


Single Object Tracking in Satellite Videos Based on Feature Enhancement and Multi-Level Matching Strategy



Abstract
:1. Introduction
- (1)
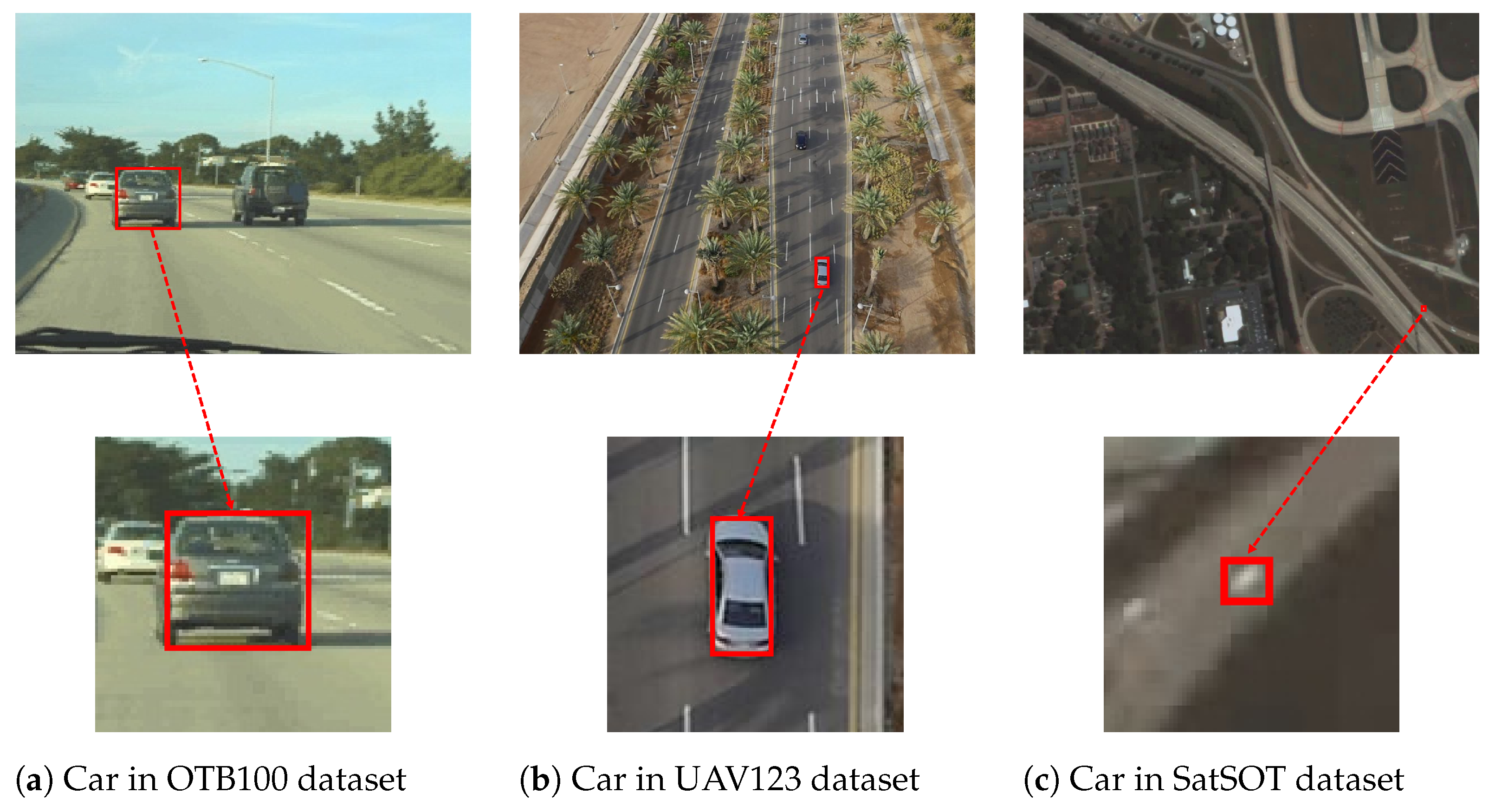
- Weak target feature: Due to the altitude of the satellite and the spatial resolution of satellite videos, the target in the satellite video usually occupies only a tiny percentage of the entire image [34]. Compared to generic optical targets, targets to be tracked in satellite video are generally too small in size, resulting in insufficient feature information for trackers to exploit [35].
- (2)
- Inappropriate matching strategy: The common Depth-wise Cross Correlation finds the best match within the search map based on the target appearance and texture information provided by the template map. However, due to the tiny size of objects in satellite videos, which usually exist in clusters or lines in images and lack noticeable contour features, the Depth-wise Cross Correlation matching strategy is not fully applicable to RSOT.
