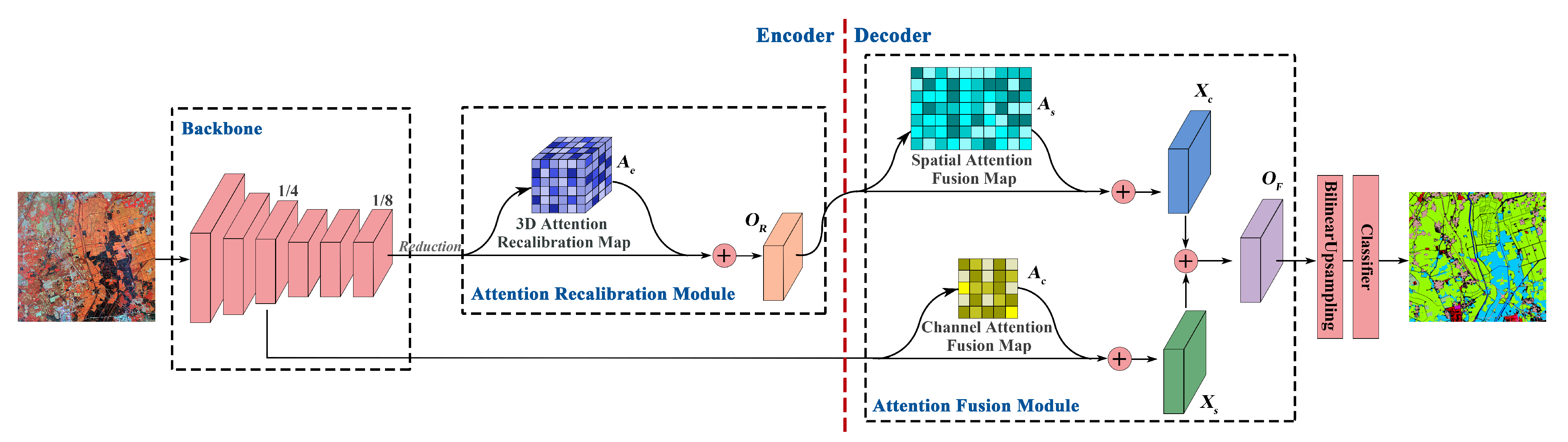
5.1. Effect of ARM
In order to investigate the effect of ARM, we employ the baseline network for ablation experiments, and utilize four state-of-the-art attention modules, including a channel attention module SE [
25], a spatial attention module NLN [
26] as well as two CS attention modules CBAM [
50] and DANet [
32], for comparisons. In the implementation of experiments, these attention modules are inserted into the bottleneck of the baseline network, i.e., the position of ARM in XANet, as shown in
Figure 1.
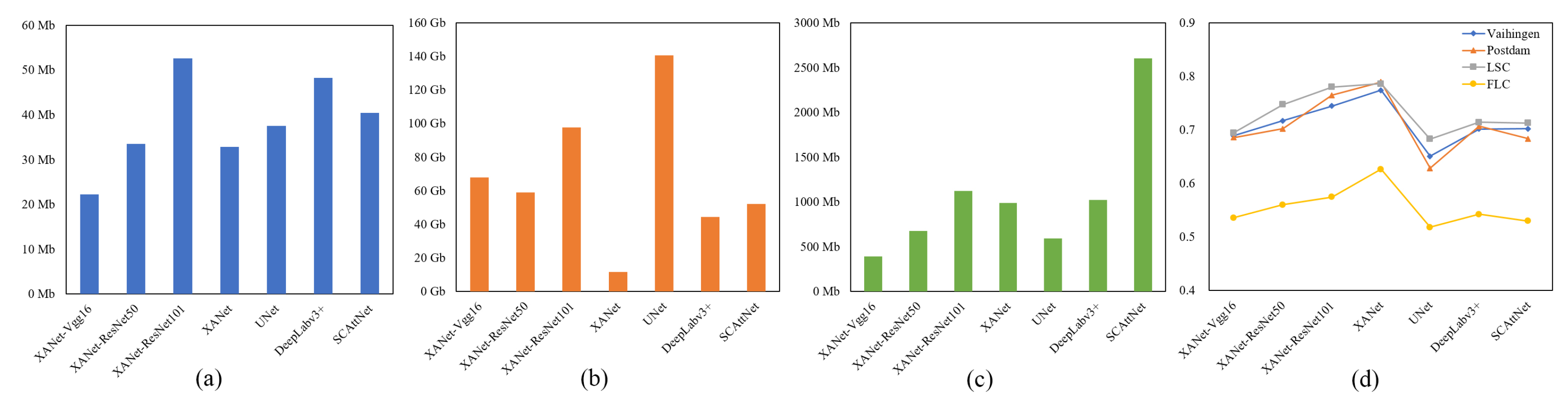
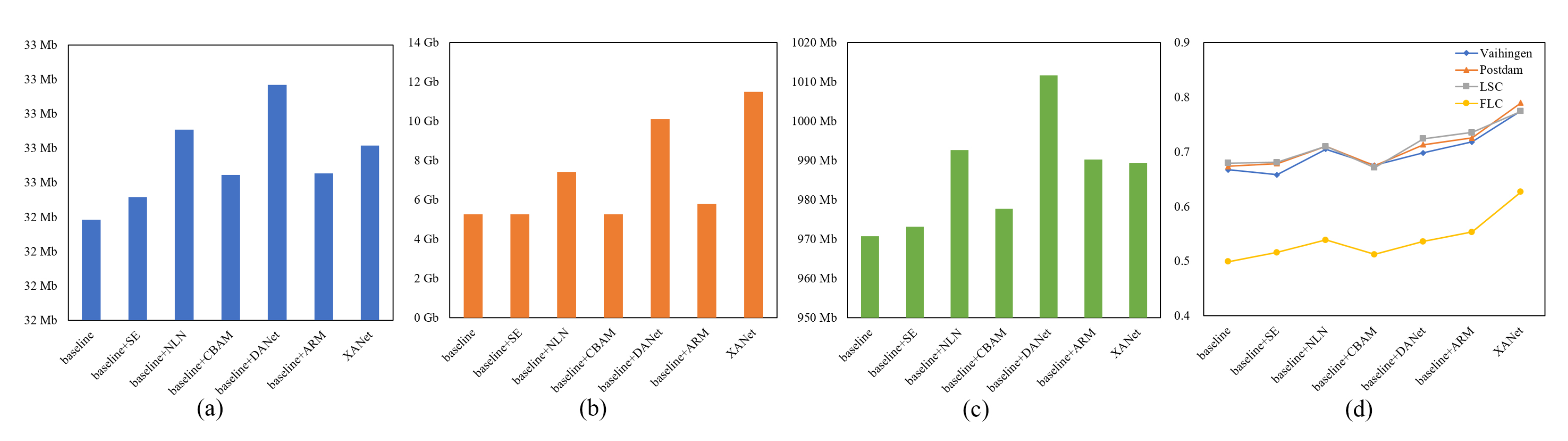
Figure 10 sketches the comprehensive comparison of these attention modules from many aspects.
