
Full Convolution Neural Network Combined with Contextual Feature Representation for Cropland Extraction from High-Resolution Remote Sensing Images

 ,
, 
 ,
,
Abstract
:
1. Introduction
- A fully convolution neural network combined with a multiple-scales framework is presented to extract cropland on a county or city scale from high-resolution remote sensing images.
- In order to solve the heterogeneity of cropland objectives, we propose the CFR module, which is connected to obtain the features of the fusion context for semantic segmentation. It focuses on more high-level features and improves the separability of targets that are more easily confused with cropland.
- The global optimization based on morphological post-processing algorithm obtains the cropland boundary closer to the real situation. It improves the overall accuracy of cropland segmentation.
2. Related Work
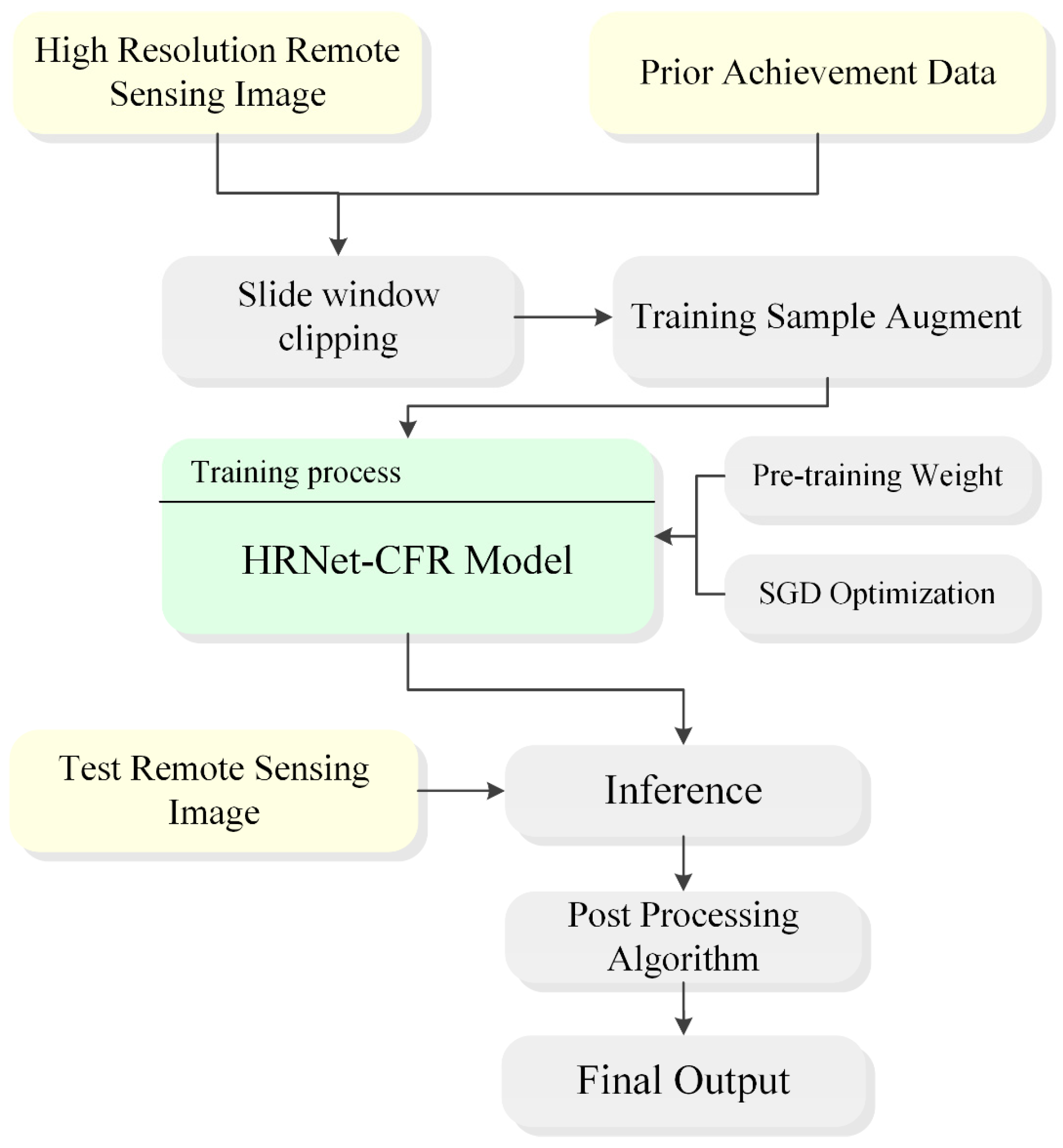
3. Proposed Method
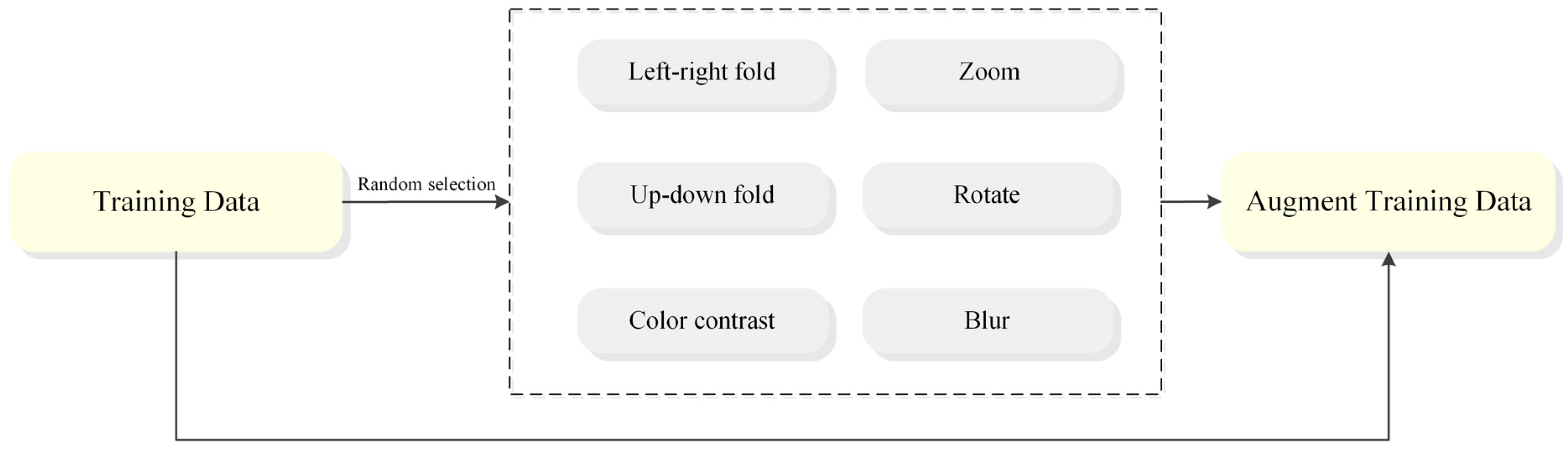
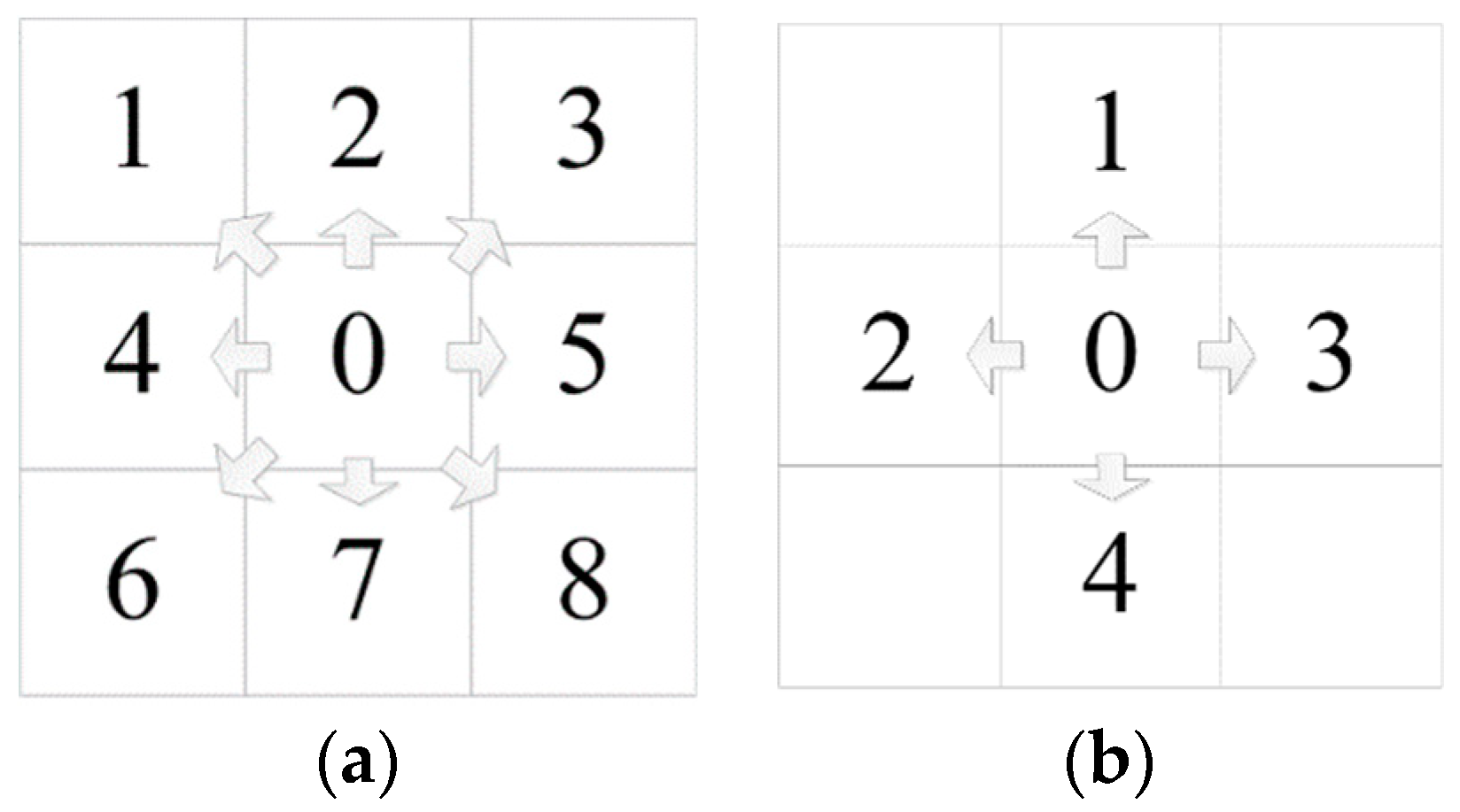
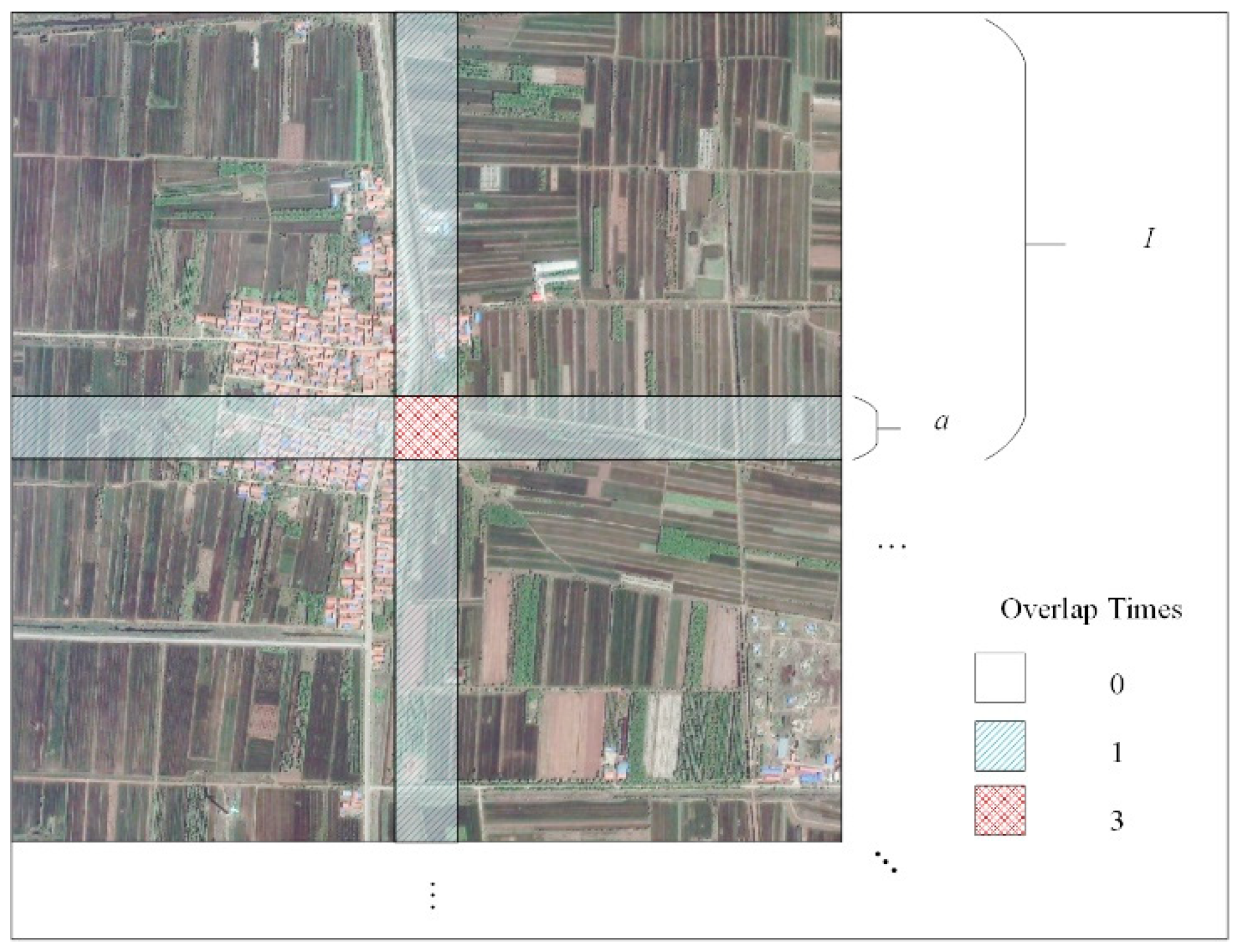
3.1. Sample Increment
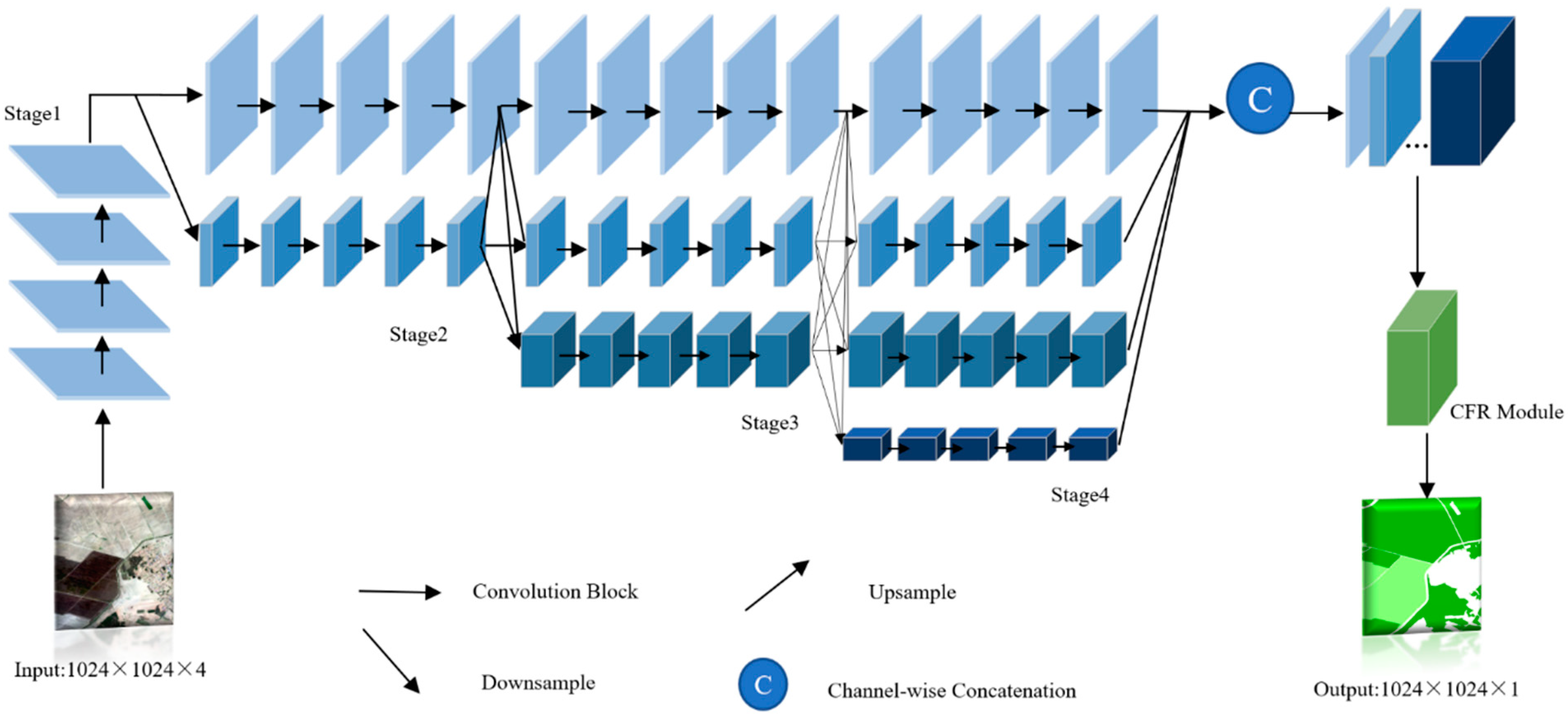
3.2. HRNet-CFR Model
3.2.1. Backbone Network
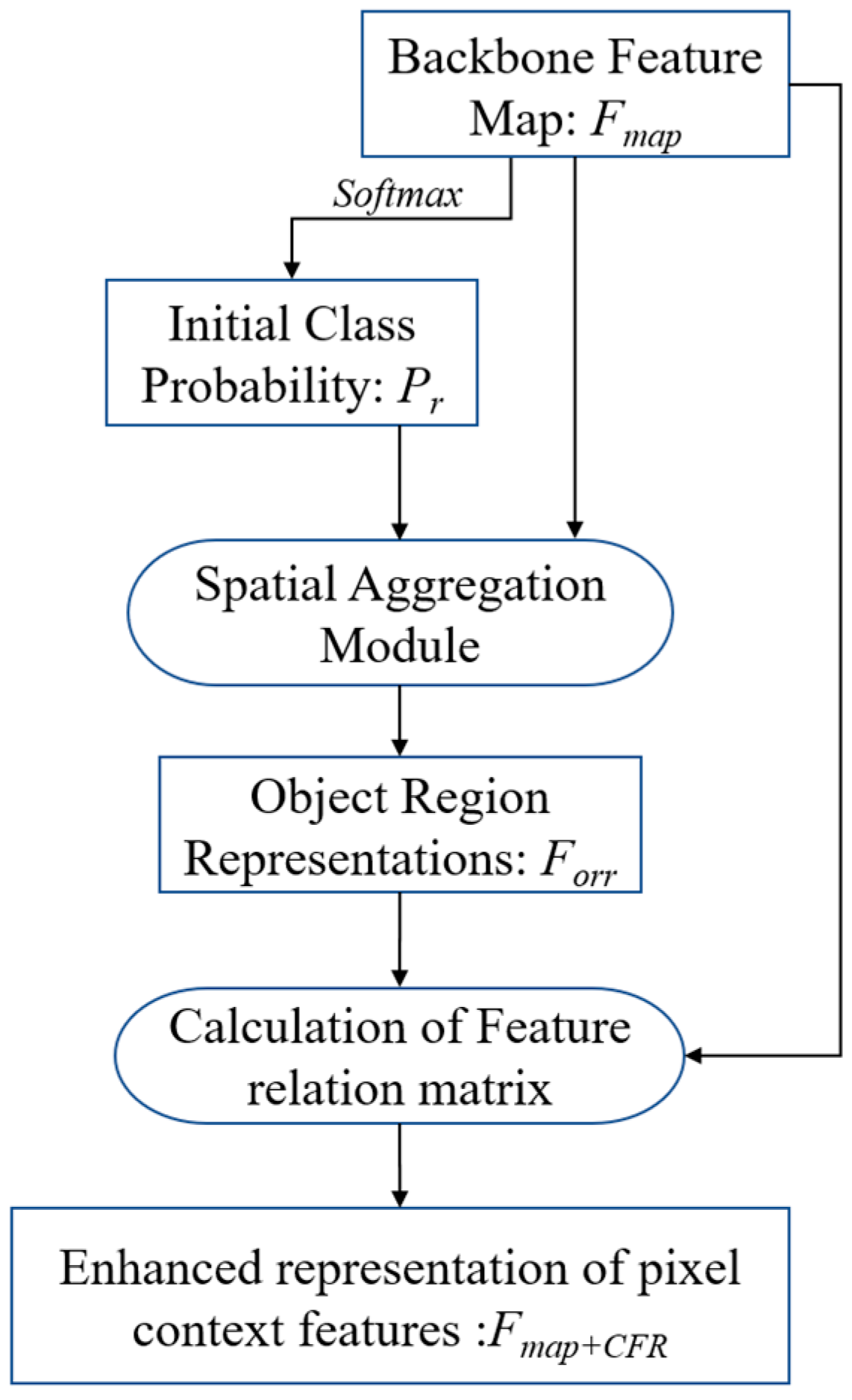
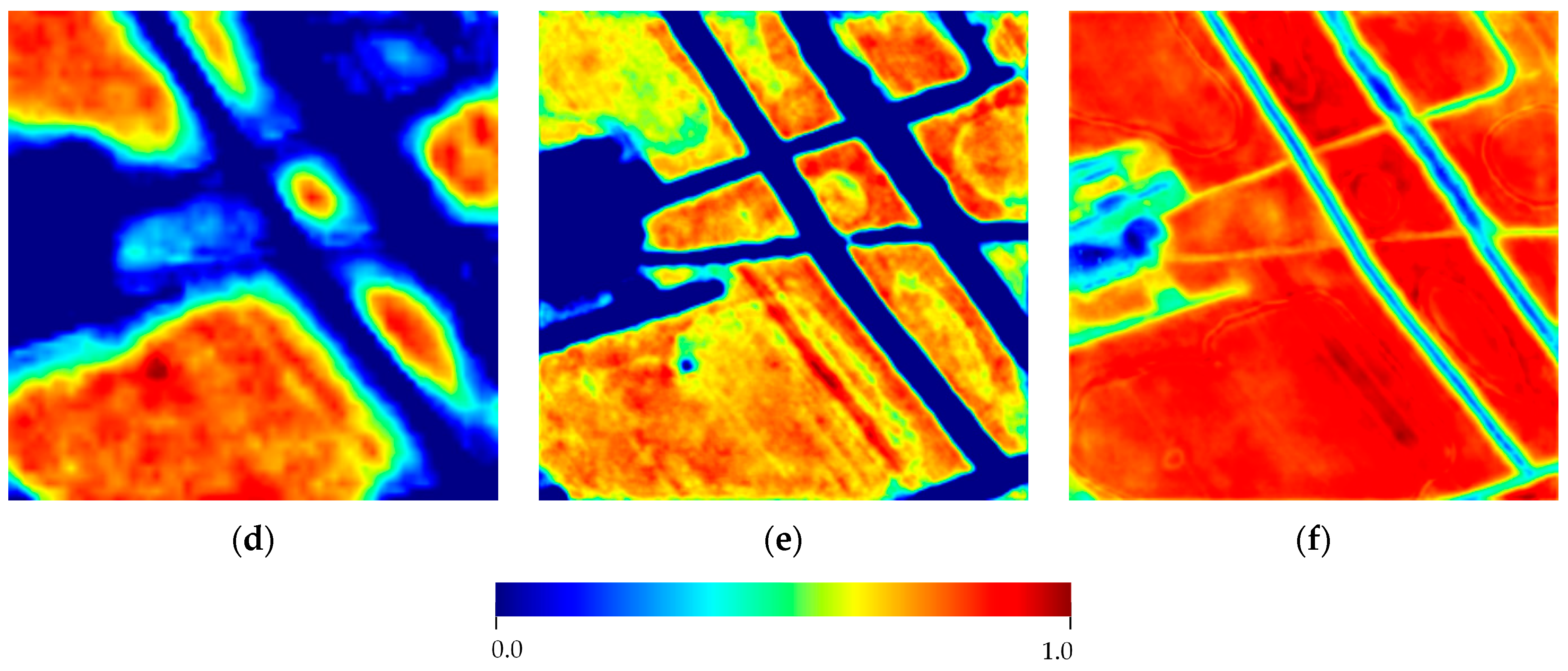
3.2.2. CFR Module
- (1)
- Generate an Initial Probability Map
- (2)
- Calculate Object Region Representations
- (3)
- Obtain Context Feature Representations
3.3. Morphological Post-Processing
4. Experiment and Result
4.1. Data Description
- Jilin-1 Dataset
GID Dataset
4.2. Experimental Settings
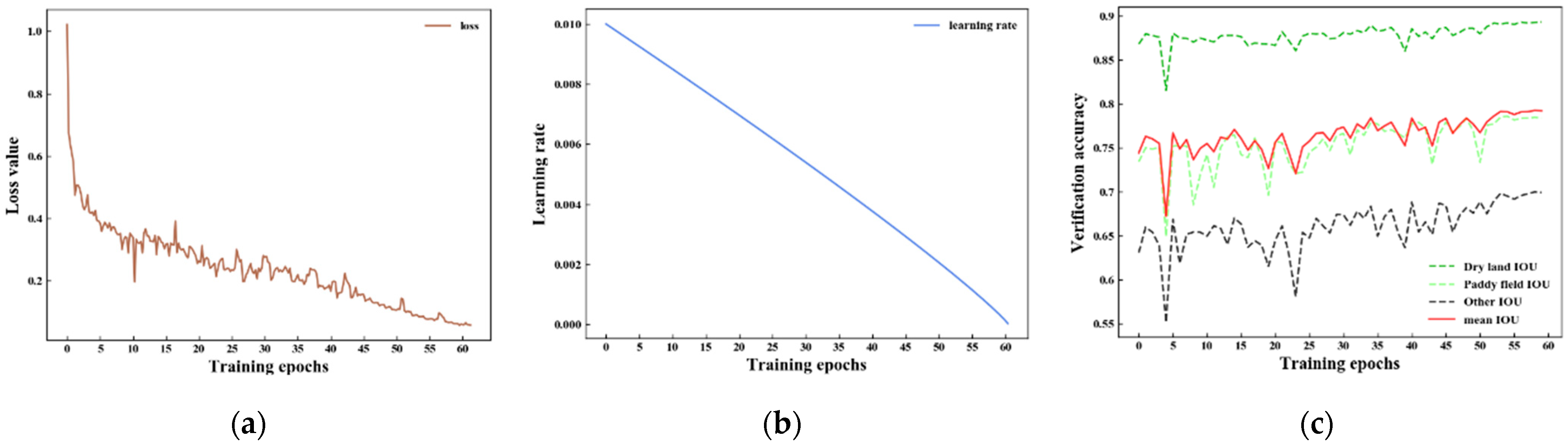
4.3. Network Training
4.4. Evaluation of Results
4.4.1. Accuracy Assessment
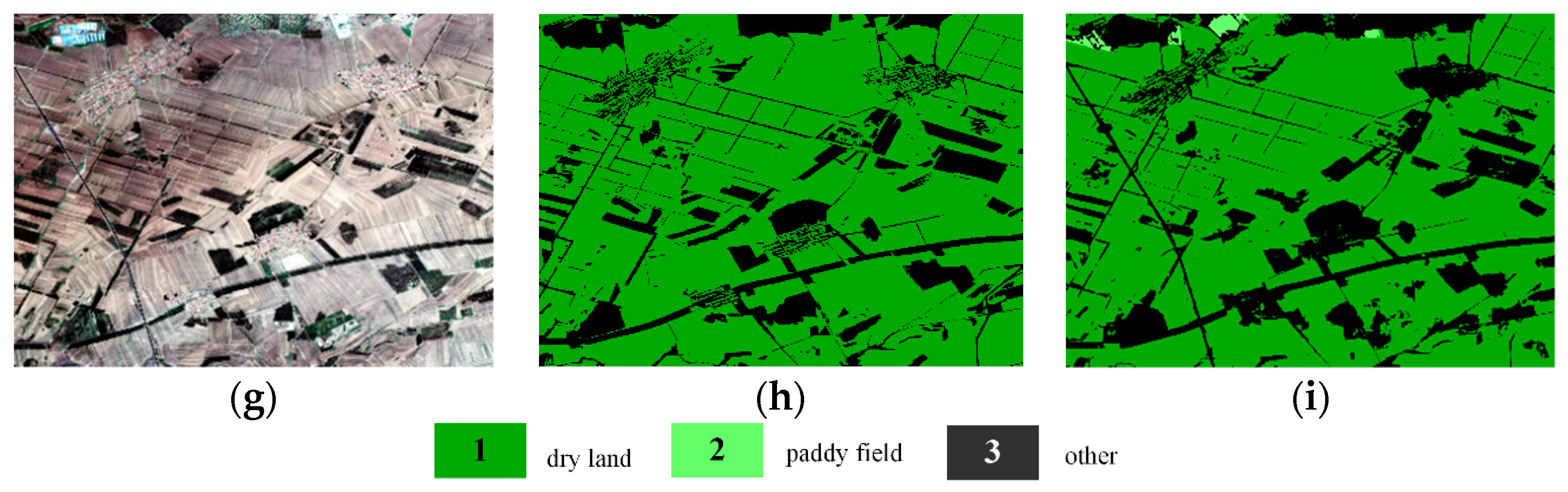
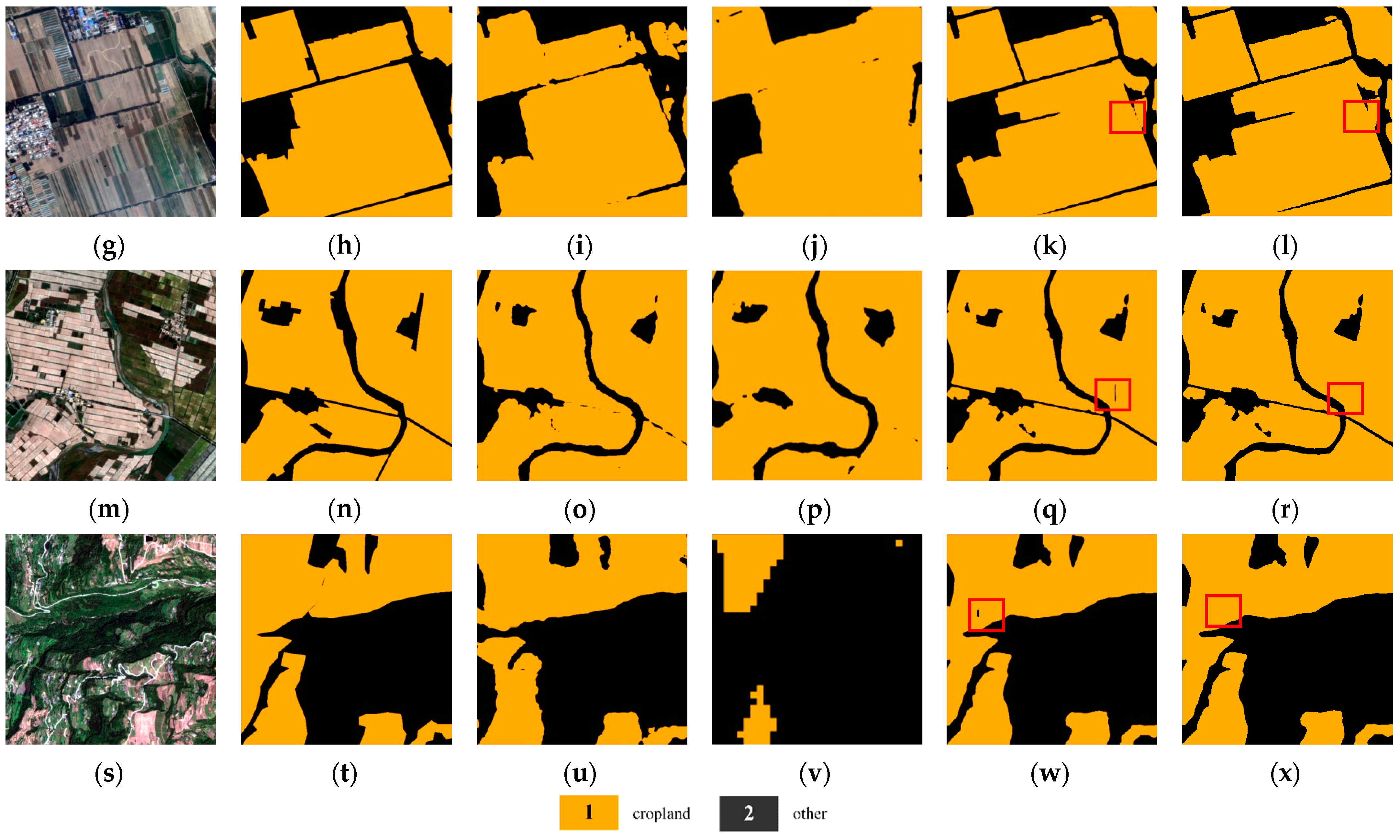
4.4.2. Results of Jilin-1 Dataset
4.4.3. Regional Cropland Extraction
5. Discussion
5.1. Network Structure Analysis