- Firstly, we propose a novel target information enhancement module that can capture the direction and position-aware information from both the horizontal and vertical dimensions, as well as inherent channel information from a global perspective of the image. The target information enhancement module embeds position information into channel attention to enhance the feature expression of our proposed SiamTM algorithm for small targets in satellite videos.
- Secondly, we have designed a multi-level matching module that is better suited for satellite video targets’ characteristics. It combines coarse-grained semantic abstraction information with fine-grained location detail information, effectively utilizing template information to accurately locate the target in the search area, thereby improving the network’s continuous tracking performance of the target in various complex scenarios.
- Finally, extensive experiments have been conducted on two large-scale satellite video single-object tracking datasets, SatSOT and SV248S. The experimental results show that the proposed SiamTM algorithm achieved state-of-the-art performance in both success and precision metrics, while having a tracking speed of 89.76 FPS, exceeding the standard of real-time tracking.
2. Related Work
2.1. Feature Enhancement Methods in Single Object Tracking
2.2. Matching Methods between Template Region and Search Region
3. Proposed Approach
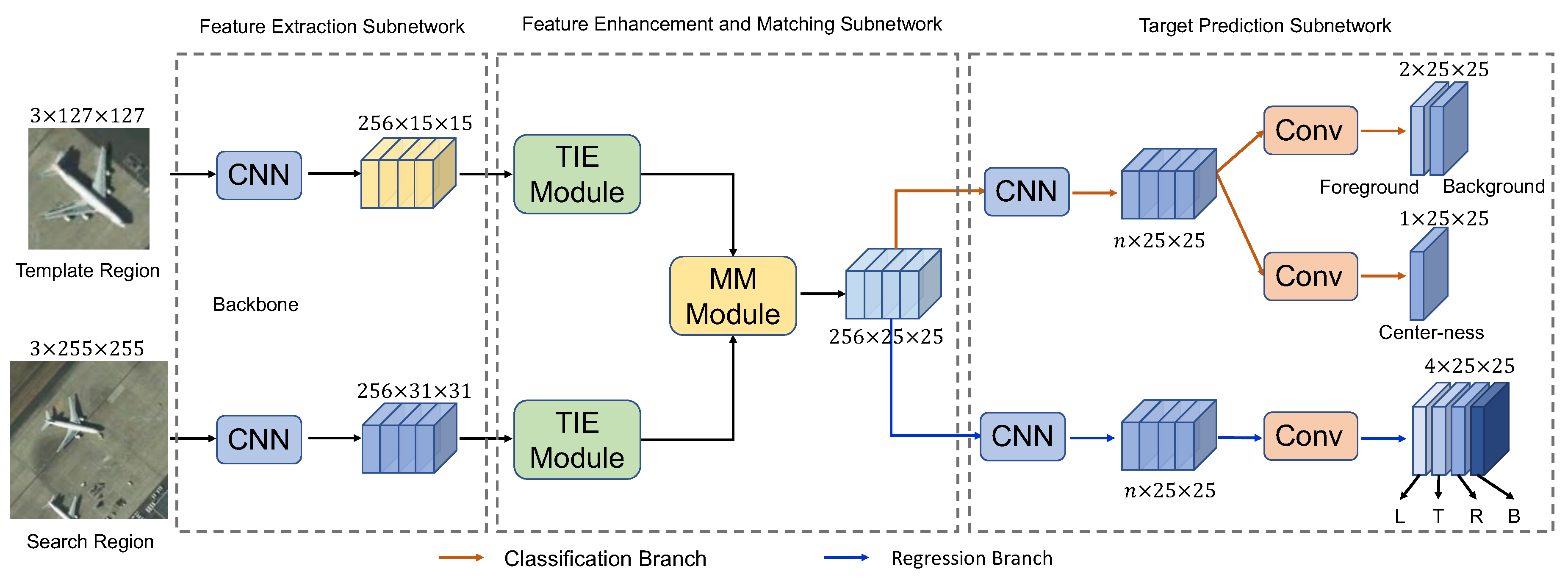
3.1. Overall Architecture
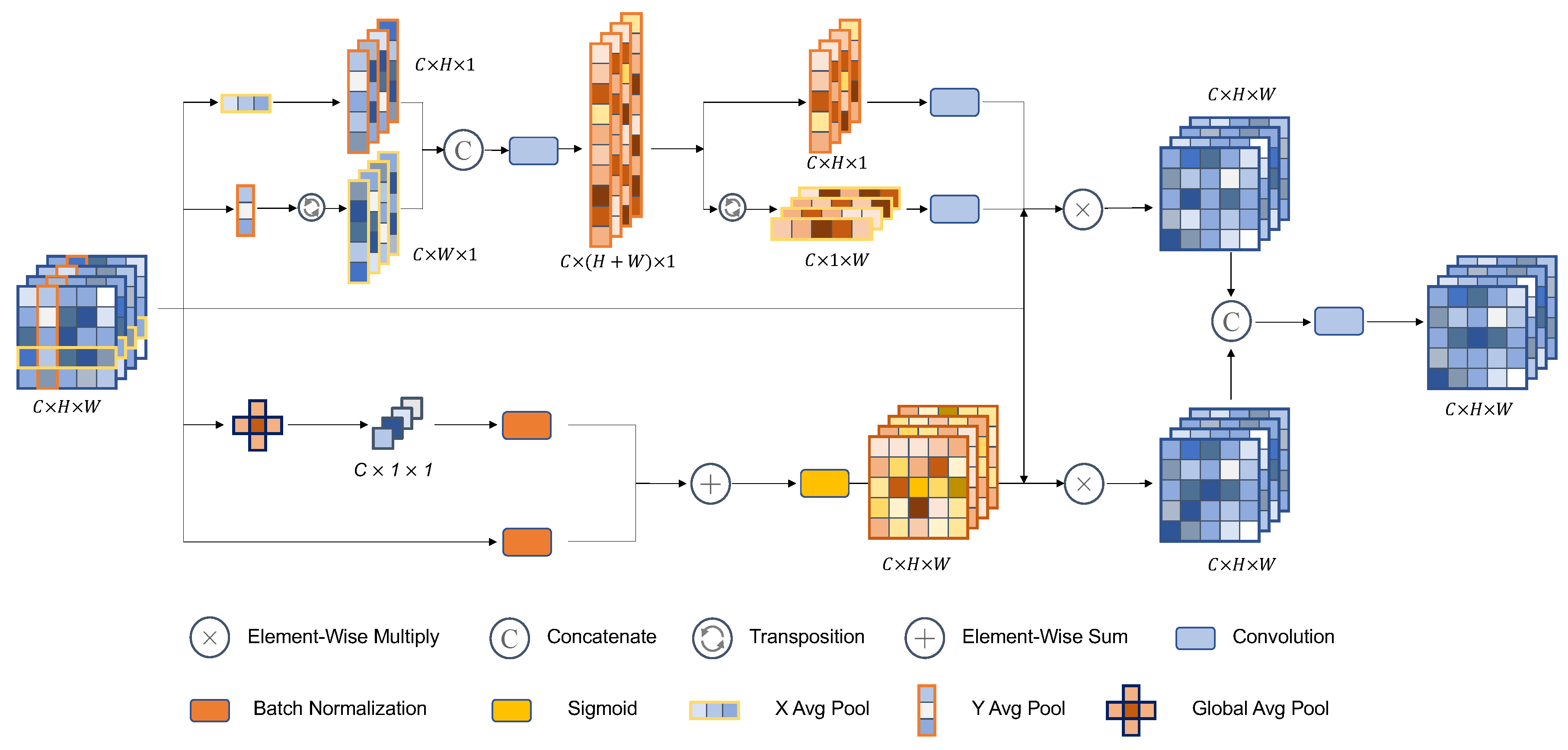
3.2. Target Information Enhancement Module
3.3. Multi-Level Matching Module
4. Evaluation
4.1. Experimental Setup
4.1.1. Introduction to Experimental Datasets
4.1.2. Evaluation Criteria
4.1.3. Implementation Details
4.2. Ablation Study
4.2.1. Target Information Enhancement Module
4.2.2. Multi-Level Matching Module
4.3. Comparison with State-of-the-Art
4.3.1. Evaluated Trackers
4.3.2. Overall Performance on SatSOT and SV248S
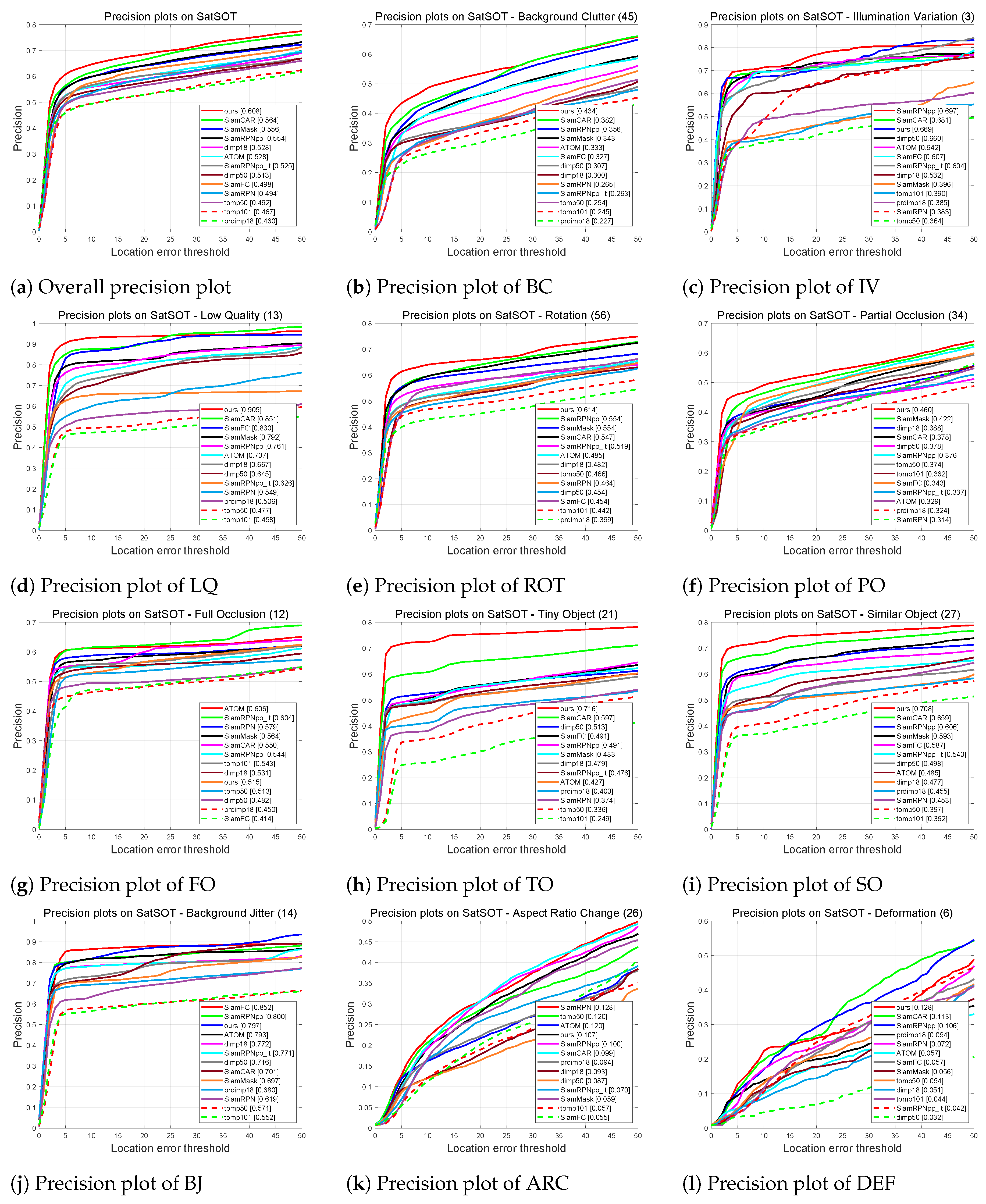
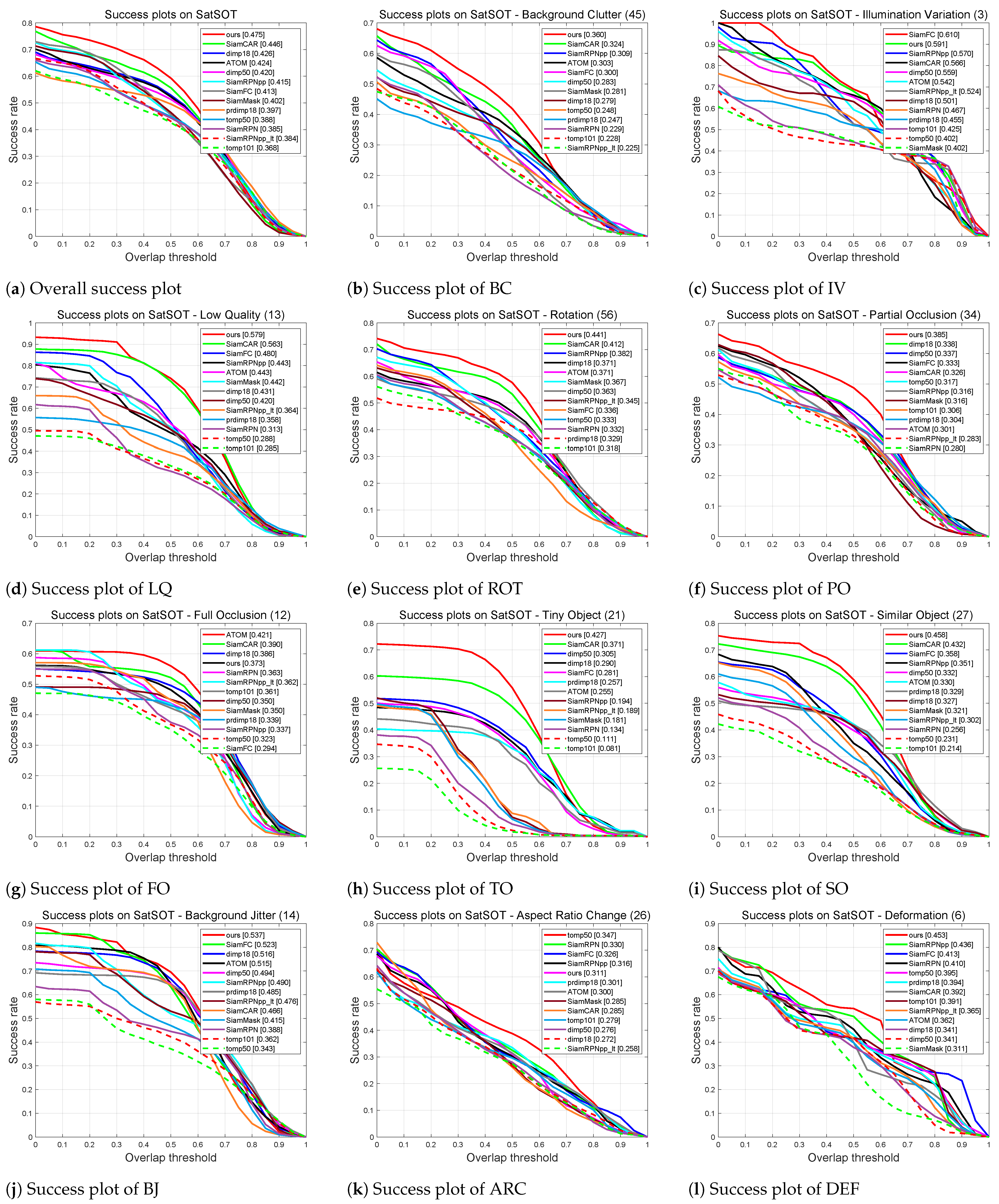
4.3.3. Attribute-Based Evaluation
4.3.4. Visual Analysis
4.3.5. Failure Case Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chan, S.; Tao, J.; Zhou, X.; Bai, C.; Zhang, X. Siamese implicit region proposal network with compound attention for visual tracking. IEEE Trans. Image Process. 2022, 31, 1882–1894. [Google Scholar] [CrossRef] [PubMed]
