DSMs with 1 m resolution depicting the elevation of vegetation and building upper surfaces. Hillshade and canopy height images at 1 m resolution were derived using standard procedures. Eigenvector images were derived from the DSMs by fitting a plane through the surface data within a 9 m × 9 m window around each pixel. The x, y, and z components of the normal vector to this plane, as well as the surface variation around this plane, were stored in a new four-band map.
The radiance data were transformed by first band-averaging into 214 bands of 10 nm spacing to reduce the noise within each spectrum. These maps were then processed with atmospheric correction software (ACORN v6; AIG, Boulder, CO, USA) to retrieve reflectance spectra. Reflectance maps were orthorectified using a calibrated camera model and a ray-tracing technique with the LiDAR-derived surface elevation maps [
24]. A brightness-normalized version of the reflectance data cubes was made by dividing the spectrum at each pixel by the total reflectance in the spectrum (i.e., dividing by its vector norm), and both the original and brightness-normalized data cubes were incorporated into further analyses.
The three areas mapped for this work (
Figure 1) were selected as part of a larger effort to provide data-driven decision support on Hawai’i Island. They are highly heterogeneous, covering a wide range of characteristics. In North Hilo—Hāmākua, high annual rainfall supports small-scale agriculture, timber plantations, and native and non-native forests. This area hosts a number of small villages as well as low-density rural development. In North Kona—South Kohala, the island’s main resort areas and some coastal development sit against a backdrop of dry, fire-prone, non-native grasslands and shrublands. Nearshore ecosystems in this area have suffered from high sediment and nutrient loads from coastal erosion, OSDS and other sources [
6,
26,
27]. The South Kona district is host to rural residential and agricultural development in a diversity of environments (such as bare lava flows, forest, orchards, and pastureland), as well as scattered coastal developments and relatively undisturbed coral reefs. With the exception of the Waikoloa Village area in North Kona—South Kohala, and small sections of South Kona and North Hilo—Hāmākua, the parts of the study geographies that lack GAO data coverage are essentially uninhabited.
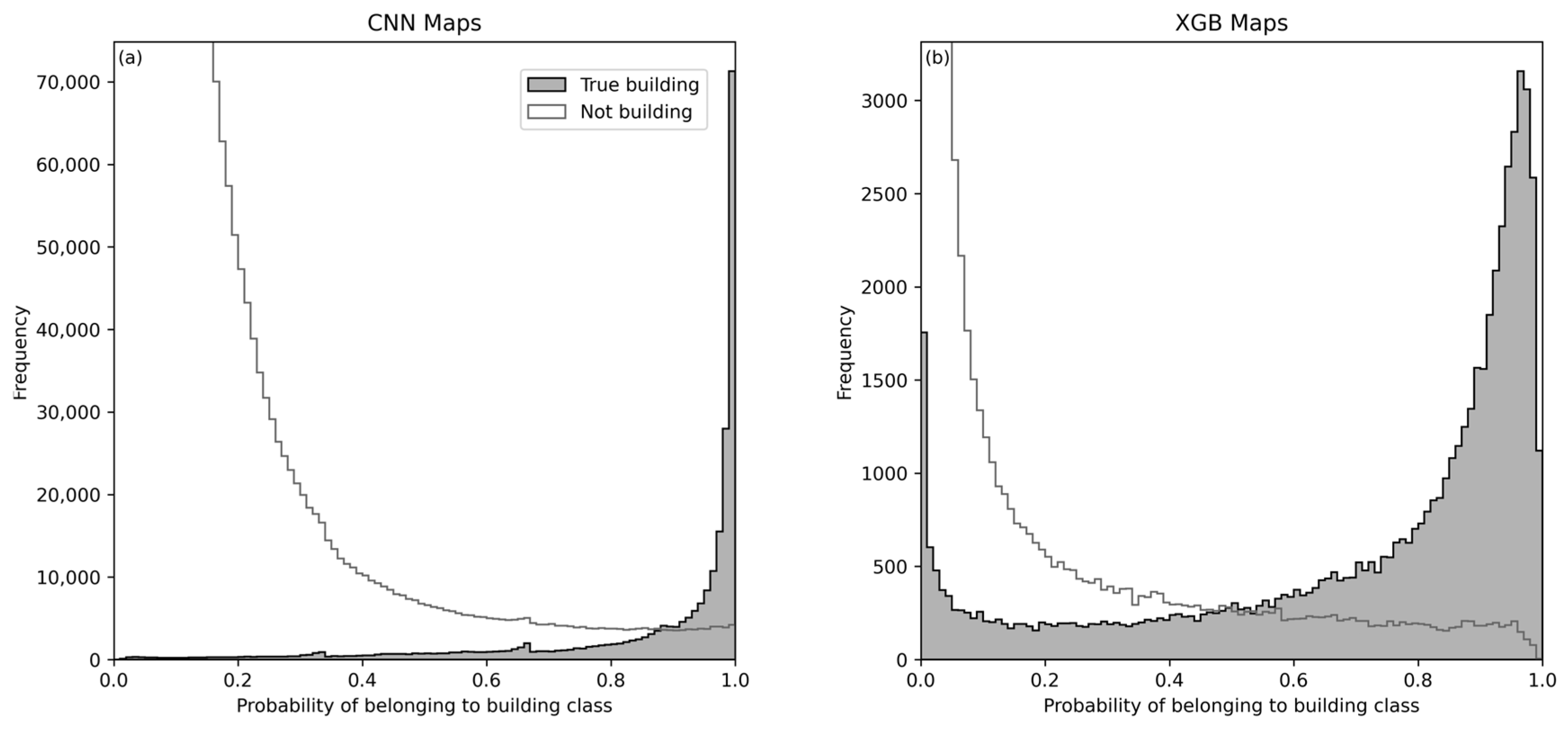
To generate infrastructural maps of the three study areas, we first employed a CNN to assign probabilities that pixels in LiDAR-derived data belonged to ‘building’ or ‘not-building’ classes (
