

Remote Sensing Neural Radiance Fields for Multi-View Satellite Photogrammetry



Abstract
:1. Introduction
2. Related Works
2.1. Stereo Matching
2.2. Novel View Synthesis for Large Scale 3D Reconstruction
2.3. NeRF Variant for Fast Training
2.4. Image Inpainting for Vehicle Removal
3. Methodology
3.1. Preliminaries on NeRFs and S-NeRFs
3.2. High Performance Sampling Based on Grids Density
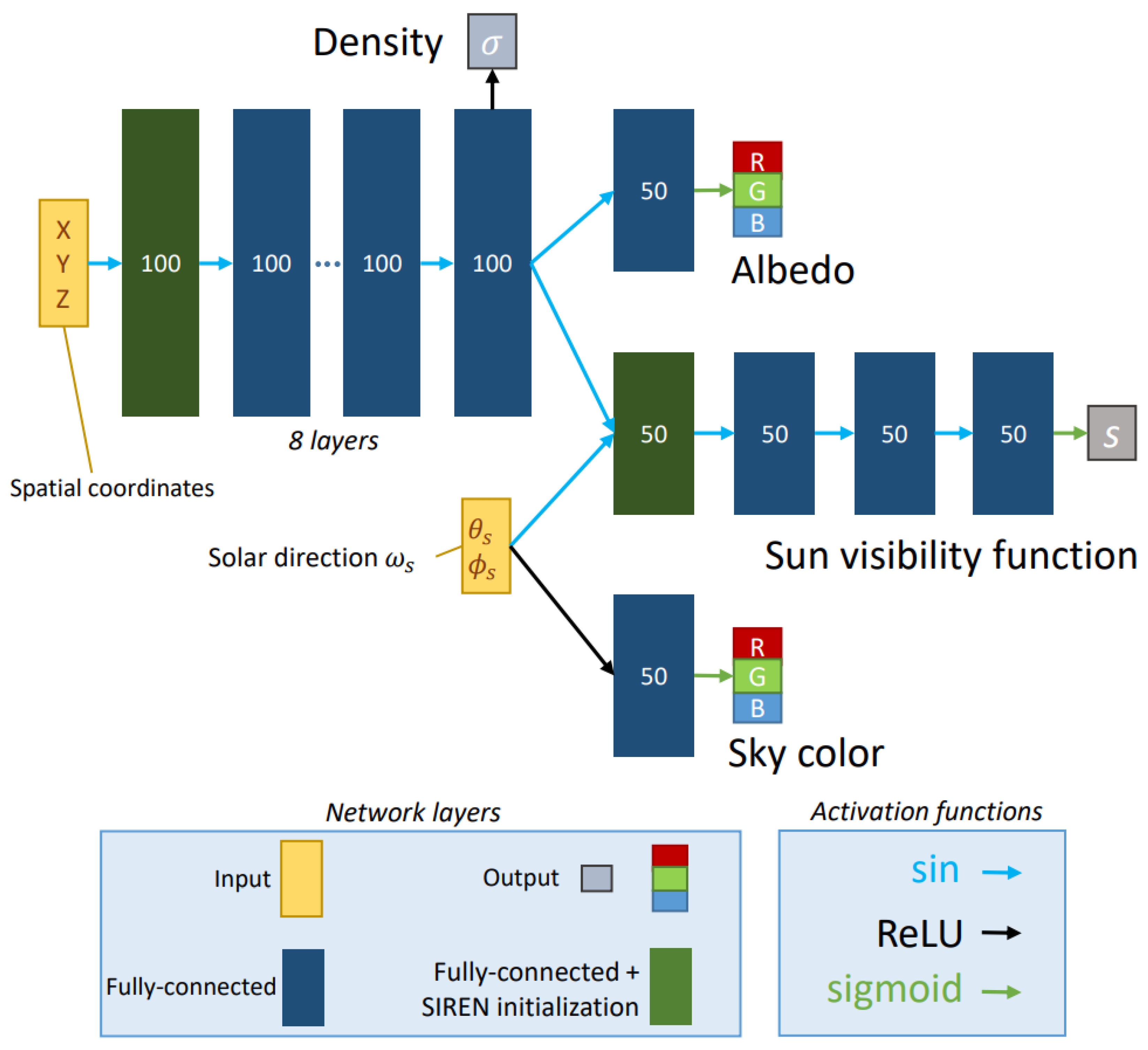
3.3. Network Architecture
3.3.1. HashEncoder
3.3.2. Network Pruning
3.4. Weights Sum Correction
3.5. Vehicle Removal
4. Experiments
4.1. Experimental Details
4.2. Novel View Synthesis




4.3. Vehicle Removal
4.4. Altitude Extraction
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hlatshwayo, S.T.; Mutanga, O.; Lottering, R.T.; Kiala, Z.; Ismail, R. Mapping forest aboveground biomass in the reforested Buffelsdraai landfill site using texture combinations computed from SPOT-6 pan-sharpened imagery. Int. J. Appl. Earth Obs. Geoinf. 2019, 74, 65–77. [Google Scholar] [CrossRef]
- Le Saux, B.; Yokoya, N.; Hänsch, R.; Brown, M. 2019 ieee grss data fusion contest: Large-scale semantic 3d reconstruction. IEEE Geosci. Remote Sens. Mag. (GRSM) 2019, 7, 33–36. [Google Scholar] [CrossRef]
- Gwinner, K.; Jaumann, R.; Hauber, E.; Hoffmann, H.; Heipke, C.; Oberst, J.; Neukum, G.; Ansan, V.; Bostelmann, J.; Dumke, A.; et al. The High Resolution Stereo Camera (HRSC) of Mars Express and its approach to science analysis and mapping for Mars and its satellites. Planet. Space Sci. 2016, 126, 93–138. [Google Scholar] [CrossRef]
- Simard, M.; Zhang, K.; Rivera-Monroy, V.H.; Ross, M.S.; Ruiz, P.L.; Castañeda-Moya, E.; Twilley, R.R.; Rodriguez, E. Mapping height and biomass of mangrove forests in Everglades National Park with SRTM elevation data. Photogramm. Eng. Remote Sens. 2006, 72, 299–311. [Google Scholar] [CrossRef]
- Demarez, V.; Helen, F.; Marais-Sicre, C.; Baup, F. In-season mapping of irrigated crops using Landsat 8 and Sentinel-1 time series. Remote Sens. 2019, 11, 118. [Google Scholar] [CrossRef] [Green Version]
- Qin, R.; Tian, J.; Reinartz, P. 3D change detection–approaches and applications. ISPRS J. Photogramm. Remote Sens. 2016, 122, 41–56. [Google Scholar] [CrossRef] [Green Version]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 328–341. [Google Scholar] [CrossRef]
- d’Angelo, P.; Kuschk, G. Dense multi-view stereo from satellite imagery. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 6944–6947. [Google Scholar]
- De Franchis, C.; Meinhardt-Llopis, E.; Michel, J.; Morel, J.M.; Facciolo, G. An automatic and modular stereo pipeline for pushbroom images. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2014, 2, 49–56. [Google Scholar] [CrossRef] [Green Version]
- Facciolo, G.; De Franchis, C.; Meinhardt-Llopis, E. Automatic 3D reconstruction from multi-date satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–27 July 2017; pp. 57–66. [Google Scholar]