5.2. Comparison with Other Methods
5.3. Potential and Limitations for Cropland Extraction
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| HRNet | High-resolution network |
| CFR | Contextual feature representation |
| GID | Gaofen Image Dataset |
| FCN | Full convolution network |
| DCNN | Deep convolutional neural network |
| PSPNet | Pyramid scene parsing network |
| UPerNet | Unified perceptual network |
| ORR | Object region representation |
| IoU | Intersection over Union |
| OA | Overall accuracy |
| SGD | Stochastic Gradient Descent |
| ReLU | Rectified linear unit |
References
- Debats, S.R.; Luo, D.; Estes, L.D.; Fuchs, T.J.; Caylor, K.K. A generalized computer vision approach to mapping crop fields in heterogeneous agricultural landscapes. Remote Sens. Environ. 2016, 179, 210–221. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object-based time-weighted dynamic time warping analysis. Remote Sens. Environ. 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Berman, M.; Triki, A.R.; Blaschko, M.B. The lovász-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4413–4421. [Google Scholar]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef] [Green Version]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xue, Y.; Zhao, J.; Zhang, M. A Watershed-Segmentation-Based Improved Algorithm for Extracting Cultivated Land Boundaries. Remote Sens. 2021, 13, 939. [Google Scholar] [CrossRef]
- Su, T.; Li, H.; Zhang, S.; Li, Y. Image segmentation using mean shift for extracting croplands from high-resolution remote sensing imagery. Remote Sens. Lett. 2015, 6, 952–961. [Google Scholar] [CrossRef]
- Rydberg, A.; Borgefors, G. Integrated method for boundary delineation of agricultural fields in multispectral satellite images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2514–2520. [Google Scholar] [CrossRef]