Figure 2). Briefly, a CNN consists of layers of nodes that receive input from the previous layer, convolve the input with a filter (kernel), and pass the result to nodes in the subsequent layer that perform similar operations. The convolutions initially detect simple shapes (e.g., edges) in the input image, then the passage through subsequent layers gradually builds up more and more complex features. The connections between layers are assigned weights that are adjusted during an optimization process, giving higher weights to more informative features and converging on the set of features that leads to the most accurate classification of a labeled training data set.
Labeled training/validation and test data for the CNN were generated by manually outlining rooftops in the DSMs. All visually identifiable buildings were labeled, regardless of perceived function, then those with area <50 m2 were excluded. Locations for gathering training/validation data were initially chosen based on (1) the presence of buildings for the model to learn from, (2) the presence of fairly closely-spaced buildings, so the training set would not be dominated by non-building pixels, and (3) landscape characteristics across the range spanned by the three geographies of interest.
Preliminary experiments were carried out on training data from three locations and adjacent test regions. Based on the results obtained, data were gathered from an additional six training and five test locations. The full training dataset contains 2083 building outlines and covers 34 km2. The full test dataset contains 1124 building outlines and covers 16 km2. This conservative ~65:35 train:test split was chosen in order to give confidence that the model was performing adequately over a wide range of landscape types, in visual as well as statistical checks. The test regions were only used for the purpose of evaluating model quality at each step, after training had been completed.
The freely-available Big Friendly Geospatial Networks (BFGN) package [
28] was used to process model training data, train a CNN to assign “building” and “not-building” probabilities to LiDAR pixels, and apply the trained model to the test datasets. BFGN implements a version of the U-NET CNN architecture [
29], adapted to handle different input sizes [
30], to perform semantic segmentation of remote sensing images. The package is designed for transparent handling of geospatial data and has previously been used to map termite mounds in LiDAR data [
30].
In the default configuration used for this project, the CNN consists of 32 layers and 7994 trainable parameters. Of the 32 layers, 24 are convolutional layers, and the remainder perform batch normalization, max pooling, up-sampling, and concatenation. Batch size = 32 was used together with batch normalization, and the “building” class was given higher weight during model training, due to its small size relative to the “not-building” class. The files recording the package/model configuration can be found as described in the Data Availability Statement. The training and application of all models discussed in this paper were carried out on a GTX1080 GPU and took a few minutes to a few hours, largely depending on the spatial coverage and number of bands of the data.
