



Combining Object-Oriented and Deep Learning Methods to Estimate Photosynthetic and Non-Photosynthetic Vegetation Cover in the Desert from Unmanned Aerial Vehicle Images with Consideration of Shadows

 ,
,  ,
,  , ,
, ,
Abstract
1. Introduction
- We evaluate the feasibility of object-oriented detection combined with deep learning semantic segmentation for the estimation of desert-area fPV and fNPV from UAV high-spatial-resolution visible light images.
- We compare three deep learning semantic segmentation methods as well as three machine learning algorithms for the estimation of fPV and fNPV, considering shaded feature classification.
- We develop a semiautomatic labeling method based on object-oriented random forest for PV/NPV data preprocessing.
- We apply the results to vegetation monitoring in the same type of area to verify the generalizability of the model.
2. Research Region and Data
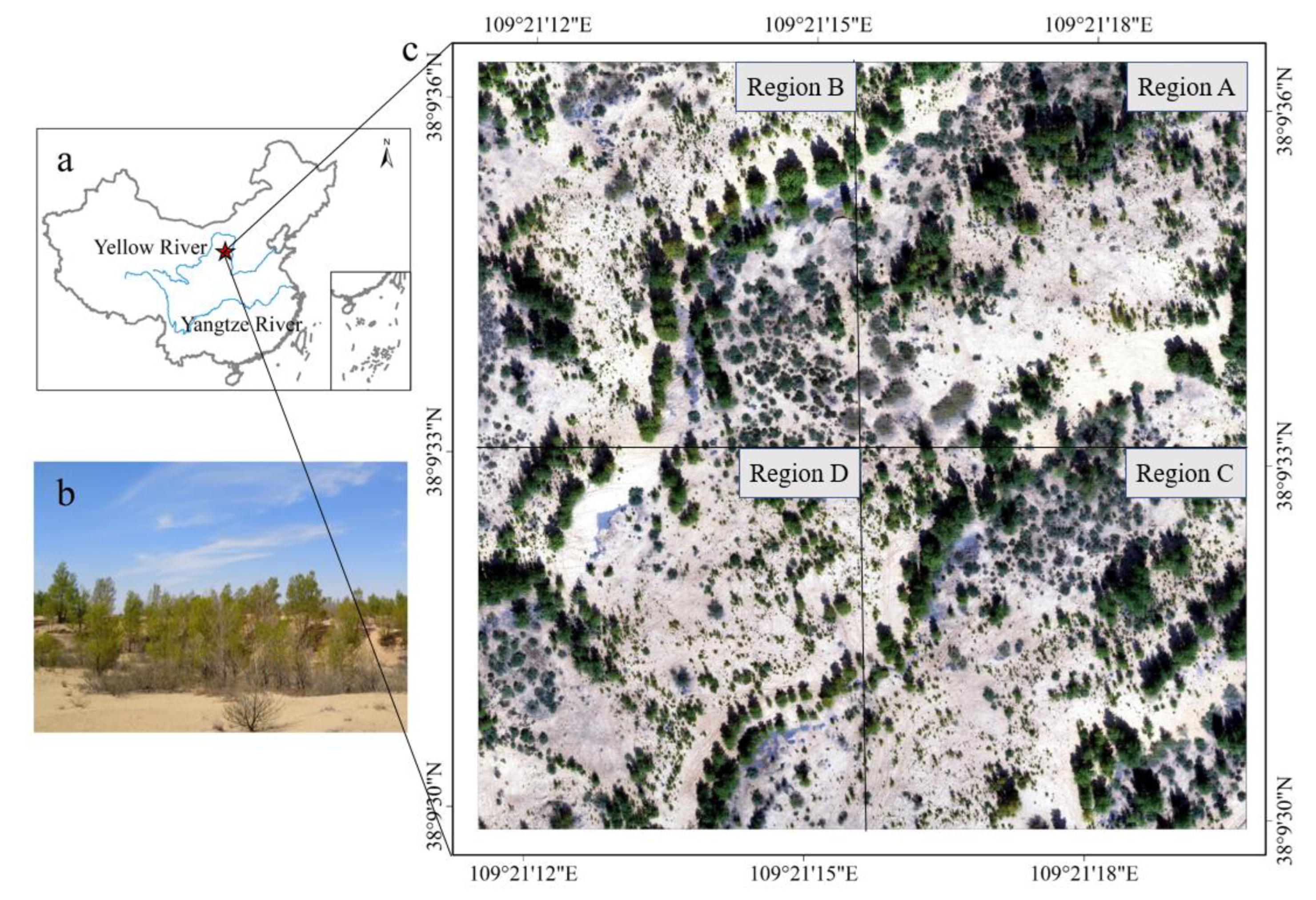
2.1. Study Area
2.2. UAV Image Stitching and Processing
3. Methods
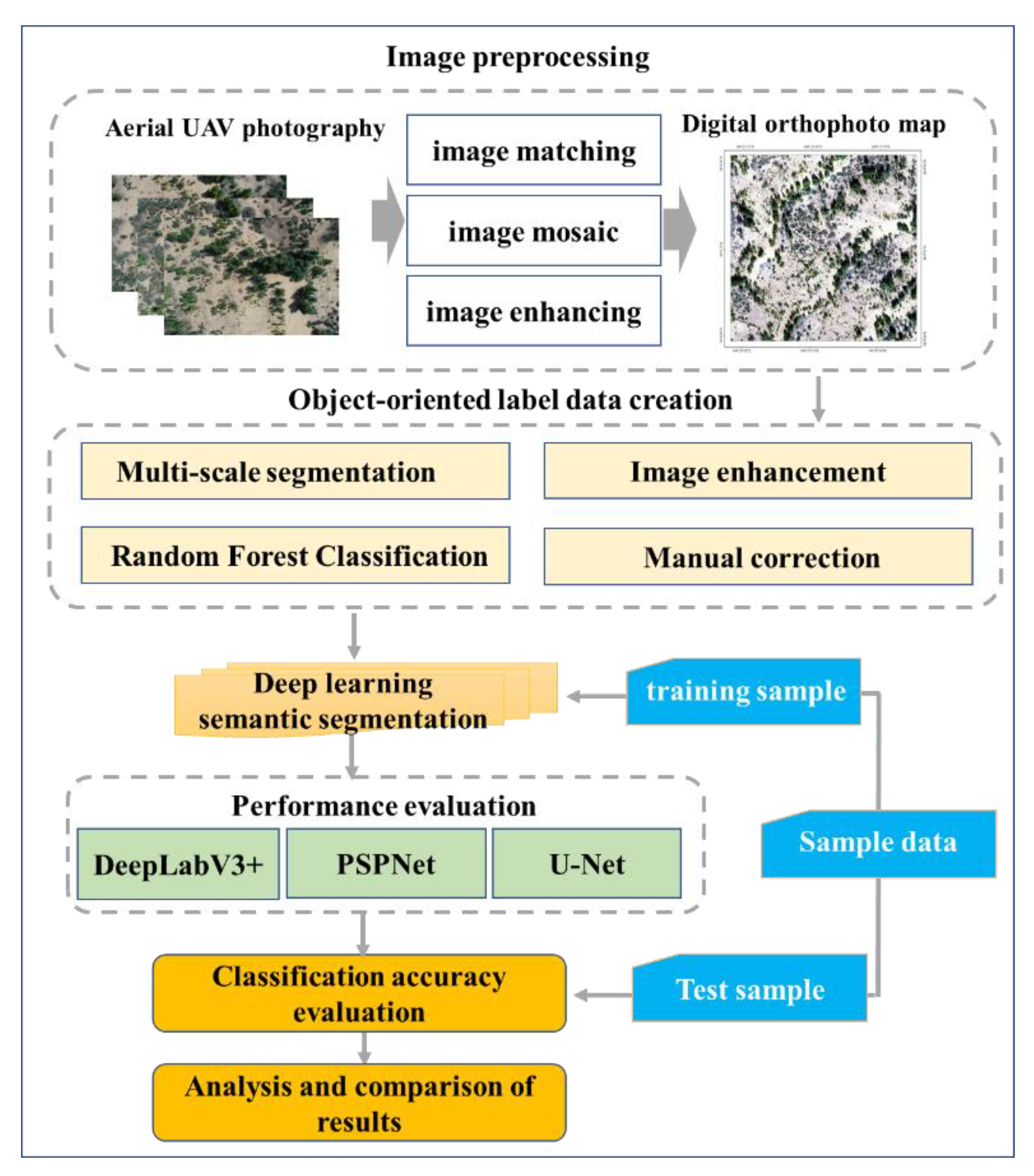
3.1. PV/NPV Estimation Process
3.2. Object-Oriented Label Data Creation
3.2.1. Feature Classification
3.2.2. Multi-Resolution Segmentation
3.2.3. Object-Oriented Random Forest Classification Algorithm
3.2.4. Manual Correction of Classification Results
3.3. Deep Learning Semantic Segmentation Methods
