
Oriented Ship Detector for Remote Sensing Imagery Based on Pairwise Branch Detection Head and SAR Feature Enhancement


Abstract
:1. Introduction
1.1. Related Work
1.1.1. Deep Learning Object Detection
1.1.2. Ship Detection
1.2. Problem Description and Motivations
1.3. Contributions and Structure
- (1)
- Aiming at the problem of high complexity caused by preset multi-oriented anchors, we propose an oriented region proposal network (ORPN). In generating the candidate regions, ORPN has abandoned artificial oriented anchors and instead designs a branch that learns the projective transformation from the HRoI to the RRoI, capturing high levels of the RRoIs while only a few parameters are added.
- (2)
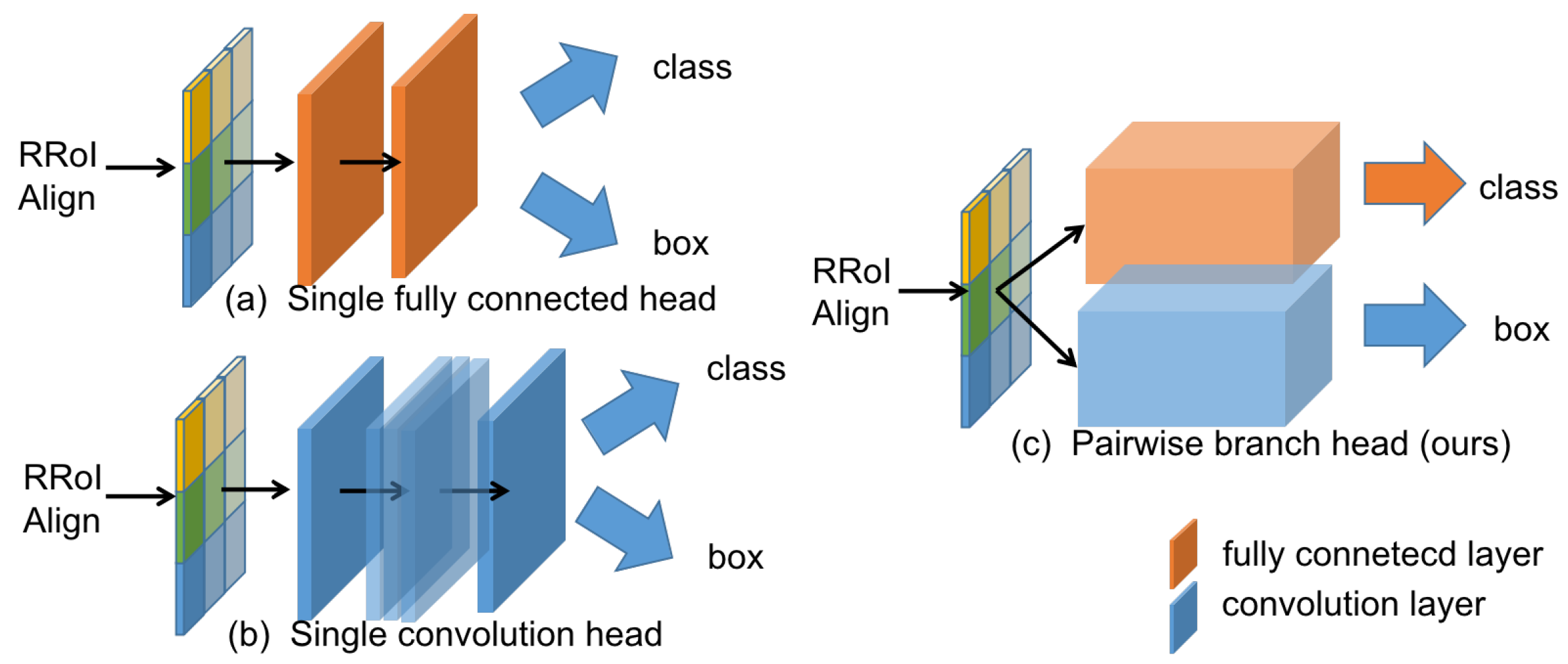
- Aiming at the inconsistency of features suitable for classification and localization, this paper proposes the pairwise branch detection head (PBH). By analyzing the respective characteristics of the fc-head and conv-head, separate branches are set for classification and localization tasks. Each branch is specifically designed to learn the appropriate features for the corresponding task.
- (3)
- To reduce the negative impact of the multiplicative coherent speckle on SAR ship feature extraction, we combine traditional SAR edge detection algorithms with the CNN framework to propose an adaptive threshold SAR edge enhancement (SEE) module. The SEE module combines the mean ratio operator to effectively remove the influence of coherent speckles and enhances the edge adaptively. The threshold value is adaptively learned by the network after setting the initial value, which enables the module to have better generality for different datasets.
