
Extraction of Agricultural Fields via DASFNet with Dual Attention Mechanism and Multi-scale Feature Fusion in South Xinjiang, China




Abstract
:
1. Introduction
- (1)
- The establishment of an agricultural field dataset from GF-2 images;
- (2)
- The introduction of a novel deep learning model DASFNet with an improved dual attention mechanism and modified multi-scale feature fusion module;
- (3)
- The high performance of DASFNet in agricultural field extraction compared with other contrastive modules and models in comparative experiments.
2. Materials and Methods
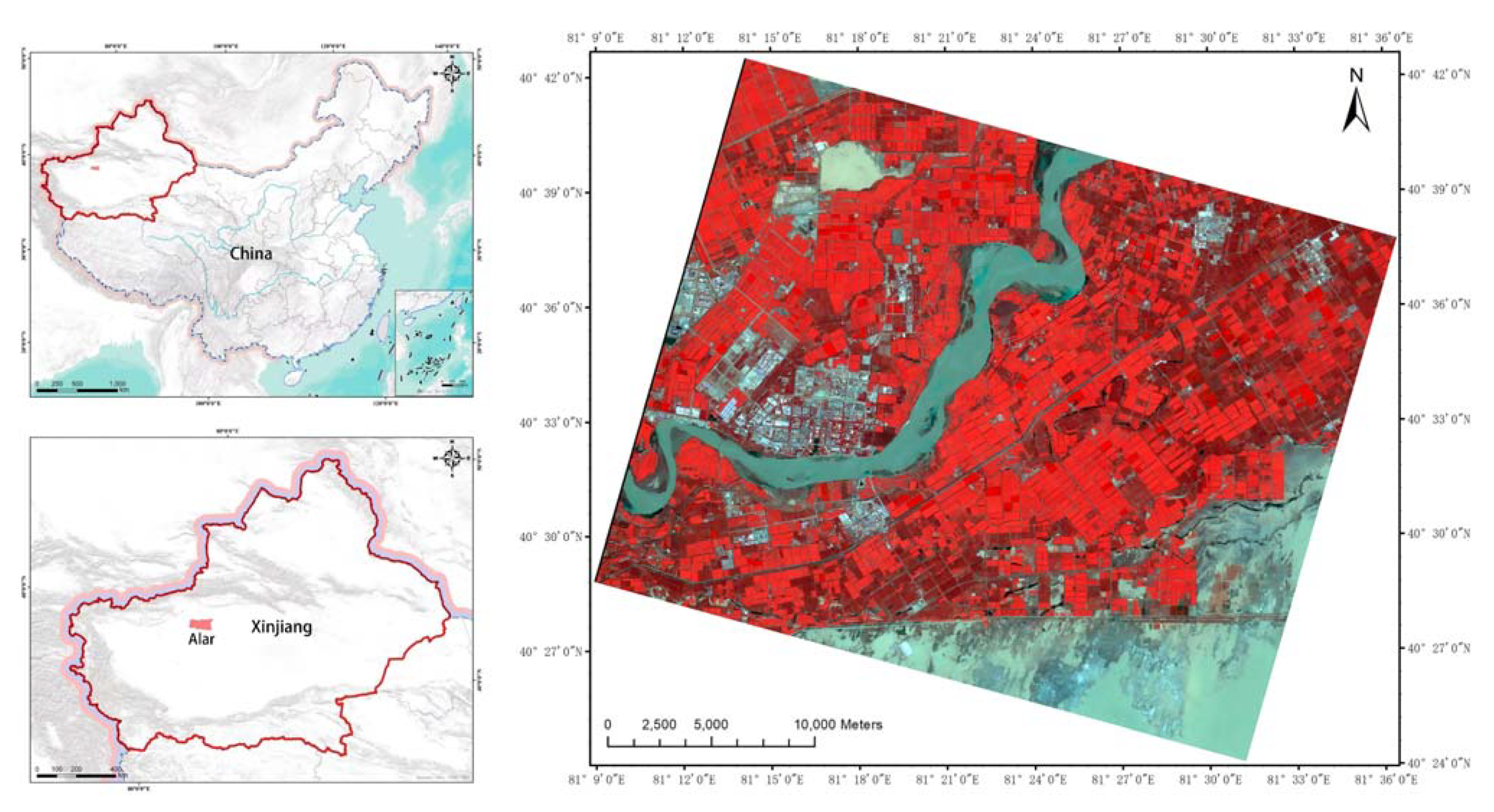
2.1. Study Area
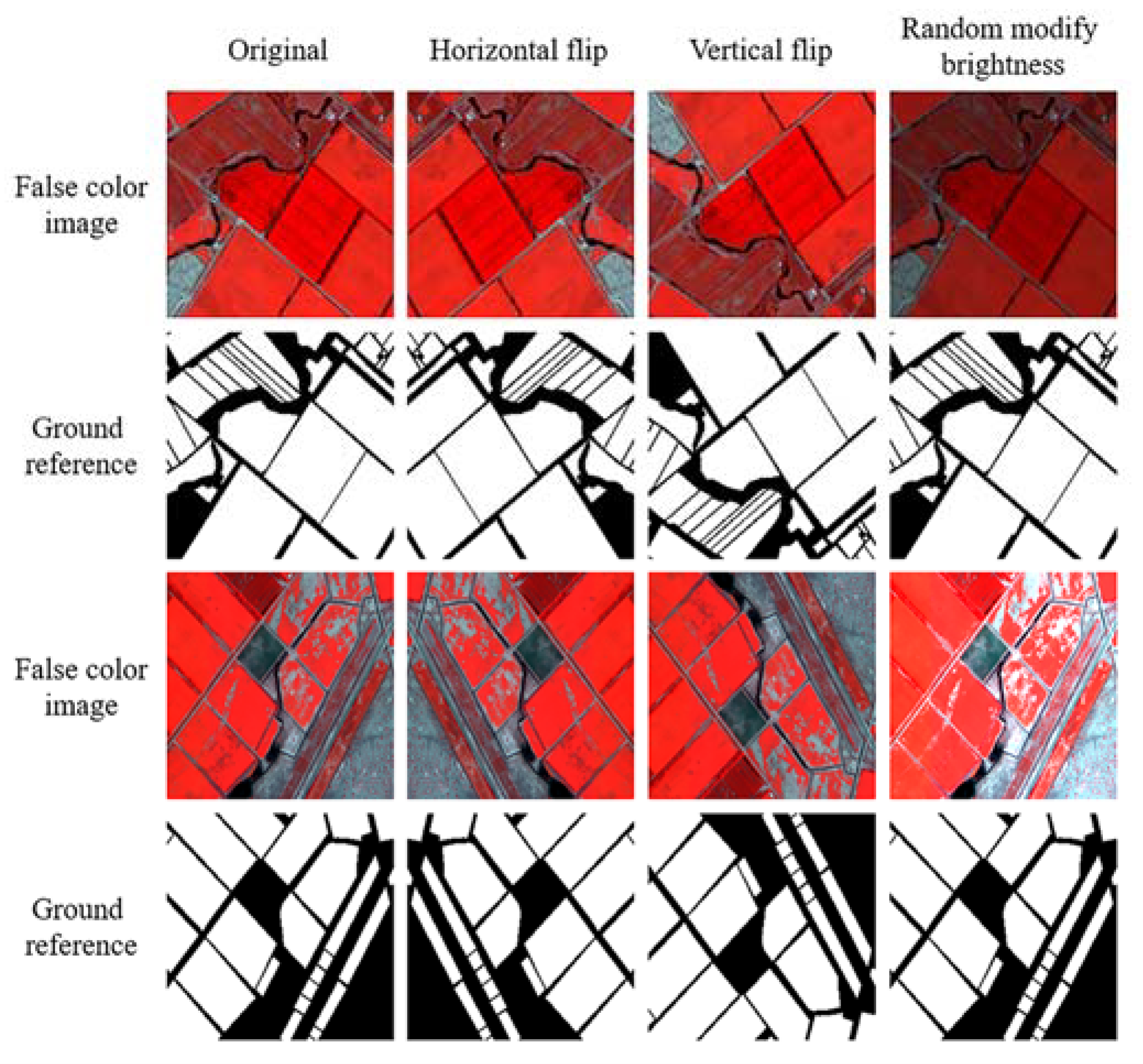
2.2. Dataset
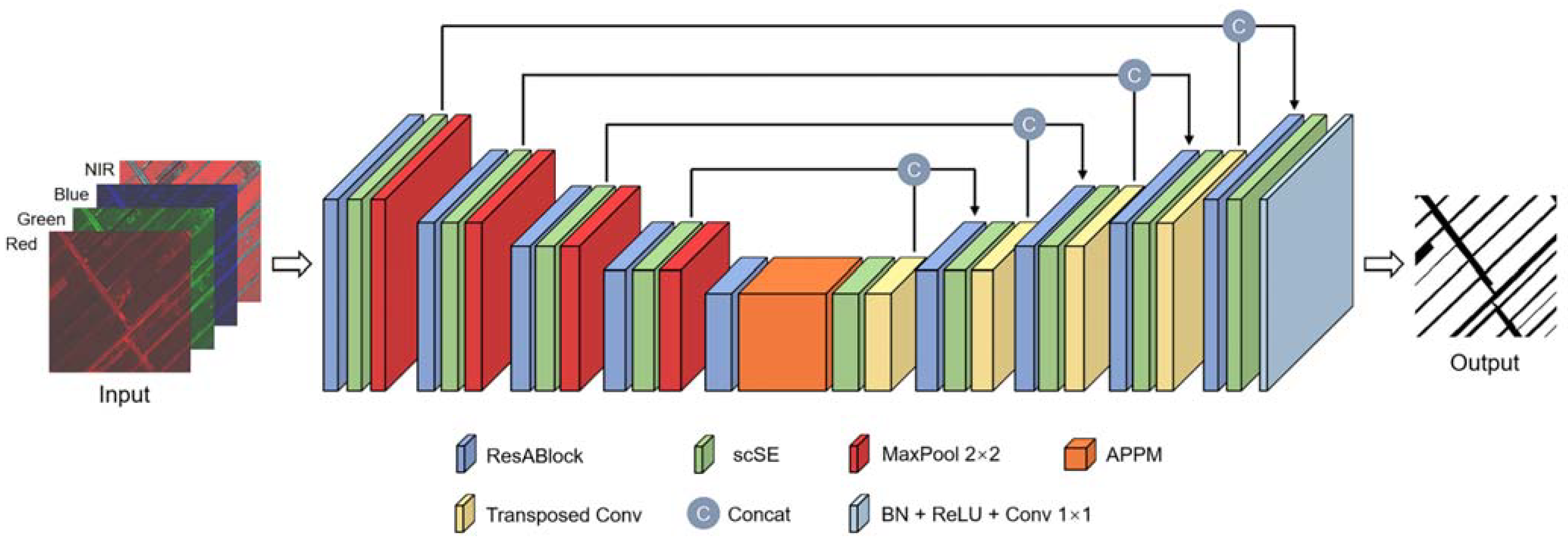
2.3. Model Architecture
2.3.1. Residual Atrous Block
2.3.2. Ameliorated Spatial and Channel Squeeze and Excitation Module
2.3.3. Atrous Pyramid Pooling Module
2.4. Training
2.5. Accuracy Assessment
3. Results
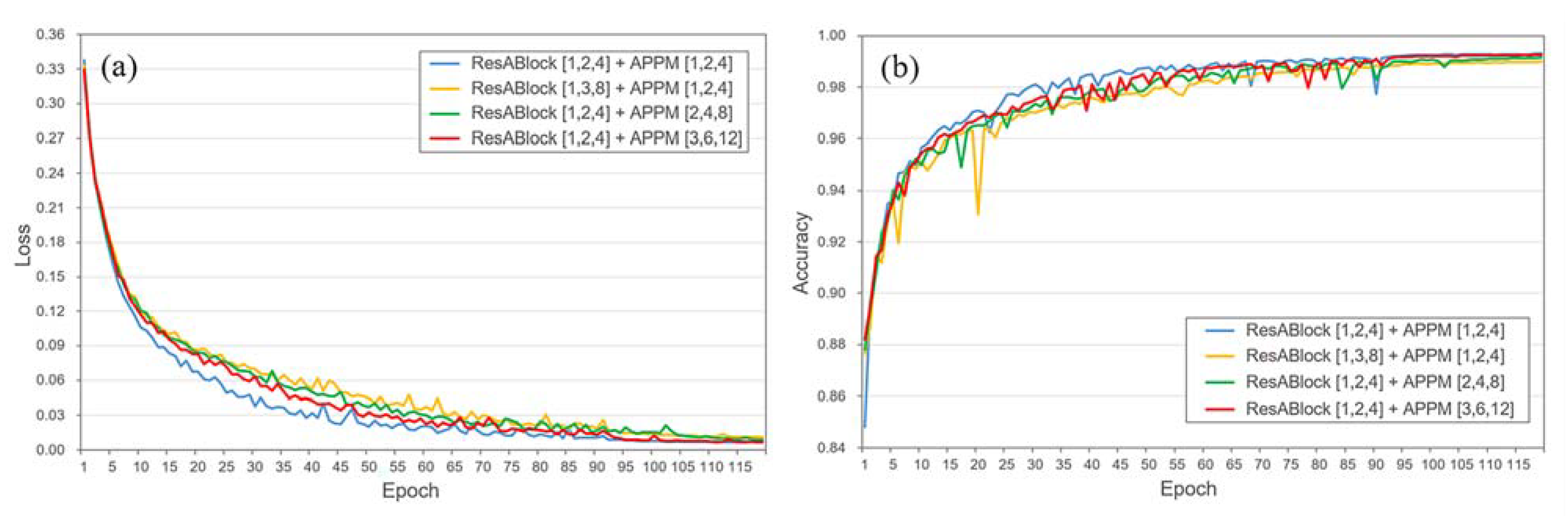
3.1. Model Parameters Selection
3.2. Comparison of Modules
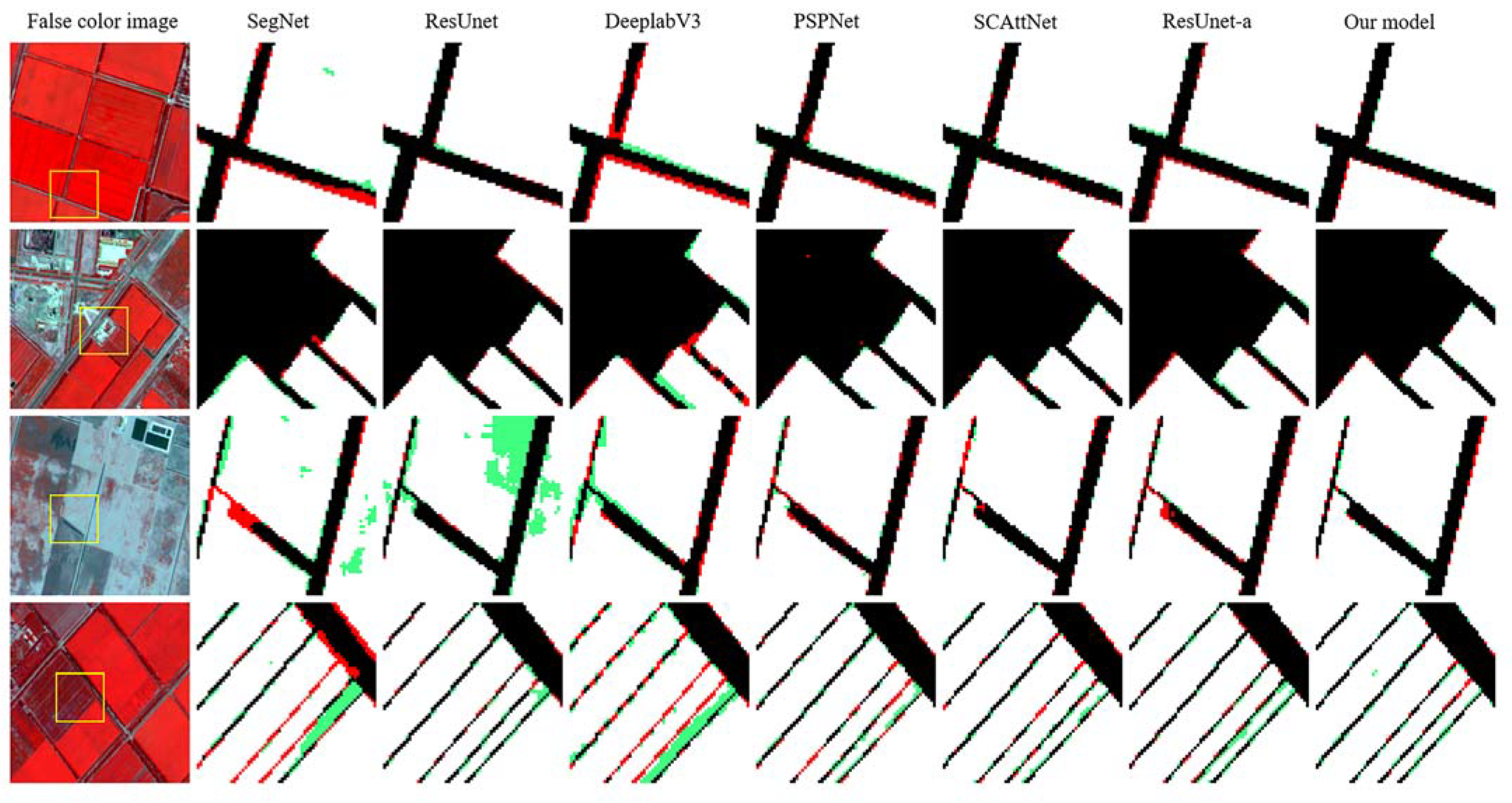
3.3. Comparison of Models
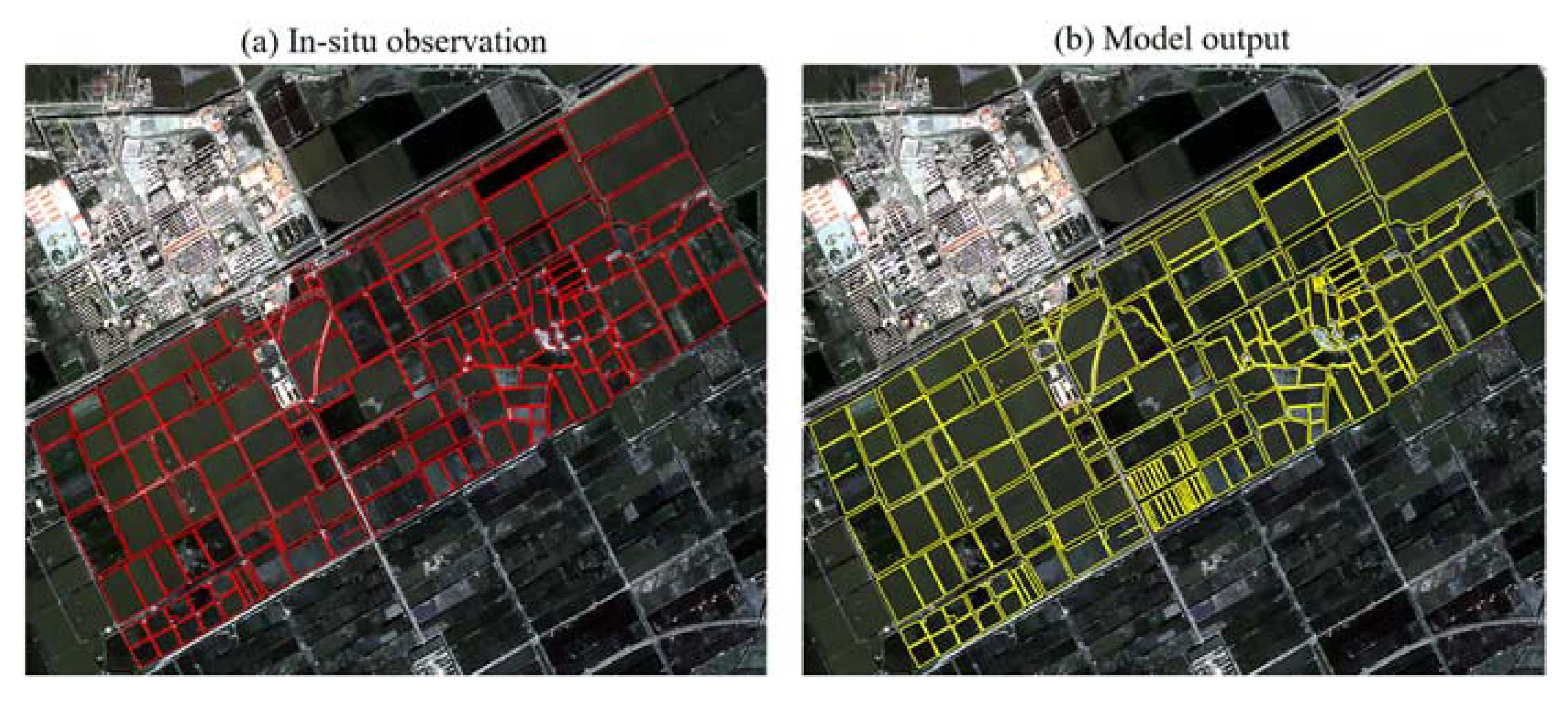
3.4. In-Situ Observation
3.5. Results of Agricultural Field Extraction
4. Discussion
4.1. Deep Learning for Agricultural Field Extraction
4.2. Dual Attention Mechanism
4.3. Multi-scale Feature Fusion
4.4. Perspective
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Matton, N.; Canto, G.S.; Waldner, F.; Valero, S.; Morin, D.; Inglada, J.; Arias, M.; Bontemps, S.; Koetz, B.; Defourny, P. An automated method for annual cropland mapping along the season for various globally-distributed agrosystems using high spatial and temporal resolution time series. Remote Sens. 2015, 7, 13208–13232. [Google Scholar] [CrossRef] [Green Version]
- Whitcraft, A.K.; Becker-Reshef, I.; Justice, C.O. A framework for defining spatially explicit earth observation requirements for a global agricultural monitoring initiative (GEOGLAM). Remote Sens. 2015, 7, 1461–1481. [Google Scholar] [CrossRef] [Green Version]
- Tirado, M.C.; Clarke, R.; Jaykus, L.A.; McQuatters-Gollop, A.; Frank, J.M. Climate change and food safety: A review. Food Res. Int. 2010, 43, 1745–1765. [Google Scholar] [CrossRef]