3.3.1. DeepLabV3+
3.3.2. PSPNet
3.3.3. U-Net
3.4. Accuracy Assessment Metrics and Strategies
4. Results
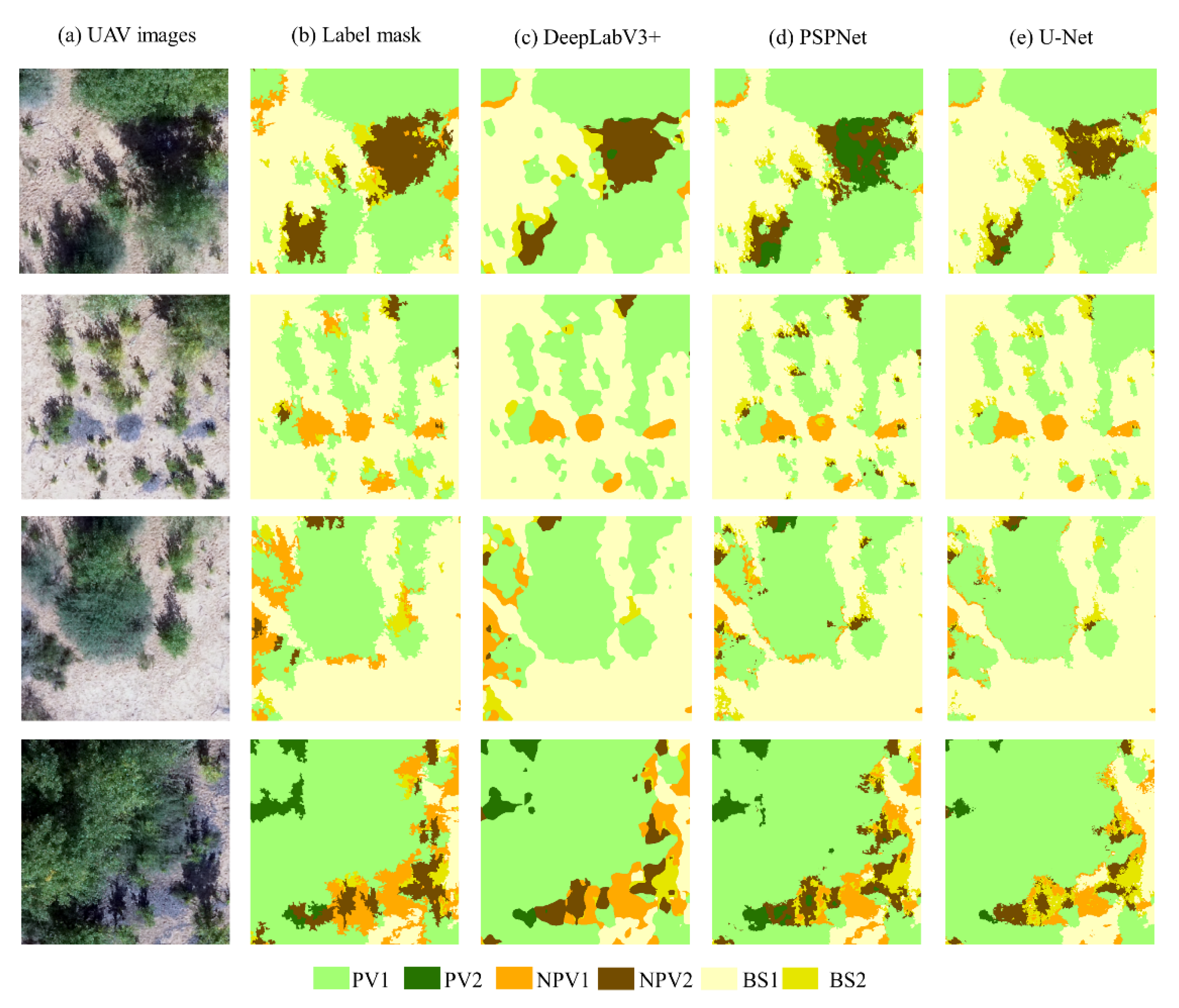
4.1. Comparison of Semantic Segmentation Network Results
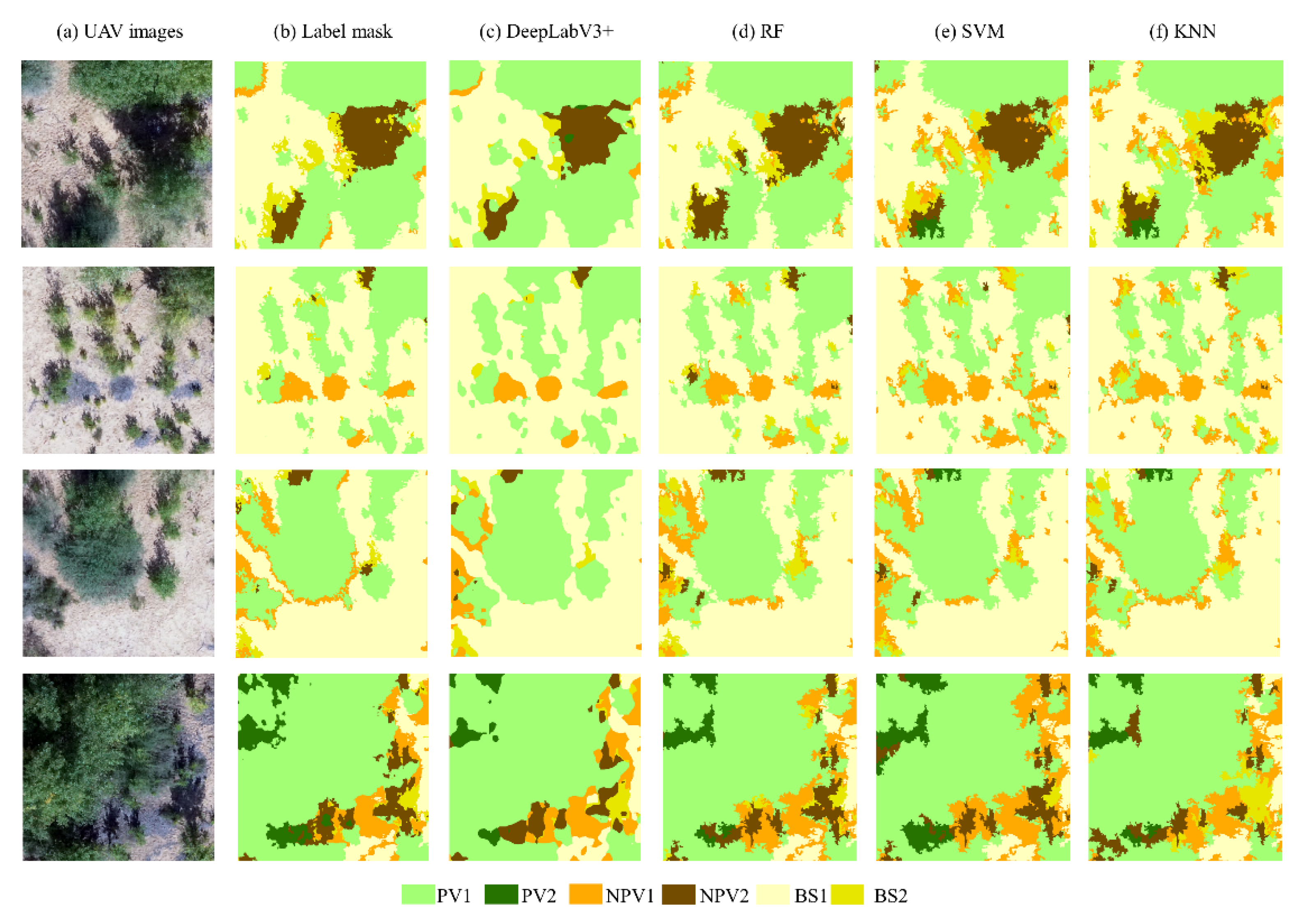
4.2. Comparison of the Results Using Typical Machine Learning Methods
4.3. Model Generalizability Verification
- Regions B, C, and D in September as alternative location sample areas in the same period;
- Area A in July as an alternative period sample region at the same location;
- Regions B, C, and D in July as both alternative location and period sample areas. With these, the classification accuracy was verified to validate the migration capabilities of the DeepLabV3+ model.
5. Discussion
5.1. Classification of Shaded Objects
5.2. Advantages and Disadvantages of Object-Oriented Deep Learning Semantic Segmentation; Its Prospects
6. Conclusions
- The application of deep learning semantic segmentation models combined with object-oriented techniques simplifies the PV–NPV estimation process of UAV visible images without reducing the classification accuracy.
- The accuracy of the DeepLapV3+ model is higher than that of the U-Net and PSPNet models.
- The estimation experiments for different time periods of the same ground class confirm that this method has better generalization ability.