2. Preliminaries
Ratio-of-Averages Edge Detector for SAR Image Processing
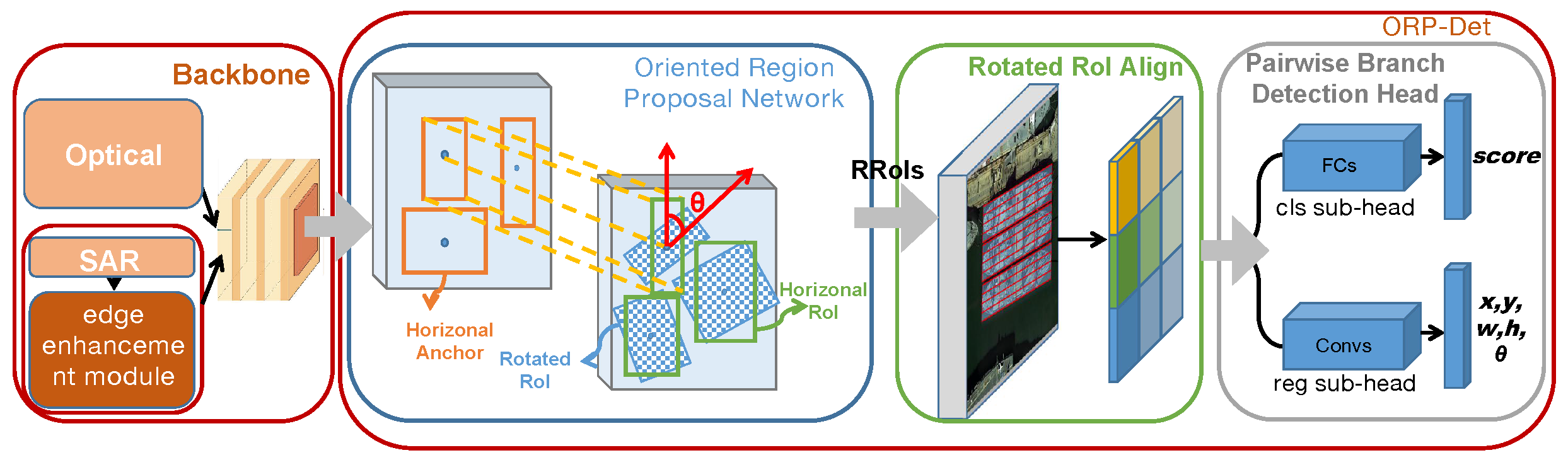
3. Proposed Method
3.1. The Overall Framework
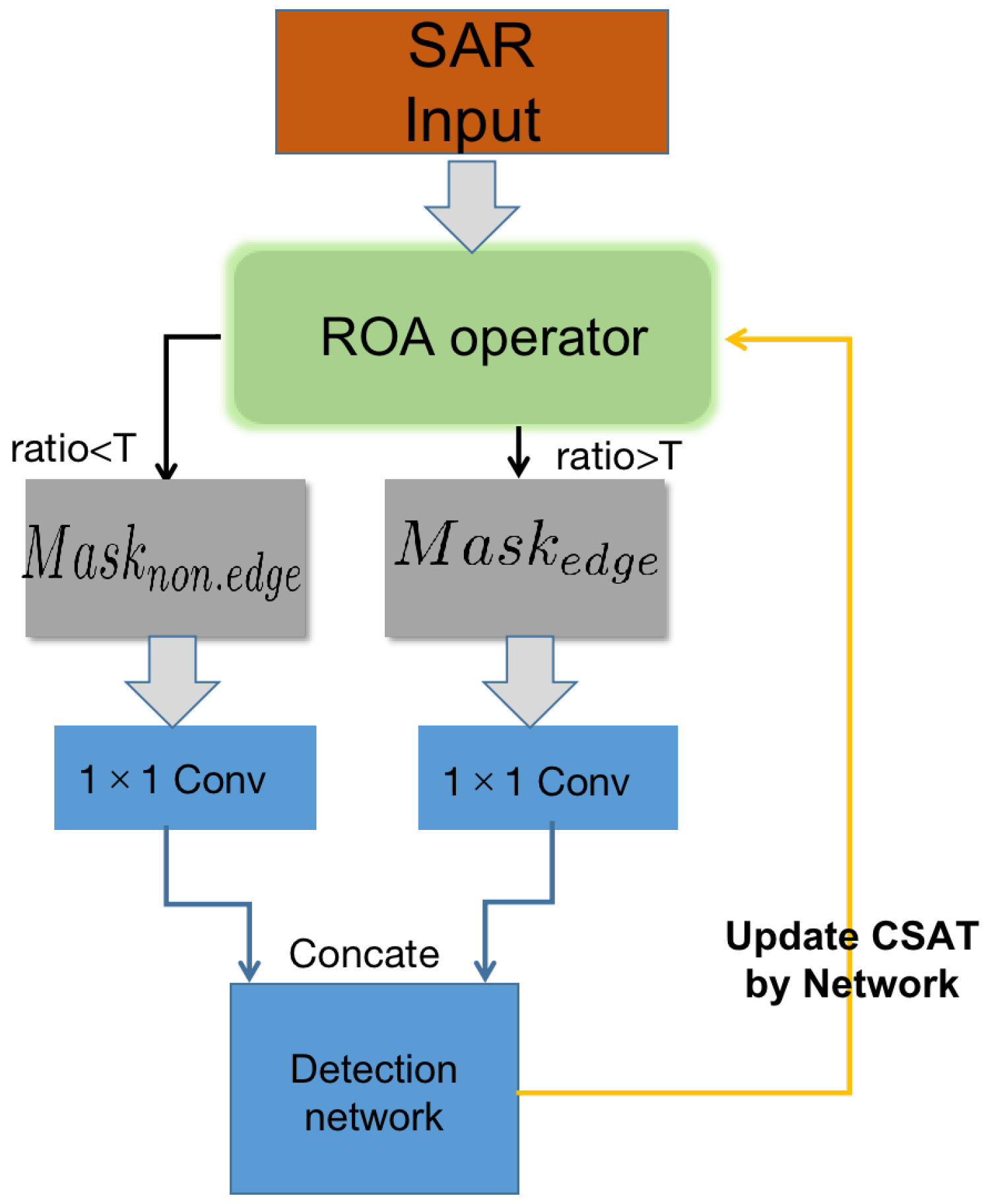
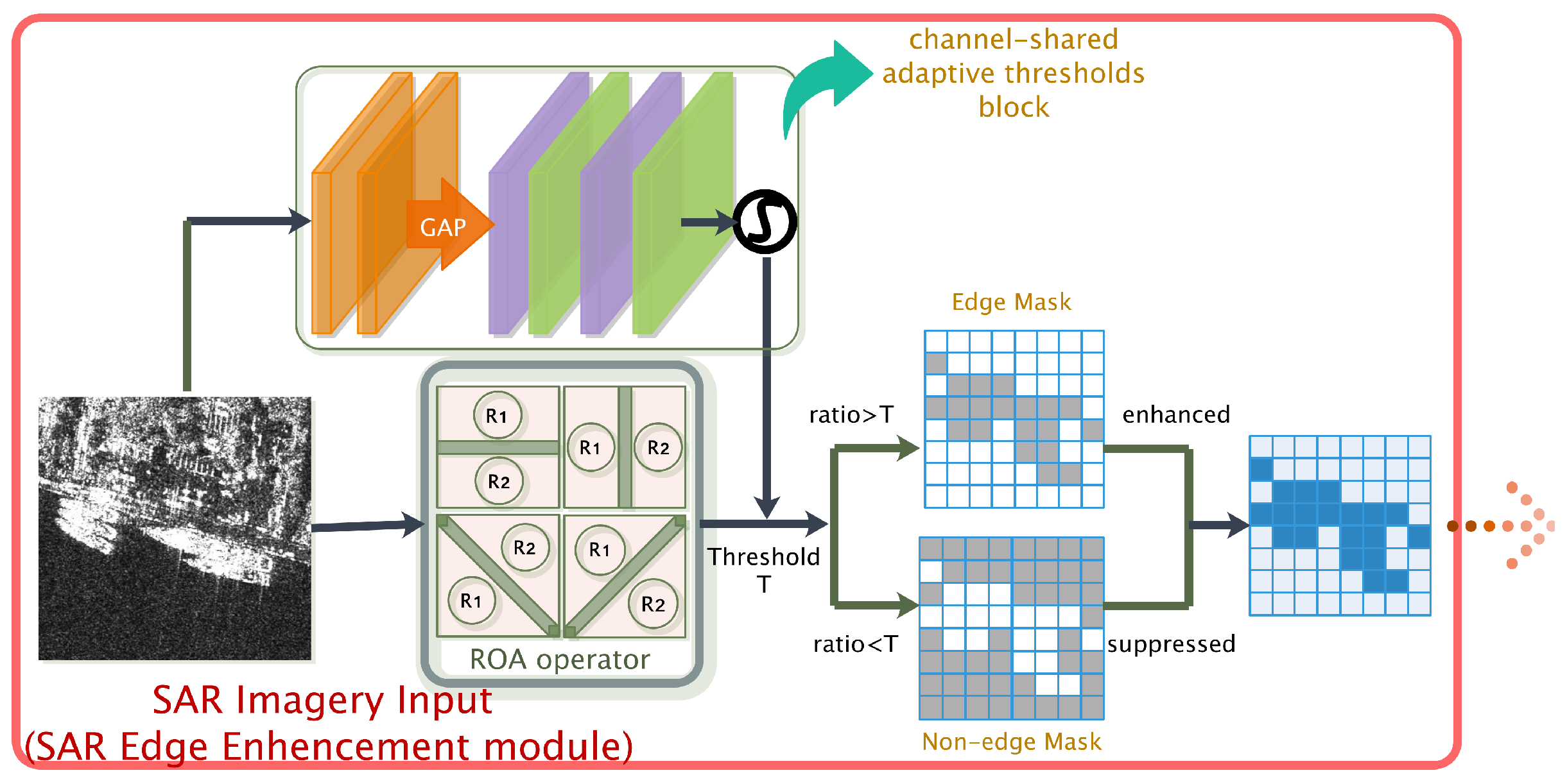
3.2. SAR Image Edge Enhancement Module
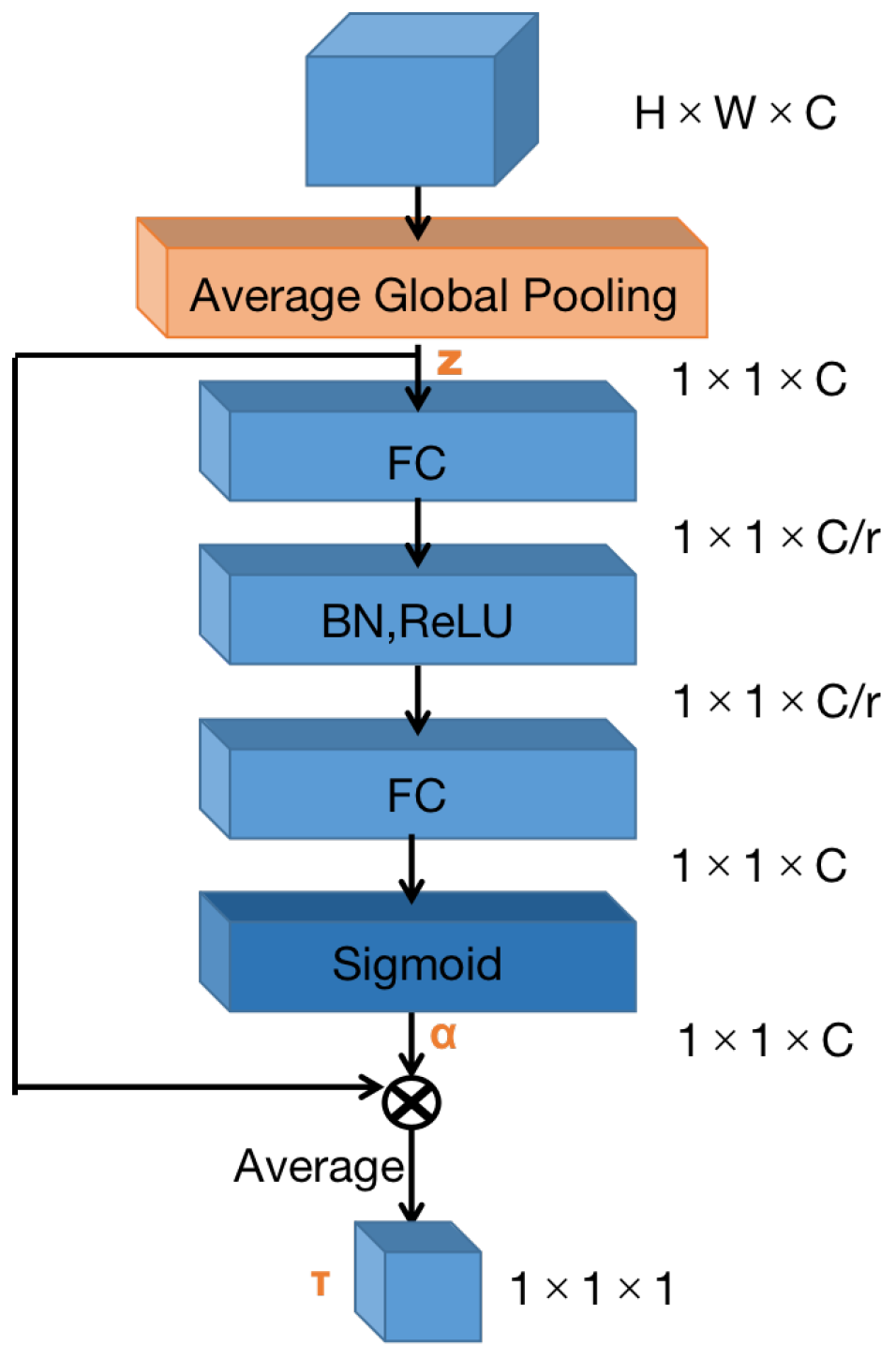