- Shao, J.; Du, B.; Wu, C.; Zhang, L. Tracking objects from satellite videos: A velocity feature based correlation filter. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7860–7871. [Google Scholar] [CrossRef]
- Lee, K.H.; Hwang, J.N. On-road pedestrian tracking across multiple driving recorders. IEEE Trans. Multimed. 2015, 17, 1429–1438. [Google Scholar] [CrossRef]
- Dong, X.; Shen, J.; Wu, D.; Guo, K.; Jin, X.; Porikli, F. Quadruplet network with one-shot learning for fast visual object tracking. IEEE Trans. Image Process. 2019, 28, 3516–3527. [Google Scholar] [CrossRef] [PubMed]
- Tao, R.; Gavves, E.; Smeulders, A.W. Siamese instance search for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1420–1429. [Google Scholar] [CrossRef]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar] [CrossRef]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4282–4291. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines. In Proceedings of the AAAI Conference On Artificial Intelligence, Online, 7–12 February 2020; Volume 34, pp. 12549–12556. [Google Scholar] [CrossRef]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6269–6277. [Google Scholar] [CrossRef]
- Guo, D.; Shao, Y.; Cui, Y.; Wang, Z.; Zhang, L.; Shen, C. Graph attention tracking. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9543–9552. [Google Scholar] [CrossRef]
- Yang, J.; Pan, Z.; Wang, Z.; Lei, B.; Hu, Y. SiamMDM: An Adaptive Fusion Network with Dynamic Template for Real-time Satellite Video Single Object Tracking. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–19. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar] [CrossRef]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning spatio-temporal transformer for visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 19–25 June 2021; pp. 10448–10457. [Google Scholar] [CrossRef]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8126–8135. [Google Scholar] [CrossRef]
- Fu, Z.; Fu, Z.; Liu, Q.; Cai, W.; Wang, Y. SparseTT: Visual Tracking with Sparse Transformers. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence—IJCAI-22, Vienna, Austria, 23–29 July 2022; pp. 905–912. [Google Scholar] [CrossRef]
- Mayer, C.; Danelljan, M.; Bhat, G.; Paul, M.; Paudel, D.P.; Yu, F.; Van Gool, L. Transforming model prediction for tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8731–8740. [Google Scholar] [CrossRef]