- Gong, K.; Fritsch, D. DSM generation from high resolution multi-view stereo satellite imagery. Photogramm. Eng. Remote Sens. 2019, 85, 379–387. [Google Scholar] [CrossRef]
- Rupnik, E.; Pierrot-Deseilligny, M.; Delorme, A. 3D reconstruction from multi-view VHR-satellite images in MicMac. ISPRS J. Photogramm. Remote Sens. 2018, 139, 201–211. [Google Scholar] [CrossRef]
- Shean, D.E.; Alexandrov, O.; Moratto, Z.M.; Smith, B.E.; Joughin, I.R.; Porter, C.; Morin, P. An automated, open-source pipeline for mass production of digital elevation models (DEMs) from very-high-resolution commercial stereo satellite imagery. ISPRS J. Photogramm. Remote Sens. 2016, 116, 101–117. [Google Scholar] [CrossRef]
- Marí, R.; Facciolo, G.; Ehret, T. Sat-NeRF: Learning Multi-View Satellite Photogrammetry with Transient Objects and Shadow Modeling Using RPC Cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1311–1321. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Barron, J.T.; Mildenhall, B.; Tancik, M.; Hedman, P.; Martin-Brualla, R.; Srinivasan, P.P. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5855–5864. [Google Scholar]
- Martin-Brualla, R.; Radwan, N.; Sajjadi, M.S.; Barron, J.T.; Dosovitskiy, A.; Duckworth, D. Nerf in the wild: Neural radiance fields for unconstrained photo collections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7210–7219. [Google Scholar]
- Park, K.; Sinha, U.; Barron, J.T.; Bouaziz, S.; Goldman, D.B.; Seitz, S.M.; Martin-Brualla, R. Nerfies: Deformable neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5865–5874. [Google Scholar]
- Li, W.; Pan, C.; Zhang, R.; Ren, J.; Ma, Y.; Fang, J.; Yan, F.; Geng, Q.; Huang, X.; Gong, H.; et al. AADS: Augmented autonomous driving simulation using data-driven algorithms. Sci. Robot. 2019, 4, eaaw0863. [Google Scholar] [CrossRef] [PubMed]
- Ost, J.; Mannan, F.; Thuerey, N.; Knodt, J.; Heide, F. Neural scene graphs for dynamic scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2856–2865. [Google Scholar]
- Yang, Z.; Chai, Y.; Anguelov, D.; Zhou, Y.; Sun, P.; Erhan, D.; Rafferty, S.; Kretzschmar, H. Surfelgan: Synthesizing realistic sensor data for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11118–11127. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Liu, A.; Tucker, R.; Jampani, V.; Makadia, A.; Snavely, N.; Kanazawa, A. Infinite nature: Perpetual view generation of natural scenes from a single image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14458–14467. [Google Scholar]
- Deng, K.; Liu, A.; Zhu, J.Y.; Ramanan, D. Depth-supervised nerf: Fewer views and faster training for free. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12882–12891. [Google Scholar]
- Tancik, M.; Casser, V.; Yan, X.; Pradhan, S.; Mildenhall, B.; Srinivasan, P.P.; Barron, J.T.; Kretzschmar, H. Block-nerf: Scalable large scene neural view synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8248–8258. [Google Scholar]