3.2.1. Channel-Shared Adaptive Threshold Block
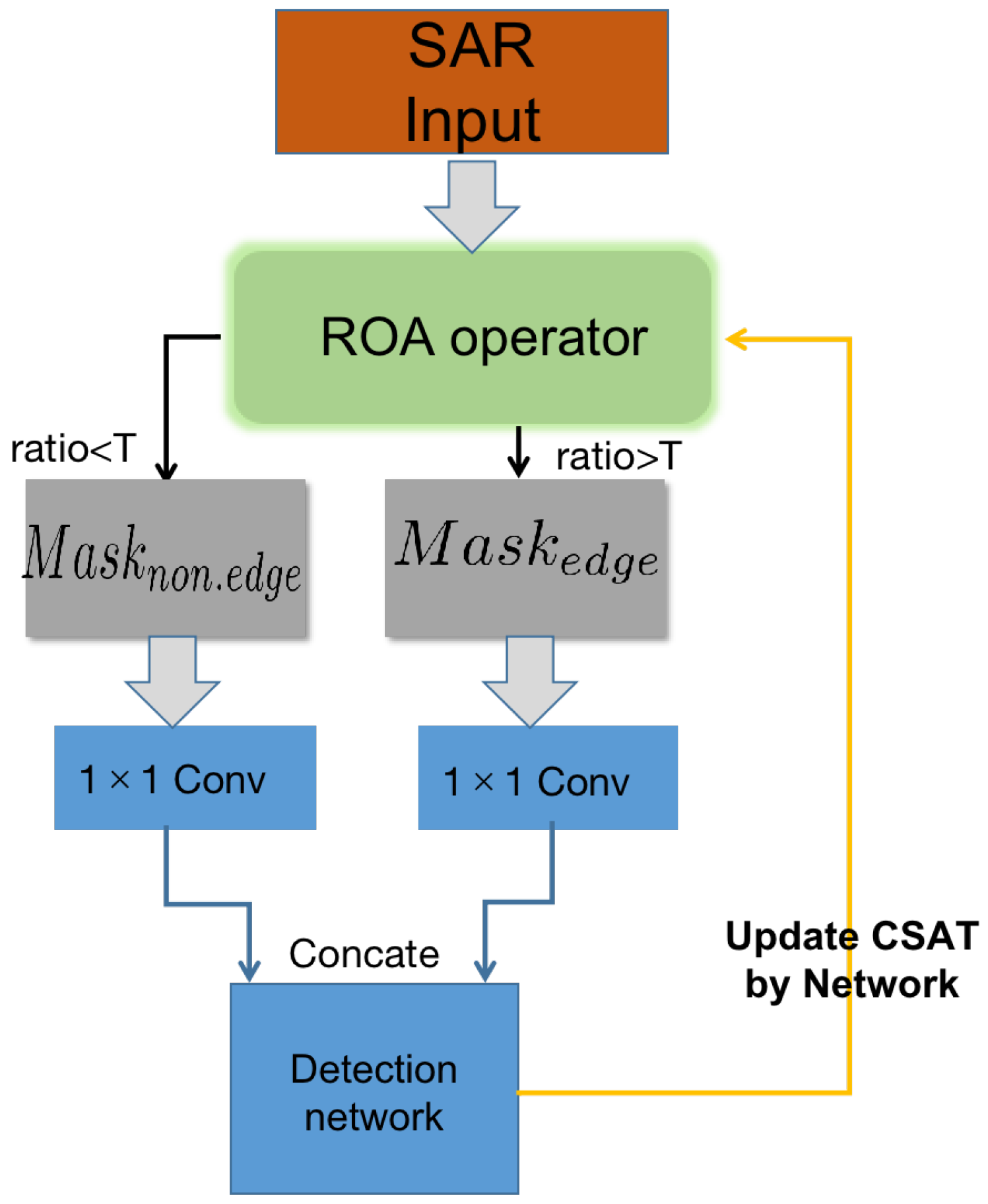
3.2.2. Feature Discrimination and Image Processing Strategy
- The ratio-of-averages value of each pixel of the input image is calculated according to the ROA operator;
- The threshold is compared with the ratio-of-averages values, and the pixels are judged as edge points and non-edge points, respectively. The original image is then divided into two mask images and ;
- The grayscale of edge pixels in is enhanced; the grayscale of non-edge pixels in is suppressed;
- and are concatenated and then input into the subsequent detection network.