- Graesser, J.; Ramankutty, N. Detection of cropland field parcels from Landsat imagery. Remote Sens. Environ. 2017, 201, 165–180. [Google Scholar] [CrossRef] [Green Version]
- Hong, R.; Park, J.; Jang, S.; Shin, H.; Kim, H.; Song, I. Development of a Parcel-Level Land Boundary Extraction Algorithm for Aerial Imagery of Regularly Arranged Agricultural Areas. Remote Sens. 2021, 13, 1167. [Google Scholar] [CrossRef]
- Wei, S.; Hong, Q.; Hou, M. Automatic image segmentation based on PCNN with adaptive threshold time constant. Neurocomputing 2011, 74, 1485–1491. [Google Scholar] [CrossRef]
- Wu, J. Efficient HIK SVM learning for image classification. IEEE Trans. Image Process. 2012, 21, 4442–4453. [Google Scholar]
- Yao, Y.; Si, H.; Wang, D. Object oriented extraction of reserve resources area for cultivated land using RapidEye image data. In Proceedings of the 2014 3rd International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Beijing, China, 11–14 August 2014; pp. 1–4. [Google Scholar]
- Xia, J.; Ghamisi, P.; Yokoya, N.; Iwasaki, A. Random forest ensembles and extended multiextinction profiles for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 202–216. [Google Scholar] [CrossRef] [Green Version]
- Dou, P.; Chen, Y.; Yue, H. Remote-sensing imagery classification using multiple classification algorithm-based AdaBoost. Int. J. Remote Sens. 2018, 39, 619–639. [Google Scholar] [CrossRef]
- Ruiz, P.; Mateos, J.; Camps-Valls, G.; Molina, R.; Katsaggelos, A.K. Bayesian active remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2013, 52, 2186–2196. [Google Scholar] [CrossRef]
- Csillik, O.; Belgiu, M. Cropland mapping from Sentinel-2 time series data using object-based image analysis. In Proceedings of the 20th AGILE International Conference on Geographic Information Science Societal Geo-Innovation Celebrating, Wageningen, The Netherlands, 9-12 May 2017; pp. 9–12. [Google Scholar]