- Compared with three typical machine learning methods, RF, SVM, and KNN, the DeepLabV3+ method can achieve accurate and fast automatic PV–NPV estimation.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Schimel, D.S. Terrestrial biogeochemical cycles: Global estimates with remote sensing. Remote Sens. Environ. 1995, 51, 49–56. [Google Scholar] [CrossRef]
- Feng, Q.; Zhao, W.; Ding, J.; Fang, X.; Zhang, X. Estimation of the cover and management factor based on stratified coverage and remote sensing indices: A case study in the Loess Plateau of China. J. Soils Sediments 2018, 18, 775–790. [Google Scholar] [CrossRef]
- Kim, Y.; Yang, Z.; Cohen, W.B.; Pflugmacher, D.; Lauver, C.L.; Vankat, J.L. Distinguishing between live and dead standing tree biomass on the North Rim of Grand Canyon National Park, USA using small-footprint lidar data. Remote. Sens. Environ. 2009, 113, 2499–2510. [Google Scholar] [CrossRef]
- Newnham, G.J.; Verbesselt, J.; Grant, I.F.; Anderson, S.A. Relative Greenness Index for assessing curing of grassland fuel. Remote Sens. Environ. 2011, 115, 1456–1463. [Google Scholar] [CrossRef]
- Ouyang, D.; Yuan, N.; Sheu, L.; Lau, G.; Chen, C.; Lai, C.J. Community Health Education at Student-Run Clinics Leads to Sustained Improvement in Patients’ Hepatitis B Knowledge. J. Community Health 2012, 38, 471–479. [Google Scholar] [CrossRef]
- Guan, K.; Wood, E.; Caylor, K. Multi-sensor derivation of regional vegetation fractional cover in Africa. Remote Sens. Environ. 2012, 124, 653–665. [Google Scholar] [CrossRef]
- Okin, G.S.; Clarke, K.D.; Lewis, M.M. Comparison of methods for estimation of absolute vegetation and soil fractional cover using MODIS normalized BRDF-adjusted reflectance data. Remote Sens. Environ. 2013, 130, 266–279. [Google Scholar] [CrossRef]
- Yao, H.; Qin, R.; Chen, X. Unmanned Aerial Vehicle for Remote Sensing Applications—A Review. Remote. Sens. 2019, 11, 1443. [Google Scholar] [CrossRef]
- Vivar-Vivar, E.D.; Pompa-García, M.; Martínez-Rivas, J.A.; Mora-Tembre, L.A. UAV-Based Characterization of Tree-Attributes and Multispectral Indices in an Uneven-Aged Mixed Conifer-Broadleaf Forest. Remote Sens. 2022, 14, 2775. [Google Scholar] [CrossRef]
- Zheng, C.; Abd-Elrahman, A.; Whitaker, V.; Dalid, C. Prediction of Strawberry Dry Biomass from UAV Multispectral Imagery Using Multiple Machine Learning Methods. Remote Sens. 2022, 14, 4511. [Google Scholar] [CrossRef]
- Fu, B.; Liu, M.; He, H.; Lan, F.; He, X.; Liu, L.; Huang, L.; Fan, D.; Zhao, M.; Jia, Z. Comparison of optimized object-based RF-DT algorithm and SegNet algorithm for classifying Karst wetland vegetation communities using ultra-high spatial resolution UAV data. Int. J. Appl. Earth Obs. Geoinf. ITC J. 2021, 104, 102553. [Google Scholar] [CrossRef]
- Xie, L.; Meng, X.; Zhao, X.; Fu, L.; Sharma, R.P.; Sun, H. Estimating Fractional Vegetation Cover Changes in Desert Regions Using RGB Data. Remote Sens. 2022, 14, 3833. [Google Scholar] [CrossRef]
- Zhang, Y.; Ta, N.; Guo, S.; Chen, Q.; Zhao, L.; Li, F.; Chang, Q. Combining Spectral and Textural Information from UAV RGB Images for Leaf Area Index Monitoring in Kiwifruit Orchard. Remote. Sens. 2022, 14, 1063. [Google Scholar] [CrossRef]
- Sa, I.; Popović, M.; Khanna, R.; Chen, Z.; Lottes, P.; Liebisch, F.; Nieto, J.; Stachniss, C.; Walter, A.; Siegwart, R. WeedMap: A Large-Scale Semantic Weed Mapping Framework Using Aerial Multispectral Imaging and Deep Neural Network for Precision Farming. Remote Sens. 2018, 10, 1423. [Google Scholar] [CrossRef]
- Wan, L.; Zhu, J.; Du, X.; Zhang, J.; Han, X.; Zhou, W.; Li, X.; Liu, J.; Liang, F.; He, Y.; et al. A model for phenotyping crop fractional vegetation cover using imagery from unmanned aerial vehicles. J. Exp. Bot. 2021, 72, 4691–4707. [Google Scholar] [CrossRef] [PubMed]
