
Dual-Stream Feature Extraction Network Based on CNN and Transformer for Building Extraction


Abstract
1. Introduction
- We proposed a CNN-based and transformer-based dual-stream feature extraction network. The CNN branch enriches detailed features in the transformer branch, and the transformer branch enhances global features in the CNN branch, realizing a complementary representation of local features and global features.
- We designed a semantic embedding module and a spatial embedding module, to enable the fusion of low and high level features, to achieve a combination of edge details and semantic information, in order to improve the semantic segmentation results of buildings.
- Our model achieved a higher performance than current state-of-the-art networks on both the Google Beijing dataset and the ISPRS Vaihingen dataset.
2. Related Work
2.1. CNN-Based Semantic Segmentation for Building Extraction
2.2. Transformer-Based Semantic Segmentation for Building Extraction
2.3. CNN and Transformer-Based Semantic Segmentation for Building Extraction
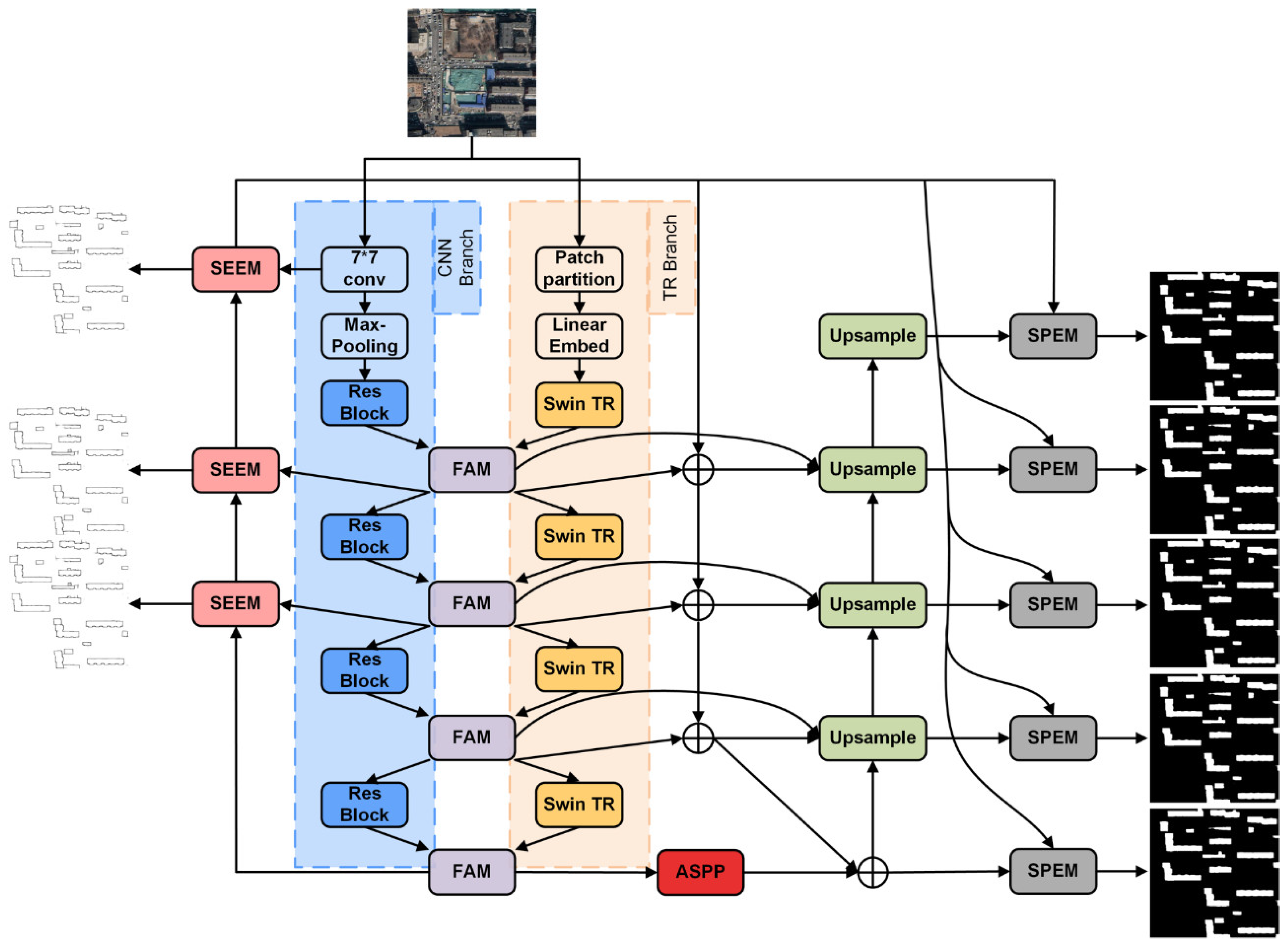
3. Materials and Methods
3.1. Dual-Stream Feature Extraction
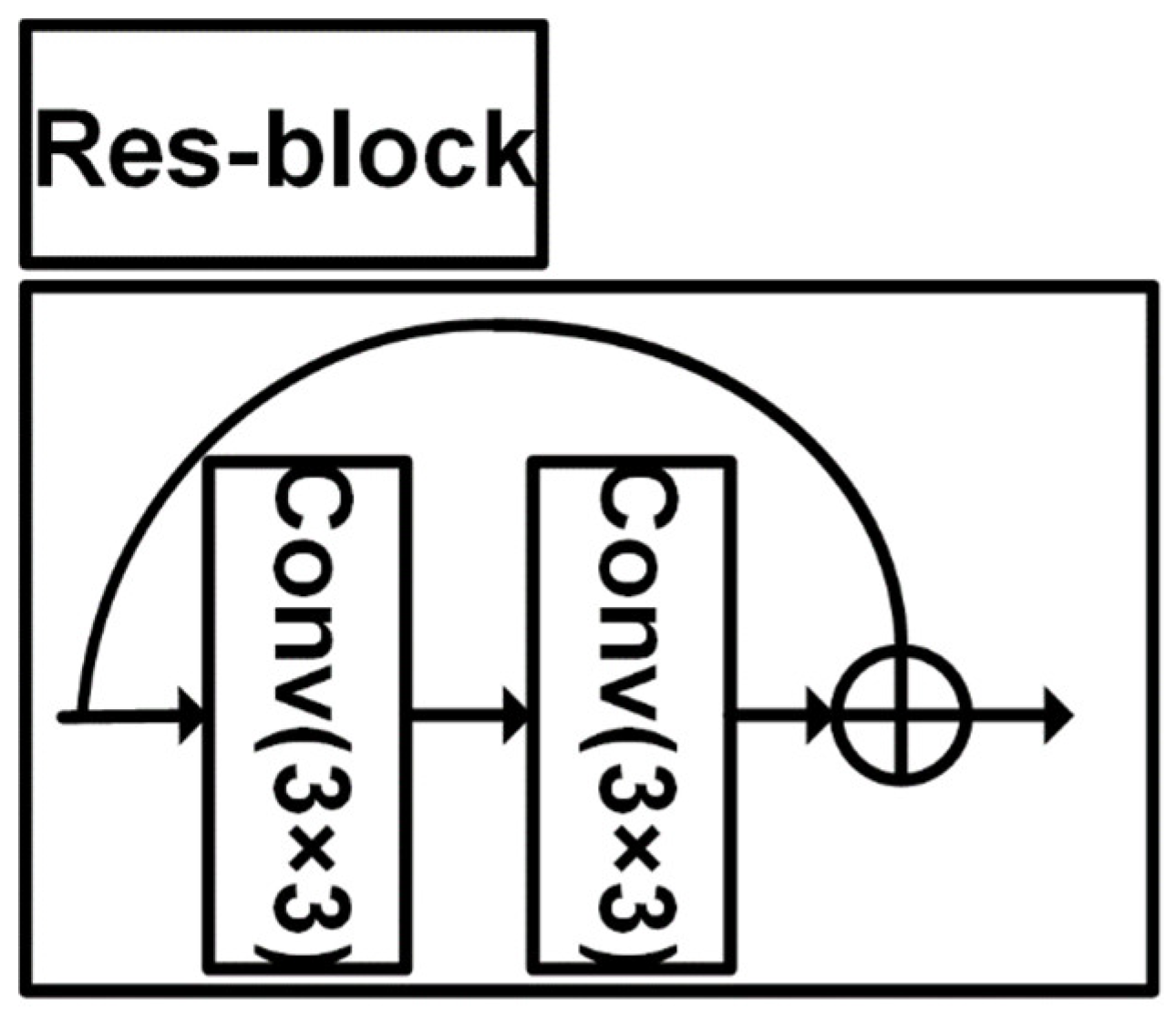
3.1.1. CNN Branch