- Jung, J.; Maeda, M.; Chang, A.; Bhandari, M.; Ashapure, A.; Landivar-Bowles, J. The potential of remote sensing and artificial intelligence as tools to improve the resilience of agriculture production systems. Curr. Opin. Biotechnol. 2021, 70, 15–22. [Google Scholar] [CrossRef]
- Lobell, D.B.; Thau, D.; Seifert, C.; Engle, E.; Little, B. A scalable satellite-based crop yield mapper. Remote Sens. Environ. 2015, 164, 324–333. [Google Scholar] [CrossRef]
- Bai, X.D.; Cao, Z.G.; Wang, Y.; Yu, Z.H.; Zhang, X.F.; Li, C.N. Crop segmentation from images by morphology modeling in the CIE L* a* b* color space. Comput. Electron. Agric. 2013, 99, 21–34. [Google Scholar] [CrossRef]
- Hassanein, M.; Lari, Z.; El-Sheimy, N. A new vegetation segmentation approach for cropped fields based on threshold detection from hue histograms. Sensors 2018, 18, 1253. [Google Scholar] [CrossRef] [Green Version]
- Riehle, D.; Reiser, D.; Griepentrog, H.W. Robust index-based semantic plant/background segmentation for RGB-images. Comput. Electron. Agric. 2020, 169, 105201. [Google Scholar] [CrossRef]
- Zheng, H.; Zhou, M.; Zhu, Y.; Cheng, T. Exploiting the textural information of UAV multispectral imagery to monitor nitrogen status in rice. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7251–7253. [Google Scholar]
- Zhang, P.; Xu, L. Unsupervised segmentation of greenhouse plant images based on statistical method. Sci. Rep. 2018, 8, 4465. [Google Scholar] [CrossRef] [Green Version]
- Crommelinck, S.; Bennett, R.; Gerke, M.; Yang, M.Y.; Vosselman, G. Contour detection for UAV-based cadastral mapping. Remote Sens. 2017, 9, 171. [Google Scholar] [CrossRef] [Green Version]
- Cheng, Z.; Qi, L.; Cheng, Y. Cherry Tree Crown Extraction from Natural Orchard Images with Complex Backgrounds. Agriculture 2021, 11, 431. [Google Scholar] [CrossRef]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef] [Green Version]
- Talukdar, S.; Singha, P.; Mahato, S.; Pal, S.; Liou, Y.A.; Rahman, A. Land-use land-cover classification by machine learning classifiers for satellite observations—A review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef] [Green Version]
