1. Introduction
With the massive amount of remote sensing data acquired through advanced satellite systems, many image interpretation challenges have arisen in the past few decades [
1]. Among them, efficiently mining the information in high-resolution remote sensing (HRRS) images is a cutting-edge issue, which can increase the value of some applications, such as instance segmentation [
2], image retrieval [
3], target detection [
4], and change detection [
5]. Based on HRRS images, the classification of scenes is a hot topic in the remote sensing community and aims to build a connection between the image and the functional area of the scene [
6].
Traditional scene classification methods can be classified into two categories: low-level and middle-level feature based methods [
7]. However, these methods mainly focus on handcrafted features (e.g., spectral, texture, and structural features) and their encoded features [
8,
9], thus ignoring the deep semantic information in HRRS images. In recent years, many deep learning-based methods have been proposed, to meet the challenge of remote sensing scene classification. Deep learning-based methods have gained extensive attention due to their ability to leverage both low-level textural features and high-level semantic information in images, while also being skillfully integrated with other advanced theoretical methodologies. Compared to traditional methods of scene classification, the methods based on deep learning techniques have distinct advantages in extracting relevant local and global features from images in large-scale datasets. These techniques can be broadly categorized into transfer learning-based methods, convolutional neural network (CNN)-based methods, and vision transformer (ViT)-based methods.
To some extent, deep learning-based remote sensing scene classification is a technique developed from natural image classification. Therefore, exploring the transfer of prior knowledge directly from natural images to HRRS images is an important way to quickly build a high-performance scene classification method. There have been several attempts to use transfer learning models pretrained on ImageNet to remote scene classification [
10,
11,
12]. Sun et al. [
10] proposed a gated bidirectional network (GBNet) that can remove interference information and aggregate interdependent information between different CNN layers for remote sensing scene classification. Bazi et al. [
11] introduced a simple and effective fine-tuning method to reduce the loss of the image feature gradient using auxiliary classification loss. Wang et al. [
12] proposed an adaptive transfer model from generic knowledge, to automatically determine which knowledge should be transferred to the remote sensing scene classification model. However, due to the great difference between remote sensing images and natural images, models pretrained on natural images have difficulties describing HRRS scenes [
13].
Convolutional neural networks (CNNs) have been considered for combination with other advanced techniques to improve scene discrimination ability. Ref. [
14] designed an improved bilinear pooling method, to build a compact model with higher discriminative power but lower dimensionality. Wang et al. [
15] proposed an enhanced feature pyramid network for remote sensing scene classification, which applied multi-level and multi-scale features, for their complementary advantages and to introduce multi-level feature fusion modules. Xu et al. [
16] proposed a deep feature aggregation framework for remote sensing scene classification, which utilized pretrained CNNs as feature extractors and integrated graph convolutions to aggregate multi-level features. Wang et al. [
17] designed an adaptive high-dimensional feature channel dimensionality reduction method for the inherent clutter and small objects in HRRS images, and introduced an multilevel feature fusion module for efficient feature fusion. Recently, many scholars have focused on the theory of combining CNNs with attention mechanisms. Shen et al. [
18] developed a dual-model deep feature fusion method that utilizes a spatial attention mechanism to filter low-level features and fuse local features with high-level features in a global–local cascaded network, addressing the drawbacks of neglecting the combination of global and local features in current single-CNN models. In [
19], the scholars discussed merging general semantic feature information with clustered semantic feature information by rearranging the weights of the corresponding information. Cao et al. [
20] proposed a spatial-level and channel-level weighted fusion multilayer feature map for CNN models using a self-attentive mechanism, where the aggregated features are fed into a support vector machine (SVM) for classification. Zhang et al. [
21] proposed a method that integrates a multiscale module and a channel position attention module, which guides the network to select and concentrate on the most relevant regions, thereby improving the performance of remote sensing scene classification. Wang et al. [
22] introduced a TMGMA method, which leverages a multi-scale attention module guided by a triplet metric, to enhance task-specific salient features, while avoiding the confusion stemming from relying solely on either an attention mechanism or metric learning. In [
23,
24], an attention mechanism was proven to be an effective method for exploiting the shallow and intermediate features of CNNs. Although CNN-based methods have notably boosted classification accuracy by modeling local features, the long-range dependencies in HRRS images are ignored [
25].
With the tremendous success of the transformer model in the field of natural language processing (NLP), scholars have focused on exploring the application of transformer on natural image classification. Dosovitskiy et al. [
26] pioneered vision transformer, which demonstrated the outstanding performance of transformer for natural image classification. A swin transformer [
27] employed a multi-stage hierarchical architecture for natural image classification, to compute attention within a local window. Based on ViT, a number of different models have been investigated for scene classification, to mine the features of HRRS images. In [
28], scholars explored the use of a data enhancement strategy to improve the transfer learning performance of a ViT model. Zhang et al. [
29] proposed a new bottleneck based on multi-head self-attention (MHSA), which improved the performance of the ViT-based scene classification method by making full use of image embedding. Sha et al. [
30] proposed a new multi-instance visual converter (MITformer) to solve the problem of the ViT ignoring key local features. MITformer combined a ViT and classic multiple instance learning (MIL) formula to highlight key image patches, and explored the positive contribution of an attention-based multilayer perceptron (MLP) and semantic consistency loss function to the scene. Bi et al. [
31] proposed a method based on a ViT model combined with supervised contrast learning, to fully leverage the advantages of both and further improve the accuracy of scene classification.