Table 3 compares their model complexity.
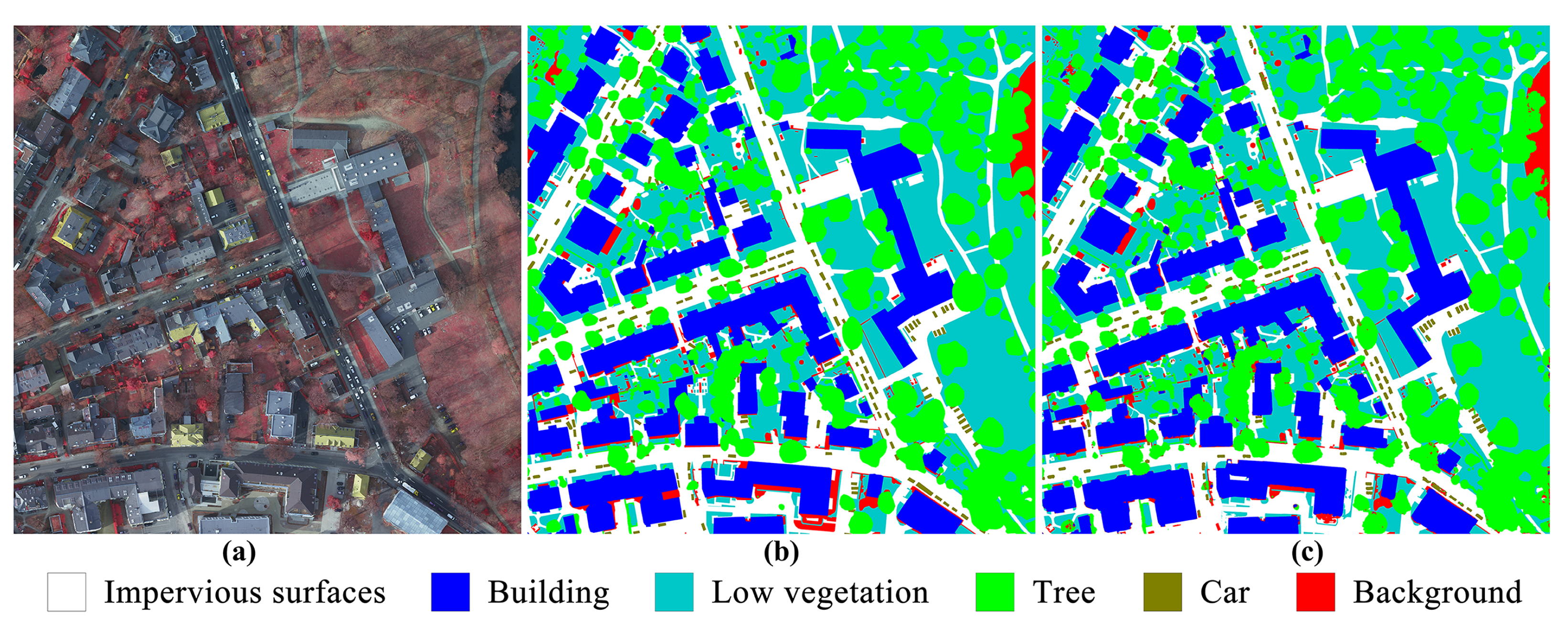
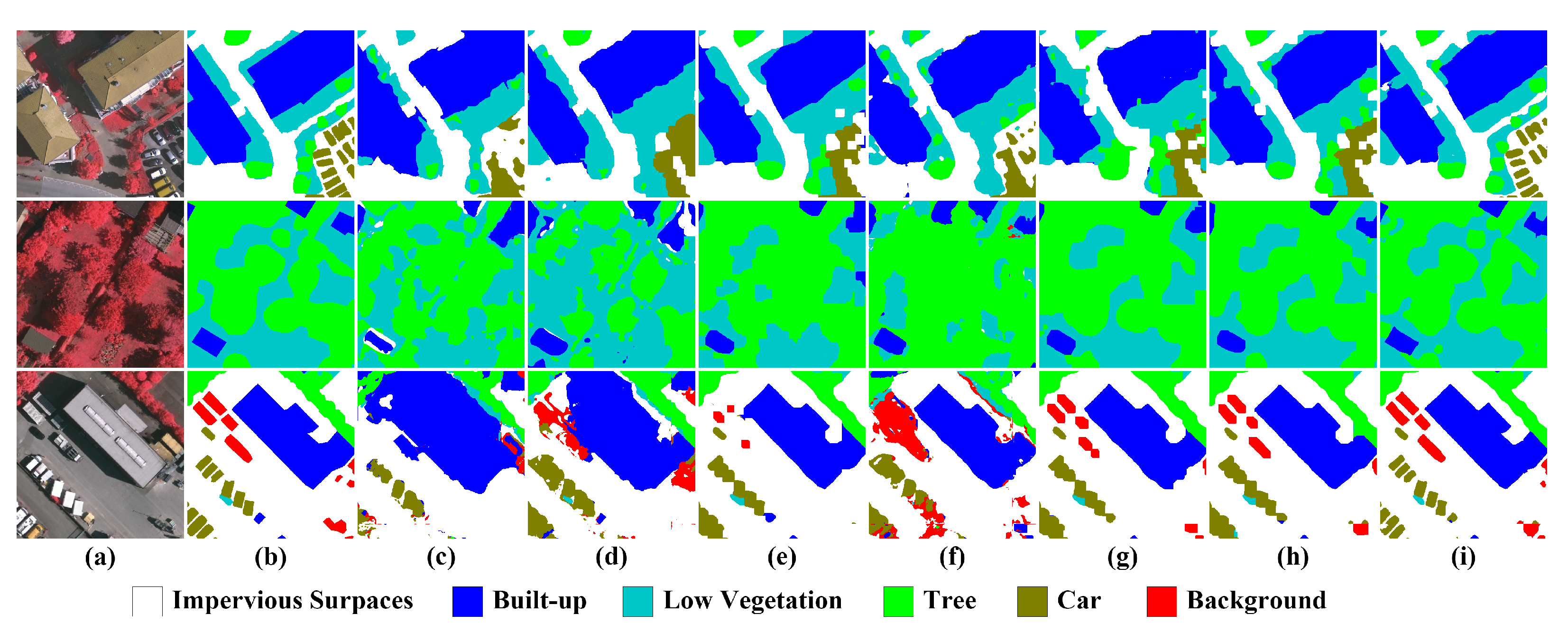
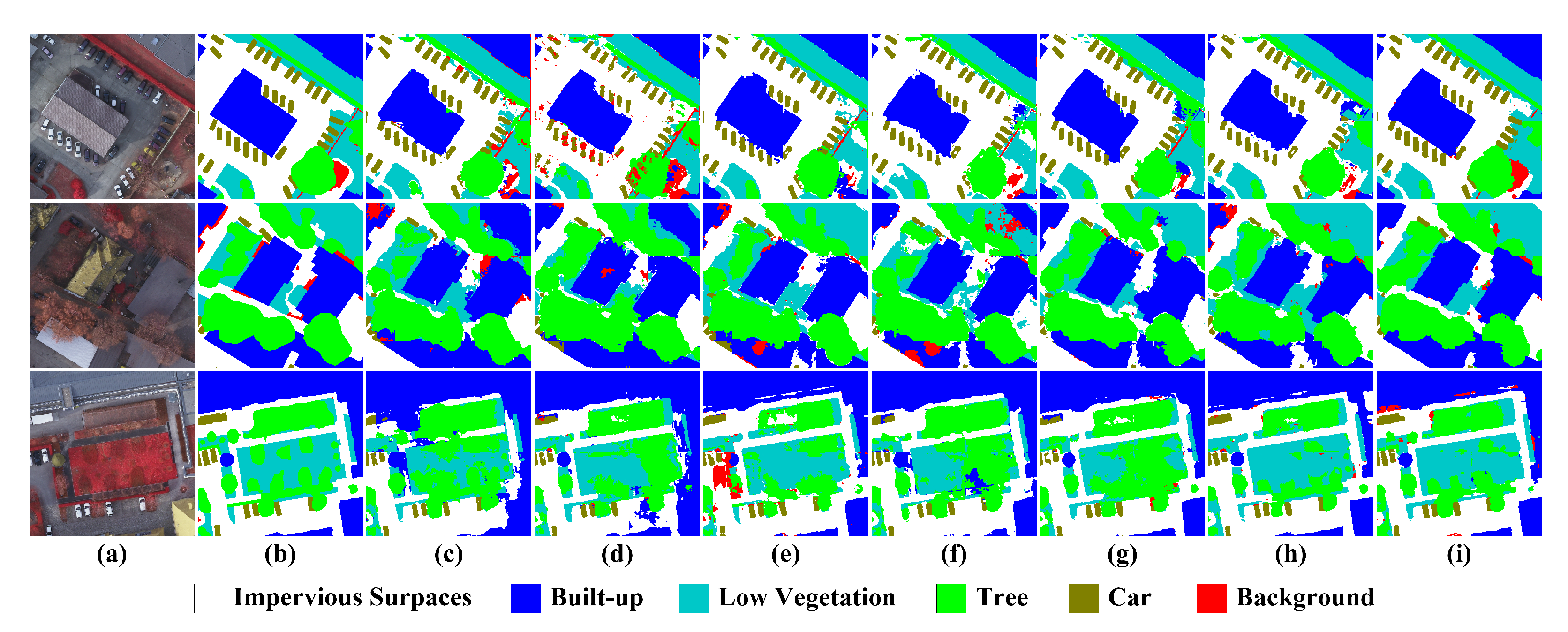
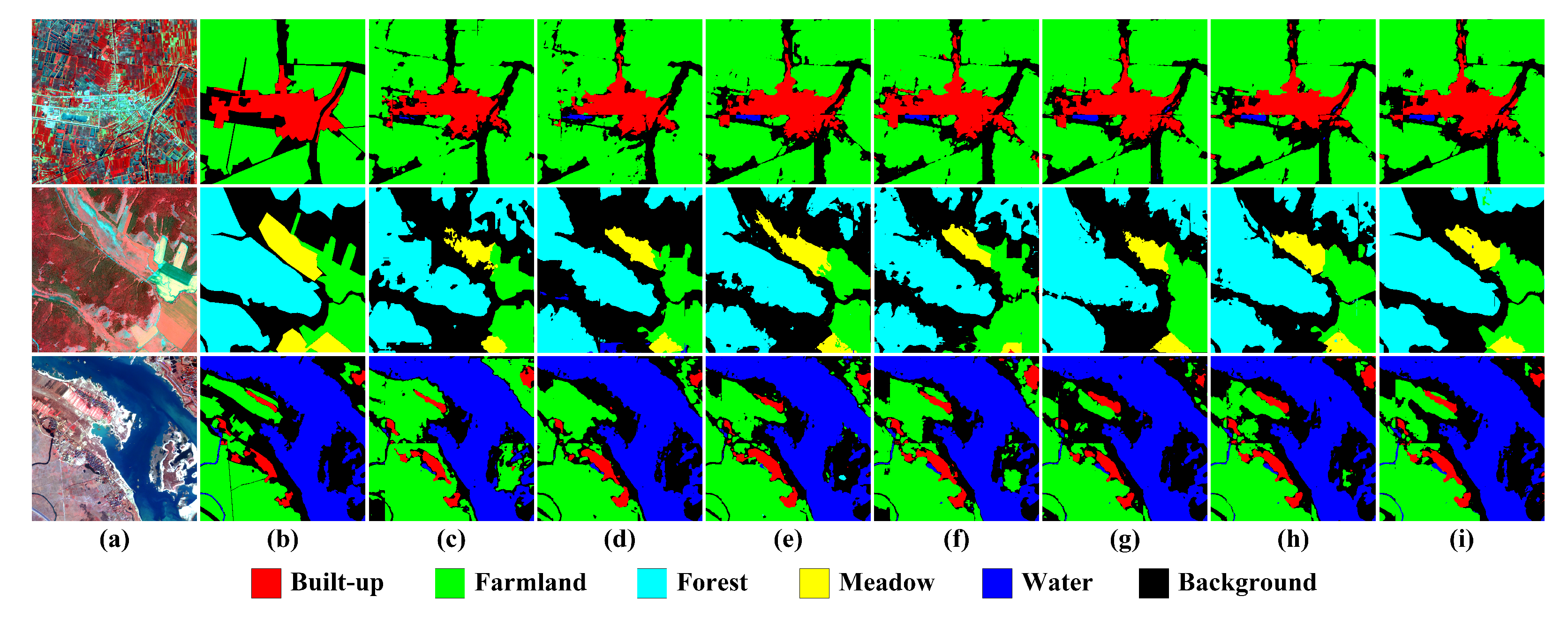
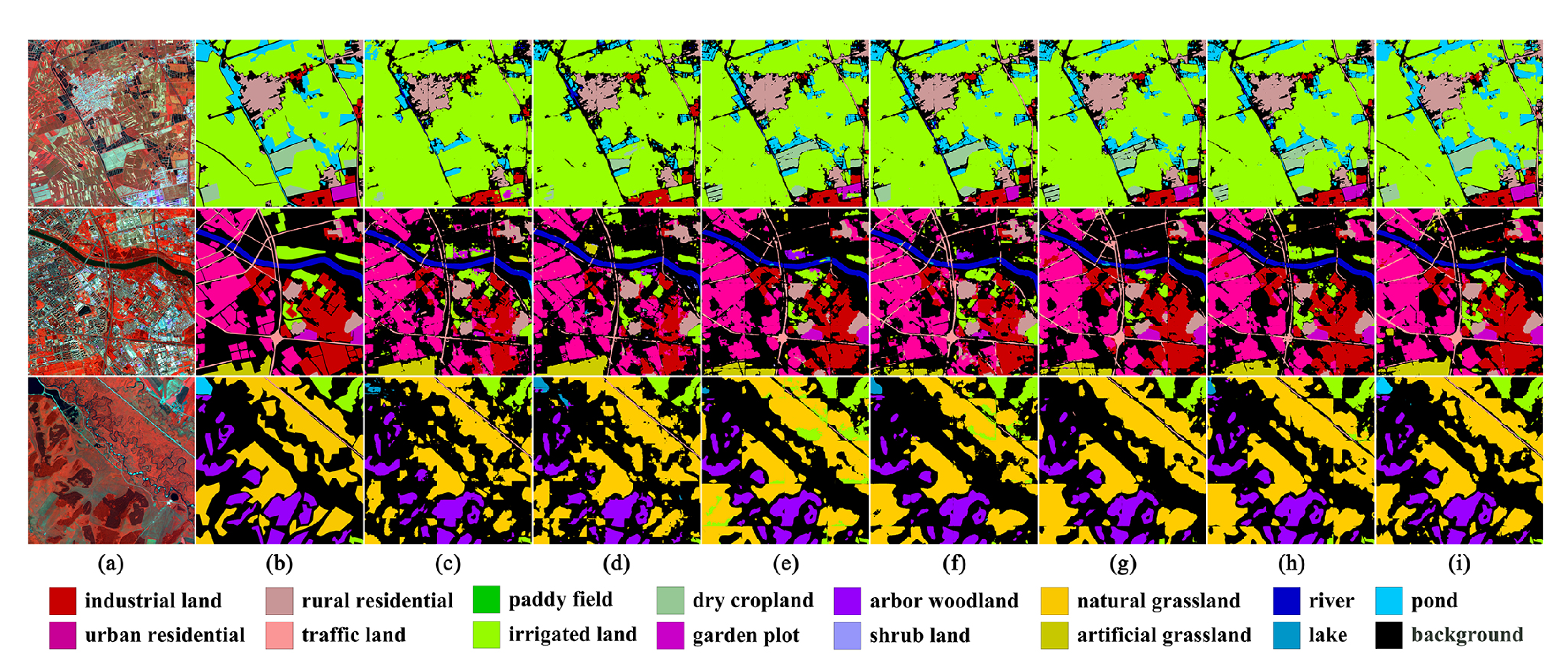
Figure 11,
Figure 12,
Figure 13 and
Figure 14 depict the examples of their segmentation results on the four datasets, and
Table 4,
Table 5,
Table 6 and
Table 7 display their accuracy results on the four datasets. The following will concretely investigate the feature enhancement ability of each attention module through ablation studies, and explore the advantages of ARM over other attention modules via comparison studies.
SE: In spite of a small increment in computational overhead, as shown in
Table 3 and
Figure 10a–c, the use of SE does not involve noticeable gains in the overall accuracy of each dataset and even brings about the negative growth of
on the Vaihingen dataset, as shown in
Figure 10d. Specifically, as shown in
Table 4,
Table 5,
Table 6 and
Table 7, SE outperforms other attention modules on some categories on the FLC dataset, and can also effectively improve the extraction of some large-scale categories and several categories strongly influenced by spectral information on the other dataset, such as Low Vegetation on the Vaihingen and Postdam datasets, as well as Farmland and Forest on the LSC dataset. However, as a whole, its improvement to most categories on each dataset is limited, even leading to obvious decreases in
. The experimental results indicate that the channel descriptors under the global receptive field are too coarse to effectively enhance the feature map from the channel dimension, which to some extent even impairs the class discriminative ability.