- De Castro, A.I.; Torres-Sánchez, J.; Peña, J.M.; Jiménez-Brenes, F.M.; Csillik, O.; López-Granados, F. An automatic random forest-OBIA algorithm for early weed mapping between and within crop rows using UAV imagery. Remote Sens. 2018, 10, 285. [Google Scholar] [CrossRef] [Green Version]
- Feng, S.; Zhao, J.; Liu, T.; Zhang, H.; Zhang, Z.; Guo, X. Crop type identification and mapping using machine learning algorithms and sentinel-2 time series data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3295–3306. [Google Scholar] [CrossRef]
- Shrestha, A.; Mahmood, A. Review of deep learning algorithms and architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Li, H.; Qiu, K.; Chen, L.; Mei, X.; Hong, L.; Tao, C. SCAttNet: Semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 905–909. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel ‘squeeze & excitation’in fully convolutional networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Cham, Switzerland, 2018; pp. 421–429. [Google Scholar]
- Chen, Z.; Wang, C.; Li, J.; Xie, N.; Han, Y.; Du, J. Reconstruction bias U-Net for road extraction from optical remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2284–2294. [Google Scholar] [CrossRef]
- Li, X.; Wang, Y.; Zhang, L.; Liu, S.; Mei, J.; Li, Y. Topology-enhanced urban road extraction via a geographic feature-enhanced network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8819–8830. [Google Scholar] [CrossRef]
- Lin, Y.; Xu, D.; Wang, N.; Shi, Z.; Chen, Q. Road extraction from very-high-resolution remote sensing images via a nested SE-Deeplab model. Remote Sens. 2020, 12, 2985. [Google Scholar] [CrossRef]
- Tan, Y.; Xiong, S.; Yan, P. Multi-branch convolutional neural network for built-up area extraction from remote sensing image. Neurocomputing 2020, 396, 358–374. [Google Scholar] [CrossRef]
- Guo, H.; Shi, Q.; Du, B.; Zhang, L.; Wang, D.; Ding, H. Scene-driven multitask parallel attention network for building extraction in high-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4287–4306. [Google Scholar] [CrossRef]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep learning based cloud detection for medium and high resolution remote sensing images of different sensors. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef] [Green Version]