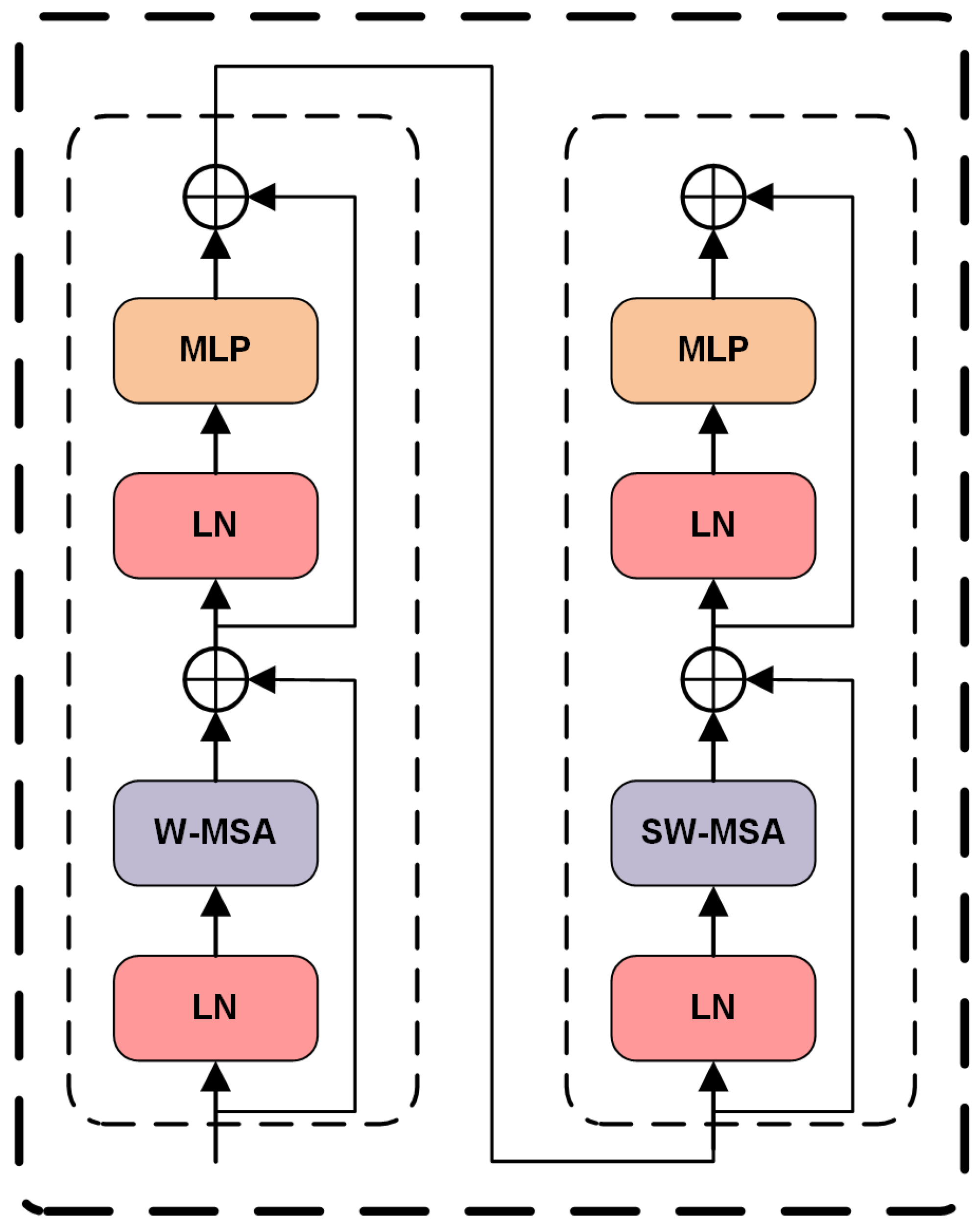
3.1.2. Swin Transformer Branch
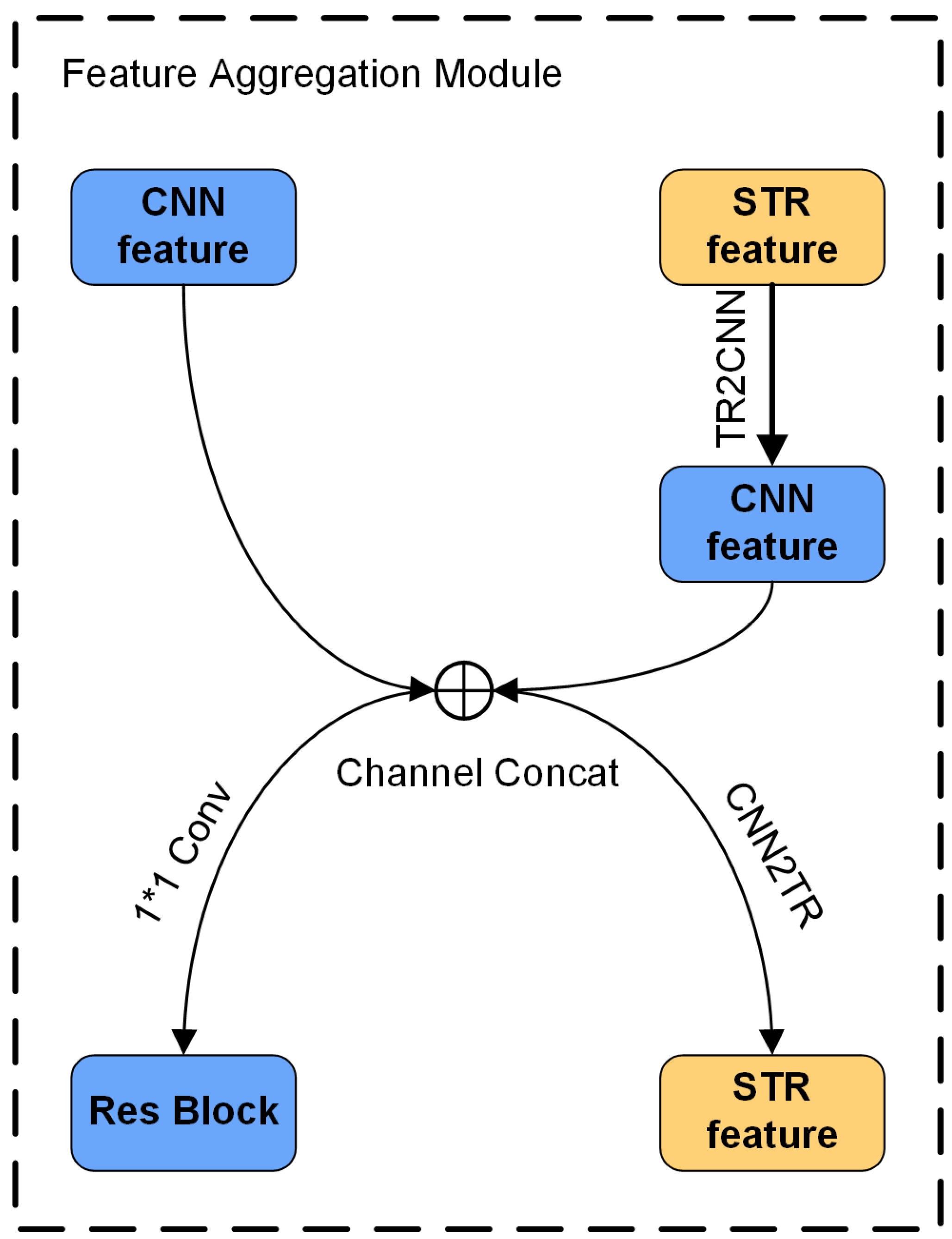
3.2. Feature Aggregation Module
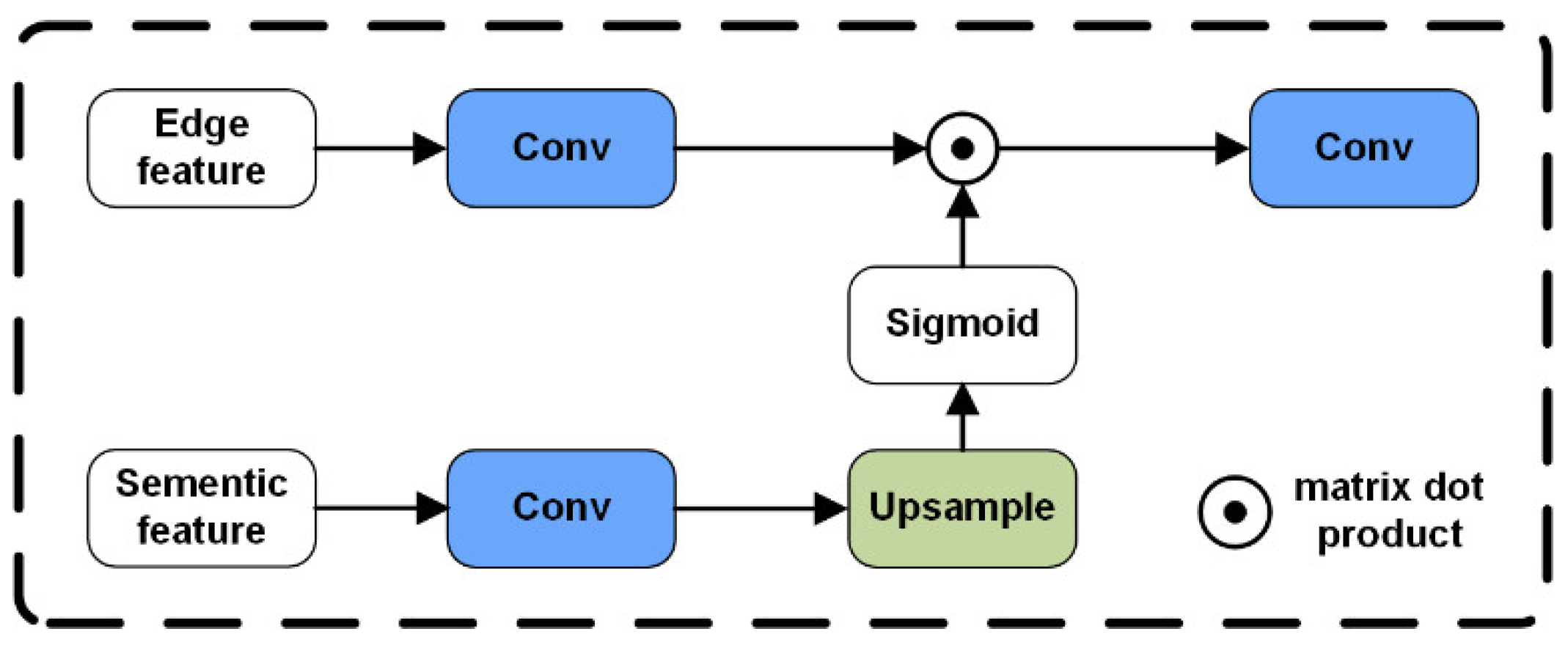
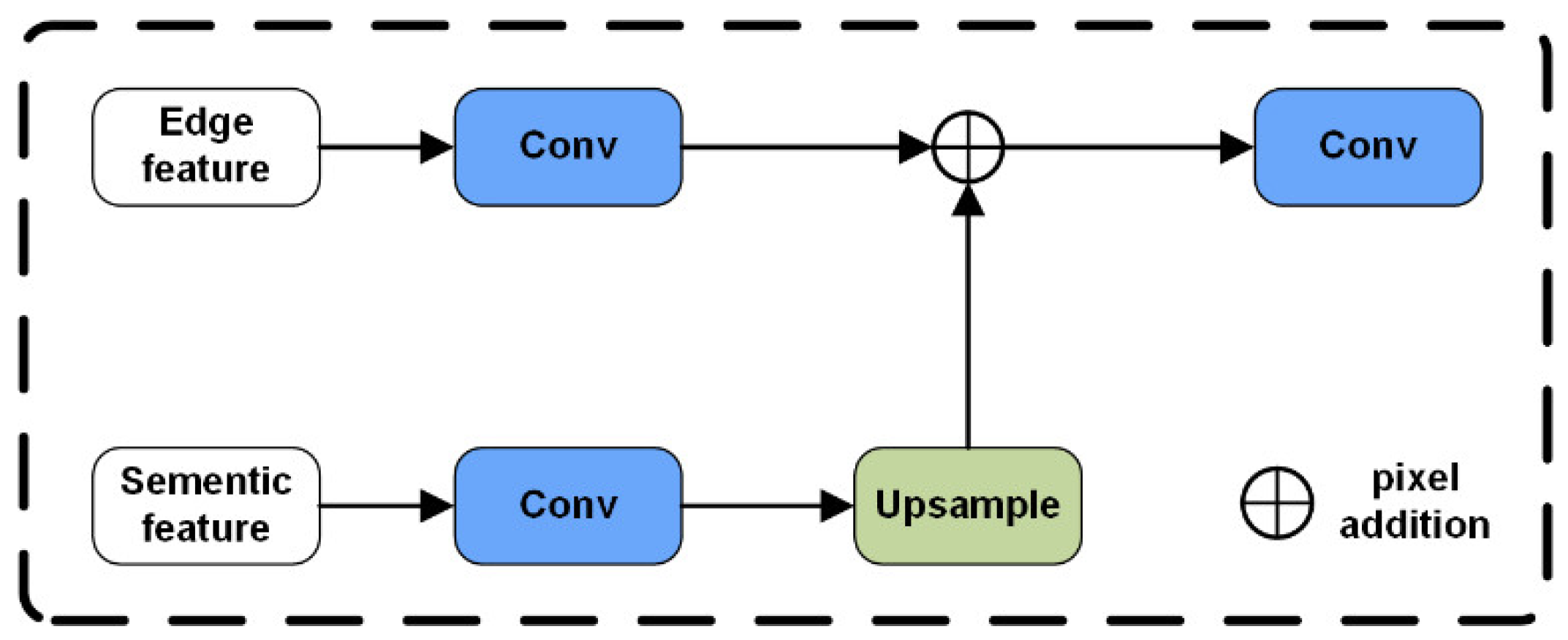
3.3. Semantic Embedding Module and Spatial Embedding Module
3.3.1. Semantic Embedding Module
3.3.2. Spatial Embedding Module
3.4. Pyramid Skip Connection
3.5. Loss
3.5.1. Polygon Loss
3.5.2. Semantic Edge Loss
4. Experiments and Results
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Results
4.5. Ablation Study
4.6. Further Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gilani, S.A.N.; Awrangjeb, M.; Lu, G. Segmentation of airborne point cloud data for automatic building roof extraction. GISci. Remote Sens. 2018, 55, 63–89. [Google Scholar] [CrossRef]
- Ding, Q.; Shao, Z.; Huang, X.; Altan, O. DSA-Net: A novel deeply supervised attention-guided network for building change detection in high-resolution remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102591. [Google Scholar] [CrossRef]
- Yang, G.; Zhang, Q.; Zhang, G. EANet: Edge-aware network for the extraction of buildings from aerial images. Remote Sens. 2020, 12, 2161. [Google Scholar] [CrossRef]