- Mishra, N.B.; Crews, K.A. Mapping vegetation morphology types in a dry savanna ecosystem: Integrating hierarchical object-based image analysis with Random Forest. Int. J. Remote. Sens. 2014, 35, 1175–1198. [Google Scholar] [CrossRef]
- Harris, J.; Grunsky, E. Predictive lithological mapping of Canada’s North using Random Forest classification applied to geophysical and geochemical data. Comput. Geosci. 2015, 80, 9–25. [Google Scholar] [CrossRef]
- Petropoulos, G.P.; Kalaitzidis, C.; Vadrevu, K.P. Support vector machines and object-based classification for obtaining land-use/cover cartography from Hyperion hyperspectral imagery. Comput. Geosci. 2012, 41, 99–107. [Google Scholar] [CrossRef]
- Weinberger, K.Q.; Saul, L.K. Distance Metric Learning for Large Margin Nearest Neighbor Classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Feng, Q.; Liu, J.; Gong, J. UAV Remote Sensing for Urban Vegetation Mapping Using Random Forest and Texture Analysis. Remote Sens. 2015, 7, 1074–1094. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote. Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Hasan, A.S.M.M.; Sohel, F.; Diepeveen, D.; Laga, H.; Jones, M.G. A survey of deep learning techniques for weed detection from images. Comput. Electron. Agric. 2021, 184, 106067. [Google Scholar] [CrossRef]
- Barbedo, J.G.A. Plant disease identification from individual lesions and spots using deep learning. Biosyst. Eng. 2019, 180, 96–107. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning—Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Zhong, Y.; Hu, X.; Luo, C.; Wang, X.; Zhao, J.; Zhang, L. WHU-Hi: UAV-borne hyperspectral with high spatial resolution (H2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF. Remote. Sens. Environ. 2020, 250, 112012. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Fang, H.; Lafarge, F. Pyramid scene parsing network in 3D: Improving semantic segmentation of point clouds with multi-scale contextual information. ISPRS J. Photogramm. Remote. Sens. 2019, 154, 246–258. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Liu, C.; Chen, L.-C.; Schroff, F.; Adam, H.; Hua, W.; Yuille, A.L.; Fei-Fei, L. Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 18 June 2019; pp. 82–92. [Google Scholar] [CrossRef]
- Fricker, G.A.; Ventura, J.D.; Wolf, J.A.; North, M.P.; Davis, F.W.; Franklin, J. A Convolutional Neural Network Classifier Identifies Tree Species in Mixed-Conifer Forest from Hyperspectral Imagery. Remote. Sens. 2019, 11, 2326. [Google Scholar] [CrossRef]
- Wagner, F.H.; Sanchez, A.; Tarabalka, Y.; Lotte, R.G.; Ferreira, M.P.; Aidar, M.P.; Gloor, E.; Phillips, O.L.; Aragao, L.E. Using the U-net convolutional network to map forest types and disturbance in the Atlantic rainforest with very high resolution images. Remote Sens. Ecol. Conserv. 2019, 5, 360–375. [Google Scholar] [CrossRef]
- Zhou, K.; Deng, X.; Yao, X.; Tian, Y.; Cao, W.; Zhu, Y.; Ustin, S.L.; Cheng, T. Assessing the Spectral Properties of Sunlit and Shaded Components in Rice Canopies with Near-Ground Imaging Spectroscopy Data. Sensors 2017, 17, 578. [Google Scholar] [CrossRef] [PubMed]
- Ji, C.C.; Jia, Y.H.; Li, X.S.; Wang, J.Y. Wang. Research on linear and nonlinear spectral mixture models for estimating vegetation frac-tional cover of nitraria bushes. Natl. Remote Sens. Bull. 2016, 20, 1402–1412. [Google Scholar] [CrossRef]
- Guo, J.H.; Tian, Q.J.; Wu, Y.Z. Study on Multispectral Detecting Shadow Areas and A Theoretical Model of Removing Shadows from Remote Sensing Images. Natl. Remote Sens. Bulletin. 2006, 151–159. [Google Scholar] [CrossRef]
- Jiao, J.N.; Shi, J.; Tian, Q.J.; Gao, L.; Xu, N.X. Research on multispectral-image-based NDVl shadow-effect-eliminating model. Natl. Remote Sens. Bulletin. 2020, 24, 53–66. [Google Scholar] [CrossRef]
- Lin, M.; Hou, L.; Qi, Z.; Wan, L. Impacts of climate change and human activities on vegetation NDVI in China’s Mu Us Sandy Land during 2000–2019. Ecol. Indic. 2022, 142, 109164. [Google Scholar] [CrossRef]