- Shao, Z.; Pan, Y.; Diao, C.; Cai, J. Cloud detection in remote sensing images based on multiscale features-convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4062–4076. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Scott, G.J.; England, M.R.; Starms, W.A.; Marcum, R.A.; Davis, C.H. Training deep convolutional neural networks for land–cover classification of high-resolution imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 549–553. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Rezaee, M.; Mohammadimanesh, F.; Zhang, Y. Very deep convolutional neural networks for complex land cover mapping using multispectral remote sensing imagery. Remote Sens. 2018, 10, 1119. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Chen, W.; Xie, S.M.; Azzari, G.; Lobell, D.B. Weakly supervised deep learning for segmentation of remote sensing imagery. Remote Sens. 2020, 12, 207. [Google Scholar] [CrossRef] [Green Version]
- Taravat, A.; Wagner, M.P.; Bonifacio, R.; Petit, D. Advanced fully convolutional networks for agricultural field boundary detection. Remote Sens. 2021, 13, 722. [Google Scholar] [CrossRef]
- Zhang, D.; Pan, Y.; Zhang, J.; Hu, T.; Zhao, J.; Li, N.; Chen, Q. A generalized approach based on convolutional neural networks for large area cropland mapping at very high resolution. Remote Sens. Environ. 2020, 247, 111912. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-resolution context extraction network for semantic segmentation of remote sensing images. Remote Sens. 2021, 13, 71. [Google Scholar] [CrossRef]
- Adhikari, U.; Nejadhashemi, A.P.; Woznicki, S.A. Climate change and eastern Africa: A review of impact on major crops. Food Energy Secur. 2015, 4, 110–132. [Google Scholar] [CrossRef]
- Li, N.; Lin, H.; Wang, T.; Li, Y.; Liu, Y.; Chen, X.; Hu, X. Impact of climate change on cotton growth and yields in Xinjiang, China. Field Crops Res. 2020, 247, 107590. [Google Scholar] [CrossRef]