- Cui, Y.; Jiang, C.; Wang, L.; Wu, G. Mixformer: End-to-end tracking with iterative mixed attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13608–13618. [Google Scholar] [CrossRef]
- Ye, B.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Joint feature learning and relation modeling for tracking: A one-stream framework. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 341–357. [Google Scholar] [CrossRef]
- Gao, S.; Zhou, C.; Ma, C.; Wang, X.; Yuan, J. Aiatrack: Attention in attention for transformer visual tracking. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 146–164. [Google Scholar] [CrossRef]
- Lin, L.; Fan, H.; Zhang, Z.; Xu, Y.; Ling, H. Swintrack: A simple and strong baseline for transformer tracking. Adv. Neural Inf. Process. Syst. 2022, 35, 16743–16754. [Google Scholar] [CrossRef]
- Wang, J.; Shao, Z.; Huang, X.; Lu, T.; Zhang, R.; Li, Y. From artifact removal to super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Wang, J.; Shao, Z.; Huang, X.; Lu, T.; Zhang, R.; Cheng, G. Pan-sharpening via deep locally linear embedding residual network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Wang, J.; Shao, Z.; Huang, X.; Lu, T.; Zhang, R. A Dual-Path Fusion Network for Pan-Sharpening. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Shao, J.; Du, B.; Wu, C.; Zhang, L. Can we track targets from space? A hybrid kernel correlation filter tracker for satellite video. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8719–8731. [Google Scholar] [CrossRef]
- Feng, J.; Zeng, D.; Jia, X.; Zhang, X.; Li, J.; Liang, Y.; Jiao, L. Cross-frame keypoint-based and spatial motion information-guided networks for moving vehicle detection and tracking in satellite videos. ISPRS J. Photogramm. Remote Sens. 2021, 177, 116–130. [Google Scholar] [CrossRef]
- Song, W.; Jiao, L.; Liu, F.; Liu, X.; Li, L.; Yang, S.; Hou, B.; Zhang, W. A joint siamese attention-aware network for vehicle object tracking in satellite videos. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Lin, B.; Bai, Y.; Bai, B.; Li, Y. Robust Correlation Tracking for UAV with Feature Integration and Response Map Enhancement. Remote Sens. 2022, 14, 4073. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar] [CrossRef]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 445–461. [Google Scholar] [CrossRef]