The model was trained on the combined data for all training regions. During pre-processing with BFGN the training data are split into small, square ‘windows’, and three different window sizes were tested (see the supplementary material for [
31] for further explanation). Training was also performed separately on the DSM, hillshade, and eigenvector data, resulting in a total of nine trained models. The models were applied to the training and held-out test regions, producing nine per-pixel building probability maps per region (
Figure 2). Ensemble maps were created by averaging the nine maps for each region. This had the effect of reducing the number of false positives, which were only weakly correlated between different combinations of input data type and window size, while preserving true positives. The ensemble maps were then interpolated to the same 2 m pixel size as the imaging spectroscopy.
The ensemble CNN-based maps, imaging spectroscopy data cubes, and canopy height images for the training regions were used as input to the XGBoost model v 1.6.2 [
32] to reclassify the pixels (
Figure 2). XGBoost is an implementation of gradient boosting with decision trees, in which successive trees are trained iteratively with each new tree trying to correct the errors of the previous one. This results in a final model that can accurately predict the target variable even when the relationships between variables are complex. Among gradient boosting implementations, XGBoost is known for its efficiency, flexibility, and ability to handle missing data, as well as a large and active user community [
33].
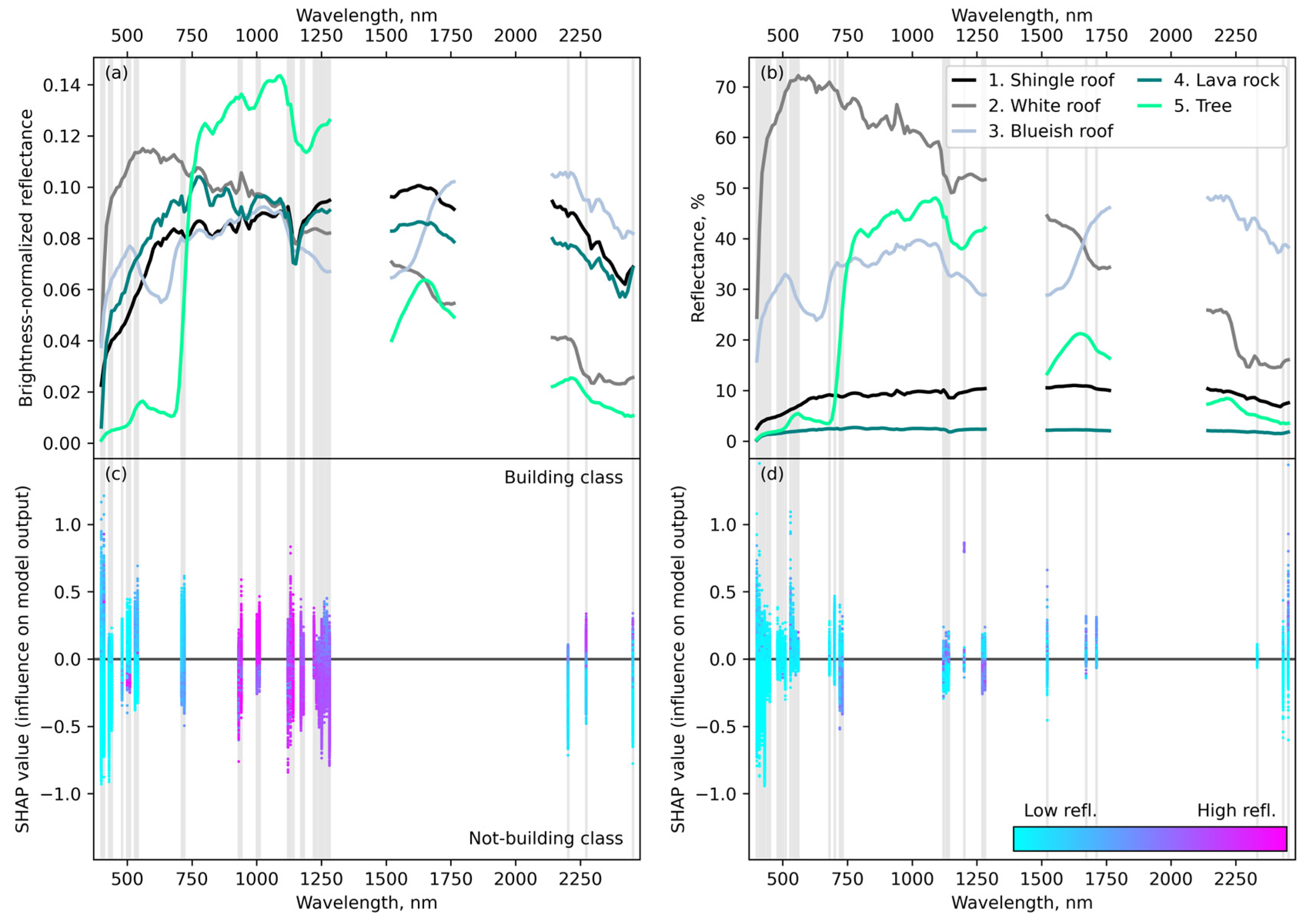
Gradient boosting trees are capable of handling high-dimensional datasets, and we were also interested in finding out which spectral regions would be particularly informative. Therefore all 147 imaging spectroscopy bands not compromised by strong atmospheric H2O absorption were included in the model training set. As with the CNN, a set of slightly different map versions were created, using slightly different subsets of the training data and spectra that had and had not been brightness-normalized, and averaged into an ensemble map. At this point, pixels with building probability ≥ 0.2 were classified as buildings, and others as not-building.