Recently, combining CNNs and a ViT to develop methods that simultaneously mine local features and long-range dependencies in HRRS images has become a trend in remote sensing communities. Deng et al. [
13] proposed a high-performance joint framework containing ViT streams and CNN streams, and established a joint loss function to increase intraclass aggregation, to mine semantic features in HRRS images. Zhao et al. [
32] introduced a local and long-range collaborative framework (L2RCF) with a dual-stream structure, to extract local and remote features. L2RCF designed a cross-feature calibration (CFC) module and a new joint loss function, to improve the representation of fused features. Referring to the aforementioned analysis, enhancing the performance of ViT-based methods in scene classification has become a mainstream research direction. Nevertheless, the current ViT-based approaches tend to solely address issues by compensating for ViT’s limitations or by merging the benefits of CNNs and a ViT. Compared to the shared weights employed in CNNs, which serve to decrease the parameter count and computational complexity of the model, a ViT utilizes a fully connected layer alongside a multi-head self-attention mechanism at many positions. The multi-head self-attention mechanism effectively establishes extensive interdependencies between different positions, thus allowing for more accurate capturing of global information. However, in a multi-head self-attention mechanism, attention weights need to be calculated between queries, keys, and values. For each query, it is necessary to calculate the similarity between it and all keys, resulting in increased computational complexity. Furthermore, the fully connected layer necessitates computation of feature vectors for each position with all other feature vectors across all positions, rendering the computational workload substantially greater. Consequently, developing an efficient and lightweight model carries crucial significance for remote sensing scene classification.
To solve the above-mentioned issues, a lightweight dual-branch swin transformer (LDBST) is proposed for remote sensing scene classification, which combines the advantages of vision transformers and CNNs. The main contributions of this paper are summarized below:
(1) In the dual branches of the LDBST model, the CNNs branch with max pooling not only preserves the original feature maps’ strong features but also lightens the LDBST through avoiding complex multi-head attention and MLP computation;