- Zhao, M.; Li, S.; Xuan, S.; Kou, L.; Gong, S.; Zhou, Z. SatSOT: A benchmark dataset for satellite video single object tracking. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Wu, D.; Song, H.; Fan, C. Object Tracking in Satellite Videos Based on Improved Kernel Correlation Filter Assisted by Road Information. Remote Sens. 2022, 14, 4215. [Google Scholar] [CrossRef]
- Wu, J.; Pan, Z.; Lei, B.; Hu, Y. FSANet: Feature-and-spatial-aligned network for tiny object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4591–4600. [Google Scholar]
- Javed, S.; Danelljan, M.; Khan, F.S.; Khan, M.H.; Felsberg, M.; Matas, J. Visual object tracking with discriminative filters and siamese networks: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 6552–6574. [Google Scholar] [CrossRef]
- Fan, H.; Ling, H. Siamese cascaded region proposal networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7952–7961. [Google Scholar]
- Yu, Y.; Xiong, Y.; Huang, W.; Scott, M.R. Deformable siamese attention networks for visual object tracking. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6728–6737. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. SiamAPN++: Siamese attentional aggregation network for real-time UAV tracking. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Prague, Czech Republic, 27 October–1 October 2021; pp. 3086–3092. [Google Scholar]
- Xie, F.; Wang, C.; Wang, G.; Cao, Y.; Yang, W.; Zeng, W. Correlation-aware deep tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8751–8760. [Google Scholar]
- Cao, J.; Song, C.; Song, S.; Xiao, F.; Zhang, X.; Liu, Z.; Ang, M.H., Jr. Robust object tracking algorithm for autonomous vehicles in complex scenes. Remote Sens. 2021, 13, 3234. [Google Scholar] [CrossRef]
- Zhang, X.; Zhu, K.; Chen, G.; Liao, P.; Tan, X.; Wang, T.; Li, X. High-resolution satellite video single object tracking based on thicksiam framework. GISci. Remote Sens. 2023, 60, 2163063. [Google Scholar] [CrossRef]
- Nie, Y.; Bian, C.; Li, L. Object tracking in satellite videos based on Siamese network with multidimensional information-aware and temporal motion compensation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Yan, B.; Zhang, X.; Wang, D.; Lu, H.; Yang, X. Alpha-refine: Boosting tracking performance by precise bounding box estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5289–5298. [Google Scholar] [CrossRef]