- Olesen, J.E.; Trnka, M.; Kersebaum, K.C.; Skjelvåg, A.O.; Seguin, B.; Peltonen-Sainio, P.; Rossi, F.; Kozyra, J.; Micale, F. Impacts and adaptation of European crop production systems to climate change. Eur. J. Agron. 2011, 34, 96–112. [Google Scholar] [CrossRef]
- Li, X.; Lei, Y.; Han, Y.; Wang, Z.; Wang, G.; Feng, L.; Du, W.; Fan, Z.; Yang, B.; Xiong, S.; et al. The relative impacts of changes in plant density and weather on cotton yield variability. Field Crops Res. 2021, 270, 108202. [Google Scholar] [CrossRef]
- Peng, J.; Biswas, A.; Jiang, Q.; Zhao, R.; Hu, J.; Hu, B.; Shi, Z. Estimating soil salinity from remote sensing and terrain data in southern Xinjiang Province, China. Geoderma 2019, 337, 1309–1319. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Yu, X.; Wu, X.; Luo, C.; Ren, P. Deep learning in remote sensing scene classification: A data augmentation enhanced convolutional neural network framework. GISci. Remote Sens. 2017, 54, 741–758. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Tang, P.; Zhao, L. Fast and accurate land-cover classification on medium-resolution remote-sensing images using segmentation models. Int. J. Remote Sens. 2021, 42, 3277–3301. [Google Scholar] [CrossRef]
- Mutanga, O.; Adam, E.; Cho, M.A. High density biomass estimation for wetland vegetation using WorldView-2 imagery and random forest regression algorithm. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 399–406. [Google Scholar] [CrossRef]
- Mohammadimanesh, F.; Salehi, B.; Mahdianpari, M.; Gill, E.; Molinier, M. A new fully convolutional neural network for semantic segmentation of polarimetric SAR imagery in complex land cover ecosystem. ISPRS J. Photogramm. Remote Sens. 2019, 151, 223–236. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shao, Z.; Zhou, Z.; Huang, X.; Zhang, Y. MRENet: Simultaneous extraction of road surface and road centerline in complex urban scenes from very high-resolution images. Remote Sens. 2021, 13, 239. [Google Scholar] [CrossRef]