The maps were converted to vector space, further refined by applying a set of simple vector operations, then converted back to raster format (
Figure 2). The vector operations consisted of (1) applying a −1 m buffer to each polygon, (2) rejecting polygons < 25 m
2, (3) rejecting polygons that coincided with roads and the coastline of the island, (4) closing holes, and (5) representing each polygon by its minimum oriented bounding box. The CNN-based and gradient boosting models derived from the training region data and these final cleaning operations were then applied to the entirety of the three study geographies. Ipython notebooks showing the full process are available as described in the Data Availability Statement.
4. Discussion
We found the combination of a CNN and gradient boosting with decision trees to be an effective means of segmenting LiDAR and imaging spectroscopy data into building and not-building classes in a highly heterogeneous landscape. The CNN was effective at detecting buildings in the higher-resolution LiDAR data, but also misclassified objects such as tree crowns and ground surface features. Including the CNN-derived probability map along with the imaging spectroscopy bands as features in a gradient boosting model reduced the number of false positive detections. This was in spite of high intra-class variation in spectral properties that results from the wide variety of roofing materials and coatings in the study areas, and spectral similarity between some roofing materials (e.g., asphalt shingle) and landscape features (e.g., rocks). A subsequent set of simple vector operations further refined the final maps.
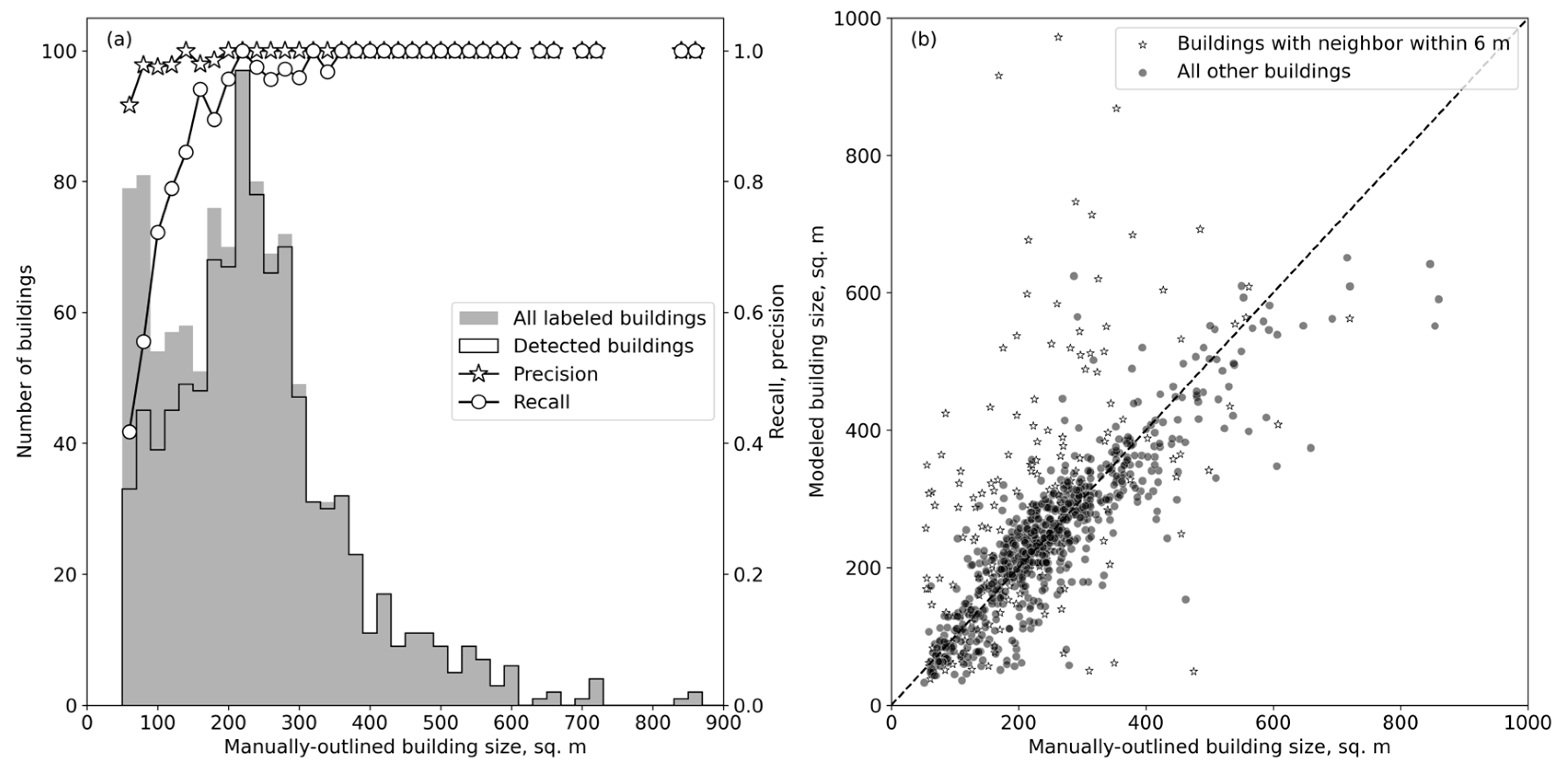