- Zheng, Y.; Dong, L.; Xia, Q.; Liang, C.; Wang, L.; Shao, Y. Effects of revegetation on climate in the Mu Us Sandy Land of China. Sci. Total Environ. 2020, 739, 139958. [Google Scholar] [CrossRef]
- Lü, D.; Liu, B.Y.; He, L.; Zhang, X.P.; Cheng, Z.; He, J. Sentinel-2A data-derived estimation of photosynthetic and non-photosynthetic vegetation cover over the loess plateau. China Environ. Sci. 2022, 42, 4323–4332. [Google Scholar] [CrossRef]
- Deng, H.; Shu, S.G.; Song, Y.Q.; Xing, F.L. Changes in the southern boundary of the distribution of drifting sand in the Mawusu Sands since the Ming Dynasty. Chin. Sci. Bull. 2007, 21, 2556–2563. [Google Scholar] [CrossRef]
- De Sá, N.C.; Castro, P.; Carvalho, S.; Marchante, E.; López-Núñez, F.A.; Marchante, H. Mapping the Flowering of an Invasive Plant Using Unmanned Aerial Vehicles: Is There Potential for Biocontrol Monitoring? Front. Plant Sci. 2018, 9, 293. [Google Scholar] [CrossRef]
- Ishida, T.; Kurihara, J.; Viray, F.A.; Namuco, S.B.; Paringit, E.C.; Perez, G.J.; Takahashi, Y.; Marciano, J.J. A novel approach for vegetation classification using UAV-based hyperspectral imaging. Comput. Electron. Agric. 2018, 144, 80–85. [Google Scholar] [CrossRef]
- Yang, M.-D.; Tseng, H.-H.; Hsu, Y.-C.; Tsai, H.P. Semantic Segmentation Using Deep Learning with Vegetation Indices for Rice Lodging Identification in Multi-date UAV Visible Images. Remote Sens. 2020, 12, 633. [Google Scholar] [CrossRef]
- Wang, H.; Han, D.; Mu, Y.; Jiang, L.; Yao, X.; Bai, Y.; Lu, Q.; Wang, F. Landscape-level vegetation classification and fractional woody and herbaceous vegetation cover estimation over the dryland ecosystems by unmanned aerial vehicle platform. Agric. For. Meteorol. 2019, 278, 107665. [Google Scholar] [CrossRef]
- Yue, J.; Tian, Q. Estimating fractional cover of crop, crop residue, and soil in cropland using broadband remote sensing data and machine learning. Int. J. Appl. Earth Obs. Geoinf. ITC J. 2020, 89, 102089. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Martins, V.S.; Kaleita, A.L.; Gelder, B.K. Digital mapping of structural conservation practices in the Midwest U.S. croplands: Implementation and preliminary analysis. Sci. Total Environ. 2021, 772, 145191. [Google Scholar] [CrossRef]
- Ayhan, B.; Kwan, C. Tree, Shrub, and Grass Classification Using Only RGB Images. Remote. Sens. 2020, 12, 1333. [Google Scholar] [CrossRef]
- Yang, Q.; Shi, L.; Han, J.; Zha, Y.; Zhu, P. Deep convolutional neural networks for rice grain yield estimation at the ripening stage using UAV-based remotely sensed images. Field Crop. Res. 2019, 235, 142–153. [Google Scholar] [CrossRef]
- Egli, S.; Höpke, M. CNN-Based Tree Species Classification Using High Resolution RGB Image Data from Automated UAV Observations. Remote Sens. 2020, 12, 3892. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Basic Parameters |
|---|---|
| Flight height/m | 50 |
| Flight elevation/m | 1200 |
| Flight speed/(m/s) | 1.2 |
| Camera angle/° | −90 |
| Heading overlap/% | 80 |
| Parallel overlap/% | 80 |
| Flight duration/min | 15 |
| Image Resolution/m | 0.015 |
| Number of aerial images | 350 |
| Aerial survey area/m2 | 40,000 |
| Classification Category | DeepLabV3+ | PSPNet | U-Net | |||
|---|---|---|---|---|---|---|
| Producer Accuracy | User Accuracy | Producer Accuracy | User Accuracy | Producer Accuracy | User Accuracy | |
| PV1 | 95.2 | 92.6 | 94.8 | 94.1 | 94.8 | 89.1 |
| PV2 | 60.0 | 92.3 | 72.5 | 70.7 | 32.5 | 81.3 |
| NPV1 | 78.3 | 82.3 | 61.4 | 87.9 | 53.0 | 89.8 |
| NPV2 | 64.5 | 66.7 | 58.0 | 39.1 | 61.3 | 44.2 |
| BS1 | 98.7 | 96.1 | 98.8 | 95.5 | 99.2 | 91.6 |
| BS2 | 78.2 | 80.3 | 66.7 | 77.6 | 71.8 | 86.2 |
| Overall accuracy (%) | 91.9 | 89.9 | 88.3 | |||
| Kappa coefficient | 0.87 | 0.84 | 0.81 | |||