- Rematas, K.; Liu, A.; Srinivasan, P.P.; Barron, J.T.; Tagliasacchi, A.; Funkhouser, T.; Ferrari, V. Urban radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12932–12942. [Google Scholar]
- Derksen, D.; Izzo, D. Shadow neural radiance fields for multi-view satellite photogrammetry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1152–1161. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. arXiv 2022, arXiv:2201.05989. [Google Scholar] [CrossRef]
- Agarwal, S.; Furukawa, Y.; Snavely, N.; Simon, I.; Curless, B.; Seitz, S.M.; Szeliski, R. Building rome in a day. Commun. ACM 2011, 54, 105–112. [Google Scholar] [CrossRef]
- Früh, C.; Zakhor, A. An automated method for large-scale, ground-based city model acquisition. Int. J. Comput. Vis. 2004, 60, 5–24. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Wu, C.; Zach, C.; Lazebnik, S.; Frahm, J.M. Modeling and recognition of landmark image collections using iconic scene graphs. In Proceedings of the Computer Vision–ECCV 2008: 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 427–440. [Google Scholar]
- Pollefeys, M.; Nistér, D.; Frahm, J.M.; Akbarzadeh, A.; Mordohai, P.; Clipp, B.; Engels, C.; Gallup, D.; Kim, S.J.; Merrell, P.; et al. Detailed real-time urban 3d reconstruction from video. Int. J. Comput. Vis. 2008, 78, 143–167. [Google Scholar] [CrossRef] [Green Version]
- Snavely, N.; Seitz, S.M.; Szeliski, R. Photo tourism: Exploring photo collections in 3D. In ACM Siggraph 2006 Papers; Association for Computing Machinery: New York, NY, USA, 2006; pp. 835–846. [Google Scholar]
- Zhu, S.; Zhang, R.; Zhou, L.; Shen, T.; Fang, T.; Tan, P.; Quan, L. Very large-scale global sfm by distributed motion averaging. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4568–4577. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Beyer, R.A.; Alexandrov, O.; McMichael, S. The Ames Stereo Pipeline: NASA’s open source software for deriving and processing terrain data. Earth Space Sci. 2018, 5, 537–548. [Google Scholar] [CrossRef]
- Rupnik, E.; Deseilligny, M.P. More surface detail with One-Two-Pixel Matching. Ph.D. Thesis, Institut Géographique National (IGN), Saint-Mandé, France, 2019. [Google Scholar]
- Liu, L.; Gu, J.; Zaw Lin, K.; Chua, T.S.; Theobalt, C. Neural sparse voxel fields. Adv. Neural Inf. Process. Syst. 2020, 33, 15651–15663. [Google Scholar]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 165–174. [Google Scholar]
- Lombardi, S.; Simon, T.; Saragih, J.; Schwartz, G.; Lehrmann, A.; Sheikh, Y. Neural volumes: Learning dynamic renderable volumes from images. arXiv 2019, arXiv:1906.07751. [Google Scholar] [CrossRef] [Green Version]
- Tewari, A.; Thies, J.; Mildenhall, B.; Srinivasan, P.; Tretschk, E.; Yifan, W.; Lassner, C.; Sitzmann, V.; Martin-Brualla, R.; Lombardi, S.; et al. Advances in neural rendering. In Computer Graphics Forum; Wiley: Hoboken, NJ, USA, 2022; Volume 41, pp. 703–735. [Google Scholar]