At the median building size in the test dataset, building detection rates approached 100%. Detection rates were lower for small buildings, which may be for several reasons. First, smaller structures were difficult for the CNN to detect against the background in the 1 m LiDAR pixels, meaning that the CNN-derived probability maps frequently assigned low or zero probability to pixels within small buildings. Then, the 2 m spectroscopy pixels may have been significantly ‘contaminated’ by non-building material, which would likely make them more difficult to classify. We also speculate that small buildings are more likely to be agricultural structures (e.g., polytunnels) and informal buildings (sheds, canopies), and this category may therefore include spectra that are both more diverse and less well-represented in the training dataset.
Other LiDAR- and imaging spectroscopy-based building detection methods tend to cover landscapes that are much smaller and/or more homogeneous than the three Hawai’i Island geographies mapped in this study. The most relevant comparison is the USBFD [
8], which is based on satellite imagery and contains footprints for 11,283 buildings in these three areas. Visually, the maps that we present appear similar in quality to the USBFD (
Figure 3, column e), with three main differences. First, the USBFD polygonization algorithm more closely approximates building outlines than we attempted to, meaning that non-rectangular structures are more accurately delineated in the USBFD. Second, in many locations there are offsets between buildings in the USBFD and both our LiDAR and spectroscopy data and Google satellite images. This is presumably related to the registration of the satellite images in which the USBFD footprints were detected. Third, numerous buildings appear on our maps but not in the USBFD. This is likely mainly because many buildings have been constructed since the acquisition of the data used for the USBFD for Hawai’i. However, there are also locations (such as the village of Papa’aloa in the Hāmākua district) where the USBFD contains only a small fraction of buildings present, despite all houses dating from the 20th century.