(2) The ViT branch integrated with the Conv-MLP is designed to enhance the long-range dependencies of local features, though boosting the connectivity between neighboring windows;
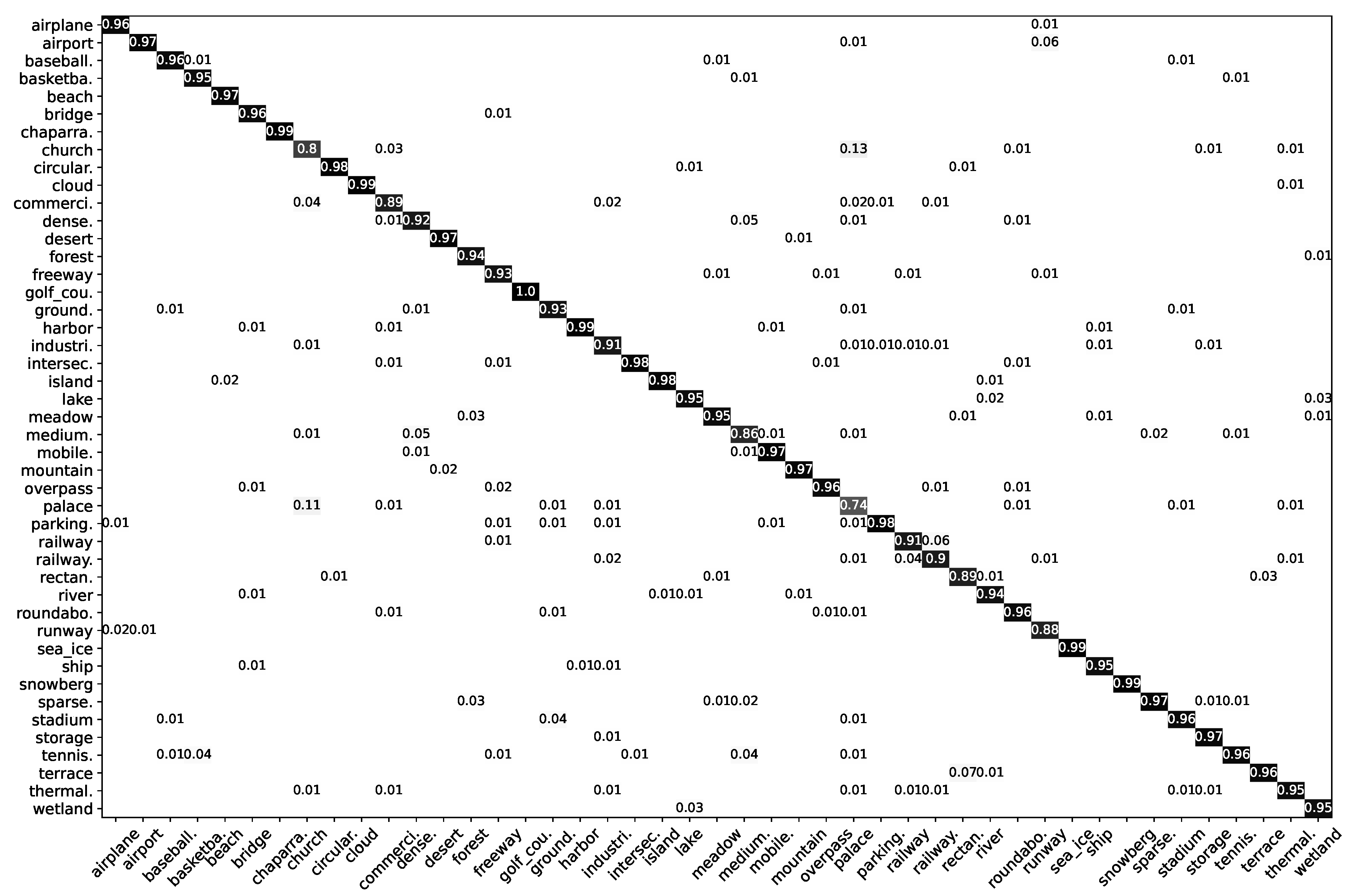
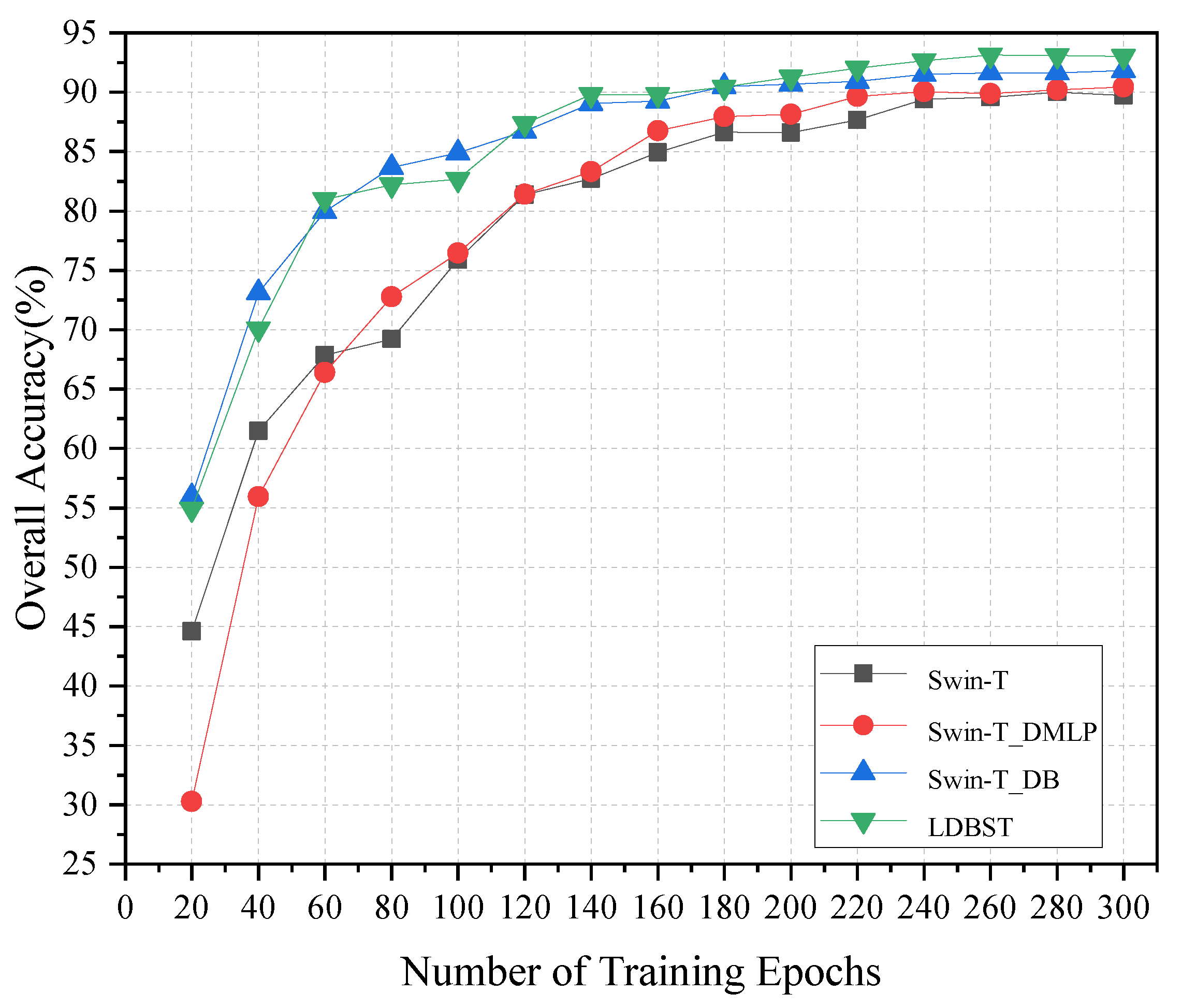
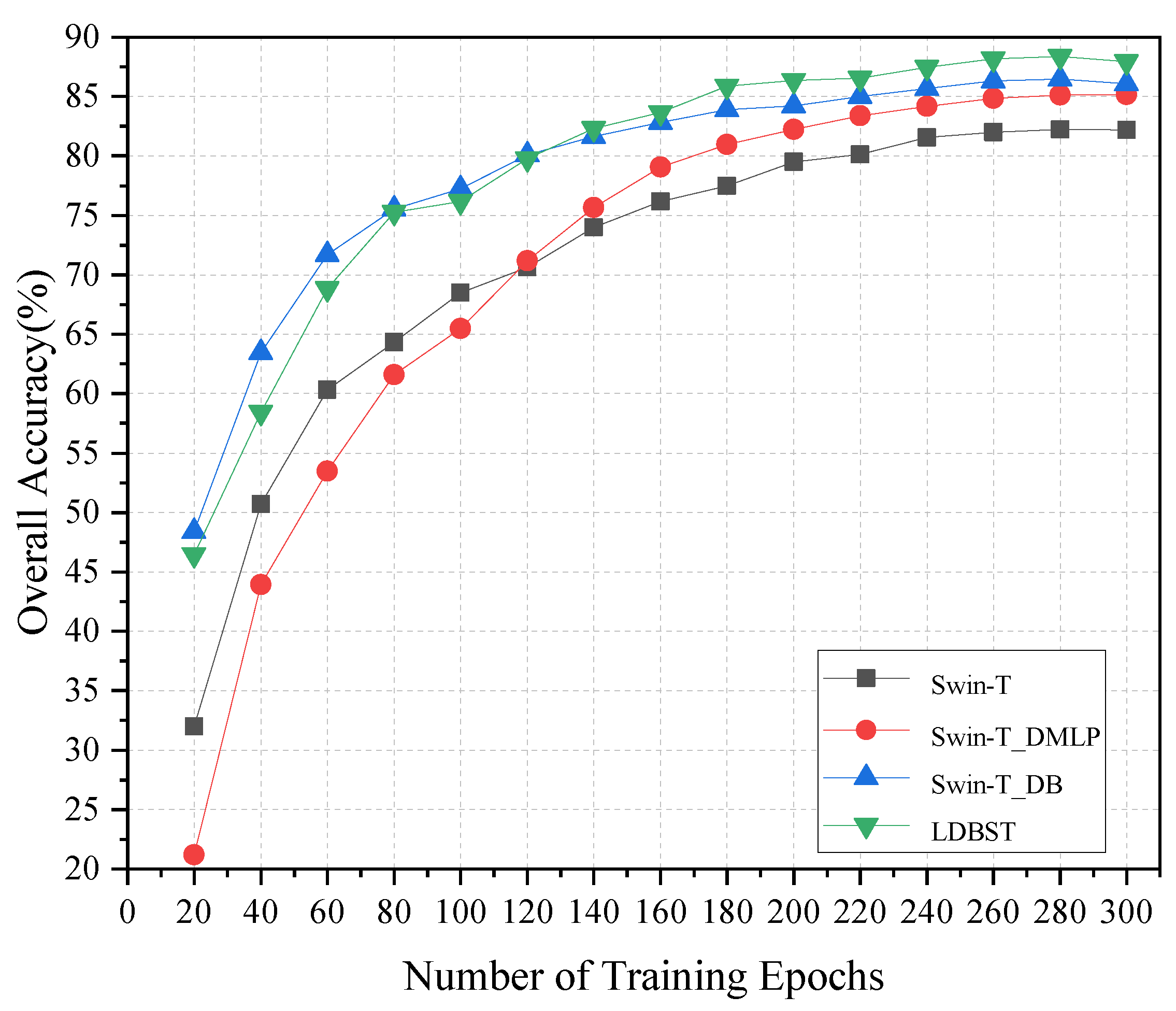
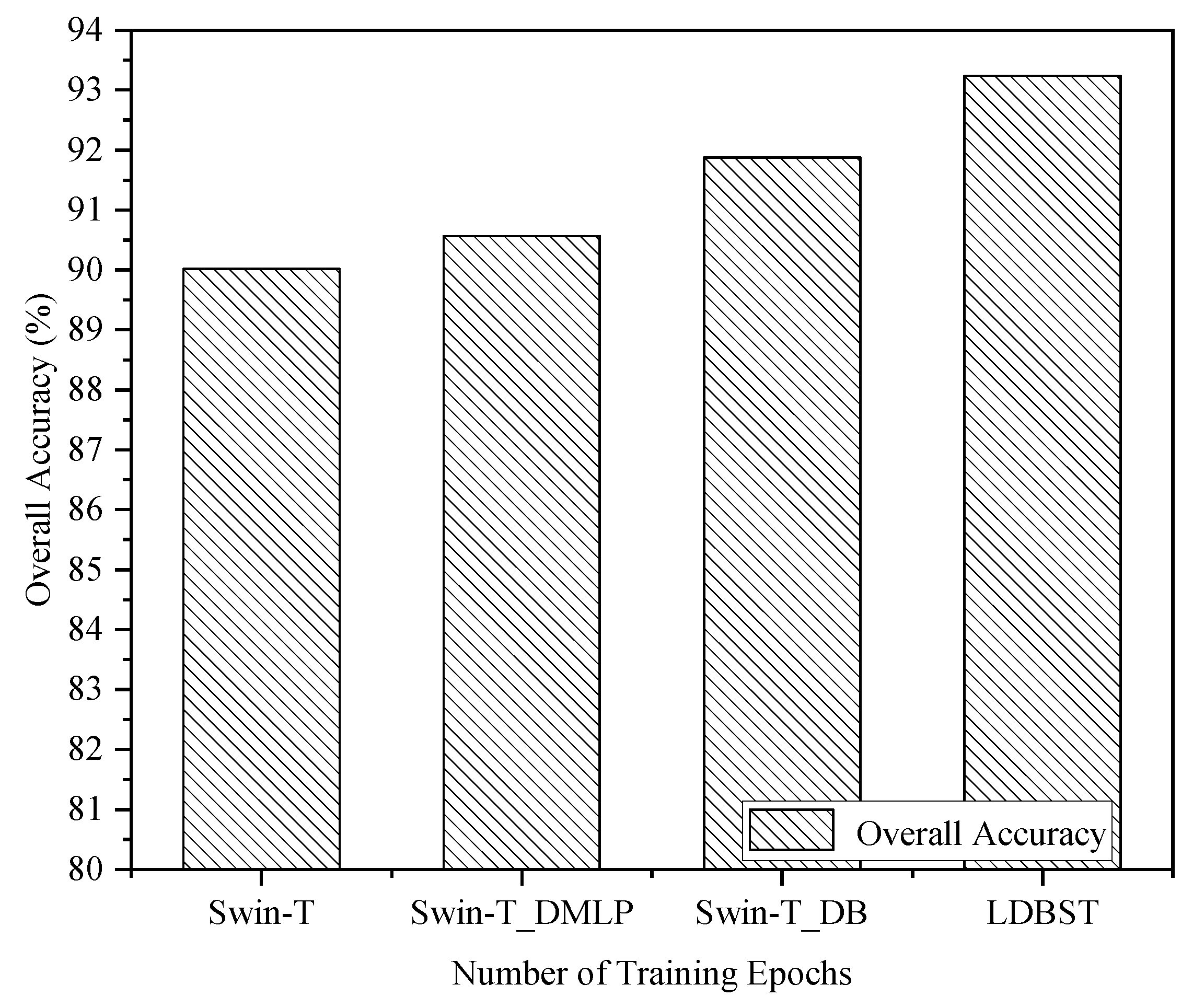
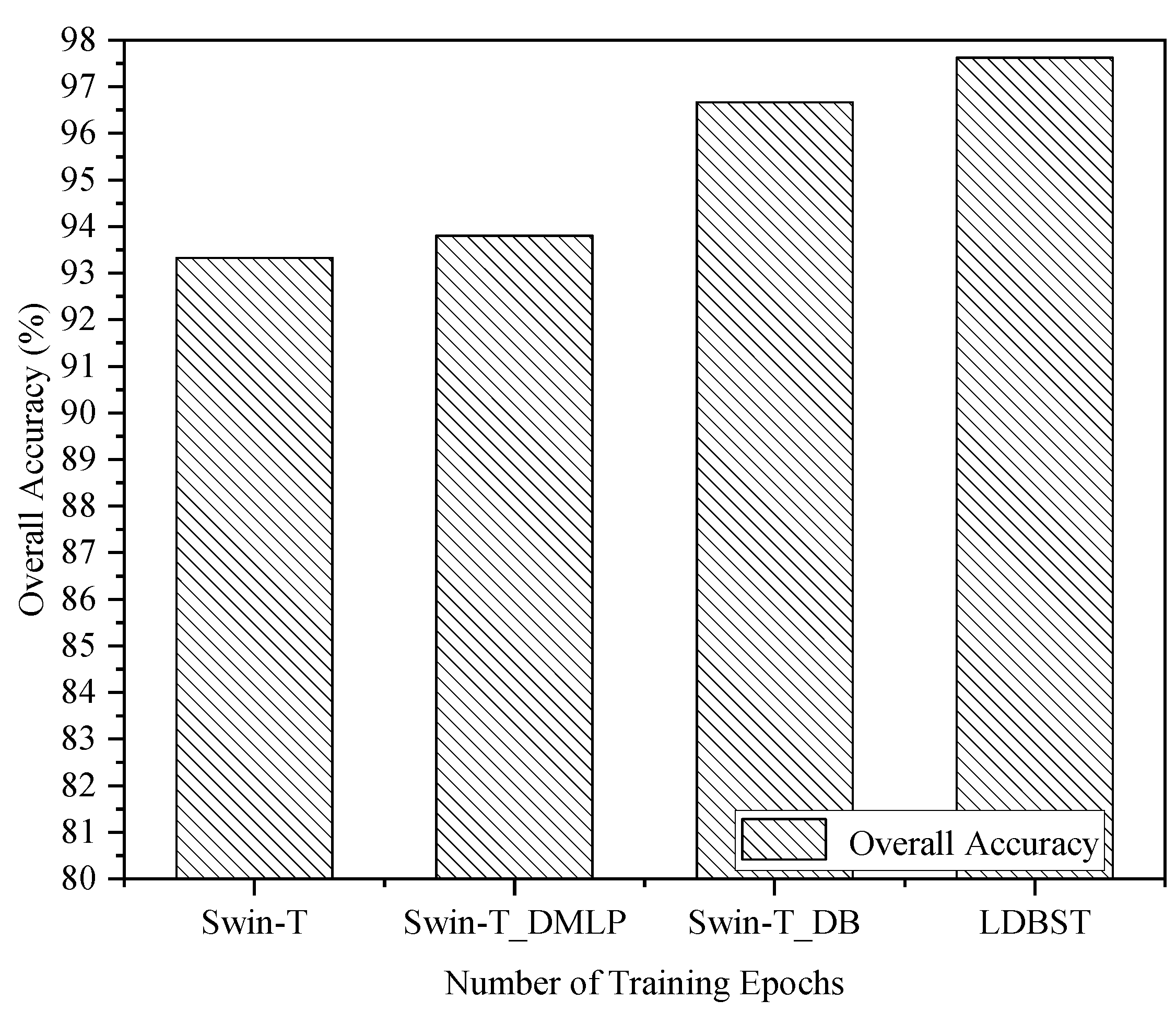
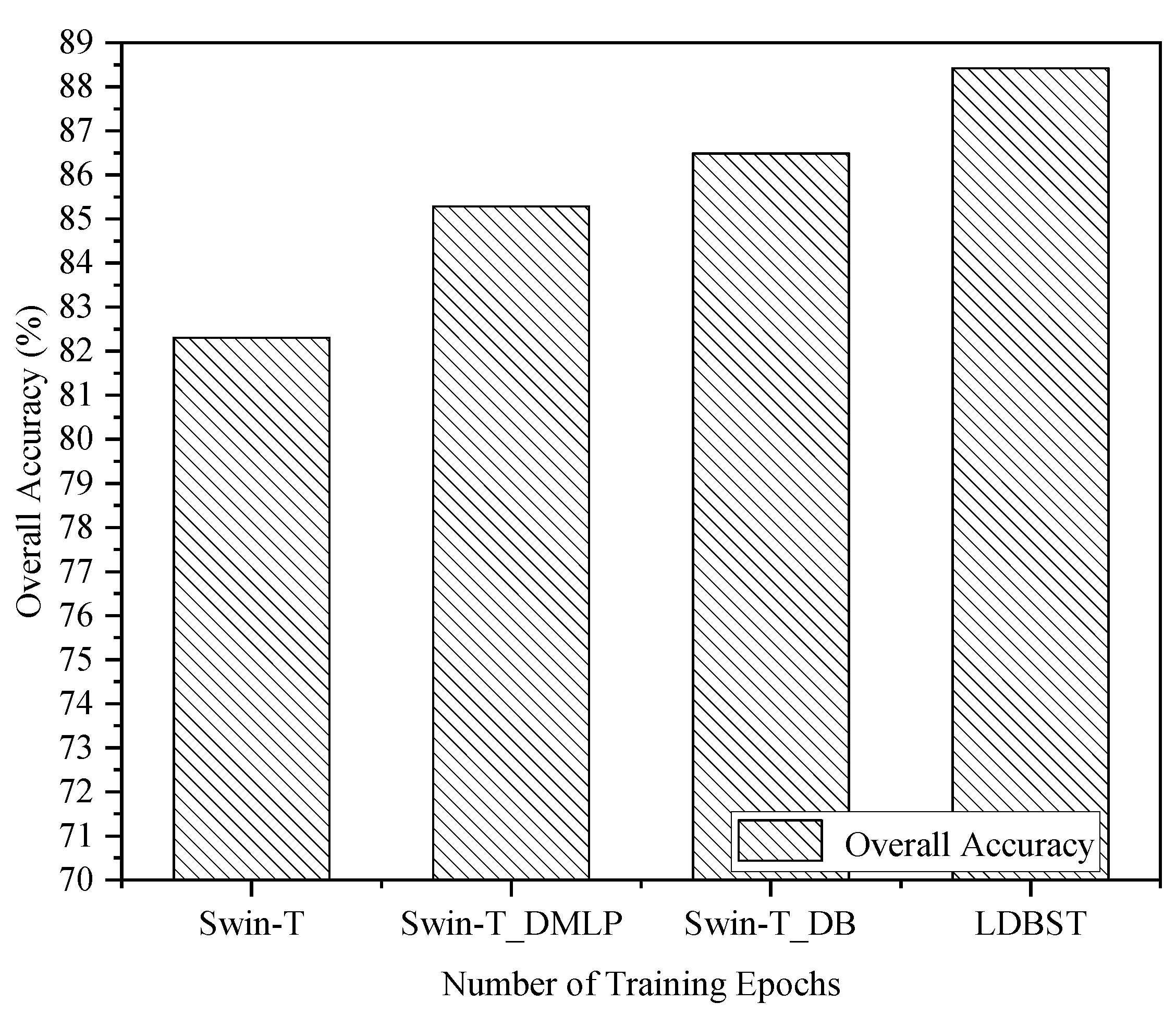
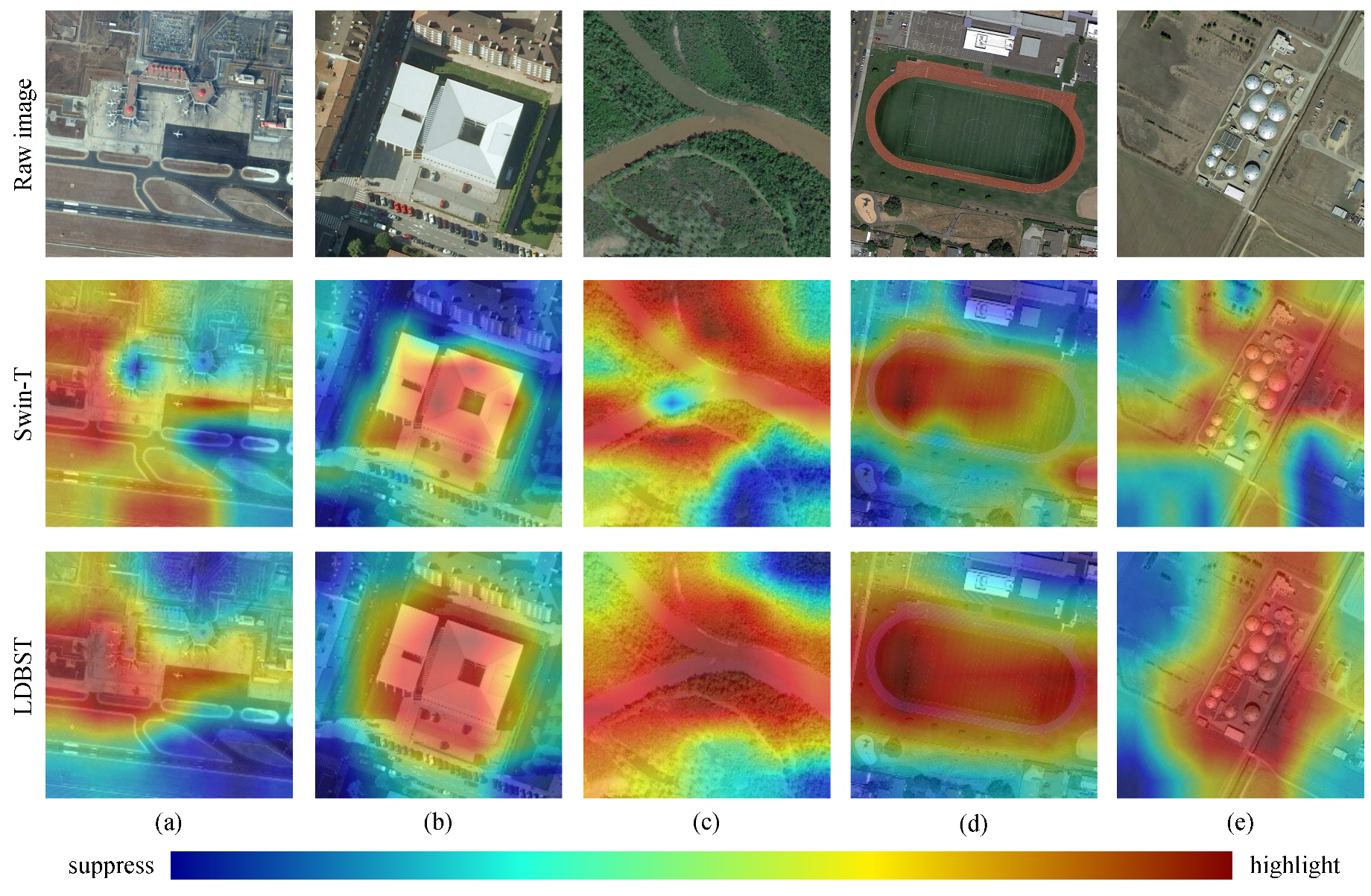
(3) The performance of the LDBST model pretrained on large-scale remote sensing datasets was validated experimentally on the AID, UC-Merced, and NWPU-RESISC45 datasets. Extensive experimental results demonstrated that LDBST exhibited consistent superiority over CNNs pretrained on ImageNet.
2. Proposed LDBST Method
In this section, we will present a comprehensive theoretical explanation of the proposed LDBST architecture and its modules, starting with an overview of the overall network structure, followed by the proposed Dual-branch “CNNs + Swin Transformer” Module.
2.1. Overall Architecture of LDBST
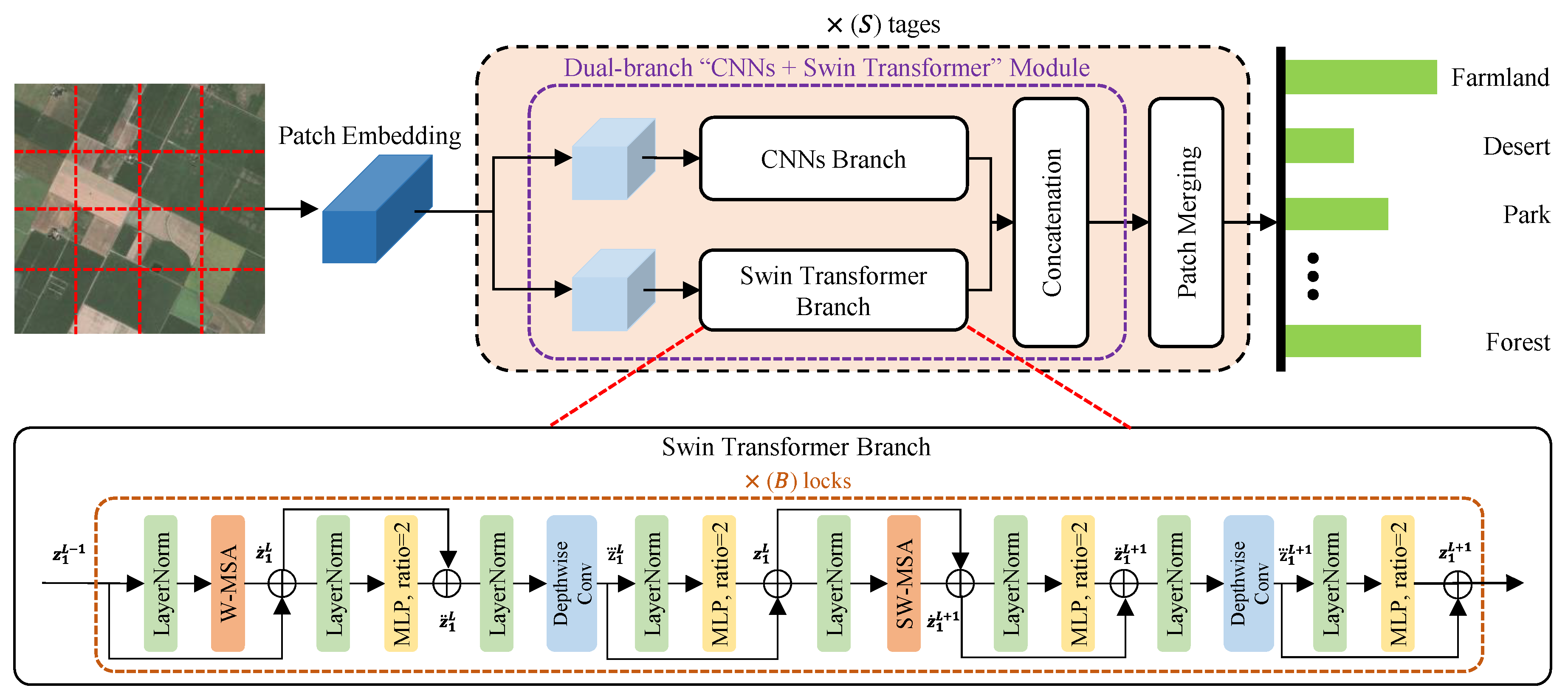
The LDBST model is proposed as a novel lightweight scene classifier, for effectively obtaining semantic context information in HRRS images, and the framework of LDBST is provided in