| Classification Category | DeepLabV3+ | RF | SVM | KNN | ||||
|---|---|---|---|---|---|---|---|---|
| Producer Accuracy | User Accuracy | Producer Accuracy | User Accuracy | Producer Accuracy | User Accuracy | Producer Accuracy | User Accuracy | |
| PV1 | 95.2 | 92.6 | 93.2 | 97.1 | 93.6 | 93.2 | 90.8 | 93.1 |
| PV2 | 60.0 | 92.3 | 72.5 | 85.9 | 72.5 | 93.5 | 52.5 | 95.5 |
| NPV1 | 78.3 | 82.3 | 73.5 | 81.3 | 74.7 | 64.5 | 63.9 | 65.4 |
| NPV2 | 64.5 | 66.7 | 64.5 | 48.8 | 58.1 | 58.0 | 58.1 | 47.4 |
| BS1 | 98.7 | 96.1 | 99.0 | 95.3 | 96.7 | 97.2 | 98.1 | 94.4 |
| BS2 | 78.2 | 80.3 | 61.5 | 66.7 | 75.6 | 77.6 | 62.8 | 64.5 |
| Overall accuracy (%) | 91.9 | 90.4 | 90.3 | 87.7 | ||||
| Kappa coefficient | 0.87 | 0.85 | 0.85 | 0.81 | ||||
| Classification Category | DeepLabV3+ | PSPNet | U-Net | RF | SVM | KNN | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Producer Accuracy | User Accuracy | Producer Accuracy | User Accuracy | Producer Accuracy | User Accuracy | Producer Accuracy | User Accuracy | Producer Accuracy | User Accuracy | Producer Accuracy | User Accuracy | |
| PV | 93.8 | 96.1 | 93.8 | 92.9 | 92.4 | 95.1 | 91.8 | 97.1 | 92.1 | 94.7 | 86.2 | 94.0 |
| NPV | 78.1 | 81.7 | 64.0 | 70.2 | 60.5 | 75.0 | 71.1 | 69.8 | 72.8 | 65.3 | 63.1 | 60.5 |
| BS | 97.7 | 95.7 | 95.9 | 94.9 | 97.9 | 93.3 | 96.1 | 93.9 | 94.9 | 95.7 | 94.9 | 92.0 |
| Overall accuracy (%) | 94.3 | 91.7 | 92.1 | 92.0 | 91.6 | 88.8 | ||||||
| Kappa coefficient | 0.90 | 0.85 | 0.85 | 0.85 | 0.85 | 0.79 | ||||||
| Date | Type | Region A | Region B | Region C | Region D | ||||
|---|---|---|---|---|---|---|---|---|---|
| Producer Accuracy | User Accuracy | Producer Accuracy | User Accuracy | Producer Accuracy | User Accuracy | Producer Accuracy | User Accuracy | ||
| September | PV | 93.8 | 96.1 | 99.06 | 94.9 | 91.4 | 98.6 | 98.7 | 95.8 |
| NPV | 78.1 | 81.7 | 79.79 | 92.0 | 78.3 | 75.5 | 77.9 | 79.8 | |
| BS | 97.7 | 95.7 | 97.57 | 95.4 | 98.3 | 95.4 | 97.2 | 98.4 | |
| Overall accuracy (%) | 94.3 | 94.7 | 94.1 | 95.9 | |||||
| Kappa coefficient | 0.9 | 0.91 | 0.89 | 0.92 | |||||
| July | PV | 92.8 | 96.2 | 93.5 | 96.5 | 90.3 | 97.2 | 94.2 | 96.4 |
| NPV | 66.7 | 81.7 | 68.3 | 72.7 | 72.0 | 76.6 | 68.3 | 83.6 | |
| BS | 98.9 | 94.7 | 98.2 | 96.0 | 98.7 | 94.5 | 98.7 | 95.2 | |
| Overall accuracy (%) | 94.2 | 94.3 | 93.9 | 94.8 | |||||
| Kappa coefficient | 0.89 | 0.89 | 0.88 | 0.90 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Lyu, D.; He, L.; Zhang, Y.; Xu, X.; Yi, H.; Tian, Q.; Liu, B.; Zhang, X. Combining Object-Oriented and Deep Learning Methods to Estimate Photosynthetic and Non-Photosynthetic Vegetation Cover in the Desert from Unmanned Aerial Vehicle Images with Consideration of Shadows. Remote Sens. 2023, 15, 105. https://doi.org/10.3390/rs15010105
He J, Lyu D, He L, Zhang Y, Xu X, Yi H, Tian Q, Liu B, Zhang X. Combining Object-Oriented and Deep Learning Methods to Estimate Photosynthetic and Non-Photosynthetic Vegetation Cover in the Desert from Unmanned Aerial Vehicle Images with Consideration of Shadows. Remote Sensing. 2023; 15(1):105. https://doi.org/10.3390/rs15010105
Chicago/Turabian StyleHe, Jie, Du Lyu, Liang He, Yujie Zhang, Xiaoming Xu, Haijie Yi, Qilong Tian, Baoyuan Liu, and Xiaoping Zhang. 2023. "Combining Object-Oriented and Deep Learning Methods to Estimate Photosynthetic and Non-Photosynthetic Vegetation Cover in the Desert from Unmanned Aerial Vehicle Images with Consideration of Shadows" Remote Sensing 15, no. 1: 105. https://doi.org/10.3390/rs15010105
APA StyleHe, J., Lyu, D., He, L., Zhang, Y., Xu, X., Yi, H., Tian, Q., Liu, B., & Zhang, X. (2023). Combining Object-Oriented and Deep Learning Methods to Estimate Photosynthetic and Non-Photosynthetic Vegetation Cover in the Desert from Unmanned Aerial Vehicle Images with Consideration of Shadows. Remote Sensing, 15(1), 105. https://doi.org/10.3390/rs15010105