NLN: It obtains a significant performance improvement on each dataset, with increases in
ranging from 3.0% to 4.0%, as shown in
Figure 10d, however, the model complexity is only better than that of DANet, as shown in
Table 3 and
Figure 10a–c. NLN models the spatial interdependencies between any two positions in spatial dimensions. The accuracy results of categories with obvious context information are greatly improved, such as Building and Car on the Vaihingen and Postdam datasets, as well as Built-Up on the LSC dataset, as shown in
Table 4,
Table 5 and
Table 6. Furthermore, unlike pooling and convolutional layers, where the receptive fields are fixed and local, NLN can capture spatial information in a more adaptable manner. Consequently, the
of categories with distinct yet irregular boundaries can also obtain significant gains, such as Water on the LSC dataset, as well as
,
and
on the FLC dataset, as shown in
Table 7. However, this way of aggregating spatial context information, which considers the influence of all locations to themselves but disregards channel information, also reduces the inter-class separability between categories with spatial adjacency or semantic similarity to a certain degree, such as Artificial Grassland and Natural Grassland on the FLC dataset. In conclusion, NLN can bring about effective feature enhancement by further encoding spatial dependencies, but given the prohibitive model complexity and the negative impacts on some categories, it still needs additional development.
CBAM: With the similar thinking of SE, per-channel and per-pixel descriptors are aggregated using max and average pooling operations, and then spatial and channel relationships are further modeled with convolutional and FC layers, respectively. However, the performance of CBAM is inferior to that of SE on the three datasets except the Vaihingen dataset, and its
is even lower than that of the baseline on the LSC dataset, as shown in
Figure 10d. We contend that the way of gathering the spatial descriptors may be detrimental to channel enhancement to some extent, hence impairing class discriminative ability. However, there are still great performance gains in some large-scale categories with distinct boundaries, such as Impervious Surfaces and Building on the Vaihingen and Postdam datasets, as shown in
Table 4 and
Table 5. To sum up, despite its enhancement in terms of both spatial and channel dimensions requiring low computational overhead, the performance improvement of CBAM is too limited to be directly employed as the efficient feature enhancement module for remote sensing image segmentation.
DANet: It calculates the pairwise correlations of channels and pixels, respectively, and the three model complexity evaluation criteria are all up to the maximum. However, the
of DANet is superior to that of NLN only on the LSC dataset, as shown in
Figure 10d, and its improvement in some categories with obvious spatial context information is also not as significant as that of NLN, such as Impervious Surfaces and Building on the Vaihingen and Postdam datasets, Built-Up on the LSC dataset, as well as Urban Residential and Rural Residential on the FLC dataset, as shown in
Table 4,
Table 5,
Table 6 and
Table 7. On the other hand, its performance on several categories with a greater reliance on spectral information is still remarkable, even reaching the best values among all attention modules such as Low Vegetation on the Vaihingen dataset, and Shrub Land on the FLC dataset. In summary, although the improvement in the baseline+DANet over the baseline is outstanding, DANet does not show absolute advantages over NLN, neither in terms of overall accuracy nor in the extraction of some categories, as shown in
Figure 10. Meanwhile, taking its huge computational overhead into consideration, it cannot be a viable option for feature enhancement in the real applications of remote sensing.
DANet: It calculates the pairwise correlations of channels and pixels, respectively, and the three model complexity evaluation criteria are all up to the maximum. However, the
of DANet is superior to that of NLN only on the LSC dataset, as shown in
Figure 10d, and its improvement in some categories with obvious spatial context information is also not as significant as that of NLN, such as Impervious Surfaces and Building on the Vaihingen and Postdam datasets, Built-Up on the LSC dataset, as well as Urban Residential and Rural Residential on the FLC dataset, as shown in
Table 4,
Table 5,
Table 6 and
Table 7. On the other hand, its performance on several categories with a greater reliance on spectral information is still remarkable, even reaching the best values among all attention modules such as Low Vegetation on the Vaihingen dataset, and Shrub Land on the FLC dataset. In summary, although the improvement in the baseline+DANet over the baseline is outstanding, DANet does not show absolute advantages over NLN, neither in terms of overall accuracy nor in the extraction of some categories, as shown in
Figure 10. Meanwhile, taking its huge computational overhead into consideration, it cannot be a viable option for feature enhancement in the real applications of remote sensing.