- Mei, S.; Ji, J.; Hou, J.; Li, X.; Du, Q. Learning sensor-specific spatial-spectral features of hyperspectral images via convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4520–4533. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual attentive fully convolutional siamese networks for change detection in high-resolution satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1194–1206. [Google Scholar] [CrossRef]
- Han, B.; Yin, J.; Luo, X.; Jia, X. Multibranch Spatial-Channel Attention for Semantic Labeling of Very High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 2167–2171. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local attention embedding to improve the semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 426–435. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, S.; Ding, L.; Bruzzone, L. Multi-scale context aggregation for semantic segmentation of remote sensing images. Remote Sens. 2020, 12, 701. [Google Scholar] [CrossRef] [Green Version]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A fully convolutional neural network for automatic building extraction from high-resolution remote sensing images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef] [Green Version]
- Lan, M.; Zhang, Y.; Zhang, L.; Du, B. Global context based automatic road segmentation via dilated convolutional neural network. Inf. Sci. 2020, 535, 156–171. [Google Scholar] [CrossRef]
- Waldner, F.; Diakogiannis, F.I. Deep learning on edge: Extracting field boundaries from satellite images with a convolutional neural network. Remote Sens. Environ. 2020, 245, 111741. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Wang, N.; Peng, J.; Xue, J.; Zhang, X.; Huang, J.; Biswas, A.; He, Y.; Shi, Z. A framework for determining the total salt content of soil profiles using time-series Sentinel-2 images and a random forest-temporal convolution network. Geoderma 2022, 409, 115656. [Google Scholar] [CrossRef]
- Kang, J.; Fernandez-Beltran, R.; Duan, P.; Liu, S.; Plaza, A.J. Deep unsupervised embedding for remotely sensed images based on spatially augmented momentum contrast. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2598–2610. [Google Scholar] [CrossRef]
- Hu, Z.; Yang, H.; Lou, T. Dual attention-guided feature pyramid network for instance segmentation of group pigs. Comput. Electron. Agric. 2021, 186, 106140. [Google Scholar] [CrossRef]