- Cao, S.; Weng, Q.; Du, M.; Li, B.; Zhong, R.; Mo, Y. Multi-scale three-dimensional detection of urban buildings using aerial LiDAR data. GISci. Remote Sens. 2020, 57, 1125–1143. [Google Scholar] [CrossRef]
- Wang, S.; Hou, X.; Zhao, X. Automatic building extraction from high-resolution aerial imagery via fully convolutional encoder-decoder network with non-local block. IEEE Access 2020, 8, 7313–7322. [Google Scholar] [CrossRef]
- Yang, H.; Yu, B.; Luo, J.; Chen, F. Semantic segmentation of high spatial resolution images with deep neural networks. GISci. Remote Sens. 2019, 56, 749–768. [Google Scholar] [CrossRef]
- Liu, T.; Yao, L.; Qin, J.; Lu, N.; Jiang, H.; Zhang, F.; Zhou, C. Multi-scale attention integrated hierarchical networks for high-resolution building footprint extraction. Int. J. Appl. Earth Obs. Geoinf. 2022, 109, 102768. [Google Scholar] [CrossRef]
- Qian, Z.; Chen, M.; Zhong, T.; Zhang, F.; Zhu, R.; Zhang, Z.; Zhang, K.; Sun, Z.; Lü, G. Deep Roof Refiner: A detail-oriented deep learning network for refined delineation of roof structure lines using satellite imagery. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102680. [Google Scholar] [CrossRef]