The USBFD reports pixel-based precision = 0.94 and recall = 0.96 for their test datasets. This is much higher than the values that we obtain (precision = 0.78 and recall = 0.71, over all building sizes;
Section 3.3). However, ref. [
39] show that actual recall values in the USBFD are a strong function of building size. Although recall ranges from 0.93–0.99 in buildings > 200 m
2, ref. [
39] find that it falls to 0.37–0.73 when calculated over all building sizes in their test datasets. This relationship between recall and building area is consistent with our findings in
Figure 6a and highlights the difficulty in making straightforward comparisons between published results.
Convolutional neural networks (CNNs) and other machine learning algorithms are rapidly gaining popularity for remote sensing-based computer vision tasks in fields such as ecology, conservation, and planning [
31,
40]. The development of accessible tools, including the BFGN package utilized in this study [
28], is making these advanced techniques more widely available to non-specialists. The combination of CNNs with other machine learning algorithms, as demonstrated in this paper, expands the range of techniques available for using complementary information in multi-modal data, and allows the user to be flexible and adapt to a variety of different data types.
Gradient boosting algorithms have received much attention in recent years, but few applications to spectroscopic data have been described in the literature so far. In a recent study, ref. [
41] used XGBoost to classify spectra of dwarf and giant stars. They concluded that, while the algorithm identified spectral features traditionally used by astronomers for stellar classification, it also identified new diagnostic regions that significantly contribute to the differentiation between classes. This conclusion was based on the number of times each wavelength band was used in the decision trees. Here, we show that gradient boosting trees are also useful in situations involving much greater spectral diversity. Extending beyond feature use counts, we used SHAP values to identify influential spectral regions. We found that although few wavelength bands disproportionately influenced the classification, short wavelengths (<500 nm) tended to be among the most important. Absorption features associated with chlorophyll, H
2O, and hydrocarbons were also influential.
The methodology presented in this study has potential for mapping other landscape components with well-defined spatial structure, such as orchard crops and roads, in rural and peri-urban areas. Furthermore, it can be customized to use other data sources that contain information about the structure and composition of landscape features, as well as to accommodate the specific conditions of different landscapes. For instance, in a more uniform landscape than the one examined in this research, multi-band or RGB imaging could serve as a satisfactory substitute for imaging spectroscopy. Similarly, if the goal is to detect small structures, it may be feasible to achieve this by carefully selecting representative training spectra based on knowledge of materials used locally. These possibilities highlight the versatility of multi-sensor data, and their potential for broadening the scope of remote sensing applications.
One issue faced during this work was the manual and time-consuming process of labelling the training data. Determining what constituted a building was not always straightforward; the difference between small houses, non-residential buildings, and structures such as temporary canopies, water tanks, piles of abandoned vehicles, etc. was not always clear. This complicated the assessment of model performance at the small end of the building size distribution. In addition, buildings separated by <3 imaging spectroscopy buildings tended to be incorrectly identified as single, larger structures. This mainly occurs in built-up areas that are connected to municipal sewer lines, rather than the rural residential development that is the focus of this work, so improving building separation was not considered a high priority. However, it may be possible to achieve better separation using traditional techniques such as watershed analysis, or by applying a CNN to the final maps.
The building maps produced using this methodology will be used within a decision support tool framework to assist hydrogeological modeling of residential wastewater transport. They will also be useful for many other purposes. For example, they may help to clarify OSDS numbers and locations on Hawai’i Island, which are currently uncertain [
42]. Measures of building density may help local advocacy groups assess the viability of community-level micro-treatment plants, potentially a preferred alternative to OSDS [
43]. The spectroscopic data available for the rooftops in this dataset could be used to assess indoor temperatures as the climate warms [
44] or to help evaluate the potential environmental impact of contaminants in roofing runoff [
45,
46]. To allow for a broad range of uses, the maps are freely available as described in the Data Availability Statement.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}