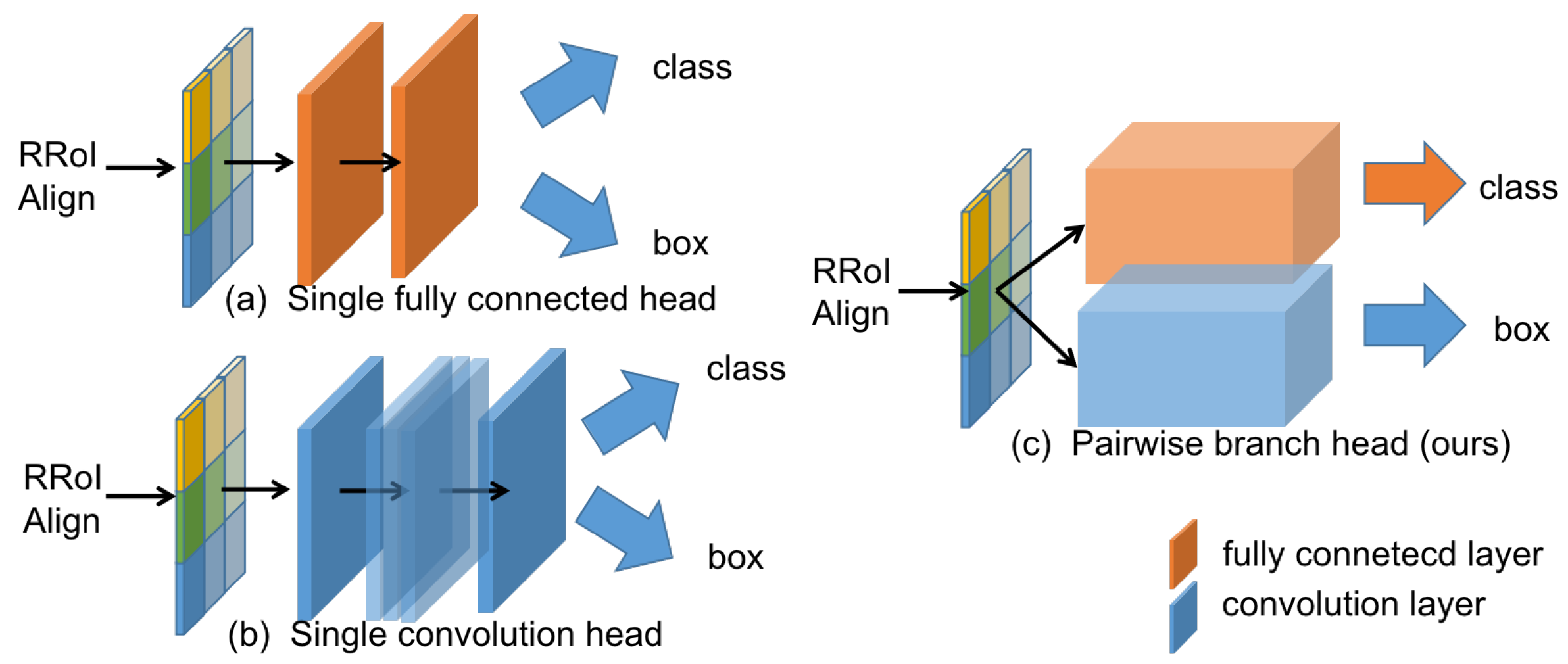
3.3. Oriented Region Detector with a Pairwise Head
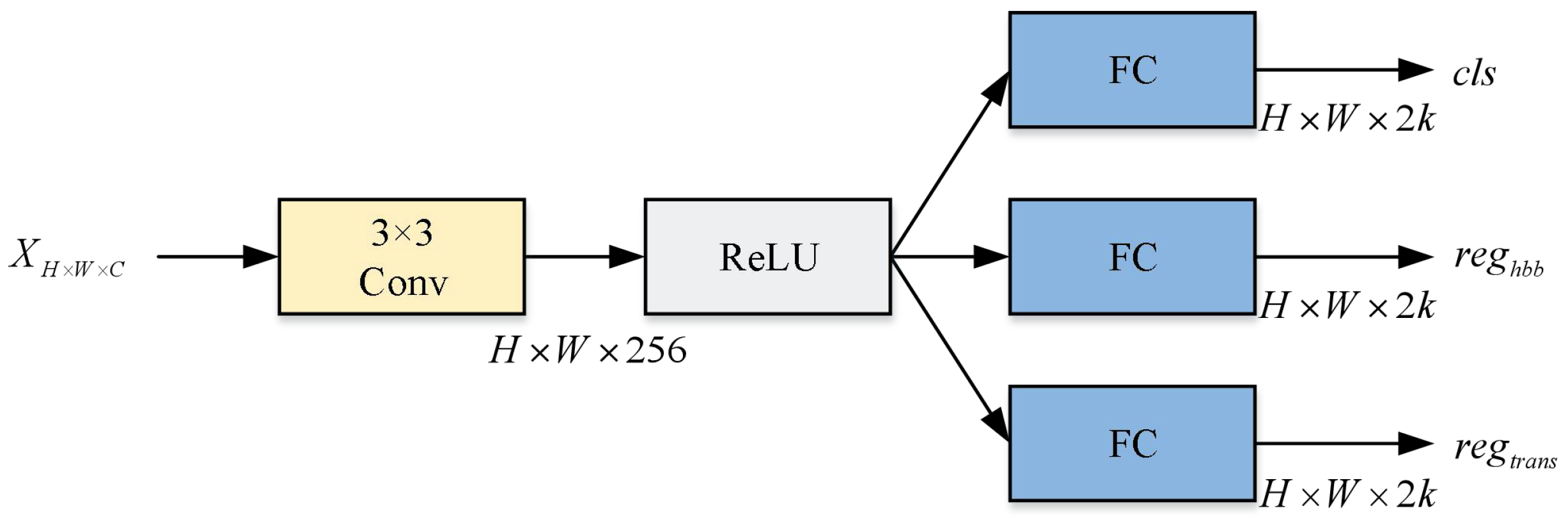
3.3.1. Oriented Region Proposal Network
3.3.2. Rotated RoI Align
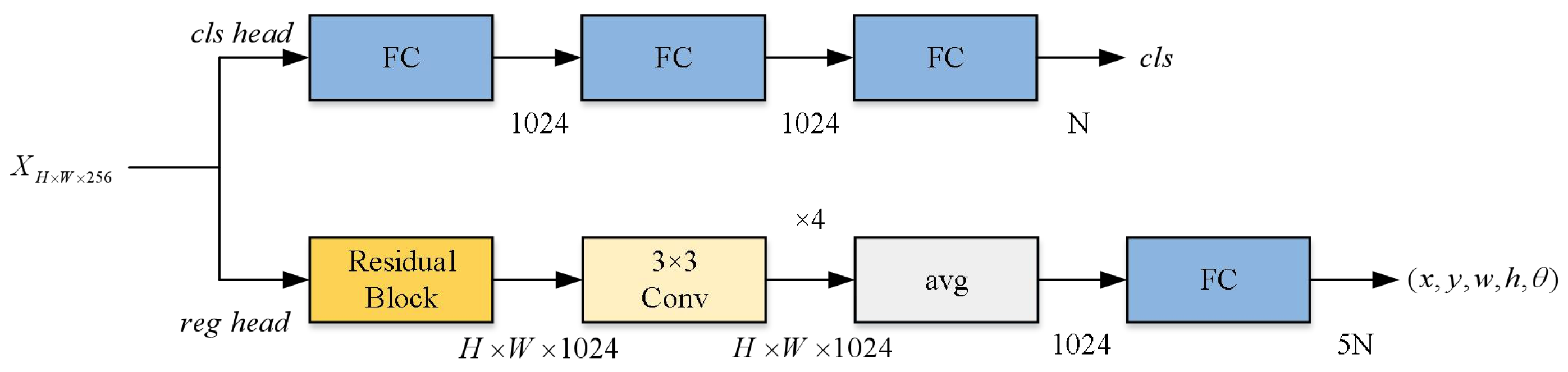
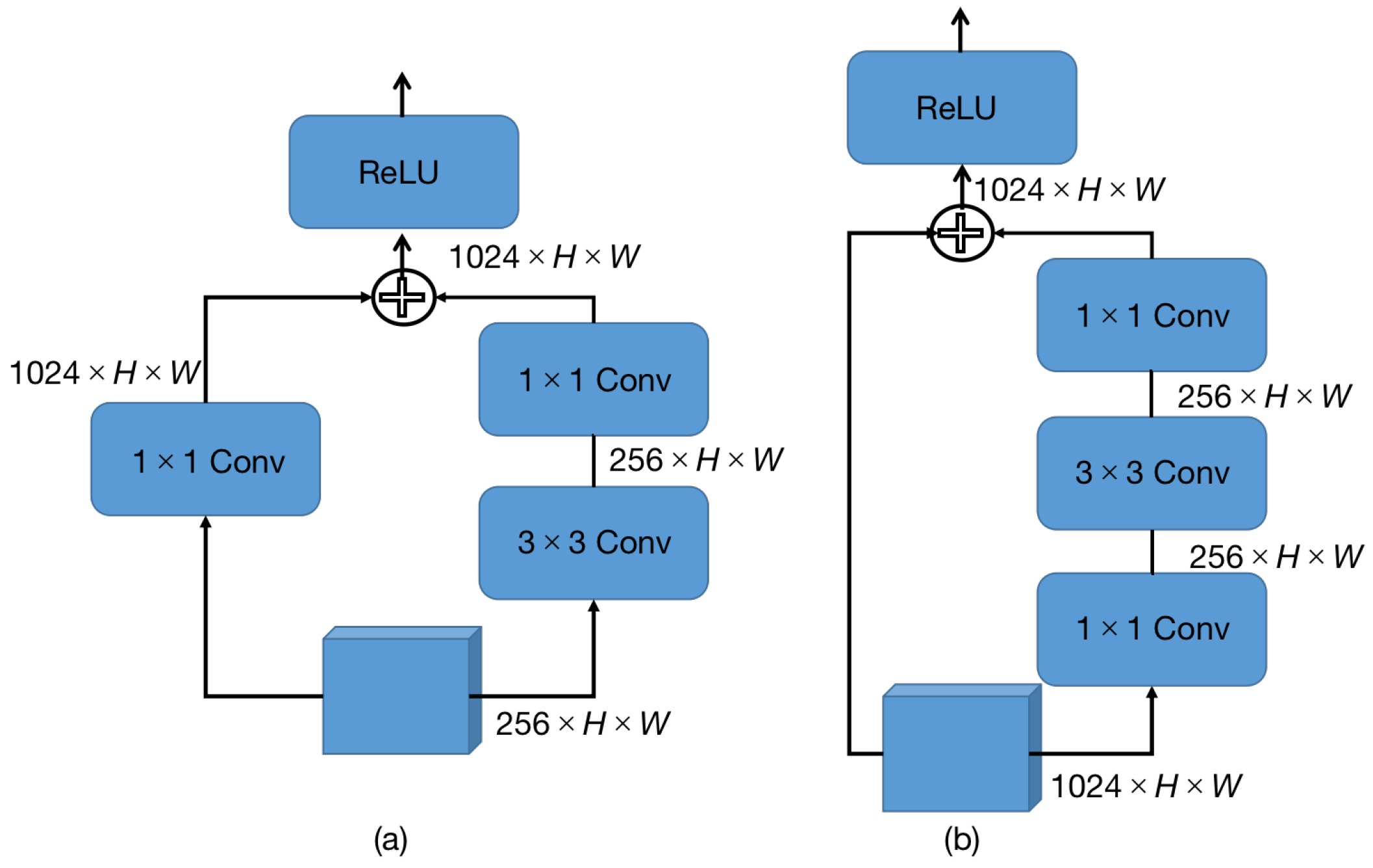
3.3.3. Pairwise Branch Detection Head
4. Experiments and Analysis
4.1. Introduction to SAR Ship Dataset
4.2. Experimental Setting
4.3. Experimental Results and Analysis
4.3.1. Experiment Evaluation of SEE
4.3.2. Experiment Evaluation of ORP-Det
- (1)
- Experiment Evaluation of ORPN
- (2)
- Experiment Evaluation of PBH
- (3)
- Experiment Evaluation of ORP-Det
4.3.3. Comparison of Performance between the Proposed Overall Framework and the State-of-the-Art
4.3.4. Visualization and Analysis of the Detection Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SAR | Synthetic aperture radar |
| RSI | Remote sensing images |
| CNN | Convolutional neural network |
| SVD | Singular value decomposition |
| CFAR | Constant false alarm rate |
| HRoI | Horizontal region of interest |
| RRoI | Rotated region of interest |
| IOU | Intersection over union |
| ROA | Ratio-of-averages |
| GAP | Global average pooling |
| HBB | Horizontal bounding box |
| OBB | Oriented bounding box |
| ORPN | Oriented region proposal network |
| PBH | Pairwise detection head |
| SEE | SAR edge enhancement |
References
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Wu, R.; Xu, K.; Wang, J.; Sun, W. RCNN-based ship detection from high resolution remote sensing imagery. Remote Sens. 2019, 11, 631. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Zhou, S.d.; Bai, H.; Ma, N.; Ye, S. SAR water image segmentation based on GLCM and wavelet textures. In Proceedings of the 2010 6th International Conference on Wireless Communications Networking and Mobile Computing (WiCOM), Chengdu, China, 23–25 September 2010; pp. 1–4. [Google Scholar]
- Dellinger, F.; Delon, J.; Gousseau, Y.; Michel, J.; Tupin, F. SAR-SIFT: A SIFT-like algorithm for SAR images. IEEE Trans. Geosci. Remote Sens. 2014, 53, 453–466. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast RCNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster RCNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29, 379–387. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. Foveabox: Beyound anchor-based object detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Zhu, C.; Zhou, H.; Wang, R.; Guo, J. A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Yang, G.; Li, B.; Ji, S.; Gao, F.; Xu, Q. Ship detection from optical satellite images based on sea surface analysis. IEEE Geosci. Remote Sens. Lett. 2013, 11, 641–645. [Google Scholar] [CrossRef]
- Qi, S.; Ma, J.; Lin, J.; Li, Y.; Tian, J. Unsupervised ship detection based on saliency and S-HOG descriptor from optical satellite images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1451–1455. [Google Scholar]
- Heikkilä, M.; Pietikäinen, M.; Schmid, C. Description of interest regions with local binary patterns. Pattern Recognit. 2009, 42, 425–436. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Zhang, R.; Yao, J.; Zhang, K.; Feng, C.; Zhang, J. S-CNN-based ship detection from high-resolution remote sensing images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 423–430. [Google Scholar] [CrossRef] [Green Version]
- Zou, Z.; Shi, Z. Ship detection in spaceborne optical image with SVD networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5832–5845. [Google Scholar] [CrossRef]
- Tang, J.; Deng, C.; Huang, G.B.; Zhao, B. Compressed-domain ship detection on spaceborne optical image using deep neural network and extreme learning machine. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1174–1185. [Google Scholar] [CrossRef]
- Lin, H.; Shi, Z.; Zou, Z. Fully convolutional network with task partitioning for inshore ship detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1665–1669. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship rotated bounding box space for ship extraction from high-resolution optical satellite images with complex backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Touzi, R.; Lopes, A.; Bousquet, P. A statistical and geometrical edge detector for SAR images. IEEE Trans. Geosci. Remote Sens. 1988, 26, 764–773. [Google Scholar] [CrossRef]
- Bovik, A.C. On detecting edges in speckle imagery. IEEE Trans. Acoust. Speech Signal Process. 1988, 36, 1618–1627. [Google Scholar] [CrossRef]
- Wei, Q.R.; Yuan, M.D.; Feng, D.Z. Automatic local thresholding algorithm for SAR image edge detection. In Proceedings of the IET International Radar Conference 2013, Xi’an, China, 14–16 April 2013. [Google Scholar] [CrossRef]