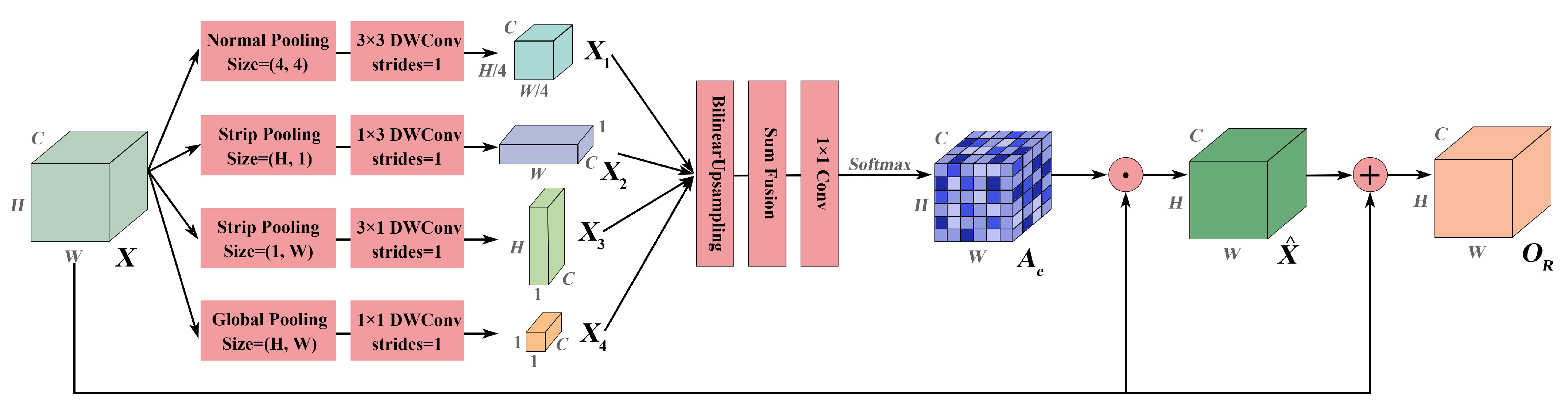
ARM: In lieu of computing the covariance matrix of pixels for the spatial similarity, it employs three types of pooling operations to probe spatial correlations, and also summarizes channel descriptors under different receptive fields in the meantime. In terms of model complexity, as shown in
Table 3 and
Figure 10a–c, the GPU memory usage of ARM is between NLN and DANet, the model parameters almost match those of CBAM, and the computational complexity, i.e.,
, is lower than that of NLN. In terms of model performance, it ameliorates the
of each dataset to the greatest extent, as shown in
Figure 10d. Specifically, different-range spatial dependencies captured by ARM contribute to the extraction of multi-scale and multi-shape categories, as shown in
Table 4,
Table 5,
Table 6 and
Table 7, thus allowing it to perform better than other attention modules on these categories. Moreover, the channel descriptors under different receptive fields can determine channel relationships more precisely and enable a more significant enhancement of semantic and discriminative information. Thus, ARM can also provide the more prominent improvement in some categories greatly influenced by spectral information. Therefore, taking efficiency and effectiveness into account, ARM has noticeable advantages over other state-of-the-art attention modules, and contributes more to the simple yet effective segmentation for remote sensing imagery.
In summary, with the aid of flexible receptive fields provided by three-type pooling operations, our proposed attention module for improving the encoder, namely ARM, can extract outstanding semantic descriptors to generate the element-wise 3D attention map, effectively enhancing a feature map from both spatial and channel dimensions at the same time. The comparison of the baseline and the baseline + ARM reveals that ARM can yield significant performance gains for each category with slight increases in model complexity. Additionally, ARM can also surpass other state-of-the-art attention modules in terms of overall accuracy and the most category extraction, and its model complexity remains competitive among these modules as well. The improvement of the baseline + ARM over the baseline and the advantages of ARM over other attention modules both demonstrate the effectiveness of ARM. Furthermore, as a better compromise between model performance and complexity, ARM is more conducive to fulfilling the high-accuracy and high-efficiency requirements in real-world remote sensing scenarios.
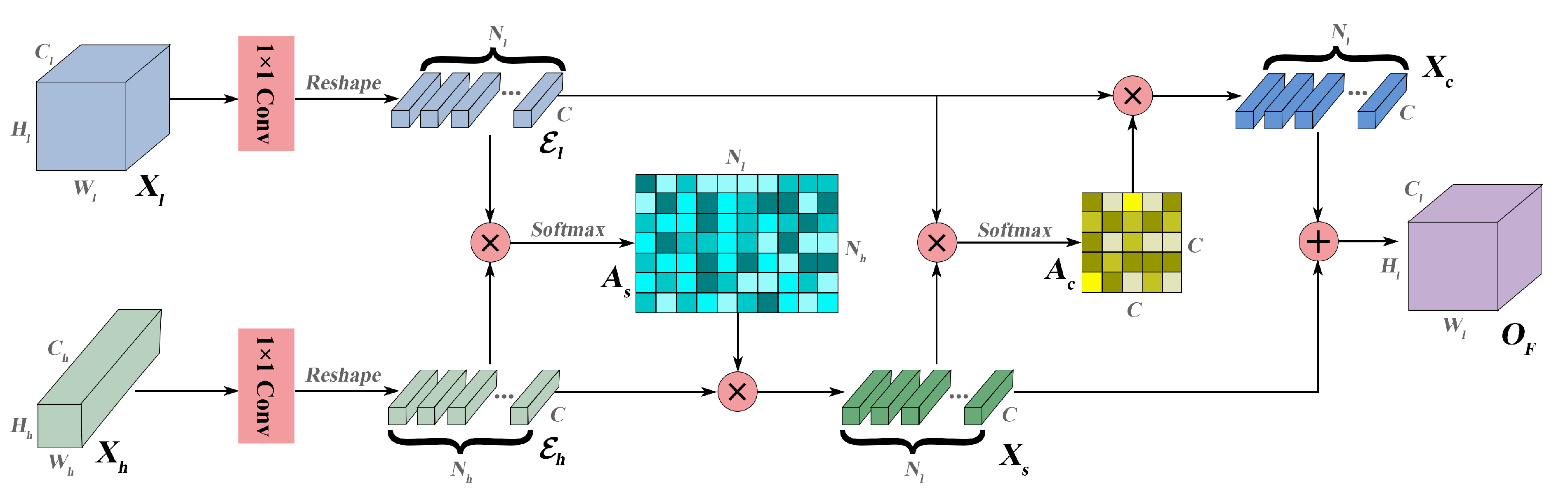
5.2. Effect of AFM
As mentioned in
Section 3.3, AFM achieves the spatial and channel fusion of low-level and high-level features via cross-attention, and the channel- and spatial-fused features are further merged by the addition operation. In this subsection, we not only investigate the effect of AFM by comparing the baseline+ARM with XANet, as shown in
Table 4,
Table 5,
Table 6 and
Table 7 and
Figure 11,
Figure 12,
Figure 13 and
Figure 14, but also explore the specific role of each component in AFM through further ablation studies, as shown in
Table 8. Three fusion modules are additionally implemented. AFM_1 only performs the sum fusion, after unifying the channel numbers of two-level features with two
convolutions and enlarging the spatial size of the high-level feature to that of the low-level feature with a bilinear upsampling operation. AFM_2 and ARM_3 are constructed by removing the channel and spatial attention fusion from AFM, respectively. The following will elaborate on the ability of each fusion module, and analyze the effectiveness and efficiency of AFM.
First of all, in terms of model complexity, as shown in
Table 3 and
Figure 10a–c, compared with the baseline + ARM, although the
of XANet are almost doubled with the addition of AFM, the increases in model size are negligible, and the required computational resources even decline due to its dimension-reduced operations. In general, AFM does not impose a huge computational burden.