- Ouyang, S.; Li, Y. Combining deep semantic segmentation network and graph convolutional neural network for semantic segmentation of remote sensing imagery. Remote Sens. 2021, 13, 119. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, J.; Wang, F. Attention bilinear pooling for fine-grained classification. Symmetry 2019, 11, 1033. [Google Scholar] [CrossRef] [Green Version]
- Ma, W.; Gong, C.; Xu, S.; Zhang, X. Multi-scale spatial context-based semantic edge detection. Inf. Fusion 2020, 64, 238–251. [Google Scholar] [CrossRef]
- Li, E.; Xia, J.; Du, P.; Lin, C.; Samat, A. Integrating multilayer features of convolutional neural networks for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5653–5665. [Google Scholar] [CrossRef]
- Persello, C.; Tolpekin, V.A.; Bergado, J.R.; de By, R.A. Delineation of agricultural fields in smallholder farms from satellite images using fully convolutional networks and combinatorial grouping. Remote Sens. Environ. 2019, 231, 111253. [Google Scholar] [CrossRef]
- Turkoglu, M.O.; D’Aronco, S.; Perich, G.; Liebisch, F.; Streit, C.; Schindler, K.; Wegner, J.D. Crop mapping from image time series: Deep learning with multi-scale label hierarchies. Remote Sens. Environ. 2021, 264, 112603. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block | OA | P | R | F | IoU | Kappa | L |
|---|---|---|---|---|---|---|---|
| ResABlock | |||||||
| [1,2,4] | 0.9928 | 0.9013 | 0.9012 | 0.9010 | 0.8929 | 0.8879 | 1.9222 |
| [1,3,8] | 0.9894 | 0.8992 | 0.8980 | 0.8983 | 0.8874 | 0.8785 | 1.8985 |
| APPM | |||||||
| [1,2,4] | 0.9928 | 0.9013 | 0.9012 | 0.9010 | 0.8929 | 0.8879 | 1.9222 |
| [2,4,8] | 0.9916 | 0.9008 | 0.9011 | 0.9009 | 0.8921 | 0.8849 | 1.6639 |
| [3,6,12] | 0.9922 | 0.9023 | 0.9011 | 0.9017 | 0.8932 | 0.8869 | 1.1752 |
| Module | OA | P | R | F | IoU | Kappa | L |
|---|---|---|---|---|---|---|---|
| ResABlock | |||||||
| Resblock | 0.9914 | 0.8995 | 0.9005 | 0.8997 | 0.8902 | 0.8833 | 1.4602 |
| ResABlock | 0.9922 | 0.9023 | 0.9011 | 0.9017 | 0.8932 | 0.8869 | 1.1752 |
| scSE | |||||||
| None | 0.9869 | 0.8974 | 0.8968 | 0.8969 | 0.8844 | 0.8712 | 2.0426 |