- Liao, B.; Wang, C.; Wang, Y.; Wang, Y.; Yin, J. Pg-net: Pixel to global matching network for visual tracking. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 429–444. [Google Scholar] [CrossRef]
- Zhou, Z.; Pei, W.; Li, X.; Wang, H.; Zheng, F.; He, Z. Saliency-associated object tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9866–9875. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Y.; Wang, X.; Li, B.; Hu, W. Learn to match: Automatic matching network design for visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13339–13348. [Google Scholar] [CrossRef]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese box adaptive network for visual tracking. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6668–6677. [Google Scholar] [CrossRef]
- Chen, S.; Wang, T.; Wang, H.; Wang, Y.; Hong, J.; Dong, T.; Li, Z. Vehicle tracking on satellite video based on historical model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 7784–7796. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, J.; Pan, Z.; Liu, Y.; Lei, B.; Hu, Y. APAFNet: Single-Frame Infrared Small Target Detection by Asymmetric Patch Attention Fusion. IEEE Geosci. Remote Sens. Lett. 2022, 20, 1–5. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar] [CrossRef]
- Li, Y.; Licheng, J.; Huang, Z.; Zhang, X.; Zhang, R.; Song, X.; Tian, C.; Zhang, Z.; Liu, F.; Shuyuan, Y.; et al. Deep learning-based object tracking in satellite videos: A comprehensive survey with a new dataset. IEEE Geosci. Remote Sens. Mag. 2022. [Google Scholar] [CrossRef]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Yin, Q.; Hu, Q.; Liu, H.; Zhang, F.; Wang, Y.; Lin, Z.; An, W.; Guo, Y. Detecting and tracking small and dense moving objects in satellite videos: A benchmark. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. Atom: Accurate tracking by overlap maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4660–4669. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H. Fast online object tracking and segmentation: A unifying approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1328–1338. [Google Scholar] [CrossRef]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning discriminative model prediction for tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6182–6191. [Google Scholar] [CrossRef]