Then, we discuss the performance of AFM through the improvement of XANet over the baseline+ARM. Specifically, as shown in
Table 4 and
Table 5, on the Vaihingen and Postdam datasets, some categories that are obviously influenced by spatial context information, such as Building and Car, are improved to a great extent after further feature fusion with AFM. Additionally, Tree on the Postdam dataset with rich texture information also obtains significant performance gains, owing to the detail information highlighted by AFM. On the LSC dataset, as shown in
Table 6, the
of Built-Up increases sharply due to the enhancement of texture and context information from the spatial attention fusion in AFM, and the channel attention fusion, which improves object semantic and discriminative information, further promotes the performance improvement of each category extraction. On the FLC dataset with the finer category system, as shown in
Table 7, AFM also brings great performance growth since the texture and detail information have become pivotal for distinguishing many categories from each other.
At last, the specific role of each component in AFM is explored by further ablation studies, as shown in
Table 8. Intuitively, comparing the baseline + ARM + AFM_1 with the baseline + ARM, AFM_1 without any attention fusion cannot provide significant improvement and even has negative impacts, indicating that the poor fusion strategy may be detrimental to the model performance. AFM_2 only employs the spatial attention fusion for the two-level features, which contributes to restoring the detailed information for pixel-level predictions, and its performance gains are second only to those of AFM on most datasets. Furthermore, benefiting from the enhancement of semantic and discriminative information brought by the channel attention fusion, the improvement of AFM_3 is also noticeable on each dataset, and the performance growth on the LSC dataset even exceeds that of AFM_2, which reveals the importance of performing an effective channel fusion strategy. Furthermore, in general, AFM effectively realizes the complementary advantages of the two-level features, and its improvement on each dataset is much better than that of other fusion modules, which illustrates that spatial and channel fusion are both indispensable, and the combination can yield the superior performance.
In summary, multi-level feature fusion is crucial for fine-grained remote sensing image segmentation, while a poor fusion strategy is susceptible to detrimental effects. The spatial and channel attention fusion in AFM can both bring about good performance gains, where the former improves the class discriminative ability and the latter remedies the spatial information losses. AFM, integrating the advantages of fusion in two aspects, becomes an outstanding strategy for efficient feature fusion, which can make full use of multi-scale information from different-level features for accurate pixel-level predictions without substantially increasing the model complexity.