| SEblock | 0.9882 | 0.8974 | 0.8992 | 0.8982 | 0.8868 | 0.8757 | 2.1688 |
| CBAM | 0.9915 | 0.9007 | 0.9006 | 0.9005 | 0.8913 | 0.8835 | 1.5780 |
| scSE | 0.9922 | 0.9023 | 0.9011 | 0.9017 | 0.8932 | 0.8869 | 1.1752 |
| APPM | |||||||
| PPM | 0.9891 | 0.8985 | 0.8989 | 0.8986 | 0.8875 | 0.8784 | 1.8046 |
| ASPP | 0.9867 | 0.8975 | 0.8945 | 0.8958 | 0.8824 | 0.8707 | 2.4273 |
| APPM | 0.9922 | 0.9023 | 0.9011 | 0.9017 | 0.8932 | 0.8869 | 1.1752 |
| Model | OA | P | R | F | IoU | Kappa | L |
|---|---|---|---|---|---|---|---|
| SegNet | 0.9780 | 0.8899 | 0.8841 | 0.8860 | 0.8652 | 0.8445 | 5.4505 |
| ResUnet | 0.9903 | 0.9003 | 0.8976 | 0.8984 | 0.8881 | 0.8799 | 2.3418 |
| DeeplabV3 | 0.9742 | 0.8834 | 0.8866 | 0.8846 | 0.8613 | 0.8344 | 2.2932 |
| PSPNet | 0.9899 | 0.8998 | 0.9002 | 0.8999 | 0.8900 | 0.8806 | 2.2462 |
| SCAttNet | 0.9907 | 0.8979 | 0.9026 | 0.9000 | 0.8905 | 0.8822 | 2.1575 |
| ResUnet-a | 0.9904 | 0.9014 | 0.8982 | 0.8996 | 0.8870 | 0.8769 | 1.4989 |
| Our Model | 0.9922 | 0.9023 | 0.9011 | 0.9017 | 0.8932 | 0.8869 | 1.1752 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, R.; Wang, N.; Zhang, Y.; Lin, Y.; Wu, W.; Shi, Z. Extraction of Agricultural Fields via DASFNet with Dual Attention Mechanism and Multi-scale Feature Fusion in South Xinjiang, China. Remote Sens. 2022, 14, 2253. https://doi.org/10.3390/rs14092253
Lu R, Wang N, Zhang Y, Lin Y, Wu W, Shi Z. Extraction of Agricultural Fields via DASFNet with Dual Attention Mechanism and Multi-scale Feature Fusion in South Xinjiang, China. Remote Sensing. 2022; 14(9):2253. https://doi.org/10.3390/rs14092253
Chicago/Turabian StyleLu, Rui, Nan Wang, Yanbin Zhang, Yeneng Lin, Wenqiang Wu, and Zhou Shi. 2022. "Extraction of Agricultural Fields via DASFNet with Dual Attention Mechanism and Multi-scale Feature Fusion in South Xinjiang, China" Remote Sensing 14, no. 9: 2253. https://doi.org/10.3390/rs14092253
APA StyleLu, R., Wang, N., Zhang, Y., Lin, Y., Wu, W., & Shi, Z. (2022). Extraction of Agricultural Fields via DASFNet with Dual Attention Mechanism and Multi-scale Feature Fusion in South Xinjiang, China. Remote Sensing, 14(9), 2253. https://doi.org/10.3390/rs14092253