- Huang, H.; Sun, G.; Rong, J.; Zhang, A.; Ma, P. Multi-feature combined for building shadow detection in GF-2 Images. In Proceedings of the 2018 Fifth International Workshop on Earth Observation and Remote Sensing Applications (EORSA), Xi’an, China, 18–20 June 2018; pp. 1–4. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local features coupling global representations for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 367–376. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5999–6009. [Google Scholar]
- Li, K.; Wang, Y.; Zhang, J.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. UniFormer: Unifying Convolution and Self-attention for Visual Recognition. arXiv 2022, arXiv:2201.09450. [Google Scholar]
- Wang, Z.; Xu, N.; Wang, B.; Liu, Y.; Zhang, S. Urban building extraction from high-resolution remote sensing imagery based on multi-scale recurrent conditional generative adversarial network. GISci. Remote Sens. 2022, 59, 861–884. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic segmentation of urban buildings from VHR remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building footprint extraction from high-resolution images via spatial residual inception convolutional neural network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef]
- Deng, W.; Shi, Q.; Li, J. Attention-Gate-Based Encoder–Decoder Network for Automatical Building Extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2611–2620. [Google Scholar] [CrossRef]
- Jing, H.; Sun, X.; Wang, Z.; Chen, K.; Diao, W.; Fu, K. Fine building segmentation in high-resolution SAR images via selective pyramid dilated network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6608–6623. [Google Scholar] [CrossRef]
- Zhu, Q.; Liao, C.; Hu, H.; Mei, X.; Li, H. MAP-Net: Multiple attending path neural network for building footprint extraction from remote sensed imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6169–6181. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Xu, Z.; Zhang, W.; Zhang, T.; Yang, Z.; Li, J. Efficient transformer for remote sensing image segmentation. Remote Sens. 2021, 13, 3585. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Chen, K.; Zou, Z.; Shi, Z. Building Extraction from Remote Sensing Images with Sparse Token Transformers. Remote Sens. 2021, 13, 4441. [Google Scholar] [CrossRef]
- Valanarasu, J.M.J.; Oza, P.; Hacihaliloglu, I.; Patel, V.M. Medical transformer: Gated axial-attention for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; pp. 36–46. [Google Scholar]