- Danelljan, M.; Gool, L.V.; Timofte, R. Probabilistic regression for visual tracking. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 7183–7192. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Zhu, P.; Jia, X.; Tang, X.; Jiao, L. Generalized few-shot object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2023, 195, 353–364. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Abbreviation | Definition |
|---|---|---|
| Background Clutter | BC | The background has similar appearance as the target. |
| Illumination Variation | IV | The illumination of the target region changes significantly. |
| Low Quality | LQ | The image is low quality and the target is difficult to be distinguished. |
| Rotation | ROT | The target rotates in the video. |
| Partial Occlusion | POC | The target is partially occluded in the video. |
| Full Occlusion | FOC | The Target is fully occluded in the video. |
| Tiny Object | TO | At least one ground truth bounding box has less than 25 pixels. |
| Similar Object | SOB | There are objects of similar shape or same type around the target. |
| Background Jitter | BJT | Background jitter brings by the shaking of satellite camera. |
| Aspect Ratio Change | ARC | The ratio of the bounding-box aspect ratio of the first and the current frame is outside the range [0.5, 2]. |
| Deformation | DEF | Non-rigid object deformation. |
| Trackers | TIE Module | MM Module | Prec. (%) | Succ. (%) | Speed (FPS) |
|---|---|---|---|---|---|
| Baseline | - | - | 56.4 | 44.6 | 158.41 |
| SiamCAR+T | ✓ | - | 60.2 | 46.6 | 113.65 |
| SiamCAR+M | - | ✓ | 59.5 | 46.7 | 109.17 |
| SiamCAR+T+M | ✓ | ✓ | 60.8 | 47.5 | 89.76 |
| Baseline | 1D | 1D | 2D | Prec. (%) | Succ. (%) | Speed (FPS) |
|---|---|---|---|---|---|---|
| ✓ | - | - | - | 56.4 | 44.6 | 158.41 |
| ✓ | ✓ | - | - | 58.1 | 45.5 | 131.48 |
| ✓ | - | ✓ | - | 57.7 | 45.0 | 142.94 |
| ✓ | - | - | ✓ | 57.4 | 44.4 | 151.93 |
| ✓ | ✓ | - | ✓ | 60.2 | 46.6 | 113.65 |
| Concatenation | Depth-Wise Cross Correlation | Multi-Level Matching Module | Prec. (%) | Succ. (%) | Speed (FPS) |
|---|---|---|---|---|---|
| ✓ | - | - | 57.9 | 42.0 | 111.13 |
| - | ✓ | - | 56.4 | 44.6 | 158.41 |
| - | - | ✓ | 59.5 | 46.7 | 109.17 |
| Trackers | Features | Backbone | Prec. (%) | Succ. (%) | Speed (FPS) |
|---|---|---|---|---|---|
| SiamFC | ConvFeat | AlexNet | 49.8 | 41.3 | 298.3 |
| SiamRPN | ConvFeat | AlexNet | 49.4 | 38.5 | 436.6 |
| ATOM | ConvFeat | ResNet-18 | 52.9 | 42.4 | 249.2 |