Figure 1. In our LDBST structure, the hierarchical ViT method (Swin-Tiny [
27]) is used as the baseline for the LDBST method to explore long-range dependencies in HRRS images. Then, Conv-MLP [
33] is integrated into each stage of the LDBST, which enhances the model’s ability to mine long-range dependencies in HRRS images, by strengthening the ViT neighboring window connections. Finally, and most importantly, a dual-branch structure called “CNNs + Swin Transformers” is designed, to split each stage feature in the original Swin-Tiny into two branches, which not only integrates the advantages of a CNN branch for local information and a ViT branch for global information, but also achieves a lightweight model by avoiding the computation of a portion of the fully connected layers and the multi-headed attention mechanism in ViT.
In the LDBST method, a hierarchical vision transformer is constructed using four cascaded stages. The four stages consist of 2, 2, 6, and 2 stacks of swin transformer blocks, respectively. Furthermore, a patch merging method based on linear layers is used to downsample feature maps between each stage, except the last stage.
Given an HRRS image , where H represents the image height, W denotes image width, and C indicates the number of image channels. LDBST first masks a window on the input x of the convolution layer to downsample the input HRRS image to the first stage, and it obtains a set of patches . Then, each patch in P is tokenized using linear embedding. In addition, relative position embeddings are added to these tokens, to represent the positional information. Finally, the embedding vector sequence is fed into the four cascaded stages of the LDBST, and the output dimensions downsampled at each stage are , , , and . Specially, we set n to 4 and C to 96.
2.2. Dual-Branch “CNNs + Swin Transformer” Module
For simplicity, assume that the input for a certain stage of the hierarchical LDBST method is
, the dual-branch structure of LDBST splits it into a
part and
part by a
convolutional layer, and the number of channels of the two features is set to be half of
. The calculating process can be expressed as follows:
For
, the window partitioning approach is adopted to compute the output
of
layer in the transformer encoder. First, to enhance the capability of the ViT branch in capturing long-range dependency information, additional multilayer perceptrons (MLP) are incorporated into the transformer encoder. Simultaneously, due to the potential drawbacks of increased MLP layers in the ViT branch, which has a limitation