- Ibrahim, N.; Sari, S. Comparative Assessment of Carotid Lumen Edges Using Canny Detection and Canny-Otsu Threshold Methods. Adv. Sci. Lett. 2017, 23, 4005–4008. [Google Scholar] [CrossRef]
- Setiawan, B.D.; Rusydi, A.N.; Pradityo, K. Lake edge detection using Canny algorithm and Otsu thresholding. In Proceedings of the 2017 International Symposium on Geoinformatics, Malang, Indonesia, 24–25 November 2017. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking classification and localization for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10186–10195. [Google Scholar]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| r | AP (%) | AR (%) | Million Parameters |
|---|---|---|---|
| 4 | 75.0 | 90.9 | 53.7 |
| 8 | 74.4 | 90.5 | 49.6 |
| 16 | 73.9 | 90.1 | 45.4 |
| 32 | 72.6 | 88.3 | 43.5 |
| Original | 72.0 | 87.6 | 41.4 |
| Detector | AIR-SARShip-1.0 | HRSID | ||
|---|---|---|---|---|
| AP(%) | AR(%) | AP(%) | AR(%) | |
| YOLO v3 | 70.3 | 86.9 | 85.9 | 91.2 |
| YOLO v3 w. SEE | 72.1 | 88.3 | 87.0 | 91.9 |
| FCOS | 65.5 | 84.3 | 86.8 | 89.1 |
| FCOS w. SEE | 66.9 | 86.2 | 87.5 | 90.4 |
| Faster RCNN | 72.0 | 87.6 | 88.5 | 90.6 |
| Faster RCNN w. SEE | 73.9 | 90.1 | 89.3 | 91.5 |
| Detector | DOTA-Ship (Optical) | HRSID (SAR) | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 | Precision (%) | Recall (%) | F1 | |
| Baseline | 91.55 | 86.43 | 88.92 | 83.2 | 81.45 | 82.31 |
| +RRPN [37] | 91.98 | 87.69 | 89.78 | 83.69 | 80.97 | 82.3 |
| +ORPN | 93.27 | 88.52 | 90.83 | 86.37 | 84.92 | 85.64 |
| Detector | DOTA-Ship (Optical) | HRSID (SAR) | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 | Precision (%) | Recall (%) | F1 | |
| Baseline | 91.55 | 86.43 | 88.92 | 83.2 | 81.45 | 82.31 |
| +PBH | 92.11 | 88.35 | 90.2 | 85.62 | 84.13 | 84.87 |
| Detector | DOTA-Ship (Optical) | HRSID (SAR) | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 | Precision (%) | Recall (%) | F1 | |
| Baseline | 91.55 | 86.43 | 88.92 | 83.2 | 81.45 | 82.31 |
| +ORPN | 93.27 | 88.52 | 90.83 | 86.37 | 84.92 | 85.64 |
| +PBH | 92.11 | 88.35 | 90.2 | 85.62 | 84.13 | 84.87 |
| ORP-Det | 93.57 | 91.46 | 92.50 | 88.43 | 85.14 | 86.75 |
| Detector | Backbone | DOTA-Ship (Optical) | HRSID (SAR) | ||||