| SiamRPN++ | ConvFeat | ResNet-50 | 55.4 | 41.5 | 172.0 |
| SiamRPN++_lt | ConvFeat | ResNet-50 | 52.5 | 38.4 | 148.2 |
| SiamMask | ConvFeat | ResNet-50 | 55.6 | 40.2 | 173.5 |
| DiMP18 | ConvFeat | ResNet-18 | 52.8 | 42.6 | 115.9 |
| DiMP50 | ConvFeat | ResNet-50 | 51.3 | 42.0 | 92.7 |
| SiamCAR | ConvFeat | ResNet-50 | 56.4 | 44.6 | 158.41 |
| PrDiMP18 | ConvFeat | ResNet-18 | 46.0 | 39.7 | 69.5 |
| ToMP50 | CF+TF | ResNet-50 | 49.2 | 38.8 | 58.1 |
| ToMP101 | CF+TF | ResNet-101 | 46.7 | 36.9 | 52.4 |
| SiamTM(Ours) | ConvFeat | ResNet-50 | 60.8 | 47.5 | 89.76 |
| Trackers | Features | Backbone | Prec. (%) | Succ. (%) | Speed (FPS) |
|---|---|---|---|---|---|
| SiamFC | ConvFeat | AlexNet | 63.4 | 39.4 | 402.0 |
| SiamRPN | ConvFeat | AlexNet | 34.4 | 14.7 | 625.6 |
| ATOM | ConvFeat | ResNet-18 | 62.8 | 36.4 | 262.0 |
| SiamRPN++ | ConvFeat | ResNet-50 | 65.6 | 40.5 | 180.7 |
| SiamRPN++_lt | ConvFeat | ResNet-50 | 56.8 | 21.5 | 167.6 |
| SiamMask | ConvFeat | ResNet-50 | 55.9 | 21.9 | 179.6 |
| DiMP18 | ConvFeat | ResNet-18 | 58.3 | 35.3 | 111.5 |
| DiMP50 | ConvFeat | ResNet-50 | 61.4 | 36.7 | 82.6 |
| SiamCAR | ConvFeat | ResNet-50 | 70.1 | 44.8 | 176.16 |
| PrDiMP18 | ConvFeat | ResNet-18 | 57.6 | 36.4 | 68.2 |
| ToMP50 | CF+TF | ResNet-50 | 38.7 | 16.5 | 65.4 |
| ToMP101 | CF+TF | ResNet-101 | 37.1 | 16.0 | 56.0 |
| SiamTM(Ours) | ConvFeat | ResNet-50 | 75.3 | 48.7 | 72.50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Pan, Z.; Liu, Y.; Niu, B.; Lei, B. Single Object Tracking in Satellite Videos Based on Feature Enhancement and Multi-Level Matching Strategy. Remote Sens. 2023, 15, 4351. https://doi.org/10.3390/rs15174351
Yang J, Pan Z, Liu Y, Niu B, Lei B. Single Object Tracking in Satellite Videos Based on Feature Enhancement and Multi-Level Matching Strategy. Remote Sensing. 2023; 15(17):4351. https://doi.org/10.3390/rs15174351
Chicago/Turabian StyleYang, Jianwei, Zongxu Pan, Yuhan Liu, Ben Niu, and Bin Lei. 2023. "Single Object Tracking in Satellite Videos Based on Feature Enhancement and Multi-Level Matching Strategy" Remote Sensing 15, no. 17: 4351. https://doi.org/10.3390/rs15174351
APA StyleYang, J., Pan, Z., Liu, Y., Niu, B., & Lei, B. (2023). Single Object Tracking in Satellite Videos Based on Feature Enhancement and Multi-Level Matching Strategy. Remote Sensing, 15(17), 4351. https://doi.org/10.3390/rs15174351