on the spatial interaction information, we introduce a depthwise convolution between two MLP blocks, to strengthen the connectivity among neighboring windows, drawing inspiration from Conv-MLP. The calculating process can be defined as
where
represents the window-based multi-head self-attention,
is the LayerNorm,
denotes the multilayer perceptron,
indicates depthwise convolution, and
T denotes the transpose matrix.
is added between two MLPs, which is a
convolution layer with the same channel as the two channels of the MLPs, thereby increasing the neighbor window connections.
Then, the shifted window partitioning approach is adopted to compute the output
of the
layer in the transformer encoder, and the corresponding output of the swin transformer branch is formed by
where
denotes the shifted window-based multi-head self-attention. All MLP extension layers in the ViT branches are set to 2, to reduce the number of parameters. Although Formulas (2) and (3) contain many complex computational processes in the ViT branch, the initial input
of Formulas (2) and (3) is only half the size of the original input feature
of each stage of the LDBST. This means that the proposed dual-branch structure not only enables the model to obtain good feature representation, but also achieves a lightweight model by avoiding certain complex calculations.
Next, for the output
of Formula (1), the CNN branch first takes a 3 × 3 convolution layer to extract features, then max pooling is adopted to retain strong features and accelerate the model convergence, finally obtaining the result
. Thus,
can be calculated using
Finally, the output
of the dual-branch “CNNs + Swin Transformer” module is obtained by stacking
and
in the channel dimension, and this can be formulated as
In summary, the dual-branch module first divides the input feature into two parts and from the channel dimension, then the part is input to the ViT branch of the integrated Conv_MLP, to enhance the connections among neighboring windows and improve the model’s ability to understand global information. To lighten the model and strengthen the ability to understand global information, a convolution layer and a max pooling layer are applied to the part. Since the part only applies a simple convolutional layer and a max pooling layer, this avoids complex multi-head self-attention and MLP computation. Therefore, the computation and parameter number of the LDBST method are significantly reduced when comparing to the baseline Swin-Tiny method.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}