|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 | Precision (%) | Recall (%) | F1 | ||
| Anchor-Free Method | |||||||
| FCOS (OBB) | R-50-FPN | 86.53 | 84.11 | 85.30 | 79.65 | 76.54 | 78.06 |
| FCOS (OBB) | R-101-FPN | 86.42 | 83.10 | 84.73 | 78.45 | 75.52 | 76.96 |
| Single-Stage Method | |||||||
| RetinaNet (OBB) | R-101-FPN | 72.67 | 70.14 | 71.85 | 83.18 | 72.56 | 72.07 |
| DRN | H-104 | 85.48 | 83.79 | 82.96 | 72.66 | 72.85 | 72.75 |
| R3Det | R-101-FPN | 77.45 | 74.54 | 75.97 | 70.13 | 69.55 | 69.84 |
| Two-Stage Method | |||||||
| Faster RCNN (OBB) | R-101-FPN | 91.55 | 86.43 | 88.92 | 83.2 | 81.45 | 82.31 |
| Mask RCNN (OBB) | R-101-FPN | 92.03 | 88.14 | 90.04 | 85.58 | 84.17 | 84.87 |
| R2CNN | R-101-FPN | 55.76 | 52.32 | 53.98 | 50.1 | 51.5 | 50.81 |
| R2CNN++ | R-101-FPN | 66.79 | 64.07 | 65.40 | 59.8 | 60.77 | 60.28 |
| SCRDet | R-101-FPN | 72.34 | 69.88 | 71.09 | 69.91 | 68.57 | 69.23 |
| RoI Transformer | R-101-FPN | 92.76 | 90.22 | 91.47 | 87.32 | 83.24 | 85.23 |
| Faster RCNN+ORPN | R-101-FPN | 93.27 | 88.52 | 90.83 | 86.37 | 84.92 | 85.64 |
| Faster RCNN+PBH | R-101-FPN | 92.11 | 88.35 | 90.2 | 85.62 | 84.13 | 84.87 |
| ORP-Det | R-101-FPN | 93.57 | 91.46 | 92.50 | 88.43 | 85.14 | 86.75 |
| ORP-Det w. SEE | R-101-FPN | ∖ | ∖ | ∖ | 90.18 | 86.66 | 88.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, B.; Zhang, Q.; Tong, M.; He, C. Oriented Ship Detector for Remote Sensing Imagery Based on Pairwise Branch Detection Head and SAR Feature Enhancement. Remote Sens. 2022, 14, 2177. https://doi.org/10.3390/rs14092177
He B, Zhang Q, Tong M, He C. Oriented Ship Detector for Remote Sensing Imagery Based on Pairwise Branch Detection Head and SAR Feature Enhancement. Remote Sensing. 2022; 14(9):2177. https://doi.org/10.3390/rs14092177
Chicago/Turabian StyleHe, Bokun, Qingyi Zhang, Ming Tong, and Chu He. 2022. "Oriented Ship Detector for Remote Sensing Imagery Based on Pairwise Branch Detection Head and SAR Feature Enhancement" Remote Sensing 14, no. 9: 2177. https://doi.org/10.3390/rs14092177
APA StyleHe, B., Zhang, Q., Tong, M., & He, C. (2022). Oriented Ship Detector for Remote Sensing Imagery Based on Pairwise Branch Detection Head and SAR Feature Enhancement. Remote Sensing, 14(9), 2177. https://doi.org/10.3390/rs14092177