- Gao, Y.; Zhou, M.; Metaxas, D.N. UTNet: A hybrid transformer architecture for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; pp. 61–71. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin Transformer Embedding UNet for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, W.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C. Transformer and CNN Hybrid Deep Neural Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–20. [Google Scholar] [CrossRef]
- Wang, L.; Fang, S.; Zhang, C.; Li, R.; Duan, C. Efficient Hybrid Transformer: Learning Global-local Context for Urban Scene Segmentation. arXiv 2021, arXiv:2109.08937. [Google Scholar]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing Swin Transformer and Convolutional Neural Network for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]
- Shang, R.; Zhang, J.; Jiao, L.; Li, Y.; Marturi, N.; Stolkin, R. Multi-scale adaptive feature fusion network for semantic segmentation in remote sensing images. Remote Sens. 2020, 12, 872. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.-W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Xia, L.; Zhang, J.; Zhang, X.; Yang, H.; Xu, M. Precise Extraction of Buildings from High-Resolution Remote-Sensing Images Based on Semantic Edges and Segmentation. Remote Sens. 2021, 13, 3083. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]
- Zhao, J.-X.; Liu, J.-J.; Fan, D.-P.; Cao, Y.; Yang, J.; Cheng, M.-M. EGNet: Edge guidance network for salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8779–8788. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Area | Method | Boundary IoU | IoU | F1 Score |
|---|---|---|---|---|
| Beijing | U-Net | 0.4599 | 0.7015 | 0.8267 |
| U-Net3+ | 0.3908 | 0.7120 | 0.8413 | |
| D-LinkNet | 0.4640 | 0.7194 | 0.8433 | |
| DDLNet | 0.5321 | 0.7662 | 0.8703 | |
| EGNet | 0.3012 | 0.6371 | 0.7887 | |
| Swin-Unet | 0.2883 | 0.5234 | 0.6976 | |
| MedT | 0.3544 | 0.5975 | 0.7545 | |
| TransUnet | 0.4452 | 0.6948 | 0.8257 | |
| UTNet | 0.4427 | 0.6799 | 0.8176 | |
| DSFENet | 0.5334 | 0.7752 | 0.8752 |
| Study Area | Method | Boundary IoU | IoU | F1 Score |
|---|---|---|---|---|
| Vaihingen | U-Net | 0.4758 | 0.8892 | 0.9405 |
| U-Net3+ | 0.4235 | 0.8969 | 0.9459 | |
| D-LinkNet | 0.5370 | 0.9279 | 0.9628 | |
| DDLNet | 0.5432 | 0.9280 | 0.9629 | |
| EGNet | 0.4025 | 0.8871 | 0.9405 | |
| Swin-Unet | 0.2224 | 0.7440 | 0.8492 | |
| MedT | 0.2614 | 0.7737 | 0.8666 | |
| TransUnet | 0.4696 | 0.8921 | 0.9470 | |
| UTNet | 0.4641 | 0.8992 | 0.9421 | |