- Zhang, Z.; Liu, S.; Zhang, Y.; Chen, W. RS-DARTS: A Convolutional Neural Architecture Search for Remote Sensing Image Scene Classification. Remote Sens. 2022, 14, 141. [Google Scholar] [CrossRef]
- Yuan, M.; Zhang, Q.; Li, Y.; Yan, Y.; Zhu, Y. A Suspicious Multi-Object Detection and Recognition Method for Millimeter Wave SAR Security Inspection Images Based on Multi-Path Extraction Network. Remote Sens. 2021, 13, 4978. [Google Scholar] [CrossRef]
- Chen, G.; Tan, X.; Guo, B.; Zhu, K.; Liao, P.; Wang, T.; Wang, Q.; Zhang, X. SDFCNv2: An Improved FCN Framework for Remote Sensing Images Semantic Segmentation. Remote Sens. 2021, 13, 4902. [Google Scholar] [CrossRef]
- Hua, Y.; Marcos, D.; Mou, L.; Zhu, X.X.; Tuia, D. Semantic segmentation of remote sensing images with sparse annotations. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Sharma, A.; Liu, X.; Yang, X.; Shi, D. A patch-based convolutional neural network for remote sensing image classification. Neural Netw. 2017, 95, 19–28. [Google Scholar] [CrossRef]
- Cao, X.; Zhou, F.; Xu, L.; Meng, D.; Xu, Z.; Paisley, J. Hyperspectral image classification with Markov random fields and a convolutional neural network. IEEE Trans. Image Process. 2018, 27, 2354–2367. [Google Scholar] [CrossRef] [Green Version]
- Jeon, M.; Jeong, Y.-S. Compact and Accurate Scene Text Detector. Appl. Sci. 2020, 10, 2096. [Google Scholar] [CrossRef] [Green Version]
- Vu, T.; Van Nguyen, C.; Pham, T.X.; Luu, T.M.; Yoo, C.D. Fast and efficient image quality enhancement via desubpixel convolutional neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Alom, M.Z.; Yakopcic, C.; Hasan, M.; Taha, T.M.; Asari, V.K. Recurrent residual U-Net for medical image segmentation. J. Med. Imaging 2019, 6, 014006. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yan, L.; Liu, D.; Xiang, Q.; Luo, Y.; Wang, T.; Wu, D.; Chen, H.; Zhang, Y.; Li, Q. PSP Net-based Automatic Segmentation Network Model for Prostate Magnetic Resonance Imaging. Comput. Methods Programs Biomed. 2021, 207, 106211. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Wang, C.; Du, P.; Wu, H.; Li, J.; Zhao, C.; Zhu, H. A cucumber leaf disease severity classification method based on the fusion of DeepLabV3+ and U-Net. Comput. Electron. Agric. 2021, 189, 106373. [Google Scholar] [CrossRef]
- Lu, J.; Jia, H.; Li, T.; Li, Z.; Ma, J.; Zhu, R. An Instance Segmentation-Based Framework for a Large-Sized High-Resolution Remote Sensing Image Registration. Remote Sens. 2021, 13, 1657. [Google Scholar] [CrossRef]
- Zhang, X.; Cheng, B.; Chen, J.; Liang, C. High-Resolution Boundary Refined Convolutional Neural Network for Automatic Agricultural Greenhouses Extraction from GaoFen-2 Satellite Imageries. Remote Sens. 2021, 13, 4237. [Google Scholar] [CrossRef]
- Zhou, N.; Yang, P.; Wei, C.; Shen, Z.; Yu, J.; Ma, X.; Luo, J. Accurate extraction method for cropland in mountainous areas based on field parcel. Trans. Chin. Agri. Eng. 2021, 36, 260–266. [Google Scholar]
- Cao, K.; Zhang, X. An improved res-unet model for tree species classification using airborne high-resolution images. Remote Sens. 2020, 12, 1128. [Google Scholar] [CrossRef] [Green Version]
- Shang, R.; Zhang, J.; Jiao, L.; Li, Y.; Marturi, N.; Stolkin, R. Multi-scale adaptive feature fusion network for semantic segmentation in remote sensing images. Remote Sens. 2020, 12, 872. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Chen, C.; Ding, M.; Li, J. Real-time dense semantic labeling with dual-Path framework for high-resolution remote sensing image. Remote Sens. 2019, 11, 3020. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Chen, W.; Xie, S.M.; Azzari, G.; Lobell, D.B. Weakly supervised deep learning for segmentation of remote sensing imagery. Remote Sens. 2020, 12, 207. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Peng, L.; Hu, Y.; Chi, T. FD-RCF-based boundary delineation of agricultural fields in high resolution remote sensing images. J. U. Chin. Acad. Sci. 2020, 37, 483–489. [Google Scholar]
- Xia, L.; Luo, J.; Sun, Y.; Yang, H. Deep extraction of cropland parcels from very high-resolution remotely sensed imagery. In Proceedings of the 2018 7th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Hangzhou, China, 6–9 August 2018; pp. 1–5. [Google Scholar]
- Bao, P.; Zhang, L.; Wu, X. Canny edge detection enhancement by scale multiplication. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1485–1490. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Masoud, K.M.; Persello, C.; Tolpekin, V.A. Delineation of agricultural field boundaries from Sentinel-2 images using a novel super-resolution contour detector based on fully convolutional networks. Remote Sens. 2019, 12, 59. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Pan, Y.; Zhang, J.; Hu, T.; Zhao, J.; Li, N.; Chen, Q. A generalized approach based on convolutional neural networks for large area cropland mapping at very high resolution. Remote Sens. Environ. 2020, 247, 111912. [Google Scholar] [CrossRef]
- Jung, A.B. Imgaug. Available online: https://imgaug.readthedocs.io/en/latest/index.html (accessed on 30 October 2018).
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Hirayama, H.; Sharma, R.C.; Tomita, M.; Hara, K. Evaluating multiple classifier system for the reduction of salt-and-pepper noise in the classification of very-high-resolution satellite images. Int. J. Remote Sens. 2019, 40, 2542–2557. [Google Scholar] [CrossRef]