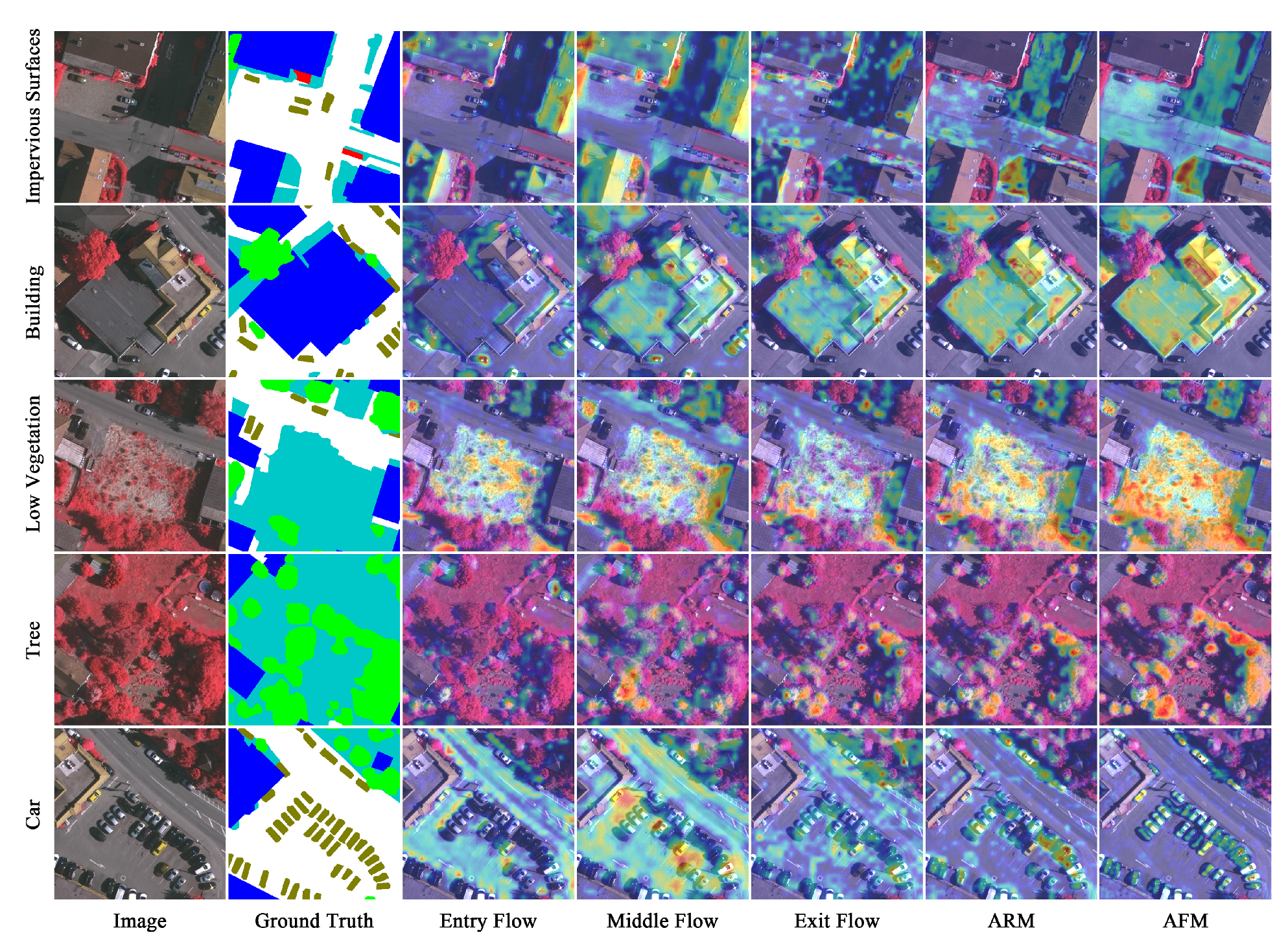
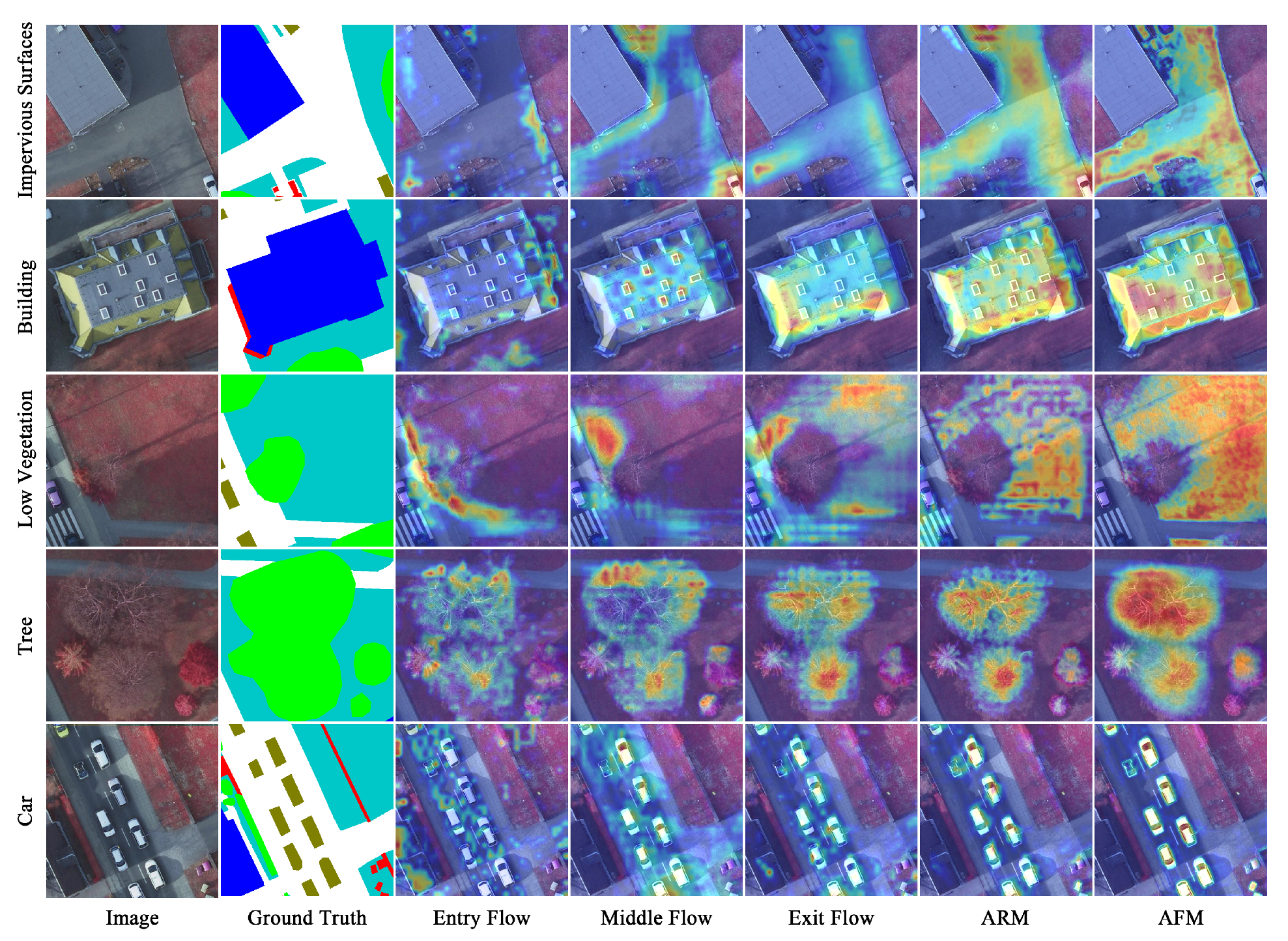
5.3. Model Interpretability
Chollet [
57] divided Xception65 into Entry Flow, Middle Flow and Exit Flow. Consequently, we consider the reasoning process of XANet as five phases, i.e., the three phases from the backbone network, as well as ARM and AFM. In order to figure out the reasoning mode of our hierarchical segmentation model and further intuitively analyze the two proposed attention modules, this section employs the Grad-CAM tool, which can clarify the regions considered important by the current network layer for a certain category in the form of a heat map, to visualize the output feature of each phase with regard to each category on the Vaihingen and Postdam datasets, as shown in
Figure 15 and
Figure 16, respectively.
In the Entry Flow phase, for some categories, the feature is activated on external context information, such as the buildings adjacent to the Impervious Surfaces on the Vaihingen dataset, and the roads where the Car is on the two datasets. For a Building with clear boundaries on the two datasets, some obvious edge information is highlighted as well. Furthermore, for Low Vegetation on the Vaihingen dataset and Tree on the Postdam dataset, a small amount of texture information is also focused to a certain degree. In the Middle Flow and Exit Flow phases, as the network goes deeper, the feature concentrates more on the category itself and less on the background, and the emphasis of each category gradually shifts to the internal texture information. After the enhancement of ARM, the discriminative information of each category is further significantly boosted, the influence of other categories is effectively suppressed, and the recognizable texture information is more abundant. After improvement with AFM, there is the stronger response to each category, and the feature activates itself almost exclusively on each category, especially Car on the two datasets.
Altogether, in the reasoning process of XANet, external spatial position information, edge information and internal texture information are successively extracted with the deepening of the network, and identifiable discriminative information is less-to-more and coarse-to-fine. The improvement of ARM and AFM is also manifestly reflected by the Grad-CAM. Intuitively, ARM can effectively recalibrate the focus on each category, and improve the class discriminative ability of a feature map. AFM further boosts the response to each category and represses the interference from other categories, especially the small-scale category, which is significantly ameliorated.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}