| DSFENet | 0.5706 | 0.9294 | 0.9637 |
| Study Area | Method | Boundary IoU | IoU | F1 Score |
|---|---|---|---|---|
| Beijing | DSFENet | 0.5334 | 0.7752 | 0.8752 |
| DSFENet-CNN | 0.5253 | 0.7739 | 0.8695 | |
| DSFENet-TR | 0.4746 | 0.7219 | 0.8388 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, L.; Mi, S.; Zhang, J.; Luo, J.; Shen, Z.; Cheng, Y. Dual-Stream Feature Extraction Network Based on CNN and Transformer for Building Extraction. Remote Sens. 2023, 15, 2689. https://doi.org/10.3390/rs15102689
Xia L, Mi S, Zhang J, Luo J, Shen Z, Cheng Y. Dual-Stream Feature Extraction Network Based on CNN and Transformer for Building Extraction. Remote Sensing. 2023; 15(10):2689. https://doi.org/10.3390/rs15102689
Chicago/Turabian StyleXia, Liegang, Shulin Mi, Junxia Zhang, Jiancheng Luo, Zhanfeng Shen, and Yubin Cheng. 2023. "Dual-Stream Feature Extraction Network Based on CNN and Transformer for Building Extraction" Remote Sensing 15, no. 10: 2689. https://doi.org/10.3390/rs15102689
APA StyleXia, L., Mi, S., Zhang, J., Luo, J., Shen, Z., & Cheng, Y. (2023). Dual-Stream Feature Extraction Network Based on CNN and Transformer for Building Extraction. Remote Sensing, 15(10), 2689. https://doi.org/10.3390/rs15102689