- Hossain, M.D.; Chen, D. Segmentation for Object-Based Image Analysis (OBIA): A review of algorithms and challenges from remote sensing perspective. ISPRS J. Photogramm. Remote Sens. 2019, 150, 115–134. [Google Scholar] [CrossRef]
- He, Z.; He, D.; Mei, X.; Hu, S. Wetland classification based on a new efficient generative adversarial network and Jilin-1 satellite image. Remote Sens. 2019, 11, 2455. [Google Scholar] [CrossRef] [Green Version]
- Zhu, R.; Ma, J.; Li, Z.; Meng, X.; Wang, D.; An, Y.; Zhong, X.; Gao, F.; Meng, X. Domestic multispectral image classification based on multilayer perception convolution neural network. Acta. Opt. Sin. 2020, 40, 1528003. [Google Scholar]
- Li, Z.; Zhu, R.; Ma, J.; Meng, X.; Wang, D.; Liu, S. Airport detection method combined with continuous learning of residual-based network on remote sensing image. Acta. Opt. Sin. 2020, 40, 1628005. [Google Scholar]
- Dang, B.; Li, Y. MSResNet: Multiscale Residual Network via Self-Supervised Learning for Water-Body Detection in Remote Sensing Imagery. Remote Sens. 2021, 13, 3122. [Google Scholar] [CrossRef]
- He, C.; Li, S.; Xiong, D.; Fang, P.; Liao, M. Remote sensing image semantic segmentation based on edge information guidance. Remote Sens. 2020, 12, 1501. [Google Scholar] [CrossRef]
- Li, J.; Xiu, J.; Yang, Z.; Liu, C. Dual Path Attention Net for Remote Sensing Semantic Image Segmentation. ISPRS Int. J. Geo-Inf. 2020, 9, 571. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Zhang, Y.; Yang, J.; Wang, D.; Wang, J.; Yu, L.; Yan, F.; Chang, L.; Zhang, S. An Integrated CNN Model for Reconstructing and Predicting Land Use/Cover Change: A Case Study of the Baicheng Area, Northeast China. Remote Sens. 2021, 13, 4846. [Google Scholar] [CrossRef]
- Discussion on the “non-grain” problem of cultivated land in Qingyun County Natural Resources Bureau. Available online: http://www.qingyun.gov.cn/n31116548/n31119226/n31120576/c65422460/content.html (accessed on 18 October 2021).