- Xiangli, Y.; Xu, L.; Pan, X.; Zhao, N.; Rao, A.; Theobalt, C.; Dai, B.; Lin, D. Bungeenerf: Progressive neural radiance field for extreme multi-scale scene rendering. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 106–122. [Google Scholar]
- Yu, A.; Li, R.; Tancik, M.; Li, H.; Ng, R.; Kanazawa, A. Plenoctrees for real-time rendering of neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5752–5761. [Google Scholar]
- Yang, B.; Zhang, Y.; Xu, Y.; Li, Y.; Zhou, H.; Bao, H.; Zhang, G.; Cui, Z. Learning object-compositional neural radiance field for editable scene rendering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13779–13788. [Google Scholar]
- Zhang, J.; Liu, X.; Ye, X.; Zhao, F.; Zhang, Y.; Wu, M.; Zhang, Y.; Xu, L.; Yu, J. Editable free-viewpoint video using a layered neural representation. ACM Trans. Graph. (TOG) 2021, 40, 1–18. [Google Scholar]
- Zeng, Y.; Lin, Z.; Lu, H.; Patel, V.M. Cr-fill: Generative image inpainting with auxiliary contextual reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14164–14173. [Google Scholar]
- Krauß, T.; d’Angelo, P.; Wendt, L. Cross-track satellite stereo for 3D modelling of urban areas. Eur. J. Remote Sens. 2019, 52, 89–98. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| area index | 004 | 068 | 214 | 260 |
| train/test | 8/2 | 16/2 | 21/2 | 14/2 |
| Alt.bounds(m) | 0/−30 | 30/−30 | 80/−30 | 30/−30 |
| SSIM | (test set) | |||
| NeRF(8hours) | 0.364 | 0.471 | 0.377 | 0.409 |
| S-NeRF no SC(6hours) | 0.352 | 0.322 | 0.360 | 0.401 |
| S-NeRF + SC(8hours) | 0.344 | 0.459 | 0.384 | 0.416 |
| RS-NeRF(6min) | 0.791 | 0.837 | 0.788 | 0.739 |
| RS-NeRF(6min with 2k) | 0.729 | 0.740 | 0.716 | 0.700 |
| Altitude | MAE (m) | |||
| NeRF(8hours) | 5.607 | 7.627 | 8.305 | 11.97 |
| S-NeRF no SC(6hours) | 3.342 | 4.799 | 4.499 | 10.18 |
| S-NeRF + SC(6hours) | 4.418 | 3.644 | 4.829 | 7.173 |
| RS-NeRF no WS(6min) | 3.045 | 2.536 | 10.677 | 5.766 |
| RS-NeRF(6min) | 1.736 | 1.693 | 2.667 | 2.629 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, S.; Zhang, L.; Jeon, G.; Yang, X. Remote Sensing Neural Radiance Fields for Multi-View Satellite Photogrammetry. Remote Sens. 2023, 15, 3808. https://doi.org/10.3390/rs15153808
Xie S, Zhang L, Jeon G, Yang X. Remote Sensing Neural Radiance Fields for Multi-View Satellite Photogrammetry. Remote Sensing. 2023; 15(15):3808. https://doi.org/10.3390/rs15153808
Chicago/Turabian StyleXie, Songlin, Lei Zhang, Gwanggil Jeon, and Xiaomin Yang. 2023. "Remote Sensing Neural Radiance Fields for Multi-View Satellite Photogrammetry" Remote Sensing 15, no. 15: 3808. https://doi.org/10.3390/rs15153808
APA StyleXie, S., Zhang, L., Jeon, G., & Yang, X. (2023). Remote Sensing Neural Radiance Fields for Multi-View Satellite Photogrammetry. Remote Sensing, 15(15), 3808. https://doi.org/10.3390/rs15153808