- Li, X.; He, H.; Li, X.; Li, D.; Cheng, G.; Shi, J.; Weng, L.; Tong, Y.; Lin, Z. PointFlow: Flowing Semantics Through Points for Aerial Image Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Place Virtually, 19–25 June 2021; pp. 4217–4226. [Google Scholar]
- Bazzi, H.; Baghdadi, N.; El Hajj, M.; Zribi, M.; Minh, D.H.T.; Ndikumana, E.; Courault, D.; Belhouchette, H. Mapping Paddy Rice Using Sentinel-1 SAR Time Series in Camargue, France. Remote Sens. 2019, 11, 887. [Google Scholar] [CrossRef] [Green Version]
- Li, N.; Huo, H.; Fang, T. A novel texture-preceded segmentation algorithm for high-resolution imagery. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2818–2828. [Google Scholar]
- Li, J.; Shen, Y.; Yang, C. An Adversarial Generative Network for Crop Classification from Remote Sensing Timeseries Images. Remote Sens. 2021, 13, 65. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, X.; Hu, Y.; Yang, Y.; Cao, X.; Zhen, X. Few-shot semantic segmentation with democratic attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), online, 23–28 August 2020. [Google Scholar]
- Naushad, R.; Kaur, T.; Ghaderpour, E. Deep Transfer Learning for Land Use and Land Cover Classification: A Comparative Study. Sensors 2021, 21, 8083. [Google Scholar] [CrossRef]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Name | Date | Data Source | Region | Resolution (m) | Original Training Images | Final Training Images | Validation Images | Test Images |
|---|---|---|---|---|---|---|---|---|
| Jilin-1 | 2020/03-04 | Jilin-1KF | ChangChun | 0.75 | 1490 | 2235 | 1341 | 894 |
| 2020/06-07 | Jilin-1KF | ChangChun | 0.75 | 1490 | 2235 | 1341 | 894 | |
| 2020/06-07 | Jilin-1KF | BaiCheng | 0.75 | 1490 | 2235 | 1341 | 894 | |
| 2020/07-08 | Jilin-1KF | NongAn | 0.75 | 1490 | 2235 | 1341 | 894 | |
| GID | Different times | GF-2 | More than 60 different cities | 4.0 | 1126 | 1690 | 1041 | 676 |
| Region | Method | Date | Number of Bands | IoU | OA | |||
|---|---|---|---|---|---|---|---|---|
| Dry Land | Paddy Field | Others | Mean | |||||
| ChangChun | HRNet | March–April | 4 | 0.898 | 0.746 | 0.592 | 0.746 | 91.15% |
| March–April | 3 | 0.877 | 0.763 | 0.669 | 0.770 | 90.14% | ||
| June–July | 4 | 0.940 | 0.770 | 0.659 | 0.789 | 94.49% | ||
| March–April | 3 | 0.892 | 0.784 | 0.700 | 0.758 | 91.34% | ||
| HRNet-CFR | June–July | 4 | 0.941 | 0.817 | 0.627 | 0.795 | 94.58% | |
| BaiCheng | HRNet-CFR | June–July | 4 | 0.926 | 0.856 | 0.686 | 0.822 | 93.61% |
| Module | Convolution | Kernels’ Number | Convolution Parameter | Input | Output |
|---|---|---|---|---|---|
| Stem Net | Conv1 | 64 | k: 3 × 3, s: 2, p: 1 | 1024 × 1024 × 4 | 512 × 512 × 64 |
| Conv2 | 64 | k: 3 × 3, s: 2, p: 1 | 512 × 512 × 64 | 256 × 256 × 256 | |
| Stage1 | Conv | 256 | k: 1 × 1, s: 1 | 256 × 256 × 256 | 256 × 256 × 256 |
| Stage2 | Conv | 48 | k: 3 × 3, s: 1, p: 1 | 256 × 256 × 256 | 256 × 256 × 48 |
| 96 | k: 3 × 3, s: 2, p: 1 | 256 × 256 × 48 | 128 × 128 × 96 | ||
| Stage3 | Conv | 48 | k: 3 × 3, s: 1, p: 1 | 256 × 256 × 48 | 256 × 256 × 48 |
| 96 | k: 3 × 3, s: 1, p: 1 | 128 × 128 × 96 | 128 × 128 × 96 | ||
| 192 | k: 3 × 3, s: 2, p: 1 | 128 × 128 × 96 | 64 × 64 × 192 | ||
| Stage4 | Conv | 48 | k: 3 × 3, s: 1, p: 1 | 256 × 256 × 48 | 256 × 256 × 48 |
| 96 | k: 3 × 3, s: 1, p: 1 | 128 × 128 × 96 | 128 × 128 × 96 | ||
| 192 | k: 3 × 3, s: 1, p: 1 | 64 × 64 × 192 | 64 × 64 × 192 | ||
| 384 | k: 3 × 3, s: 2, p: 1 | 64 × 64 × 192 | 32 × 32 × 384 | ||
| CFR | Softmax | - | - | 256 × 256 × 720 | L × 256 × 256 |
| Conv | 512 | k: 1 × 1, s: 1 | Stage4; L × 512 | 256 × 256 × 512 |
| Method | Image Test Size | IoU | OA | Inference Time/s | ||
|---|---|---|---|---|---|---|
| Cropland | Other | Mean | ||||
| Deeplabv3+ | 512 × 512 × 4 | 0.777 | 0.812 | 0.795 | 88.64% | 1.27 |
| UPerNet | 0.753 | 0.806 | 0.779 | 86.91% | 1.12 | |
| HRNet-CFR | 0.810 | 0.833 | 0.821 | 90.22% | 1.01 | |
| HRNet-CFR+ | 0.824 | 0.852 | 0.838 | 92.03% | 1.15 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Chen, S.; Meng, X.; Zhu, R.; Lu, J.; Cao, L.; Lu, P. Full Convolution Neural Network Combined with Contextual Feature Representation for Cropland Extraction from High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 2157. https://doi.org/10.3390/rs14092157
Li Z, Chen S, Meng X, Zhu R, Lu J, Cao L, Lu P. Full Convolution Neural Network Combined with Contextual Feature Representation for Cropland Extraction from High-Resolution Remote Sensing Images. Remote Sensing. 2022; 14(9):2157. https://doi.org/10.3390/rs14092157
Chicago/Turabian StyleLi, Zhuqiang, Shengbo Chen, Xiangyu Meng, Ruifei Zhu, Junyan Lu, Lisai Cao, and Peng Lu. 2022. "Full Convolution Neural Network Combined with Contextual Feature Representation for Cropland Extraction from High-Resolution Remote Sensing Images" Remote Sensing 14, no. 9: 2157. https://doi.org/10.3390/rs14092157
APA StyleLi, Z., Chen, S., Meng, X., Zhu, R., Lu, J., Cao, L., & Lu, P. (2022). Full Convolution Neural Network Combined with Contextual Feature Representation for Cropland Extraction from High-Resolution Remote Sensing Images. Remote Sensing, 14(9), 2157. https://doi.org/10.3390/rs14092157